Toward better phone call and video transcription with new Cloud Speech-to-Text
Dan Aharon
Product Manager, Speech
It’s been full speed ahead for our Cloud AI speech products as of late. Last month, we introduced Cloud Text-to-Speech, our speech synthesis API featuring DeepMind WaveNet models. And today, we’re announcing the largest overhaul of Cloud Speech-to-Text (formerly known as Cloud Speech API) since it was introduced two years ago.
We first unveiled the Cloud Speech API in 2016, and it’s been generally available for almost a year now, with usage more than doubling every six months. Today, with the opening of NAB and SpeechTek conferences, we’re introducing new features and updates that we think will make Speech-to-Text much more useful for business, including phone-call and video transcription.
Cloud Speech-to-Text now supports:
- A selection of pre-built models for improved transcription accuracy from phone calls and video
- Automatic punctuation, to improve readability of transcribed long-form audio
- A new mechanism (recognition metadata) to tag and group your transcription workloads, and provide feedback to the Google team
- A standard service level agreement (SLA) with a commitment to 99.9% availability
New video and phone call transcription models
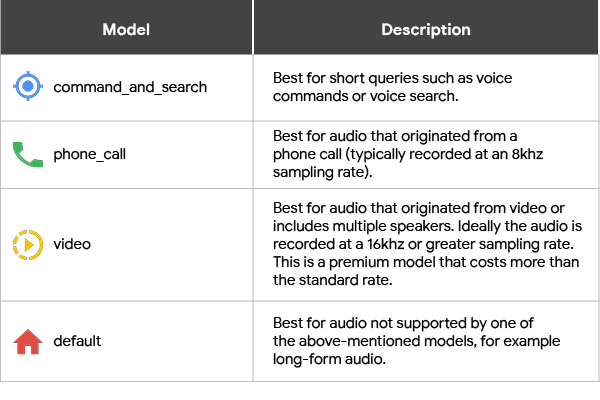
There are lots of different ways to use speech recognition technology—everything from human-computer interaction (e.g., voice commands or IVRs) to speech analytics (e.g., call center analytics). In this version of Cloud Speech-to-Text, we’ve added models that are tailored for specific use cases— e.g., phone call transcriptions and transcriptions of audio from video.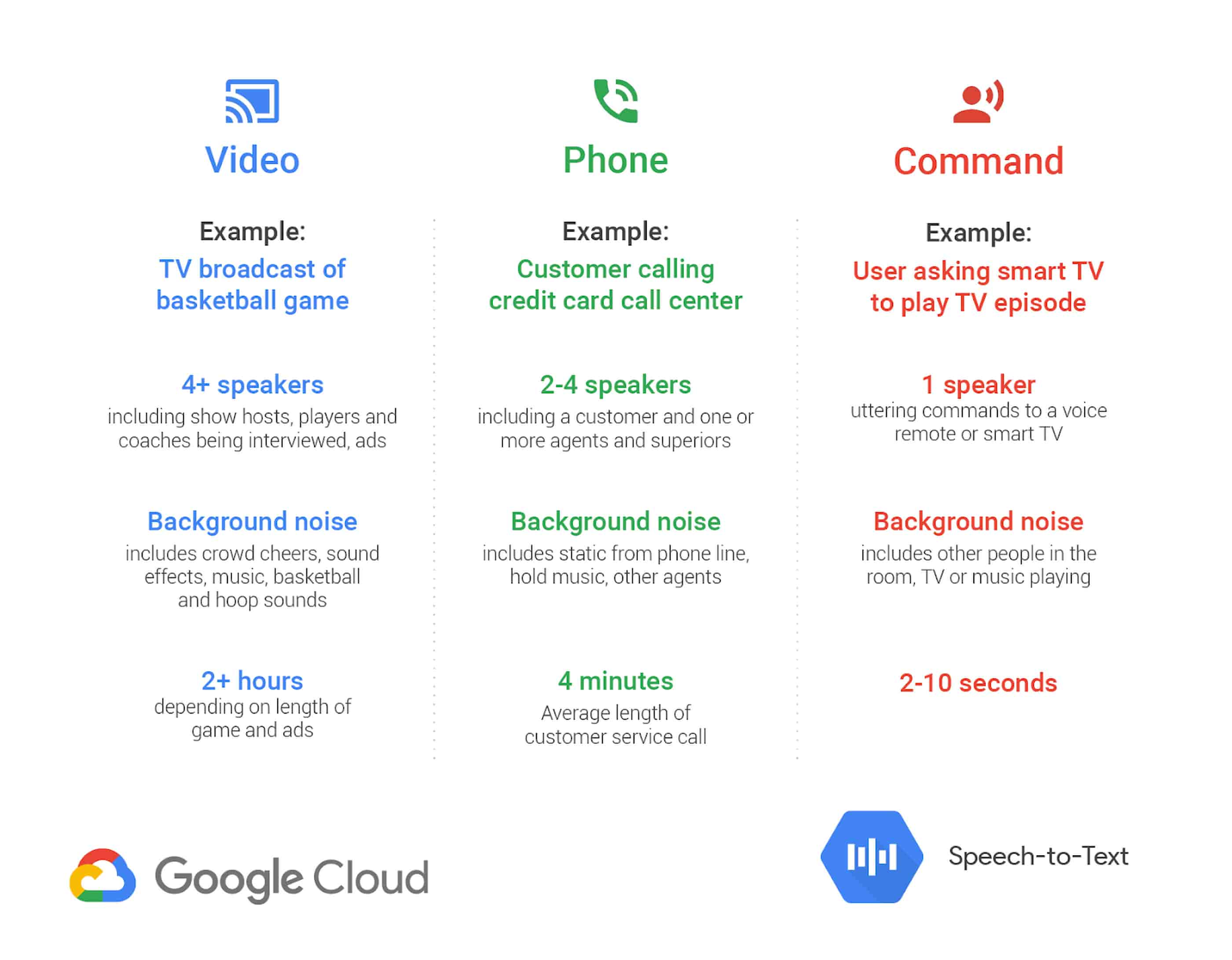
For example, for processing phone calls, we’ve routed incoming English US phone call requests to a model that's optimized to handle phone calls and is considered by many customers to be best-in-class in the industry. Now we’re giving customers the power to explicitly choose the model that they prefer rather than rely on automatic model selection.
Most major cloud providers use speech data from incoming requests to improve their products. Here at Google Cloud, we’ve avoided this practice, but customers routinely request that we use real data that's representative of theirs, to improve our models. We want to meet this need, while being thoughtful about privacy and adhering to our data protection policies. That’s why today, we’re putting forth one of the industry’s first opt-in programs for data logging, and introducing a first model based on this data: enhanced phone_call.
We developed the enhanced phone_call model using data from customers who volunteered to share their data with Cloud Speech-to-Text for model enhancement purposes. Customers who choose to participate in the program going forward will gain access to this and other enhanced models that result from customer data. The enhanced phone_call model has 54% fewer errors than our basic phone_call model for our phone call test set.
In addition, we’re also unveiling the video model, which has been optimized to process audio from videos and/or audio with multiple speakers. The video model uses machine learning technology similar to that used by YouTube captioning, and shows a 64% reduction in errors compared to our default model on a video test set.
Both the enhanced phone_call and premium-priced video model are now available for en-US transcription and will soon be available for additional languages. We also continue to offer our existing models for voice command_and_search, as well as our default model for longform transcription.
Check out the demo on our product website to upload an audio file and see transcription results from each of these models.
Generate readable text with automatic punctuation
Most of us learn how to use basic punctuation (commas, periods, question marks) by the time we leave grade school. But properly punctuating transcribed speech is hard to do. Here at Google, we learned just how hard it can be from our early attempts at transcribing voicemail messages, which produced run-on sentences that were notoriously hard to read.Check out the demo on our product website to upload an audio file and see transcription results from each of these models.
Generate readable text with automatic punctuation
Most of us learn how to use basic punctuation (commas, periods, question marks) by the time we leave grade school. But properly punctuating transcribed speech is hard to do. Here at Google, we learned just how hard it can be from our early attempts at transcribing voicemail messages, which produced run-on sentences that were notoriously hard to read.Unstructured data, like audio, is full of rich information but many businesses struggle to find applications that make it easy to extract value from it and manage it. Descript makes it easier to edit and view audio files, just like you would a document. We chose to power our application with Google Cloud Speech-to-Text. Based on our testing, it’s the most advanced speech recognition technology and the new video model had half as many errors as anything else we looked at. And, with its simple pricing model, we’re able to offer the best prices for our users.
Andrew Mason, CEO, Descript
LogMeIn’s GoToMeeting provides market leading collaboration software to millions of users around the globe. We are always looking for the best customer experience and after evaluating multiple solutions to allow our users to transcribe meetings we found Google’s Cloud Speech-to-Text’s new video model to be far more accurate than anything else we’ve looked at. We are excited to work with Google to help drive value for our customers beyond the meeting with the addition of transcription for GoToMeeting recordings.
Matt Kaplan, Chief Product Officer, Collaboration Products at LogMeIn
At InteractiveTel, we've been using Cloud Speech-to-Text since the beginning to power our real-time telephone call transcription and analytics products. We've constantly been amazed by Google's ability to rapidly improve features and performance, but we were stunned by the results obtained when using the new phone_call model. Just by switching to the new phone_call model we experienced accuracy improvements in excess of 64% when compared to other providers, and 48% when compared to Google's generic narrow-band model.
Jon Findley, Lead Product Engineer, InteractiveTel
Access to quality speech transcription technology opens up a world of possibilities for companies that want to connect with and learn from their users. With this update to Cloud Speech-to-Text, you get access to the latest research from our team of machine learning experts, all through a simple REST API. Pricing is $0.006 per 15 seconds of audio for all models except the video model, which is $0.012 per 15 seconds. We'll be providing the new video model for the same price ($0.006 per 15 seconds) for a limited trial period through May 31. To learn more, try out the demo on our product page or visit our documentation.



