サンドボックスを使用して BigQuery を試す
BigQuery サンドボックスを使用すると、制限付きの BigQuery の機能を無料で試すことができ、BigQuery がニーズを満たすかどうかを確認できます。BigQuery サンドボックスでは、クレジット カード情報の登録、請求先アカウントの作成を行うことなく、BigQuery を体験できます。請求先アカウントがすでに作成されている場合でも、無料枠で BigQuery を料金なしで使用できます。
BigQuery サンドボックスを使用すると、料金なしで一部の BigQuery 機能を試してみることができます。BigQuery サンドボックスを使用して、一般公開データセットを表示してクエリすることで、BigQuery を評価できます。
Google Cloud は、BigQuery に保存され、Google Cloud 一般公開データセット プログラムを通じて一般提供されている一般公開データセットを提供します。一般公開データセットの操作の詳細については、BigQuery 一般公開データセットをご覧ください。
このタスクを Google Cloud コンソールで直接行う際の順を追ったガイダンスについては、「ガイドを表示」をクリックしてください。
始める前に
BigQuery サンドボックスを有効にする
Google Cloud コンソールで、[BigQuery] ページに移動します。
ブラウザで次の URL を入力して、 Google Cloud コンソールで BigQuery を開くこともできます。
https://console.cloud.google.com/bigquery
Google Cloud コンソールは、BigQuery リソースの作成と管理、SQL クエリの実行に使用できるグラフィカル インターフェースです。
Google アカウントで認証するか、新しいアカウントを作成します。
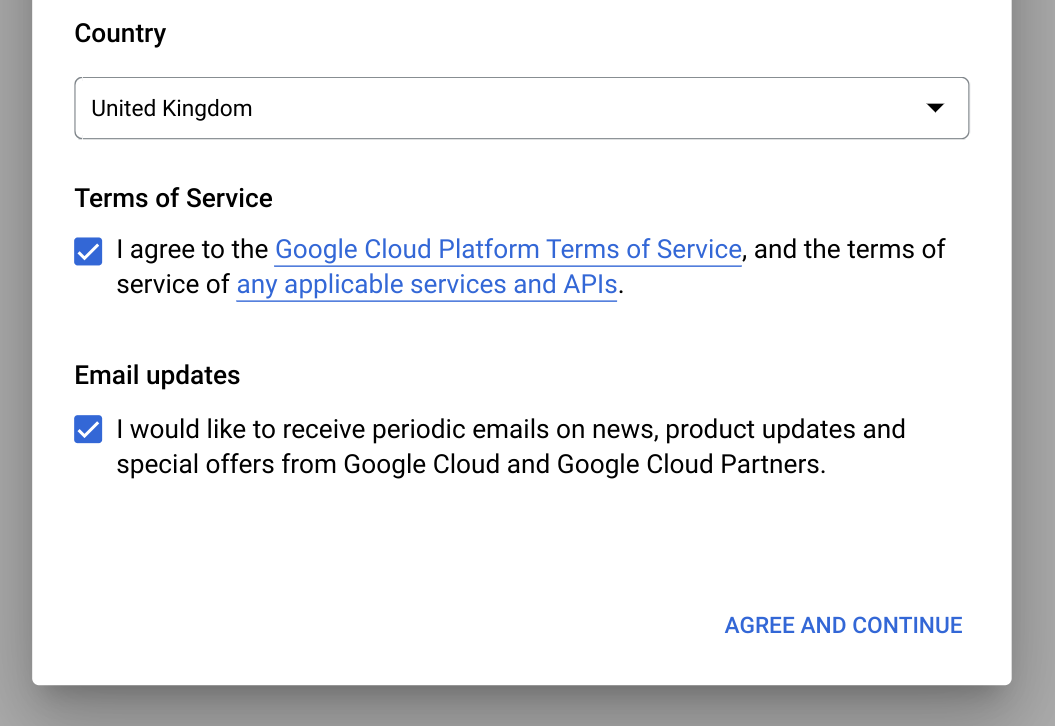
[ようこそ] ページで、次の操作を行います。
[国] で国を選択します。
[利用規約] で、利用規約に同意する場合はチェックボックスをオンにします。
省略可: 最新情報に関する通知メールについて尋ねられたら、最新情報に関する通知メールで受け取る場合はチェックボックスをオンにします。
[同意して続行] をクリックします。
[プロジェクトの作成] をクリックします。
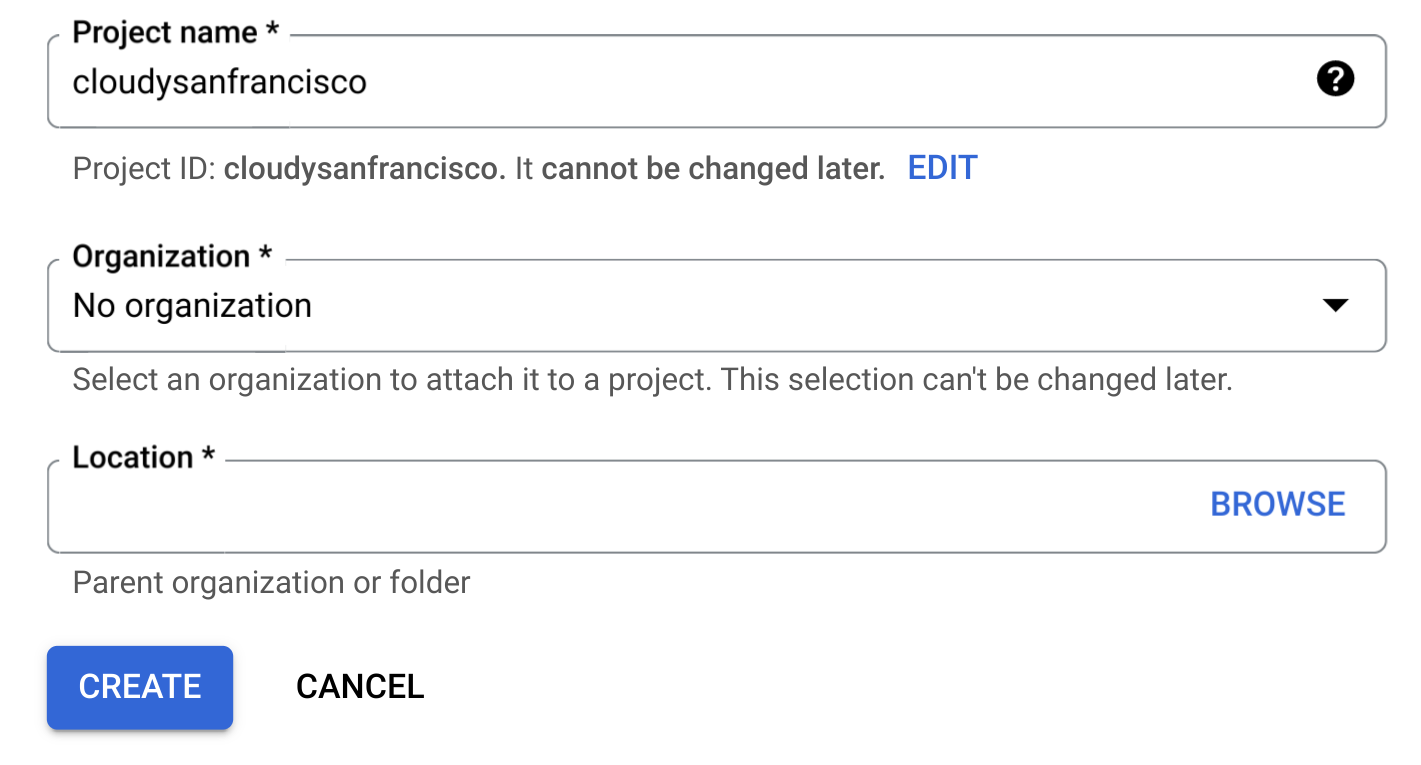
[新しいプロジェクト] ページで、次の操作を行います。
[プロジェクト名] にプロジェクトの名前を入力します。
[組織] で組織を選択します。組織に属していない場合は、[組織なし] を選択します。 管理対象アカウント(学術機関に関連付けられたアカウントなど)では、組織を選択する必要があります。
ロケーションを選択するように求められたら、[参照] をクリックしてプロジェクトのロケーションを選択します。
[作成] をクリックします。 Google Cloud コンソールの [BigQuery] ページにリダイレクトされます。
BigQuery サンドボックスが有効になりました。これで、[BigQuery] ページに BigQuery サンドボックスに関する通知が表示されます。

制限事項
BigQuery サンドボックスには次の制限があります。
- すべての BigQuery の割り当てと上限が適用されます。
- BigQuery の無料枠と同じ無料使用量の上限(毎月 10 GB のアクティブ ストレージと 1 TB のクエリデータ処理)が設定されます。
- すべての BigQuery データセットにはデフォルトのテーブルの有効期限があり、すべてのテーブル、ビュー、パーティションは 60 日後に自動的に有効期限が切れます。
BigQuery サンドボックスは、次のような一部の BigQuery 機能をサポートしていません。
一般公開データセットを表示する
BigQuery の一般公開データセットは、デフォルトで BigQuery Studio の bigquery-public-data という名前のプロジェクトに表示されます。このチュートリアルでは、NYC Citi Bike Trips データセットに対してクエリを実行します。シティバイクは、マンハッタン、ブルックリン、クイーンズ、ジャージーシティの全域で 10,000 台の自転車と 600 のステーションを持つ、大規模な自転車シェア プログラムです。このデータセットには、2013 年 9 月にシティバイクが発足して以来のシティバイクの移動記録が含まれています。
Google Cloud コンソールで、[BigQuery] ページに移動します。
左側のペインで、 [エクスプローラ] をクリックします。

左側のペインが表示されていない場合は、 左側のペインを開くをクリックしてペインを開きます。
[エクスプローラ] ペインで、[データを追加] をクリックします。
[データを追加] ダイアログの [フィルタ条件] ペインで、[
![[フィルタ条件] ページにある一般公開データセットのアイコン](https://cloud.google.com/static/bigquery/images/icon-public-dataset.png?hl=ja) 一般公開データセット] をクリックします。
一般公開データセット] をクリックします。[Marketplace] ページの [Marketplace を検索] フィールドに「
NYC Citi Bike Trips」と入力して、検索結果を絞り込みます。検索結果で [NYC Citi Bike Trips] をクリックします。
[プロダクトの詳細] ページで、[データセットを表示] をクリックします。データセットに関する情報は、[詳細] タブで確認できます。
一般公開データセットに対してクエリを実行する
次の手順では、citibike_trips テーブルに対してクエリを実行し、NYC Citi Bike Trips 一般公開データセットで最も人気のある Citi Bike ステーション 100 か所を特定します。このクエリは、ステーションの名前と場所、そのステーションから開始された乗車回数を取得します。
このクエリでは、ST_GEOGPOINT 関数を使用して、各ステーションの経度と緯度のパラメータからポイントを作成し、そのポイントを GEOGRAPHY 列に含めて返します。GEOGRAPHY 列は、統合された地理データビューアでヒートマップを生成するために使用されます。
Google Cloud コンソールで、[BigQuery] ページを開きます。
[
SQL クエリ ] をクリックします。クエリエディタ で、次のクエリを入力します。SELECT start_station_name, start_station_latitude, start_station_longitude, ST_GEOGPOINT(start_station_longitude, start_station_latitude) AS geo_location, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY 1, 2, 3 ORDER BY num_trips DESC LIMIT 100;クエリが有効な場合は、クエリによって処理されるデータの量とともにチェックマークが表示されます。クエリが無効な場合は、感嘆符がエラー メッセージとともに表示されます。

[
実行 ] をクリックします。最も人気のある駅が [クエリ結果 ] セクションに表示されます。
省略可: ジョブの期間とクエリジョブで処理されたデータの量を表示するには、[クエリ結果] セクションの [ジョブ情報] タブをクリックします。
[
ビジュアリゼーション ] タブに切り替えます。このタブでは、結果をすばやく可視化するための地図が生成されます。[可視化の構成] パネルで、次の操作を行います。
- [可視化タイプ] が [マップ] に設定されていることを確認します。
- [地域列] が [
geo_location] に設定されていることを確認します。 - [DATA 列] で [
num_trips] を選択します。 - [ズームイン] オプションを使用して、マンハッタンの地図を表示します。
![[ビジュアリゼーション] タブで生成されたヒートマップ](https://cloud.google.com/static/bigquery/images/query-visualization-ui.png?hl=ja)
BigQuery サンドボックスからアップグレードする
BigQuery サンドボックスを使用すると、一部の BigQuery 機能を費用なしで利用して、BigQuery を試すことができます。ストレージとクエリの機能を増やす準備が整ったら、BigQuery サンドボックスからアップグレードします。
アップグレードする手順は次のとおりです。
プロジェクトに対する課金を有効にします。
BigQuery の各エディションを確認して、最適な料金モデルを決定します。
BigQuery サンドボックスからアップグレードしたら、テーブル、ビュー、パーティションなどの BigQuery リソースのデフォルトの有効期限を更新する必要があります。
クリーンアップ
このページで使用したリソースについて、 Google Cloud アカウントに課金されないようにするには、次の手順を実施します。
プロジェクトを削除する
BigQuery サンドボックスを使用して一般公開データセットをクエリした場合、そのプロジェクトでは課金は有効になっていないため、プロジェクトを削除する必要はありません。
課金をなくす最も簡単な方法は、チュートリアル用に作成したプロジェクトを削除することです。
プロジェクトを削除するには:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
次のステップ
- 無料枠で BigQuery を費用なしで使用する方法については、無料枠をご覧ください。
- BigQuery でデータセットを作成し、データを読み込み、テーブルに対してクエリを実行する方法を学習する。