In diesem Dokument wird ein Beispiel für eine in Google Cloud implementierte Pipeline beschrieben, die eine Neigungsmodellierung ausführt. Es richtet sich an Data Engineers, Machine Learning Engineers oder Marketing Science-Teams, die Modelle für maschinelles Lernen erstellen und bereitstellen. In diesem Dokument wird davon ausgegangen, dass Sie mit den Konzepten für maschinelles Lernen vertraut sind und mit Google Cloud, BigQuery, Kubeflow Pipelines, Python und Jupyter Notebooks vertraut sind. Außerdem werden Vorkenntnisse zu Google Analytics 360 und der Rohexportfunktion von BigQuery vorausgesetzt.
Die von Ihnen verwendete Pipeline verwendet Google Analytics-Beispieldaten. Die Pipeline erstellt mithilfe von BigQuery ML und XGBoost mehrere Modelle und führt die Pipeline mithilfe von Kubeflow Pipelines in Vertex AI Pipelines aus. In diesem Dokument wird beschrieben, wie Sie Modelle trainieren, bewerten und bereitstellen. Außerdem wird beschrieben, wie Sie den gesamten Prozess automatisieren können.
Der vollständige Pipelinecode befindet sich in einem Jupyter-Notebook in einem GitHub-Repository.
Was ist eine Neigungsmodellierung?
Mithilfe der Neigungsmodellierung werden Aktionen vorhergesagt, die ein Nutzer ausführen könnte. Beispiele für Neigungsmodellierungen umfassen Vorhersagen, welche Nutzer wahrscheinlich ein Produkt kaufen, sich für einen Dienst registrieren oder sogar abwandern und nicht mehr aktiver Kunde einer Marke sind.
Die Ausgabe eines Neigungsmodells ist ein Wert zwischen 0 und 1 für jeden Nutzer, wobei dieser Wert angibt, wie wahrscheinlich der Nutzer diese Aktion ausführt. Einer der Hauptfaktoren, die Unternehmen zur Neigungsmodellierung vorantreiben, ist die Notwendigkeit, mehr mit eigenen Daten zu tun. Für Marketinganwendungsfälle sind unter anderem Signale aus Online- und Offlinequellen wie Website-Analysen und CRM-Daten geeignet.
In dieser Demo werden GA360-Beispieldaten aus BigQuery verwendet. Für Ihren Anwendungsfall sollten Sie zusätzliche Offlinesignale berücksichtigen.
MLOps vereinfacht Ihre ML-Pipelines
Die meisten ML-Modelle werden nicht in der Produktion verwendet. Modellergebnisse liefern Informationen. Häufig muss ein ML-Engineering- oder Software Engineering-Team ein Modell mit einem Framework wie Flask oder FastAPI für die Produktion codieren, nachdem sie es fertiggestellt haben. Dabei muss das Modell häufig in einem neuen Framework erstellt werden. Dies bedeutet, dass die Daten neu transformiert werden müssen. Diese Arbeit kann Wochen oder Monate dauern und viele Modelle kommen daher nicht in die Produktion.
MLOps (ML-Vorgänge) sind wichtig, um von ML-Projekten und MLOps einen Nutzen zu erzielen, und sind mittlerweile ein wachsendes Know-how für Data-Science-Organisationen. Damit Unternehmen diesen Wert besser verstehen, hat Google Cloud einen Leitfaden für MLOps mit MLOps veröffentlicht.
Mithilfe der MLOps-Prinzipien und Google Cloud können Sie Modelle mithilfe eines automatischen Prozesses an einen Endpunkt übertragen, der den Komplexität des manuellen Prozesses erheblich erschwert. Die in diesem Dokument beschriebenen Tools und Prozesse zeigen einen Ansatz für einen Inhaber der Pipeline von Anfang bis Ende. Damit können Sie Ihre Modelle in die Produktion bringen. Im zuvor erwähnten Leitfaden für die Verarbeiter erhalten Sie eine horizontale Lösung und eine Übersicht über die Möglichkeiten, die sich durch MLOps und Google Cloud ergeben.
Was ist Kubeflow Pipelines und was ist Vertex AI?
Kubeflow-Pipelines ist ein Open-Source-Framework, mit dem Sie Ihre Pipeline erstellen.
Jeder Schritt im Kubeflow Pipelines-Prozess besteht aus einem unabhängigen Container, der Eingaben machen oder Ausgaben in Form von Artefakten erzeugen kann. Wenn Ihr Dataset beispielsweise in einem Schritt erstellt wird, ist die Ausgabe das Dataset-Artefakt. Dieses Dataset-Artefakt kann als Eingabe für den nächsten Schritt verwendet werden. Da jede Komponente ein separater Container ist, müssen Sie Informationen für jede Komponente der Pipeline angeben, z. B. den Namen des Basis-Images und eine Liste aller Abhängigkeiten.
Mit Vertex AI Pipelines können Sie Pipelines ausführen, die entweder mit Kubeflow Pipelines oder TensorFlow Extended (TFX) erstellt wurden. Ohne Vertex AI müssen Sie eigene Kubernetes-Cluster einrichten und verwalten, wenn Sie eines dieser Open-Source-Frameworks im großen Maßstab ausführen. Vertex AI Pipelines löst diese Herausforderung. Da es sich um einen verwalteten Dienst handelt, wird er nach Bedarf hoch- oder herunterskaliert und erfordert keine laufende Wartung.
Der Build-Prozess der Pipeline
Im in diesem Dokument beschriebenen Beispiel wird ein Juptyer-Notebook verwendet, um die Pipelinekomponenten zu erstellen und sie zu kompilieren, auszuführen und zu automatisieren. Wie bereits erwähnt, befindet sich das Notebook in einem GitHub-Repository.
Sie können den Notebookcode mit einer nutzerverwalteten Notebook-Instanz von Vertex AI Workbench ausführen, die die Authentifizierung für Sie übernimmt. Mit Vertex AI Workbench können Sie mit Notebooks arbeiten, um Maschinen zu erstellen, Notebooks zu erstellen und eine Verbindung zu Git herzustellen. (Vertex AI Workbench bietet viele weitere Features, die in diesem Dokument jedoch nicht behandelt werden.)
Wenn die Pipelineausführung abgeschlossen ist, wird in Vertex AI Pipelines ein Diagramm ähnlich dem folgenden generiert:
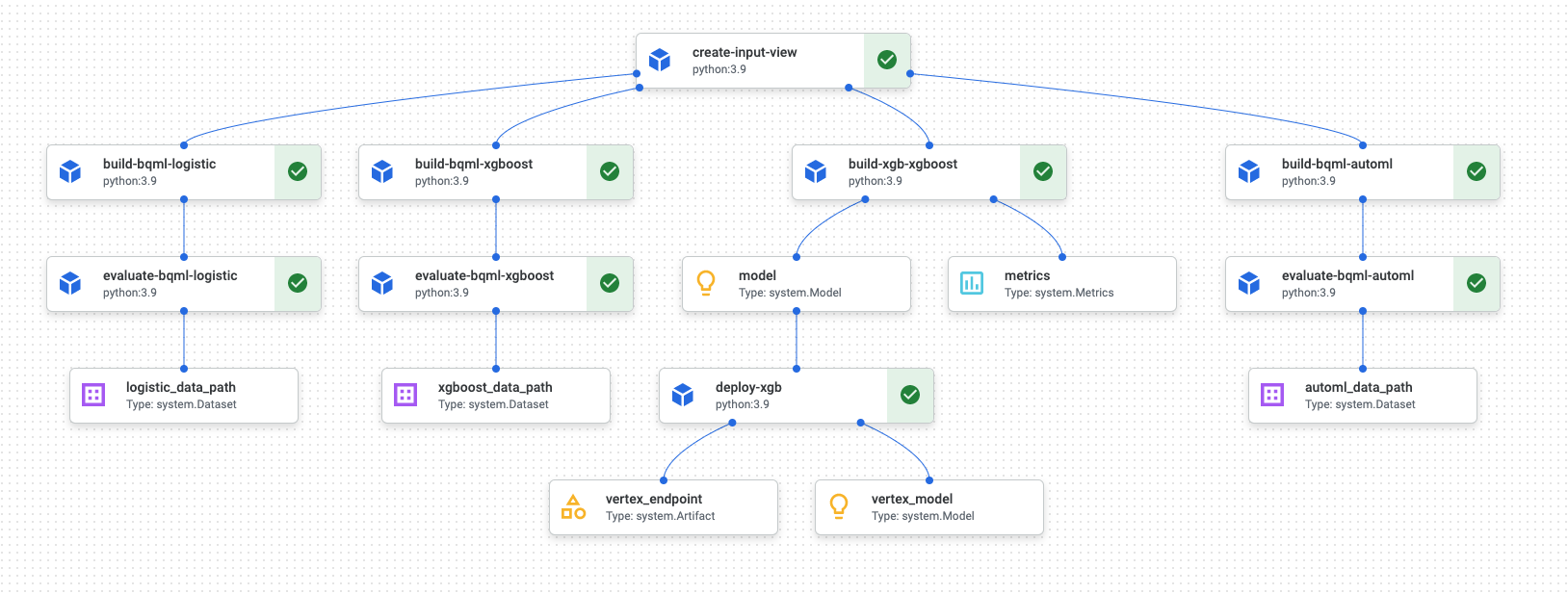
Das obige Diagramm ist ein gerichteter azyklischer Graph (DAG). Das Erstellen und Prüfen des DAG ist ein zentraler Schritt zum Verständnis Ihrer Daten- oder ML-Pipeline. Die Hauptattribute von DAGs sind, dass Komponenten in eine Richtung weisen (in diesem Fall von oben nach unten) und kein Zyklus auftritt, das heißt, dass eine übergeordnete Komponente nicht auf ihrer untergeordneten Komponente beruht. Einige Komponenten können parallel ausgeführt werden, während andere Abhängigkeiten haben und daher in Reihe auftreten.
Das grüne Kästchen in jeder Komponente gibt an, dass der Code ordnungsgemäß ausgeführt wurde. Wenn Fehler aufgetreten sind, wird ein rotes Ausrufezeichen angezeigt. Sie können auf jede Komponente im Diagramm klicken, um weitere Details des Jobs aufzurufen.
Das DAG-Diagramm ist in diesem Abschnitt des Dokuments enthalten, das als Vorlage für jede Komponente dient, die von der Pipeline erstellt wird. Die folgende Liste enthält eine Beschreibung jeder Komponente:
Die vollständige Pipeline führt die folgenden Schritte aus, wie im DAG-Diagramm dargestellt:
create-input-view: Diese Komponente erstellt eine BigQuery-Ansicht. Die Komponente kopiert SQL aus einem Cloud Storage-Bucket und füllt die von Ihnen angegebenen Parameterwerte aus. Diese BigQuery-Ansicht ist das Eingabe-Dataset, das für alle Modelle später in der Pipeline verwendet wird.build-bqml-logistic: Die Pipeline verwendet BigQuery ML, um ein logistisches Regressionsmodell zu erstellen. Nach Abschluss dieser Komponente kann ein neues Modell in der BigQuery Console angezeigt werden. Mit diesem Modellobjekt können Sie die Modellleistung anzeigen und später Vorhersagen erstellen.evaluate-bqml-logistic: Die Pipeline verwendet diese Komponente, um eine Genauigkeits-/Trefferquotenkurve (logistic_data_pathim DAG-Diagramm) für die logistische Regression zu erstellen. Dieses Artefakt wird in einem Cloud Storage-Bucket gespeichert.build-bqml-xgboost: Diese Komponente erstellt ein XGBoost-Modell mit BigQuery ML. Wenn diese Komponente abgeschlossen ist, können Sie ein neues Modellobjekt (system.Model) in der BigQuery-Konsole aufrufen. Mit diesem Objekt können Sie die Modellleistung anzeigen und später Vorhersagen erstellen.evaluate-bqml-xgboost: Diese Komponente erstellt eine Genauigkeits-/Trefferquotenkurve mit dem Namenxgboost_data_pathfür das XGBoost-Modell. Dieses Artefakt wird in einem Cloud Storage-Bucket gespeichert.build-xgb-xgboost: Die Pipeline erstellt ein XGBoost-Modell. Diese Komponente verwendet Python anstelle von BigQuery ML, damit Sie verschiedene Ansätze zum Erstellen des Modells sehen können. Wenn diese Komponente abgeschlossen ist, speichert sie ein Modellobjekt und Leistungsmesswerte in einem Cloud Storage-Bucket.deploy-xgb: Diese Komponente stellt das XGBoost-Modell bereit. Es wird ein Endpunkt erstellt, der entweder Batch- oder Onlinevorhersagen zulässt. Sie können den Endpunkt auf der Seite der Vertex AI Console auf dem Tab Modelle untersuchen. Der Endpunkt wird automatisch entsprechend dem Traffic skaliert.build-bqml-automl: Die Pipeline erstellt mithilfe von BigQuery ML ein AutoML-Modell. Wenn diese Komponente abgeschlossen ist, kann ein neues Modellobjekt in der BigQuery Console angezeigt werden. Mit diesem Objekt können Sie die Modellleistung anzeigen und später Vorhersagen erstellen.evaluate-bqml-automl: Die Pipeline erstellt eine Genauigkeits-/Trefferquotenkurve für das AutoML-Modell. Das Artefakt wird in einem Cloud Storage-Bucket gespeichert.
Beachten Sie, dass der Prozess die BigQuery ML-Modelle nicht an einen Endpunkt überträgt. Das liegt daran, dass Sie Vorhersagen direkt aus dem Modellobjekt in BigQuery generieren können. Berücksichtigen Sie bei der Entscheidung, ob Sie BigQuery ML und andere Bibliotheken für Ihre Lösung verwenden, wie Vorhersagen generiert werden müssen. Wenn eine tägliche Batchvorhersage Ihre Anforderungen erfüllt, kann das Verlassen der BigQuery-Umgebung Ihren Workflow vereinfachen. Wenn Sie jedoch Echtzeitvorhersagen benötigen oder wenn Ihr Szenario Funktionen benötigt, die sich in einer anderen Bibliothek befinden, führen Sie die Schritte in diesem Dokument aus, um das gespeicherte Modell an einen Endpunkt zu übertragen.
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Hinweis
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
Das Jupyter-Notebook für dieses Szenario
Die Aufgaben zum Erstellen und Erstellen der Pipeline sind in ein Jupyter-Notebook eingebunden, das sich in einem GitHub-Repository befindet.
Zum Ausführen der Aufgaben rufen Sie das Notebook ab und führen dann die Codezellen im Notebook in der angegebenen Reihenfolge aus. Der in diesem Dokument beschriebene Ablauf setzt voraus, dass Sie die Notebooks in Vertex AI Workbench ausführen.
Vertex AI Workbench-Umgebung öffnen
Zuerst klonen Sie das GitHub-Repository in eine Vertex AI Workbench-Umgebung.
- Wählen Sie in der Google Cloud Console das Projekt aus, in dem Sie das Notebook erstellen möchten.
Rufen Sie die Seite Vertex AI Workbench auf.
Rufen Sie die Seite Vertex AI Workbench auf.
Klicken Sie auf dem Tab Nutzerverwaltete Notebooks auf Neues Notebook.
Wählen Sie in der Liste der Notebooktypen ein Python 3-Notebook aus.
Klicken Sie im Dialogfeld Neues Notebook auf Erweiterte Optionen und wählen Sie dann unter Maschinentyp den Maschinentyp aus, den Sie verwenden möchten. Wählen Sie n1-standard-1 (1 cVPU, 3,75 GB RAM) aus, wenn Sie sich nicht sicher sind.
Klicken Sie auf Erstellen.
Das Erstellen der Notebook-Umgebung dauert einen Moment.
Wählen Sie das Notebook aus und klicken Sie auf Jupyterlab öffnen, nachdem das Notebook erstellt wurde.
Die JupyterLab-Umgebung wird im Browser geöffnet.
Wählen Sie zum Starten eines Terminal-Tabs Datei > Neu > Launcher aus.
Klicken Sie auf dem Tab Launcher auf das Symbol Terminal.
Klonen Sie im Terminal das GitHub-Repository
mlops-on-gcp:git clone https://github.com/GoogleCloudPlatform/cloud-for-marketing/
Wenn der Befehl ausgeführt ist, wird der Ordner
cloud-for-marketingim Dateibrowser angezeigt.
Notebook-Einstellungen konfigurieren
Bevor Sie das Notebook ausführen, müssen Sie es konfigurieren. Das Notebook benötigt einen Cloud Storage-Bucket, um Pipelineartefakte zu speichern. Erstellen Sie also zuerst diesen Bucket.
- Erstellen Sie einen Cloud Storage-Bucket, in dem das Notebook Pipelineartefakte speichern kann. Der Name des Buckets muss global eindeutig sein.
- Öffnen Sie im Ordner
cloud-for-marketing/marketing-analytics/predicting/kfp_pipeline/das NotebookPropensity_Pipeline.ipynb. - Legen Sie im Notebook den Wert der Variable
PROJECT_IDauf die ID des Google Cloud-Projekts fest, in dem Sie die Pipeline ausführen möchten. - Legen Sie den Wert der Variable
BUCKET_NAMEauf den Namen des Buckets fest, den Sie gerade erstellt haben.
Im weiteren Verlauf dieses Dokuments werden Code-Snippets beschrieben, die zum Verständnis der Funktionsweise der Pipeline wichtig sind. Die vollständige Implementierung finden Sie im GitHub-Repository.
BigQuery-Ansicht erstellen
Der erste Schritt in der Pipeline generiert die Eingabedaten, die zum Erstellen der einzelnen Modelle verwendet werden. Diese Kubeflow Pipelines-Komponente generiert eine BigQuery-Ansicht. Um das Erstellen der Ansicht zu vereinfachen, wurden einige SQL-Dateien bereits generiert und in einer Textdatei in GitHub gespeichert.
Der Code für jede Komponente beginnt mit der Dekoration (Änderung einer übergeordneten Klasse oder Funktion über Attribute) der Kubeflow Pipelines-Komponentenklasse. Der Code definiert dann die Funktion create_input_view, die ein Schritt in der Pipeline ist.
Für die Funktion sind mehrere Eingaben erforderlich. Einige dieser Werte sind derzeit fest im Code codiert, z. B. das Startdatum und Enddatum. Wenn Sie Ihre Pipeline automatisieren, können Sie den Code so ändern, dass geeignete Werte verwendet werden, z. B. mit der Funktion CURRENT_DATE für ein Datum. Alternativ können Sie die Komponente aktualisieren, um diese Werte als Parameter zu verwenden, anstatt sie hart zu codieren. Sie müssen auch den Wert von ga_data_ref in den Namen Ihrer GA360-Tabelle ändern und den Wert der conversion-Variable auf Ihre Konvertierung setzen. In diesem Beispiel werden die öffentlichen GA360-Beispieldaten verwendet.
Die folgende Auflistung zeigt den Code für die Komponente create-input-view.
@component(
# this component builds a BigQuery view, which will be the underlying source for model
packages_to_install=["google-cloud-bigquery", "google-cloud-storage"],
base_image="python:3.9",
output_component_file="output_component/create_input_view.yaml",
)
def create_input_view(view_name: str,
data_set_id: str,
project_id: str,
bucket_name: str,
blob_path: str
):
from google.cloud import bigquery
from google.cloud import storage
client = bigquery.Client(project=project_id)
dataset = client.dataset(data_set_id)
table_ref = dataset.table(view_name)
ga_data_ref = 'bigquery-public-data.google_analytics_sample.ga_sessions_*'
conversion = "hits.page.pageTitle like '%Shopping Cart%'"
start_date = '20170101'
end_date = '20170131'
def get_sql(bucket_name, blob_path):
from google.cloud import storage
storage_client = storage.Client()
bucket = storage_client.get_bucket(bucket_name)
blob = bucket.get_blob(blob_path)
content = blob.download_as_string()
return content
def if_tbl_exists(client, table_ref):
...
else:
content = get_sql()
content = str(content, 'utf-8')
create_base_feature_set_query = content.
format(start_date = start_date,
end_date = end_date,
ga_data_ref = ga_data_ref,
conversion = conversion)
shared_dataset_ref = client.dataset(data_set_id)
base_feature_set_view_ref = shared_dataset_ref.table(view_name)
base_feature_set_view = bigquery.Table(base_feature_set_view_ref)
base_feature_set_view.view_query = create_base_feature_set_query.format(project_id)
base_feature_set_view = client.create_table(base_feature_set_view)
BigQuery ML-Modell erstellen
Nachdem die Ansicht erstellt wurde, führen Sie die Komponente namens build_bqml_logistic aus, um ein BigQuery ML-Modell zu erstellen. Dieser Block des Notebooks ist eine Kernkomponente. Mithilfe der Trainingsansicht, die Sie im ersten Block erstellt haben, wird ein BigQuery ML-Modell erstellt. In diesem Beispiel verwendet das Notebook die logistische Regression.
Informationen zu Modelltypen und den verfügbaren Hyperparametern finden Sie in der Referenzdokumentation zu BigQuery ML.
In der folgenden Liste wird der Code für diese Komponente aufgeführt.
@component(
# this component builds a logistic regression with BigQuery ML
packages_to_install=["google-cloud-bigquery"],
base_image="python:3.9",
output_component_file="output_component/create_bqml_model_logistic.yaml"
)
def build_bqml_logistic(project_id: str,
data_set_id: str,
model_name: str,
training_view: str
):
from google.cloud import bigquery
client = bigquery.Client(project=project_id)
model_name = f"{project_id}.{data_set_id}.{model_name}"
training_set = f"{project_id}.{data_set_id}.{training_view}"
build_model_query_bqml_logistic = '''
CREATE OR REPLACE MODEL `{model_name}`
OPTIONS(model_type='logistic_reg'
, INPUT_LABEL_COLS = ['label']
, L1_REG = 1
, DATA_SPLIT_METHOD = 'RANDOM'
, DATA_SPLIT_EVAL_FRACTION = 0.20
) AS
SELECT * EXCEPT (fullVisitorId, label),
CASE WHEN label is null then 0 ELSE label end as label
FROM `{training_set}`
'''.format(model_name = model_name, training_set = training_set)
job_config = bigquery.QueryJobConfig()
client.query(build_model_query_bqml_logistic, job_config=job_config)
XGBoost anstelle von BigQuery ML verwenden
Die im vorherigen Abschnitt dargestellte Komponente verwendet BigQuery ML. Im nächsten Abschnitt der Notebooks erfahren Sie, wie Sie XGBoost direkt in Python anstelle von BigQuery ML verwenden.
Sie führen die Komponente mit dem Namen build_bqml_xgboost aus, um die Komponente zu erstellen, um ein Standard-XGBoost-Klassifizierungsmodell mit einer Grid-Suche auszuführen. Der Code speichert dann das Modell als Artefakt im von Ihnen erstellten Cloud Storage-Bucket.
Die Funktion unterstützt zusätzliche Parameter (metrics und model) für Ausgabeartefakte. Diese Parameter werden von Kubeflow Pipelines benötigt.
@component(
# this component builds an xgboost classifier with xgboost
packages_to_install=["google-cloud-bigquery", "xgboost", "pandas", "sklearn", "joblib", "pyarrow"],
base_image="python:3.9",
output_component_file="output_component/create_xgb_model_xgboost.yaml"
)
def build_xgb_xgboost(project_id: str,
data_set_id: str,
training_view: str,
metrics: Output[Metrics],
model: Output[Model]
):
...
data_set = f"{project_id}.{data_set_id}.{training_view}"
build_df_for_xgboost = '''
SELECT * FROM `{data_set}`
'''.format(data_set = data_set)
...
xgb_model = XGBClassifier(n_estimators=50,
objective='binary:hinge',
silent=True,
nthread=1,
eval_metric="auc")
random_search = RandomizedSearchCV(xgb_model,
param_distributions=params,
n_iter=param_comb,
scoring='precision',
n_jobs=4,
cv=skf.split(X_train,y_train),
verbose=3,
random_state=1001 )
random_search.fit(X_train, y_train)
xgb_model_best = random_search.best_estimator_
predictions = xgb_model_best.predict(X_test)
score = accuracy_score(y_test, predictions)
auc = roc_auc_score(y_test, predictions)
precision_recall = precision_recall_curve(y_test, predictions)
metrics.log_metric("accuracy",(score * 100.0))
metrics.log_metric("framework", "xgboost")
metrics.log_metric("dataset_size", len(df))
metrics.log_metric("AUC", auc)
dump(xgb_model_best, model.path + ".joblib")
Endpunkt erstellen
Sie führen die Komponente deploy_xgb aus, um einen Endpunkt mit dem XGBoost-Modell aus dem vorherigen Abschnitt zu erstellen. Die Komponente verwendet das vorherige XGBoost-Modellartefakt, erstellt einen Container und stellt dann den Endpunkt bereit. Außerdem stellt es die Endpunkt-URL als Artefakt bereit, damit Sie es aufrufen können. Nach Abschluss dieses Schritts wurde ein Vertex AI-Endpunkt erstellt, und Sie können den Endpunkt auf der Konsolenseite für Vertex AI sehen.
@component(
# Deploys xgboost model
packages_to_install=["google-cloud-aiplatform", "joblib", "sklearn", "xgboost"],
base_image="python:3.9",
output_component_file="output_component/xgboost_deploy_component.yaml",
)
def deploy_xgb(
model: Input[Model],
project_id: str,
vertex_endpoint: Output[Artifact],
vertex_model: Output[Model]
):
from google.cloud import aiplatform
aiplatform.init(project=project_id)
deployed_model = aiplatform.Model.upload(
display_name="tai-propensity-test-pipeline",
artifact_uri = model.uri.replace("model", ""),
serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/xgboost-cpu.1-4:latest"
)
endpoint = deployed_model.deploy(machine_type="n1-standard-4")
# Save data to the output params
vertex_endpoint.uri = endpoint.resource_name
vertex_model.uri = deployed_model.resource_name
Pipeline definieren
Um die Pipeline zu definieren, definieren Sie jeden Vorgang anhand der zuvor erstellten Komponenten. Anschließend können Sie die Reihenfolge der Pipeline-Elemente angeben, wenn diese nicht explizit in der Komponente aufgerufen werden.
Der folgende Code im Notebook definiert beispielsweise eine Pipeline. In diesem Fall erfordert der Code, dass die Komponente build_bqml_logistic_op nach der Komponente create_input_view_op ausgeführt wird.
@dsl.pipeline(
# Default pipeline root. You can override it when submitting the pipeline.
pipeline_root=PIPELINE_ROOT,
# A name for the pipeline.
name="pipeline-test",
description='Propensity BigQuery ML Test'
)
def pipeline():
create_input_view_op = create_input_view(
view_name = VIEW_NAME,
data_set_id = DATA_SET_ID,
project_id = PROJECT_ID,
bucket_name = BUCKET_NAME,
blob_path = BLOB_PATH
)
build_bqml_logistic_op = build_bqml_logistic(
project_id = PROJECT_ID,
data_set_id = DATA_SET_ID,
model_name = 'bqml_logistic_model',
training_view = VIEW_NAME
)
# several components have been deleted for brevity
build_bqml_logistic_op.after(create_input_view_op)
build_bqml_xgboost_op.after(create_input_view_op)
build_bqml_automl_op.after(create_input_view_op)
build_xgb_xgboost_op.after(create_input_view_op)
evaluate_bqml_logistic_op.after(build_bqml_logistic_op)
evaluate_bqml_xgboost_op.after(build_bqml_xgboost_op)
evaluate_bqml_automl_op.after(build_bqml_automl_op)
Pipeline kompilieren und ausführen
Sie können jetzt die Pipeline kompilieren und ausführen.
Der folgende Code im Notebook legt den Wert enable_caching auf "true" fest, um das Caching zu aktivieren. Wenn das Caching aktiviert ist, werden alle vorherigen Ausführungen, in denen eine Komponente erfolgreich abgeschlossen wurde, nicht noch einmal ausgeführt. Dieses Flag ist insbesondere beim Testen der Pipeline nützlich, da die Ausführung bei aktiviertem Caching schneller abgeschlossen wird und weniger Ressourcen benötigt.
compiler.Compiler().compile(
pipeline_func=pipeline, package_path="pipeline.json"
)
TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S")
run = pipeline_jobs.PipelineJob(
display_name="test-pipeine",
template_path="pipeline.json",
job_id="test-{0}".format(TIMESTAMP),
enable_caching=True
)
run.run()
Pipeline automatisieren
Sie haben nun die erste Pipeline gestartet. Sie können den Status dieses Jobs auf der Seite Vertex AI Pipelines in der Console aufrufen. Sie können beobachten, wie die einzelnen Container erstellt und ausgeführt werden. Sie können auch Fehler für bestimmte Komponenten in diesem Abschnitt verfolgen, indem Sie auf die einzelnen Komponenten klicken.
Zum Planen der Pipeline erstellen Sie eine Cloud Functions-Funktion und verwenden einen Planer, der einem Cronjob ähnelt.
Der Code im letzten Abschnitt des Notebooks plant die tägliche Ausführung der Pipeline, wie im folgenden Code-Snippet gezeigt:
from kfp.v2.google.client import AIPlatformClient
api_client = AIPlatformClient(project_id=PROJECT_ID,
region='us-central1'
)
api_client.create_schedule_from_job_spec(
job_spec_path='pipeline.json',
schedule='0 * * * *',
enable_caching=False
)
Fertige Pipeline in der Produktion verwenden
Die abgeschlossene Pipeline hat folgende Aufgaben ausgeführt:
- Ein Eingabe-Dataset wurde erstellt.
- Mehrere Modelle werden sowohl mit BigQuery ML als auch mit XGBoost in Python trainiert.
- Analysierte Modellergebnisse
- Sie haben das XGBoost-Modell bereitgestellt.
Sie haben die Pipeline auch mithilfe von Cloud Functions und Cloud Scheduler automatisiert, um sie täglich auszuführen.
Die im Notebook definierte Pipeline wurde erstellt, um Möglichkeiten zum Erstellen verschiedener Modelle zu veranschaulichen. Sie würden die Pipeline nicht ausführen, da sie derzeit in einem Produktionsszenario erstellt wird. Sie können diese Pipeline jedoch als Richtlinie verwenden und die Komponenten an Ihre Anforderungen anpassen. Sie können beispielsweise den Prozess zur Featureerstellung bearbeiten, um die Daten zu nutzen, Datumsbereiche zu ändern und alternative Modelle zu erstellen. Sie wählen auch das Modell aus, das am besten Ihren Produktionsanforderungen entspricht.
Wenn die Pipeline für die Produktion bereit ist, können Sie zusätzliche Aufgaben implementieren. Sie können beispielsweise ein Champion-/Challenger-Modell implementieren, bei dem jeden Tag ein neues Modell (der Challenger) und das vorhandene Modell (der Champion) für neue Daten bewertet werden. Das neue Modell wird nur dann in die Produktion aufgenommen, wenn dessen Leistung besser ist als die Leistung des aktuellen Modells. Zur Überwachung des Fortschritts Ihres Systems können Sie auch die Modellleistung jedes Tages aufzeichnen und die Trendleistung visualisieren.
Nächste Schritte
- Wie Sie MLOps verwenden, um produktionsreife ML-Systeme zu erstellen, erfahren Sie im Leitfaden für ML-Entwickler.
- Weitere Informationen zu Vertex AI finden Sie in der Dokumentation zu Vertex AI.
- Weitere Informationen zu Kubeflow Pipelines finden Sie in der KFP-Dokumentation.
- Weitere Referenzarchitekturen, Diagramme und Best Practices finden Sie im Cloud-Architekturcenter.