このチュートリアルでは、ARIMA_PLUS 単変量時系列モデルを使用して、特定の列の過去の値に基づいて、その列の将来の値を予測する方法について説明します。
このチュートリアルでは、複数の時系列の予測を行います。予測値は、指定された 1 つ以上の列の値ごとに、各時点について計算されます。たとえば、天気を予測し、都市データを含む列を指定した場合、予測データには、都市 A のすべての時間ポイントの予測と、都市 B のすべての時間ポイントの予測値が含まれます。
このチュートリアルでは、一般公開テーブル bigquery-public-data.new_york.citibike_trips のデータを使用します。このテーブルには、ニューヨーク市でのシティバイクの利用回数に関する情報が含まれています。
このチュートリアルを読む前に、単変量モデルを使用して 1 つの時系列を予測するをお読みになることを強くおすすめします。
データセットを作成する
ML モデルを保存する BigQuery データセットを作成します。
コンソール
Google Cloud コンソールで、[BigQuery] ページに移動します。
[エクスプローラ] ペインで、プロジェクト名をクリックします。
[アクションを表示] > [データセットを作成] をクリックします。
[データセットを作成する] ページで、次の操作を行います。
[データセット ID] に「
bqml_tutorial」と入力します。[ロケーション タイプ] で [マルチリージョン] を選択してから、[US(米国の複数のリージョン)] を選択します。
残りのデフォルトの設定は変更せず、[データセットを作成] をクリックします。
bq
新しいデータセットを作成するには、--location フラグを指定した bq mk コマンドを使用します。使用可能なパラメータの一覧については、bq mk --dataset コマンドのリファレンスをご覧ください。
データの場所が
USに設定され、BigQuery ML tutorial datasetという説明の付いた、bqml_tutorialという名前のデータセットを作成します。bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
このコマンドでは、
--datasetフラグの代わりに-dショートカットを使用しています。-dと--datasetを省略した場合、このコマンドはデフォルトでデータセットを作成します。データセットが作成されたことを確認します。
bq ls
API
定義済みのデータセット リソースを使用して datasets.insert メソッドを呼び出します。
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
入力データを可視化する
モデルを作成する前に、必要に応じて入力時系列データを可視化して分布を把握できます。これは、Looker Studio を使用して行います。
SQL
次のクエリの SELECT ステートメントは、EXTRACT 関数を使用して、starttime 列から日付情報を抽出します。さらに、COUNT(*) 句を使用して、1 日あたりのシティバイクの合計利用回数を取得します。
時系列データを可視化する手順は次のとおりです。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
SELECT EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY date;
クエリが完了したら、[データを探索] > [Looker Studio で調べる] をクリックします。Looker Studio が新しいタブで開きます。新しいタブで次の操作を行います。
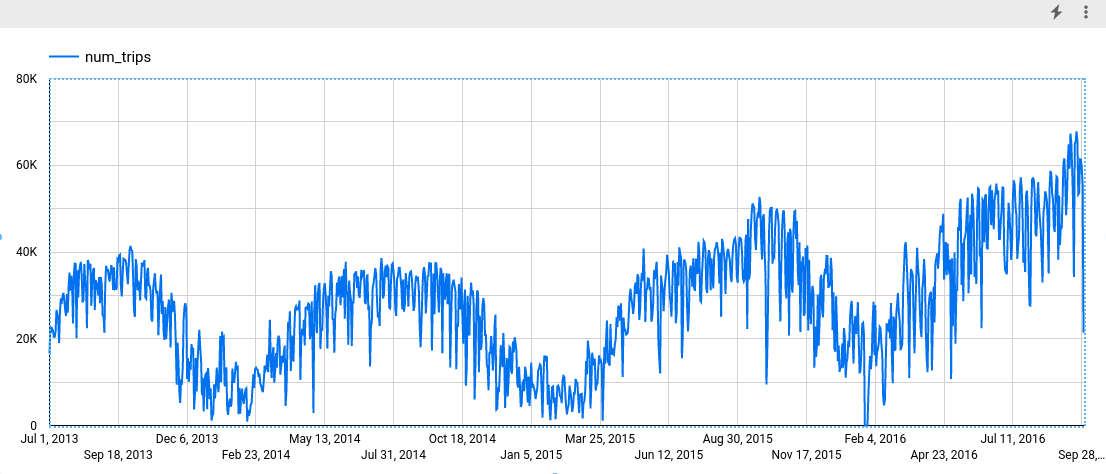
Looker Studio で、[挿入] > [期間グラフ] をクリックします。
[グラフ] ペインで、[設定] タブを選択します。
[指標] セクションで、num_trips フィールドを追加し、デフォルトの指標である [レコード数] を削除します。作成されたグラフは次のようになります。
BigQuery DataFrames
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
時系列モデルを作成する
シティバイク ステーションごとの自転車利用回数を予測したいとします。この場合、入力データに含まれるシティバイク ステーションごとに 1 つずつ、多くの時系列モデルが必要になります。これは複数のモデルを作成すればできますが、特に多数の時系列が存在する場合に、作成に手間や時間がかかる可能性があります。代わりに、1 つのクエリを使用して一連の時系列モデルを作成して適合させ、複数の時系列を一度に予測できます。
SQL
次のクエリの OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...) 句は、ARIMA ベースの時系列モデルを作成していることを示します。CREATE MODEL ステートメントの time_series_id_col オプションを使用して、予測を取得する入力データの 1 つ以上の列(この場合は、start_station_name 列で表されるシティバイク ステーション)を指定します。WHERE 句を使用して、名前に Central Park が含まれるステーションに限定します。CREATE MODEL ステートメントの auto_arima_max_order オプションは、auto.ARIMA アルゴリズムでのハイパーパラメータ チューニングの検索空間を制御します。CREATE MODEL ステートメントの decompose_time_series オプションはデフォルトで TRUE に設定されているため、次のステップでモデルを評価するときに時系列データに関する情報が返されます。
次の手順でモデルを作成します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_group` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 5 ) AS SELECT start_station_name, EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` WHERE start_station_name LIKE '%Central Park%' GROUP BY start_station_name, date;
クエリが完了するまでに約 24 秒かかります。完了後、
nyc_citibike_arima_model_groupモデルにアクセスできます。クエリはCREATE MODELステートメントを使用するため、クエリの結果は表示されません。
このクエリでは、入力データ内の 12 個のシティバイクの出発ステーションごとに 1 つずつ、12 個の時系列モデルを作成します。所要時間は約 24 秒です。並列処理を行うため、これは 1 つの時系列モデルを作成する場合の 1.4 倍程度にすぎません。ただし、WHERE ... LIKE ... 句を削除すると、600 以上の時系列が予測され、スロットの容量の制限により、時系列の予測が完全に並列では処理されない可能性があります。その場合、クエリが完了するまでに約 15 分かかることがあります。モデルの品質がわずかに低下する可能性がありますが、クエリの実行時間を短縮するには、auto_arima_max_order の値を小さくします。これにより、auto.ARIMA アルゴリズムのハイパーパラメータ調整の検索空間が縮小されます。詳細については、Large-scale time series forecasting best practices をご覧ください。
BigQuery DataFrames
次のスニペットでは、ARIMA ベースの時系列モデルを作成します。
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
これにより、入力データ内の 12 個のシティバイクの出発ステーションごとに 1 つずつ、12 個の時系列モデルが作成されます。所要時間は約 24 秒です。並列処理を行うため、これは 1 つの時系列モデルを作成する場合の 1.4 倍程度にすぎません。
モデルを評価する
SQL
ML.ARIMA_EVALUATE 関数を使用して時系列モデルを評価します。ML.ARIMA_EVALUATE 関数は、ハイパーパラメータの自動チューニング プロセス中にモデルに対して生成された評価指標を表示します。
次の手順でモデルを評価します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
SELECT * FROM ML.ARIMA_EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`);
結果は次のようになります。
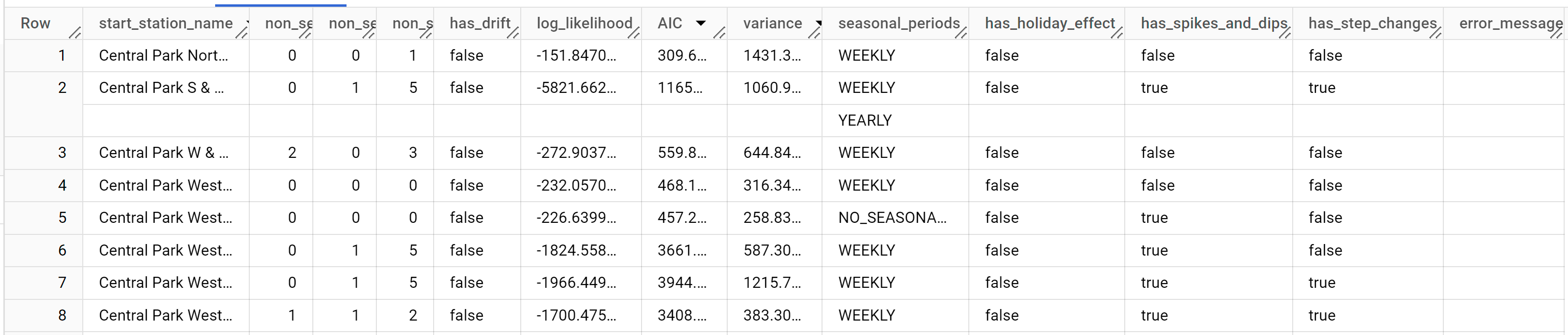
auto.ARIMAは、各時系列について複数の ARIMA 候補モデルを評価しますが、ML.ARIMA_EVALUATEはデフォルトでは出力テーブルをコンパクトにするため、最適モデルの情報のみを出力します。すべての候補モデルを表示するには、ML.ARIMA_EVALUATE関数のshow_all_candidate_model引数をTRUEに設定します。
BigQuery DataFrames
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
start_station_name 列は、時系列が作成された入力データ列を識別します。これは、モデルの作成時に time_series_id_col オプションで指定した列です。
non_seasonal_p、non_seasonal_d、non_seasonal_q、has_drift の出力列は、トレーニング パイプラインの ARIMA モデルを定義します。log_likelihood、AIC、variance の出力列は、ARIMA モデルの適合プロセスに関連しています。適合プロセスでは、時系列ごとに 1 つ、auto.ARIMA アルゴリズムを使用して最適な ARIMA モデルが決定されます。
auto.ARIMA アルゴリズムは KPSS テストを使用して、non_seasonal_d の最適値を決定します。この場合は 1 になります。non_seasonal_d が 1 の場合、auto.ARIMA アルゴリズムは 42 個の ARIMA 候補モデルを並行してトレーニングします。この例では、42 個の候補モデルがすべて有効であるため、出力には 42 行(ARIMA 候補モデルごとに 1 行)が含まれます。一部のモデルが無効な場合は、出力から除外されます。これらの候補モデルは、AIC の昇順で返されます。最初の行のモデルは AIC が最も低く、最適なモデルとみなされます。この最適モデルが最終モデルとして保存され、次の手順で示すようにデータの予測、モデルの評価、モデルの係数の検査を行うときに使用されます。
seasonal_periods 列には、時系列データで識別された季節パターンに関する情報が含まれます。時系列ごとに異なるシーズン パターンがある場合があります。たとえば、この図では 1 つの時系列に 1 年ごとのパターンがありますが、他の時系列には存在しません。
has_holiday_effect、has_spikes_and_dips、has_step_changes 列は、decompose_time_series=TRUE の場合にのみ入力されます。これらの列も、入力時系列データに関する情報が反映されますが、ARIMA モデリングとは関係ありません。また、これらの列の値はすべての出力行で同じになります。
モデルの係数を調べる
SQL
ML.ARIMA_COEFFICIENTS 関数を使用して、時系列モデルの係数を調べます。
モデルの係数を取得する手順は次のとおりです。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
SELECT * FROM ML.ARIMA_COEFFICIENTS(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`);
クエリが完了するまでに 1 秒もかかりません。結果は次のようになります。
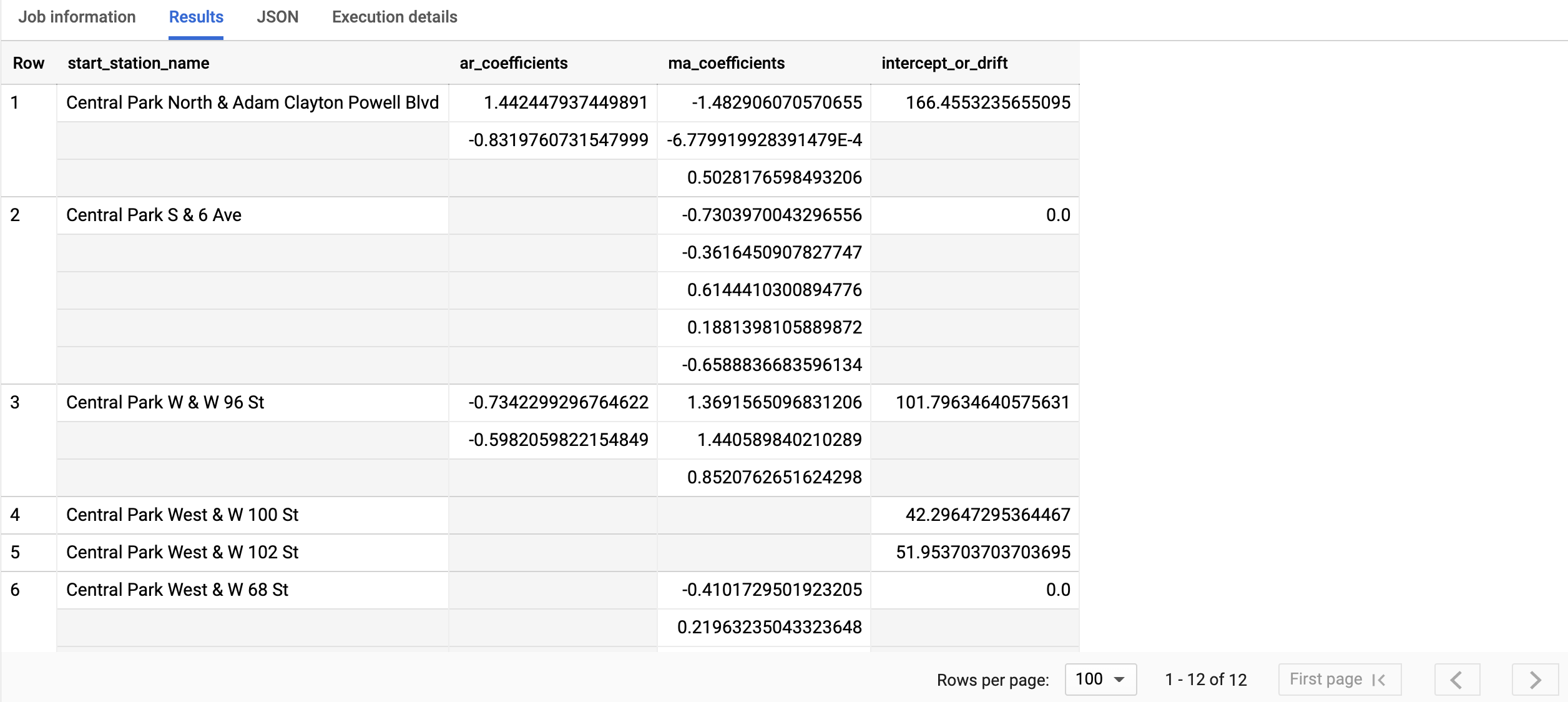
出力列の詳細については、
ML.ARIMA_COEFFICIENTS関数をご覧ください。
BigQuery DataFrames
coef_ 関数を使用して、時系列モデルの係数を調べます。
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
start_station_name 列は、時系列が作成された入力データ列を識別します。これは、モデルの作成時に time_series_id_col オプションで指定した列です。
ar_coefficients 出力列には、ARIMA モデルの自己回帰(AR)部分のモデル係数が表示されます。同様に、ma_coefficients 出力列には、ARIMA モデルの移動平均(MA)部分のモデル係数が表示されます。どちらの列にも配列値が含まれ、長さはそれぞれ non_seasonal_p と non_seasonal_q です。intercept_or_drift 値は、ARIMA モデルの定数項です。
モデルを使用してデータを予測する
SQL
ML.FORECAST 関数を使用して、将来の時系列値を予測します。
次の GoogleSQL クエリの STRUCT(3 AS horizon, 0.9 AS confidence_level) 句は、3 個の将来の時点を予測し、信頼度レベル 90% の予測間隔を生成するように表示します。
次の手順でモデルを使用し、データを予測します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
SELECT * FROM ML.FORECAST(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`, STRUCT(3 AS horizon, 0.9 AS confidence_level))
[実行] をクリックします。
クエリが完了するまでに 1 秒もかかりません。結果は次のようになります。
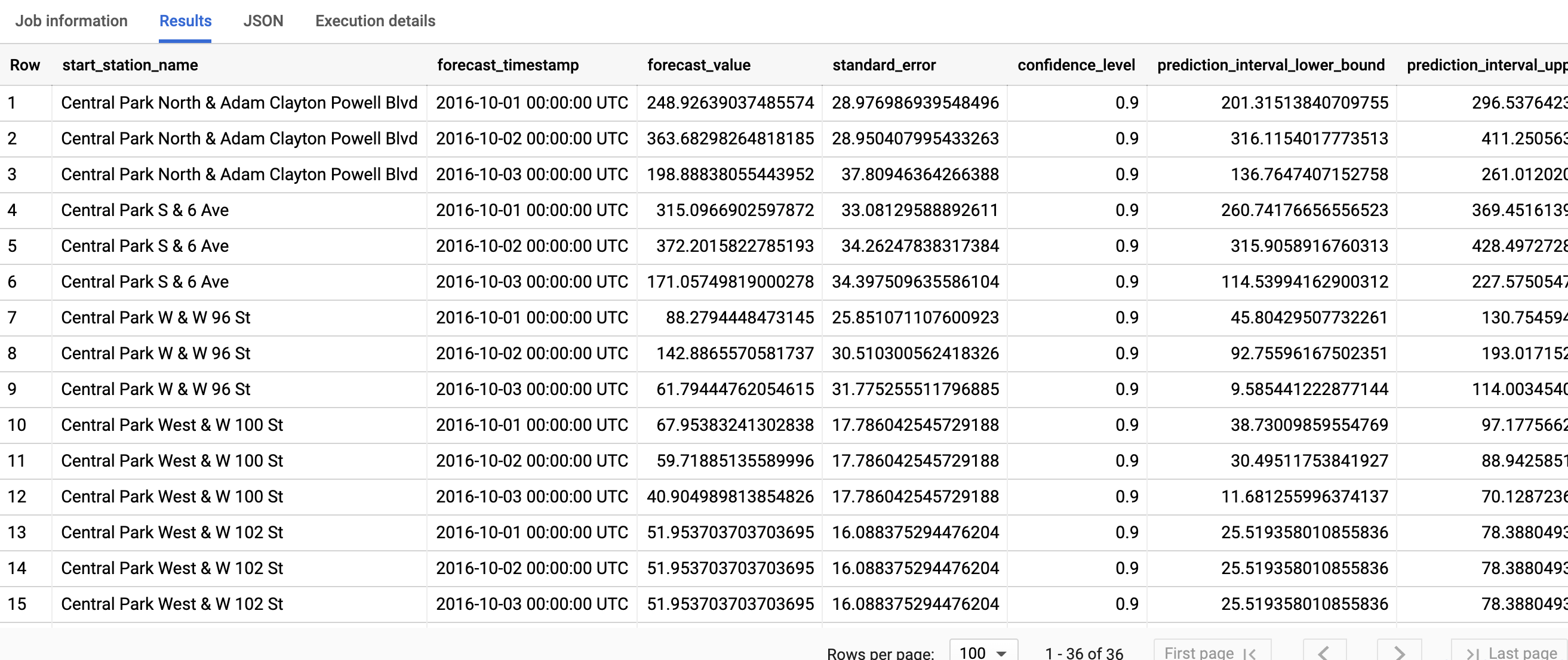
出力列の詳細については、ML.FORECAST 関数をご覧ください。
BigQuery DataFrames
predict 関数を使用して、将来の時系列値を予測します。
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
最初の列 start_station_name は、各時系列モデルが適合される時系列にアノテーションを付けます。各 start_station_name には、horizon 値で指定された 3 行の予測結果があります。
start_station_name ごとに、出力行は forecast_timestamp 列の値で時系列順に並べ替えられます。時系列予測では、prediction_interval_lower_bound 列と prediction_interval_upper_bound 列の値で表される予測間隔は、forecast_value 列の値と同じくらい重要です。forecast_value 値は予測間隔の中間点です。予測間隔は、standard_error 列と confidence_level 列の値によって異なります。
予測結果を説明する
SQL
ML.EXPLAIN_FORECAST 関数を使用すると、予測データに加えて説明可能性の指標を取得できます。ML.EXPLAIN_FORECAST 関数は、将来の時系列値を予測し、時系列の個別のコンポーネントをすべて返します。予測データを返すだけの場合は、モデルを使用してデータを予測するで説明されているように、代わりに ML.FORECAST 関数を使用します。
ML.EXPLAIN_FORECAST 関数で使用される STRUCT(3 AS horizon, 0.9 AS confidence_level) 句は、クエリが 3 個の将来の時点を予測し、信頼度 90% の予測間隔を生成するように表示します。
モデルの結果を説明する手順は次のとおりです。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
SELECT * FROM ML.EXPLAIN_FORECAST(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`, STRUCT(3 AS horizon, 0.9 AS confidence_level));
クエリが完了するまでに 1 秒もかかりません。結果は次のようになります。


返される最初の数千行はすべて履歴データです。予測データを表示するには、結果をスクロールする必要があります。
出力行は、まず
start_station_nameで並べ替えられ、次にtime_series_timestamp列の値で時系列で並べ替えられます。時系列予測では、prediction_interval_lower_bound列とprediction_interval_upper_bound列の値で表される予測間隔は、forecast_value列の値と同じくらい重要です。forecast_value値は予測間隔の中間点です。予測間隔は、standard_error列とconfidence_level列の値によって異なります。出力列の詳細については、
ML.EXPLAIN_FORECASTをご覧ください。
BigQuery DataFrames
predict_explain 関数を使用すると、予測データに加えて説明可能性の指標を取得できます。predict_explain 関数は、将来の時系列値を予測し、時系列の個別のコンポーネントをすべて返します。予測データを返すだけの場合は、モデルを使用してデータを予測するで説明されているように、代わりに predict 関数を使用します。
predict_explain 関数で使用される horizon=3, confidence_level=0.9 句は、クエリが 3 個の将来の時点を予測し、信頼度 90% の予測間隔を生成するように表示します。
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
出力行は、まず time_series_timestamp で並べ替えられ、次に start_station_name 列の値で時系列で並べ替えられます。時系列予測では、prediction_interval_lower_bound 列と prediction_interval_upper_bound 列の値で表される予測間隔は、forecast_value 列の値と同じくらい重要です。forecast_value 値は予測間隔の中間点です。予測間隔は、standard_error 列と confidence_level 列の値によって異なります。