Nachdem Sie einen Dataproc-Cluster erstellt haben, können Sie den Cluster anpassen ("skalieren"), indem Sie die Anzahl der primären oder sekundären Worker-Knoten (horizontale Skalierung) im Cluster erhöhen oder verringern. Dataproc-Cluster können jederzeit skaliert werden, auch wenn Jobs auf dem Cluster ausgeführt werden. Der Maschinentyp eines vorhandenen Clusters (vertikale Skalierung) kann nicht geändert werden. Erstellen Sie zur vertikalen Skalierung einen Cluster mit einem unterstützten Maschinentyp und migrieren Sie dann Jobs zum neuen Cluster.
Sie können einen Dataproc-Cluster für Folgendes skalieren:
- Erhöhen der Anzahl vorhandener Worker, um die Ausführung eines Jobs zu beschleunigen
- Reduzieren der Anzahl der Worker, um Geld zu sparen. (Beachten Sie beim Reduzieren eines Clusters die ordnungsgemäße Außerbetriebnahme, um den Verlust laufender Aufgaben zu vermeiden.)
- Erhöhen der Anzahl vorhandener Knoten, um verfügbaren HDFS-Speicher (Hadoop Distributed File System) zu erweitern.
Da Cluster mehrmals skaliert werden können, kann es sinnvoll sein, die Clustergröße einmalig zu erhöhen oder zu verringern und dann zu einem späteren Zeitpunkt zu verringern oder zu erhöhen.
Skalierung verwenden
Es gibt drei Methoden zum Skalieren von Dataproc-Clustern:
- Verwenden Sie das
gcloud-Befehlszeilentool in der gcloud CLI. - Bearbeiten Sie die Clusterkonfiguration in der Google Cloud Console.
- Verwenden der Rest API
Neue Worker, die einem Cluster hinzugefügt wurden, verwenden den gleichen Maschinentyp wie bestehende Worker. Beispiel: Wird ein Cluster mit Workern des Maschinentyps n1-standard-8 erstellt, so nutzen neue Worker ebenfalls den Maschinentyp n1-standard-8.
Sie können die Anzahl der primären Worker, der sekundären Worker (Worker auf Abruf) oder beider skalieren. Wenn Sie beispielsweise nur die Anzahl der Worker (auf Abruf) skalieren, bleibt die Anzahl der primären Worker unverändert.
gcloud
Führen Sie den folgenden Befehl aus, um einen Cluster mitgcloud dataproc clusters update zu skalieren:
gcloud dataproc clusters update cluster-name \ --region=region \ [--num-workers and/or --num-secondary-workers]=new-number-of-workers
gcloud dataproc clusters update dataproc-1 \
--region=region \
--num-workers=5
...
Waiting on operation [operations/projects/project-id/operations/...].
Waiting for cluster update operation...done.
Updated [https://dataproc.googleapis.com/...].
clusterName: my-test-cluster
...
masterDiskConfiguration:
bootDiskSizeGb: 500
masterName: dataproc-1-m
numWorkers: 5
...
workers:
- my-test-cluster-w-0
- my-test-cluster-w-1
- my-test-cluster-w-2
- my-test-cluster-w-3
- my-test-cluster-w-4
...
REST API
Weitere Informationen finden Sie unter cluster.patch.
Beispiel
PATCH /v1/projects/project-id/regions/us-central1/clusters/example-cluster?updateMask=config.worker_config.num_instances,config.secondary_worker_config.num_instances
{
"config": {
"workerConfig": {
"numInstances": 4
},
"secondaryWorkerConfig": {
"numInstances": 2
}
},
"labels": null
}
Konsole
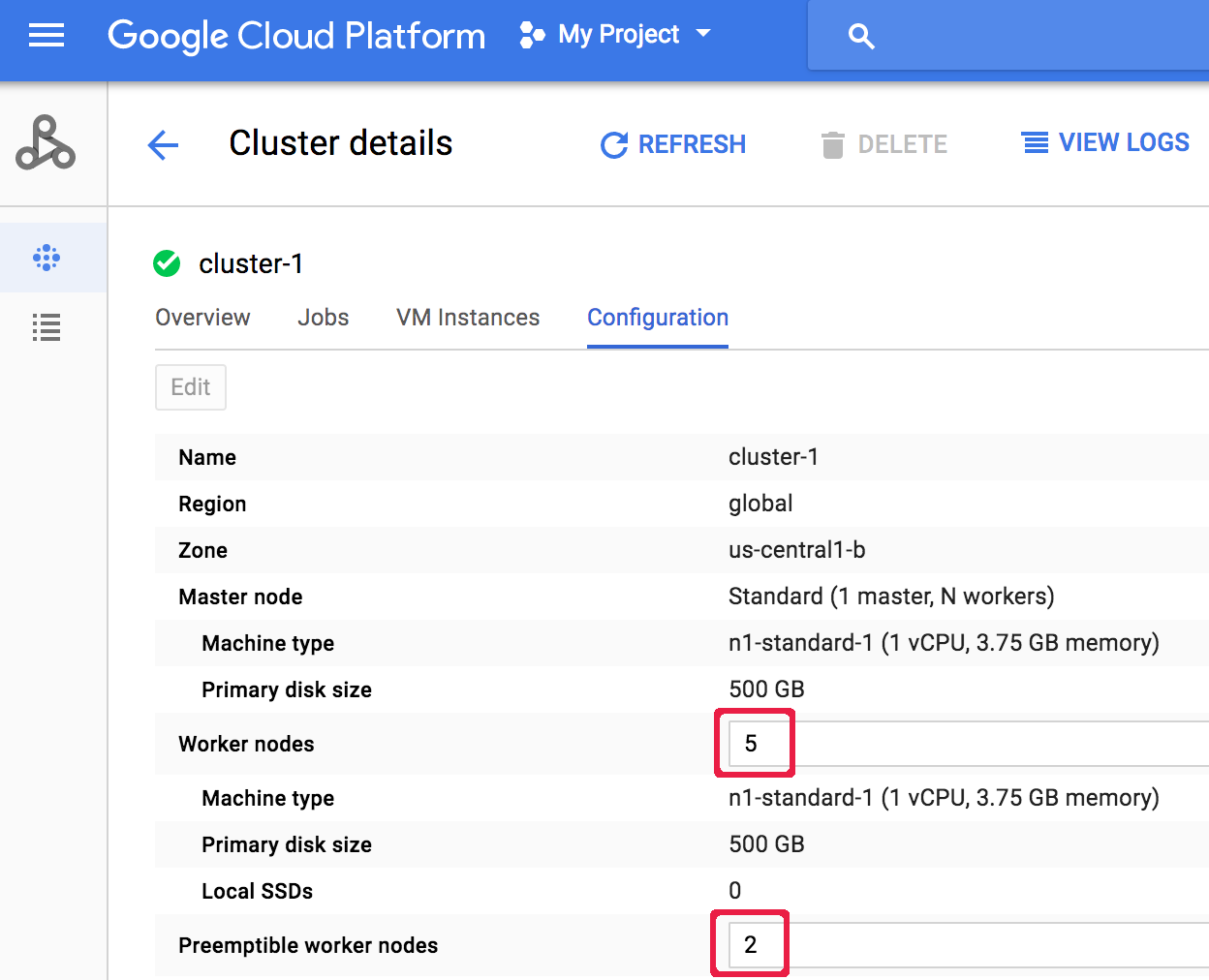
Wenn Sie einen Cluster nach dessen Erstellung skalieren möchten, wechseln Sie zur Seite Cluster in der Google Cloud -Konsole und öffnen die Seite Clusterdetails für den betreffenden Cluster. Klicken Sie dann auf dem Tab Konfiguration auf die Schaltfläche Bearbeiten. Geben Sie einen neuen Wert für die Anzahl der Worker-Knoten und/oder Worker-Knoten auf Abruf ein (im folgenden Screenshot auf „5“ bzw. „2“ aktualisiert).
Geben Sie einen neuen Wert für die Anzahl der Worker-Knoten und/oder Worker-Knoten auf Abruf ein (im folgenden Screenshot auf „5“ bzw. „2“ aktualisiert).
 Klicken Sie auf Speichern, um den Cluster zu aktualisieren.
Klicken Sie auf Speichern, um den Cluster zu aktualisieren.
So wählt Dataproc Clusterknoten zum Entfernen aus
Bei Clustern, die mit den Image-Versionen 1.5.83+, 2.0.57+ und 2.1.5+ erstellt wurden, versucht Dataproc beim Herunterskalieren eines Clusters, die Auswirkungen des Entfernens von Knoten auf laufende YARN-Anwendungen zu minimieren. Dazu werden zuerst inaktive, fehlerhafte und inaktive Knoten entfernt und dann Knoten mit den wenigsten laufenden YARN-Anwendungsmaster und laufenden Containern.
Ordnungsgemäße Außerbetriebnahme
Wenn Sie einen Cluster herunterskalieren, werden laufende Aufgaben möglicherweise beendet, bevor sie abgeschlossen sind. Wenn Sie Dataproc 1.2 oder höher verwenden, können Sie die ordnungsgemäße Außerbetriebnahme verwenden. Diese Funktion beinhaltet die ordnungsgemäße Außerbetriebnahme von YARN-Knoten, um laufende Aufgaben auf einem Worker abzuschließen, bevor dieser aus dem Cloud Dataproc-Cluster entfernt wird.
Ordnungsgemäße Außerbetriebnahme und sekundäre Worker
Die sekundäre Worker-Gruppe (Worker-Gruppe auf Abruf) stellt Worker weiter bereit oder löscht sie, um die erwartete Größe zu erreichen, nachdem ein Cluster-Skalierungsvorgang als abgeschlossen markiert wurde. Wenn Sie versuchen, einen sekundären Worker ordnungsgemäß außer Betrieb zu nehmen, erhalten Sie möglicherweise eine Fehlermeldung wie die folgende:
"Die sekundäre Worker-Gruppe kann nicht außerhalb von Dataproc geändert werden. Wenn Sie diesen Cluster vor Kurzem erstellt oder aktualisiert haben, warten Sie einige Minuten, bevor Sie ihn ordnungsgemäß außer Betrieb nehmen, damit alle sekundären Instanzen hinzugefügt bzw. aus dem Cluster entfernt werden können.
Erwartete Größe der sekundären Worker-Gruppe: x, tatsächliche Größe: y".
Warten Sie einige Minuten und wiederholen Sie dann die Anfrage zur ordnungsgemäßen Außerbetriebnahme.
Ordnungsgemäße Außerbetriebnahme verwenden
Die ordnungsgemäße Außerbetriebnahme von Dataproc umfasst auch die ordnungsgemäße Außerbetriebnahme von YARN-Knoten. Damit werden laufende Aufgaben für einen Worker beendet, bevor sie aus dem Cloud Dataproc-Cluster entfernt werden. Die ordnungsgemäße Außerbetriebnahme ist standardmäßig deaktiviert. Sie kann aktiviert werden, indem Sie einen Zeitüberschreitungswert festlegen, wenn Sie Ihren Cluster aktualisieren, um einen oder mehrere Worker aus dem Cluster zu entfernen.
gcloud
Wenn Sie einen Cluster aktualisieren, um einen oder mehrere Worker zu entfernen, verwenden Sie den Befehl gcloud dataproc clusters update mit dem Flag--graceful-decommission-timeout. Die Zeitüberschreitungswerte (String) können den Wert "0s" (Standardeinstellung; erzwungene Außerbetriebnahme, nicht ordnungsgemäß) oder eine positive Dauer relativ zum aktuellen Zeitpunkt (z. B. "3s") haben.
Die maximale Dauer beträgt 1 Tag.
gcloud dataproc clusters update cluster-name \ --region=region \ --graceful-decommission-timeout="timeout-value" \ [--num-workers and/or --num-secondary-workers]=decreased-number-of-workers \ ... other args ...
REST API
Weitere Informationen finden Sie unter clusters.patch.gracefulDecommissionTimeout. Die Zeitüberschreitungswerte (String) können den Wert "0" (Standardeinstellung; erzwungene Außerbetriebnahme, nicht ordnungsgemäß) oder eine Dauer in Sekunden (z. B. "3s") haben. Die maximale Dauer beträgt 1 Tag.Konsole
Wenn Sie für einen Cluster nach dessen Erstellung die ordnungsgemäße Außerbetriebnahme auswählen möchten, wechseln Sie zur Seite Cluster in der Google Cloud -Konsole und öffnen die Seite Clusterdetails für den betreffenden Cluster. Klicken Sie dann auf dem Tab Konfiguration auf die Schaltfläche Bearbeiten.
Wählen Sie im Bereich Ordnungsgemäße Außerbetriebnahme die Option Ordnungsgemäße Außerbetriebnahme verwenden aus und wählen Sie dann ein Zeitlimit aus.
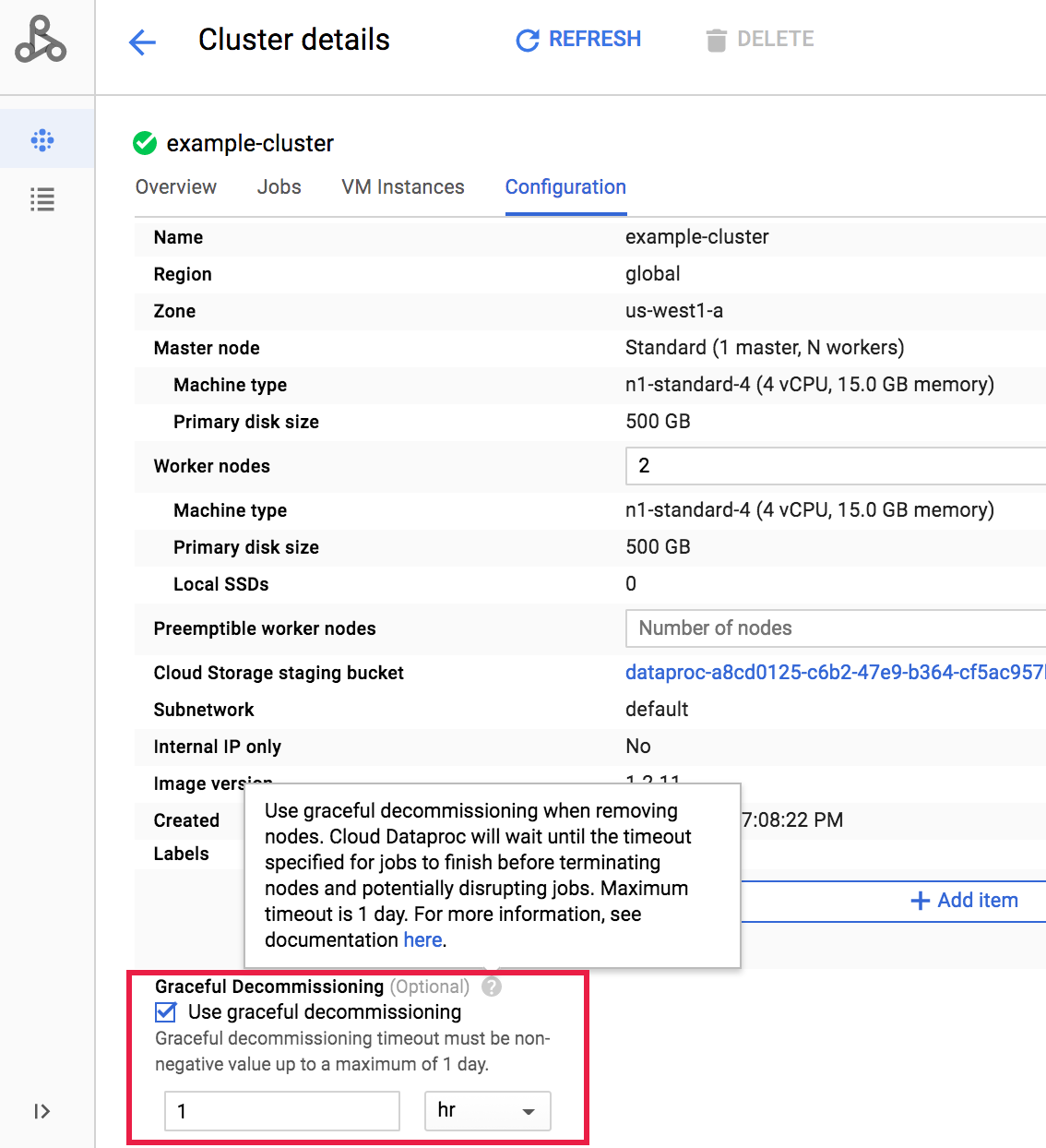 Klicken Sie auf Speichern, um den Cluster zu aktualisieren.
Klicken Sie auf Speichern, um den Cluster zu aktualisieren.
Herunterskalierungsvorgang für die ordnungsgemäße Außerbetriebnahme abbrechen
Auf Dataproc-Clustern, die mit Image-Versionen 2.0.57+ oder 2.1.5+ erstellt wurden, können Sie den Befehl gcloud dataproc operations cancel ausführen oder eine Dataproc API-Anfrage operations.cancel senden, um einen Graceful Decommissioning-Vorgang zum Herunterskalieren abzubrechen.
Wenn Sie einen Skalierungsvorgang für die ordnungsgemäße Außerbetriebnahme abbrechen:
Worker im Status
DECOMMISSIONINGwerden neu in Betrieb genommen und erhalten nach Abschluss des Vorgangs zum Abbrechen den StatusACTIVE.Wenn der Vorgang zum Herunterskalieren Label-Aktualisierungen umfasst, werden diese möglicherweise nicht wirksam.
Sie können den Status der Kündigungsanfrage mit dem Befehl gcloud dataproc operations describe oder mit einer Dataproc API-Anfrage operations.get prüfen. Wenn der Abbruchvorgang erfolgreich ist, wird der Status des inneren Vorgangs als CANCELLED markiert.