このチュートリアルでは、ARIMA_PLUS 単変量時系列モデルを使用し、特定の列の過去の値に基づいて、その列の将来の値を予測する方法について説明します。
このチュートリアルでは、単一の時系列を予測します。予測値は、入力データの各時点に対して 1 回ずつ計算されます。
このチュートリアルでは、一般公開サンプル テーブル bigquery-public-data.google_analytics_sample.ga_sessions のデータを使用します。このテーブルには、Google Merchandise Store の難読化された e コマースデータが含まれています。
目標
このチュートリアルでは、次のタスクの手順について説明します。
CREATE MODELステートメントを使用して、サイト トラフィックを予測する時系列モデルを作成します。ML.ARIMA_EVALUATE関数を使用して、モデル内の自己回帰統合移動平均(ARIMA)情報を評価します。ML.ARIMA_COEFFICIENTS関数を使用してモデルの係数を検査します。ML.FORECAST関数を使用して、モデルから予測されたサイト トラフィック情報を取得します。ML.EXPLAIN_FORECAST関数を使用して、季節性やトレンドなどの時系列のコンポーネントを取得します。これらの時系列コンポーネントを調べて、予測値を説明できます。
費用
このチュートリアルでは、課金対象となる以下の Google Cloudのコンポーネントを使用しています。
- BigQuery
- BigQuery ML
BigQuery の費用の詳細については、BigQuery の料金ページをご覧ください。
BigQuery ML の費用の詳細については、BigQuery ML の料金をご覧ください。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
- 新しいプロジェクトでは、BigQuery が自動的に有効になります。既存のプロジェクトで BigQuery を有効にするには、
Enable the BigQuery API.
に移動します。 データセットを作成するには、
bigquery.datasets.createIAM 権限が必要です。モデルを作成するには、次の権限が必要です。
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
推論を実行するには、次の権限が必要です。
bigquery.models.getDatabigquery.jobs.create
必要な権限
BigQuery における IAM ロールと権限の詳細については、IAM の概要をご覧ください。
データセットを作成する
ML モデルを保存する BigQuery データセットを作成します。
コンソール
Google Cloud コンソールで、[BigQuery] ページに移動します。
[エクスプローラ] ペインで、プロジェクト名をクリックします。
[アクションを表示] > [データセットを作成] をクリックします。
![[データセットを作成] のメニュー オプション。](https://cloud.google.com/static/bigquery/images/create-dataset.png?hl=ja)
[データセットを作成] ページで、次の操作を行います。
[データセット ID] に「
bqml_tutorial」と入力します。[ロケーション タイプ] で [マルチリージョン] を選択してから、[US(米国の複数のリージョン)] を選択します。
残りのデフォルトの設定は変更せず、[データセットを作成] をクリックします。
bq
新しいデータセットを作成するには、--location フラグを指定した bq mk コマンドを使用します。使用可能なパラメータの一覧については、bq mk --dataset コマンドのリファレンスをご覧ください。
データの場所が
USに設定され、BigQuery ML tutorial datasetという説明の付いた、bqml_tutorialという名前のデータセットを作成します。bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
このコマンドでは、
--datasetフラグの代わりに-dショートカットを使用しています。-dと--datasetを省略した場合、このコマンドはデフォルトでデータセットを作成します。データセットが作成されたことを確認します。
bq ls
API
定義済みのデータセット リソースを使用して datasets.insert メソッドを呼び出します。
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
入力データを可視化する
モデルを作成する前に、必要に応じて入力時系列データを可視化して分布を把握できます。これは、Looker Studio を使用して行います。
時系列データを可視化する手順は次のとおりです。
SQL
次の GoogleSQL クエリでは、SELECT ステートメントで入力テーブルの date 列を解析して TIMESTAMP 型に変換し、名前を parsed_date に変更します。また、SUM(...) 句と GROUP BY date 句を使用して、1 日あたりの totals.visits 値を作成します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
SELECT PARSE_TIMESTAMP("%Y%m%d", date) AS parsed_date, SUM(totals.visits) AS total_visits FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` GROUP BY date;
クエリが完了したら、[データを探索] > [Looker Studio で調べる] をクリックします。Looker Studio が新しいタブで開きます。新しいタブで次の操作を行います。
Looker Studio で、[挿入] > [期間グラフ] をクリックします。
[グラフ] ペインで、[設定] タブを選択します。
[指標] セクションで、total_visits フィールドを追加し、デフォルトの指標である [レコード数] を削除します。作成されたグラフは次のようになります。
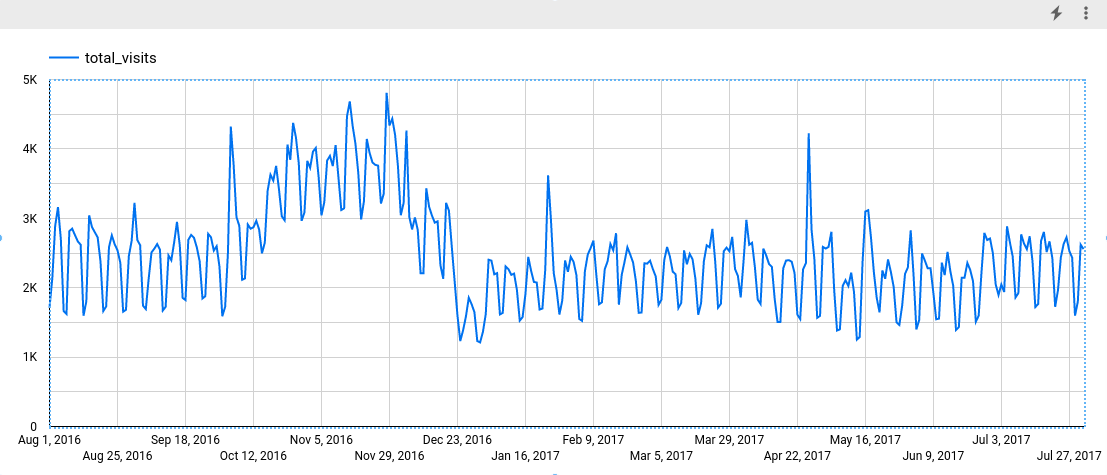
グラフを見ると、入力時系列には週ごとの季節パターンがあることがわかります。
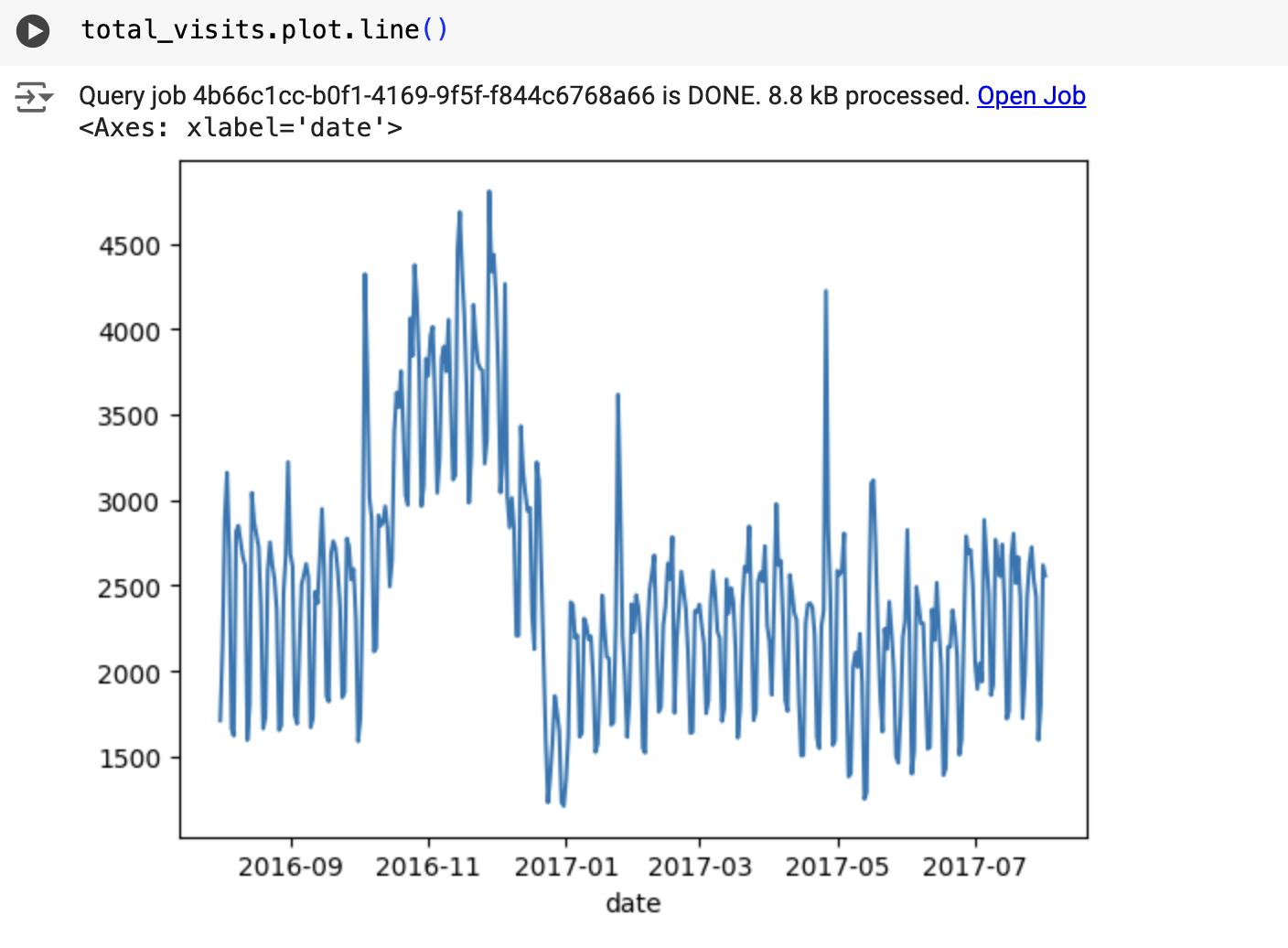
BigQuery DataFrames
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
次のような結果になります。
時系列モデルを作成する
totals.visits 列で表されるサイト訪問数の合計を予測する時系列モデルを作成し、Google アナリティクス 360 のデータでトレーニングします。
SQL
次のクエリの OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...) 句は、ARIMA ベースの時系列モデルを作成していることを示します。CREATE MODEL ステートメントの auto_arima オプションはデフォルトで TRUE であるため、auto.ARIMA アルゴリズムによってモデルのハイパーパラメータが自動的にチューニングされます。アルゴリズムが多数の候補モデルを学習し、Akaike information criterion(AIC)が最も低い最適なモデルを選択します。CREATE MODEL ステートメントの data_frequency オプションはデフォルトで AUTO_FREQUENCY に設定されているため、トレーニング プロセスでは入力時系列のデータ頻度が自動的に推定されます。CREATE MODEL ステートメントの decompose_time_series オプションはデフォルトで TRUE に設定されているため、次のステップでモデルを評価するときに時系列データに関する情報が返されます。
次の手順でモデルを作成します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
CREATE OR REPLACE MODEL `bqml_tutorial.ga_arima_model` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'parsed_date', time_series_data_col = 'total_visits', auto_arima = TRUE, data_frequency = 'AUTO_FREQUENCY', decompose_time_series = TRUE ) AS SELECT PARSE_TIMESTAMP("%Y%m%d", date) AS parsed_date, SUM(totals.visits) AS total_visits FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` GROUP BY date;
クエリが完了するまでに約 4 秒かかります。完了後、
ga_arima_modelモデルが [エクスプローラ] ペインに表示されます。クエリはCREATE MODELステートメントを使用してモデルを作成するため、クエリの結果は表示されません。
BigQuery DataFrames
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
候補モデルを評価する
SQL
ML.ARIMA_EVALUATE 関数を使用して時系列モデルを評価します。ML.ARIMA_EVALUATE ファンクションは、自動ハイパーパラメータ チューニング プロセス中に評価されたすべての候補モデルの評価指標を表示します。
次の手順でモデルを評価します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
SELECT * FROM ML.ARIMA_EVALUATE(MODEL `bqml_tutorial.ga_arima_model`);
結果は次のようになります。

BigQuery DataFrames
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
non_seasonal_p、non_seasonal_d、non_seasonal_q、has_drift の出力列は、トレーニング パイプラインの ARIMA モデルを定義します。log_likelihood、AIC、variance 出力列は、ARIMA モデルの適合プロセスに関連するものです。
auto.ARIMA アルゴリズムは KPSS テストを使用して、non_seasonal_d の最適値を決定します。この場合は 1 になります。non_seasonal_d が 1 の場合、auto.ARIMA アルゴリズムは 42 個の ARIMA 候補モデルを並行してトレーニングします。この例では、42 個の候補モデルがすべて有効であるため、出力には 42 行(ARIMA 候補モデルごとに 1 行)が含まれます。一部のモデルが無効な場合は、出力から除外されます。これらの候補モデルは、AIC の昇順で返されます。最初の行のモデルは AIC が最も低く、最適なモデルとみなされます。この最適モデルが最終モデルとして保存され、モデルで ML.FORECAST などの関数を呼び出すときに使用されます。
seasonal_periods 列には、時系列データで識別された季節パターンに関する情報が含まれます。ARIMA モデリングとは関係がないため、すべての出力行で同じ値になります。週単位でのパターンが報告され、これは入力データを可視化した場合の結果と一致します。
has_holiday_effect、has_spikes_and_dips、has_step_changes 列は、decompose_time_series=TRUE の場合にのみ入力されます。これらの列も、入力時系列データに関する情報が反映されますが、ARIMA モデリングとは関係ありません。また、これらの列の値はすべての出力行で同じになります。
error_message 列には、auto.ARIMA の適合プロセス中に発生したエラーが表示されます。エラーの原因として考えられるのは、選択した non_seasonal_p、non_seasonal_d、non_seasonal_q、has_drift 列で時系列が安定しないことです。すべての候補モデルのエラー メッセージを取得するには、モデルの作成時に show_all_candidate_models オプションを TRUE に設定します。
出力列の詳細については、ML.ARIMA_EVALUATE 関数をご覧ください。
モデルの係数を調べる
SQL
ML.ARIMA_COEFFICIENTS 関数を使用して、時系列モデルの係数を調べます。
モデルの係数を取得する手順は次のとおりです。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
SELECT * FROM ML.ARIMA_COEFFICIENTS(MODEL `bqml_tutorial.ga_arima_model`);
ar_coefficients 出力列には、ARIMA モデルの自己回帰(AR)部分のモデル係数が表示されます。同様に、ma_coefficients 出力列には、ARIMA モデルの移動平均(MA)部分のモデル係数が表示されます。どちらの列にも配列値が含まれ、長さはそれぞれ non_seasonal_p と non_seasonal_q です。ML.ARIMA_EVALUATE ファンクションの出力から、最適なモデルの non_seasonal_p 値は 2、non_seasonal_q 値は 3 となります。したがって、ML.ARIMA_COEFFICIENTS の出力では、ar_coefficients 値は 2 要素の配列で、ma_coefficients 値は 3 要素の配列です。intercept_or_drift は、ARIMA モデルの定数項です。
出力列の詳細については、ML.ARIMA_COEFFICIENTS 関数をご覧ください。
BigQuery DataFrames
coef_ 関数を使用して、時系列モデルの係数を調べます。
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
ar_coefficients 出力列には、ARIMA モデルの自己回帰(AR)部分のモデル係数が表示されます。同様に、ma_coefficients 出力列には、ARIMA モデルの移動平均(MA)部分のモデル係数が表示されます。どちらの列にも配列値が含まれ、長さはそれぞれ non_seasonal_p と non_seasonal_q です。
モデルを使用してデータを予測する
SQL
ML.FORECAST 関数を使用して、将来の時系列値を予測します。
次の GoogleSQL クエリの STRUCT(30 AS horizon, 0.8 AS confidence_level) 句は、30 個の将来の時点を予測し、信頼度レベル 80% の予測間隔を生成するように指示します。
次の手順でモデルを使用し、データを予測します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
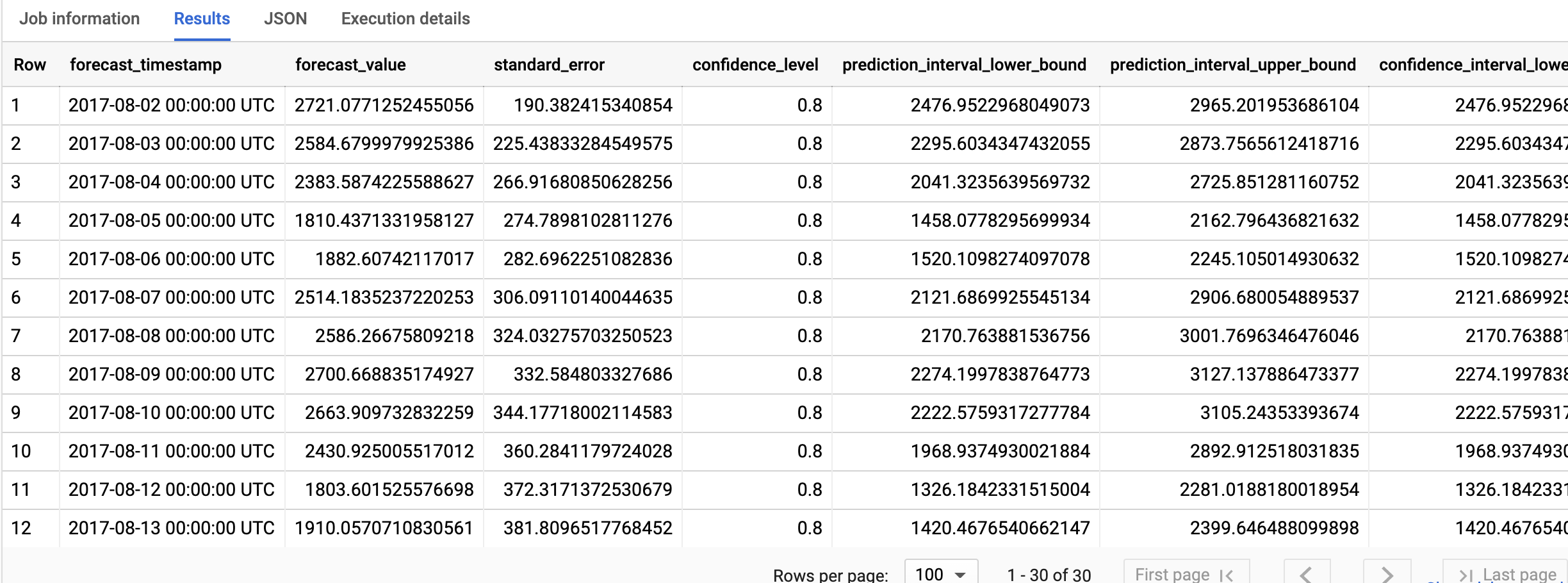
SELECT * FROM ML.FORECAST(MODEL `bqml_tutorial.ga_arima_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level));
結果は次のようになります。
BigQuery DataFrames
predict 関数を使用して、将来の時系列値を予測します。
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
出力行は、forecast_timestamp 列の値で時系列順に並べ替えられます。時系列予測では、prediction_interval_lower_bound 列と prediction_interval_upper_bound 列の値で表される予測間隔は、forecast_value 列の値と同じくらい重要です。forecast_value 値は予測間隔の中間点です。予測間隔は、standard_error 列と confidence_level 列の値によって異なります。
出力列の詳細については、ML.FORECAST 関数をご覧ください。
予測結果を説明する
SQL
ML.EXPLAIN_FORECAST 関数を使用すると、予測データに加えて説明可能性の指標を取得できます。ML.EXPLAIN_FORECAST 関数は、将来の時系列値を予測し、時系列の個別のコンポーネントをすべて返します。
ML.FORECAST 関数と同様に、ML.EXPLAIN_FORECAST 関数で使用される STRUCT(30 AS horizon, 0.8 AS confidence_level) 句は、30 個の将来の時点を予測し、信頼度 80% の予測間隔を生成するように指示します。
モデルの結果を説明する手順は次のとおりです。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
SELECT * FROM ML.EXPLAIN_FORECAST(MODEL `bqml_tutorial.ga_arima_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level));
結果は次のようになります。
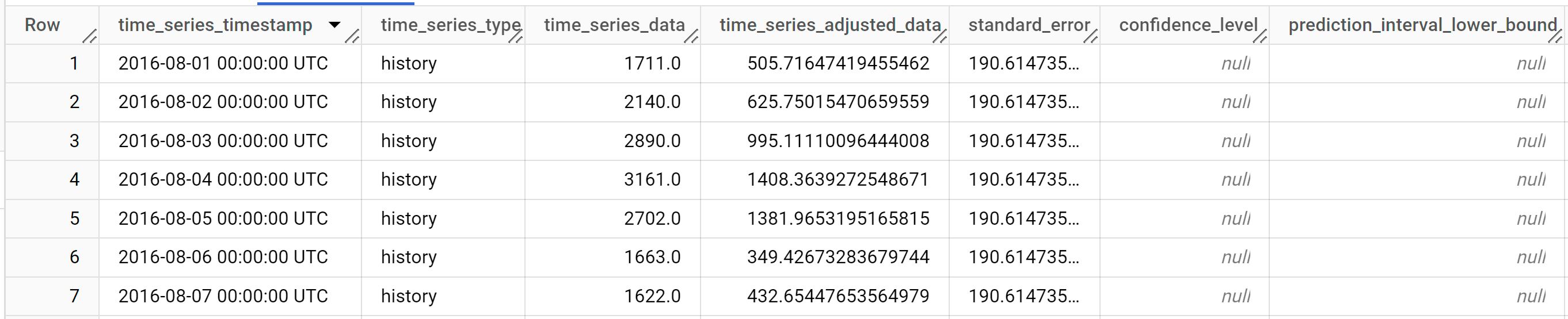
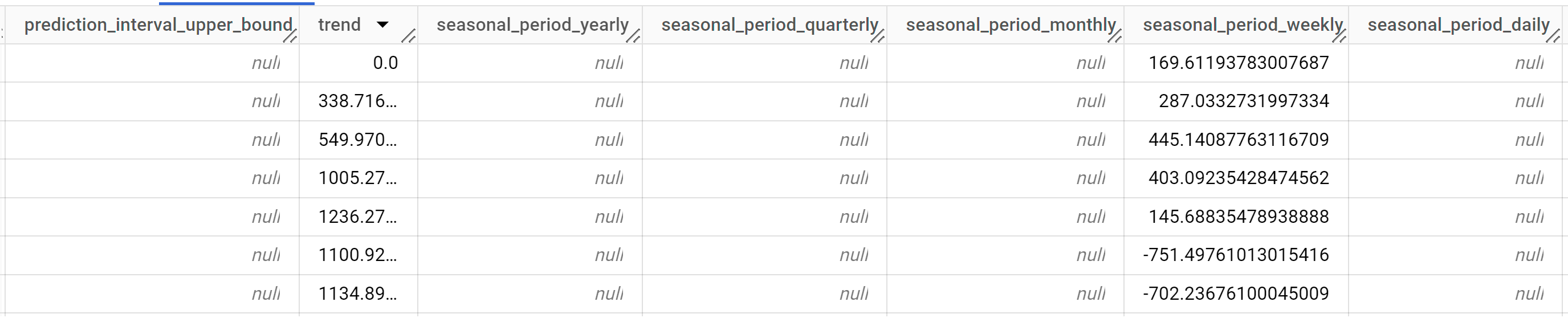
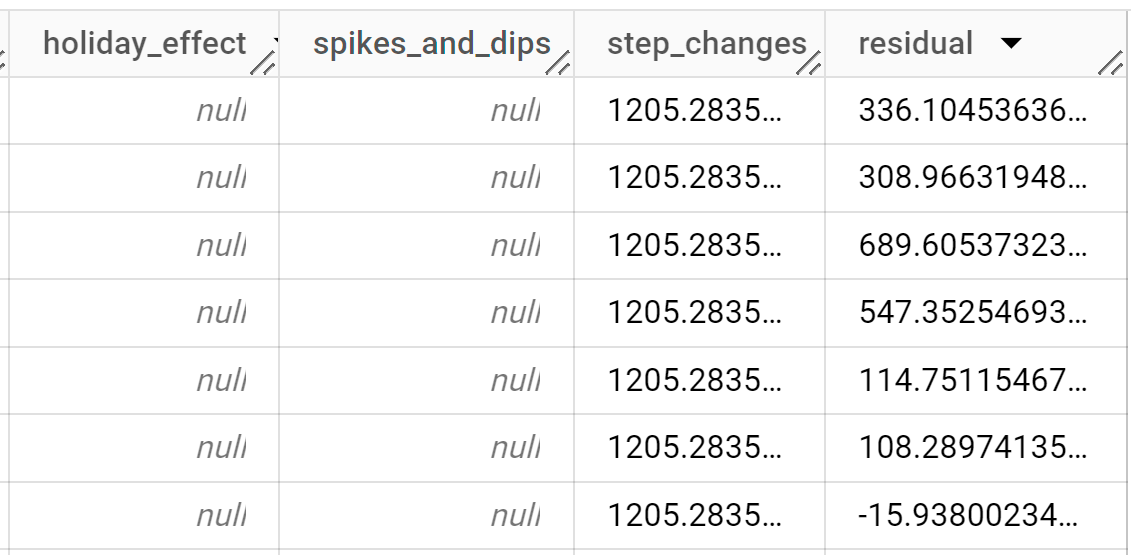
出力行は、
time_series_timestamp列の値で時系列順に表示されます。出力列の詳細については、
ML.EXPLAIN_FORECAST関数をご覧ください。
BigQuery DataFrames
predict_explain 関数を使用すると、予測データに加えて説明可能性の指標を取得できます。predict_explain 関数は、将来の時系列値を予測し、時系列の個別のコンポーネントをすべて返します。
predict 関数と同様に、predict_explain 関数で使用される horizon=30, confidence_level=0.8 句は、30 個の将来の時点を予測し、信頼度 80% の予測間隔を生成するように指示します。
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
結果を可視化するには、入力データを可視化するセクションで説明されているように、Looker Studio を使用して次の列を指標としてチャートを作成します。
time_series_dataprediction_interval_lower_boundprediction_interval_upper_boundtrendseasonal_period_weeklystep_changes
クリーンアップ
このチュートリアルで使用したリソースについて、Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
- 作成したプロジェクトを削除する。
- または、プロジェクトを保存して、データセットを削除する。
データセットを削除する
プロジェクトを削除すると、プロジェクト内のデータセットとテーブルがすべて削除されます。プロジェクトを再利用する場合は、このチュートリアルで作成したデータセットを削除できます。
必要に応じて、Google Cloud コンソールで [BigQuery] ページを開きます。
ナビゲーションで、作成した bqml_tutorial データセットをクリックします。
ウィンドウの右側にある [データセットを削除] をクリックします。この操作を行うと、データセット、テーブル、すべてのデータが削除されます。
[データセットの削除] ダイアログ ボックスでデータセットの名前(
bqml_tutorial)を入力して、[削除] をクリックします。
プロジェクトを削除する
プロジェクトを削除するには、次の操作を行います。
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
次のステップ
- 多変量モデルを使用して単一の時系列を予測する方法を学習する。
- 単変量モデルを使用して複数の時系列を予測する方法を学習する
- 多数の行にわたって複数の時系列を予測する際に単変量モデルをスケーリングする方法を学習する。
- 単変量モデルを使用して複数の時系列を階層的に予測する方法を学習する。
- BigQuery ML の概要について、BigQuery の AI と ML の概要で確認する。