このチュートリアルでは、データ アナリストを対象に BigQuery ML の行列分解モデルを紹介します。BigQuery ML を使用すると、BigQuery で SQL クエリを使用して機械学習モデルを作成して実行できます。このチュートリアルは、SQL のユーザーが簡単に機械学習を利用できるようにすることを目標としています。使い慣れたツールを使用してモデルを構築でき、データを移動する必要もないため、開発スピードを向上させることができます。
このチュートリアルでは、GA360_test.ga_sessions_sample サンプル テーブルを使用して暗黙的なフィードバックから行列分解モデルを作成し、訪問者 ID とコンテンツ ID を指定してレコメンデーションを行う方法を学びます。
ga_sessions_sample テーブルには、Google アナリティクス 360 によって収集され、BigQuery に送信されたセッション データのスライスに関する情報が含まれています。
目標
このチュートリアルでは、以下を使用します。
- BigQuery ML。
CREATE MODELステートメントを使用して暗黙的なレコメンデーション モデルを作成します。 ML.EVALUATE関数。ML モデルを評価します。ML.WEIGHTS関数。トレーニング中に生成された潜在因子の重みを検査します。ML.RECOMMEND関数。ユーザー向けにレコメンデーションを生成します。
費用
このチュートリアルでは、Google Cloud の課金対象となる以下のコンポーネントを使用します。
- BigQuery
- BigQuery ML
BigQuery の費用の詳細については、BigQuery の料金ページをご覧ください。
BigQuery ML の費用の詳細については、BigQuery ML の料金をご覧ください。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
Google Cloud Console の [プロジェクト セレクタ] ページで、Google Cloud プロジェクトを選択または作成します。
-
Google Cloud Console の [プロジェクト セレクタ] ページで、Google Cloud プロジェクトを選択または作成します。
- 新しいプロジェクトでは、BigQuery が自動的に有効になります。既存のプロジェクトで BigQuery を有効にするには、
BigQuery API を有効にします。
にアクセスします。
ステップ 1: データセットを作成する
ML モデルを保存する BigQuery データセットを作成します。
Google Cloud コンソールで [BigQuery] ページに移動します。
[エクスプローラ] ペインで、プロジェクト名をクリックします。
[アクションを表示] > [データセットを作成] をクリックします。

[データセットの作成] ページで、次の操作を行います。
[データセット ID] に「
bqml_tutorial」と入力します。[ロケーション タイプ] で [マルチリージョン] を選択してから、[US(multiple regions in United States)] を選択します。
一般公開データセットは
USマルチリージョンに保存されています。わかりやすくするため、データセットを同じロケーションに保存します。残りのデフォルトの設定は変更せず、[データセットを作成] をクリックします。

ステップ 2: アナリティクス 360 のデータを BigQuery に読み込む
ほとんどの場合、データ内の評価にはユーザーが明示的に設定した値は反映されていません。このようなシナリオでは、これらの値の代替値を暗黙的な評価として作成し、別のアルゴリズムを使用してレコメンデーションをコンピューティングできます。このサンプルでは、アナリティクス 360 データセットを使用します。このサンプルは、次の記事を基にしています。
以下は、ユーザーが cloud-training-demos.GA360_test.ga_sessions_sample のページで行ったセッション継続時間の暗黙的な評価をもつデータセットを作成するクエリです。このクエリの目的は、ユーザー列、アイテム列、評価列にマッピングできる 3 つの列をもったデータセットを作成することです。
Google Cloud コンソールで、[クエリを新規作成] ボタンをクリックします。
クエリエディタのテキスト領域に、次の GoogleSQL クエリを入力します。
#standardSQL CREATE OR REPLACE TABLE bqml_tutorial.analytics_session_data AS WITH visitor_page_content AS ( SELECT fullVisitorID, ( SELECT MAX( IF (index=10, value, NULL)) FROM UNNEST(hits.customDimensions)) AS latestContentId, (LEAD(hits.time, 1) OVER (PARTITION BY fullVisitorId ORDER BY hits.time ASC) - hits.time) AS session_duration FROM `cloud-training-demos.GA360_test.ga_sessions_sample`, UNNEST(hits) AS hits WHERE # only include hits on pages hits.type = "PAGE" GROUP BY fullVisitorId, latestContentId, hits.time ) # aggregate web stats SELECT fullVisitorID AS visitorId, latestContentId AS contentId, SUM(session_duration) AS session_duration FROM visitor_page_content WHERE latestContentId IS NOT NULL GROUP BY fullVisitorID, latestContentId HAVING session_duration > 0 ORDER BY latestContentId(省略可)処理を行うロケーションを設定するには、[展開] > [クエリ設定] をクリックします。[処理を行うロケーション] には
USを選択します。処理を行うロケーションはデータセットのロケーションに基づいて自動的に検出されるため、この手順は省略できます。
[実行] をクリックします。
クエリが完了すると、
bqml_tutorial.analytics_session_dataがナビゲーション パネルに表示されます。クエリはCREATE TABLEステートメントを使用してテーブルを作成するため、クエリ結果は表示されません。生成されたテーブルは、次のようになります。
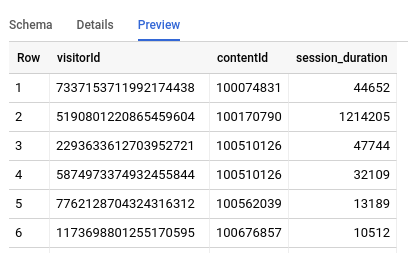
この結果は、BigQuery へのデータのエクスポート方法に特有のものです。実際のデータを抽出するクエリは異なる場合があります。
ステップ 3: 暗黙的レコメンデーションモデルを作成する
次に、前のステップで読み込んだ Google アナリティクス テーブルを使用して、暗黙的なレコメンデーション モデルを作成します。次の GoogleSQL クエリを使用して、すべての visitorId と contentId のペアの信頼度評価の予測に使用するモデルを作成します。評価の作成には、セッション継続時間の中央値を基準にセンタリングとスケーリングを行い、セッション継続時間が中央値の 3.33 倍を超えるレコードを外れ値としてフィルタします。
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.my_implicit_mf_model` OPTIONS (model_type='matrix_factorization', feedback_type='implicit', user_col='visitorId', item_col='contentId', rating_col='rating', l2_reg=30, num_factors=15) AS SELECT visitorId, contentId, 0.3 * (1 + (session_duration - 57937) / 57937) AS rating FROM `bqml_tutorial.analytics_session_data` WHERE 0.3 * (1 + (session_duration - 57937) / 57937) < 1
クエリの詳細
CREATE MODEL 句は、bqml_tutorial.my_implicit_mf_model という名前のモデルを作成し、トレーニングするために使用されます。
OPTIONS(model_type='matrix_factorization', feedback_type='IMPLICIT',
user_col='visitorId', ...) 句は、行列分解モデルを作成していることを示します。feedback_type='IMPLICIT' が指定されているため、暗黙的な行列分解モデルがトレーニングされます。明示的な行列分解モデルの作成方法の例については、明示的な行列分解モデルの作成をご覧ください。
このクエリの SELECT ステートメントは、次の列を使用してレコメンデーションを生成します。
visitorId- 訪問者 ID(INT64)。contentId- コンテンツ ID(INT64)。rating- センタリングおよびスケーリングされた、visitorIdと個々のcontentIdの 0 から 1 の暗黙的な評価(FLOAT64)。
FROM 句(bqml_tutorial.analytics_session_data)は、bqml_tutorial データセットの analytics_session_data テーブルにクエリを実行していることを示しています。ステップ 2 と 8 の手順を行っている場合は、このデータセットは BigQuery プロジェクトにあります。
CREATE MODEL クエリを実行する
モデルを作成してトレーニングする CREATE MODEL クエリを実行するには:
Google Cloud コンソールで、[クエリを新規作成] ボタンをクリックします。
[クエリエディタ] のテキスト領域に、次の GoogleSQL クエリを入力します。
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.my_implicit_mf_model` OPTIONS (model_type='matrix_factorization', feedback_type='implicit', user_col='visitorId', item_col='contentId', rating_col='rating', l2_reg=30, num_factors=15) AS SELECT visitorId, contentId, 0.3 * (1 + (session_duration - 57937) / 57937) AS rating FROM `bqml_tutorial.analytics_session_data`
[実行] をクリックします。
クエリが完了するまで約 12 分かかります。完了すると、完了後、モデル(
my_implicit_mf_model)がナビゲーション パネルに表示されます。クエリはCREATE MODELステートメントを使用してモデルを作成するため、クエリの結果は表示されません。
ステップ 4(省略可): トレーニングの統計情報を取得する
モデルのトレーニング結果を確認するには、ML.TRAINING_INFO 関数を使用するか、Google Cloud コンソールで統計情報を表示します。このチュートリアルでは、Google Cloud コンソールを使用します。
機械学習アルゴリズムは、多くのサンプルを検査し、損失を最小限に抑えるモデルを見つけることでモデルを構築します。このプロセスを経験損失最小化と呼びます。
CREATE MODEL クエリで生成したモデルのトレーニング統計を確認するには:
Google Cloud コンソールのナビゲーション パネルの [リソース] セクションで、[PROJECT_ID] > [bqml_tutorial] を開き、[my_implicit_mf_model] をクリックします。
[トレーニング] タブをクリックしてから、[テーブル] をクリックします。結果は次のようになります。
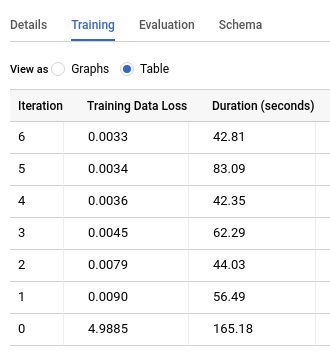
[トレーニング データの損失] 列は、トレーニング データセットでモデルのトレーニングを行った後に計算された損失指標を表します。行列分解を実行したため、この列は平均二乗誤差になります。データを分割するとユーザーやアイテムの評価をすべて失う可能性があるため、デフォルトでは、行列分解モデルはデータ分割を行いません。そのため、ホールドアウト データセットを指定しない限り [評価データの損失] 列は存在しません。その結果、欠落しているユーザーやアイテムに関する潜在因子の情報はモデルに含まれなくなります。
ML.TRAINING_INFO関数の詳細については、BigQuery ML 構文リファレンスをご覧ください。
ステップ 5: モデルを評価する
モデルを作成したら、ML.EVALUATE 関数を使用して評価者のパフォーマンスを評価します。ML.EVALUATE 関数は、実際の評価に対する予測評価を評価します。
モデルの評価に使用するクエリは次のとおりです。
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.my_implicit_mf_model`)
クエリの詳細
先頭の SELECT ステートメントで、モデルから列を取得します。
FROM 句で、モデル bqml_tutorial.my_implicit_mf_model に対して ML.EVALUATE 関数を使用します。
ML.EVALUATE クエリを実行する
モデルを評価する ML.EVALUATE クエリを実行するには:
Google Cloud コンソールで、[クエリを新規作成] ボタンをクリックします。
クエリエディタのテキスト領域に、次の GoogleSQL クエリを入力します。
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.my_implicit_mf_model`)
(省略可)処理を行うロケーションを設定するには、[展開] > [クエリ設定] をクリックします。[処理を行うロケーション] には
USを選択します。処理を行うロケーションはデータセットのロケーションに基づいて自動的に検出されるため、この手順は省略できます。 [実行] をクリックします。
クエリが完了したら、クエリテキスト領域の下にある [結果] タブをクリックします。結果は次のようになります。

暗黙的な行列分解を実行したため、結果には次の列が含まれます。
mean_average_precisionmean_squared_errornormalized_discounted_cumulative_gainaverage_rank
mean_average_precision、normalized_discounted_cumulative_gain、average_rankは、暗黙的な行列分解の指標で説明されているランキング指標です。
ステップ 6: 評価を予測してレコメンデーションを行う
モデルを使用して評価を予測し、レコメンデーションを行う
一連の visitorIds に対するすべての contentId 評価信頼度を確認する
ML.RECOMMEND は、モデル以外に引数を追加で受け取る必要はありませんが、オプションのテーブルを受け取ることができます。入力テーブルに入力 user 列または入力 item 列の名前と一致する列が 1 つしかない場合、各 user の予測アイテム評価がすべて出力されます。逆もまた同様です。すべての users またはすべての items が入力テーブルにある場合、オプションの引数を ML.RECOMMEND に渡さない場合と同じ結果が出力されます。
以下は、5 人の訪問者に関してすべての予測評価の信頼度を取得するクエリの例です。
#standardSQL
SELECT
*
FROM
ML.RECOMMEND(MODEL `bqml_tutorial.my_implicit_mf_model`,
(
SELECT
visitorId
FROM
`bqml_tutorial.analytics_session_data`
LIMIT 5))
クエリの詳細
一番上の SELECT ステートメントは、visitorId、contentId、predicted_rating_confidence 列を取得します。この最後の列は ML.RECOMMEND 関数によって生成されます。ML.RECOMMEND 関数を使用する場合、暗黙的な行列分解モデルの出力列名は predicted_rating-column-name_confidence です。暗黙的な行列分解モデルの場合、predicted_rating_confidence は user / item ペアの推定信頼度です。この信頼値はおよそ 0~1 で、信頼度の高い item ほど、信頼値の低い item よりも user に適していることになります。
ML.RECOMMEND 関数は、モデル bqml_tutorial.my_implicit_mf_model を使用して評価を予測するために使用されます。
このクエリでネストしている SELECT ステートメントは、トレーニングに使用される元のテーブルから visitorId 列のみを選択します。
LIMIT 句(LIMIT 5)は、ML.RECOMMEND に送信する 5 つの visitorId をランダムに除外します。
すべての訪問者 ID とコンテンツ ID のペアの評価を確認する
モデルを評価したら、次のステップではそのモデルを使用して評価の信頼度を取得します。このモデルを使用して、次のクエリですべてのユーザーとアイテムの組み合わせの信頼度を予測します。
#standardSQL SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_implicit_mf_model`)
クエリの詳細
一番上の SELECT ステートメントは、visitorId、contentId、predicted_rating_confidence 列を取得します。この最後の列は ML.RECOMMEND 関数によって生成されます。ML.RECOMMEND 関数を使用する場合、暗黙的な行列分解モデルの出力列名は predicted_rating-column-name_confidence です。暗黙的な行列分解モデルの場合、predicted_rating_confidence は user / item ペアの推定信頼度です。この信頼値はおよそ 0~1 で、信頼度の高い item ほど、信頼値の低い item よりも user に適していることになります。
ML.RECOMMEND 関数は、モデル bqml_tutorial.my_implicit_mf_model を使用して評価を予測するために使用されます。
結果をテーブルに保存する方法の 1 つは次のとおりです。
#standardSQL CREATE OR REPLACE TABLE `bqml_tutorial.recommend_content` OPTIONS() AS SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_implicit_mf_model`)
ML.RECOMMEND で Query Exceeded Resource Limits エラーが発生した場合は、上位の課金階層で再試行してください。BigQuery コマンドライン ツールで、--maximum_billing_tier を使用して設定できます。
レコメンデーションを生成する
次のクエリでは、ML.RECOMMEND を使用して、visitorId ごとに上位 5 つの推奨する contentId を出力します。
#standardSQL
SELECT
visitorId,
ARRAY_AGG(STRUCT(contentId, predicted_rating_confidence)
ORDER BY predicted_rating_confidence DESC LIMIT 5) AS rec
FROM
`bqml_tutorial.recommend_content`
GROUP BY
visitorId
クエリの詳細
SELECT ステートメントは、GROUP BY visitorId を使用して ML.RECOMMEND クエリの結果を集計して contentId と predicted_rating_confidence を降順で集計し、上位 5 つのコンテンツ ID のみを保持します。
前のレコメンデーション クエリを使用して、予測された評価で並べ替えを行い、ユーザーごとの上位予測アイテムを出力できます。次のクエリでは、item_ids を先ほどアップロードした movielens.movie_titles テーブルにある movie_ids と結合し、ユーザーごとに上位 5 つのおすすめ映画を出力します。
ML.RECOMMEND クエリを実行する
ML.RECOMMEND クエリを実行して、訪問者 ID 別に上位 5 つのおすすめコンテンツ ID を出力するには:
Google Cloud コンソールで、[クエリを新規作成] ボタンをクリックします。
[クエリエディタ] のテキスト領域に、次の GoogleSQL クエリを入力します。
#standardSQL CREATE OR REPLACE TABLE `bqml_tutorial.recommend_content` OPTIONS() AS SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_implicit_mf_model`)
[実行] をクリックします。
クエリの実行が完了すると、(
bqml_tutorial.recommend_content)が Google Cloud コンソールのナビゲーション パネルに表示されます。クエリはCREATE TABLEステートメントを使用してテーブルを作成するため、クエリ結果は表示されません。新しいクエリをもう 1 つ作成します。前のクエリの実行が完了したら、[クエリエディタ] のテキスト領域に次の GoogleSQL クエリを入力します。
#standardSQL SELECT visitorId, ARRAY_AGG(STRUCT(contentId, predicted_rating_confidence) ORDER BY predicted_rating_confidence DESC LIMIT 5) AS rec FROM `bqml_tutorial.recommend_content` GROUP BY visitorId
(省略可)処理を行うロケーションを設定するには、[展開] > [クエリの設定] をクリックします。[処理を行うロケーション] には
USを選択します。処理を行うロケーションはデータセットのロケーションに基づいて自動的に検出されるため、この手順は省略できます。 [実行] をクリックします。
クエリが完了したら、クエリテキスト領域の下にある [結果] タブをクリックします。結果は次のようになります。
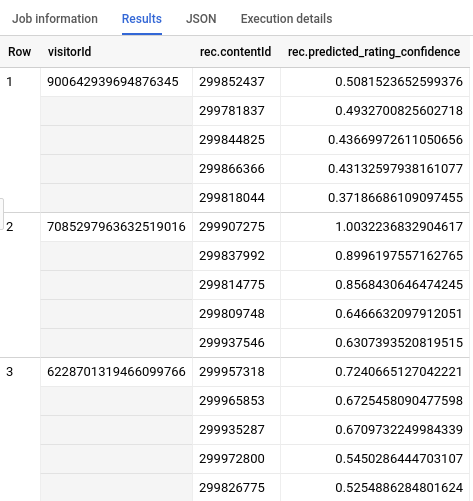
クリーンアップ
このチュートリアルで使用したリソースについて、Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
- 作成したプロジェクトを削除する。
- または、プロジェクトを保存して、データセットを削除する。
データセットを削除する
プロジェクトを削除すると、プロジェクト内のデータセットとテーブルがすべて削除されます。プロジェクトを再利用する場合は、このチュートリアルで作成したデータセットを削除できます。
必要に応じて、Google Cloud コンソールで [BigQuery] ページを開きます。
ナビゲーションで、作成した bqml_tutorial データセットをクリックします。
ウィンドウの右側にある [データセットを削除] をクリックします。この操作を行うと、データセット、テーブル、すべてのデータが削除されます。
[データセットの削除] ダイアログ ボックスでデータセットの名前(
bqml_tutorial)を入力して、[削除] をクリックします。
プロジェクトを削除する
プロジェクトを削除するには:
- Google Cloud コンソールで、[リソースの管理] ページに移動します。
- プロジェクト リストで、削除するプロジェクトを選択し、[削除] をクリックします。
- ダイアログでプロジェクト ID を入力し、[シャットダウン] をクリックしてプロジェクトを削除します。
次のステップ
- 機械学習集中講座で機械学習について学習する。
- BigQuery ML の概要で BigQuery ML の概要を確認する。
- Google Cloud コンソールの使用で、Google Cloud コンソールの詳細を確認する。