In diesem Dokument wird beschrieben, wie Sie Apache Spark-Jobs nach Dataproc verschieben können. Das Dokument richtet sich an Big-Data-Entwickler und -Architekten. Es behandelt Themen wie Migration, Vorbereitung, Jobmigration und Management.
Übersicht
Wenn Sie Ihre Apache Spark-Arbeitslasten aus einer lokalen Umgebung zu Google Cloud verschieben möchten, empfehlen wir die Verwendung von Dataproc zum Ausführen von Apache Spark/Apache Hadoop-Clustern. Dataproc ist ein vollständig verwalteter und unterstützter Dienst von Google Cloud. Sie können Speicher und Computing voneinander trennen, wodurch Sie Ihre Kosten besser verwalten und Arbeitslasten flexibler skalieren können.
Wenn eine verwaltete Hadoop-Umgebung nicht Ihren Anforderungen entspricht, können Sie auch eine andere Bereitstellung verwenden, z. B. Spark auf Google Kubernetes Engine (GKE) ausführen oder virtuelle Maschinen für die Compute Engine mieten und einen Hadoop- oder Spark-Cluster selbst einrichten. Wenn Sie aber statt Dataproc andere Optionen verwenden, müssen Sie diese selber verwalten und erhalten nur Community-Support.
Migration planen
Zwischen der lokalen Ausführung von Spark-Jobs und der Ausführung in Dataproc- oder Hadoop-Clustern in Compute Engine bestehen zahlreiche Unterschiede. Es ist wichtig, die Arbeitslast genau abzuschätzen und sich auf die Migration vorzubereiten. In diesem Abschnitt wird beschrieben, welche Überlegungen und Vorbereitungen für die Migration von Spark-Jobs erforderlich sind.
Jobtypen identifizieren und Cluster planen
Es gibt drei Arten von Spark-Arbeitslasten, die im Folgenden beschrieben werden:
Regelmäßig geplante Batchjobs
Regelmäßig geplante Batchjobs umfassen Anwendungsfälle wie tägliche oder stündliche ETL-Prozesse oder Pipelines für das Trainieren von Modellen für maschinelles Lernen mit Spark ML. In diesen Fällen wird empfohlen, dass Sie für jede Batcharbeitslast einen Cluster erstellen und den Cluster anschließend löschen, nachdem der Job abgeschlossen ist. Sie können Cluster flexibel konfigurieren, da Sie die Konfiguration für jede Arbeitslast separat anpassen können. Dataproc-Cluster werden nach der ersten Minute im Sekundentakt abgerechnet, sodass dieser Ansatz auch kostengünstig ist, da Sie die Cluster mit Labels kennzeichnen können. Weitere Informationen finden Sie auf der Seite Dataproc – Preise.
Sie können Batch-Jobs mit Workflowvorlagen oder wie folgt implementieren:
Erstellen Sie einen Cluster und warten Sie, bis der Vorgang abgeschlossen ist. Sie können mit einem API-Aufruf oder einem gcloud-Befehl feststellen, ob der Cluster erstellt wurde. Wenn Sie den Job in einem dedizierten Dataproc-Cluster ausführen, kann es hilfreich sein, die dynamische Zuordnung und den externen Shuffle-Dienst zu deaktivieren. Der folgende
gcloud-Befehl enthält Spark-Konfigurationsattribute, die beim Erstellen des Dataproc-Clusters verfügbar sind:dataproc clusters create ... \ --properties 'spark:spark.dynamicAllocation.enabled=false,spark:spark.shuffle.service.enabled=false,spark.executor.instances=10000'Senden Sie den Job an den Cluster. Sie können den Status des Jobs mithilfe eines API-Aufrufs oder eines gcloud-Befehls überwachen. Beispiel:
jobId=$(gcloud --quiet dataproc jobs submit pyspark \ --async \ --format='value(reference.jobId)' \ --cluster $clusterName \ --region global \ gs://dataproc-examples-2f10d78d114f6aaec76462e3c310f31f/src/pyspark/hello-world/hello-world.py) gcloud dataproc jobs describe $jobId \ --region=global \ --format='value(status.state)'Löschen Sie den Cluster mit einem API-Aufruf oder einem gcloud-Befehl, nachdem der Job ausgeführt wurde.
Streamingjobs
Für Streamingjobs müssen Sie einen Dataproc-Cluster mit langer Laufzeit erstellen und diesen für die Ausführung im Modus für hohe Verfügbarkeit konfigurieren. Es wird nicht empfohlen, für diesen Fall VMs auf Abruf zu verwenden.
Ad-hoc- oder interaktive Arbeitslasten, die von Nutzern gesendet werden
Beispiele für Ad-hoc-Arbeitslasten sind Anwendungsfälle, in denen Nutzer tagsüber Abfragen schreiben oder Analysejobs ausführen.
In diesen Fällen müssen Sie entscheiden, ob der Cluster im Modus für hohe Verfügbarkeit ausgeführt werden soll, ob Sie VMs auf Abruf verwenden möchten und wie Sie den Zugriff auf den Cluster verwalten. Sie können das Erstellen und Beenden der Cluster planen (z. B. wenn Sie den Cluster in der Nacht oder an Wochenenden nie benötigen) und Sie können nach diesem Zeitplan eine Skalierung nach oben und unten implementieren.
Datenquellen und Abhängigkeiten identifizieren
Jeder Job hat seine eigenen Abhängigkeiten (z. B. die Datenquellen, die er benötigt) und andere Teams in Ihrem Unternehmen sind möglicherweise vom Ergebnis solcher Jobs abhängig. Daher müssen Sie alle Abhängigkeiten ermitteln und anschließend einen Migrationsplan mit folgenden Aktionen erstellen:
Schrittweise Migration aller Datenquellen zu Google Cloud. Am Anfang ist es hilfreich, die Datenquelle in Google Cloud zu spiegeln, sodass sie an zwei Stellen verfügbar ist.
Jobweise Migration der Spark-Arbeitslasten zu Google Cloud, sobald die entsprechenden Datenquellen migriert wurden. Wie bei den Daten werden eventuell auch hier zeitweise zwei Arbeitslasten in der alten Umgebung und in Google Cloud parallel ausgeführt.
Migration anderer Arbeitslasten, die von der Ausgabe der Spark-Arbeitslasten abhängen. Alternativ können Sie die Ausgabe einfach wieder in die ursprüngliche Umgebung replizieren.
Beenden der Spark-Jobs in der alten Umgebung, nachdem alle betroffenen Teams bestätigt haben, dass sie die Jobs nicht mehr benötigen.
Speicheroptionen wählen
Es gibt zwei Speicheroptionen, die mit Dataproc-Clustern verwendet werden können: Sie können alle Daten in Cloud Storage speichern oder alternativ lokale Laufwerke oder nichtflüchtigen Speicher mit den Cluster-Workern verwenden. Die richtige Wahl hängt von der Art der Jobs ab.
Vergleich von Cloud Storage und HDFS
Auf jedem Knoten eines Dataproc-Clusters ist ein Cloud Storage-Connector installiert. Standardmäßig wird der Connector unter /usr/lib/hadoop/lib installiert. Der Connector implementiert die Hadoop-Klasse FileSystem als Schnittstelle und gewährleistet die Kompatibilität zwischen Cloud Storage und dem HDFS.
Da Cloud Storage ein BLOB-Speichersystem (Binary Large Object) ist, emuliert der Connector Verzeichnisse entsprechend dem Namen des Objekts. Sie können auf Ihre Daten zugreifen. Verwenden Sie dafür das Präfix gs:// anstelle des Präfixes hdfs://.
Der Cloud Storage-Connector muss normalerweise nicht angepasst werden. Sollten Sie jedoch Änderungen vornehmen müssen, folgen Sie der Anleitung Connector konfigurieren. Auch die vollständige Liste der Konfigurationsschlüssel ist hier verfügbar.
Cloud Storage ist in folgenden Fällen eine gute Option:
- Wenn Ihre Daten in ORC, Parquet, Avro oder einem anderen Format von verschiedenen Clustern oder Jobs verwendet werden und die Daten nach dem Beenden des Clusters erhalten bleiben sollen.
- Wenn Sie einen hohen Durchsatz benötigen und Ihre Daten in Dateien gespeichert werden, die größer als 128 MB sind.
- Wenn Sie für Ihre Daten eine zonenübergreifende Langlebigkeit benötigen.
- Wenn Sie für Ihre Daten Hochverfügbarkeit benötigen, etwa, wenn Sie HDFS NameNode als "Single Point of Failure" umgehen möchten.
Der lokale HDFS-Speicher ist in folgenden Fällen eine gute Option:
- Wenn für Ihre Jobs viele Metadatenvorgänge benötigt werden, etwa wenn Tausende von Partitionen und Verzeichnissen vorhanden, die Dateien aber verhältnismäßig klein sind.
- Wenn Sie die HDFS-Daten häufig ändern oder Verzeichnisse umbenennen; Cloud Storage-Objekte sind unveränderlich, d. h., das Umbenennen eines Verzeichnisses ist kostenintensiv, weil alle Objekte auf einen neuen Schlüssel kopiert und anschließend gelöscht werden müssen.
- Wenn Sie für HDFS-Dateien häufig den Append-Vorgang nutzen.
Wenn Ihre Arbeitslasten intensive E/A-Vorgänge erfordern, beispielsweise bei vielen partitionierten Schreibvorgängen wie z. B.:
spark.read().write.partitionBy(...).parquet("gs://")Wenn Ihre E/A-Arbeitslasten besonders empfindlich auf Latenzen reagieren, zum Beispiel wenn Sie pro Speichervorgang eine Latenz im einstelligen Millisekundenbereich benötigen
Im Allgemeinen empfehlen wir die Verwendung von Cloud Storage als erste und letzte Datenquelle in einer Big-Data-Pipeline. Wenn ein Workflow beispielsweise fünf aufeinanderfolgende Spark-Jobs enthält, ruft der erste Job die ursprünglichen Daten aus Cloud Storage ab und schreibt dann die Shuffle-Daten und die Zwischenausgaben von Jobs in HDFS. Der letzte Spark-Job schreibt seine Ergebnisse wieder in Cloud Storage.
Speichergröße anpassen
Durch die Verwendung von Dataproc mit Cloud Storage können Sie die Laufwerksanforderungen reduzieren und die Kosten senken. Legen Sie dazu die Daten dort und nicht im HDFS ab. Wenn Sie die Daten in Cloud Storage und nicht im lokalen HDFS speichern, können Sie für den Cluster kleinere Laufwerke verwenden. Wenn Sie den Cluster wirklich bedarfsgerecht gestalten, können Sie, wie bereits erwähnt, auch Speicher und Datenverarbeitung voneinander trennen, wodurch Sie die Kosten erheblich senken können.
Auch wenn Sie alle Daten in Cloud Storage speichern, benötigt der Dataproc-Cluster HDFS für bestimmte Vorgänge wie beispielsweise die Speicherung von Steuerungs- und Wiederherstellungsdateien und das Zusammenfassen von Logs. Außerdem benötigt er für das Shuffling auch lokalen Laufwerksspeicher, der nicht mit HDFS formatiert ist. Wenn Sie das lokale HDFS nicht intensiv nutzen, können Sie die Festplattengröße pro Worker reduzieren.
Im Folgenden sind einige Optionen zur Anpassung der Größe des lokalen HDFS aufgeführt:
- Verringern Sie die Gesamtgröße des lokalen HDFS durch Reduzierung der Größe der primären nichtflüchtigen Speicher für Master und Worker. Der primäre nichtflüchtige Speicher enthält auch das Start-Volume und die Systembibliotheken. Weisen Sie also mindestens 100 GB zu.
- Erhöhen Sie die Gesamtgröße des lokalen HDFS durch Steigerung der Größe des primären nichtflüchtigen Speichers für die Worker. Nutzen Sie diese Option mit Bedacht. Es gibt nur selten Arbeitslasten, bei denen durch die Verwendung von HDFS mit nichtflüchtigen Standardspeichern eine bessere Leistung erzielt wird als durch die Verwendung von Cloud Storage oder eines lokalen HDFS mit SSD.
- Hängen Sie jedem Worker bis zu acht SSDs (je 375 GB) an und verwenden Sie diese Laufwerke für das HDFS. Dies ist eine gute Option, wenn Sie das HDFS für E/A-intensive Arbeitslasten benötigen und eine Latenz im einstelligen Millisekundenbereich erforderlich ist. Achten Sie darauf, dass ein Maschinentyp verwendet wird, der genügend CPUs und Arbeitsspeicher zur Unterstützung dieser Laufwerke hat.
- Verwenden Sie für den Master oder die Worker nichtflüchtigen SSD-Speicher (PD-SSDs) als primären Speicher.
Auf Dataproc zugreifen
Der Zugriff auf Dataproc oder Hadoop in Compute Engine unterscheidet sich vom Zugriff auf einen lokalen Cluster. Sie müssen im vorliegenden Fall Sicherheitseinstellungen und Netzwerkzugriffsoptionen selbst festlegen.
Netzwerk
Alle VM-Instanzen eines Dataproc-Clusters erfordern ein internes Netzwerk sowie offene UDP-, TCP- und ICMP-Ports. Sie können den Zugriff auf Ihren Dataproc-Cluster von externen IP-Adressen aus zulassen. Verwenden Sie dafür die Standardnetzwerkkonfiguration oder ein VPC-Netzwerk. Ihr Dataproc-Cluster hat Netzwerkzugriff auf alle Google Cloud-Dienste (Cloud Storage-Buckets, APIs usw.) mit allen von Ihnen verwendeten Netzwerkoptionen. Wählen Sie eine VPC-Netzwerkkonfiguration aus und richten Sie die entsprechenden Firewallregeln ein, um den Netzwerkzugriff auf lokale Ressourcen oder von diesen aus zu ermöglichen. Weitere Informationen finden Sie in der Anleitung Dataproc-Cluster – Netzwerkkonfiguration und im Abschnitt Auf YARN zugreifen weiter unten.
Identitäts- und Zugriffsverwaltung
Zusätzlich zum Netzwerkzugriff benötigt Ihr Dataproc-Cluster Berechtigungen, um auf Ressourcen zuzugreifen. Wenn Sie beispielsweise Daten in einen Cloud Storage-Bucket schreiben möchten, muss der Dataproc-Cluster Schreibzugriff für den Bucket haben. Den Zugriff richten Sie mithilfe von Rollen ein. Identifizieren Sie in Ihrem Spark-Code alle nicht zu Dataproc gehörenden Ressourcen, die der Code benötigt, und weisen Sie dem Dienstkonto des Clusters die entsprechenden Rollen zu. Achten Sie auch darauf, dass Nutzer, die Cluster, Jobs, Vorgänge und Workflowvorlagen erstellen, die erforderlichen Berechtigungen haben.
Weitere Informationen und Best Practices finden Sie in der IAM-Dokumentation.
Abhängigkeiten von Spark und anderen Bibliotheken prüfen
Vergleichen Sie Ihre Version von Spark und die Versionen anderer Bibliotheken mit der offiziellen Versionsliste von Dataproc und suchen Sie nach Bibliotheken, die noch nicht verfügbar sind. Es wird empfohlen, Spark-Versionen zu verwenden, die offiziell von Dataproc unterstützt werden.
Wenn Sie Bibliotheken hinzufügen müssen, können Sie so vorgehen:
- Erstellen Sie ein benutzerdefiniertes Image eines Dataproc-Clusters.
- Erstellen Sie in Cloud Storage Initialisierungsskripts für den Cluster. Sie können mithilfe von Initialisierungsskripts zusätzliche Abhängigkeiten installieren, Binärdateien kopieren usw.
- Kompilieren Sie den Java- oder Scala-Code neu und packen Sie alle zusätzlichen Abhängigkeiten, die nicht Teil der Basisdistribution sind, mithilfe von Gradle, Maven, Sbt oder einem anderen Tool als vollständiges JAR-Archiv.
Größe des Dataproc-Clusters anpassen
In jeder Clusterkonfiguration, ob lokal oder in der Cloud, ist die Clustergröße für die Leistung von Spark-Jobs entscheidend. Ein Spark-Job ohne ausreichende Ressourcen ist entweder langsam oder schlägt fehl, insbesondere wenn er nicht über genügend Executor-Arbeitsspeicher verfügt. Informationen dazu, was Sie bei der Dimensionierung eines Hadoop-Clusters beachten müssen, finden Sie im Leitfaden für die Hadoop-Migration im Abschnitt Clustergröße anpassen.
In den folgenden Abschnitten werden einige Optionen für die Dimensionierung des Clusters beschrieben.
Konfiguration der aktuellen Spark-Jobs abrufen
Untersuchen Sie die Konfiguration Ihrer aktuellen Spark-Jobs und prüfen Sie, ob der Dataproc-Cluster groß genug ist. Wenn Sie von einem freigegebenen Cluster zu mehreren Dataproc-Clustern wechseln (einem für jede Batcharbeitslast), sehen Sie sich die YARN-Konfiguration für jede Anwendung an, damit Sie wissen, wie viele Executors Sie benötigen, wie viele CPUs pro Executor vorhanden sind und wie viel Arbeitsspeicher insgesamt verfügbar ist. Wenn im lokalen Cluster YARN-Warteschlangen eingerichtet sind, prüfen Sie, welche Jobs die Ressourcen der einzelnen Warteschlangen gemeinsam nutzen und ermitteln Sie Engpässe. Diese Migration bietet die Gelegenheit, Ressourceneinschränkungen in Ihrem lokalen Cluster zu beheben.
Maschinentypen und Festplattenoptionen auswählen
Wählen Sie die Anzahl und den Typ der VMs aus, die den Anforderungen Ihrer Arbeitslast entsprechen. Wenn Sie sich für die Verwendung eines lokalen HDFS zum Speichern entschieden haben, achten Sie darauf, dass die VMs Laufwerke des richtigen Typs und angemessener Größe haben. Denken Sie auch daran, den Ressourcenbedarf der Treiberprogramme in Ihre Berechnung einzubeziehen.
Jede VM hat eine Obergrenze für ausgehenden Netzwerktraffic von 2 Gbit/s pro vCPU. Das Schreiben in nichtflüchtige Speicher oder nichtflüchtige SSD-Speicher wird auf diese Obergrenze angerechnet. Daher wird eine VM mit sehr wenigen vCPUs möglicherweise durch die Obergrenze gedrosselt, wenn sie auf diese Laufwerke schreibt. Dies ist wahrscheinlich in der Shuffle-Phase der Fall, wenn Spark Shuffle-Daten auf das Laufwerk schreibt und die Shuffle-Daten über das Netzwerk zwischen den Executors verschiebt. Nichtflüchtiger Speicher benötigt mindestens 2 vCPUs, um die maximale Schreibleistung zu erreichen, und nichtflüchtiger SSD-Speicher benötigt 4 vCPUs. Beachten Sie, dass bei diesen Mindestwerten der Traffic wie die Kommunikation zwischen VMs nicht berücksichtigt wird. Auch die Größe der einzelnen Laufwerke beeinflusst die Spitzenleistung.
Die gewählte Konfiguration wirkt sich auf die Kosten des Dataproc-Clusters aus. Dataproc-Preise gelten zusätzlich zum Compute Engine-Preis pro Instanz für jede VM und andere Google Cloud-Ressourcen. Weitere Informationen und Hinweise zur Verwendung des Google Cloud-Preisrechners für die Kostenschätzung finden Sie auf der Seite Dataproc – Preise.
Leistung benchmarken und optimieren
Nachdem Sie die Jobmigrationsphase abgeschlossen haben und bevor Sie die Ausführung von Spark-Arbeitslasten im Cluster beenden, sollten Sie die Spark-Jobs vergleichen und ggf. Optimierungen in Betracht ziehen. Denken Sie daran, dass Sie die Größe des Clusters ändern können, wenn die Konfiguration nicht optimal ist.
Dataproc Serverless für Spark-Autoscaling
Verwenden Sie Dataproc Serverless, um Spark-Arbeitslasten auszuführen, ohne Ihren eigenen Cluster bereitzustellen und zu verwalten. Geben Sie Arbeitslastparameter an und senden Sie die Arbeitslast dann an den serverlosen Dataproc-Dienst. Der Dienst führt die Arbeitslast auf einer verwalteten Computing-Infrastruktur aus und skaliert die Ressourcen automatisch nach Bedarf. Serverlose Dataproc-Gebühren gelten nur für den Zeitpunkt, an dem die Arbeitslast ausgeführt wird.
Migration durchführen
In diesem Abschnitt wird beschrieben, wie Sie die Daten migrieren sowie den Jobcode und den Ausführungstyp der Jobs ändern.
Migration von Daten
Bevor Sie Spark-Jobs auf Ihrem Dataproc-Cluster ausführen, müssen Sie Ihre Daten zu Google Cloud migrieren. Weitere Informationen finden Sie im Leitfaden zur Datenmigration.
Spark-Code migrieren
Nachdem Sie die Migration zu Dataproc geplant und die erforderlichen Datenquellen verschoben haben, können Sie den Jobcode migrieren. Wenn in den beiden Clustern keine unterschiedlichen Spark-Versionen verwendet werden und Sie Daten in Cloud Storage anstatt im lokalen HDFS speichern möchten, müssen Sie lediglich das Präfix aller HDFS-Dateipfade von hdfs:// zu gs:// ändern.
Wenn Sie verschiedene Spark-Versionen verwenden, lesen Sie in den Versionshinweisen zu Spark die Gegenüberstellung der beiden Versionen und passen Sie Ihren Spark-Code entsprechend an.
Sie können die JAR-Dateien für die Spark-Anwendungen entweder in den mit Ihrem Dataproc-Cluster verknüpften Cloud Storage-Bucket oder in einen HDFS-Ordner kopieren. Im nächsten Abschnitt werden die Optionen zum Ausführen von Spark-Jobs erläutert.
Wenn Sie sich für Workflowvorlagen entscheiden, empfehlen wir, jeden Spark-Auftrag, den Sie hinzufügen möchten, separat zu testen. Anschließend können Sie einen letzten Testlauf der Vorlage ausführen, um zu gewährleisten, dass der Workflow der Vorlage korrekt ist (keine fehlenden Upstream-Jobs, Ausgaben werden an den richtigen Orten gespeichert usw.).
Jobs ausführen
So können Sie Spark-Jobs ausführen:
Verwenden Sie den folgenden
gcloud-Befehl:gcloud dataproc jobs submit [COMMAND]
Dabei gilt:
[COMMAND]istspark,pysparkoderspark-sql.Sie können Spark-Attribute mit der Option
--propertiesfestlegen. Weitere Informationen finden Sie in der Dokumentation zu diesem Befehl.Verwenden Sie den gleichen Prozess, den Sie vor der Migration des Jobs zu Dataproc angewendet haben. Auf den Dataproc-Cluster muss ein lokaler Zugriff möglich sein und Sie müssen die gleiche Konfiguration verwenden.
Verwenden Sie Cloud Composer. Sie können eine Umgebung erstellen (einen verwalteten Apache Airflow-Server), mehrere Spark-Jobs als DAG-Workflow definieren und dann den gesamten Workflow ausführen.
Weitere Informationen finden Sie in der Anleitung Job senden.
Jobs nach der Migration verwalten
Nachdem Sie die Spark-Jobs nach Google Cloud verschoben haben, müssen Sie diese Jobs mithilfe der in der Google Cloud verfügbaren Tools und Mechanismen verwalten. In diesem Abschnitt werden das Logging, das Monitoring, der Zugriff auf Cluster, das Skalieren von Clustern und das Optimieren von Jobs beschrieben.
Logging und Leistungs-Monitoring nutzen
In Google Cloud können Sie mit Cloud Logging und Cloud Monitoring Logs aufrufen und anpassen sowie Jobs und Ressourcen überwachen.
Wenn Sie ermitteln möchten, welcher Fehler das Fehlschlagen eines Spark-Jobs verursacht hat, können Sie die Treiberausgabe und die von den Spark-Executors generierten Logs überprüfen.
Sie können die Ausgabe von Treiberprogrammen in der Google Cloud Console oder mithilfe eines gcloud-Befehls abrufen. Die Ausgabe wird auch im Cloud Storage-Bucket des Dataproc-Clusters gespeichert. Weitere Informationen finden Sie in der Dataproc-Dokumentation im Abschnitt Auf die Treiberausgabe eines Jobs zugreifen.
Alle anderen Logs befinden sich in unterschiedlichen Dateien auf den Computern des Clusters. Sie können sich die Logs aller Container über die Web-UI der Spark-Anwendung (oder nach Beendigung des Programms über den Verlaufsserver) im Tab "Executors" ansehen. Sie müssen in allen Spark-Containern suchen, um alle Logs zu finden. Wenn Sie Logs schreiben oder in Ihrem Anwendungscode an stdout oder stderr senden, werden die Logs in der Weiterleitung von stdout oder stderr gespeichert.
In einem Dataproc-Cluster ist YARN so konfiguriert, dass alle diese Logs standardmäßig erfasst werden. Sie sind in Cloud Logging verfügbar. Cloud Logging bietet eine konsolidierte und prägnante Ansicht aller Logs, sodass Sie nicht mehr zwischen Containerlogs suchen müssen, um Fehler zu finden.
Die folgende Abbildung zeigt die Cloud Logging-Seite in der Google Cloud Console. Sie können alle Logs Ihres Dataproc-Clusters aufrufen. Wählen Sie dazu den Namen des Clusters im Auswahlmenü aus. Denken Sie auch daran, mit der Zeitraumauswahl die Dauer zu verlängern.
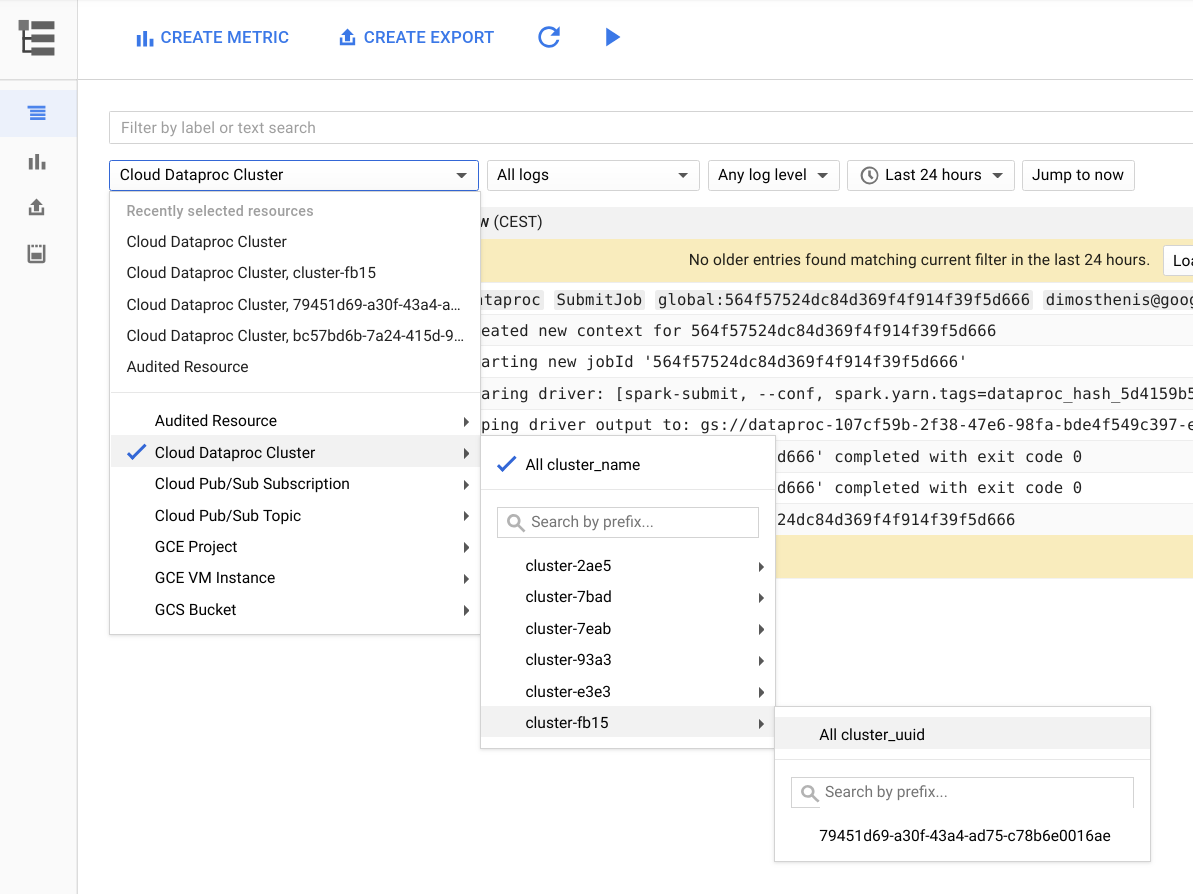
Sie können Logs von einer Spark-Anwendung abrufen, wenn Sie nach ihrer ID filtern. Diese Anwendungs-ID finden Sie in der Treiberausgabe.
Labels erstellen und verwenden
Sie finden Logs schneller, wenn Sie für jeden Cluster oder für jeden Dataproc-Job eigene Labels erstellen und verwenden. Für einen Datenexplorationsjob können Sie beispielsweise ein Label mit dem Schlüssel env und dem Wert exploration erstellen. Sie können dann Logs für alle Explorationsjobs abrufen. Filtern Sie dazu in Cloud Logging nach label:env:exploration.
Dieser Filter gibt nicht alle Logs für diesen Job, sondern nur Logs der Ressourcenerstellung zurück.
Logebene festlegen
Mit dem folgenden gcloud-Befehl können Sie die Logebene für Treiber festlegen:
gcloud dataproc jobs submit hadoop --driver-log-levels
Die Logebene für alle anderen Elemente der Anwendung können Sie über den Spark-Kontext definieren. Beispiel:
spark.sparkContext.setLogLevel("DEBUG")Jobs beobachten
Cloud Monitoring kann die CPU, das Laufwerk, die Netzwerknutzung und die YARN-Ressourcen des Clusters beobachten. Sie können ein benutzerdefiniertes Dashboard erstellen, um aktuelle Diagramme für diese und andere Messwerte abzurufen. Dataproc wird in Compute Engine ausgeführt. Wenn Sie die CPU-Auslastung, Laufwerk-E/A oder Netzwerkmesswerte in einem Diagramm darstellen möchten, müssen Sie eine VM-Instanz in Compute Engine als Ressourcentyp auswählen und dann nach dem Clusternamen filtern. Das folgende Diagramm zeigt ein Beispiel für die Ausgabe.
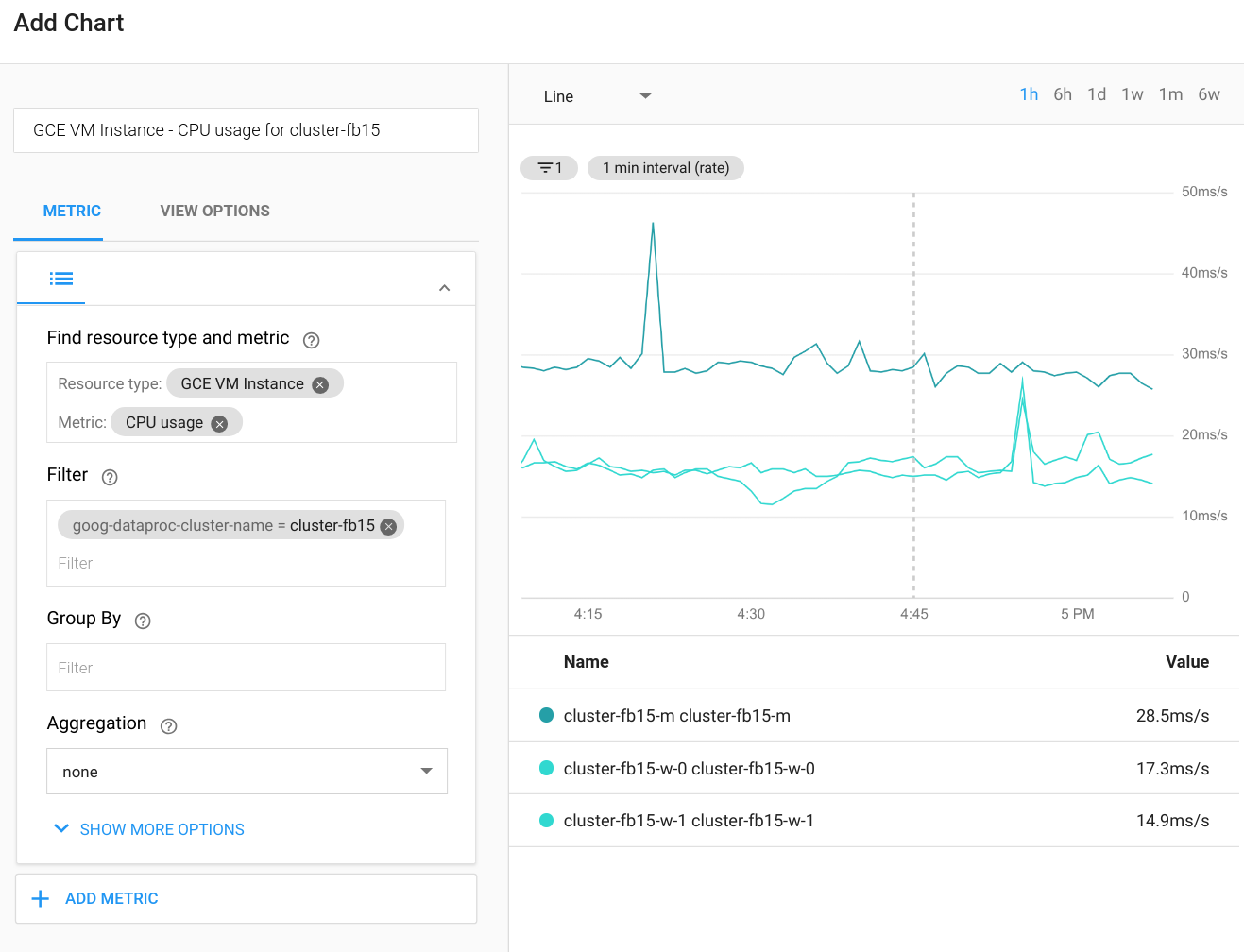
Stellen Sie eine Verbindung zur Web-UI der Spark-Anwendung her, um Messwerte für Abfragen, Jobs, Phasen oder Aufgaben aus Spark anzusehen. Die Vorgehensweise wird im nächsten Abschnitt erklärt. Ausführliche Informationen zum Erstellen benutzerdefinierter Messwerte finden Sie in der Anleitung Benutzerdefinierte Messwerte vom Agent.
Auf YARN zugreifen
Sie können von außerhalb des Dataproc-Clusters auf die Weboberfläche des YARN-Ressourcenmanagers zugreifen. Richten Sie dazu einen SSH-Tunnel ein. Es wird empfohlen, den einfachen SOCKS-Proxy anstelle der lokalen Portweiterleitung zu verwenden, da das Durchsuchen der Weboberfläche so einfacher ist.
Die folgenden URLs sind hilfreich für den Zugriff auf YARN:
YARN-Ressourcenmanager:
http://[MASTER_HOST_NAME]:8088Spark-Verlaufsserver:
http://[MASTER_HOST_NAME]:18080
Wenn der Dataproc-Cluster nur interne IP-Adressen hat, können Sie die Verbindung entweder über ein VPN oder über einen Bastion Host herstellen. Weitere Informationen finden Sie unter Verbindungsoption für ausschließlich interne VMs auswählen.
Dataproc-Cluster skalieren und in der Größe anpassen
Der Dataproc-Cluster kann durch Erhöhen oder Verringern der Anzahl der primären Worker oder der sekundären Worker (auf Abruf) skaliert werden. Dataproc unterstützt auch die ordnungsgemäße Außerbetriebnahme.
Das Herunterskalieren in Spark wird von einigen Faktoren beeinflusst. Berücksichtigen Sie Folgendes:
Die Verwendung von
ExternalShuffleServicewird nicht empfohlen, insbesondere wenn Sie den Cluster regelmäßig herunterskalieren. Für das Shuffling werden die Ergebnisse verwendet, die nach der Compute-Phase auf das lokale Laufwerk des Workers geschrieben wurden. Der Knoten kann daher auch dann nicht entfernt werden, wenn keine Rechenressourcen mehr genutzt werden.Spark speichert Daten im Cache (sowohl RDDs als auch Datasets) und für die Speicherung im Cache verwendete Executors werden immer ausgeführt. Deshalb wird ein für die Speicherung im Cache verwendeter Worker in keinem Fall ordnungsgemäß außer Betrieb genommen. Eine erzwungene Entfernung von Workern würde die Gesamtleistung beeinflussen, da dabei die im Cache gespeicherten Daten verloren gehen.
In Spark Streaming ist die dynamische Zuweisung standardmäßig deaktiviert und der zugrunde liegende Konfigurationsschlüssel ist nicht dokumentiert. In der Diskussion der Spark-Probleme wird das Verhalten der dynamischen Zuordnung erörtert. Wenn Sie Spark Streaming oder Spark Structured Streaming verwenden, müssen Sie die dynamische Zuordnung explizit deaktivieren, wie zuvor unter Jobtypen identifizieren und Cluster planen beschrieben.
Allgemein wird empfohlen, das Herunterskalieren eines Dataproc-Clusters zu vermeiden, wenn Sie Batch- oder Streamingarbeitslasten ausführen.
Leistung optimieren
In diesem Abschnitt wird beschrieben, wie Sie beim Ausführen von Spark-Jobs die Leistung verbessern und die Kosten senken können.
Dateigröße in Cloud Storage verwalten
Für eine optimale Leistung wird empfohlen, die Daten in Cloud Storage in Dateien mit einer Größe von 128 MB bis 1 GB aufzuteilen. Die Verwendung vieler kleiner Dateien kann zu Engpässen führen. Wenn Sie viele kleine Dateien haben, sollten Sie sie zur Verarbeitung auf das lokale HDFS kopieren und dann die Ergebnisse zurückkopieren.
Zu SSD-Festplatten wechseln
Wenn Sie viele Datenumverteilungen nach dem Zufallsprinzip oder partitionierte Schreibvorgänge ausführen, können Sie zu SSDs wechseln, um die Leistung zu erhöhen.
VMs in derselben Zone platzieren
Verwenden Sie für Ihre Cloud Storage-Buckets den gleichen regionalen Standort, den Sie auch für Ihre Dataproc-Cluster verwenden, um die Netzwerkkosten zu reduzieren und die Leistung zu steigern.
Wenn Sie globale oder regionale Dataproc-Endpunkte verwenden, werden die VMs des Clusters bei der Erstellung standardmäßig in derselben Zone (oder einer anderen Zone in derselben Region mit ausreichender Kapazität) platziert. Sie können beim Erstellen des Clusters auch eine Zone angeben.
VMs auf Abruf verwenden
Dataproc-Cluster können VM-Instanzen auf Abruf als Worker verwenden. Dies führt zu geringeren Compute-Kosten pro Stunde für Ihre nicht kritischen Arbeitslasten als bei der Verwendung normaler Instanzen. Bei der Verwendung von VMs auf Abruf müssen jedoch einige Faktoren berücksichtigt werden:
- VMs auf Abruf können nicht für HDFS-Speicher verwendet werden.
- Standardmäßig werden VMs auf Abruf mit einer geringeren Bootlaufwerkgröße erstellt. Sie können diese Konfiguration entsprechend ändern, wenn Sie Arbeitslasten mit intensiven Shuffle-Vorgängen ausführen. Weitere Informationen finden Sie in der Dataproc-Dokumentation auf der Seite über VMs auf Abruf.
- Es wird nicht empfohlen, mehr als die Hälfte Ihrer gesamten Worker auf Abruf zu nutzen.
Wenn Sie VMs auf Abruf verwenden, empfiehlt es sich, die Clusterkonfiguration für eine fehlertolerantere Ausführung von Aufgaben anzupassen, da möglicherweise weniger VMs verfügbar sind. Nehmen Sie beispielsweise folgende Einstellungen in der YARN-Konfiguration vor:
yarn.resourcemanager.am.max-attempts mapreduce.map.maxattempts mapreduce.reduce.maxattempts spark.task.maxFailures spark.stage.maxConsecutiveAttempts
Sie können VMs auf Abruf problemlos zu Ihrem Cluster hinzufügen oder daraus entfernen. Ausführliche Informationen finden Sie unter VMs auf Abruf.
Nächste Schritte
- Lesen Sie die Anleitung unter Lokale Hadoop-Infrastruktur zu Google Cloud migrieren.
- Informieren Sie sich über den Lebenszyklus eines Dataproc-Jobs.
- Referenzarchitekturen, Diagramme und Best Practices zu Google Cloud kennenlernen. Weitere Informationen zu Cloud Architecture Center