このチュートリアルでは、BigQuery ML の K 平均法モデルを使用して、データセット内のクラスタを識別する方法について説明します。
データをクラスタにグループ化する K 平均法アルゴリズムは、教師なし機械学習の一種です。教師あり機械学習が予測分析を目的としているのとは異なり、教師なし機械学習では記述分析が目的となります。教師なし機械学習は、データを理解してデータドリブンの意思決定を行うのに役立ちます。
このチュートリアルのクエリでは、地理空間分析で使用できる地理関数を使用します。詳細については、地理空間分析の概要をご覧ください。
このチュートリアルでは、ロンドンのレンタル自転車の一般公開データセットを使用します。また、開始時と停止時のタイムスタンプ、ステーション名、乗車時間も含まれます。
目標
このチュートリアルでは、次のタスクの手順について説明します。- モデルのトレーニングに使用されたデータを調べます。
- K 平均法クラスタリング モデルの作成
- BigQuery ML のクラスタの可視化を使用して、生成されたデータクラスタを解釈します。
- K 平均法モデルで
ML.PREDICT関数を実行して、自転車レンタル ステーションのクラスタを予測します。
料金
このチュートリアルでは、 Google Cloudの課金対象コンポーネントを使用します。これには次のコンポーネントが含まれます。
- BigQuery
- BigQuery ML
BigQuery の費用の詳細については、BigQuery の料金ページをご覧ください。
BigQuery ML の費用については、BigQuery ML の料金をご覧ください。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- 新しいプロジェクトでは、BigQuery が自動的に有効になります。既存のプロジェクトで BigQuery を有効にするには、
Enable the BigQuery API.
に移動します。
必要な権限
データセットを作成するには、
bigquery.datasets.createIAM 権限が必要です。モデルを作成するには、次の権限が必要です。
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
推論を実行するには、次の権限が必要です。
bigquery.models.getDatabigquery.jobs.create
BigQuery における IAM ロールと権限の詳細については、IAM の概要をご覧ください。
データセットを作成する
k-means モデルを保存する BigQuery データセットを作成します。
Google Cloud コンソールで [BigQuery] ページに移動します。
[エクスプローラ] ペインで、プロジェクト名をクリックします。
「アクションを表示」> [データセットを作成] をクリックします。

[データセットを作成する] ページで、次の操作を行います。
[データセット ID] に
bqml_tutorialを入力します。[ロケーション タイプ] で、[マルチリージョン] を選択し、[EU(欧州連合の複数のリージョン)] を選択します。
ロンドンのレンタル自転車の一般公開データセットは、
EUマルチリージョンロケーションに格納されています。データセットも同じロケーションに存在する必要があります。残りのデフォルトの設定は変更せず、[データセットを作成] をクリックします。

トレーニング データを調べる
K 平均法モデルのトレーニングに使用するデータを調べます。このチュートリアルでは、以下の属性に基づいて自転車ステーションのクラスタリングを行います。
- レンタル期間
- 1 日あたりの利用数
- 市中心部からの距離
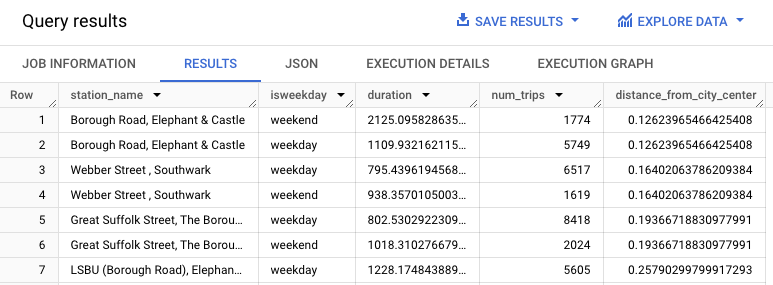
このクエリは、start_station_name 列と duration 列を含む自転車レンタルのデータを抽出し、このデータをステーション情報に結合します。これには、市の中心部からの駅までの距離を含む計算列を作成することが含まれます。そして、平均乗車時間と利用数を含んだ stationstats 列でステーションの属性を計算します。この計算には、計算された distance_from_city_center 列も含まれます。
トレーニング データを調べる手順は次のとおりです。
Google Cloud コンソールで [BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * FROM stationstats ORDER BY distance_from_city_center ASC;
結果は次のようになります。
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
K 平均法モデルを作成する
ロンドンのレンタル自転車のトレーニング データを使用して K 平均法モデルを作成します。
次のクエリでは、CREATE MODEL ステートメントで使用するクラスタの数(4)を指定します。SELECT ステートメントの EXCEPT 句は、この列に特徴が含まれていないため、station_name 列を除外します。このクエリでは、station_name ごとに一意の行が作成され、SELECT ステートメントには特徴のみが指定されます。
K 平均法モデルを作成する手順は次のとおりです。
Google Cloud コンソールで [BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
CREATE OR REPLACE MODEL `bqml_tutorial.london_station_clusters` OPTIONS ( model_type = 'kmeans', num_clusters = 4) AS WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * EXCEPT (station_name, isweekday) FROM stationstats;
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
データクラスタを解釈する
モデルの [評価] タブの情報は、モデルによって生成されたクラスタを解釈するのに役立ちます。
モデルの評価情報を表示する手順は次のとおりです。
Google Cloud コンソールで [BigQuery] ページに移動します。
[エクスプローラ] ペインでプロジェクトを開き、
bqml_tutorialデータセットを開き、[モデル] フォルダを開きます。london_station_clustersモデルを選択します。[評価] タブを選択します。このタブには、K 平均法モデルによって識別されたクラスタが可視化されます。[数値特徴] セクションの棒グラフには、各セントロイドの最も重要な数値特徴値が表示されます。各セントロイドは、特定のデータクラスタを表します。可視化する特徴をプルダウン メニューから選択できます。
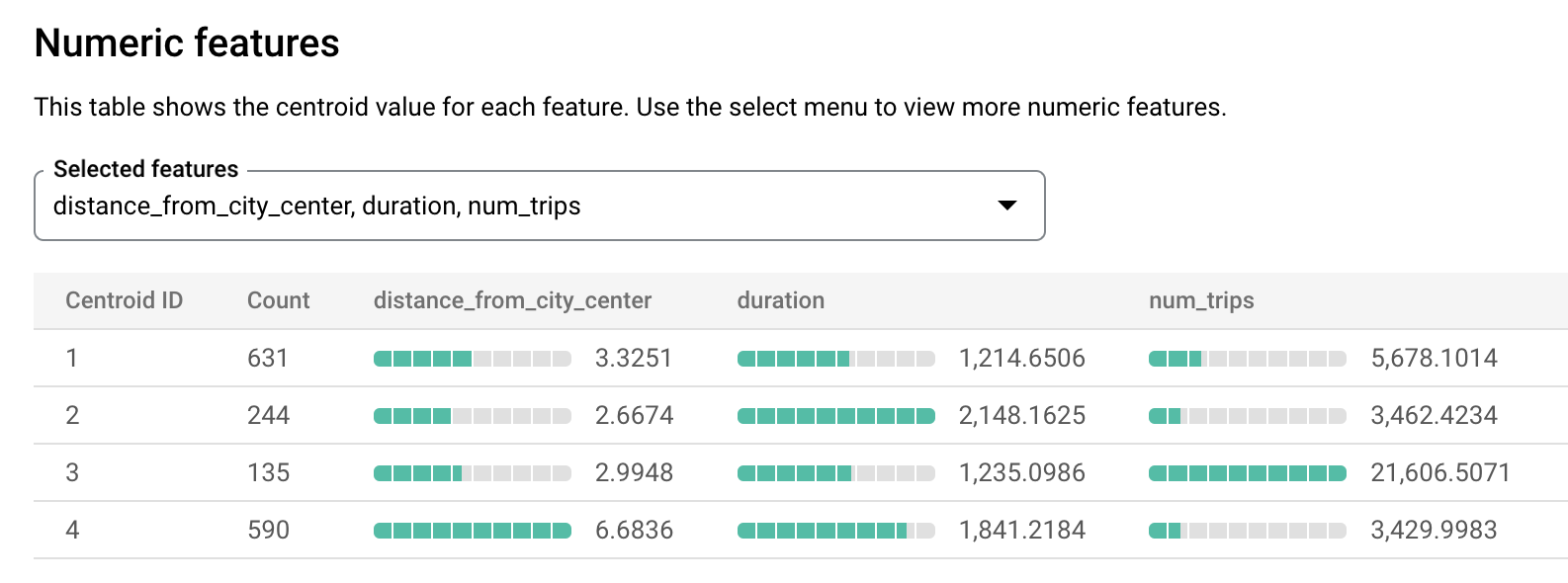
このモデルでは、次の重心が作成されます。
- セントロイド 1 は、あまり混雑しておらず、レンタル期間が短い都市ステーションを示しています。
- セントロイド 2 は、あまり混雑しておらずレンタル使用期間が長い、2 番目の都市ステーションを示しています。
- セントロイド 3 は、市内中心部に近い混雑している都市ステーションを示しています。
- セントロイド 4 は、移動がより長い郊外のステーションを示しています。
自転車レンタル事業を運営している場合は、この情報を使用してビジネス上の意思決定を行うことができます。次に例を示します。
新しいタイプの鍵を試す必要があるとします。実験の対象には、どのクラスタのステーションを選択すればいいでしょうか。セントロイド 1、セントロイド 2、またはセントロイド 4 のステーションは最も混雑しているステーションではないので、論理的に言ってこれらを選択するのがよいでしょう。
長距離用の自転車をいくつかのステーションに置いてみたいと考えているとします。どのステーションが適しているでしょうか。セントロイド 4 は、市内中心部から離れた場所にあるステーションのグループで、最も長い利用になっています。したがって、長距離用の自転車を置くには最も適したステーションと思われます。
ML.PREDICT 関数を使用してステーションのクラスタを予測する
ML.PREDICT SQL 関数または predict BigQuery DataFrames 関数を使用して、特定のステーションが属するクラスタを特定します。
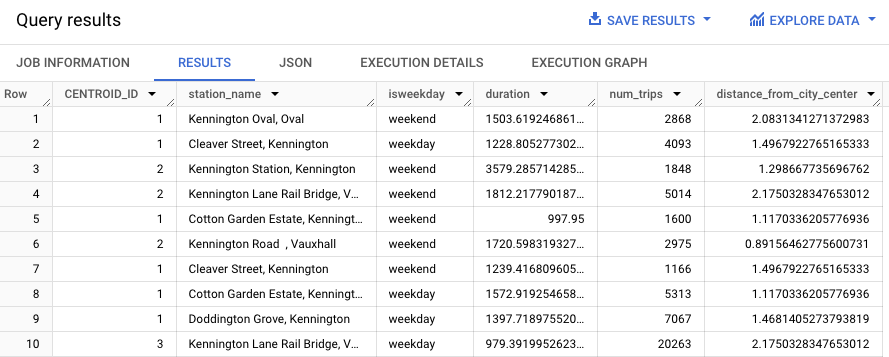
次のクエリは REGEXP_CONTAINS 関数を使用して、station_name 列に文字列 Kennington を含むすべてのエントリを検索します。ML.PREDICT 関数は、これらの値を使用して、どのクラスタにステーションが含まれるかを予測します。
次の手順で、名前に Kennington という文字列を含むすべてのステーションのクラスタを予測します。
Google Cloud コンソールで [BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * EXCEPT (nearest_centroids_distance) FROM ML.PREDICT( MODEL `bqml_tutorial.london_station_clusters`, ( SELECT * FROM stationstats WHERE REGEXP_CONTAINS(station_name, 'Kennington') ));
結果は次のようになります。
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
クリーンアップ
このチュートリアルで使用したリソースについて、Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
- 作成したプロジェクトを削除する。
- または、プロジェクトを保存して、データセットを削除する。
データセットを削除する
プロジェクトを削除すると、プロジェクト内のデータセットとテーブルがすべて削除されます。プロジェクトを再利用する場合は、このチュートリアルで作成したデータセットを削除できます。
必要に応じて、Google Cloud コンソールで [BigQuery] ページを開きます。
ナビゲーションで、作成した bqml_tutorial データセットをクリックします。
ウィンドウの右側にある [データセットを削除] をクリックします。この操作を行うと、データセットとモデルが削除されます。
[データセットの削除] ダイアログ ボックスでデータセットの名前(
bqml_tutorial)を入力し、[削除] をクリックして確定します。
プロジェクトの削除
プロジェクトを削除するには:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
次のステップ
- BigQuery ML の概要で BigQuery ML の概要を確認する。
CREATE MODEL構文ページでモデルの作成方法を確認する。