Migrate from IBM Netezza
This document provides high-level guidance on how to migrate from Netezza to BigQuery. It describes the fundamental architectural differences between Netezza and BigQuery and describes the additional capabilities that BigQuery offers. It also shows how you can rethink your existing data model and extract, transform, and load (ETL) processes to maximize the benefits of BigQuery.
This document is for enterprise architects, DBAs, application developers, and IT security professionals who want to migrate from Netezza to BigQuery and solve technical challenges in the migration process. This document provides details about the following phases of the migration process:
- Exporting data
- Ingesting data
- Leveraging third-party tools
You can also use batch SQL translation to migrate your SQL scripts in bulk, or interactive SQL translation to translate ad hoc queries. IBM Netezza SQL/NZPLSQL is supported by both tools in preview.
Architecture comparison
Netezza is a powerful system that can help you store and analyze vast amounts of data. However, a system like Netezza requires huge investments in hardware, maintenance, and licensing. This can be difficult to scale due to challenges in node management, volume of data per source, and archiving costs. With Netezza, storage and processing capacity are constrained by hardware appliances. When the maximum utilization is reached, the process of extending appliance capacity is elaborate and sometimes not even possible.
With BigQuery, you don't have to manage infrastructure, and you don't need a database administrator. BigQuery is a fully managed, petabyte-scale, serverless data warehouse that can scan billions of rows, without an index, in tens of seconds. Because BigQuery shares Google's infrastructure, it can parallelize each query and run it on tens of thousands of servers simultaneously. The following core technologies differentiate BigQuery:
- Columnar storage. Data is stored in columns rather than rows, which makes it possible to achieve a very high compression ratio and scan throughput.
- Tree architecture. Queries are dispatched and results are aggregated across thousands of machines in a few seconds.
Netezza architecture
Netezza is a hardware accelerated appliance that comes with a software data abstraction layer. The data abstraction layer manages the data distribution in the appliance and optimizes queries by distributing data processing among the underlying CPUs and FPGAs.
Netezza TwinFin and Striper models reached their end of support in June 2019.
The following diagram illustrates the data abstraction layers within Netezza:
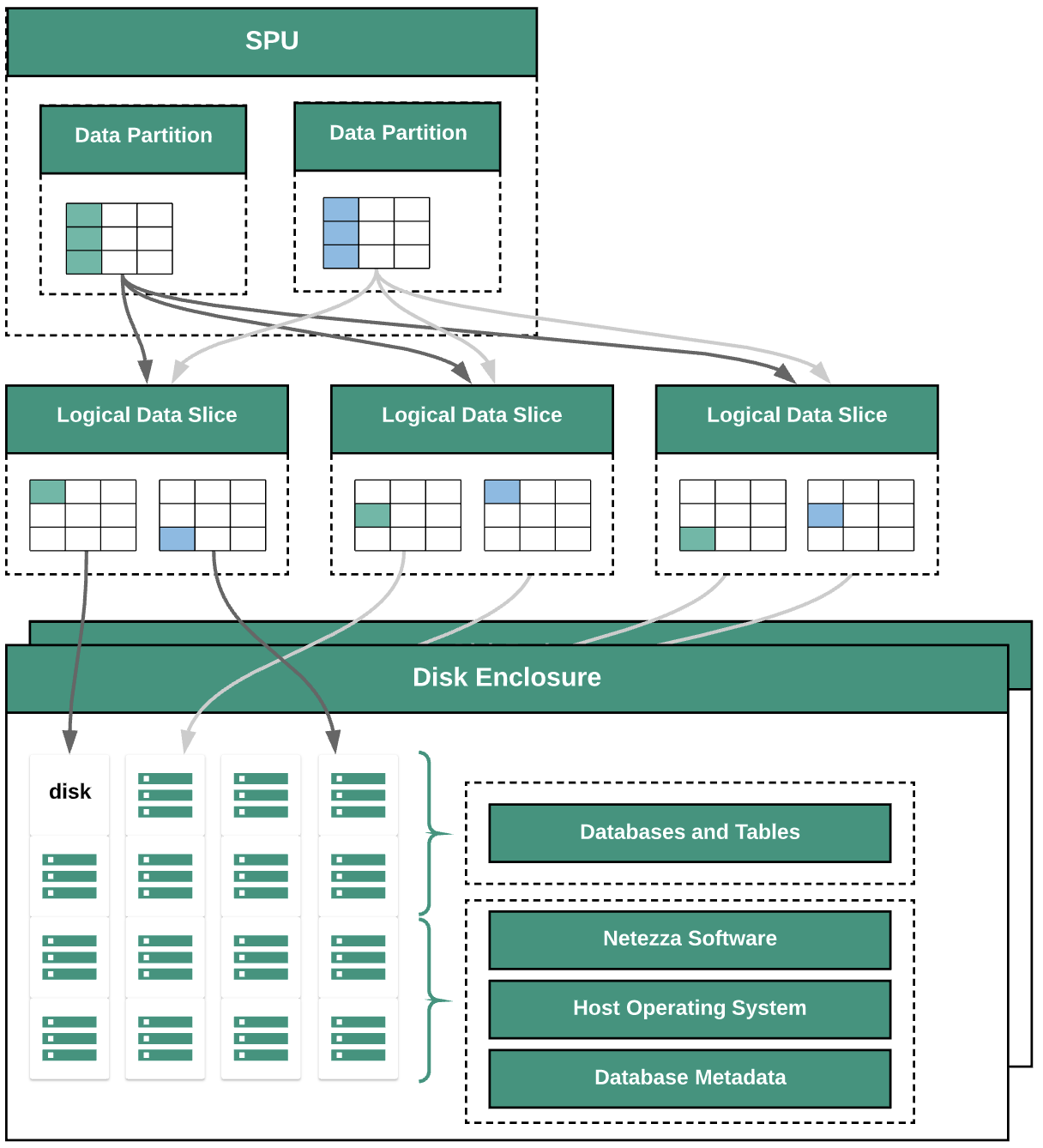
The diagram shows the following data abstraction layers:
- Disk enclosure. The physical space inside of the appliance where the disks are mounted.
- Disks. Physical drives within the disk enclosures store the databases and tables.
- Data slices. Logical representation of the data that is saved on a disk.
Data is distributed across the data slices using a distribution key. You can
monitor the status of data slices by using
nzdscommands. - Data partitions. Logical representation of a data slice that is managed by a specific Snippet Processing Units (SPUs). Each SPU owns one or more data partition containing the user data that the SPU is responsible for processing during queries.
All of the system components are connected by network fabric. The Netezza appliance runs a customized protocol based on IP addresses.
BigQuery architecture
BigQuery is a fully managed enterprise data warehouse that helps you manage and analyze your data with built-in features like machine learning, geospatial analysis, and business intelligence. For more information, see What is BigQuery?.
BigQuery handles storage and computation to provide durable data storage and high performance responses to analytics queries. For more information, see BigQuery explained.
For information about BigQuery pricing, see Understanding BigQuery's rapid scaling and simple pricing.
Pre-migration
To ensure a successful data warehouse migration, start planning your migration strategy early in your project timeline. For information about how to systematically plan your migration work, see What and how to migrate: The migration framework.
BigQuery capacity planning
Analytics throughput in BigQuery is measured in slots. A BigQuery slot is Google's proprietary unit of compute, RAM, and network throughput required to execute SQL queries. BigQuery automatically calculates how many slots are required by each query, depending on the query size and complexity.
To run queries in BigQuery, select one of the following pricing models:
- On-demand. The default pricing model, where you are charged for the number of bytes processed by each query.
- Capacity-based pricing. You purchase
slots, which are virtual CPUs. When you buy slots, you are buying dedicated
processing capacity that you can use to run queries. Slots are available in
the following commitment plans:
- Annual. You commit to 365 days.
- Three-year. You commit to 365*3 days.
A BigQuery slot shares some similarities with Netezza's SPUs, such as, CPU, memory, and processing of data; however, they don't represent the same unit of measurement. Netezza SPUs have a fixed mapping to the underlying hardware components, whereas the BigQuery slot represents a virtual CPU used to execute queries. To help with slot estimation, we recommend setting up BigQuery monitoring using Cloud Monitoring and analyzing your audit logs using BigQuery. To visualize BigQuery slot utilization, you can also use tools like Looker Studio or Looker. Regularly monitoring and analyzing your slot utilization helps you estimate how many total slots your organization needs as you grow on Google Cloud.
For example, suppose you initially reserve 2,000 BigQuery slots to run 50 medium-complexity queries simultaneously. If queries consistently take more than a few hours to run and your dashboards show high slot utilization, your queries might not be optimized or you might need additional BigQuery slots to help support your workloads. To purchase slots yourself in yearly or three-year commitments, you can create BigQuery reservations using the Google Cloud console or the bq command-line tool. If you signed an offline agreement for your capacity-based purchase, your plan might deviate from the details described here.
For information about how to control both storage and query processing costs on BigQuery, see Optimize workloads.
Security in Google Cloud
The following sections describe common Netezza security controls and how you can help to protect your data warehouse in a Google Cloud environment.
Identity and access management
The Netezza database contains a set of fully integrated system access control capabilities that lets users access resources for which they are authorized.
Access to Netezza is controlled through the network to the Netezza appliance by managing the Linux user accounts that can log in to the operating system. Access to the Netezza database, objects, and tasks are managed using the Netezza database user accounts that can establish SQL connections to the system.
BigQuery uses Google's Identity and Access Management (IAM) service to manage access to resources. The types of resources available in BigQuery are organizations, projects, datasets, tables, and views. In the IAM policy hierarchy, datasets are child resources of projects. A table inherits permissions from the dataset that contains it.
To grant access to a resource, you assign one or more roles to a user, group, or service account. Organization and project roles control access to run jobs or manage the project, whereas dataset roles control access to view or modify the data inside a project.
IAM provides the following types of roles:
- Predefined roles. To support common use cases and access control patterns.
- Basic roles. Include the Owner, Editor, and Viewer roles. Basic roles provide granular access for a specific service and are managed by Google Cloud.
- Custom roles. Provide granular access according to a user-specified list of permissions.
When you assign both predefined and basic roles to a user, the permissions granted are a union of the permissions of each individual role.
Row-level security
Multi-level security is an abstract security model, which Netezza uses to define rules to control user access to row-secure tables (RSTs). A row-secure table is a database table with security labels on rows to filter out users that don't have the appropriate privileges. The results that are returned on queries differ based upon the privileges of the user who makes the query.
To achieve row-level security in BigQuery, you can use authorized views and row-level access policies. For more information about how to design and implement these policies, see Introduction to BigQuery row-level security.
Data encryption
Netezza appliances use self-encrypting drives (SEDs) for improved security and protection of the data stored on the appliance. SEDs encrypt data when it's written to the disk. Each disk has a disk encryption key (DEK) that is set at the factory and stored on the disk. The disk uses the DEK to encrypt data as it writes and then to decrypt the data when it's read from disk. The operation of the disk, and its encryption and decryption, is transparent to the users who are reading and writing data. This default encryption and decryption mode is referred to as secure erase mode.
In secure erase mode, you don't need an authentication key or password to decrypt and read data. SEDs offer improved capabilities for an easy and speedy secure erase for situations when disks must be repurposed or returned for support or warranty reasons.
Netezza uses symmetric encryption; if your data is field-level encrypted, the following decrypt function can help you to read and export data:
varchar = decrypt(varchar text, varchar key [, int algorithm [, varchar IV]]); nvarchar = decrypt(nvarchar text, nvarchar key [, int algorithm[, varchar IV]]);
All data stored within BigQuery is encrypted at rest. If you want to control encryption yourself, you can use customer-managed encryption keys (CMEK) for BigQuery. With CMEK, instead of Google managing the key encryption keys that protect your data, you control and manage key encryption keys in Cloud Key Management Service. For more information, see Encryption at rest.
Performance benchmarking
To track progress and improvement throughout the migration process, it's important to establish a baseline performance for the current-state Netezza environment. To establish the baseline, select a set of representational queries, which are captured from the consuming applications (such as Tableau or Cognos).
| Environment | Netezza | BigQuery |
|---|---|---|
| Data size | size TB | - |
| Query 1: name (full table scan) | mm:ss.ms | - |
| Query 2: name | mm:ss.ms | - |
| Query 3: name | mm:ss.ms | - |
| Total | mm:ss.ms | - |
Foundational project setup
Before you provision storage resources for migration of data, you need to complete your project setup.
- To set up projects and enable IAM at the project level, see Google Cloud Well-Architected Framework.
- To design foundational resources to make your cloud deployment enterprise-ready, see Landing zone design in Google Cloud.
- To learn about data governance and the controls that you need when you migrate your on-premises data warehouse to BigQuery, see Overview of data security and governance.
Network connectivity
A reliable and secure network connection is required between the on-premises data center (where the Netezza instance is running) and the Google Cloud environment. For information about how to help secure your connection, see Introduction to data governance in BigQuery. When you upload data extracts, network bandwidth can be a limiting factor. For information about how to meet your data transfer requirements, see Increasing network bandwidth.
Supported data types and properties
Netezza data types differ from BigQuery data types. For information about BigQuery data types, see Data types. For a detailed comparison between Netezza and BigQuery data types, see the IBM Netezza SQL translation guide.
SQL comparison
Netezza data SQL consists of DDL, DML, and Netezza-only Data Control Language (DCL), which are different from GoogleSQL. GoogleSQL is compliant with the SQL 2011 standard and has extensions that support querying nested and repeated data. If you're using BigQuery legacy SQL, see Legacy SQL Functions and Operators. For a detailed comparison between Netezza and BigQuery SQL and functions, see the IBM Netezza SQL translation guide.
To help with your SQL code migration, use batch SQL translation to migrate your SQL code in bulk, or interactive SQL translation to translate ad hoc queries.
Function comparison
It is important to understand how Netezza functions map to
BigQuery functions. For example, the Netezza Months_Between
function outputs a decimal, while the BigQuery DateDiff
function outputs an integer. Therefore, you must use a
custom UDF function to output the correct data
type. For a detailed comparison between Netezza SQL and GoogleSQL
functions, see the
IBM Netezza SQL translation guide.
Data migration
To migrate data from Netezza to BigQuery, you export data out of Netezza, transfer and stage the data on Google Cloud, then load the data into BigQuery. This section provides a high level overview of the data migration process. For a detailed description of the data migration process, see Schema and data migration process. For a detailed comparison between Netezza and BigQuery supported data types, see the IBM Netezza SQL translation guide.
Export data out of Netezza
To explore data from Netezza database tables, we recommend that you export to an external table in the CSV format. For more information, see Unloading data to a remote client system. You can also read data using third-party systems like Informatica (or custom ETL) using JDBC/ODBC connectors to produce CSV files.
Netezza only supports export of uncompressed flat files (CSV) for each table.
However, if you're exporting large tables, the uncompressed CSV can become very
large. If possible, consider converting the CSV to a schema-aware format such as
Parquet, Avro, or ORC, which results in smaller export files with higher
reliability. If CSV is the only available format, we recommend that you compress
the export files to reduce file size before you upload to Google Cloud.
Reducing the file size helps to make the upload faster and increases the
reliability of the transfer. If you transfer files to Cloud Storage, you can
use the --gzip-local flag in a
gcloud storage cp command, which
compresses the files before uploading them.
Data transfer and staging
After data is exported, it needs to be transferred and staged on Google Cloud. There are several options for transferring the data, depending on the amount of data that you're transferring and the network bandwidth available. For more information, see Schema and data transfer overview.
When you use the Google Cloud CLI, you can automate and parallelize the transfer of files to Cloud Storage. Limit file sizes to 4 TB (uncompressed) for faster loading into BigQuery. However, you have to export the schema beforehand. This is a good opportunity to optimize BigQuery using partitioning and clustering.
Use gcloud storage bucket create
to create the staging buckets for storage of the exported data, and use
gcloud storage cp to transfer the
data export files into Cloud Storage buckets.
The gcloud CLI automatically performs the copy operation using a combination of multithreading and multiprocessing.
Loading data into BigQuery
After data is staged on Google Cloud, there are several options to load the data into BigQuery. For more information, see Load the schema and data into BigQuery.
Partner tools and support
You can get partner support in your migration journey. To help with your SQL code migration, use batch SQL translation to migrate your SQL code in bulk.
Many Google Cloud partners also offer data warehouse migration services. For a list of partners and their provided solutions, see Work with a partner with BigQuery expertise.
Post-migration
After data migration is complete, you can begin to optimize your usage of Google Cloud to solve business needs. This might include using Google Cloud's exploration and visualization tools to derive insights for business stakeholders, optimizing underperforming queries, or developing a program to aid user adoption.
Connect to BigQuery APIs over the internet
The following diagram shows how an external application can connect to BigQuery using the API:
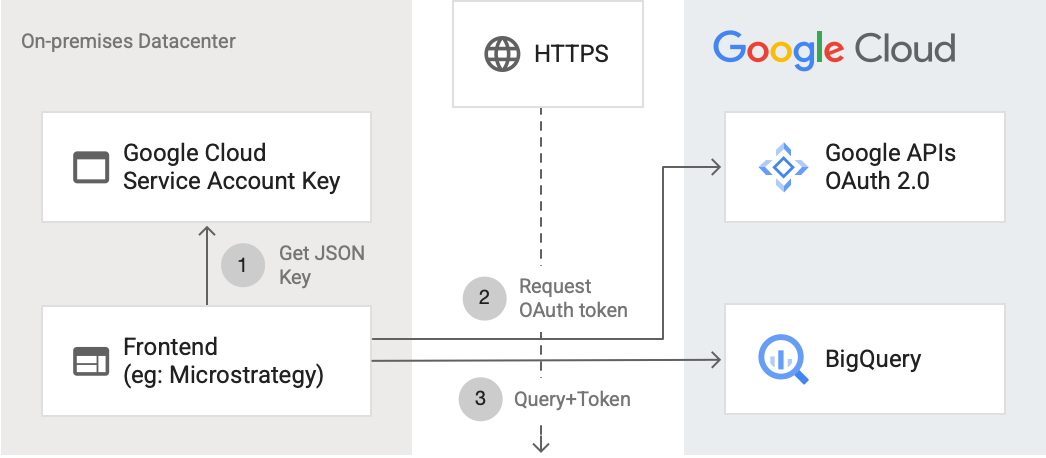
The diagram shows the following steps:
- In Google Cloud, a service account is created with IAM permissions. The service account key is generated in JSON format and copied to the frontend server (for example, MicroStrategy).
- The frontend reads the key and requests an OAuth token from Google APIs on HTTPS.
- The frontend then sends BigQuery requests along with the token to BigQuery.
For more information, see Authorizing API requests.
Optimizing for BigQuery
GoogleSQL supports compliance with the SQL 2011 standard and has extensions that support querying nested and repeated data. Optimizing queries for BigQuery is critical in improving performance and response time.
Replacing the Months_Between function in BigQuery with UDF
Netezza treats the days in a month as 31. The following custom UDF recreates the Netezza function with close accuracy, which you can call from your queries:
CREATE TEMP FUNCTION months_between(date_1 DATE, date_2 DATE) AS ( CASE WHEN date_1 = date_2 THEN 0 WHEN EXTRACT(DAY FROM DATE_ADD(date_1, INTERVAL 1 DAY)) = 1 AND EXTRACT(DAY FROM DATE_ADD(date_2, INTERVAL 1 DAY)) = 1 THEN date_diff(date_1,date_2, MONTH) WHEN EXTRACT(DAY FROM date_1) = 1 AND EXTRACT(DAY FROM DATE_ADD(date_2, INTERVAL 1 DAY)) = 1 THEN date_diff(DATE_ADD(date_1, INTERVAL -1 DAY), date_2, MONTH) + 1/31 ELSE date_diff(date_1, date_2, MONTH) - 1 + ((EXTRACT(DAY FROM date_1) + (31 - EXTRACT(DAY FROM date_2))) / 31) END );
Migrate Netezza stored procedures
If you use Netezza stored procedures in ETL workloads to construct fact tables, you must migrate these stored procedures to BigQuery-compatible SQL queries. Netezza uses the NZPLSQL scripting language to work with stored procedures. NZPLSQL is based on the Postgres PL/pgSQL language. For more information, see the IBM Netezza SQL translation guide.
Custom UDF to emulate Netezza ASCII
The following custom UDF for BigQuery corrects encoding errors in columns:
CREATE TEMP FUNCTION ascii(X STRING) AS (TO_CODE_POINTS(x)[ OFFSET (0)]);
What's next
- Learn how to Optimize workloads for overall performance optimization and cost reduction.
- Learn about how to Optimize storage in BigQuery.
- Reference the IBM Netezza SQL translation guide.