このチュートリアルでは、Vertex AI Workbench のマネージド Jupyter ノートブック インスタンスで、Python 用の BigQuery クライアント ライブラリと pandas を使用してデータを探索し、可視化する方法について説明します。データ可視化ツールは、BigQuery データをインタラクティブに分析して、データから傾向を特定し、分析情報を伝達するのに役立ちます。このチュートリアルでは、Google トレンドの BigQuery 一般公開データセットに含まれるデータを使用します。
目標
- Vertex AI Workbench を使用してマネージド Jupyter ノートブック インスタンスを作成します。
- ノートブックでマジック コマンドを使用して BigQuery データをクエリします。
- BigQuery Python クライアント ライブラリと pandas を使用して BigQuery データをクエリして可視化します。
費用
BigQuery は有料プロダクトであるため、BigQuery にアクセスすると BigQuery の利用料金が発生します。処理されるクエリデータは毎月 1 TB まで無料です。詳細については、BigQuery の料金ページをご覧ください。
Vertex AI Workbench は有料プロダクトであるため、Vertex AI Workbench インスタンスを使用すると、コンピューティング、ストレージ、管理の費用が発生します。詳細については、Vertex AI Workbench の料金ページをご覧ください。
始める前に
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery API.
新しいプロジェクトでは、BigQuery が自動的に有効になります。
Notebooks API を有効にします。
概要: Jupyter ノートブック
ノートブックにより、コードを作成および実行する環境が提供されます。ノートブックは、本質的にソース アーティファクトであり、IPYNB ファイルとして保存されます。このファイルには、説明テキスト コンテンツ、実行可能コードブロック、インタラクティブ HTML として表示される出力を含めることができます。
構造的には、ノートブックは一連のセルです。セルは、結果を生成するために評価される入力テキストのブロックです。セルには次の 3 種類があります。
- コードセル - 評価するコードが含まれます。実行されるコードの出力または結果は、その実行されるコードに沿って表示されます。
- マークダウン セル - ヘッダー、リスト、書式付きテキストを作成するために HTML に変換されるマークダウン テキストが含まれます。
- 未加工のセル - さまざまなコード形式を HTML や LaTeX で表示するために使用できます。
次の画像には、マークダウン セルの後に Python コードセルが表示され、その後に出力が表示されています。
開いた各ノートブックは、実行セッション(Python では「カーネル」とも呼ばれます)に関連付けられます。このセッションは、ノートブック内のすべてのコードを実行し、状態を管理します。状態には、変数とその値、関数、クラス、読み込まれる既存の Python モジュールが含まれます。
Google Cloudでは、Vertex AI Workbench ノートブックベースの環境を使用して、データのクエリと探索、モデルの開発とトレーニング、パイプラインの一部としてのコードの実行を行うことができます。このチュートリアルでは、Vertex AI Workbench でマネージド ノートブック インスタンスを作成し、JupyterLab インターフェース内で BigQuery データを探索します。
マネージド ノートブック インスタンスを作成する
このセクションでは、マネージド ノートブックを作成できるように、 Google Cloud で JupyterLab インスタンスを設定します。
Google Cloud コンソールの [ワークベンチ] ページに移動します。
[新しいノートブック] をクリックします。
[ノートブック名] フィールドにインスタンスの名前を入力します。
[リージョン] リストで、インスタンスのリージョンを選択します。
[権限] セクションで、マネージド ノートブック インスタンスにアクセスできるユーザーを定義するためのオプションを選択します。
- サービス アカウント: このオプションを選択すると、ランタイムにリンクする Compute Engine サービス アカウントにアクセスできるすべてのユーザーにアクセス権が付与されます。独自のサービス アカウントを指定するには、[Compute Engine のデフォルトのサービス アカウントを使用する] チェックボックスをオフにして、使用するサービス アカウントのメールアドレスを入力します。サービス アカウントの詳細については、サービス アカウントのタイプをご覧ください。
- シングル ユーザーのみ: このオプションでは、特定のユーザーのみにアクセス権が付与されます。[ユーザーのメール] フィールドに、マネージド ノートブック インスタンスを使用するユーザー アカウントのメールアドレスを入力します。
省略可: インスタンスの詳細設定を変更するには、[詳細設定] をクリックします。詳細については、詳細設定を使用してインスタンスを作成するをご覧ください。
[作成] をクリックします。
インスタンスが作成されるまで数分かかります。Vertex AI Workbench がインスタンスを自動的に起動します。インスタンスを使用する準備が整うと、Vertex AI Workbench で [JupyterLab を開く] リンクが有効になります。
JupyterLab で BigQuery リソースを確認する
このセクションでは、JupyterLab を開き、マネージド ノートブック インスタンスで利用可能な BigQuery リソースを確認します。
作成したマネージド ノートブック インスタンスの行で、[JupyterLab を開く] をクリックします。
プロンプトが表示されたら、利用規約に同意する場合は [認証] をクリックします。マネージド ノートブック インスタンスで JupyterLab が新しいブラウザタブで開きます。
JupyterLab のナビゲーション メニューで
 [BigQuery in Notebooks] をクリックします。
[BigQuery in Notebooks] をクリックします。[BigQuery] ペインに、使用可能なプロジェクトとデータセットが一覧表示されます。ここで、次のタスクを実行できます。
- データセットの説明を表示する。データセットの名前をダブルクリックします。
- データセットのテーブル、ビュー、モデルを表示する。データセットを開きます。
- 概要説明を JupyterLab のタブとして開く。テーブル、ビュー、またはモデルをダブルクリックします。
注: テーブルの概要説明で [Preview] タブをクリックして、テーブルデータをプレビューします。次の図は、
bigquery-public-dataプロジェクトのgoogle_trendsデータセットにあるinternational_top_termsテーブルのプレビューを示しています。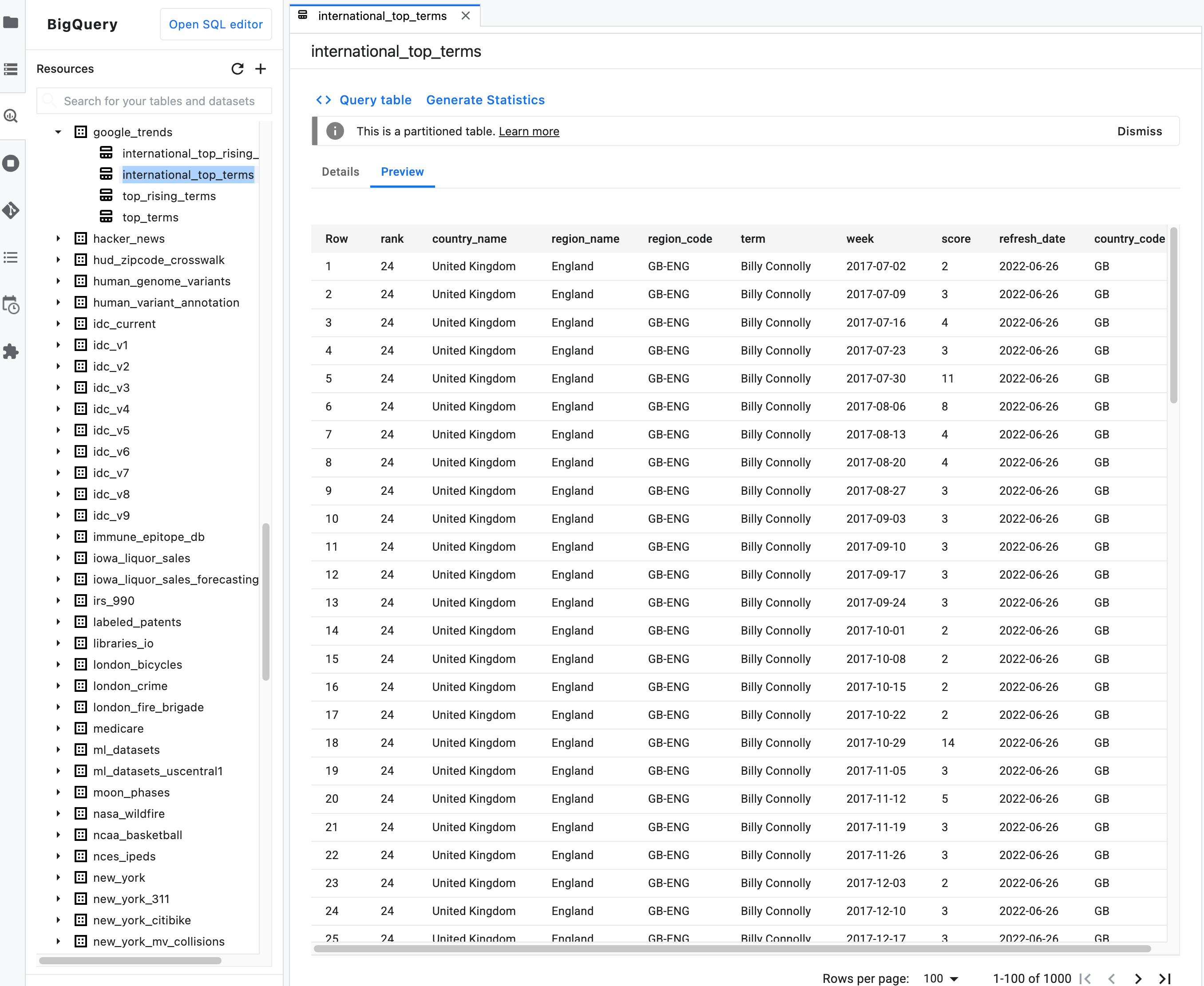
%%bigquery マジック コマンドを使用してノートブック データをクエリする
このセクションでは、ノートブック セルに SQL を直接記述し、BigQuery から Python ノートブックにデータを読み取ります。
単一または 2 個のパーセント記号(% または %%)を使用するマジック コマンドでは、ノートブック内で最小限の構文を使用して BigQuery を操作できます。マネージド ノートブック インスタンスには、Python 用 BigQuery クライアント ライブラリが自動的にインストールされます。%%bigquery マジック コマンドは、バックグラウンドで Python 用 BigQuery クライアント ライブラリを使用して指定のクエリを実行し、結果を Pandas DataFrame に変換(オプションで結果を変数に保存)して、それを表示します。
注: google-cloud-bigquery Python パッケージのバージョン 1.26.0 では、%%bigquery マジックから結果をダウンロードする際にデフォルトで BigQuery Storage API が使用されます。
ノートブック ファイルを開くには、[フィル] > [新規] > [ノートブック] の順に選択します。
[Select Kernel] ダイアログで [Python (Local)] を選択し、[Select] をクリックします。
新しい IPYNB ファイルが開きます。
international_top_termsデータセット内の国別のリージョン数を取得するには、次のステートメントを入力します。%%bigquery SELECT country_code, country_name, COUNT(DISTINCT region_code) AS num_regions FROM `bigquery-public-data.google_trends.international_top_terms` WHERE refresh_date = DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) GROUP BY country_code, country_name ORDER BY num_regions DESC;
[ Run cell] をクリックします。
出力は次のようになります。
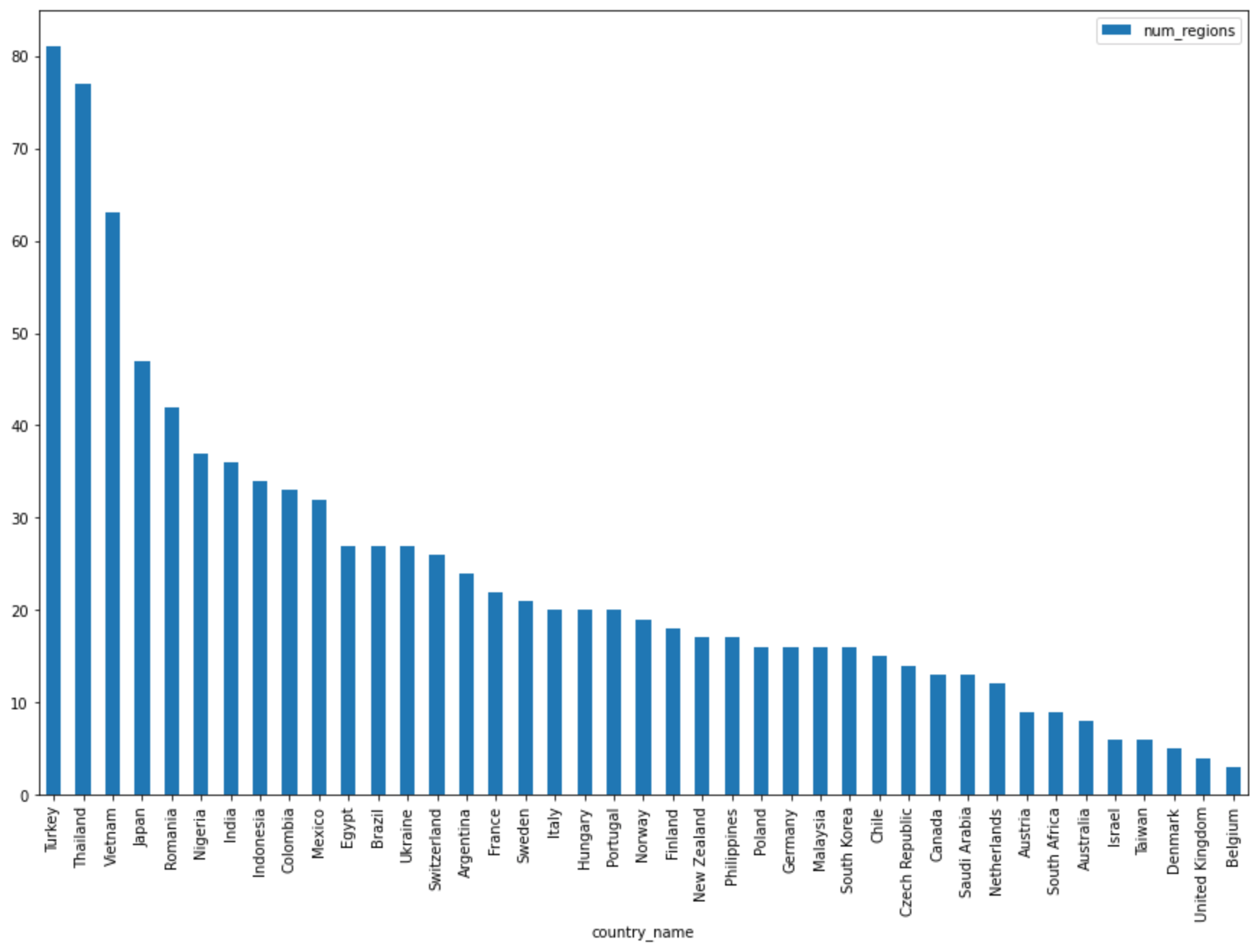
Query complete after 0.07s: 100%|██████████| 4/4 [00:00<00:00, 1440.60query/s] Downloading: 100%|██████████| 41/41 [00:02<00:00, 20.21rows/s] country_code country_name num_regions 0 TR Turkey 81 1 TH Thailand 77 2 VN Vietnam 63 3 JP Japan 47 4 RO Romania 42 5 NG Nigeria 37 6 IN India 36 7 ID Indonesia 34 8 CO Colombia 33 9 MX Mexico 32 10 BR Brazil 27 11 EG Egypt 27 12 UA Ukraine 27 13 CH Switzerland 26 14 AR Argentina 24 15 FR France 22 16 SE Sweden 21 17 HU Hungary 20 18 IT Italy 20 19 PT Portugal 20 20 NO Norway 19 21 FI Finland 18 22 NZ New Zealand 17 23 PH Philippines 17 ...
次のセル(前のセルの出力の下)で、以下のコマンドを入力して同じクエリを実行します。ただし、今回は
regions_by_countryという名前の新しい pandas DataFrame に結果を保存します。この名前は、%%bigqueryマジック コマンドで引数を使用して指定します。%%bigquery regions_by_country SELECT country_code, country_name, COUNT(DISTINCT region_code) AS num_regions FROM `bigquery-public-data.google_trends.international_top_terms` WHERE refresh_date = DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) GROUP BY country_code, country_name ORDER BY num_regions DESC;
注:
%%bigqueryコマンドで使用できる引数の詳細については、クライアント ライブラリのマジックのドキュメントをご覧ください。[ Run cell] をクリックします。
次のセルで以下のコマンドを入力すると、先ほど読み取ったクエリ結果の最初の数行が表示されます。
regions_by_country.head()[ Run cell] をクリックします。
これで、pandas DataFrame
regions_by_countryをプロットに使用する準備ができました。
BigQuery クライアント ライブラリを直接使用してノートブック内のデータをクエリする
このセクションでは、Python 用 BigQuery クライアント ライブラリを直接使用して Python ノートブックにデータを読み込みます。
クライアント ライブラリを使用すると、クエリをより詳細に制御できます。また、クエリとジョブでより複雑な構成を使用することもできます。ライブラリと pandas のインテグレーションにより、宣言型の SQL の機能と命令コード(Python)を組み合わせて、データの分析、可視化、変換を行うことができます。
注: Python 用にさまざまなデータ分析、データ ラングリング、可視化のライブラリが用意されています(numpy、pandas、matplotlib など)。これらのライブラリのいくつかは DataFrame オブジェクトを基盤とします。
次のセルに以下の Python コードを入力して、Python 用 BigQuery クライアント ライブラリをインポートし、クライアントを初期化します。
from google.cloud import bigquery client = bigquery.Client()BigQuery クライアントは、BigQuery API との間のメッセージの送受信に使用されます。
[ Run cell] をクリックします。
次のセルに以下のコードを入力して、米国の
top_termsで 1 日の上位語句の重なりの割合を日数差で取得します。これは、各日の上位語句が前日、2 日前、3 日前と何 % 重なっているのかを調べるものです(約 1 か月間のすべての日付ペアについて調べます)。sql = """ WITH TopTermsByDate AS ( SELECT DISTINCT refresh_date AS date, term FROM `bigquery-public-data.google_trends.top_terms` ), DistinctDates AS ( SELECT DISTINCT date FROM TopTermsByDate ) SELECT DATE_DIFF(Dates2.date, Date1Terms.date, DAY) AS days_apart, COUNT(DISTINCT (Dates2.date || Date1Terms.date)) AS num_date_pairs, COUNT(Date1Terms.term) AS num_date1_terms, SUM(IF(Date2Terms.term IS NOT NULL, 1, 0)) AS overlap_terms, SAFE_DIVIDE( SUM(IF(Date2Terms.term IS NOT NULL, 1, 0)), COUNT(Date1Terms.term) ) AS pct_overlap_terms FROM TopTermsByDate AS Date1Terms CROSS JOIN DistinctDates AS Dates2 LEFT JOIN TopTermsByDate AS Date2Terms ON Dates2.date = Date2Terms.date AND Date1Terms.term = Date2Terms.term WHERE Date1Terms.date <= Dates2.date GROUP BY days_apart ORDER BY days_apart; """ pct_overlap_terms_by_days_apart = client.query(sql).to_dataframe() pct_overlap_terms_by_days_apart.head()
使用する SQL は Python 文字列にカプセル化されて
query()メソッドに渡され、クエリが実行されます。クエリが完了すると、to_dataframeメソッドは BigQuery Storage API を使用して結果を pandas DataFrame にダウンロードします。[ Run cell] をクリックします。
クエリ結果の最初の数行がコードセルの下に表示されます。
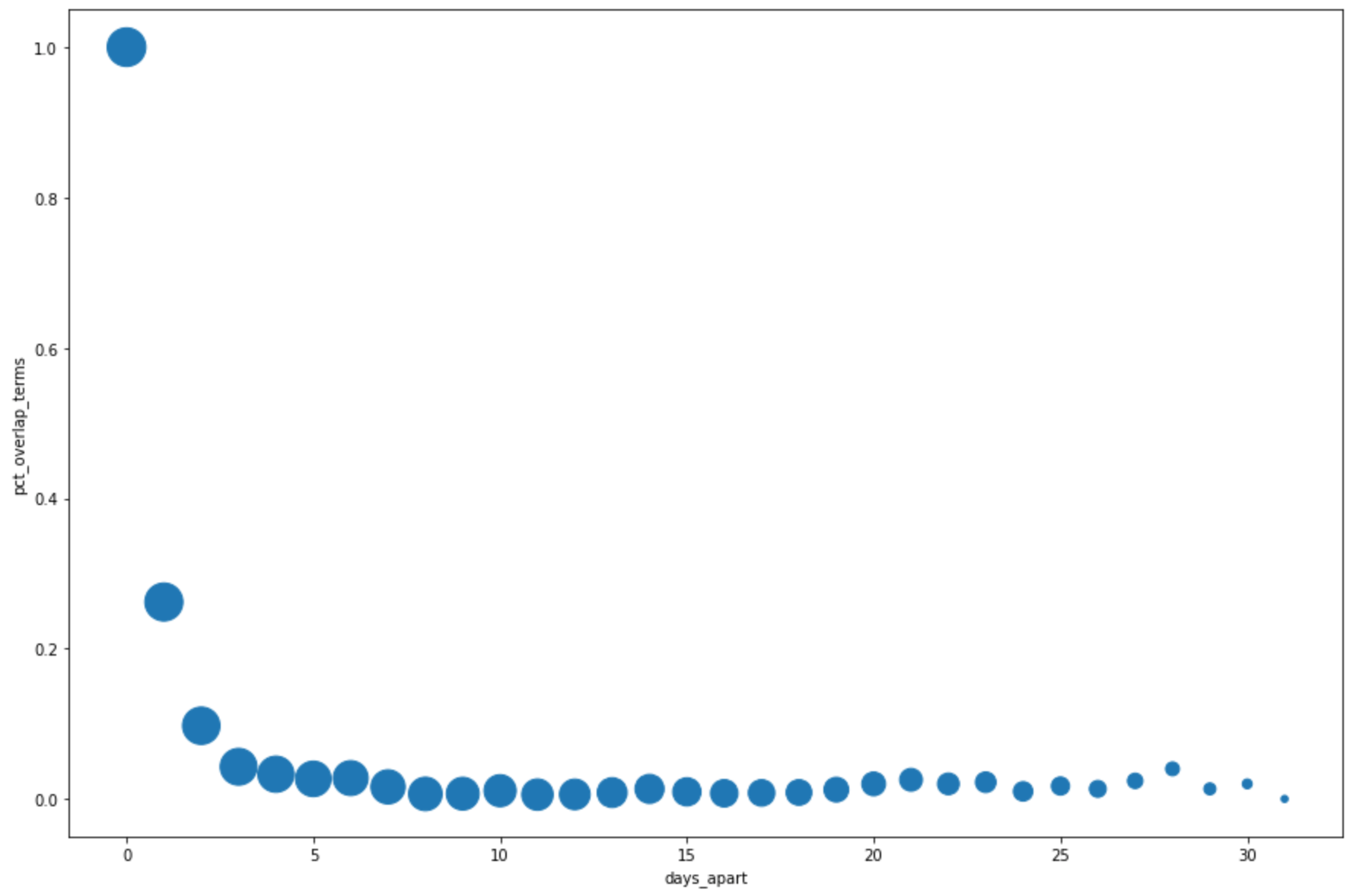
days_apart num_date_pairs num_date1_terms overlap_terms pct_overlap_terms 0 0 32 800 800 1.000000 1 1 31 775 203 0.261935 2 2 30 750 73 0.097333 3 3 29 725 31 0.042759 4 4 28 700 23 0.032857
BigQuery クライアント ライブラリの詳しい使用方法については、クイックスタートのクライアント ライブラリの使用をご覧ください。
BigQuery のデータを視覚化する
このセクションでは、プロット機能を使用して、Jupyter ノートブックで以前に実行したクエリの結果を可視化します。
次のセルに以下のコードを入力し、pandas
DataFrame.plot()メソッドを使用して、国別のリージョン数を返すクエリの結果を棒グラフで可視化します。regions_by_country.plot(kind="bar", x="country_name", y="num_regions", figsize=(15, 10))[ Run cell] をクリックします。
次のようなグラフになります。
次のセルに以下のコードを入力し、pandas
DataFrame.plot()メソッドを使用して、クエリ結果から上位の検索語句の重複率を日単位で視覚化する散布図を作成します。pct_overlap_terms_by_days_apart.plot( kind="scatter", x="days_apart", y="pct_overlap_terms", s=len(pct_overlap_terms_by_days_apart["num_date_pairs"]) * 20, figsize=(15, 10) )[ Run cell] をクリックします。
次のようなグラフになります。各ポイントのサイズは、データ内の日数が異なる日付ペアの数を反映します。たとえば、上位の検索語句はほぼ 1 か月間毎日出現しているため、期間が 1 日のペアのほうが 30 日のペアよりも数が多くなります。
データの可視化の詳細については、pandas のドキュメントをご覧ください。
%bigquery_stats マジックを使用して、すべてのテーブル列の統計情報を取得し可視化する
このセクションでは、ノートブックのショートカットを使用して、BigQuery テーブルのすべてのフィールドの要約統計を取得し、可視化します。
BigQuery クライアント ライブラリには %bigquery_stats マジック コマンドがあります。特定のテーブル名を指定してこのコマンドを呼び出すと、テーブルの概要と各テーブル列の詳細な統計情報を取得できます。
次のセルに以下のコードを入力して、米国の
top_termsテーブルで分析を行います。%bigquery_stats bigquery-public-data.google_trends.top_terms[ Run cell] をクリックします。
しばらく実行すると、
top_termsテーブルの 7 つの変数のそれぞれについて、さまざまな統計情報を含む画像が表示されます。次の図は、出力例の一部を示しています。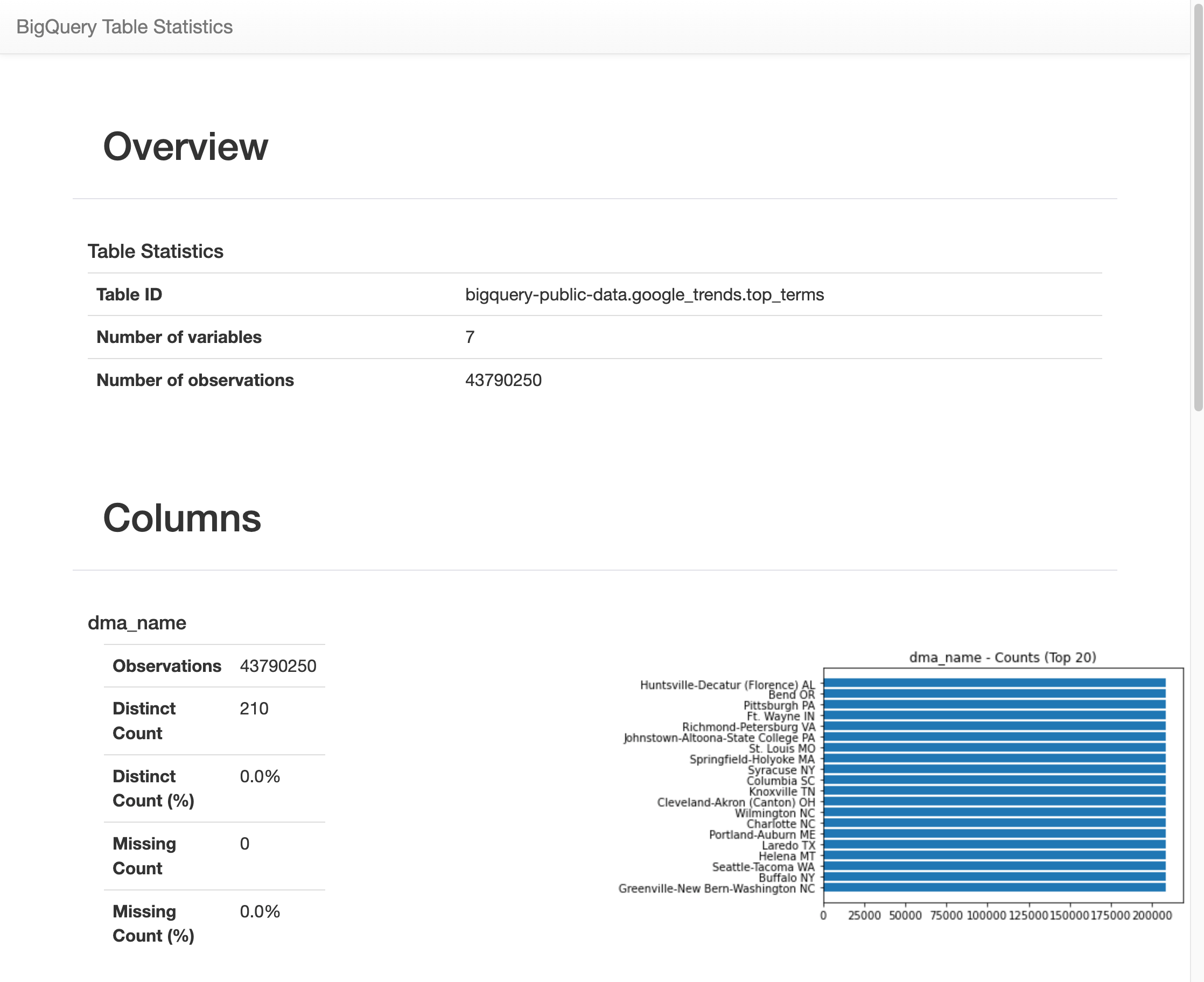
クエリ履歴を表示してクエリを再利用する
JupyterLab でクエリ履歴をタブとして表示するには、次の手順を行います。
JupyterLab のナビゲーション メニューで [
BigQuery in Notebooks] をクリックして [BigQuery] ペインを開きます。[BigQuery] ペインで下にスクロールして、[Query history] をクリックします。
クエリのリストが新しいタブで開きます。ここでは、次のような操作を実行できます。
- ジョブ ID、クエリの実行日時、所要時間など、クエリの詳細を表示するには、クエリをクリックします。
- クエリの修正、再実行、または今後使用するためにノートブックにコピーするには、[Open query in editor] をクリックします。
ノートブックを保存してダウンロードする
このセクションでは、このチュートリアルで使用したリソースをクリーンアップした後、今後使用できるようにノートブックを保存してダウンロードします。
- [File] > [Save Notebook] の順に選択します。
- [File] > [Download] を選択して、ノートブックのローカルコピーを IPYNB ファイルとしてパソコンにダウンロードします。
クリーンアップ
課金を停止する最も簡単な方法は、チュートリアル用に作成した Google Cloud プロジェクトを削除することです。
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
次のステップ
- BigQuery 用のクエリの作成方法については、インタラクティブ クエリとバッチクエリのジョブの実行をご覧ください。
- Vertex AI Workbench の詳細については、Vertex AI Workbench をご覧ください。