This document describes several architectures that provide high availability (HA) for PostgreSQL deployments on Google Cloud. HA is the measure of system resiliency in response to underlying infrastructure failure. In this document, HA refers to the availability of PostgreSQL clusters either within a single cloud region or between multiple regions, depending on the HA architecture.
This document is intended for database administrators, cloud architects, and DevOps engineers who want to learn how to increase PostgreSQL data-tier reliability by improving overall system uptime. This document discusses concepts relevant to running PostgreSQL on Compute Engine. The document doesn't discuss using managed databases such as Cloud SQL for PostgreSQL and AlloyDB for PostgreSQL.
If a system or application requires a persistent state to handle requests or transactions, the data persistence layer (the data tier) must be available to successfully handle requests for data queries or mutations. Downtime in the data tier prevents the system or application from performing the necessary tasks.
Depending on the service level objectives (SLOs) of your system, you might require an architecture that provides a higher level of availability. There is more than one way to achieve HA, but in general you provision redundant infrastructure that you can quickly make accessible to your application.
This document discusses the following topics:
- Definition of terms related to HA database concepts.
- Options for HA PostgreSQL topologies.
- Contextual information for consideration of each architecture option.
Terminology
The following terms and concepts are industry-standard, and they are useful to understand for purposes beyond the scope of this document.
- replication
-
The process by which write transactions (
INSERT,UPDATE, orDELETE) and schema changes (data definition language (DDL)) are reliably captured, logged, and then serially applied to all downstream database replica nodes in the architecture. - primary node
- The node that provides a read with the most up-to-date state of persisted data. All database writes must be directed to a primary node.
- replica (secondary) node
- An online copy of the primary database node. Changes are either synchronously or asynchronously replicated to replica nodes from the primary node. You can read from replica nodes with the understanding that the data might be slightly delayed due to replication lag.
- replication lag
- A measurement, in log sequence number (LSN), transaction ID, or time. Replication lag expresses the difference between when change operations are applied to the replica compared to when they are applied to the primary node.
- continuous archiving
- An incremental backup in which the database continuously saves sequential transactions to a file.
- write-ahead log (WAL)
- A write-ahead log (WAL) is a log file that records changes to data files before any changes are actually made to the files. In case of a server crash, the WAL is a standard way to help ensure the data integrity and durability of your writes.
- WAL record
- A record of a transaction that was applied to the database. A WAL record is formatted and stored as a series of records that describe data file page-level changes.
- Log Sequence Number (LSN)
- Transactions create WAL records which are appended to the WAL file. The position where the insert occurs is called Log Sequence Number (LSN). It is a 64-bit integer, represented as two hexadecimal numbers separated by a slash (XXXXXXXX/YYZZZZZZ). The 'Z' represents the offset position in the WAL file.
- segment files
- Files that contain as many WAL records as possible, depending on the file size that you configure. Segment files have monotonically increasing filenames and a default file size of 16 MB.
- synchronous replication
-
A form of replication in which the primary server waits for the replica to
confirm that data was written to the replica transaction log before
confirming a commit to the client. When you run streaming replication, you
can use the PostgreSQL
synchronous_commitoption, which helps to ensure consistency between your primary server and replica. - asynchronous replication
- A form of replication in which the primary server doesn't wait for the replica to confirm that the transaction was successfully received before confirming a commit to the client. Asynchronous replication has lower latency when compared with synchronous replication. However, if the primary crashes and its committed transactions aren't transferred to the replica, there is a chance of data loss. Asynchronous replication is the default mode of replication on PostgreSQL, either using file-based log shipping or streaming replication.
- file-based log shipping
- A replication method in PostgreSQL that transfers the WAL segment files from the primary database server to the replica. The primary operates in continuous archiving mode, while each standby service operates in continuous recovery mode to read the WAL files. This type of replication is asynchronous.
- streaming replication
- A replication method wherein the replica connects to the primary and continuously receives a continuous sequence of changes. Because updates arrive through a stream, this method keeps the replica more up-to-date with the primary when compared with log-shipping replication. Although replication is asynchronous by default, you can alternatively configure synchronous replication.
- physical streaming replication
- A replication method that transports changes to the replica. This method uses the WAL records that contain the physical data changes in the form of disk block addresses and byte-by-byte changes.
- logical streaming replication
- A replication method that captures changes based on their replication identity (primary key) which allows for more control over how the data is replicated compared to physical replication. Because of restrictions in PostgreSQL logical replication, logical streaming replication requires special configuration for an HA setup. This guide discusses the standard physical replication and doesn't discuss logical replication.
- uptime
- The percent of time that a resource is working and capable of delivering a response to a request.
- failure detection
- The process of identifying that an infrastructure failure has occurred.
- failover
- The process of promoting the backup or standby infrastructure (in this case, the replica node) to become the primary infrastructure. During failover, the replica node becomes the primary node.
- switchover
- The process of running a manual failover on a production system. A switchover either tests that the system is working well, or takes the current primary node out of the cluster for maintenance.
- recovery time objective (RTO)
- The elapsed, real-time duration for the data tier failover process to complete. RTO depends on the amount of time that's acceptable from a business perspective.
- recovery point objective (RPO)
- The amount of data loss (in elapsed real time) for the data tier to sustain as a result of failover. RPO depends on the amount of data loss that's acceptable from a business perspective.
- fallback
- The process of reinstating the former primary node after the condition that caused a failover is remedied.
- self-healing
- The capability of a system to resolve issues without external actions by a human operator.
- network partition
- A condition when two nodes in an architecture—for example the primary and replica nodes—can't communicate with one another over the network.
- split brain
- A condition that occurs when two nodes simultaneously believe that they are the primary node.
- node group
- A set of compute resources that provide a service. In this document, that service is the data persistence tier.
- witness or quorum node
- A separate compute resource that helps a node group determine what to do when a split-brain condition occurs.
- primary or leader election
- The process by which a group of peer-aware nodes, including witness nodes, determine which node should be the primary node.
When to consider an HA architecture
HA architectures provide increased protection against data-tier downtime when compared to single node database setups. To select the best option for your business use case, you need to understand your tolerance for downtime, and the respective tradeoffs of the various architectures.
Use an HA architecture when you want to provide increased data-tier uptime to meet the reliability requirements for your workloads and services. If your environment tolerates some amount of downtime, an HA architecture might introduce unnecessary cost and complexity. For example, development or test environments infrequently need high database tier availability.
Consider your requirements for HA
Following are several questions to help you decide what PostgreSQL HA option is best for your business:
- What level of availability do you hope to achieve? Do you require an option that allows your service to continue to function during only a single zone or complete regional failure? Some HA options are limited to a region while others can be multi-region.
- What services or customers rely on your data tier, and what is the cost to your business if there is downtime in the data persistence tier? If a service caters only to internal customers who require occasional use of the system, it likely has lower availability requirements than an end-customer facing service that serves customers continually.
- What is your operational budget? Cost is a notable consideration: to provide HA, your infrastructure and storage costs are likely to increase.
- How automated does the process need to be, and how quickly do you need to fail over? (What is your RTO?) HA options vary by how quickly the system can failover and be available to customers.
- Can you afford to lose data as a result of the failover? (What is your RPO?) Because of the distributed nature of HA topologies, there is a tradeoff between commit latency and risk of data loss due to a failure.
How HA works
This section describes streaming and synchronous streaming replication that underlie PostgreSQL HA architectures.
Streaming replication
Streaming replication is a replication approach in which the replica connects to the primary and continuously receives a stream of WAL records. Compared to log-shipping replication, streaming replication allows the replica to stay more up-to-date with the primary. PostgreSQL offers built-in streaming replication beginning in version 9. Many PostgreSQL HA solutions use the built-in streaming replication to provide the mechanism for multiple PostgreSQL replica nodes to be kept in sync with the primary. Several of these options are discussed in the PostgreSQL HA architectures section later in this document.
Each replica node requires dedicated compute and storage resources. Replica node infrastructure is independent from the primary. You can use replica nodes as hot standbys to serve read-only client queries. This approach allows read-only query load-balancing across the primary and one or more replicas.
Streaming replication is by default asynchronous; the primary doesn't wait for a confirmation from a replica before it confirms a transaction commit to the client. If a primary suffers a failure after it confirms the transaction, but before a replica receives the transaction, asynchronous replication can result in a data loss. If the replica is promoted to become a new primary, such a transaction wouldn't be present.
Synchronous streaming replication
You can configure streaming replication as synchronous by choosing one or more replicas to be a synchronous standby. If you configure your architecture for synchronous replication, the primary doesn't confirm a transaction commit until after the replica acknowledges the transaction persistence. Synchronous streaming replication provides increased durability in return for a higher transaction latency.
The
synchronous_commit
configuration option also lets you configure the
following progressive replica durability levels for the transaction:
local: synchronous standby replicas are not involved in the commit acknowledgement. The primary acknowledges transaction commits after WAL records are written and flushed to its local disk. Transaction commits on the primary don't involve standby replicas. Transactions can be lost if there is any failure on the primary.on[default]: synchronous standby replicas write the committed transactions to their WAL before they send acknowledgment to the primary. Using theonconfiguration ensures that the transaction can only be lost if the primary and all synchronous standby replicas suffer simultaneous storage failures. Because the replicas only send an acknowledgment after they write WAL records, clients that query the replica won't see changes until the respective WAL records are applied to the replica database.remote_write: synchronous standby replicas acknowledge receipt of the WAL record at the OS level, but they don't guarantee that the WAL record was written to disk. Becauseremote_writedoesn't guarantee that the WAL was written, the transaction can be lost if there is any failure on both the primary and secondary before the records are written.remote_writehas lower durability than theonoption.remote_apply: synchronous standby replicas acknowledge transaction receipt and successful application to the database before they acknowledge the transaction commit to the client. Using theremote_applyconfiguration ensures that the transaction is persisted to the replica, and that client query results immediately include the effects of the transaction.remote_applyprovides increased durability and consistency compared toonandremote_write.
The synchronous_commit configuration option works with the
synchronous_standby_names
configuration option that specifies the list of standby servers which take part
in the synchronous replication process. If no synchronous standby names are
specified, transaction commits don't wait for replication.
PostgreSQL HA architectures
At the most basic level, data tier HA consists of the following:
- A mechanism to identify if a failure of the primary node occurs.
- A process to perform a failover in which the replica node is promoted to be a primary node.
- A process to change the query routing so that application requests reach the new primary node.
- Optionally, a method to fallback to the original architecture using pre-failover primary and replica nodes in their original capacities.
The following sections provide an overview of the following HA architectures:
- The Patroni template
- pg_auto_failover extension and service
- Stateful MIGs and regional persistent disk
These HA solutions minimize downtime if there is an infrastructure or zonal outage. When you choose between these options, balance commit latency and durability according to your business needs.
A critical aspect of an HA architecture is the time and manual effort that are required to prepare a new standby environment for subsequent failover or fallback. Otherwise, the system can only withstand one failure, and the service doesn't have protection from an SLA violation. We recommend that you select an HA architecture that can perform manual failovers, or switchovers, with the production infrastructure.
HA using the Patroni template
Patroni is a mature and actively maintained, open source (MIT licensed) software template that provides you with the tools to configure, deploy, and operate a PostgreSQL HA architecture. Patroni provides a shared cluster state and an architecture configuration that is persisted in a distributed configuration store (DCS). Options for implementing a DCS include: etcd, Consul, Apache ZooKeeper, or Kubernetes. The following diagram shows the major components of a Patroni cluster.

Figure 1. Diagram of the major components of a Patroni cluster.
In figure 1, the load balancers front the PostgreSQL nodes, and the DCS and the Patroni agents operate on the PostgreSQL nodes.
Patroni runs an agent process on each PostgreSQL node. The agent process manages the PostgreSQL process and data node configuration. The Patroni agent coordinates with other nodes through the DCS. The Patroni agent process also exposes a REST API that you can query to determine the PostgreSQL service health and configuration for each node.
To assert its cluster membership role, the primary node regularly updates the leader key in the DCS. The leader key includes a time to live (TTL). If the TTL elapses without an update, the leader key is evicted from the DCS, and the leader election starts to select a new primary from the candidate pool.
The following diagram shows a healthy cluster in which Node A successfully updates the leader lock.

Figure 2. Diagram of a healthy cluster.
Figure 2 shows a healthy cluster: Node B and Node C watch while Node A successfully updates leader key.
Failure detection
The Patroni agent continuously telegraphs its health by updating its key in the DCS. At the same time, the agent validates PostgreSQL health; if the agent detects an issue, it either self-fences the node by shutting itself down, or demotes the node to a replica. As shown in the following diagram, if the impaired node is the primary, its leader key in the DCS expires, and a new leader election occurs.
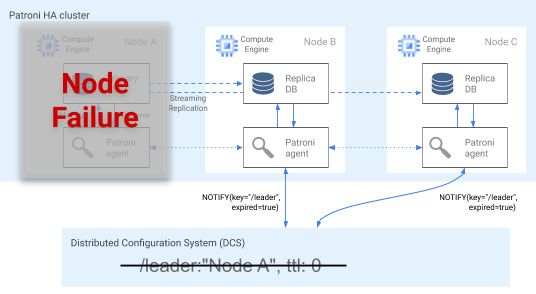
Figure 3. Diagram of an impaired cluster.
Figure 3 shows an impaired cluster: a down primary node hasn't recently updated its leader key in the DCS, and the non-leader replicas are notified that the leader key has expired.
On Linux hosts, Patroni also runs an OS-level watchdog on primary nodes. This watchdog listens for keep-alive messages from the Patroni agent process. If the process becomes unresponsive, and the keep alive isn't sent, the watchdog restarts the host. The watchdog helps prevent a split brain condition in which the PostgreSQL node continues to serve as the primary, but the leader key in the DCS expired due to agent failure, and a different primary (leader) was elected.
Failover process
If the leader lock expires in the DCS, the candidate replica nodes begin a leader election. When a replica discovers a missing leader lock, it checks its replication position compared to the other replicas. Each replica uses the REST API to get the WAL log positions of the other replica nodes, as shown in the following diagram.

Figure 4. Diagram of the Patroni failover process.
Figure 4 shows WAL log position queries and respective results from the active replica nodes. Node A isn't available, and the healthy nodes B and C return the same WAL position to each other.
The most up-to-date node (or nodes if they are at the same position)
simultaneously attempt to acquire the leader lock in the DCS. However, only one
node can create the leader key in the DCS. The first node to successfully create
the leader key is the winner of the leader race, as shown in the following
diagram. Alternatively, you can designate preferred failover candidates by
setting the
failover_priority tag
in the configuration files.

Figure 5. Diagram of the leader race.
Figure 5 shows a leader race: two leader candidates try to obtain the leader lock, but only one of the two nodes, Node C, successfully sets the leader key and wins the race.
Upon winning the leader election, the replica promotes itself to be the new primary. Starting at the time that the replica promotes itself, the new primary updates the leader key in the DCS to retain the leader lock, and the other nodes serve as replicas.
Patroni also provides the
patronictl control tool
that lets you run switchovers to test the nodal failover process.
This tool helps operators to test their HA setups in production.
Query routing
The Patroni agent process that runs on each node exposes REST API endpoints that reveal the current node role: either primary or replica.
| REST endpoint | HTTP return code if primary | HTTP return code if replica |
|---|---|---|
/primary |
200 |
503 |
/replica |
503 |
200 |
Because the relevant health checks change their responses if a particular node changes its role, a load balancer health check can use these endpoints to inform primary and replica node traffic routing. The Patroni project provides template configurations for a load balancer such as HAProxy . The internal passthrough Network Load Balancer can use these same health checks to provide similar capabilities.
Fallback process
If there is a node failure, a cluster is left in a degraded state. Patroni's fallback process helps to restore an HA cluster back to a healthy state after a failover. The fallback process manages the return of the cluster to its original state by automatically initializing the impacted node as a cluster replica.
For example, a node might restart due to a failure in the operating system or underlying infrastructure. If the node is the primary and takes longer than the leader key TTL to restart, a leader election is triggered and a new primary node is selected and promoted. When the stale primary Patroni process starts, it detects that it doesn't have the leader lock, automatically demotes itself to a replica, and joins the cluster in that capacity.
If there is an unrecoverable node failure, such as an unlikely zonal failure, you need to start a new node. A database operator can manually start a new node, or you can use a stateful regional managed instance group (MIG) with a minimum node count to automate the process. After the new node is created, Patroni detects that the new node is part of an existing cluster and automatically initializes the node as a replica.
HA using the pg_auto_failover extension and service
pg_auto_failover is an actively developed, open source (PostgreSQL license) PostgreSQL extension. pg_auto_failover configures an HA architecture by extending existing PostgreSQL capabilities. pg_auto_failover doesn't have any dependencies other than PostgreSQL.
To use the pg_auto_failover extension with an HA architecture, you need at
least three nodes, each running PostgreSQL with the extension enabled. Any of
the nodes can fail without affecting the uptime of the database group. A
collection of nodes managed by pg_auto_failover is called a formation. The
following diagram shows a pg_auto_failover architecture.

Figure 6. Diagram of a pg_auto_failover architecture.
Figure 6 shows a pg_auto_failover architecture that consists of two main components: the Monitor service and the Keeper agent. Both the Keeper and Monitor are contained in the pg_auto_failover extension.
Monitor service
The pg_auto_failover Monitor service is implemented as a PostgreSQL extension; when the service creates a Monitor node, it starts a PostgreSQL instance with the pg_auto_failover extension enabled. The Monitor maintains the global state for the formation, obtains health check status from the member PostgreSQL data nodes, and orchestrates the group using the rules established by a finite state machine (FSM). According to the FSM rules for state transitions, the Monitor communicates instructions to the group nodes for actions like promote, demote, and configuration changes.
Keeper agent
On each pg_auto_failover data node, the extension starts a Keeper agent process. This Keeper process observes and manages the PostgreSQL service. The Keeper sends status updates to the Monitor node, and receives and executes actions that the Monitor sends in response.
By default, pg_auto_failover sets up all group secondary data nodes as
synchronous replicas. The number of synchronous replicas required for a commit
are based on the number_sync_standby configuration that you set on the
Monitor.
Failure detection
The Keeper agents on primary and secondary data nodes periodically connect to the Monitor node to communicate their current state, and check whether there are any actions to be executed. The Monitor node also connects to the data nodes to perform a health check by executing the PostgreSQL protocol (libpq) API calls, imitating the pg_isready() PostgreSQL client application. If neither of these actions are successful after a period of time (30 seconds by default), the Monitor node determines that a data node failure occurred. You can change the PostgreSQL configuration settings to customize monitor timing and number of retries. For more information, see Failover and fault tolerance.
If a single-node failure occurs, one of the following is true:
- If the unhealthy data node is a primary, the Monitor starts a failover.
- If the unhealthy data node is a secondary, the Monitor disables synchronous replication for the unhealthy node.
- If the failed node is the Monitor node, automated failover isn't possible. To avoid this single point of failure, you need to ensure that the right monitoring and disaster recovery is in place.
The following diagram shows the failure scenarios and the formation result states that are described in the preceding list.

Figure 7. Diagram of the pg_auto_failover failure scenarios.
Failover process
Each database node in the group has the following configuration options that determine the failover process:
replication_quorum: a boolean option. Ifreplication_quorumis set totrue, then the node is considered as a potential failover candidatecandidate_priority: an integer value from 0 through 100.candidate_priorityhas a default value of 50 that you can change to affect failover priority. Nodes are prioritized as potential failover candidates based on thecandidate_priorityvalue. Nodes that have a highercandidate_priorityvalue have a higher priority. The failover process requires that at least two nodes have a nonzero candidate priority in any pg_auto_failover formation.
If there is a primary node failure, secondary nodes are considered for
promotion to primary if they have active synchronous replication and if they are
members of the replication_quorum.
Secondary nodes are considered for promotion according to the following progressive criteria:
- Nodes with the highest candidate priority
- Standby with the most advanced WAL log position published to the Monitor
- Random selection as a final tie break
A failover candidate is a lagging candidate when it hasn't published the most advanced LSN position in the WAL. In this scenario, pg_auto_failover orchestrates an intermediate step in the failover mechanism: the lagging candidate fetches the missing WAL bytes from a standby node that has the most advanced LSN position. The standby node is then promoted. Postgres allows this operation because cascading replication lets any standby act as the upstream node for another standby.
Query routing
pg_auto_failure doesn't provide any server-side query routing capabilities.
Instead, pg_auto_failure relies on client-side query routing that uses the
official PostgreSQL client driver
libpq.
When you define the connection URI, the driver can accept multiple hosts in its
host keyword.
The client library that your application uses must either wrap libpq or implement the ability to supply multiple hosts for the architecture to support a fully automated failover.
Fallback and switchover processes
When the Keeper process restarts a failed node or starts a new replacement node, the process checks the Monitor node to determine the next action to perform. If a failed, restarted node was formerly the primary, and the Monitor has already picked a new primary according to the failover process, the Keeper reinitializes this stale primary as a secondary replica.
pg_auto_failure provides the pg_autoctl tool, which lets you run switchovers
to test the node failover process. Along with letting operators test their HA
setups in production, the tool helps you restore an HA cluster back to a healthy
state after a failover.
HA using stateful MIGs and regional persistent disk
This section describes an HA approach that uses the following Google Cloud components:
- regional persistent disk. When you use regional persistent disks, data is synchronously replicated between two zones in a region, so you don't need to use streaming replication. However, HA is limited to exactly two zones in a region.
- Stateful managed instance groups. A pair of stateful MIGs are used as part of a control plane to keep one primary PostgreSQL node running. When the stateful MIG starts a new instance, it can attach the existing regional persistent disk. At a single point in time, only one of the two MIGs will have a running instance.
- Cloud Storage. An object in a Cloud Storage bucket contains a configuration that indicates which of the two MIGs is running the primary database node, and in which MIG a failover instance should be created.
- MIG health checks and autohealing. The health check monitors instance health. If the running node becomes unhealthy, the health check initiates the autohealing process.
- Logging. When autohealing stops the primary node, an entry is recorded in Logging. The pertinent log entries are exported to a Pub/Sub sink topic using a filter.
- Event-driven Cloud Run functions. The Pub/Sub message triggers Cloud Run functions. Cloud Run functions uses the config in Cloud Storage to determine what actions to take for each stateful MIG.
- Internal passthrough Network Load Balancer. The load balancer provides routing to the running instance in the group. This ensures that an instance IP address change that's caused by instance recreation is abstracted from the client.
The following diagram shows an example of an HA using stateful MIGs and regional persistent disks:

Figure 8. Diagram of an HA that uses stateful MIGs and regional persistent disks.
Figure 8 shows a healthy Primary node serving client traffic. Clients connect to the internal passthrough Network Load Balancer's static IP address. The load balancer routes client requests to the VM that is running as part of the MIG. Data volumes are stored on mounted regional persistent disks.
To implement this approach, create a VM image with PostgreSQL that starts up on initialization to be used as the instance template of the MIG. You also need to configure an HTTP-based health check (such as HAProxy or pgDoctor) on the node. An HTTP-based health check helps ensure that both the load balancer and the instance group can determine the health of the PostgreSQL node.
Regional persistent disk
To provision a block storage device that provides synchronous data replication between two zones in a region, you can use the Compute Engine regional persistent disk storage option. A regional persistent disk can provide a foundational building block for you to implement a PostgreSQL HA option that doesn't rely on PostgreSQL's built-in streaming replication.
If your primary node VM instance becomes unavailable due to infrastructure failure or zonal outage, you can force the regional persistent disk to attach to a VM instance in your backup zone in the same region.
To attach the regional persistent disk to a VM instance in your backup zone, you can do one of the following:
- Maintain a cold standby VM instance in the backup zone. A cold standby VM instance is a stopped VM instance that doesn't have a regional Persistent Disk mounted to it but is an identical VM instance to the primary node VM instance. If there is a failure, the cold standby VM is started and the regional persistent disk is mounted to it. The cold standby instance and the primary node instance have the same data.
- Create a pair of stateful MIGs using the same instance template. The MIGs provide health checks and serve as part of the control plane. If the primary node fails, a failover instance is created in the target MIG declaratively. The target MIG is defined in the Cloud Storage object. A per-instance configuration is used to attach the regional persistent disk.
If the data service outage is promptly identified, the force-attach operation typically completes in less than one minute, so an RTO measured in minutes is attainable.
If your business can tolerate the additional downtime required for you to detect and communicate an outage, and for you to perform the failover manually, then you don't need to automate the force-attach process. If your RTO tolerance is lower, you can automate the detection and failover process. Alternatively Cloud SQL for PostgreSQL also provides a fully managed implementation of this HA approach.
Failure detection and failover process
The HA approach uses the autohealing capabilities of instance groups to monitor node health using a health check. If there is a failed health check, the existing instance is considered unhealthy, and the instance is stopped. This stop initiates the failover process using Logging, Pub/Sub, and the triggered Cloud Run functions function.
To fulfill the requirement that this VM always has the regional disk mounted, one of the two the MIGs will be configured by the Cloud Run functions to create an instance in one of the two zones where the regional persistent disk is available. Upon a node failure, the replacement instance is started, according to the state persisted in Cloud Storage, in the alternate zone.

Figure 9. Diagram of a zonal failure in a MIG.
In figure 9, the former primary node in Zone A has experienced a failure and the Cloud Run functions has configured MIG B to launch a new primary instance in Zone B. The failure detection mechanism is automatically configured to monitor the health of the new primary node.
Query routing
The internal passthrough Network Load Balancer routes clients to the instance that is running the PostgreSQL service. The load balancer uses the same health check as the instance group to determine whether the instance is available to serve queries. If the node is unavailable because it's being recreated, the connections fail. After the instance is back up, health checks start passing and the new connections are routed to the available node. There are no read-only nodes in this setup because there is only one running node.
Fallback process
If the database node is failing a health check due to an underlying hardware issue, the node is recreated on a different underlying instance. At that point, the architecture is returned to its original state without any additional steps. However, if there is a zonal failure, the setup continues to run in a degraded state until the first zone recovers. While highly unlikely, if there are simultaneous failures in both zones that are configured for the regional Persistent Disk replication and stateful MIG, the PostgreSQL instance can't recover–the database is unavailable to serve requests during the outage.
Comparison between the HA options
The following tables provide a comparison of the HA options available from Patroni, pg_auto_failover, and Stateful MIGs with regional persistent disks.
Setup and architecture
| Patroni | pg_auto_failover | Stateful MIGs with regional persistent disks |
|---|---|---|
|
Requires an HA architecture, DCS setup, and monitoring and alerting. Agent setup on data nodes is relatively straightforward. |
Doesn't require any external dependencies other than PostgreSQL. Requires a node dedicated as a monitor. The monitor node requires HA and DR to ensure that it isn't a single point of failure (SPOF). | Architecture that consists exclusively of Google Cloud services. You only run one active database node at a time. |
High availability configurability
| Patroni | pg_auto_failover | Stateful MIGs with regional persistent disks |
|---|---|---|
| Extremely configurable: supports both synchronous and asynchronous replication, and lets you specify which nodes are to be synchronous and asynchronous. Includes automatic management of the synchronous nodes. Allows for multiple zone and multi-region HA setups. The DCS must be accessible. | Similar to Patroni: very configurable. However, because the monitor is only available as a single instance, any type of setup needs to consider access to this node. | Limited to two zones in a single region with synchronous replication. |
Ability to handle network partition
| Patroni | pg_auto_failover | Stateful MIGs with regional persistent disks |
|---|---|---|
| Self-fencing along with an OS-level monitor provides protection against split brain. Any failure to connect to the DCS results in the primary demoting itself to a replica and triggering a failover to ensure durability over availability. | Uses a combination of health checks from the primary to the monitor and to the replica to detect a network partition, and demotes itself if necessary. | Not applicable: there is only one active PostgreSQL node at a time, so there isn't a network partition. |
Cost
| Patroni | pg_auto_failover | Stateful MIGs with regional persistent disks |
|---|---|---|
| High cost because it depends on the DCS that you choose and the number of PostgreSQL replicas. The Patroni architecture doesn't add significant cost. However, the overall expense is affected by the underlying infrastructure, which uses multiple compute instances for PostgreSQL and the DCS. Because it uses multiple replicas and a separate DCS cluster, this option can be the most expensive. | Medium cost because it involves running a monitor node and at least three PostgreSQL nodes (one primary and two replicas). | Low cost because only one PostgreSQL node is actively running at any given time. You only pay for a single compute instance. |
Client configuration
| Patroni | pg_auto_failover | Stateful MIGs with regional persistent disks |
|---|---|---|
| Transparent to the client because it connects to a load balancer. | Requires client library to support multiple host definition in setup because it isn't easily fronted with a load balancer. | Transparent to the client because it connects to a load balancer. |
Scalability
| Patroni | pg_auto_failover | Stateful MIGs with regional persistent disks |
|---|---|---|
| High flexibility in configuring for scalability and availability tradeoffs. Read scaling is possible by adding more replicas. | Similar to Patroni: Read scaling is possible by adding more replicas. | Limited scalability due to only having one active PostgreSQL node at a time. |
Automation of PostgreSQL node initialization, configuration management
| Patroni | pg_auto_failover | Stateful MIGs with regional persistent disks |
|---|---|---|
Provides tools to manage PostgreSQL configuration (patronictl
edit-config) and automatically initializes new nodes or restarted
nodes in the cluster. You can initialize nodes using
pg_basebackup or other tools like barman.
|
Automatically initializes nodes, but limited to only using
pg_basebackup when initializing a new replica node.
Configuration management is limited to pg_auto_failover-related
configurations.
|
Stateful instance group with shared disk removes the need for any PostgreSQL node initialization. Because there is only ever one node running, configuration management is on a single node. |
Customizability and feature richness
| Patroni | pg_auto_failover | Stateful MIGs with regional persistent disks |
|---|---|---|
|
Provides a hook interface to allow for user definable actions to be called at key steps, such as on demotion or on promotion. Feature-rich configurability like support for different types of DCS, different means to initialize replicas, and different ways to provide PostgreSQL configuration. Lets you set up standby clusters that allow for cascaded replica clusters to ease migration between clusters. |
Limited because it's a relatively new project. | Not applicable. |
Maturity
| Patroni | pg_auto_failover | Stateful MIGs with regional persistent disks |
|---|---|---|
| Project has been available since 2015 and it's used in production by large companies like Zalando and GitLab. | Relatively new project announced early 2019. | Composed entirely of generally available Google Cloud products. |
Best Practices for Maintenance and Monitoring
Maintaining and monitoring your PostgreSQL HA cluster is crucial for ensuring high availability, data integrity, and optimal performance. The following sections provide some best practices for monitoring and maintaining a PostgreSQL HA cluster.
Perform regular backups and recovery testing
Regularly back up your PostgreSQL databases and test the recovery process. Doing so helps to ensure data integrity and minimizes downtime in case of an outage. Test your recovery process to validate your backups and identify potential issues before an outage occurs.
Monitor PostgreSQL servers and replication lag
Monitor your PostgreSQL servers to verify that they're running. Monitor the
replication lag between the primary and replica nodes. Excessive lag can lead
to data inconsistency and increased data loss in case of a failover. Set up
alerts for significant lag increases and investigate the root cause promptly.
Using views like pg_stat_replication and pg_replication_slots can help
you to monitor replication lag.
Implement connection pooling
Connection pooling can help you to efficiently manage database connections. Connection pooling helps to reduce the overhead of establishing new connections, which improves application performance and database server stability. Tools such as PGBouncer and Pgpool-II can provide connection pooling for PostgreSQL.
Implement comprehensive monitoring
To gain insights into your PostgreSQL HA clusters, establish robust monitoring systems as follows:
- Monitor key PostgreSQL and system metrics, such as CPU utilization, memory usage, disk I/O, network activity, and active connections.
- Collect PostgreSQL logs, including server logs, WAL logs, and autovacuum logs, for deep analysis and troubleshooting.
- Use monitoring tools and dashboards to visualize metrics and logs for rapid issue identification.
- Integrate metrics and logs with alerting systems for proactive notification of potential problems.
For more information about monitoring a Compute Engine instance, see Cloud Monitoring overview.
What's next
- Read about the Cloud SQL high availability configuration.
- Learn more about High availability options using regional persistent disk.
- Read about Patroni.
- Read about pg_auto_failover.
- For more reference architectures, diagrams, and best practices, explore the Cloud Architecture Center.
Contributors
Author: Alex Cârciu | Solutions Architect