Text-to-Speech-KI
Mit einer API auf Grundlage der besten KI-Technologien von Google wandeln Sie Text in natürlich klingende Sprache um.
Neukundinnen und Neukunden erhalten ein Guthaben von bis zu 300 $, um Text-to-Speech und andere Google Cloud-Produkte auszuprobieren.
Intelligente, lebensechte Antworten mit natürlich klingenden KI-Stimmen geben
Sprachschnittstellen für Apps mit integrierter Sprachausgabe erstellen
Kommunikation und Audio je nach Nutzervorlieben für Stimme und Sprache personalisieren

Vorteile
High-Fidelity-Sprache
High-Fidelity-Sprache
Nutzen Sie die bahnbrechenden Technologien von Google, um Sprache mit menschenähnlicher Intonation zu generieren. Basierend auf der Sprachsynthese von DeepMind liefert die API Stimmen, die fast wie Menschen klingen.
Große Auswahl an Stimmen
Große Auswahl an Stimmen
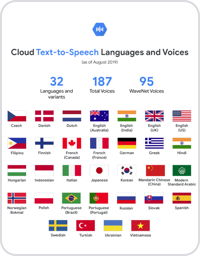
Sie haben die Wahl zwischen mehr als 380 Stimmen in über 75 Sprachen und Varianten, darunter Mandarin, Hindi, Spanisch, Arabisch und Russisch. Wählen Sie die Stimme aus, die perfekt zu Ihren Nutzerinnen und Nutzern und Ihrer Anwendung passt.
Einzigartige Stimme
Einzigartige Stimme
Setzen Sie an allen Kunden-Touchpoints auf eine einzigartige Stimme als Wiedererkennungseffekt für Ihr Unternehmen, anstatt eine gängige Stimme zu verwenden, die auch von anderen Organisationen genutzt wird.
Demo
Text-to-Speech in Aktion
Geben Sie einen Text ein, wählen Sie eine Sprache aus und klicken Sie auf „Speak It“, um ihn anzuhören.
Wichtige Features
Wichtige Features
Gemini-TTS
Sie können für kurze Sprach-Snippets bis hin zu langen Gesprächen mit einer oder mehreren Personen alle Inhalte synthetisieren und dabei den Kontext beibehalten. Stil, Akzent, Tempo, Ton und emotionaler Ausdruck lassen sich präzise festlegen – alles über einfache Prompts in natürlicher Sprache in über 75 Sprachen. Weitere Informationen finden Sie im Media Studio oder in unserer Dokumentation.
Chirp 3: HD-Stimmen
Nutzen Sie die neuesten spontanen AudioLM-basierten Konversationsstimmen, um einen attraktiven Kundenservice anzubieten. Diese Stimmen liefern Audio in hoher Qualität, Streaming mit geringer Latenz und natürlich klingende Sprache, einschließlich Unflüssigkeiten, emotionaler Bandbreite und genauer Intonation. Weitere Informationen finden Sie im Media Studio oder in unserer Dokumentation.
Chirp 3: Instant-Custom Voice
Erstellen Sie personalisierte Sprachmodelle mit Audioeingaben von nur zehn Sekunden Länge. Perfekt für Videospiele, Hörbücher, Podcasts und mehr. In über 30 Sprachen verfügbar. Weitere Informationen finden Sie im Media Studio oder in unserer Dokumentation.
Unterstützung von Prompts, Text und SSML
Sie können, je nach unterstütztem Modell, Zahlen- und Zeitformat, Bereitstellung, Aussprache und Emotionen anhand von einfachem Klartext-Scripting, SSML-Tags oder sogar leistungsstarken Prompts in natürlicher Sprache steuern. Weitere Informationen finden Sie im Media Studio oder in unserer Dokumentation.
Das ist neu
Das ist neu
Melden Sie sich für die Google Cloud-Newsletter an – so erhalten Sie regelmäßig Produktupdates, Veranstaltungsinformationen, Sonderangebote und mehr.




Dokumentation
Dokumentation
Anwendungsfälle
Anwendungsfälle
Sprachbots im Callcenter
Mithilfe von Sprachbots in Customer Experience Agent Studio können Sie die Sprachfunktionen im Kundenservice natürlicher gestalten, indem Sie Sprache dynamisch generieren, anstatt statische, vorab erstellte Audioaufnahmen abzuspielen. Begeistern Sie mit qualitativ hochwertigen, synthetischen Stimmen, die Anrufenden ein vertrautes und persönliches Gefühl geben.

Stimmgenerierung für Geräte
Sorgen Sie für eine natürlich klingende Kommunikation mit Nutzerinnen und Nutzern, indem Sie Geräten mit einem Text-Reader eine menschliche Stimme verleihen. Mit Speech-to-Text und Natural Language stellen Sie eine umfassende sprachgesteuerte Benutzeroberfläche bereit und bieten so einfache und natürliche Interaktionen.

Barrierefreie EPGs (Electronic Program Guides)
Lassen Sie die EPGs ganz einfach Text vorlesen, um eine bessere User Experience zu bieten und die Anforderungen an die Barrierefreiheit Ihrer Dienste und Anwendungen zu erfüllen. EPG-Demoversion testen
Implementieren Sie Text-zu-Sprache in EPGs, um die Nutzerfreundlichkeit zu verbessern und die Anforderungen an die Barrierefreiheit Ihrer Dienste und Anwendungen zu erfüllen.

Alle Features
Alle Features
| Streaming-Audiosynthese | Mit Streaming-Audiosynthese können Sie KI-Agenten Sprache verleihen für Unterhaltungen in Echtzeit mit extrem niedriger Latenz. |
| Synthese von Audioinhalten im Langformat | Mit der Synthese von Audioinhalten im Langformat können Sie bis zu 1 Million Byte asynchron synthetisieren. |
| Stimm- und Sprachauswahl | Sie können aus mehr als 380 Stimmen in über 75 Sprachen und Varianten wählen. Weitere folgen demnächst. |
| Unterstützung von Text und SSML | Sie können die Sprachausgabe mithilfe von SSML-Tags anpassen, um Pausen, Zahlen, Datums- und Uhrzeitformate sowie andere Anweisungen für die Aussprache hinzuzufügen. |
| Einstellung der Tonlage | Sie können die Tonlage Ihrer ausgewählten Stimme bezogen auf die Standardausgabe um bis zu 20 Halbtöne erhöhen oder senken. |
| Einstellung der Sprechgeschwindigkeit | Sie können die Sprechgeschwindigkeit auf bis zu viermal höheres oder niedrigeres Tempo als normal einstellen. |
| Lautstärkeregelung | Sie können die Ausgabelautstärke um bis zu 16 dB erhöhen oder um bis zu -96 dB verringern. |
| Integrierte REST API und gRPC API | Die Einbindung in alle Anwendungen oder Geräte, die REST- oder gRPC-Anfragen senden können, zum Beispiel Smartphones, PCs, Tablets und IoT-Geräte wie Autos, Fernseher oder Lautsprecher ist ganz einfach. |
| Flexibles Audioformat | Sie können Text in MP3, Linear16, OGG Opus und andere Audioformate konvertieren. |
| Audioprofile | Sie können Audioprofile für die Art von Lautsprecher optimieren, mit der die Audiodatei wiedergegeben werden soll, wie Kopfhörer oder Telefonleitungen. |
Preise
Preise
Die Kosten für Text-to-Speech basieren darauf, wie viele Zeichen pro Monat zur Sprachsynthese an den Dienst gesendet werden. Die ersten eine Million Zeichen für WaveNet-Stimmen sind jeden Monat kostenlos. Für Standardstimmen (nicht WaveNet) sind die ersten vier Millionen Zeichen pro Monat kostenlos. Wenn das Kontingent der kostenlosen Stufe aufgebraucht ist, wird Text-to-Speech pro eine Million verarbeiteter Zeichen abgerechnet.
Wenn Sie nicht in US-Dollar bezahlen, gelten die Preise, die unter Google Cloud SKUs für Ihre Währung angegeben sind.
Gleich loslegen
Neukundinnen und Neukunden erhalten ein Startguthaben von 300 $, um Text-to-Speech und andere Google Cloud-Produkte selbst auszuprobieren.
Benötigen Sie Hilfe beim Einstieg?
Vertrieb kontaktierenMit einem zertifizierten Partnerunternehmen arbeiten
Partner findenMehr entdecken
Alle Produkte ansehen


















