Making AI-powered speech more accessible—now with more options, lower prices, and new languages and voices
Dan Aharon
Product Manager, Speech
The ability to recognize and synthesize speech is critical for making human-machine interaction natural, easy, and commonplace, but it’s still too rare. Today we're making our Cloud Speech-to-Text and Text-to-Speech products more accessible to companies around the world, with more features, more voices (roughly doubled), more languages in more countries (up 50+%), and at lower prices (by up to 50% in some cases).
Making Cloud Speech-to-Text more accessible for enterprises
When creating intelligent voice applications, speech recognition accuracy is critical. Even at 90% accuracy, it's hard to have a useful conversation. Unfortunately, many companies build speech applications that need to run on phone lines and that produce noisy results, and that data has historically been hard for AI-based speech technologies to interpret.

For these situations with less than pristine data, we announced premium models for video and enhanced phone in beta last year, developed with customers who opted in to share usage data with us via data logging to help us refine model accuracy. We are excited to share today that the resulting enhanced phone model now has 62% fewer transcription errors (improved from 54% last year), while the video model, which is based on technology similar to what YouTube uses for automatic captioning, has 64% fewer errors. In addition, the video model also works great in settings with multiple speakers such as meetings or podcasts.
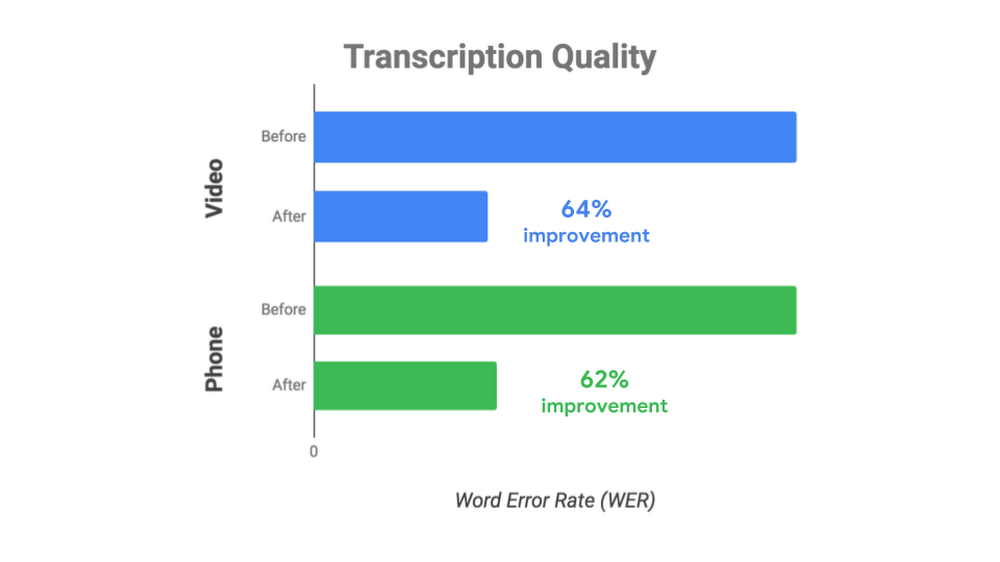
The enhanced phone model was initially available only to customers participating in the opt-in data logging program announced last year. However, many large enterprises have been asking us for the option to use the enhanced model without opting into data logging. Starting today, anyone can access the enhanced phone model, and customers who choose the data logging option pay a lower rate, bringing the benefits of improved accuracy to more users.
In addition to the general availability of both premium models, we’re also announcing the general availability of multi-channel recognition, which helps the Cloud Speech-to-Text API distinguish between multiple audio channels (e.g., different people in a conversation), which is very useful for doing call or meeting analytics and other use cases involving multiple participants. With general availability, all these features now qualify for an SLA and other enterprise-level guarantees.
Cloud Speech-to-Text at LogMeIn
LogMeIn is an example of a customer that requires both accuracy and enterprise scale: Every day, millions of employees use its GoToMeeting product to attend an online meeting. Cloud Speech-to-Text lets LogMeIn automatically create transcripts for its enterprise GoToMeeting customers, enabling users to collaborate more effectively.
“LogMeIn continues to be excited about our work with Google Cloud and its market-leading video and real-time speech to text technology. After an extensive market study for the best Speech-to-Text video partner, we found Google to be the highest quality and offered a useful array of related technologies. We continue to hear from our customers that the feature has been a way to add significant value by capturing in-meeting content and making it available and shareable post-meeting. Our work with Google Cloud affirms our commitment to making intelligent collaboration a fundamental part of our product offering to ultimately add more value for our global UCC customers.” - Mark Strassman, SVP and General Manager, Unified Communications and Collaboration (UCC) at LogMeIn.
Making Cloud Speech-to-Text more accessible through lower pricing (up to 50% cheaper)
Lowering prices is another way we are making Cloud Speech-to-Text more accessible. Starting now:
- For standard models and the premium video model, customers that opt-in to our data logging program will now pay 33% less for all usage that goes through the program.
- We’ve cut pricing for the premium video model by 25%, for a total savings of 50% for current video model customers who opt-in to data logging.

Making Cloud Text-to-Speech accessible across more countries
We’re also excited to help enterprises benefit from our research and experience in speech synthesis. Thanks to unique access to WaveNet technology powered by Google Cloud TPUs, we can build new voices and languages faster and easier than is typical in the industry: Since our update last August, we’ve made dramatic progress on Cloud Text-to-Speech, roughly doubling the number of overall voices, WaveNet voices, and WaveNet languages, and increasing the number of supported languages overall by ~50%, including:
- Support for seven new languages or variants, including Danish, Portuguese/Portugal, Russian, Polish, Slovakian, Ukrainian, and Norwegian Bokmål (all in beta). This update expands the list of supported languages to 21 and enables applications for millions of new end-users.
- 31 new WaveNet voices (and 24 new standard voices) across those new languages. This gives more enterprises around the world access to our speech synthesis technology, which based on mean opinion score has already closed the quality gap with human speech by 70%. You can find the complete list of languages and voices here.
- 20 languages and variants with WaveNet voices, up from nine last August--and up from just one a year ago when Cloud Text-to-Speech was introduced, marking a broad international expansion for WaveNet.

In addition, the Cloud Text-to-Speech Device Profiles feature, which optimizes audio playback on different types of hardware, is now generally available. For example, some customers with call center applications optimize for interactive voice response (IVR), whereas others that focus on content and media (e.g., podcasts) optimize for headphones. In every case, the audio effects are customized for the hardware.
Get started today
It’s easy to give Cloud Speech products a try—check out the simple demos on the Cloud Speech-to-Text and Cloud Text-to-Speech landing pages. If you like what you see, you can use the $300 GCP credit to start testing. And as always, the first 60 minutes of audio you process every month with Cloud Speech-to-Text is free.



