BigQuery ML は教師なし学習をサポートしています。データをクラスタにグループ化するために K 平均法アルゴリズムを適用することができます。教師あり機械学習が予測分析を目的としているのとは異なり、教師なし学習では記述分析が目的となります。データに基づいて意思決定を下せるように、データを理解することが重要になります。
このチュートリアルでは、BigQuery ML の K 平均法モデルを使用して、ロンドンのレンタル自転車の一般公開データセットからデータのクラスタを構築します。同データセットには、ロンドンの Santander Cycle Hire Scheme の 2011 年から現在までの利用者数が含まれています。また、開始時と停止時のタイムスタンプ、ステーション名、乗車時間も含まれます。
このチュートリアルのクエリでは、地理空間分析で使用できる地理関数を使用します。地理空間分析の詳細については、地理空間分析の概要をご覧ください。
目標
このチュートリアルの内容は次のとおりです。- K 平均法クラスタリング モデルの作成。
- BigQuery ML のクラスタの可視化に基づいたデータドリブンの意思決定。
料金
このチュートリアルでは、Google Cloud の課金対象となる次のコンポーネントを使用します。
- BigQuery
- BigQuery ML
BigQuery の費用については、BigQuery の料金ページをご覧ください。
BigQuery ML の費用については、BigQuery ML の料金をご覧ください。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
Google Cloud Console の [プロジェクト セレクタ] ページで、Google Cloud プロジェクトを選択または作成します。
-
Google Cloud Console の [プロジェクト セレクタ] ページで、Google Cloud プロジェクトを選択または作成します。
- 新しいプロジェクトでは、BigQuery が自動的に有効になります。既存のプロジェクトで BigQuery を有効にするには、
BigQuery API を有効にします。
にアクセスします。
はじめに
実際のデータには、データの自然な集まりやクラスタが含まれていることがあります。データドリブンな意思決定を行うには、これらのグループを記述的に識別するのが適切な場合があります。たとえば小売店であれば、購買習慣や場所が互いに似ている顧客の自然なグループを特定できます。このようなプロセスを「顧客セグメンテーション」と呼びます。
顧客セグメンテーションに使用するデータには、訪問した店舗、購入した商品、支払った金額などがあります。モデルを作成し、こうした顧客特性を反映するグループの特徴を把握することで、そのグループを構成するユーザーにアピールする商品を考案できるようになります。
また、購入されたさまざまな商品の中から商品グループを見つけることもできます。この場合、商品を購入したユーザー、購入した日時、購入した場所、その他の類似する特性に基づいてアイテムをクラスタ化します。モデルを作成して製品グループの特性を判別することで、クロスセルの改善方法など、情報に基づく決定を下せるようになります。
このチュートリアルでは、ロンドンのレンタル自転車のデータを自転車ステーションの属性に基づいてクラスタ化します。その際、BigQuery ML を使用して K 平均法モデルを作成します。
K 平均法モデルの作成は、次の手順で行われます。
- ステップ 1: モデルを格納するためのデータセットを作成する。
- 最初のステップとして、モデルを格納するデータセットを作成します。
- ステップ 2: トレーニング データを確認する。
- 次のステップでは、
london_bicyclesテーブルに対してクエリを実行し、クラスタリング モデルのトレーニングに使用するデータの確認を行います。K 平均法は教師なし学習にあたるため、モデルのトレーニングを行う際に、トレーニング データや評価用データにラベルの指定やデータの分割を行う必要はありません。
- ステップ 3: K 平均法モデルを作成する。
- ステップ 3 では、K 平均法モデルを作成します。モデルを作成すると、クラスタリング フィールドは
station_nameになり、市内中心部から駅までの距離などのステーション属性に基づいてデータがクラスタリングされます。
- ステップ 4:
ML.PREDICT関数を使用してステーションのクラスタを予測する。 - 次に、
ML.PREDICT関数を使用して、特定のステーションのクラスタを予測します。名前にKenningtonという文字列を含むすべてのステーションのクラスタを予測します。
- ステップ 4:
- ステップ 5: モデルを使用してデータドリブンの意思決定を行う。
- 最後のステップは、モデルを使用してデータドリブンの意思決定を行うことです。たとえば、モデルの結果に基づいて、利用台数を増やすことでどのステーションにメリットが出るかがわかります。
ステップ 1: データセットを作成する
ML モデルを保存する BigQuery データセットを作成します。
Google Cloud コンソールで [BigQuery] ページに移動します。
[エクスプローラ] ペインで、プロジェクト名をクリックします。
[アクションを表示] > [データセットを作成] をクリックします。

[データセットの作成] ページで、次の操作を行います。
[データセット ID] に「
bqml_tutorial」と入力します。[ロケーション タイプ] で、[マルチリージョン] を選択し、[EU(欧州連合の複数のリージョン)] を選択します。
ロンドンのレンタル自転車の一般公開データセットは、
EUマルチリージョンロケーションに格納されています。データセットも同じロケーションに存在する必要があります。残りのデフォルトの設定は変更せず、[データセットを作成] をクリックします。

ステップ 2: トレーニング データを確認する
次に、K 平均法モデルのトレーニングに使用するデータを調べます。このチュートリアルでは、以下の属性に基づいて自転車ステーションのクラスタリングを行います。
- レンタル期間
- 1 日あたりの利用数
- 市中心部からの距離
クエリの詳細
このクエリは、start_station_name と duration を含む自転車レンタルのデータを抽出し、distance-from-city-center を含むステーション情報に結合します。そして、平均乗車時間と利用数を含んだ stationstats でステーションの属性を計算します。この計算には、ステーション属性 distance_from_city_center も含まれます。
このクエリでは、WITH 句を使用してサブクエリを定義します。また、地理空間分析関数 ST_DISTANCE と ST_GEOGPOINT も使用します。これらの関数の詳細については、地理関数をご覧ください。地理空間分析の詳細については、地理空間分析の概要をご覧ください。
クエリを実行する
次のクエリはトレーニング データをコンパイルします。このチュートリアル後半の CREATE MODEL ステートメントでもこれが使用されます。
クエリを実行するには:
[BigQuery] ページに移動します。
[エディタ] ペインで、次の SQL ステートメントを実行します。
WITH hs AS ( SELECT h.start_station_name AS station_name, IF (EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, "weekend", "weekday") AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5))/1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * FROM stationstats ORDER BY distance_from_city_center ASCクエリが完了したら、クエリテキスト領域の下にある [結果] タブをクリックします。[結果] タブの列には、モデルのトレーニングに使用したクエリ
station_name、duration、num_trips、distance_from_city_centerが表示されます。結果は次のようになります。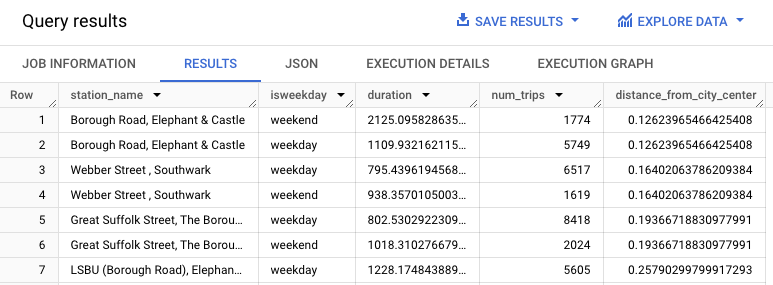
ステップ 3: K 平均法モデルを作成する
トレーニング データを確認したら、次のステップでは、そのデータを使用して K 平均法モデルを作成します。
CREATE MODEL ステートメントを model_type=kmeans オプション付きで使用することで、K 平均法モデルの作成とトレーニングが行えます。
クエリの詳細
CREATE MODEL ステートメントで、使用するクラスタの数(4)を指定します。station_name は特徴ではないので、SELECT ステートメントで EXCEPT 句を使って station_name 列を除外します。クエリによって station_name ごとに個別に行が作成されますが、SELECT ステートメントにより特徴だけが抽出されます。
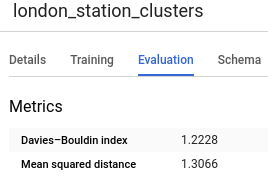
num_clusters オプションを省略すると、トレーニング データの総行数に基づき適切なデフォルト値が BigQuery ML によって選択されます。あるいは、ハイパーパラメータを調整して適切な数値を見つけることもできます。適切なクラスタ数を決定するには、複数の num_clusters 値で CREATE MODEL クエリを実行して、誤差測定値を確認します。そして、誤差測定値が最小になるポイントを選択します。誤差測定値は、モデルを選択して [評価] タブをクリックすると取得できます。このタブには、Davies-Bouldin インデックスが表示されます。
クエリを実行する
次のクエリでは、トレーニング データの確認で使用したクエリに CREATE MODEL ステートメントを追加し、さらにデータ内の id フィールドを削除します。
クエリを実行して K 平均法モデルを作成するには:
[BigQuery] ページに移動します。
[エディタ] ペインで、次の SQL ステートメントを実行します。
CREATE OR REPLACE MODEL `bqml_tutorial.london_station_clusters` OPTIONS(model_type='kmeans', num_clusters=4) AS WITH hs AS ( SELECT h.start_station_name AS station_name, IF (EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, "weekend", "weekday") AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5))/1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday) SELECT * EXCEPT(station_name, isweekday) FROM stationstatsナビゲーション パネルの [リソース] セクションでプロジェクト名を展開し、[bqml_tutorial] をクリックしてから [london_station_clusters] をクリックします。
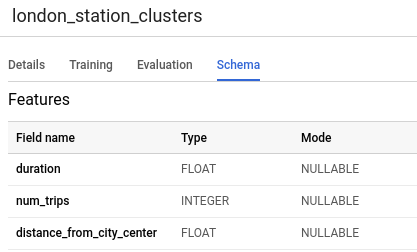
[スキーマ] タブをクリックします。モデルのスキーマには、BigQuery ML がクラスタリングを行う際に使用した 4 つのステーション属性が一覧表示されています。スキーマは次のように表示されます。
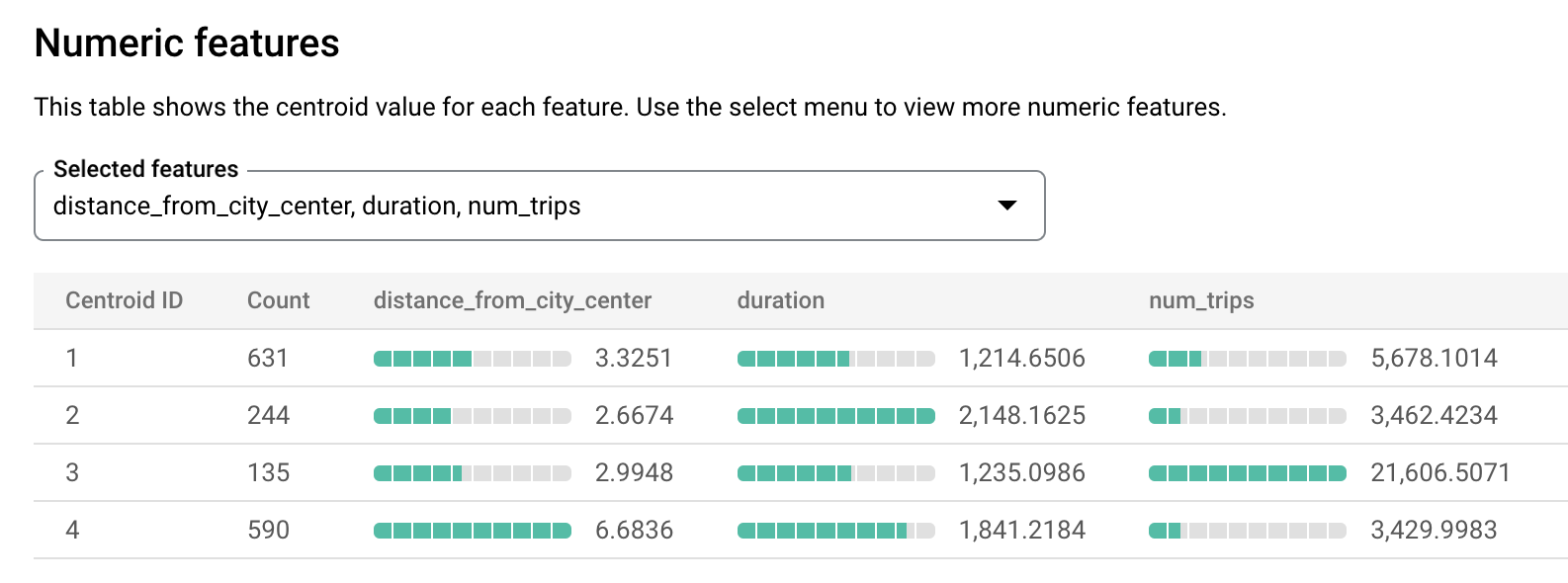
[評価] タブをクリックします。このタブには、K 平均法モデルによって識別されたクラスタが可視化されます。[数値特徴] には、セントロイドごとに最大 10 個の重要な特徴値が棒グラフで表示されます。可視化する特徴をプルダウン メニューから選択できます。
ステップ 4: ML.PREDICT 関数を使用してステーションのクラスタを予測する。
特定のステーションが属するクラスタを特定するには、ML.PREDICT 関数を使用します。
クエリの詳細
このクエリは REGEXP_CONTAINS 関数を使用して、station_name 列に文字列「Kennington」を含むすべてのエントリを検索します。ML.PREDICT 関数は、これらの値を使用して、どのクラスタにステーションが含まれるかを予測します。
クエリを実行する
次のクエリは、名前に「Kennington」という文字列を含むすべてのステーションのクラスタを予測します。
ML.PREDICT クエリを実行するには:
[BigQuery] ページに移動します。
[エディタ] ペインで、次の SQL ステートメントを実行します。
WITH hs AS ( SELECT h.start_station_name AS station_name, IF (EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, "weekend", "weekday") AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5))/1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * EXCEPT(nearest_centroids_distance) FROM ML.PREDICT( MODEL `bqml_tutorial.london_station_clusters`, ( SELECT * FROM stationstats WHERE REGEXP_CONTAINS(station_name, 'Kennington')))クエリが完了したら、クエリテキスト領域の下にある [結果] タブをクリックします。結果は次のようになります。
ステップ 5: モデルを使用してデータドリブンの意思決定を行う
評価結果により、さまざまなクラスタの状況を把握しやすくなります。次の例のセントロイド 3 は、市内中心部に近い混雑している都市ステーションを示しています。セントロイド 2 は、あまり混雑しておらずレンタル使用期間が長い、2 番目の都市ステーションを示しています。セントロイド 1 は、あまり混雑しておらず、レンタル期間が短い都市ステーションを示しています。セントロイド 4 は、移動がより長い郊外のステーションを示しています。
以上のような結果に基づき、データを参考にして判断を行うことができます。次に例を示します。
新しいタイプの鍵を試す必要があるとします。この実験の対象として、どのステーション クラスタを選択すればよいでしょうか。セントロイド 1、セントロイド 2、またはセントロイド 4 のステーションは最も混雑しているステーションではないので、論理的に言ってこれらを選択するのがよいでしょう。
長距離用の自転車をいくつかのステーションに置くことを考えているとします。どのステーションが適しているでしょうか。セントロイド 4 は、市内中心部から離れた場所にあるステーションのグループで、最も長い利用になっています。したがって、長距離用の自転車を置くには最も適したステーションと思われます。
クリーンアップ
このチュートリアルで使用したリソースについて、Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
- 作成したプロジェクトを削除する。
- または、プロジェクトを保存して、データセットを削除する。
データセットを削除する
プロジェクトを削除すると、プロジェクト内のデータセットとテーブルがすべて削除されます。プロジェクトを再利用する場合は、このチュートリアルで作成したデータセットを削除できます。
必要に応じて、Google Cloud コンソールで [BigQuery] ページを開きます。
ナビゲーションで、作成した bqml_tutorial データセットをクリックします。
ウィンドウの右側にある [データセットを削除] をクリックします。この操作を行うと、データセットとモデルが削除されます。
[データセットの削除] ダイアログ ボックスでデータセットの名前(
bqml_tutorial)を入力し、[削除] をクリックして確定します。
プロジェクトの削除
プロジェクトを削除するには:
- Google Cloud コンソールで、[リソースの管理] ページに移動します。
- プロジェクト リストで、削除するプロジェクトを選択し、[削除] をクリックします。
- ダイアログでプロジェクト ID を入力し、[シャットダウン] をクリックしてプロジェクトを削除します。
次のステップ
- BigQuery ML の概要で BigQuery ML の概要を確認する。
CREATE MODEL構文ページでモデルの作成方法を確認する。