このチュートリアルでは、BigQuery ML のバイナリ ロジスティック回帰モデルを使用して、ユーザー属性データに基づいて個人の収入の範囲を予測します。バイナリ ロジスティック回帰モデルは、値が 2 つのカテゴリのいずれかに該当するかどうか(この場合は、個人の年収が $50,000 を上回っているか下回っているか)を予測します。
このチュートリアルでは、bigquery-public-data.ml_datasets.census_adult_income データセットを使用します。このデータセットには、2000 年と 2010 年の米国居住者のユーザー属性と収入情報が含まれています。
目標
このチュートリアルでは、次のタスクを実行します。- ロジスティック回帰モデルを作成する。
- モデルを評価する。
- モデルを使用して予測する。
- モデルによって生成される結果を説明する。
費用
このチュートリアルでは、課金対象となる以下の Google Cloudのコンポーネントを使用しています。
- BigQuery
- BigQuery ML
BigQuery の費用の詳細については、BigQuery の料金ページをご覧ください。
BigQuery ML の費用の詳細については、BigQuery ML の料金をご覧ください。
始める前に
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery API.
必要な権限
BigQuery ML を使用してモデルを作成するには、次の IAM 権限が必要です。
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.models.updateMetadata
推論を実行するには、次の権限が必要です。
- モデルに対する
bigquery.models.getData bigquery.jobs.create
はじめに
ML の一般的な問題は、ラベルと呼ばれる 2 つのタイプのいずれかにデータを分類することです。たとえば、販売店は特定の顧客が新しい製品を購入するかどうかを、その顧客に関するその他の情報に基づいて予測したい場合があります。この場合、2 つのラベルは will buy と won't buy になります。販売店は、1 つの列が両方のラベルを表し、顧客のロケーション、以前の購入、報告された好みなどの顧客情報を含むデータセットを構築できます。販売店は、この顧客情報を使用するバイナリ ロジスティック回帰モデルを使用して、各顧客を最もよく表すラベルを予測できます。
このチュートリアルでは、米国国勢調査の回答者のユーザー属性に基づいて、その回答者の収入が 2 つの範囲のどちらに分類されるかを予測するバイナリ ロジスティック回帰モデルを作成します。
データセットを作成する
モデルを格納する BigQuery データセットを作成します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
[エクスプローラ] ペインで、プロジェクト名をクリックします。
[アクションを表示] > [データセットを作成] をクリックします。
[データセットを作成する] ページで、次の操作を行います。
[データセット ID] に「
census」と入力します。[ロケーション タイプ] で [マルチリージョン] を選択してから、[US(米国の複数のリージョン)] を選択します。
一般公開データセットは
USマルチリージョンに保存されています。わかりやすくするため、データセットを同じロケーションに保存します。残りのデフォルトの設定は変更せず、[データセットを作成] をクリックします。
データを検討する
データセットを確認して、ロジスティック回帰モデルのトレーニング データとして使用する列を特定します。census_adult_income テーブルから 100 行を選択します。
SQL
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタで、次の GoogleSQL クエリを実行します。
SELECT age, workclass, marital_status, education_num, occupation, hours_per_week, income_bracket, functional_weight FROM `bigquery-public-data.ml_datasets.census_adult_income` LIMIT 100;
結果は次のようになります。

BigQuery DataFrames
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
クエリ結果から、census_adult_income テーブルの income_bracket 列には <=50K または >50K の 2 つの値のどちらかしかないことがわかります。
サンプルデータを準備する
このチュートリアルでは、census_adult_income テーブルの次の列の値に基づいて、国勢調査回答者の収入を予測します。
age: 回答者の年齢。workclass: 経験した仕事の種類(地方自治体、民間企業、自営業など)。marital_statuseducation_num: 回答者の最終学歴。occupationhours_per_week: 週あたりの労働時間
データが重複している列を除外します。たとえば、education 列。education 列と education_num 列の値は同じデータを異なる形式で表しているためです。
functional_weight 列は、国勢調査機関が特定の行に対応すると考えている人数です。この列の値は、特定の行の income_bracket の値とは無関係であるため、この列の値を使用して、functional_weight 列から派生した新しい dataframe 列を作成し、データをトレーニング セット、評価セット、予測セットに分割します。データの 80% にはモデルのトレーニング用のラベルを付け、10% には評価用のラベルを付け、10% には予測用のラベルを付けます。
SQL
サンプルデータを使用してビューを作成します。このビューは、このチュートリアルの後半の CREATE MODEL ステートメントで使用されます。
サンプルデータを準備するクエリを実行します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
[クエリエディタ] ペインで、次のクエリを実行します。
CREATE OR REPLACE VIEW `census.input_data` AS SELECT age, workclass, marital_status, education_num, occupation, hours_per_week, income_bracket, CASE WHEN MOD(functional_weight, 10) < 8 THEN 'training' WHEN MOD(functional_weight, 10) = 8 THEN 'evaluation' WHEN MOD(functional_weight, 10) = 9 THEN 'prediction' END AS dataframe FROM `bigquery-public-data.ml_datasets.census_adult_income`;
サンプルデータを表示します。
SELECT * FROM `census.input_data`;
BigQuery DataFrames
input_data という DataFrame を作成します。このチュートリアルの後半では、input_data を使用して、モデルをトレーニングおよび評価し、予測を行います。
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
ロジスティック回帰モデルを作成する
前のセクションでラベルを付けたトレーニング データを使用して、ロジスティック回帰モデルを作成します。
SQL
CREATE MODEL ステートメントを使用し、モデルタイプに LOGISTIC_REG を指定します。
CREATE MODEL ステートメントについては、次の点に注意してください。
input_label_colsオプションは、SELECTステートメントでラベル列として使用する列を指定します。ここで、ラベル列はincome_bracketであるため、モデルはその行の他の値に基づいて、特定の行に対してincome_bracketの 2 つの値のどちらに分類される可能性が高いかを学習します。ロジスティック回帰モデルがバイナリかマルチクラスかを指定する必要はありません。BigQuery ML は、ラベル列の一意の値の数に基づいて、トレーニングするモデルのタイプを決定します。
トレーニング データ内のクラスラベルのバランスを取るために、
auto_class_weightsオプションはTRUEに設定されています。デフォルトでは、トレーニング データは重み付けされません。トレーニング データ内のラベルが不均衡である場合、モデルは最も出現回数の多いラベルクラスをより重視して予測するように学習することがあります。この場合、データセット内の回答者の大多数は低い方の収入階層に属します。このため、低い方の収入階層を過度に重視して予測するモデルになる可能性があります。クラスの重みは、各クラスの頻度に反比例した重みを計算して、クラスラベルのバランスを取ります。enable_global_explainオプションは、チュートリアルの後半でモデルでML.GLOBAL_EXPLAIN関数を使用できるようにTRUEに設定されています。SELECTステートメントは、サンプルデータを含むinput_dataビューをクエリします。WHERE句はその行をフィルタリングし、トレーニング データとしてラベル付けされた行のみがモデルのトレーニングに使用されるようにします。
ロジスティック回帰モデルを作成するクエリを実行します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
[クエリエディタ] ペインで、次のクエリを実行します。
CREATE OR REPLACE MODEL `census.census_model` OPTIONS ( model_type='LOGISTIC_REG', auto_class_weights=TRUE, enable_global_explain=TRUE, data_split_method='NO_SPLIT', input_label_cols=['income_bracket'], max_iterations=15) AS SELECT * EXCEPT(dataframe) FROM `census.input_data` WHERE dataframe = 'training'
[エクスプローラ] ペインで [データセット] をクリックします。
[データセット] ペインで
censusをクリックします。[モデル] ペインをクリックします。
[
census_model] をクリックします。[詳細] タブには、BigQuery ML がロジスティック回帰の実行に使用した属性が一覧表示されます。
BigQuery DataFrames
fit メソッドを使用してモデルをトレーニングし、to_gbq メソッドを使用してモデルをデータセットに保存します。
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
モデルのパフォーマンスを評価する
モデルを作成したら、評価データに対するモデルのパフォーマンスを評価します。
SQL
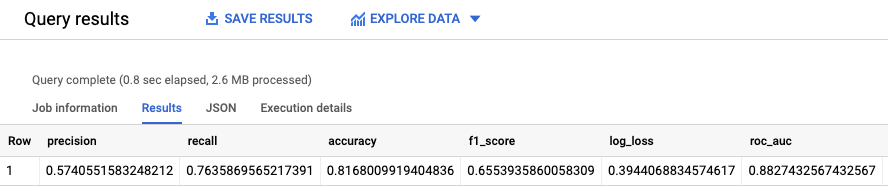
ML.EVALUATE 関数は、モデルによって生成された予測値を評価データに照らして評価します。
入力では、ML.EVALUATE 関数はトレーニング済みモデルと、dataframe 列の値が evaluation である input_data ビューの行を取得します。この関数は、モデルに関する統計を単一行で返します。
ML.EVALUATE クエリを実行します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
[クエリエディタ] ペインで、次のクエリを実行します。
SELECT * FROM ML.EVALUATE (MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'evaluation' ) );
結果は次のようになります。
BigQuery DataFrames
score メソッドを使用して、実際のデータに照らしてモデルを評価します。
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
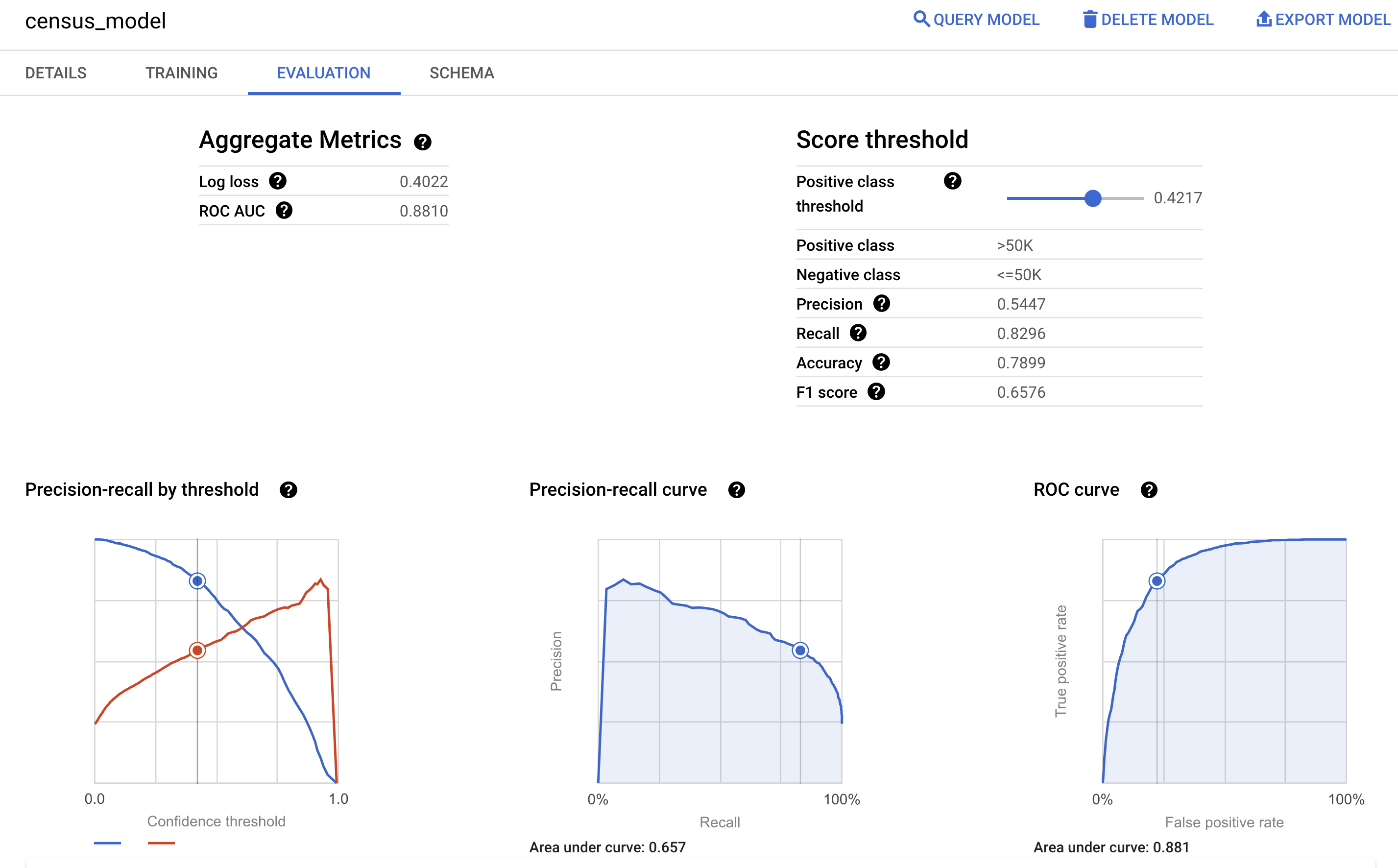
Google Cloud コンソールのモデルの [評価] ペインで、トレーニング中に計算された評価指標を確認することもできます。
収入階層を予測する
モデルを使用して、各回答者の最も可能性の高い収入階層を予測します。
SQL
ML.PREDICT 関数を使用して、可能性のある収入階層を予測します。入力では、ML.PREDICT 関数はトレーニング済みモデルと、dataframe 列の値が prediction である input_data ビューの行を取得します。
ML.PREDICT クエリを実行します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
[クエリエディタ] ペインで、次のクエリを実行します。
SELECT * FROM ML.PREDICT (MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'prediction' ) );
結果は次のようになります。
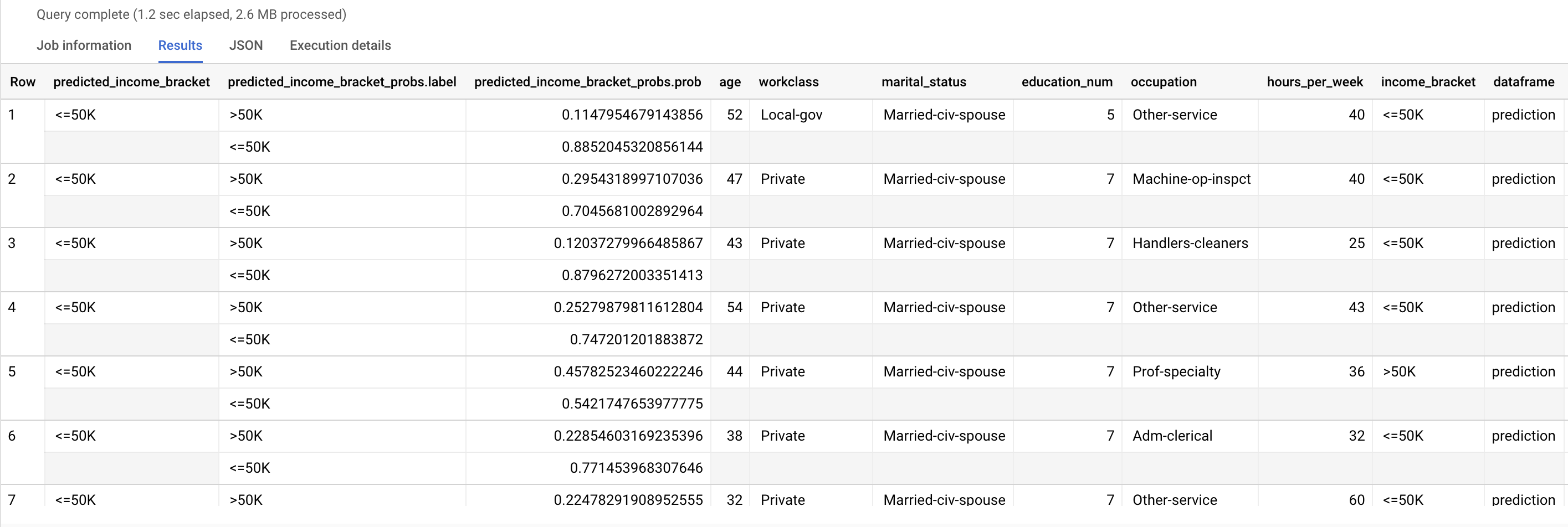
predicted_income_bracket 列には、回答者の予測収入階層が含まれます。
BigQuery DataFrames
predict メソッドを使用して、可能性のある収入階層を予測します。
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
予測結果について説明する
モデルがこれらの予測結果を生成する理由を理解するには、ML.EXPLAIN_PREDICT 関数を使用します。
ML.EXPLAIN_PREDICT は、ML.PREDICT 関数の拡張バージョンです。ML.EXPLAIN_PREDICT は、予測結果だけでなく、予測結果の説明に使用する追加の列も出力します。説明可能性の詳細については、BigQuery ML Explainable AI の概要をご覧ください。
ML.EXPLAIN_PREDICT クエリを実行します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
[クエリエディタ] ペインで、次のクエリを実行します。
SELECT * FROM ML.EXPLAIN_PREDICT(MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'evaluation'), STRUCT(3 as top_k_features));
結果は次のようになります。
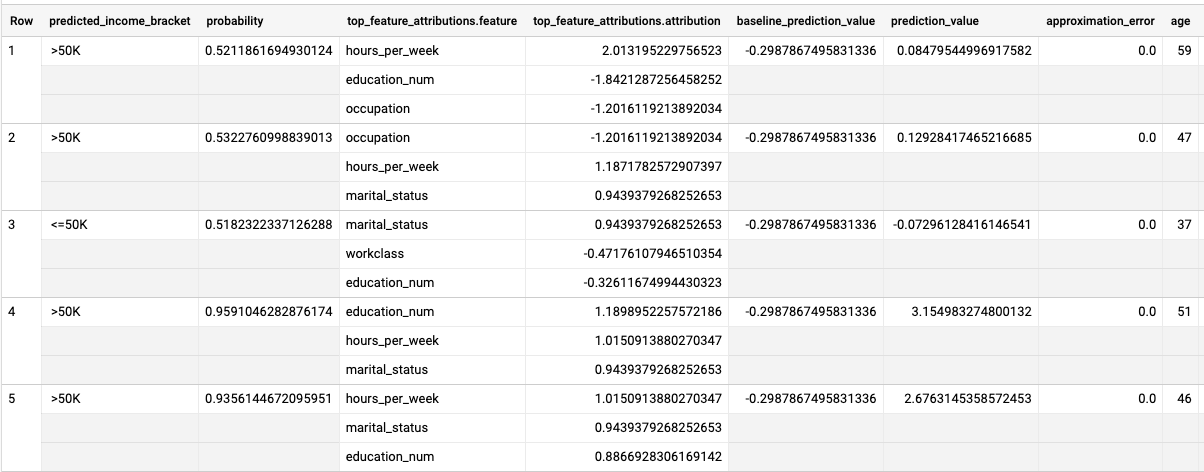
ロジスティック回帰モデルでは、Shapley 値を使用して、モデル内の各特徴の相対的な特徴アトリビューションを決定します。クエリで top_k_features オプションが 3 に設定されているため、ML.EXPLAIN_PREDICT は input_data ビューの各行の上位 3 つの特徴アトリビューションを出力します。これらのアトリビューションは、アトリビューションの絶対値の降順で表示されます。
モデルをグローバルに説明する
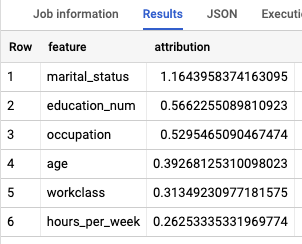
収入階層を判断するうえで最も重要な特徴を特定するには、ML.GLOBAL_EXPLAIN 関数を使用します。
モデルのグローバルな説明を取得します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタで次のクエリを実行して、グローバルな説明を取得します。
SELECT * FROM ML.GLOBAL_EXPLAIN(MODEL `census.census_model`)
結果は次のようになります。
クリーンアップ
このチュートリアルで使用したリソースについて、Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
データセットを削除する
プロジェクトを削除すると、プロジェクト内のデータセットとテーブルがすべて削除されます。プロジェクトを再利用する場合は、このチュートリアルで作成したデータセットを削除できます。
必要に応じて、Google Cloud コンソールで [BigQuery] ページを開きます。
ナビゲーションで、作成した census データセットをクリックします。
ウィンドウの右側にある [データセットを削除] をクリックします。この操作を行うと、データセットとモデルが削除されます。
[データセットの削除] ダイアログ ボックスでデータセットの名前(
census)を入力し、[削除] をクリックして確定します。
プロジェクトの削除
プロジェクトを削除するには:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
次のステップ
- BigQuery ML の概要で BigQuery ML の概要を確認する。
CREATE MODEL構文ページでモデルの作成方法を確認する。