Announcing updates to Cloud Speech-to-Text and the general availability of Cloud Text-to-Speech
Dan Aharon
Product Manager, Speech
Speech recognition and synthesis are two of Google Cloud’s hallmark ML-based services—in no small part due to underlying advanced AI research. Today, we’re announcing the general availability of Cloud Text-to-Speech, which also now offers multilingual access to DeepMind WaveNet voices and speaker optimization. We’re also sharing more on recent updates to Cloud Speech-to-Text that offer a wider feature-set and address needs around availability and reliability.
Here’s more on today’s updates:
Cloud Text-to-Speech: now generally available
Less than two years after DeepMind published the original model, and less than one year since the updated WaveNet research, Cloud Text-to-Speech is now generally available and ready for your production workloads. This is another way we’re making advanced AI more accessible to everyone.
WaveNet voices now available in 17 languages
Since we announced Cloud Text-to-Speech in March, one of our top customer requests has been to expand our WaveNet voice portfolio beyond US English. WaveNet voices mimic human voices and sound more natural, providing a much better experience for users. The addition of 17 new WaveNet voices allows Cloud Text-to-Speech customers to build apps in many more languages, targeting a much larger user population. Cloud Text-to-Speech now supports 14 languages and variants, with 56 total voices including 30 standard voices, and 26 WaveNet voices. You can find the full list on this page.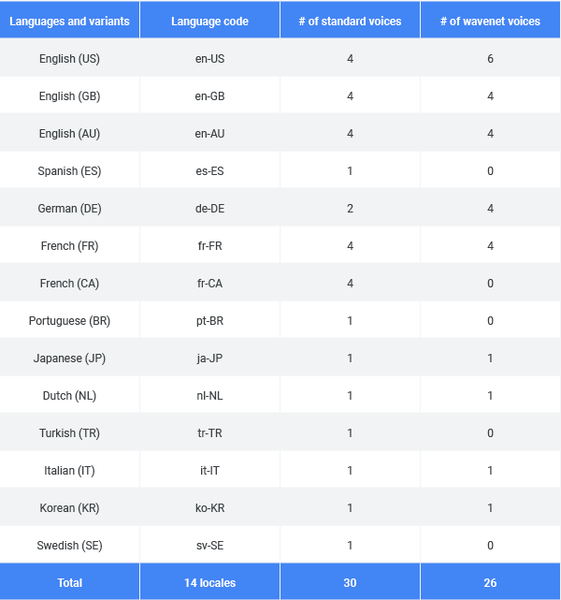
Tune the output to your audience with Audio Profiles (beta)
From headphones to speakers to phone lines, audio files can sound quite different on different playback media and mechanisms. The physical properties of each device, as well as the environment they are placed in, influence the range of frequencies and level of detail they produce (e.g., bass, treble and volume). With the release of Audio Profiles, you can optimize Cloud Text-to-Speech for playback on different types of hardware. You can now specify whether audio is intended to be played over phone lines, headphones, or speakers, and we’ll optimize the audio for playback. For example, if the audio your application produces is listened to primarily on headphones, you can create synthetic speech from Cloud Text-to-Speech API that is optimized specifically for headphones.
In the animation below you can see an audio sample that is intended to be played over the phone. The areas on the left and right would not be audible to the listener because phone calls are bandwidth-limited to exclude bass and treble frequencies. Cloud Text-to-Speech moves audio from frequencies that aren’t audible to the audible spectrum, enhancing the clarity of the voice for improved intelligibility. The resulting audio sample might actually sound worse than the original sample on laptop speakers, but will sound better on a phone line.

Ingram Content Group, a supplier to the publishing industry, is one company already taking advantage of Cloud Text-to-Speech. “At Ingram, we are working towards a vision of the world where anyone, no matter where they are, has easy access to the books they want,” says Deanna Steele, CIO. “Text-to-Speech helps make that possible, but hinges on understandability, and we found that understandability with Google. Not only that, but with Cloud Text-to-Speech's WaveNet voices, we found the listening experience to be enjoyable. We are using Cloud Text-to-Speech to create a scalable and natural sounding voice solution to let our users access book previews for over 18 million titles.”
Cloud Speech-to-Text: new beta updates
At Next ‘18 in July, we announced new beta features have recently been added to Cloud Speech-to-Text. Here’s more on those features.
Separate different speakers with speaker diarization and multi-channel recognition
For speech analytics use cases (where you’re interpreting multiple people talking to each other rather than voice commands), developers often need to transcribe audio samples that include more than one speaker. Separating the speakers in the transcription then becomes a critical next step for most types of analysis, including sentiment analysis with Cloud Natural Language.
You can achieve the best transcription quality when each speaker is separated into its own audio channel—for example, using a pair of stereo channels for a customer and the corresponding support agent on a phone call. For this use case, we now provide multi-channel recognition that can transcribe multiple channels of audio, denoting the separate channels for each word so you know who said what.
For audio samples that aren’t separated into channels, we now provide speaker diarization. This lets you input the number of speakers as an API parameter and through machine learning, Cloud Speech-to-Text will tag each word with a speaker number. Speaker tags attached to each word are continuously updated as more and more data is received, so Cloud Speech-to-Text becomes increasingly more accurate at identifying who is speaking, and what they said.
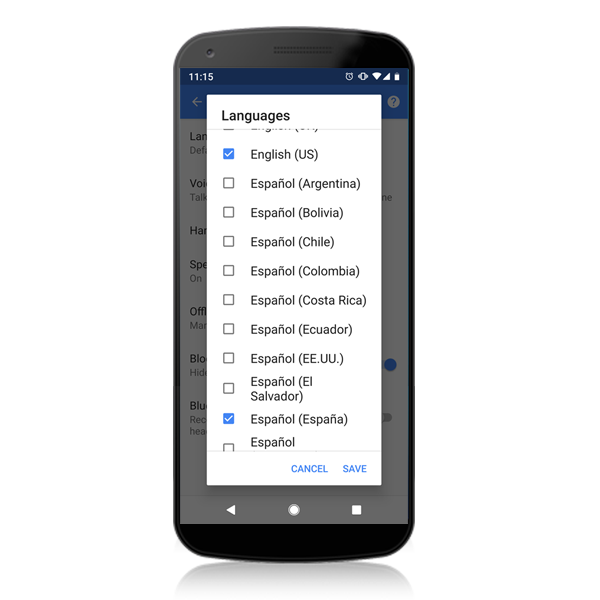
Build apps that can accept multiple languages with language auto-detect
Some users—for example, bilingual speakers—want the ability to alternate between a few languages when using voice commands. To help, we made it possible for users of the Google Search App to select multiple languages, enabling the app to automatically detect which language was being spoken. Many of our Cloud customers have asked for similar capability when building their own apps, which is why we’ve introduced language auto-detect. This means developers that need voice search and command functionality can send up to four language codes in each query to Cloud Speech-to-Text, and the API will automatically determine which language was spoken and return the transcript in that language. Your users can select which languages they may choose to input so they have flexibility in their interaction with the app.
Word-level confidence
Cloud Speech-to-Text has always returned a confidence score for each segment of speech. However, many of our users have asked for more fine-grained control, which is why we now offer word-level confidence scores. These scores allow developers to build apps that can highlight specific words, and then depending on the score, write code to prompt users to repeat those words as needed. For example, if a user inputs “please setup a meeting with John for tomorrow at 2PM” into your app, you can decide to prompt the user to repeat “John” or “2PM,” if either have low confidence, but not to prompt for “please” even if has low confidence since it’s not critical to that particular sentence.
We hope these added features make it easier to create smarter speech-enabled applications, and we’re excited to see what you build. To learn more, and try out product demos, visit Cloud Text-to-Speech and Cloud Speech-to-Text on our website.


