Migrate code with the batch SQL translator
This document describes how to use the batch SQL translator in BigQuery to translate scripts written in other SQL dialects into GoogleSQL queries. This document is intended for users who are familiar with the Google Cloud console.
Before you begin
Before you submit a translation job, complete the following steps:
- Ensure that you have all the required permissions.
- Enable the BigQuery Migration API.
- Collect the source files containing the SQL scripts and queries to be translated.
- Optional. Create a metadata file to improve the accuracy of the translation.
- Optional. Decide if you need to map SQL object names in the source files to new names in BigQuery. Determine what name mapping rules to use if this is necessary.
- Decide what method to use to submit the translation job.
- Upload the source files to Cloud Storage.
Required permissions
You must have the following permissions on the project to enable the BigQuery Migration Service:
resourcemanager.projects.getserviceusage.services.enableserviceusage.services.get
You need the following permissions on the project to access and use the BigQuery Migration Service:
bigquerymigration.workflows.createbigquerymigration.workflows.getbigquerymigration.workflows.listbigquerymigration.workflows.deletebigquerymigration.subtasks.getbigquerymigration.subtasks.listAlternatively, you can use the following roles to get the same permissions:
bigquerymigration.viewer- Read only access.bigquerymigration.editor- Read/write access.
To access the Cloud Storage buckets for input and output files:
storage.objects.geton the source Cloud Storage bucket.storage.objects.liston the source Cloud Storage bucket.storage.objects.createon the destination Cloud Storage bucket.
You can have all the above necessary Cloud Storage permissions from the following roles:
roles/storage.objectAdminroles/storage.admin
Enable the BigQuery Migration API
If your Google Cloud CLI project was created before February 15, 2022, enable the BigQuery Migration API as follows:
In the Google Cloud console, go to the BigQuery Migration API page.
Click Enable.
Collect source files
Source files must be text files that contain valid SQL for the source dialect. Source files can also include comments. Do your best to ensure the SQL is valid, using whatever methods are available to you.
Create metadata files
To help the service generate more accurate translation results, we recommend that you provide metadata files. However, this isn't mandatory.
You can use the dwh-migration-dumper command-line extraction tool to generate the metadata
information, or you can provide your own metadata files. Once metadata files are prepared, you can include them along with the source files in the translation
source folder. The translator automatically detects them and leverages them
to translate source files, you don't need to configure any extra settings to enable this.
To generate metadata information by using the
dwh-migration-dumper tool, see
Generate metadata for translation.
To provide your own metadata, collect the data definition language (DDL) statements for the SQL objects in your source system into separate text files.
Decide how to submit the translation job
You have three options for submitting a batch translation job:
Batch translation client: Configure a job by changing settings in a configuration file, and submit the job using the command line. This approach doesn't require you to manually upload source files to Cloud Storage. The client still uses Cloud Storage to store files during translation job processing.
The legacy batch translation client is an open-source Python client that lets you translate source files located on your local machine and have the translated files output to a local directory. You configure the client for basic use by changing a few settings in its configuration file. If you choose to, you can also configure the client to address more complex tasks like macro replacement, and pre- and postprocessing of translation inputs and outputs. For more information, see the batch translation client readme.
Google Cloud console: Configure and submit a job using a user interface. This approach requires you to upload source files to Cloud Storage.
Create configuration YAML files
You can optionally create and use configuration configuration YAML files to customize your batch translations. These files can be used to transform your translation output in various ways. For example, you can create a configuration YAML file to change the case of a SQL object during translation.
If you want to use the Google Cloud console or the BigQuery Migration API for a batch translation job, you can upload the configuration YAML file to the Cloud Storage bucket containing the source files.
If you want to use the batch translation client, you can place the configuration YAML file in the local translation input folder.
Upload input files to Cloud Storage
If you want to use the Google Cloud console or the BigQuery Migration API to perform a translation job, you must upload the source files containing the queries and scripts you want to translate to Cloud Storage. You can also upload any metadata files or configuration YAML files to the same Cloud Storage bucket and directory containing the source files. For more information about creating buckets and uploading files to Cloud Storage, see Create buckets and Upload objects from a filesystem.
Supported SQL dialects
The batch SQL translator is part of the BigQuery Migration Service. The batch SQL translator can translate the following SQL dialects into GoogleSQL:
- Amazon Redshift SQL
- Apache HiveQL and Beeline CLI
- IBM Netezza SQL and NZPLSQL
- Teradata and Teradata Vantage:
- SQL
- Basic Teradata Query (BTEQ)
- Teradata Parallel Transport (TPT)
Additionally, translation of the following SQL dialects is supported in preview:
- Apache Impala SQL
- Apache Spark SQL
- Azure Synapse T-SQL
- BigQuery SQL
- Greenplum SQL
- IBM DB2 SQL
- MySQL SQL
- Oracle SQL, PL/SQL, Exadata
- PostgreSQL SQL
- Trino or PrestoSQL
- Snowflake SQL
- SQL Server T-SQL
- SQLite
- Vertica SQL
Handling unsupported SQL functions with helper UDFs
When translating SQL from a source dialect to BigQuery, some functions might not have a direct equivalent. To address this, the BigQuery Migration Service (and the broader BigQuery community) provide helper user-defined functions (UDFs) that replicate the behavior of these unsupported source dialect functions.
These UDFs are often found in the bqutil public dataset, allowing translated queries to initially reference them using the format bqutil.<dataset>.<function>(). For example, bqutil.fn.cw_count().
Important considerations for production environments:
While bqutil offers convenient access to these helper UDFs for initial translation and testing, direct reliance on bqutil for production workloads is not recommended for several reasons:
- Version control: The
bqutilproject hosts the latest version of these UDFs, which means their definitions can change over time. Relying directly onbqutilcould lead to unexpected behavior or breaking changes in your production queries if a UDF's logic is updated. - Dependency isolation: Deploying UDFs to your own project isolates your production environment from external changes.
- Customization: You might need to modify or optimize these UDFs to better suit your specific business logic or performance requirements. This is only possible if they are within your own project.
- Security and governance: Your organization's security policies might restrict direct access to public datasets like
bqutilfor production data processing. Copying UDFs to your controlled environment aligns with such policies.
Deploying helper UDFs to your project:
For reliable and stable production use, you should deploy these helper UDFs into your own project and dataset. This gives you full control over their version, customization, and access. For detailed instructions on how to deploy these UDFs, refer to the UDFs deployment guide on GitHub. This guide provides the necessary scripts and steps to copy the UDFs into your environment.
Locations
The batch SQL translator is available in the following processing locations:
| Region description | Region name | Details | |
|---|---|---|---|
| Asia Pacific | |||
| Delhi | asia-south2 |
||
| Hong Kong | asia-east2 |
||
| Jakarta | asia-southeast2 |
||
| Melbourne | australia-southeast2 |
||
| Mumbai | asia-south1 |
||
| Osaka | asia-northeast2 |
||
| Seoul | asia-northeast3 |
||
| Singapore | asia-southeast1 |
||
| Sydney | australia-southeast1 |
||
| Taiwan | asia-east1 |
||
| Tokyo | asia-northeast1 |
||
| Europe | |||
| Belgium | europe-west1 |
|
|
| Berlin | europe-west10 |
||
| EU multi-region | eu |
||
| Finland | europe-north1 |
|
|
| Frankfurt | europe-west3 |
||
| London | europe-west2 |
|
|
| Madrid | europe-southwest1 |
|
|
| Milan | europe-west8 |
||
| Netherlands | europe-west4 |
|
|
| Paris | europe-west9 |
|
|
| Stockholm | europe-north2 |
|
|
| Turin | europe-west12 |
||
| Warsaw | europe-central2 |
||
| Zürich | europe-west6 |
|
|
| Americas | |||
| Columbus, Ohio | us-east5 |
||
| Dallas | us-south1 |
|
|
| Iowa | us-central1 |
|
|
| Las Vegas | us-west4 |
||
| Los Angeles | us-west2 |
||
| Mexico | northamerica-south1 |
||
| Northern Virginia | us-east4 |
||
| Oregon | us-west1 |
|
|
| Québec | northamerica-northeast1 |
|
|
| São Paulo | southamerica-east1 |
|
|
| Salt Lake City | us-west3 |
||
| Santiago | southamerica-west1 |
|
|
| South Carolina | us-east1 |
||
| Toronto | northamerica-northeast2 |
|
|
| US multi-region | us |
||
| Africa | |||
| Johannesburg | africa-south1 |
||
| MiddleEast | |||
| Dammam | me-central2 |
||
| Doha | me-central1 |
||
| Israel | me-west1 |
||
Submit a translation job
Follow these steps to start a translation job, view its progress, and see the results.
Console
These steps assume you have source files uploaded into a Cloud Storage bucket already.
In the Google Cloud console, go to the BigQuery page.
In the navigation menu, click Tools and guide.
In the Translate SQL panel, click Translate > Batch translation.
The translation configuration page opens. Enter the following details:
- For Display name, type a name for the translation job. The name can contain letters, numbers or underscores.
- For Processing location, select the location where you want the
translation job to run. For example, if you are in Europe and you
don't want your data to cross any location boundaries, select the
euregion. The translation job performs best when you choose the same location as your source file bucket. - For Source dialect, select the SQL dialect that you want to translate.
- For Target dialect, select BigQuery.
Click Next.
For Source location, specify the path to the Cloud Storage folder containing the files to translate. You can type the path in the format
bucket_name/folder_name/or use the Browse option.Click Next.
For Target location, specify the path to the destination Cloud Storage folder for the translated files. You can type the path in the format
bucket_name/folder_name/or use the Browse option.If you're doing translations that don't need to have default object names or source-to-target name mapping specified, skip to Step 11. Otherwise, click Next.
Fill in the optional settings that you need.
Optional. For Default database, type a default database name to use with the source files. The translator uses this default database name to resolve SQL objects' fully qualified names where the database name is missing.
Optional. For Schema search path, specify a schema to search when the translator needs to resolve SQL objects' fully qualified names in the source files where the schema name is missing. If the source files use a number of different schema names, click Add Schema Name and add a value for each schema name that might be referenced.
The translator searches through the metadata files you provided to validate tables with their schema names. If a definite option can't be determined from the metadata, the first schema name you enter is used as the default. For more information on how the default schema name is used, see default schema.
Optional. If you want to specify name mapping rules to rename SQL objects between the source system and BigQuery during translation, you can either provide a JSON file with the name mapping pair, or you can use the Google Cloud console to specify the values to map.
To use a JSON file:
- Click Upload JSON file for name mapping.
Browse to the location of a name mapping file in the appropriate format, select it, and click Open.
Note that the file size must be less than 5 MB.
To use the Google Cloud console:
- Click Add name mapping pair.
- Add the appropriate parts of the source object name in the Database, Schema, Relationship, and Attribute fields in the Source column.
- Add the parts of the target object name in BigQuery in the fields in the Target column.
- For Type, select the object type that describes the object you are mapping.
- Repeat Steps 1 - 4 until you have specified all of the name mapping pairs that you need. Note that you can only specify up to 25 name mapping pairs when using the Google Cloud console.
Optional. To generate translation AI suggestions using the Gemini model, select the Gemini AI suggestions checkbox. Suggestions are based on the configuration YAML file ending in
.ai_config.yamland located in the Cloud Storage directory. Each type of suggestion output is saved in its own sub-directory within your output folder with the naming patternREWRITETARGETSUGGESTION_TYPE_suggestion. For example, suggestions for the Gemini-enhanced target SQL customization is stored intarget_sql_query_customization_suggestionand the translation explanation generated by Gemini is stored intranslation_explanation_suggestion. To learn how to write the configuration YAML file for AI suggestions, see Create a Gemini-based configuration YAML file.
Click Create to start the translation job.
Once the translation job is created, you can see its status in the translation jobs list.
Batch translation client
Install the batch translation client and the Google Cloud CLI.
In the batch translation client installation directory, use the text editor of your choice to open the
config.yamlfile and modify the following settings:project_number: Type the project number of the project you want to use for the batch translation job. You can find this in the Project info pane on the Google Cloud console welcome page for the project.gcs_bucket: Type the name of the Cloud Storage bucket that the batch translation client uses to store files during translation job processing.input_directory: Type the absolute or relative path to the directory containing the source files and any metadata files.output_directory: Type the absolute or relative path to the target directory for the translated files.
Save the changes and close the
config.yamlfile.Place your source and metadata files in the input directory.
Run the batch translation client using the following command:
bin/dwh-migration-clientOnce the translation job is created, you can see its status in the translation jobs list in the Google Cloud console.
Optional. Once the translation job is completed, delete the files that the job created in the Cloud Storage bucket you specified, in order to avoid storage costs.
Explore the translation output
After running the translation job, you can see information about the job in the Google Cloud console. If you used the Google Cloud console to run the job, you can see job results in the destination Cloud Storage bucket that you specified. If you used the batch translation client to run the job, you can see job results in the output directory that you specified. The batch SQL translator outputs the following files to the specified destination:
- The translated files.
- The translation summary report in CSV format.
- The consumed output name mapping in JSON format.
- The AI suggestion files.
Google Cloud console output
To see translation job details, follow these steps:
In the Google Cloud console, go to the BigQuery page.
In the navigation menu, click SQL translation.
In the list of translation jobs, locate the job for which you want to see the translation details. Then, click the translation job name. You can see a Sankey visualization that illustrates the overall quality of the job, the number of input lines of code (excluding blank lines and comments), and a list of issues that occurred during the translation process. You should prioritize fixes from left to right. Issues in an early stage can cause additional issues in subsequent stages.
Hold the pointer over the error or warning bars, and review the suggestions to determine next steps to debug the translation job.
Select the Log Summary tab to see a summary of the translation issues, including issue categories, suggested actions, and how often each issue occurred. You can click the Sankey visualization bars to filter issues. You can also select an issue category to see log messages associated with that issue category.
Select the Log Messages tab to see more details about each translation issue, including the issue category, the specific issue message, and a link to the file in which the issue occurred. You can click the Sankey visualization bars to filter issues. You can select an issue in the Log Message tab to open the Code tab that displays the input and output file if applicable.
Click the Job details tab to see the translation job configuration details.
Summary report
The summary report is a CSV file that contains a table of all of the warning and error messages encountered during the translation job.
To see the summary file in the Google Cloud console, follow these steps:
In the Google Cloud console, go to the BigQuery page.
In the navigation menu, click SQL translation.
In the list of translation jobs, locate the job that you are interested in, then click the job name or click More options > Show details.
In the Job details tab, in the Translation report section, click translation_report.csv.
On the Object details page, click the value in the Authenticated URL row to see the file in your browser.
The following table describes the summary file columns:
| Column | Description |
|---|---|
| Timestamp | The timestamp at which the issue occurred. |
| FilePath | The path to the source file that the issue is associated with. |
| FileName | The name of the source file that the issue is associated with. |
| ScriptLine | The line number where the issue occurred. |
| ScriptColumn | The column number where the issue occurred. |
| TranspilerComponent | The translation engine internal component where the warning or error occurred. This column might be empty. |
| Environment | The translation dialect environment associated with the warning or error. This column might be empty. |
| ObjectName | The SQL object in the source file that is associated with the warning or error. This column might be empty. |
| Severity | The severity of the issue, either warning or error. |
| Category | The translation issue category. |
| SourceType | The source of this issue. The value in this column can either be
SQL, indicating an issue in the input SQL files, or
METADATA, indicating an issue in the metadata package. |
| Message | The translation issue warning or error message. |
| ScriptContext | The SQL snippet in the source file that is associated with the issue. |
| Action | The action we recommend you take to resolve the issue. |
Code tab
The code tab lets you review further information about the input and output files for a particular translation job. In the code tab, you can examine the files used in a translation job, review a side-by-side comparison of an input file and its translation for any inaccuracies, and view log summaries and messages for a specific file in a job.
To access the code tab, follow these steps:
In the Google Cloud console, go to the BigQuery page.
In the navigation menu, click SQL translation.
In the list of translation jobs, locate the job that you are interested in, then click the job name or click More options > Show details.
Select Code tab. The code tab consists of the following panels:
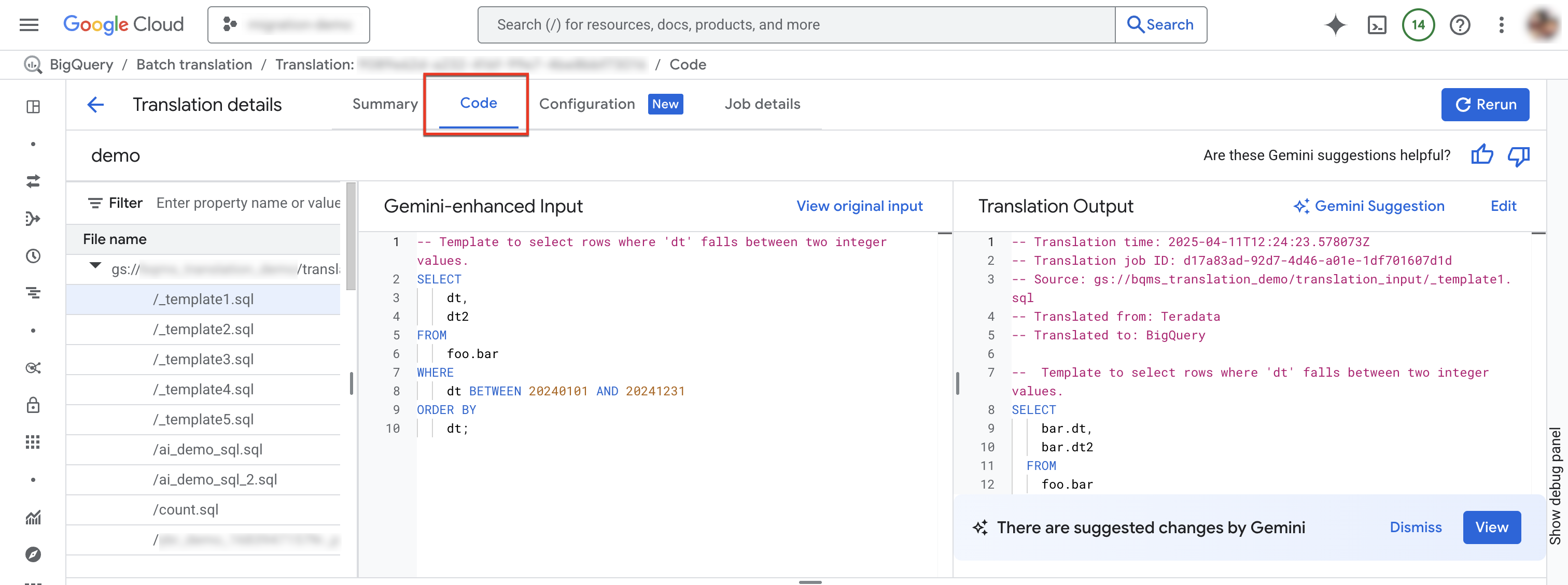
- File explorer: Contains all SQL files used for translation. Click a file to view its translation input and output, and any translation issues from its translation.
- Gemini-enhanced input: The input SQL that was translated by the translation engine. If you have specified Gemini customization rules for the source SQL in the Gemini configuration, then the translator transforms the original input first and then translates the Gemini-enhanced input. To view the original input, click View original input.
- Translation output: The translation result. If you have specified Gemini customization rules for the target SQL in the Gemini configuration, then the transformation is applied to the translated result as a Gemini-enhanced output. If a Gemini-enhanced output is available, then you can click the Gemini suggestion button to review the Gemini-enhanced output.
Optional: To view an input file and its output file in the BigQuery interactive SQL translator, click Edit. You can edit the files and save the output file back to Cloud Storage.
Configuration tab
You can add, rename, view, or edit your configuration YAML files in the Configuration tab.The Schema Explorer shows the documentation for supported configuration types to help you write your configuration YAML files. After you edit the configuration YAML files, you can rerun the job to use the new configuration.
To access the configuration tab, follow these steps:
In the Google Cloud console, go to the BigQuery page.
In the navigation menu, click SQL translation.
In the list of translation jobs, locate the job that you are interested in, then click the job name or click More options > Show details.
In the Translation details window, click the Configuration tab.
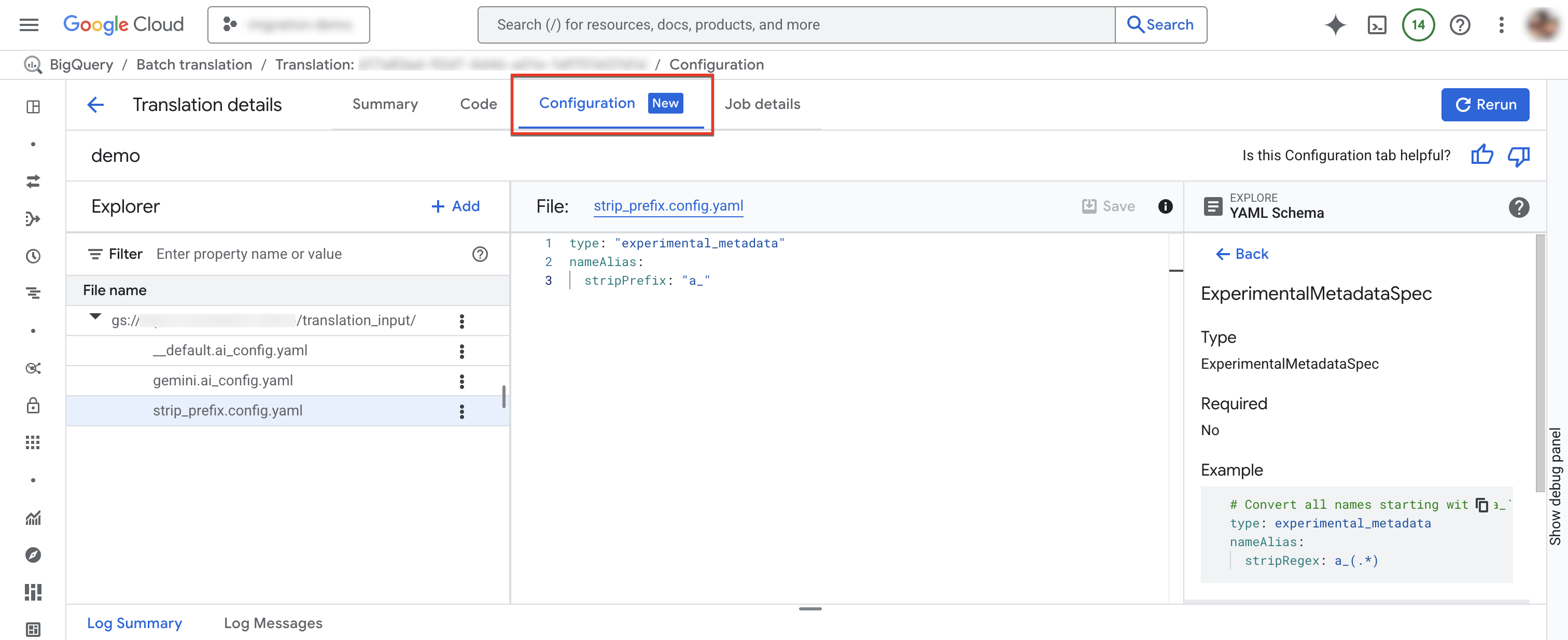
To add a new configuration file:
- Click more_vert More options > Create configuration YAML file.
- A panel appears where you can choose the type, location, and name of the new configuration YAML file.
- Click Create.
To edit an existing configuration file:
- Click on the configuration YAML file.
- Edit the file, then click Save.
- Click Re-run to run a new translation job that uses the edited configuration YAML files.
You can rename an existing configuration file by clicking more_vert More options > Rename.
Consumed output name mapping file
This JSON file contains the output name mapping rules that were used by the translation job. The rules in this file might differ from the output name mapping rules that you specified for the translation job, due to either conflicts in the name mapping rules, or lack of name mapping rules for SQL objects that were identified during translation. Review this file to determine whether the name mapping rules need correction. If they do, create new output name mapping rules that address any issues you identify, and run a new translation job.
Translated files
For each source file, a corresponding output file is generated in the destination path. The output file contains the translated query.
Debug batch translated SQL queries with the interactive SQL translator
You can use the BigQuery interactive SQL translator to review or debug a SQL query using the same metadata or object mapping information as your source database. After you complete a batch translation job, BigQuery generates a translation configuration ID that contains information about the job's metadata, the object mapping, or the schema search path, as applicable to the query. You use the batch translation configuration ID with the interactive SQL translator to run SQL queries with the specified configuration.
To start an interactive SQL translation by using a batch translation configuration ID, follow these steps:
In the Google Cloud console, go to the BigQuery page.
In the navigation menu, click SQL translation.
In the list of translation jobs, locate the job that you are interested in, and then click More Options > Open Interactive Translation.
The BigQuery interactive SQL translator now opens with the corresponding batch translation configuration ID. To view the translation configuration ID for the interactive translation, click More > Translation settings in the interactive SQL translator.
To debug a batch translation file in the interactive SQL translator, follow these steps:
In the Google Cloud console, go to the BigQuery page.
In the navigation menu, click SQL translation.
In the list of translation jobs, locate the job that you are interested in, and then click the job name or click More options > Show details.
In the Translation details window, click the Code tab.
In the file explorer, click your filename to open the file.
Next to the output filename, click Edit to open the files in the interactive SQL translator (Preview).
You see the input and output files populated in the interactive SQL translator that now uses the corresponding batch translation configuration ID.
To save the edited output file back to Cloud Storage, in the interactive SQL translator click Save > Save To GCS.
Limitations
The translator can't translate user-defined functions (UDFs) from languages other than SQL, because it can't parse them to determine their input and output data types. This causes translation of SQL statements that reference these UDFs to be inaccurate. To make sure non-SQL UDFs are properly referenced during translation, use valid SQL to create placeholder UDFs with the same signatures.
For example, say you have a UDF written in C that calculates the sum of two integers. To make sure that SQL statements that reference this UDF are correctly translated, create a placeholder SQL UDF that shares the same signature as the C UDF, as shown in the following example:
CREATE FUNCTION Test.MySum (a INT, b INT)
RETURNS INT
LANGUAGE SQL
RETURN a + b;
Save this placeholder UDF in a text file, and include that file as one of the source files for the translation job. This enables the translator to learn the UDF definition and identify the expected input and output data types.
Quota and limits
- BigQuery Migration API quotas apply.
- Each project can have at most 10 active translation tasks.
- While there is no hard limit on the total number of source and metadata files, we recommend keeping the number of files to under 1000 for better performance.
Troubleshoot translation errors
RelationNotFound or AttributeNotFound translation issues
Translation works best with metadata DDLs. When SQL object definitions cannot be
found, the translation engine raises RelationNotFound or AttributeNotFound
issues. We recommend using the metadata extractor to generate metadata packages
to make sure all object definitions are present. Adding metadata is the
recommended first step to resolve most translation errors, as it often can fix
many other errors that are indirectly caused from a lack of metadata.
For more information, see Generate metadata for translation and assessment.
Pricing
There is no charge to use the batch SQL translator. However, storage used to store input and output files incurs the normal fees. For more information, see Storage pricing.
What's next
Learn more about the following steps in data warehouse migration:
- Migration overview
- Migration assessment
- Schema and data transfer overview
- Data pipelines
- Interactive SQL translation
- Data security and governance
- Data validation tool