このチュートリアルでは、一連の時系列モデルを作成し、1 つのクエリで複数の時系列予測を行う方法を学習します。また、さまざまな高速トレーニング戦略を適用してクエリを大幅に高速化する方法や予測精度を評価する方法も学習します。new_york.citibike_trips データを使用します。このデータには、ニューヨーク市でのシティバイクの利用状況に関する情報が含まれています。
このチュートリアルを読む前に、Google アナリティクス データからの 1 つの時系列を予測するをお読みになることを強くおすすめします。
目標
このチュートリアルでは、以下を使用します。
CREATE MODELステートメント: 1 つの時系列モデルまたは時系列モデルのセットを作成します。ML.ARIMA_EVALUATE関数: モデルを評価します。ML.ARIMA_COEFFICIENTS関数: モデルの係数を検査します。ML.EXPLAIN_FORECAST関数: 予測結果の説明に使用できる時系列のさまざまなコンポーネント(季節性やトレンドなど)を取得します。- Looker Studio: 予測結果を可視化します。
- 省略可:
ML.FORECAST関数: 1 日の合計訪問数を予測します。
費用
このチュートリアルでは、Google Cloud の課金対象となる以下のコンポーネントを使用します。
- BigQuery
- BigQuery ML
BigQuery の費用の詳細については、BigQuery の料金ページをご覧ください。
BigQuery ML の費用の詳細については、BigQuery ML の料金をご覧ください。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- 新しいプロジェクトでは、BigQuery が自動的に有効になります。既存のプロジェクトで BigQuery を有効にするには、
Enable the BigQuery API.
に移動します。
ステップ 1: データセットを作成する
ML モデルを保存する BigQuery データセットを作成します。
Google Cloud コンソールで [BigQuery] ページに移動します。
[エクスプローラ] ペインで、プロジェクト名をクリックします。
「アクションを表示」> [データセットを作成] をクリックします。

[データセットを作成する] ページで、次の操作を行います。
[データセット ID] に「
bqml_tutorial」と入力します。[ロケーション タイプ] で [マルチリージョン] を選択してから、[US (米国の複数のリージョン)] を選択します。
一般公開データセットは
USマルチリージョンに保存されています。わかりやすくするため、データセットを同じロケーションに保存します。残りのデフォルトの設定は変更せず、[データセットを作成] をクリックします。

ステップ 2(省略可): 予測する時系列を可視化する
モデルを作成する前に、入力時系列がどのように表示されるかを確認しておきましょう。これは、Looker Studio を使用して行います。
次のクエリでは、FROM bigquery-public-data.new_york.citibike_trips 句により new_york データセット内の citibike_trips テーブルのデータを取得します。
SELECT ステートメントで EXTRACT 関数を使用し、starttime 列から日付情報を抽出します。さらに、COUNT(*) 句を使用して、1 日あたりのシティバイクの合計利用回数を取得します。
#standardSQL SELECT EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY date
クエリを実行する手順は次のとおりです。
Google Cloud コンソールで、[クエリを新規作成] ボタンをクリックします。
[クエリエディタ] のテキスト領域に、次の GoogleSQL クエリを入力します。
#standardSQL SELECT EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY date
[実行] をクリックします。
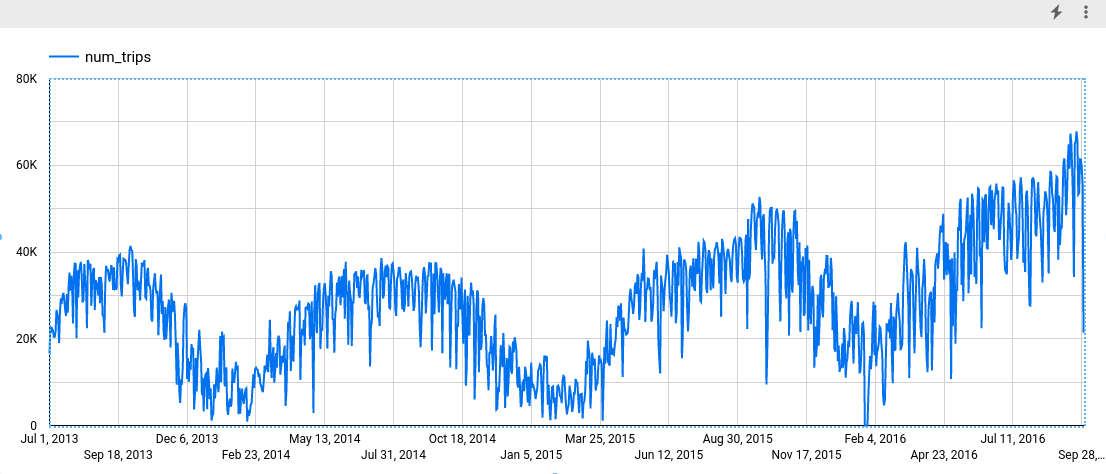
クエリを実行すると、次のスクリーンショットのような出力が表示されます。スクリーンショットを見ると、この時系列に 1,184 個の日次データポイントがあり、その期間は 4 年以上になっています。[データを探索] ボタンをクリックして、[Looker Studio で調べる] をクリックします。Looker Studio が新しいタブで開きます。新しいタブで次の操作を行います。
[グラフ] パネルで [時系列グラフ] を選択します。
[データ] パネルで、[グラフ] パネルの下にある [指標] セクションに移動します。num_trips フィールドを追加し、デフォルトの指標である [レコード数] を削除します。
上記の操作を行うと、次のようなグラフが表示されます。このグラフでは、入力時系列が週単位と年単位の両方のパターンで表示されています。また、時系列は上昇傾向にあります。
ステップ 3: 時系列モデルを作成して単一の時系列を予測する
次に、ニューヨーク市のシティバイクの利用データを使用して時系列モデルを作成します。
次の GoogleSQL クエリでは、1 日あたりの自転車レンタルの合計回数を予測するモデルを作成します。CREATE MODEL 句で bqml_tutorial.nyc_citibike_arima_model という名前のモデルを作成してトレーニングします。
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips' ) AS SELECT EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY date
OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...) 句で ARIMA ベースの時系列モデルを作成しています。デフォルトは auto_arima=TRUE であるため、auto.ARIMA アルゴリズムによって ARIMA_PLUS モデルのハイパーパラメータが自動的に調整されます。アルゴリズムが多数の候補モデルを学習し、Akaike information criterion(AIC)が最も低い最適なモデルを選択します。また、data_frequency='AUTO_FREQUENCY' がデフォルトのため、トレーニング プロセスでは入力時系列のデータ頻度が自動的に推定されます。最後に、CREATE MODEL ステートメントではデフォルトで decompose_time_series=TRUE を使用し、ユーザーは季節、休日効果などの別々の時系列のコンポーネントの取得により時系列を予測する方法をさらに理解できます。
CREATE MODEL クエリを実行してモデルを作成し、トレーニングします。
Google Cloud コンソールで、[クエリを新規作成] ボタンをクリックします。
[クエリエディタ] のテキスト領域に、次の GoogleSQL クエリを入力します。
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips' ) AS SELECT EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY date
[実行] をクリックします。
クエリが完了するまでに約 17 秒かかります。完了後、モデル(
nyc_citibike_arima_model)がナビゲーション パネルに表示されます。クエリはCREATE MODELステートメントを使用してモデルを作成するため、クエリの結果は表示されません。
ステップ 4: 時系列を予測して結果を可視化する
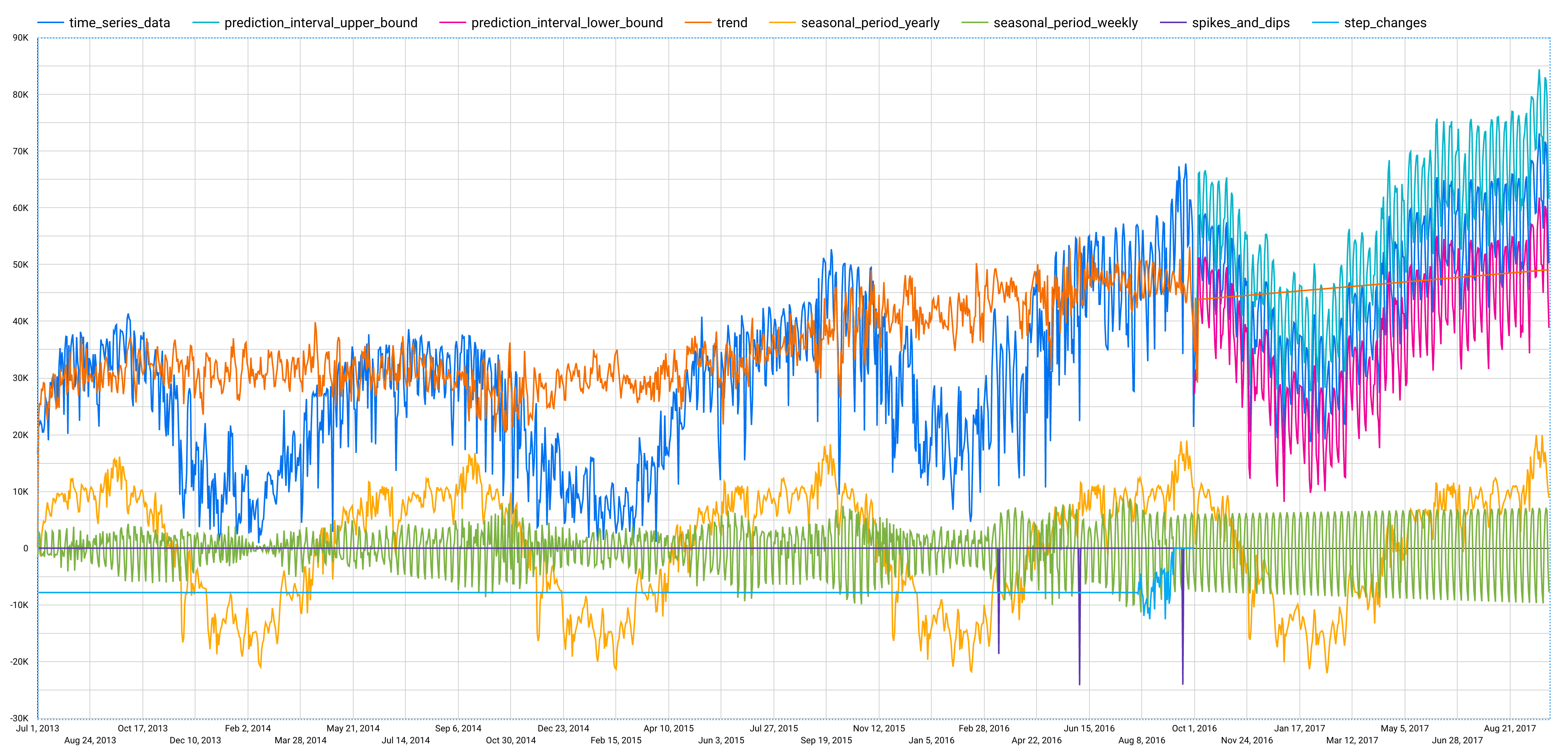
時系列を予測する方法を説明するには、ML.EXPLAIN_FORECAST 関数を使用して、季節性、トレンドなどのすべての副時系列のコンポーネントを可視化します。
これを実施する手順は次のとおりです。
Google Cloud コンソールで、[クエリを新規作成] ボタンをクリックします。
[クエリエディタ] のテキスト領域に、次の GoogleSQL クエリを入力します。
#standardSQL SELECT * FROM ML.EXPLAIN_FORECAST(MODEL `bqml_tutorial.nyc_citibike_arima_model`, STRUCT(365 AS horizon, 0.9 AS confidence_level))
[実行] をクリックします。
クエリが完了したら、[データを探索] ボタンをクリックし、[Looker Studio で調べる] をクリックします。ブラウザで新しいタブが開きます。次に、[グラフ] パネルで [時系列グラフ] アイコンをクリックします。次のスクリーンショットをご覧ください。
[データ] パネルで次の操作を行います。
- [期間のディメンション] セクションで、
time_series_timestamp (Date)を選択します。 - [ディメンション] セクションで [
time_series_timestamp (Date)] を選択します。 - [指標] セクションで、デフォルトの指標
Record Countを削除し、以下を追加します。time_series_dataprediction_interval_lower_boundprediction_interval_upper_boundtrendseasonal_period_yearlyseasonal_period_weeklyspikes_and_dipsstep_changes
- [期間のディメンション] セクションで、
[スタイル] パネルで、[Missing Data] オプションまでスクロールし、[Line to Zer] ではなく [Line Breaks] を使用します。
この手順を完了すると、左パネルに次のグラフが表示されます。
ステップ 5: 複数の時系列を同時に予測する
次に、さまざまなシティバイク ステーションでの 1 日あたりの合計利用回数を予測します。これを行うには、複数の時系列を予測する必要があります。複数の CREATE MODEL クエリを作成できますが、時系列が非常に多い場合は、作成に手間や時間がかかる可能性があります。
この作業を効率的に行うため、BigQuery ML では、1 つのクエリで複数の時系列を予測する一連の時系列モデルを作成できます。また、すべての時系列モデルが同時に適合されます。
次の GoogleSQL クエリでは、CREATE MODEL 句を使用して、bqml_tutorial.nyc_citibike_arima_model_group という名前のモデルセットを作成してトレーニングします。
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_group` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 5 ) AS SELECT start_station_name, EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` WHERE start_station_name LIKE '%Central Park%' GROUP BY start_station_name, date
OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...) 句で、一連の ARIMA ベースの時系列 ARIMA_PLUS モデルを作成します。time_series_timestamp_col と time_series_data_col のほかに、time_series_id_col を指定する必要があります。これは、異なる入力時系列にアノテーションを付けるために使用します。auto_arima_max_order オプションは、auto.ARIMA アルゴリズムにおいて、ハイパーパラメータ調整の検索空間を制御します。最後に、CREATE MODEL ステートメントはデフォルトで decompose_time_series=TRUE を使用しますが、これによりユーザーは、分解の結果の取得によりトレーニング パイプラインで時系列を分析する方法をさらに理解できます。
SELECT ... FROM ... GROUP BY ... 句で、複数の時系列を作成しています。それぞれの時系列が異なる start_station_name に関連付けられます。わかりやすくするため、WHERE ... LIKE ... 句を使用して、名前に Central Park が含まれるステーションに限定します。
CREATE MODEL クエリを実行してモデルを作成し、トレーニングする手順は次のとおりです。
Google Cloud コンソールで、[クエリを新規作成] ボタンをクリックします。
[クエリエディタ] のテキスト領域に、次の GoogleSQL クエリを入力します。
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_group` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 5 ) AS SELECT start_station_name, EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` WHERE start_station_name LIKE '%Central Park%' GROUP BY start_station_name, date
[実行] をクリックします。
クエリが完了するまでに約 24 秒かかります。完了後、モデル(
nyc_citibike_arima_model_group)がナビゲーション パネルに表示されます。クエリはCREATE MODELステートメントを使用するため、クエリの結果は表示されません。
ステップ 6: 一連の時系列モデルの評価指標を調べる
モデルを作成したら、ML.ARIMA_EVALUATE 関数を使用して、作成したすべてのモデルの評価指標を確認します。
次の GoogleSQL クエリでは、FROM 句でモデル bqml_tutorial.nyc_citibike_arima_model_group に対して ML.ARIMA_EVALUATE 関数を使用します。評価指標はトレーニングの入力にのみ依存します。このため、モデルは唯一の入力となります。
ML.ARIMA_EVALUATE クエリを実行する手順は次のとおりです。
Google Cloud コンソールで、[クエリを新規作成] ボタンをクリックします。
[クエリエディタ] のテキスト領域に、次の GoogleSQL クエリを入力します。
#standardSQL SELECT * FROM ML.ARIMA_EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`)
[実行] をクリックします。
クエリが完了するまでに 1 秒もかかりません。クエリが完了したら、クエリテキスト領域の下にある [結果] タブをクリックします。結果は次のようになります。
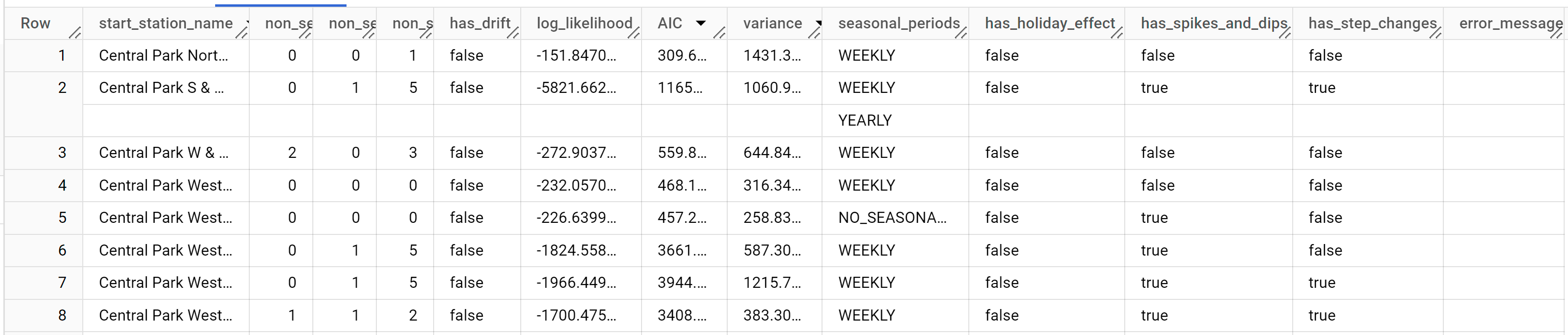
結果には次の列が含まれます。
start_station_namenon_seasonal_pnon_seasonal_dnon_seasonal_qhas_driftlog_likelihoodAICvarianceseasonal_periodshas_holiday_effecthas_spikes_and_dipshas_step_changeserror_message
最初の列である
start_station_nameは、各時系列モデルが適合される時系列にアノテーションを付けます。これはtime_series_id_colで指定されたものと同じです。次の 4 つの列(
non_seasonal_p、non_seasonal_d、non_seasonal_q、has_drift)でトレーニング パイプライン内の ARIMA モデルを定義します。その後の 3 つの指標(log_likelihood、AIC、variance)は ARIMA モデルの適合プロセスに関連しています。適合プロセスでは、時系列ごとにauto.ARIMAアルゴリズムが使用され、最適な ARIMA モデルが決定されます。has_holiday_effect、has_spikes_and_dips、has_step_changes列は、decompose_time_series=TRUEの場合にのみ入力されます。seasonal_periods列は、入力時系列内の季節パターンです。時系列ごとに異なるパターンがある場合があります。たとえば、この図では 1 つの時系列に 1 年ごとのパターンがありますが、他の時系列には存在しません。
ステップ 7: モデルの係数を調べる
ML.ARIMA_COEFFICIENTS 関数を使用して、ARIMA_PLUS モデル bqml_tutorial.nyc_citibike_arima_model_group のモデル係数を取得します。ML.ARIMA_COEFFICIENTS は、モデルを唯一の入力として受け取ります。
ML.ARIMA_COEFFICIENTS クエリを実行する手順は次のとおりです。
Google Cloud コンソールで、[クエリを新規作成] ボタンをクリックします。
[クエリエディタ] のテキスト領域に、次の GoogleSQL クエリを入力します。
#standardSQL SELECT * FROM ML.ARIMA_COEFFICIENTS(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`)
[実行] をクリックします。
クエリが完了するまでに 1 秒もかかりません。結果は次のスクリーンショットのようになります。
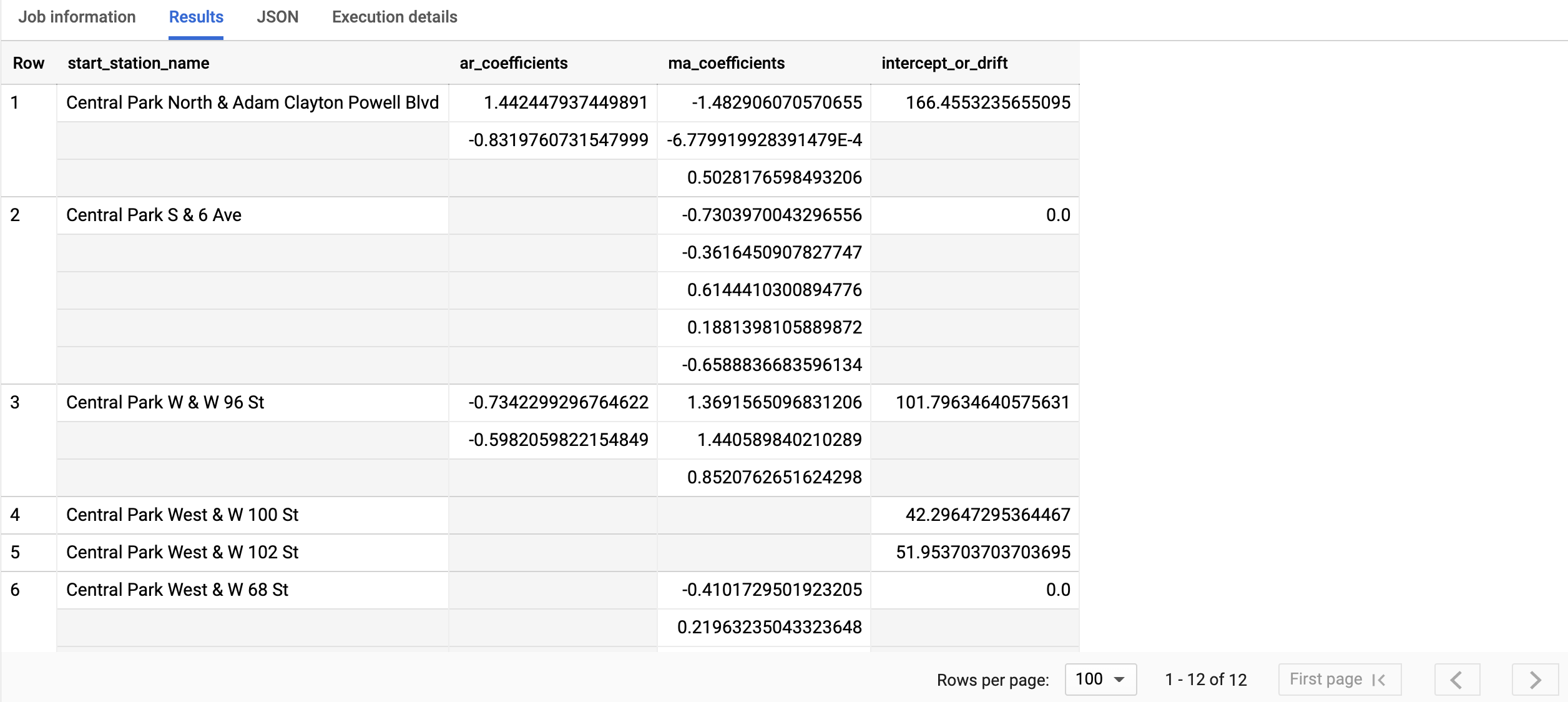
結果には次の列が含まれます。
start_station_namear_coefficientsma_coefficientsintercept_or_drift
最初の列である
start_station_nameは、各時系列モデルが適合される時系列にアノテーションを付けます。ar_coefficientsは、ARIMA モデルの自己回帰(AR)部分のモデル係数を示します。同様に、ma_coefficientsは移動平均(MA)部分のモデル係数を示します。どちらも配列で、長さはそれぞれnon_seasonal_pとnon_seasonal_qです。intercept_or_driftは、ARIMA モデルの定数項です。
ステップ 8: モデルを使用して複数の時系列を説明とともに同時に予測する
ML.EXPLAIN_FORECAST 関数は、モデル bqml_tutorial.nyc_citibike_arima_model_group を使用して将来の時系列値を特定の予測間隔で予測し、それと同時に時系列の個々のコンポーネントをすべて返します。
STRUCT(3 AS horizon, 0.9 AS confidence_level) 句は、クエリが 3 個の将来の時点を予測し、信頼度 90% の予測間隔を生成するように指示します。ML.EXPLAIN_FORECAST 関数は、モデルおよび数個のオプションの引数を取得します。
ML.EXPLAIN_FORECAST クエリを実行する手順は次のとおりです。
Google Cloud コンソールで、[クエリを新規作成] ボタンをクリックします。
[クエリエディタ] のテキスト領域に、次の GoogleSQL クエリを入力します。
#standardSQL SELECT * FROM ML.EXPLAIN_FORECAST(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`, STRUCT(3 AS horizon, 0.9 AS confidence_level))
[実行] をクリックします。
クエリが完了するまでに 1 秒もかかりません。結果は次のようになります。


結果には次の列が含まれます。
start_station_nametime_series_timestamptime_series_typetime_series_datatime_series_adjusted_datastandard_errorconfidence_levelprediction_interval_lower_boundprediction_interval_lower_boundtrendseasonal_period_yearlyseasonal_period_quarterlyseasonal_period_monthlyseasonal_period_weeklyseasonal_period_dailyholiday_effectspikes_and_dipsstep_changesresidual
出力行は
start_station_name順に並べ替えられ、start_station_nameごとに出力行はtime_series_timestampの日付順に表示されます。さまざまなコンポーネントが出力の列として一覧表示されます。詳細については、ML.EXPLAIN_FORECASTの定義をご覧ください。
(省略可)ステップ 9: モデルを使用して複数の時系列を同時に予測する
また、ML.FORECAST 関数を使用して、モデル bqml_tutorial.nyc_citibike_arima_model_group から将来の時系列値を特定の予測間隔で予測することもできます。
ML.EXPLAIN_FORECAST と同様に、STRUCT(3 AS horizon, 0.9 AS confidence_level) 句は、時系列ごとにクエリは 3 個の将来の時間点を予測し、信頼度 90% で予測間隔を生成するように指示します。
ML.FORECAST 関数は、モデルおよび数個のオプションの引数を取得します。
ML.FORECAST クエリを実行する手順は次のとおりです。
Google Cloud コンソールで、[クエリを新規作成] ボタンをクリックします。
[クエリエディタ] のテキスト領域に、次の GoogleSQL クエリを入力します。
#standardSQL SELECT * FROM ML.FORECAST(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`, STRUCT(3 AS horizon, 0.9 AS confidence_level))
[実行] をクリックします。
クエリが完了するまでに 1 秒もかかりません。結果は次のようになります。
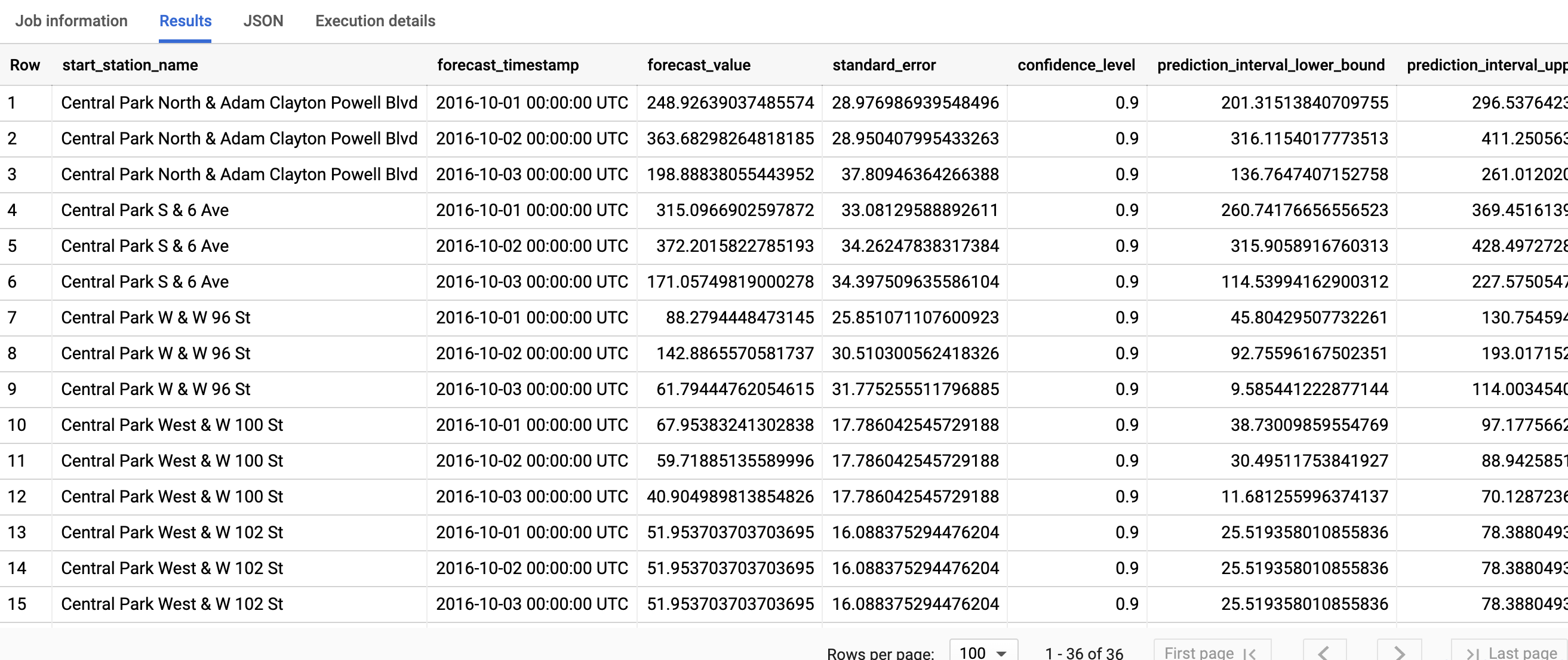
結果には次の列が含まれます。
start_station_nameforecast_timestampforecast_valuestandard_errorconfidence_levelprediction_interval_lower_boundprediction_interval_upper_boundconfidence_interval_lower_bound(間もなくサポート終了)confidence_interval_upper_bound(間もなくサポート終了)
最初の列
start_station_nameは、各時系列モデルが適合される時系列にアノテーションを付けます。各start_station_nameには、予測結果用に horizon 数の行があります。start_station_nameごとに、出力行がforecast_timestampの日付順に並べ替えられます。時系列予測の場合、下限と上限で取得される予測間隔はforecast_valueと同じくらい重要です。forecast_valueは予測間隔の中間点です。予測間隔はstandard_errorとconfidence_levelによって異なります。
クリーンアップ
このチュートリアルで使用したリソースについて、Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
- 作成したプロジェクトを削除する。
- または、プロジェクトを保存して、データセットを削除する。
データセットを削除する
プロジェクトを削除すると、プロジェクト内のデータセットとテーブルがすべて削除されます。プロジェクトを再利用する場合は、このチュートリアルで作成したデータセットを削除できます。
必要に応じて、Google Cloud コンソールで [BigQuery] ページを開きます。
ナビゲーションで、作成した bqml_tutorial データセットをクリックします。
[データセットの削除] をクリックして、データセット、テーブル、すべてのデータを削除します。
[データセットの削除] ダイアログ ボックスでデータセットの名前(
bqml_tutorial)を入力し、[削除] をクリックして確定します。
プロジェクトの削除
プロジェクトを削除するには:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
次のステップ
- ARIMA_PLUS を高速化して 100 万時系列を数時間で予測する方法を学習する。
- 機械学習集中講座で機械学習について学習する。
- BigQuery ML の概要で BigQuery ML の概要を確認する。
- Google Cloud コンソールの使用で、Google Cloud コンソールの詳細を確認する。