Google Cloud コンソールの詳細を見る
Google Cloud コンソールには、BigQuery リソースの作成と管理、SQL クエリの実行に使用できるグラフィカル インターフェースが用意されています。
Google Cloud コンソールで BigQuery を試すには、クイックスタートの Google Cloud コンソールで一般公開データセットにクエリを実行するをご覧ください。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.新しいプロジェクトでは、BigQuery API が自動的に有効になります。
- (省略可)プロジェクトに対する課金を有効にします。課金を有効にしない場合や、クレジット カードを指定しない場合でも、このドキュメントの手順は行えます。BigQuery には、この手順を実施するためのサンドボックスが用意されています。詳細については、BigQuery サンドボックスを有効にするをご覧ください。
Google Cloud コンソールに移動します。
Google Cloud コンソールのツールバーで、[ ナビゲーション メニュー] をクリックします。
[ソリューション] > [すべてのプロダクト] をクリックします。
[分析] で、[BigQuery] をクリックします。
Google Cloud コンソールのナビゲーション メニューで、[BigQuery] にポインタを合わせます。
[ 固定する] をクリックします。
- BigQuery のナビゲーション メニュー
- 左側のペイン
- 詳細ペイン
[データを追加] ダイアログ
Studio: データセット、テーブル、その他の BigQuery リソースが表示されます。このワークスペースでは、次のような BigQuery の一般的なタスクを実行できます。
- クエリと Colab Enterprise ノートブックを作成、実行、保存、共有する。
- テーブル、ビュー、ルーティン、その他の BigQuery リソースを操作する。
- BigQuery ジョブの履歴を表示する。
検索(プレビュー): 自然言語クエリを使用して BigQuery から Google Cloud リソースを検索できます。
パイプラインと統合
データ転送: BigQuery Data Transfer Service にアクセスして、データ転送を作成、構成できます。
パイプライン(Dataform):Google Cloud プロジェクト用に作成された Dataform リポジトリのリストが表示されます。
スケジュールされたクエリ: スケジュールされたクエリが表示されます。
スケジュール設定: Google Cloud プロジェクトのパイプラインとスケジュールのリストが表示されます。
ガバナンス
Sharing(Analytics Hub): Google Cloud プロジェクトでアクセスできるすべてのデータ交換が表示されます。
ポリシータグ: ポリシータグの階層型グループの作成に使用できる分類のリストが表示されます。
メタデータのキュレーション: Cloud Storage バケット内のデータをスキャンして、メタデータを抽出してからカタログ化できます。
管理
移行
その他のリソース
パートナー センター: ワークフローを加速するためのパートナーのツールとサービスを提供します。
設定(プレビュー): 次のタブが含まれます。
個人設定: BigQuery Studio でセッションを開始するときに適用されるデフォルト設定を設定できます。一部の設定はプロジェクトまたは組織から継承されますが、[個人設定] ページでオーバーライドできます。
構成設定: BigQuery 管理者が選択したプロジェクト内または組織内のユーザー向けに BigQuery Studio のエクスペリエンスをカスタマイズできます。たとえば、[結果を保存] > [CSV(Google ドライブ)]、[次で開く] > [Looker Studio]、[エクスポート] > [シートを使って調べる] などのユーザー インターフェース要素の表示 / 非表示を切り替えることができます。これらの設定を BigQuery Studio で非表示にした場合でも、それによって基盤となるデータやツールへのアクセスが制限されることはありません。組織レベルで変更を加えるには、
bigquery.config.get権限が必要です。
リリースノート: BigQuery のプロダクトの最新情報とお知らせが記載されています。
BigQuery のナビゲーション メニューの表示形式は調整できます。
ナビゲーション メニューを閉じて、アイコンのみを表示するには、
 [BigQuery のナビゲーション メニューの切り替え] をクリックします。
[BigQuery のナビゲーション メニューの切り替え] をクリックします。閉じた状態のメニューを一時的に開くには、メニューの上にポインタを重ねます。
メニューを開いてラベルを表示したままにするには、
 [BigQuery のナビゲーション メニューの切り替え] をクリックします。
[BigQuery のナビゲーション メニューの切り替え] をクリックします。
プロジェクト内でアクセス権のあるデータセットを表示するには、プロジェクトを開きます。
データセット内のテーブル、ビュー、関数を表示するには、データセットを展開します。
外部データに関する BigQuery テーブルを設定する(フェデレーション): BigQuery が外部データにアクセスする際にそのデータを BigQuery に取り込む必要がなくなります。外部データにアクセスするテーブルを作成するか、外部ソースへの接続を作成できます。
BigQuery にデータを読み込む: Data Transfer Service を設定するかパートナー機能を使用して、BigQuery にデータを読み込むことができます。大規模なデータ処理を最適化するには、BigQuery にデータを読み込むことをおすすめします。
BigQuery への変更データ キャプチャ: 変更をキャプチャして適用することで、データソースから BigQuery にデータを複製します。Datastream やパートナー ソリューションなどのアプリケーションを使用して、データソースからデータを取り込むことができます。
BigQuery にデータをストリーミングする: 低レイテンシで BigQuery にデータを取り込みます。Dataflow、Pub/Sub、パートナー ソリューションなどのアプリケーションを使用して、データソースからデータを取り込むことができます。
- 一般公開データセットにアクセスしてクエリを実行する。
- [Sharing(Analytics Hub)] ページに移動する。詳細については、BigQuery Sharing の概要をご覧ください。
- 名前を指定してプロジェクトにスターを付ける。
Google Cloud コンソールのツールバーで、プロジェクトの名前をクリックします。
プロジェクト ダイアログで、切り替え後のプロジェクトの名前をクリックします。
この選択したプロジェクトが、アクティブ プロジェクトになります。
データセットまたはテーブルにアクセスできるものの、そのデータセットを含むプロジェクトにアクセスできない場合は、次の手順を行います。
Google Cloud コンソールのツールバーで、プロジェクトの名前をクリックします。
プロジェクト ダイアログで、スターを付けるプロジェクトを検索します。
プロジェクト名の上にポインタを合わせて、スターを付けるアイコン をクリックします。
プロジェクトに対する閲覧者(
roles/viewer)IAM ロールが付与されている場合は、次の操作を行います。方法 1
スターを付けるプロジェクトに切り替えます。
[エクスプローラ] ペインで、スターを付けるプロジェクトの名前の上にポインタを置いて、 [スターを付ける] をクリックします。
方法 2
[エクスプローラ] ペインで、[ データを追加] をクリックします。
[データを追加] ダイアログで、[名前を指定してプロジェクトにスターを付ける] をクリックします。
表示されたダイアログで、スターを付けるプロジェクトの名前を入力し、[スターを付ける] をクリックします。
- プロジェクトのデータセットを表示するには、そのプロジェクトの [ ノードを切り替える] をクリックし、[データセット] をクリックします。[詳細] タブに新しいタブが開き、プロジェクト内のすべてのデータセットのリストが表示されます。データセットをクリックすると、詳細が表示されます。
- データセット内のテーブル、ビュー、関数を表示するには、[概要] > [テーブル] をクリックします。他のタブで、データセットの詳細、モデル、ルーティンを表示することもできます。
次のスクリーンショットに示すように、パンくずリストを使用して、さまざまなタブやリソースをシームレスに移動することもできます。
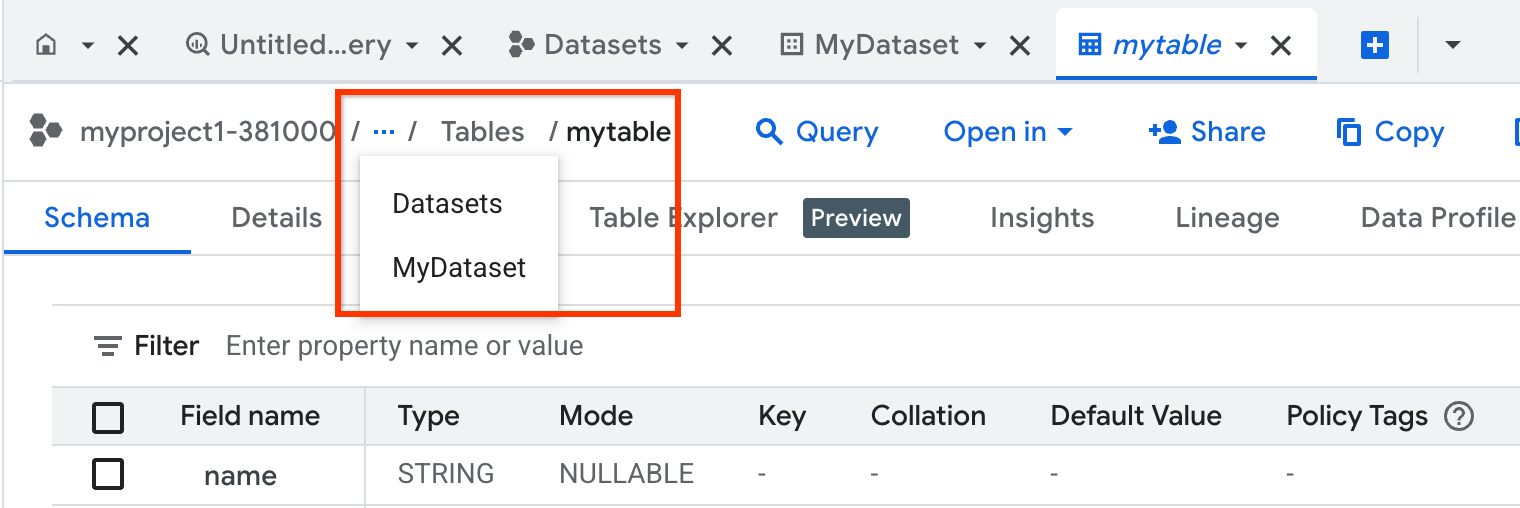
タブの増加を抑えるため、リソースをクリックすると、同じタブ内で開きます。リソースを別のタブで開くには、Ctrl キー(macOS では Command キー)を押したままリソースをクリックします。現在のタブのコンテンツが置き換えられないようにするには、タブ名をダブルクリックします(タブ名が斜体から通常のフォントに変わります)。それでもリソースが見つからない場合は、詳細ペインで tab_recent [最近のタブ] をクリックして、リソースを探します。
- BigQuery Studio の新機能が一覧表示される [Studio の新機能を確認する] セクション。[試す] をクリックすると、コンソールで機能を確認できます。セクションが表示されていない場合は、[Studio の新機能] をクリックしてセクションを開きます。
[新規作成] セクション: 新しい SQL クエリ、ノートブック、Apache Spark ノートブック、データ キャンバス、データ準備ファイル、パイプライン、テーブルを作成するオプションがあります。
次のデモガイド:
Google Cloud コンソールで、[BigQuery] ページに移動します。
BigQuery のホームページが表示されていることを確認します。必要に応じて、[エクスプローラ] ペインで
 [ホーム] をクリックします。
[ホーム] をクリックします。[最近] セクションに、最近アクセスした 10 個のリソースが表示されます。
Google Cloud コンソールで、[BigQuery] ページに移動します。
BigQuery のホームページが表示されていることを確認します。必要に応じて、[エクスプローラ] ペインで
[ホーム] をクリックします。[ このクエリを開きます] をクリックします。
bigquery-public-dataプロジェクトが [エクスプローラ] ペインに自動的に追加されます。公開プロジェクトとgoogle_trendsデータセットが展開され、[Google トレンド データ] ダイアログに、スターが付いたtop_termsテーブルがハイライト表示されます。また、クエリエディタが開き、事前定義されたクエリが表示されます。![事前定義されたクエリと [Google トレンドのデータ] ダイアログ。](https://cloud.google.com/static/bigquery/images/demo-predefined-query.png?hl=ja)
[Google トレンドのデータ] ダイアログで [次へ] をクリックします。
[Google トレンド クエリ] ダイアログで [次へ] をクリックします。
前のステップに戻るには、ダイアログで [戻る] をクリックします。
[このクエリを実行する] ダイアログで [試してみる] をクリックします。
前のステップに戻るには、ダイアログで [戻る] をクリックします。
[クエリ結果] ダイアログで、[完了] をクリックします。
![[結果] ペインに表示されたクエリ結果。](https://cloud.google.com/static/bigquery/images/demo-query-results.png?hl=ja)
Google Cloud コンソールで、[BigQuery] ページに移動します。
BigQuery のホームページが表示されていることを確認します。必要に応じて、[エクスプローラ] ペインで
[ホーム] をクリックします。[ノートブックを開く] をクリックします。
Demo notebookノートブックが [エクスプローラ] ペインの [共有ノートブック] に自動的に追加され、タブ付きエディタで開きます。[ノートブック] ダイアログで [次へ] をクリックします。
[アクティビティ] ダイアログで、ファイルの詳細とバージョン履歴の検索に関する情報を確認してから、[次へ] をクリックします。
[接続] ダイアログには、ハイライト表示された [接続] ボタンがあります。このボタンを使用して、ノートブックをランタイムに接続できます。[次へ] をクリックします。
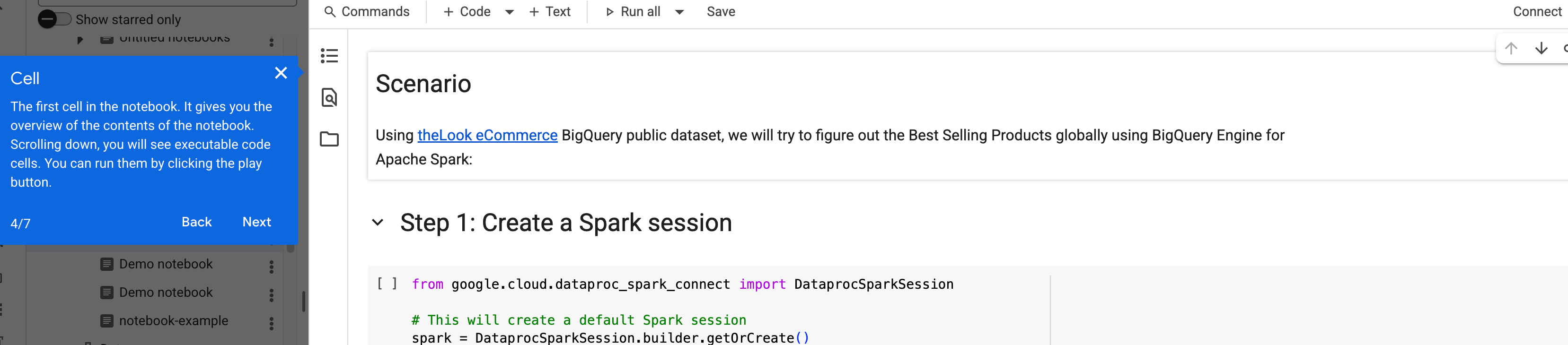
[セル] ダイアログで、ノートブックのセルに関する情報を確認してから、[次へ] をクリックします。

[コード] ダイアログには、ハイライト表示された [コード] ボタンがあります。このボタンを使用して、ノートブックに新しいコードセルを追加できます。[次へ] をクリックします。
[コマンド] ダイアログには、ハイライト表示された [コマンド] ボタンがあります。このボタンを使用して、ノートブック アクションのリストを開くことができます。[次へ] をクリックします。
[ターミナル] ダイアログには、ハイライト表示された [ターミナル] ボタンがあります。このボタンを使用して、ターミナルを開き、コマンドラインからランタイムにアクセスできます。[完了] をクリックします。
Google Cloud コンソールで、[BigQuery] ページに移動します。
BigQuery のホームページが表示されていることを確認します。必要に応じて、[エクスプローラ] ペインで [
ホーム] をクリックします。[Spark でノートブックを開く] をクリックします。
リージョンを選択し、BigQuery Unified API を有効にします(まだ有効になっていない場合)。デモ用の Spark ノートブックが [エクスプローラ] ペインの [共有ノートブック] に自動的に追加され、タブ付きエディタで開きます。
[ノートブック] ダイアログで [次へ] をクリックします。
[アクティビティ] ダイアログで、ファイルの詳細とバージョン履歴の検索に関する情報を確認してから、[次へ] をクリックします。
[接続] ダイアログには、ハイライト表示された [接続] ボタンがあります。このボタンを使用して、ノートブックをランタイムに接続できます。[次へ] をクリックします。
[セル] ダイアログで、ノートブックのセルに関する情報を確認してから、[次へ] をクリックします。
[コード] ダイアログには、ハイライト表示された [コード] ボタンがあります。このボタンを使用して、ノートブックに新しいコードセルを追加できます。[次へ] をクリックします。
[コマンド] ダイアログには、ハイライト表示された [コマンド] ボタンがあります。このボタンを使用して、ノートブック アクションのリストを開くことができます。[次へ] をクリックします。
[ターミナル] ダイアログには、ハイライト表示された [ターミナル] ボタンがあります。このボタンを使用して、ターミナルを開き、コマンドラインからランタイムにアクセスできます。[完了] をクリックします。
Google Cloud コンソールで、[BigQuery] ページに移動します。
BigQuery のホームページが表示されていることを確認します。必要に応じて、[エクスプローラ] ペインで
[ホーム] をクリックします。[このガイドを開始] をクリックして、[ローカル ファイル]、[Google ドライブ]、[Google Cloud Storage] の 3 つのオプションのいずれかを選択します。
[[データを追加] パネルを開く] ダイアログで、[試してみる] をクリックします。
選択したソースタイプが [データを追加] ペインでハイライト表示されます。
[ソースの選択] ダイアログで、[試してみる] をクリックします。
[ソースの詳細の構成] ダイアログで、[次へ] をクリックします。
[宛先の詳細の構成] ダイアログで、[次へ] をクリックします。
[テーブルの作成] ダイアログで、[完了] をクリックします。
タブ名の横にある [ メニューを開く] をクリックします。
次のオプションのいずれかを選択します。
- 選択したタブを左側のペインに配置するには、[タブを左に分割] を選択します。
- 選択したタブを右側のペインに配置するには、[タブを右に分割] を選択します。
[エクスプローラ] メニューで、クエリを実行するテーブルをクリックします。
[クエリ] をクリックし、続いて [新しいタブ] か [分割タブ] をクリックします。
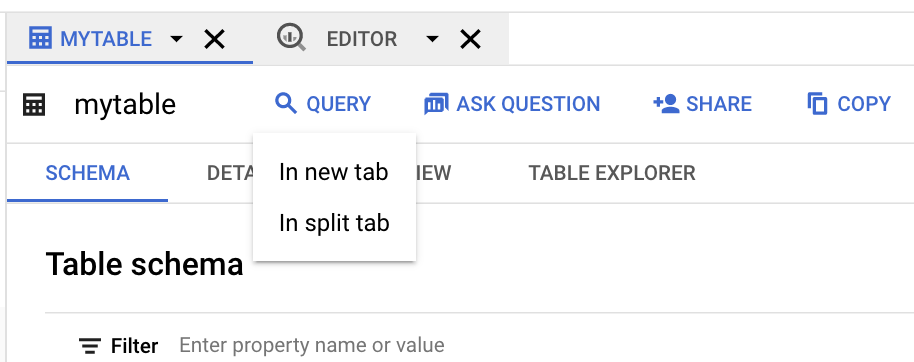
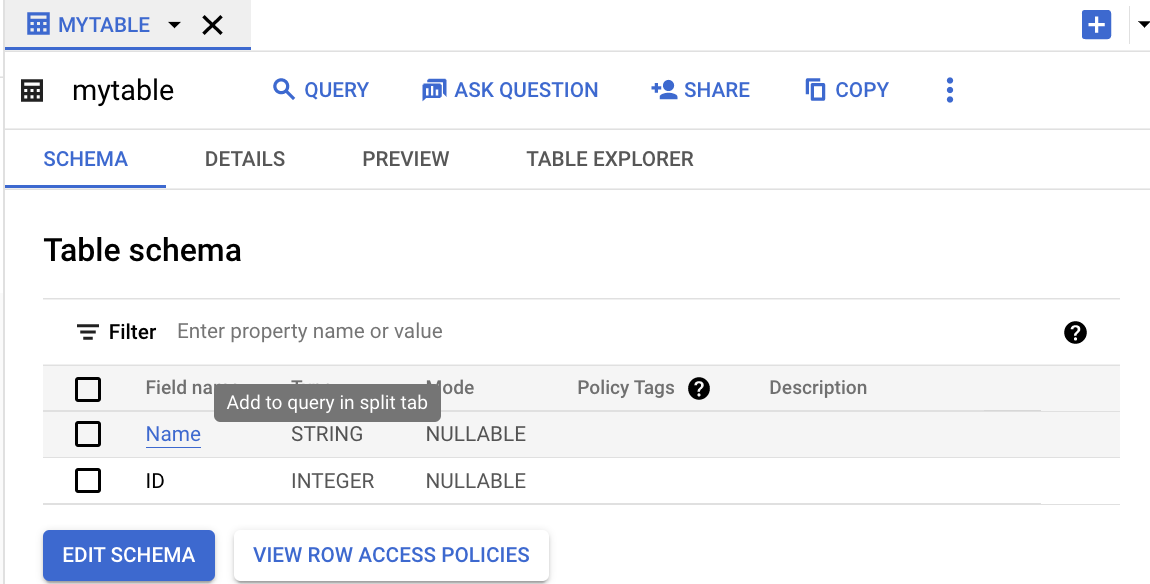
クエリするフィールドの名前をクリックします。
タブ名の横にある [ メニューを開く] をクリックします。
[タブを右ペインに移動] または [タブを左ペインに移動] を選択します(使用可能などちらかのオプションを使用します)。
タブ名の横にある [ メニューを開く] をクリックします。
[ 他のタブを閉じる] を選択します。
[BigQuery] ページに移動します。
左側のペインで、 [エクスプローラ] をクリックします。

[エクスプローラ] ペインで、[ジョブの履歴] をクリックします。
ジョブ履歴のリストが新しいタブで開きます。

自分のジョブの詳細を表示するには、[個人履歴] をクリックします。
プロジェクト内の最近のジョブの詳細を表示するには、[プロジェクト履歴] をクリックします。
ジョブまたはクエリの [操作] 列で、[ 操作] をクリックします。
[ジョブの詳細を表示] または [エディタでジョブを表示する] を選択します。
- 一般公開データセットのクエリと BigQuery サンドボックスの使用方法については、 Google Cloud コンソールで一般公開データセットにクエリを実行するをご覧ください。
Google Cloud コンソールで BigQuery を開く
ブラウザに次の URL を入力して、[BigQuery] ページを開くこともできます。
https://console.cloud.google.com/bigquery
最後にアクセスしたプロジェクトで、BigQuery が開きます。
ナビゲーションを容易にするには、ナビゲーション メニューの上位のプロダクトとして BigQuery を追加(または固定)します。
BigQuery ページの概要
[BigQuery] ページには、次のメイン セクションがあります。
ナビゲーション メニュー
BigQuery のナビゲーション メニューでは、次のカテゴリから任意のオプションを選択できます。
左側のペイン
ナビゲーション メニューにある [スタジオ] を選択すると、左側のペインが表示されます。このペインは、[エクスプローラ]、[従来のエクスプローラ]、[Git リポジトリ] の 3 つのペインで構成されています。
左側のペインを折りたたむには、[ 左側のペインを折りたたむ] をクリックします。左側のペインを開くには、 [左側のペインを開く] をクリックします。
[エクスプローラ] ペイン
[エクスプローラ] ペインには、さまざまなコードアセットとデータリソースが一覧表示されます。詳細ペインで新しいタブを開くには、コード アセットタイプをクリックします。このタブには、プロジェクト内のそのコードアセット タイプのすべてのファイルが一覧表示されます。たとえば、[ノートブック] をクリックして [ノートブック] タブを開くと、プロジェクト内のすべてのノートブックが一覧表示されます。検索バーまたはフィルタを使用してファイルを見つけることができます。
[ホームタブ] に移動したり、新しいタブでジョブ履歴やスター付きリソースを開いたりすることもできます。
[エクスプローラ] ペインの検索機能を使用すると、BigQuery のリソースを検索できます。結果は、詳細ペインの新しいタブに表示されます。プロジェクトやリソースタイプ(データセットなど)で検索を絞り込むことができます。この検索機能は組織内の BigQuery リソースを対象としていますが、 Google Cloud ツールバーの検索機能はGoogle Cloud全体を対象としています。
![[エクスプローラ] タブの検索バー。](https://cloud.google.com/static/bigquery/images/explorer-search-bar.png?hl=ja)
従来のエクスプローラ ペイン
このペインには、現在の Google Cloud プロジェクトとスター付きのプロジェクトが一覧表示されます。
プロジェクトとデータセットのリソースを表示する方法は次のとおりです。
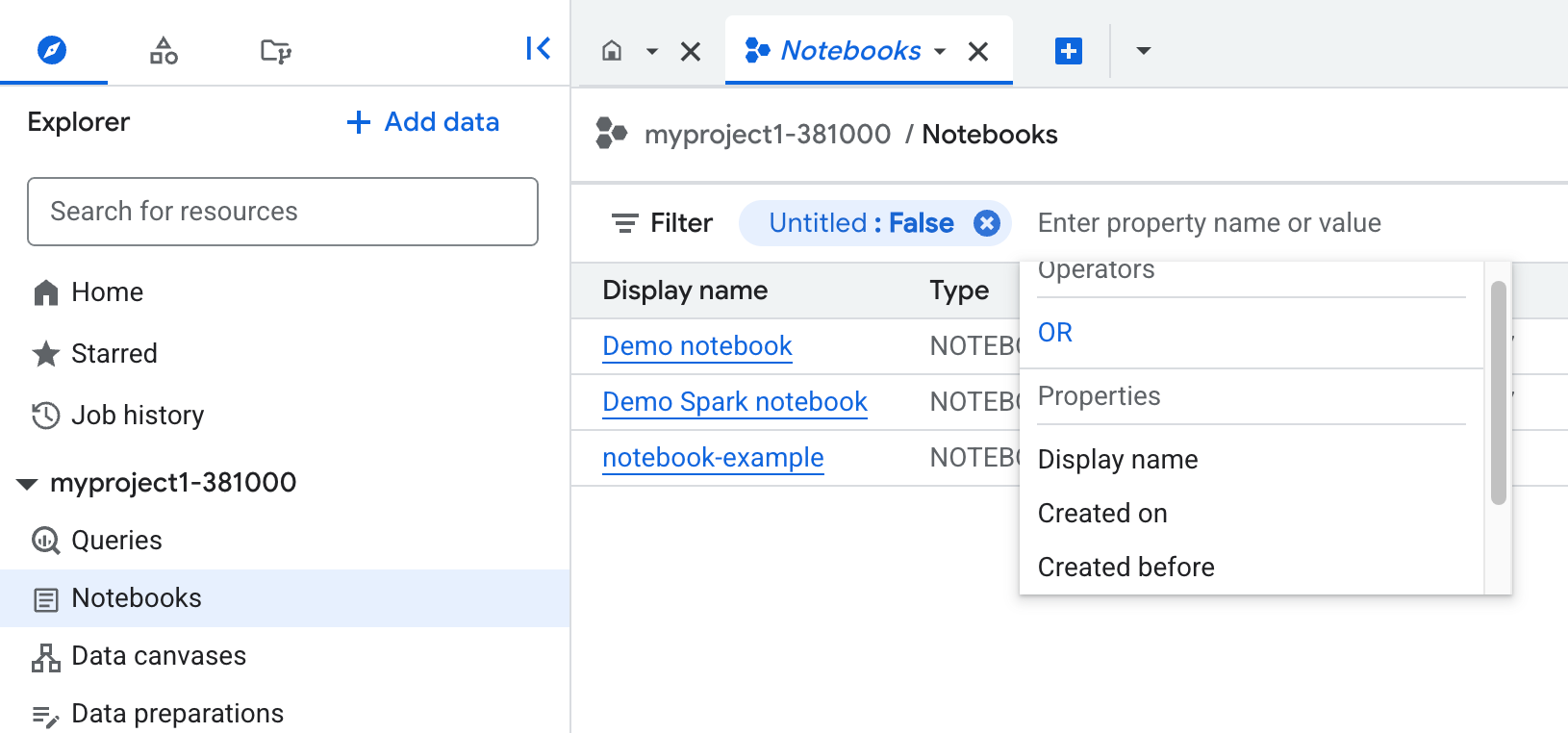
また、リソースは、検索ボックスを使用して、現在のプロジェクトやスターがつけられたプロジェクト内の名前(データセット、テーブル、ビュー名)またはラベルで検索することもできます。検索機能では、検索クエリと完全に一致するリソースか、部分的に一致するリソースが表示されます。一致したリソースのレベルにあるすべてのリソースが表示されない場合があります。すべてのリソースを表示するには、[もっと見る] をクリックします。
Git リポジトリ ペイン
リポジトリを使用すると、BigQuery で使用するファイルのバージョン管理を行うことができます。BigQuery では、変更の記録とファイルのバージョン管理のために、Git を使用します。詳細については、リポジトリの概要をご覧ください。
リポジトリ内のワークスペースを使用して、リポジトリに保存されているコードを編集できます。[Git リポジトリ] ペインでワークスペースをクリックすると、詳細ペインのタブで開きます。詳細については、ワークスペースの概要をご覧ください。
詳細ペイン
詳細ペインには、BigQuery リソースに関する情報が表示されます。[クラシック エクスプローラ] ペインでデータセット、テーブル、ビューなどのリソースを選択すると、詳細ペインに新しいタブが表示されます。これらのタブでは、リソースに関する情報を表示できます。また、テーブルとビューの作成、テーブル スキーマの変更、データのエクスポートなどの操作も行えます。
タブをエディタの端にドラッグして新しい列で開くことで、タブを比較できます。また、タブを現在の列または隣接する列の別の位置にドラッグすることもできます。この機能はプレビュー版です。
クエリエディタでは、インタラクティブ クエリを実行し、クエリの実行後に開く [クエリ結果] ペインで結果を確認できます。
タブ間を移動すると、フォーカスされているタブに対応するリソースが [従来のエクスプローラ] ペインで選択されます。ワークスペースの URL を使用して BigQuery を開くと、ワークスペース クエリエディタのタブが開き、対応するリソースが [クラシック エクスプローラ] ペインで選択されます。
Google Cloud ツールバーの検索バーを使用して、 Google Cloud全体のリソース(プロジェクト、データセット、テーブル)、ドキュメント、プロダクト(Compute Engine や Cloud Storage など)を検索できます。異なるプロダクトのリソースにアクセスするには、BigQuery の権限と同様の権限が必要になる場合があります。
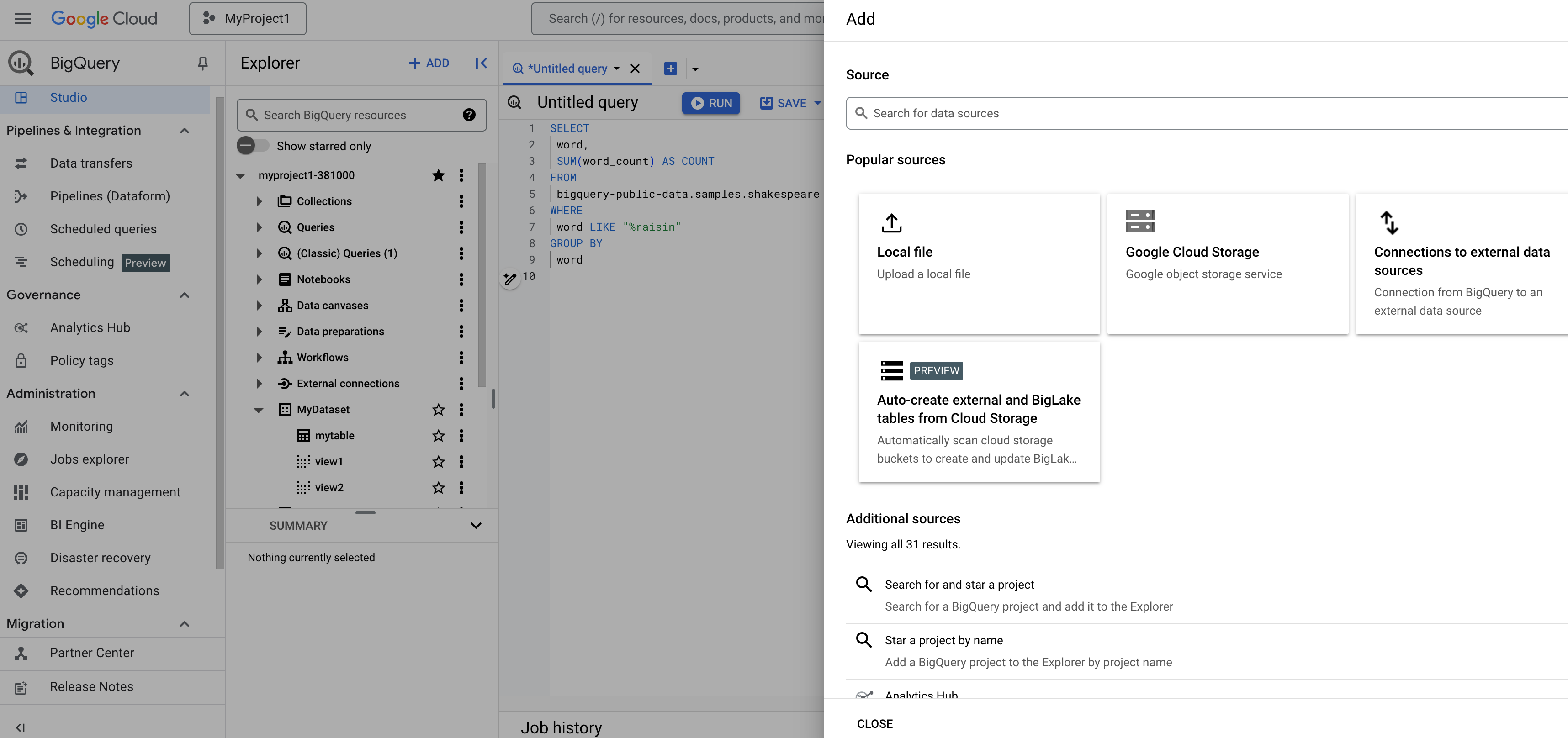
[データを追加] ダイアログ
[データを追加] ダイアログでは、検索機能とフィルタ機能を使用して、操作するデータソースを見つけることができます。データソースを選択したら、そのデータソースに利用可能な機能に応じて次の操作を行うことができます。
BigQuery へのデータの読み込みの詳細については、データの読み込みの概要をご覧ください。
また、次の操作も行うことができます。
プロジェクトに関する作業
BigQuery でのすべての作業はGoogle Cloud プロジェクト内で行います。プロジェクト名は、Google Cloud コンソール ツールバーに表示されます。

BigQuery の使用で発生するすべての費用は、プロジェクトにリンクされている請求先アカウントに請求されます。詳しくは、BigQuery の料金をご覧ください。
プロジェクトに切り替える
Google Cloud コンソールで Google Cloud プロジェクトに切り替える手順は次のとおりです。
プロジェクトにスターを付ける
次の方法で Google Cloud プロジェクトにスターを付けると、[エクスプローラ] ペインに表示できます。
Google Cloud プロジェクトにスターを付けることができるのは、 Google Cloud コンソールからのみです。
プロジェクトを削除する
[エクスプローラ] ペインからプロジェクトを削除するには、スターを外すプロジェクトの名前にポインタを合わせて、 [スターを外す] をクリックします。
リソースの表示
[エクスプローラ] ペインに、現在のプロジェクトまたはスターがつけられたプロジェクトで閲覧可能なデータセットのリストが表示されます。リソースを表示する際は、次の点を考慮してください。
リソースにスターを付ける
重要な、または現在のプロジェクト、データセット、テーブルがある場合は、[従来のエクスプローラ] ペインでスターを付けることができます。リソースにスターを付けるには、スターを付けるリソースの名前の上にポインタを置いて、[ スターを付ける] をクリックします。
プロジェクトにスターを付ける方法について詳しくは、プロジェクトにスターを付けるをご覧ください。
スター付きのリソースを表示する
スター付きのリソースを表示するには、[エクスプローラ] ペインで [スター付き] をクリックします。スター付きリソースのリストを含む新しいタブが表示されます。
すべてのリソースをリソースツリーとして表示するには、[クラシック エクスプローラ] ペインをクリックし、[スター付きのみを表示] 切り替えをオフにします。
リソースのスターを外す
リソースのスターをはずすには、[クラシック エクスプローラ] ペインに移動し、リソースの横にある [ スターをはずす] をクリックします。
[ホーム] タブ
BigQuery を初めて開くと、ホームタブとクエリエディタのタブが表示され、ホームタブがフォーカスされます。[ホーム] タブには以下が含まれています。
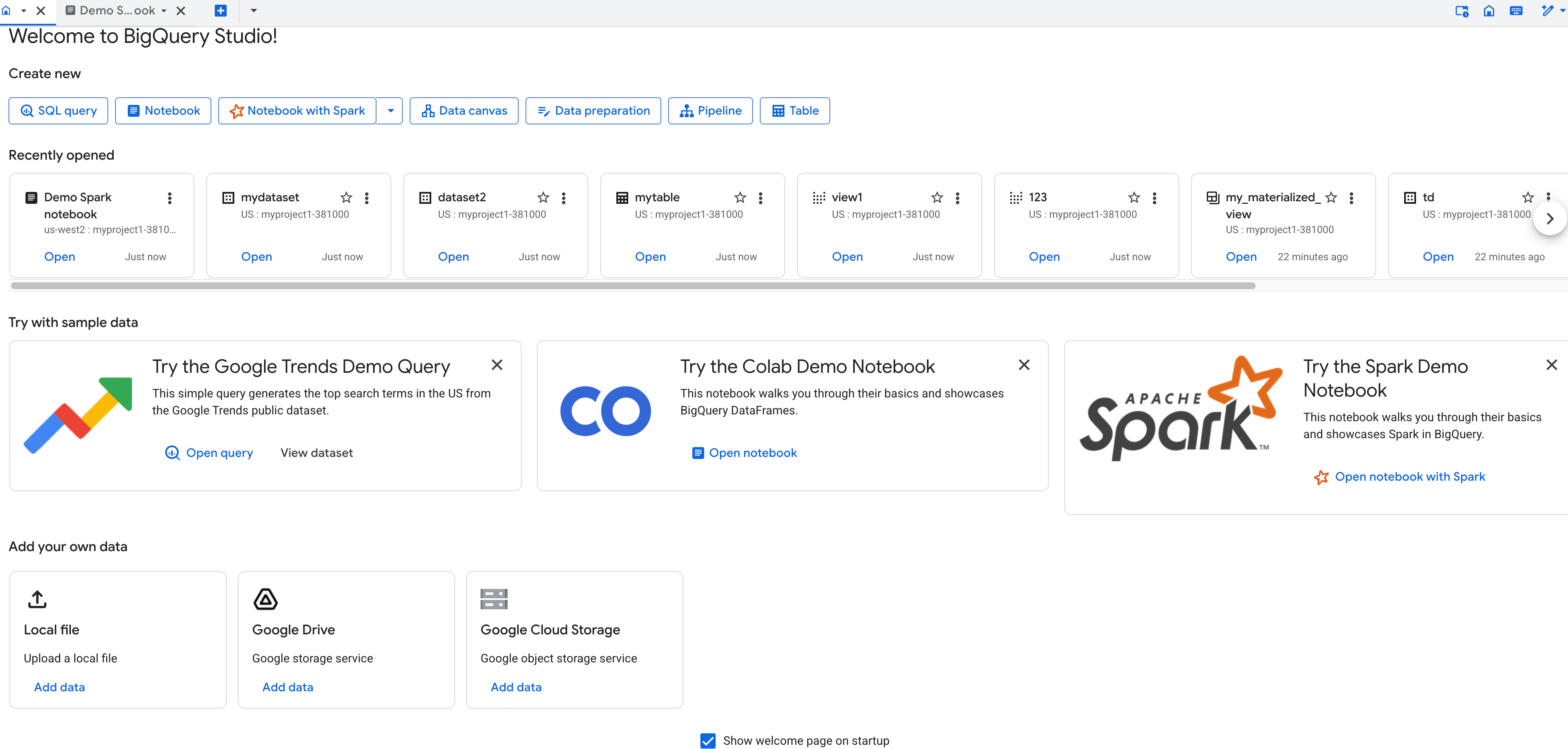
ホームタブを閉じることができます。[ホーム] タブに戻るには、[エクスプローラ] ペインで * [ホーム] をクリックします。
[ホーム] タブからクエリエディタを開くには、[ SQL クエリ] をクリックします。BigQuery で動作するデータのインポートとデータソースの検索方法にアクセスするには、[ データを追加] をクリックします。
ワークスペースの URL を使用して BigQuery を開くと、ワークスペースの [クエリエディタ] タブが最初に開きます。
最近アクセスしたリソースを表示する
Google Cloud コンソールには、最近アクセスした 10 個のリソースが表示されます。これらのリソースには、テーブル、保存済みクエリ、モデル、ルーティンが含まれます。
コンソールまたはクエリエディタでリソースを作成または更新すると、そのリソースは「最近」とマークされます。最近開いたリソースを「最近」としてマークするには、ワークスペース タブでリソースを開く必要があります。リソースに対してクエリを実行しても、リソースは「最近」としてマークされません。
最近アクセスしたリソースを表示する手順は次のとおりです。
クエリ デモガイドを実行する
Google トレンドの一般公開データセットに対してサンプルクエリを実行するデモガイドを実行するには、次の手順を行います。デモを途中で終了するには、[ ツアーを閉じる] をクリックします。
このデモは複数回実行できます。
Google トレンドの一般公開データセットを表示するには、ホームページで [データセットを表示] をクリックします。
Colab ノートブックのデモガイドを実行する
デモガイドを実行するには、次の手順を行います。デモを途中で終了するには、[ ツアーを閉じる] をクリックします。必要に応じて、前のステップに戻る場合は、ダイアログ内の [戻る] をクリックします。
Apache Spark ノートブックのデモガイドを実行する
デモガイドを実行するには、次の手順を行います。デモを途中で終了するには、[ ツアーを閉じる] をクリックします。必要に応じて、前のステップに戻る場合は、ダイアログ内の [戻る] をクリックします。
データ追加デモガイドを実行する
[独自データの追加] セクションには、一般的なソースから BigQuery にデータを追加するためのデモガイドが用意されています。
デモガイドを実行するには、次の手順を行います。デモを途中で終了するには、[ ツアーを閉じる] をクリックします。必要に応じて、前のステップに戻る場合は [戻る] をクリックします。
このデモガイドは、[独自データの追加] セクションで利用できる 3 つのソースのいずれかで 1 回だけ実行できます。デモを完了すると、[このガイドを開始] ボタンが [データを追加] に変更され、[テーブルの作成] サブタスクへのショートカットとして機能します。
タブの操作
詳細ペインのタブでの作業環境は調整できます。
2 つのタブの分割
リソースを選択するか、詳細ペインでクエリを新規作成()をクリックすると、新しいタブが開きます。複数のタブを開いている場合は、タブを 2 つのペインに分割し、横に並べて表示できます。
タブを 2 つのペインに分割するには、次の操作を行います。
タブの分割を解除するには、開いているタブの 1 つでメニューを開く()を選択し、続いて [タブを左側ペインに移動] か [タブを右側ペインに移動] を選択します。
テーブルをクエリするときにタブを分割する手順は、次のとおりです。
次の画像では、2 つのタブが開いている詳細ペインを示します。1 つのタブには SQL クエリが表示され、もう一方のタブにはテーブルの詳細が表示されています。
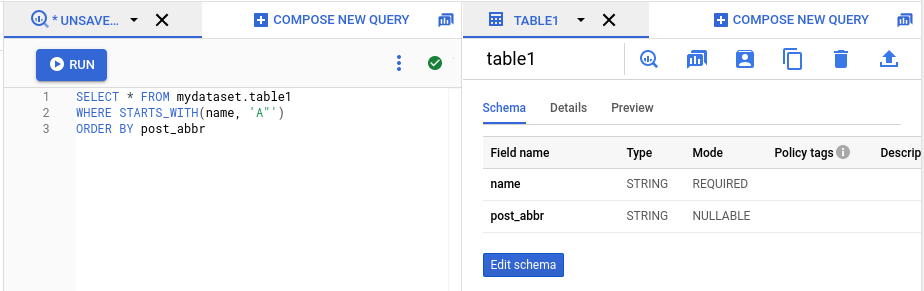
タブの移動
タブを別のペインに移動するには、次の操作を行います。
タブを閉じる
1 つを除くすべてのタブを閉じるには、次の操作を行います。
個人履歴とプロジェクト履歴の表示
データを読み込み、エクスポート、クエリ、コピーするたびに、BigQuery によってタスクの進行状況を追跡するジョブが自動的に作成、スケジュールされ、実行されます。現在の課金プロジェクトのジョブ履歴を表示する手順は次のとおりです。
ジョブの詳細を表示する、またはクエリをエディタで開くには、次の操作を行います。
ジョブの管理の詳細については、ジョブを管理するをご覧ください。
キーボード ショートカット
Google Cloud コンソールでショートカットを表示するには、[ BigQuery Studio のショートカット] をクリックします。 Google Cloud コンソールでは次のキーボード ショートカットがサポートされています。
| アクション | Windows または Linux のショートカット | macOS のショートカット |
|---|---|---|
| 新しいタブを作成する |
|
|
| タブを閉じる(キーボード フォーカス タブ) |
または
|
または
|
| クエリを書式設定する |
|
|
| Gemini のコード補完と生成 |
|
|
| 特定のタブに移動する |
|
|
| 最後のタブに移動する |
|
|
| 開いている次のタブに移動する |
または
|
|
| 開いている前のタブに移動する |
または
|
|
| タブを左に移動する |
|
|
| タブを右に移動する |
|
|
| タブメニューを開く(キーボード フォーカス タブ) |
|
|
| クエリの実行、またはハイライトされたクエリの実行 |
または
|
または
|
| エディタのショートカットのリストを表示 |
|
|
| アクティブなタブを分割するか左に移動する |
|
|
| アクティブなタブを分割するか右に移動する |
|
|
| SQL 自動提案 |
または
|
または
|
| SQL 生成ツール |
|
|
| 行コメントを切り替える |
|
|
例
Google Cloud コンソールの例は、BigQuery ドキュメントの入門ガイドセクションに多く記載されています。
Google Cloud コンソールを使用してデータを読み込み、クエリを実行する例については、 Google Cloud コンソールを使用してデータを読み込んでクエリを実行するをご覧ください。