Unlock Inference-as-a-Service with Cloud Run and Vertex AI
Jason (Jay) Smith
Customer Engineer - AppMod Specialist
It’s no secret that large language models (LLMs) and generative AI have become a key part of the application landscape. But most foundational LLMs are consumed as a service, meaning they're hosted and served by a third party and accessed via APIs. Ultimately, this reliance on external APIs creates bottlenecks for developers.
There are many proven ways to host applications. Until lately, the same couldn't be said of the LLMs those applications depend on. To improve velocity, developers can consider an approach called Inference-as-a-Service. Let's explore how this approach can drive your LLM-powered applications.
What is Inference-as-a-Service?
When it comes to the cloud, everything is a service. For example, rather than buying physical servers to host your applications and databases, cloud providers use them as a metered service. The key word here is “metered.” As an end user, you pay online for the compute time and storage you use. Phrases such as “Software-as-a-Service”, “Platform-as-a-Service”, and “Functions-as-a-Service” have been in the cloud glossary for over a decade.
With “Inference-as-a-Service”, an enterprise application interfaces with the machine learning model (in this case, the LLM), with low operational overhead. This means you can run your code to interface with the LLM without focusing on infrastructure.
Why Cloud Run for Inference-as-a-Service
Cloud Run is Google Cloud’s serverless container platform. In short, it helps developers leverage container runtimes without having to concern themselves with the infrastructure. Historically, serverless has centered around functions. This is why Cloud Run is a good fit for driving your LLM-powered applications – you only pay when the service is running.
There are many ways to use Cloud Run to inference with LMMs. Today, we’ll explore how to host open LLMs on Cloud Run with GPUs.
First, get familiar with Vertex AI. Vertex AI is Google Cloud’s all-in-one AI/ML platform that offers the primitives required for an enterprise to train and serve ML models. In Vertex AI, you can access Model Garden, which offers over 160 foundation models including first-party models (Gemini), third-party, and open source models.
To inference with Vertex AI, activate the Gemini API first. You can use Vertex AI’s standard or express mode to inference. Then, by simply adding the right Google Cloud credentials into your application, you can deploy the application as a container on Cloud Run and it will seamlessly inference with Vertex AI. You can try this yourself with this GitHub sample.
While Vertex AI provides managed inference endpoints, Google Cloud also offers a new level of flexibility with GPUs for Cloud Run. This fundamentally shifts the inference paradigm. Why? Because instead of relying solely on Vertex AI's infrastructure, you can now containerize your LLM (or other models) and deploy them directly to Cloud Run.
This means you're not just building a serverless layer around an LLM, but you're hosting the LLM itself on a serverless architecture. Models scale to zero when inactive, and scale dynamically with demand, optimizing costs and performance. For example, you could host an LLM on one Cloud Run service and a chat agent on another, enabling independent scaling and management. And with GPU acceleration, a Cloud Run service can be ready for inference in under 30 seconds.
Tailor your LLM with RAG
Beyond hosting and scaling LLMs, you'll often need to tailor their responses to specific domains or datasets. This is where Retrieval-Augmented Generation (RAG) comes into play, a core component of extending your LLM experience – and one that’s quickly becoming the standard for contextual customization.
Think of it this way: LLMs are trained on broad datasets, but your applications need to leverage your data. RAG uses a vector database, like AlloyDB, to store embeddings of your private data. When your application queries an LLM, RAG retrieves relevant embeddings, providing the LLM with the necessary context to generate highly specific and accurate responses.
There are a few ways Inference-as-a-Service comes into play. For example, when looking at this architecture, we see that Cloud Run handles the core inference logic, orchestrating interactions between Vertex AI and AlloyDB. Specifically, it serves as the bridge for both fetching data from AlloyDB and passing queries to Vertex AI, effectively managing the entire RAG data flow.
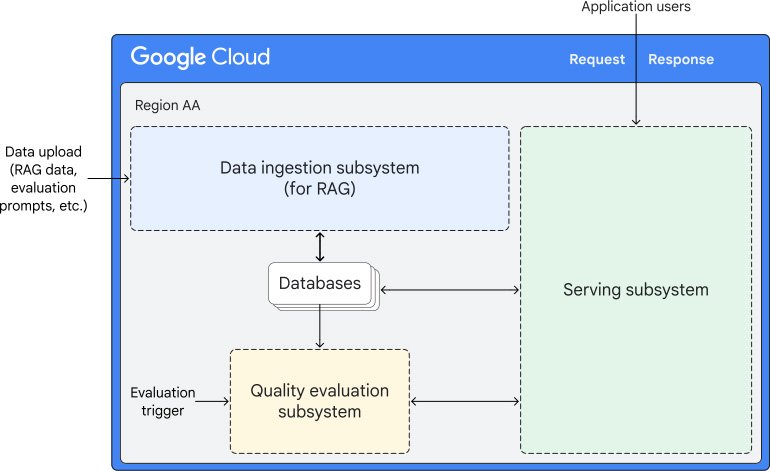
Let’s take an example
Consider a chatbot architecture. The architecture below uses Cloud Run to host our chatbot. Our developer is able to write an application using common chatbot tools such as Streamlit and Langchain. It can then inference with LLMs hosted in the Vertex AI Model Garden (or it could use another Cloud Run instance) and then store embeddings into AlloyDB. This gives you a customizable gen AI chatbot – all on a serverless runtime.




