Cloud Text-to-Speech expands its number of voices by nearly 70%, now covering 32 languages and variants
Dan Aharon
Product Manager, Speech
Editor's Note: We have updated this blog to accurately reflect supported languages and variants; Norwegian (Nynorsk) voices are not currently available.
In February, we provided an update on how we’re expanding our support for new languages/variants and voices in Cloud Text-to-Speech. Today, we’re adding to that progress by announcing:
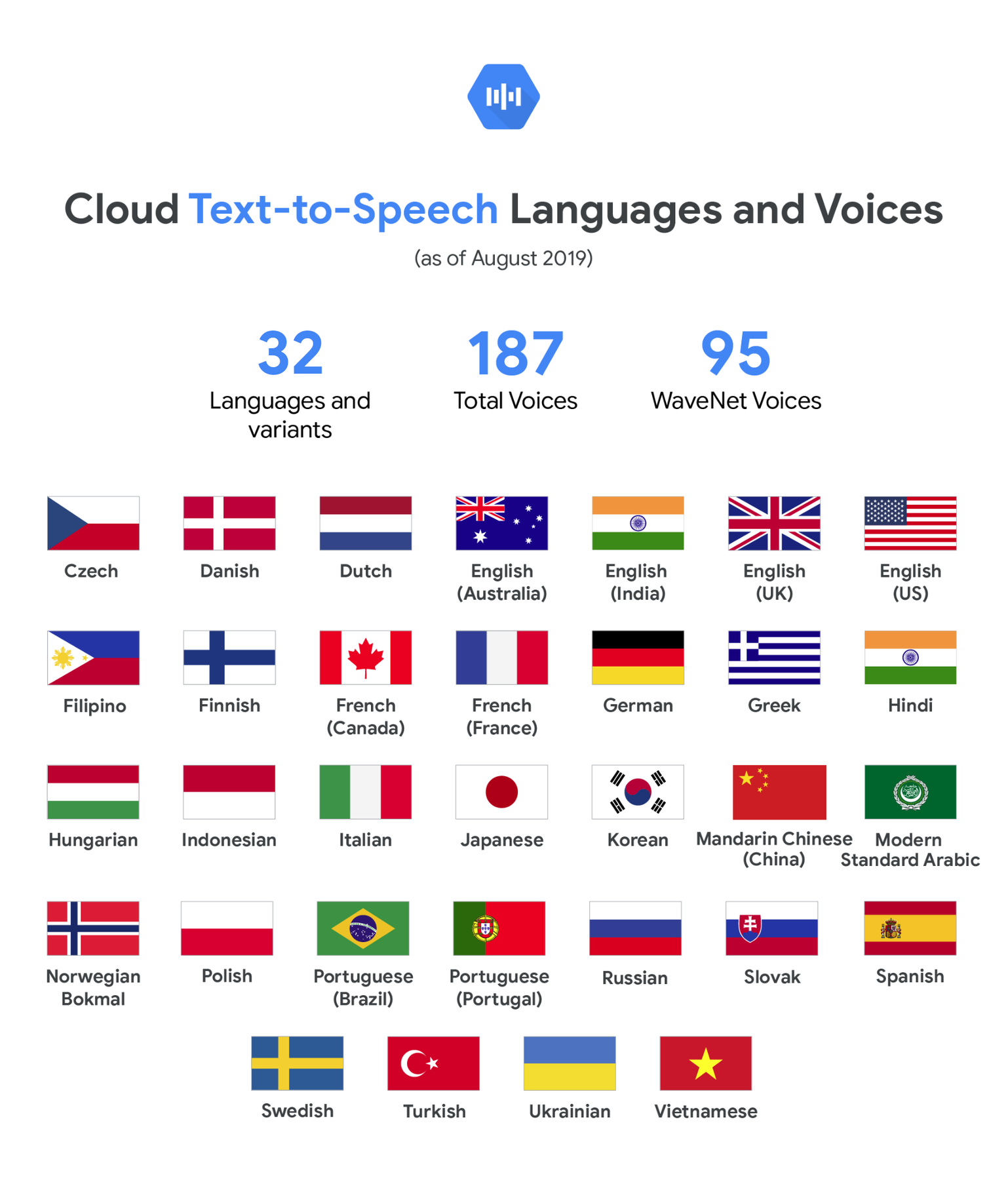
- Voices in 11 new languages or variants, including Czech, English (India), Filipino, Finnish, Greek, Hindi, Hungarian, Indonesian, Mandarin Chinese (China), Modern Standard Arabic, and Vietnamese—bringing the list of total languages/variants available to 32.
- 76 new voices (now 187 in total) overall across all languages/variants, including 38 new WaveNet neural net-powered voices (now 95 in total). See the complete list here.
- Availability of at least one WaveNet voice in all 32 languages/variants.
With these updates, Cloud Text-to-Speech developers can now reach millions more people across numerous countries with their applications—with many more languages to come. This enables a broad range of use cases, including Contact Center AI virtual agents, interacting with IoT devices in cars and the home, and audio-enablement of books and other text-based content.
Google Cloud Text-to-Speech runs on Google’s Tensor Processing Units (TPUs)—custom silicon chips that we designed from the ground up to accelerate machine learning and AI workloads. Our unique compute infrastructure, together with cutting-edge research, has allowed us to develop and deploy WaveNet voices much faster than is typical in the industry. Cloud Text-to-Speech launched a year and a half ago with 6 WaveNet voices in 1 language, and we now have 95 WaveNet voices in 33 languages.
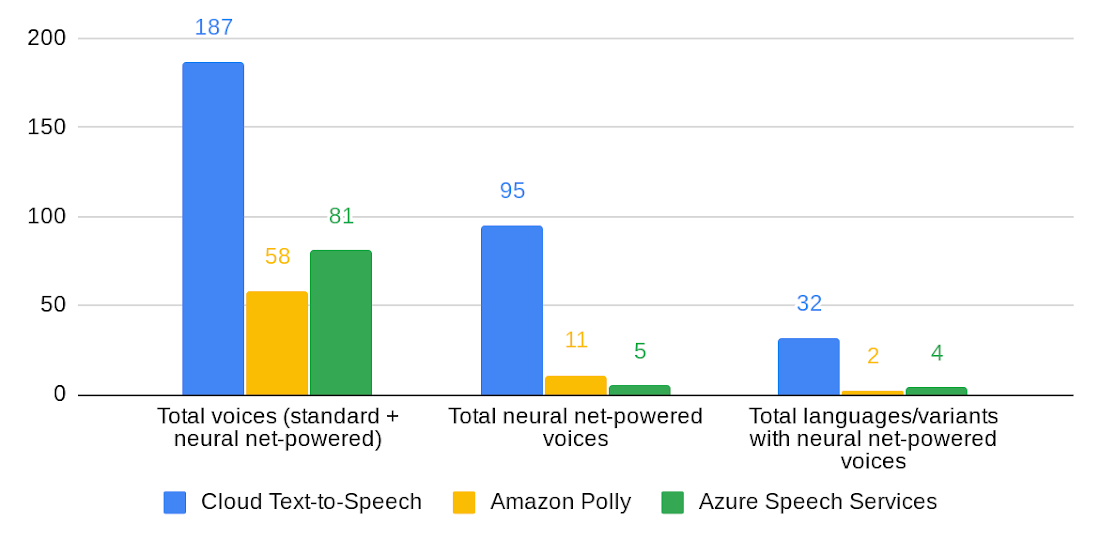
Among the major public cloud platforms, Cloud Text-to-Speech now offers the most languages/variants with “natural” (neural net-powered) voices, and the most voices overall:
The WaveNet advantage
When customers call into contact centers, use verbal commands with connected devices in cars or in their homes, or listen to audio conversions of text-based media, they increasingly expect a voice that sounds natural and human. Businesses that offer human-sounding voices offer the best experiences for their customers, and if that experience can also be provided in numerous languages and countries, that advantage becomes global.
WaveNet in Cloud Text-to-Speech makes that advantage possible without the need for vast investments in developing your own AI-powered speech synthesis. Based on neural-net technology, WaveNet creates natural-sounding voices, closing the perceived quality gap between speech synthesis and human speech in US English by 70% per Mean Opinion Score. The practical impact is that for most listeners, a WaveNet voice makes human/computer interaction a smooth and familiar experience.
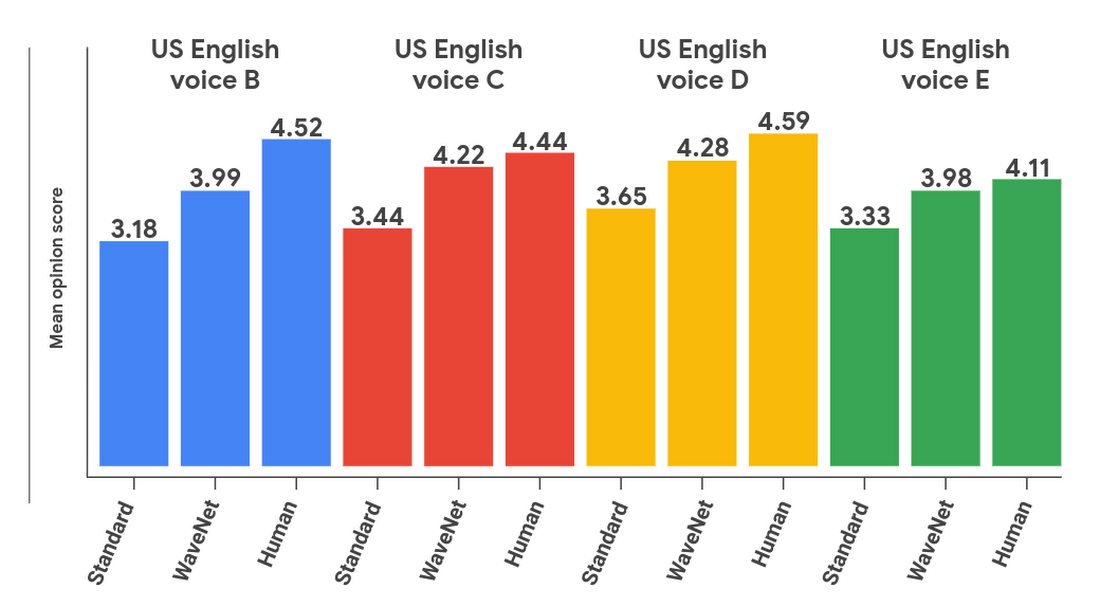
The difference between a standard synthetic voice and a WaveNet one is pretty clear; just listen to some of the new voices for yourself:
English (India): Standard Voice vs WaveNet Voice
Hungarian: Standard Voice vs WaveNet Voice
Vietnamese: Standard Voice vs WaveNet Voice
Mandarin Chinese: Standard Voice vs WaveNet Voice
Japanese: Standard Voice vs WaveNet Voice
For a demo using text of your choosing, test-drive the example UI we built using the Cloud Text-to-Speech API.
Next steps
Cloud Text-to-Speech is free to use up to the first million characters processed by the API, so it’s easy to get started by building a simple test/demo app using your own data. We look forward to seeing what you build!



