In dieser Anleitung wird gezeigt, wie Sie mit Dataflow Daten aus einer relationalen OLTP-Datenbank (Datenbank zur Online-Transaktionsverarbeitung) extrahieren und transformieren und anschließend zur Analyse in BigQuery laden können.
Diese Anleitung richtet sich an Datenbankadministratoren, Betriebsexperten und Cloud-Architekten, die die Abfragefunktionen von BigQuery zu Analysezwecken und die Batchverarbeitungsfunktionen von Dataflow nutzen möchten.
OLTP-Datenbanken sind oft relationale Datenbanken, die für E-Commerce-Seiten, SaaS-Anwendungen (Software as a Service) oder Spiele Informationen speichern und Transaktionen verarbeiten. OLTP-Datenbanken sind normalerweise für Transaktionen optimiert, die die ACID-Attribute erfordern: Atomarität, Konsistenz, Isolation und Langlebigkeit (Atomicity, Consistency, Isolation, Durability). Ihre Schemas sind in der Regel stark normalisiert. Data Warehouses tendieren hingegen dazu, für den Datenabruf und die Datenanalyse statt für Transaktionen optimiert zu sein, und haben meist denormalisierte Schemas. Allgemein werden Daten durch die Denormalisierung aus einer OLTP-Datenbank nützlicher für die Analyse in BigQuery.
Ziele
In der Anleitung werden zwei Ansätze dafür gezeigt, wie normalisierte RDBMS-Daten (Relational Database Management System) durch Extrahieren, Transformieren und Laden (ETL) in denormalisierte BigQuery-Daten umgewandelt werden können:
- BigQuery zum Laden und Transformieren der Daten verwenden: Nutzen Sie diesen Ansatz, um ein einmaliges Laden einer kleinen Datenmenge in BigQuery für die Analyse durchzuführen. Sie können diesen Ansatz auch verwenden, um für Ihr Dataset einen Prototyp zu erstellen, bevor Sie die Automatisierung mit großen oder mehreren Datasets nutzen.
- Dataflow zum Laden, Transformieren und Bereinigen der Daten verwenden: Nutzen Sie diesen Ansatz, um größere Datenmengen oder Daten aus mehreren Datenquellen zu laden oder Daten schrittweise oder automatisch zu laden.
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Nach Abschluss der in diesem Dokument beschriebenen Aufgaben können Sie weitere Kosten vermeiden, indem Sie die erstellten Ressourcen löschen. Weitere Informationen finden Sie unter Bereinigen.
Hinweis
- Melden Sie sich bei Ihrem Google Cloud-Konto an. Wenn Sie mit Google Cloud noch nicht vertraut sind, erstellen Sie ein Konto, um die Leistungsfähigkeit unserer Produkte in der Praxis sehen und bewerten zu können. Neukunden erhalten außerdem ein Guthaben von 300 $, um Arbeitslasten auszuführen, zu testen und bereitzustellen.
-
Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
-
Compute Engine und Dataflow APIs aktivieren.
-
Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
-
Compute Engine und Dataflow APIs aktivieren.
MusicBrainz-Datasets verwenden
Diese Anleitung beruht auf JSON-Snapshots von Tabellen in der MusicBrainz-Datenbank, die auf PostgreSQL basiert und Informationen über die gesamte MusicBrainz-Musik enthält. Zu den Elementen des MusicBrainz-Schemas gehören:
- Interpreten
- Versionsgruppen
- Versionen
- Aufnahmen
- Works
- Labels
- Viele Beziehungen zwischen diesen Elementen
Das MusicBrainz-Schema umfasst drei relevante Tabellen: artist, recording und artist_credit_name. artist_credit steht für die Zuordnung einer Aufnahme zu einem Interpreten. Die Zeilen artist_credit_name verknüpfen die Aufnahme mit dem entsprechenden Interpreten über den artist_credit-Wert.
Diese Anleitung enthält die PostgreSQL-Tabellen, die bereits in das durch Zeilenumbruch getrennte JSON-Format extrahiert und in einem öffentlichen Cloud Storage-Bucket gespeichert wurden: gs://solutions-public-assets/bqetl.
Wenn Sie diesen Schritt selbst ausführen möchten, benötigen Sie eine PostgreSQL-Datenbank mit dem MusicBrainz-Dataset. Exportieren Sie dann mit den folgenden Befehlen jede der Tabellen:
host=POSTGRES_HOST
user=POSTGRES_USER
database=POSTGRES_DATABASE
for table in artist recording artist_credit_name
do
pg_cmd="\\copy (select row_to_json(r) from (select * from ${table}) r ) to exported_${table}.json"
psql -w -h ${host} -U ${user} -d ${db} -c $pg_cmd
# clean up extra '\' characters
sed -i -e 's/\\\\/\\/g' exported_${table}.json
done
Ansatz 1: ETL mit BigQuery
Nutzen Sie diesen Ansatz, um ein einmaliges Laden einer kleinen Datenmenge in BigQuery für die Analyse durchzuführen. Sie können diesen Ansatz auch nutzen, um für Ihr Dataset einen Prototyp zu erstellen, bevor Sie die Automatisierung mit großen oder mehreren Datasets nutzen.
BigQuery-Dataset erstellen
Zum Erstellen eines BigQuery-Datasets laden Sie die MusicBrainz-Tabellen einzeln in BigQuery und führen die geladenen Tabellen dann zusammen, sodass jede Zeile die von Ihnen gewünschte Datenverknüpfung enthält. Die Verknüpfungsergebnisse speichern Sie in einer neuen BigQuery-Tabelle. Dann können Sie die ursprünglichen Tabellen, die Sie geladen haben, löschen.
Öffnen Sie BigQuery in der Google Cloud Console.
Klicken Sie im Bereich Explorer auf das Menü more_vert neben Ihrem Projektnamen und dann auf Dataset erstellen.
Führen Sie im Dialogfeld Dataset erstellen die folgenden Schritte aus:
- Geben Sie im Feld Dataset-ID den Wert
musicbrainzein. - Setzen Sie den Speicherort der Daten auf us.
- Klicken Sie auf Dataset erstellen.
- Geben Sie im Feld Dataset-ID den Wert
MusicBrainz-Tabellen importieren
Führen Sie für jede MusicBrainz-Tabelle die folgenden Schritte aus, um die Tabellen in das von Ihnen erstellte Dataset einzufügen:
- Maximieren Sie im BigQuery-Bereich Explorer der Google Cloud Console die Zeile mit Ihrem Projektnamen, um das neu erstellte Dataset
musicbrainzaufzurufen. - Klicken Sie auf das Menü more_vert neben Ihrem Dataset
musicbrainzund dann auf Tabelle erstellen. Führen Sie im Dialogfeld Dataset erstellen die folgenden Schritte aus:
- Wählen Sie in der Drop-down-Liste Tabelle erstellen aus die Option Google Cloud Storage aus.
Geben Sie im Feld Datei aus GCS-Bucket auswählen den Pfad zur Datendatei ein:
solutions-public-assets/bqetl/artist.jsonWählen Sie für Dateiformat den Eintrag JSONL (durch Zeilenumbruch getrenntes JSON) aus.
Achten Sie darauf, dass das Projekt Ihren Projektnamen enthält.
Achten Sie darauf, dass Dataset
musicbrainzist.Geben Sie unter Tabelle den Tabellennamen ein:
artist.Lassen Sie unter Tabellentyp den Wert Native Tabelle ausgewählt.
Klicken Sie unter dem Abschnitt Schema auf Als Text bearbeiten.
Laden Sie die Schemadatei
artistherunter und öffnen Sie sie in einem Texteditor oder Betrachter.Ersetzen Sie den Inhalt im Abschnitt Schema durch den Inhalt der Schemadatei, die Sie heruntergeladen haben.
Klicken Sie auf Tabelle erstellen:
Warten Sie einen Moment, bis der Ladejob beendet ist.
Nach Abschluss des Ladejobs wird die neue Tabelle im Dataset angezeigt.
Wiederholen Sie die Schritte 1 bis 5, um die Tabelle
artist_credit_namemit den folgenden Änderungen zu erstellen:Verwenden Sie den folgenden Pfad für die Quelldatendatei:
solutions-public-assets/bqetl/artist_credit_name.jsonVerwenden Sie
artist_credit_nameals Namen für die Tabelle.Laden Sie die
artist_credit_nameSchemadatei und verwenden Sie den Inhalt für das Schema.
Wiederholen Sie die Schritte 1 bis 5, um die Tabelle
recordingmit den folgenden Änderungen zu erstellen:Verwenden Sie den folgenden Pfad für die Quelldatendatei:
solutions-public-assets/bqetl/recording.jsonVerwenden Sie
recordingals Namen für die Tabelle.Laden Sie die Schemadatei
recordingherunter und verwenden Sie den Inhalt für das Schema.
Daten manuell denormalisieren
Führen Sie die Daten zum Denormalisieren in einer neuen BigQuery-Tabelle zusammen, die eine Zeile für jede Aufnahme des Interpreten hat, gemeinsam mit ausgewählten Metadaten, die für die Analyse aufbewahrt werden sollen.
- Wenn der BigQuery-Abfrageeditor nicht in der Google Cloud Console geöffnet ist, klicken Sie auf add_box Neue Abfrage erstellen.
Kopieren Sie die folgende Abfrage und fügen Sie sie in den Abfrageeditor ein:
SELECT artist.id, artist.gid AS artist_gid, artist.name AS artist_name, artist.area, recording.name AS recording_name, recording.length, recording.gid AS recording_gid, recording.video FROM `musicbrainz.artist` AS artist INNER JOIN `musicbrainz.artist_credit_name` AS artist_credit_name ON artist.id = artist_credit_name.artist INNER JOIN `musicbrainz.recording` AS recording ON artist_credit_name.artist_credit = recording.artist_creditKlicken Sie auf die Drop-down-Liste settingsMehr und wählen Sie dann Abfrageeinstellungen aus.
Führen Sie im Dialogfeld Abfrageeinstellungen die folgenden Schritte aus:
- Wählen Sie Zieltabelle für Abfrageergebnisse festlegen.
- Geben Sie unter Dataset den Wert
musicbrainzein und wählen Sie das Dataset in Ihrem Projekt aus. - Geben Sie unter Tabellen-ID
recordings_by_artists_manualein. - Klicken Sie für Schreibeinstellung für Zieltabelle auf Tabelle überschreiben.
- Klicken Sie auf das Kästchen Allow large results (no size limit) (Große Ergebnisse zulassen (kein Größenlimit)).
- Klicken Sie auf Speichern.
Klicken Sie auf play_circle_filledAusführen.
Wenn die Abfrage abgeschlossen ist, werden die Daten aus dem Abfrageergebnis in der neu erstellten BigQuery-Tabelle bei jedem Interpreten in Lieder organisiert. Außerdem wird eine Stichprobe der in den Abfrageergebnissen angezeigten Ergebnisse angezeigt. Beispiel:
Row id artist_gid artist_name Gebiet recording_name Zeitfenster recording_gid video 1 97546 125ec42a... unknown 240 Horo Gun Toireamaid Hùgan Fhathast Air 174106 c8bbe048... FALSE 2 266317 2e7119b5... Capella Istropolitana 189 Concerto Grosso in D minor, op. 2 no. 3: II. Adagio 134000 af0f294d... FALSE 3 628060 34cd3689... Conspirare 5196 Liturgy, op. 42: 9. Praise the Lord from the Heavens 126933 8bab920d... FALSE 4 423877 54401795... Boys Air Choir 1178 Nunc Dimittis 190000 111611eb... FALSE 5 394456 9914f9f9... L’Orchestre de la Suisse Romande 23036 Concert Waltz no. 2, op. 51 509960 b16742d1... FALSE
Ansatz 2: ETL in BigQuery mit Dataflow
In diesem Abschnitt der Anleitung verwenden Sie anstelle der BigQuery-UI ein Beispielprogramm, um Daten mithilfe einer Dataflow-Pipeline in BigQuery zu laden. Anschließend verwenden Sie das Programmiermodell von Beam, um die Daten, die in BigQuery geladen werden sollen, zu denormalisieren und zu bereinigen.
Sehen Sie sich zuerst die Konzepte und den Beispielcode an.
Konzepte
Obwohl die Datenmenge klein ist und mithilfe der BigQuery-UI schnell hochgeladen werden kann, verwenden Sie jetzt zu Lernzwecken Dataflow, um sie zu extrahieren, zu transformieren und zu laden (ETL). Normalerweise bietet es sich eher bei sehr umfassenden Joins an, anstelle der BigQuery-UI Dataflow zum Extrahieren, Transformieren und Laden von Daten in BigQuery zu verwenden, also bei etwa 500 bis 5.000 Spalten mit mehr als 10 TB Daten. Dabei wird Folgendes angestrebt:
- Sie möchten die Daten bereinigen oder transformieren, während sie in BigQuery geladen werden, statt sie zu speichern und anschließend zusammenzuführen. Bei diesem Ansatz sind daher die Speicheranforderungen geringer, weil die Daten in BigQuery nur in ihrem zusammengeführten, transformierten Zustand gespeichert werden.
- Sie möchten eine benutzerdefinierte Datenbereinigung vornehmen, was mit SQL allein nicht möglich ist.
- Sie planen, die Daten während des Ladevorgangs mit Daten außerhalb der OLTP zu kombinieren, wie etwa Logs oder per Fernzugriff gesteuerten Daten.
- Sie möchten das Testen und Bereitstellen der Logik zum Laden von Daten mit einer kontinuierlichen Integration oder kontinuierlichen Bereitstellung (Continuous Integration/Continuous Deployment, CI/CD) automatisieren.
- Sie erwarten eine allmähliche Iteration, Optimierung und Verbesserung des ETL-Prozesses.
- Sie planen, Daten stufenweise hinzuzufügen, statt einen einmaligen ETL-Schritt durchzuführen.
Es folgt ein Diagramm der Datenpipeline, die vom Beispielprogramm erstellt wird:

Im Beispielcode sind viele der Pipelineschritte gruppiert oder in praktische Methoden eingebettet. Sie erhalten aussagekräftige Namen und werden wiederverwendet. Im Diagramm werden wiederverwendete Schritte durch gestrichelte Linien dargestellt.
Pipelinecode
Der Code erstellt eine Pipeline, die die folgenden Schritte ausführt:
Lädt jede Tabelle, die Teil des Joins aus dem öffentlichen Cloud Storage-Bucket sein soll, in eine
PCollectionvon Strings. Jedes Element umfasst die JSON-Darstellung einer Tabellenzeile.Konvertiert diese JSON-Strings in Objektdarstellungen (
MusicBrainzDataObject-Objekte) und organisiert diese Objektdarstellungen nach einem der Spaltenwerte, z. B. einem Primär- oder Fremdschlüssel.Führt die Listen anhand eines gemeinsamen Interpreten zusammen.
artist_credit_nameverknüpft eine Interpretenzuordnung mit der Aufnahme und umfasst den Fremdschlüssel des Interpreten. Die Tabelleartist_credit_namewird als Liste der SchlüsselwertobjekteKVgeladen. DasK-Mitglied ist der Interpret.Führt die Listen über die Methode
MusicBrainzTransforms.innerJoin()zusammen.- Gruppiert die Sammlungen von
KV-Objekten nach dem Schlüsselmitglied, für das die Zusammenführung durchgeführt werden soll. Dies führt zu einerPCollectionvonKV-Objekten mit einem langen Schlüssel (dem Spaltenwertartist.id) und dem daraus resultierendenCoGbkResult(steht für "Combine Group by Key Result"). DasCoGbkResult-Objekt ist ein Tupel von Objektlisten mit dem gemeinsamen Schlüsselwert aus den ersten und zweitenPCollections. Dieses Tupel ist mit dem für jedePCollectionformulierten Tupel-Tag vor dem Ausführen desCoGroupByKey-Vorgangs in dergroup-Methode erreichbar. Führt jeden Objektabgleich in einem Objekt
MusicBrainzDataObjectzusammen, das ein Verknüpfungsergebnis darstellt.Erkennt die Sammlung in einer Liste von
KV-Objekten, um mit dem nächsten Join zu beginnen. Hier ist derK-Wert die Spalteartist_credit, die für den Join mit der Tabelle verwendet wird, die die Aufnahmen enthält.Erfasst die abschließend resultierende Sammlung von
MusicBrainzDataObject-Objekten, indem dieses Ergebnis mit der geladenen Sammlung von Aufnahmen zusammengeführt wird, die nachartist_credit.idorganisiert sind.Bildet die resultierenden
MusicBrainzDataObjects-Objekte inTableRowsab.Schreibt die resultierenden
TableRowsin BigQuery.
- Gruppiert die Sammlungen von
Details zur Funktionsweise der Beam-Pipelineprogrammierung finden Sie in den folgenden Themen zum Programmiermodell:
PCollection- Daten aus Textdateien laden (einschließlich Cloud Storage)
- Transformationen wie
ParDound MapElements` - Zusammenführen und
GroupByKey - BigQuery IO
Nachdem Sie sich die Schritte angesehen haben, die der Code durchführt, können Sie die Pipeline ausführen.
Cloud Storage-Bucket erstellen
Pipelinecode ausführen
Öffnen Sie Cloud Shell in der Google Cloud Console.
Umgebungsvariablen für Ihr Projekt und das Pipeline-Skript festlegen
export PROJECT_ID=PROJECT_ID export REGION=us-central1 export DESTINATION_TABLE=recordings_by_artists_dataflow export DATASET=musicbrainzErsetzen Sie PROJECT_ID durch die Projekt-ID Ihres Google Cloud-Projekts.
Achten Sie darauf, dass
gclouddas Projekt verwendet, das Sie zu Beginn der Anleitung erstellt oder ausgewählt haben:gcloud config set project $PROJECT_IDErstellen Sie nach dem Sicherheitsprinzip der geringsten Berechtigung ein Dienstkonto für die Dataflow-Pipeline und gewähren Sie ihm nur die erforderlichen Berechtigungen:
roles/dataflow.worker,roles/bigquery.jobUserund diedataEditor-Rolle für das Datasetmusicbrainz:gcloud iam service-accounts create musicbrainz-dataflow export SERVICE_ACCOUNT=musicbrainz-dataflow@${PROJECT_ID}.iam.gserviceaccount.com gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member=serviceAccount:${SERVICE_ACCOUNT} \ --role=roles/dataflow.worker gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member=serviceAccount:${SERVICE_ACCOUNT} \ --role=roles/bigquery.jobUser bq query --use_legacy_sql=false \ "GRANT \`roles/bigquery.dataEditor\` ON SCHEMA musicbrainz TO 'serviceAccount:${SERVICE_ACCOUNT}'"Erstellen Sie einen Bucket für die Dataflow-Pipeline zur Verwendung als temporäre Dateien und gewähren Sie dem Dienstkonto
musicbrainz-dataflowdie BerechtigungOwner:export DATAFLOW_TEMP_BUCKET=gs://temp-bucket-${PROJECT_ID} gsutil mb -l us ${DATAFLOW_TEMP_BUCKET} gsutil acl ch -u ${SERVICE_ACCOUNT}:O ${DATAFLOW_TEMP_BUCKET}Klonen Sie das Repository, das den Dataflow-Code enthält:
git clone https://github.com/GoogleCloudPlatform/bigquery-etl-dataflow-sample.gitÄndern Sie das Verzeichnis in das Beispiel:
cd bigquery-etl-dataflow-sampleKompilieren Sie den Dataflow-Job und führen Sie ihn aus:
./run.sh simpleDie Ausführung des Jobs dauert etwa 10 Minuten.
Wechseln Sie in der Google Cloud Console zur Seite Dataflow, um sich den Fortschritt der Pipeline anzusehen.
Der Status der Jobs wird in der Statusspalte angezeigt. Der Status Erfolgreich zeigt an, dass der Job abgeschlossen ist.
Optional: Wenn Sie die Jobgrafik und Details zu den Schritten sehen möchten, klicken Sie auf den Jobnamen, z. B.
etl-into-bigquery-bqetlsimple.Rufen Sie nach Abschluss des Jobs die BigQuery-Seite auf.
Geben Sie im Bereich Abfrageeditor zum Ausführen einer Abfrage in der neuen Tabelle Folgendes ein:
SELECT artist_name, artist_gender, artist_area, recording_name, recording_length FROM musicbrainz.recordings_by_artists_dataflow WHERE artist_area is NOT NULL AND artist_gender IS NOT NULL LIMIT 1000;Der Ergebnisbereich enthält eine Reihe von Ergebnissen, die in etwa so aussehen:
Row artist_name artist_gender artist_area recording_name recording_length 1 mirin 2 107 Sylphia 264000 2 mirin 2 107 Dependence 208000 3 Gaudiburschen 1 81 Die Hände zum Himmel 210000 4 Sa4 1 331 Ein Tag aus meiner Sicht 221000 5 Dpat 1 7326 Cutthroat 249000 6 Dpat 1 7326 Deloused 178000 Die tatsächliche Ausgabe kann abweichen, da die Ergebnisse nicht sortiert sind.
Daten bereinigen
Als Nächstes nehmen Sie eine kleine Änderung an der Dataflow-Pipeline vor, sodass Sie Suchtabellen laden und diese als Nebeneingaben verarbeiten können. Dies ist im folgenden Diagramm zu sehen:

Wenn Sie die resultierende BigQuery-Tabelle abfragen, ist es schwierig zu erahnen, woher der Interpret stammt, ohne manuell nachzusehen, wofür die numerische Gebiets-ID aus der area-Tabelle in der MusicBrainz-Datenbank steht. Dies macht die Analyse von Abfrageergebnissen schwieriger als nötig.
Ebenso wird auch das Geschlecht des Interpreten als ID angezeigt. Die gesamte MusicBrainz-Tabelle zum Geschlecht besteht jedoch nur aus drei Zeilen. Sie können dies beheben, indem Sie einen Schritt zur Dataflow-Pipeline hinzufügen, um die IDs mithilfe der area- und gender-Tabellen von MusicBrainz ihren entsprechenden Labels zuzuordnen.
Sowohl die Tabelle artist_area als auch die Tabelle artist_gender enthalten eine erheblich geringere Anzahl von Zeilen als die Tabellen für Interpreten und für Aufnahmedaten. Die Anzahl unterschiedlicher Elemente in den erstgenannten Tabellen ist durch die Anzahl der geografischen Gebiete bzw. der Geschlechter eingeschränkt.
Infolgedessen wird beim Suchschritt das Dataflow-Feature Nebeneingabe verwendet.
Nebeneingaben werden als Tabellenexporte im durch Zeilen getrennten JSON-Dateien in den öffentlichen Cloud Storage-Bucket geladen, der das Musicbrainz-Dataset enthält, und zum Denormalisieren der Tabellendaten in nur einem Schritt verwendet.
Code zum Hinzufügen von Nebeneingaben zur Pipeline
Gehen Sie vor dem Ausführen der Pipeline den Code durch, um die neuen Schritte besser nachvollziehen zu können.
Dieser Code zeigt die Datenbereinigung bei Nebeneingaben. Die Klasse MusicBrainzTransforms ist für die Nutzung von Nebeneingaben besser geeignet, um Fremdschlüsselwerte den Labels zuzuordnen. Die Bibliothek MusicBrainzTransforms bietet eine Methode zum Erstellen einer internen Suchklasse. Die Suchklasse beschreibt sämtliche Suchtabellen und die Felder, die durch Labels ersetzt werden, sowie Argumente variabler Länge. keyKey ist die Bezeichnung für die Spalte, die den Schlüssel für die Suche enthält, und valueKey ist der Name der Spalte, die das entsprechende Label enthält.
Alle Nebeneingaben werden als einzelne Zuordnungsobjekte geladen, die für die Suche nach dem entsprechenden Label für eine ID verwendet werden.
Zuerst werden die JSON-Daten für die Suchtabelle mit einem leeren Namespace in MusicBrainzDataObjects geladen und in eine Zuordnung vom Key-Spaltenwert zum Value-Spaltenwert konvertiert.
Jedes dieser Map-Objekte wird entsprechend dem Wert seines destinationKey in eine Map verschoben, wobei es sich um den Schlüssel für die Ersetzung durch den Suchwert handelt.
Dann wird der Wert für destinationKey (der mit einer Zahl beginnt) während der Transformation der Interpretenobjekte aus JSON durch das entsprechende Label ersetzt.
Führen Sie die folgenden Schritte aus, um die Decodierung der Felder artist_area und artist_gender hinzuzufügen:
Prüfen Sie in Cloud Shell, ob die Umgebung für das Pipelineskript eingerichtet ist:
export PROJECT_ID=PROJECT_ID export REGION=us-central1 export DESTINATION_TABLE=recordings_by_artists_dataflow_sideinputs export DATASET=musicbrainz export DATAFLOW_TEMP_BUCKET=gs://temp-bucket-${PROJECT_ID} export SERVICE_ACCOUNT=musicbrainz-dataflow@${PROJECT_ID}.iam.gserviceaccount.comErsetzen Sie PROJECT_ID durch die Projekt-ID Ihres Google Cloud-Projekts.
Führen Sie die Pipeline aus, um die Tabelle mit dem decodierten Bereich und dem Geschlecht des Interpreten zu erstellen:
./run.sh simple-with-lookupsWie zuvor sehen Sie den Fortschritt der Pipeline auf der Seite Dataflow.
Die Ausführung der Pipeline dauert etwa zehn Minuten.
Rufen Sie nach Abschluss des Jobs die BigQuery-Seite auf.
Wiederholen Sie dann die Abfrage, die
artist_areaundartist_genderumfasst:SELECT artist_name, artist_gender, artist_area, recording_name, recording_length FROM musicbrainz.recordings_by_artists_dataflow_sideinputs WHERE artist_area is NOT NULL AND artist_gender IS NOT NULL LIMIT 1000;In der Ausgabe werden
artist_areaundartist_gendernun decodiert:Row artist_name artist_gender artist_area recording_name recording_length 1 mirin Female Japan Sylphia 264000 2 mirin Female Japan Dependence 208000 3 Gaudiburschen Male Germany Die Hände zum Himmel 210000 4 Sa4 Male Hamburg Ein Tag aus meiner Sicht 221000 5 Dpat Male Houston Cutthroat 249000 6 Dpat Male Houston Deloused 178000 Die tatsächliche Ausgabe kann abweichen, da die Ergebnisse nicht sortiert sind.
BigQuery-Schema optimieren
Im letzten Teil dieser Anleitung führen Sie eine Pipeline aus, die mithilfe verschachtelter Felder ein besser geeignetes Tabellenschema generiert.
Nehmen Sie sich einen Moment Zeit, um sich den Code anzusehen, mit dem diese optimierte Version der Tabelle generiert wird.
Das folgende Diagramm zeigt eine leicht veränderte Dataflow-Pipeline, die die Aufnahmen des Interpreten in jeder Interpretenzeile verschachtelt, anstatt doppelte Interpretenzeilen zu erstellen.

Die Daten werden aktuell ziemlich vereinfacht dargestellt. Das heißt, dass die Darstellung eine Zeile pro zugeordneter Aufnahme umfasst, die alle Interpretenmetadaten aus dem BigQuery-Schema und alle Aufnahmen- sowie artist_credit_name-Metadaten enthält. Diese vereinfachte Darstellung hat mindestens zwei Nachteile:
- Sie wiederholt die
artist-Metadaten für jede Aufnahme, die einem Interpret zugeordnet ist, wodurch wiederum mehr Speicher benötigt wird. - Wenn Sie die Daten als JSON exportieren, wird ein Array exportiert, das diese Daten anstelle des Interpreten mit den verschachtelten Aufnahmedaten wiederholt – was vermutlich das ist, was Sie möchten.
Ohne Leistungseinbußen und ohne die Nutzung zusätzlichen Speichers können Sie, statt eine Aufnahme pro Zeile zu speichern, Aufnahmen als wiederkehrendes Feld im Interpreteneintrag speichern, indem Sie ein paar Änderungen an der Dataflow-Pipeline vornehmen.
Statt die Aufnahmen mit den Interpreteninformationen über artist_credit_name.artist zusammenzuführen, erstellt diese alternative Pipeline eine verschachtelte Liste mit Aufnahmen innerhalb eines Interpretenobjekts.
Für BigQuery gilt ein maximales Zeilengrößenlimit von 100 MB, wenn Sie Bulk-Insert-Anweisungen ausführen (10 MB für Streaming-Insert-Anweisungen). Daher beschränkt der Code die Anzahl verschachtelter Aufnahmen für einen bestimmten Datensatz. auf 1.000 Elemente, um sicherzustellen, dass dieses Limit nicht erreicht wird. Wenn ein bestimmter Interpret mehr als 1.000 Aufnahmen hat, dupliziert der Code die Zeile, einschließlich der artist-Metadaten, und fährt mit der Verschachtelung der Aufnahmedaten in der duplizierten Zeile fort.
Das folgende Diagramm zeigt die Quellen, Transformationen und Senken der Pipeline:
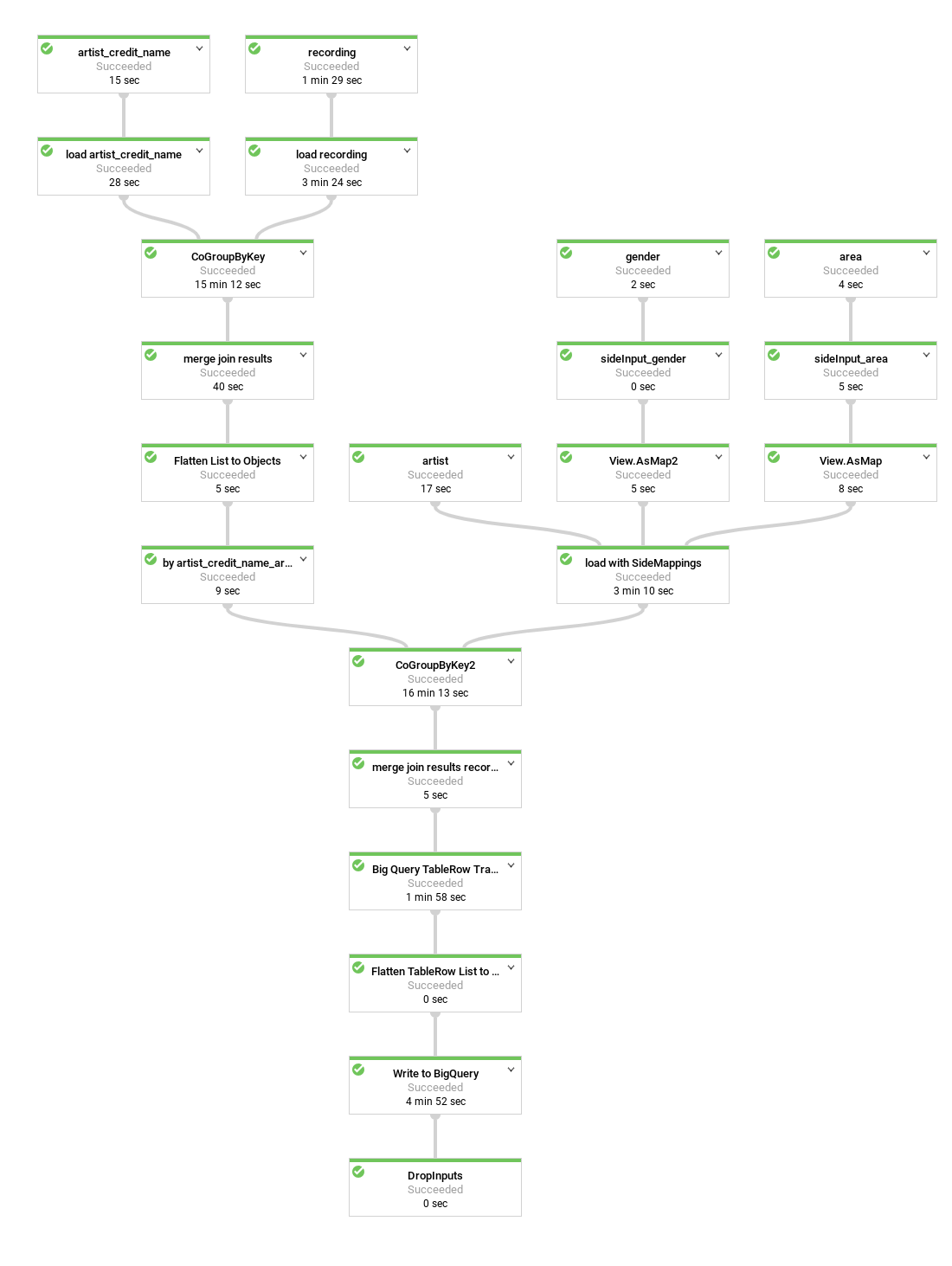
In den meisten Fällen werden die Schrittnamen im Code als Teil des apply-Methodenaufrufs angegeben.
Führen Sie die folgenden Schritte aus, um die optimierte Pipeline zu erstellen:
Prüfen Sie in Cloud Shell, ob die Umgebung für das Pipelineskript eingerichtet ist:
export PROJECT_ID=PROJECT_ID export REGION=us-central1 export DESTINATION_TABLE=recordings_by_artists_dataflow_nested export DATASET=musicbrainz export DATAFLOW_TEMP_BUCKET=gs://temp-bucket-${PROJECT_ID} export SERVICE_ACCOUNT=musicbrainz-dataflow@${PROJECT_ID}.iam.gserviceaccount.comFühren Sie die Pipeline aus, um Aufnahmezeilen innerhalb von Interpretenzeilen zu verschachteln:
./run.sh nestedWie zuvor sehen Sie den Fortschritt der Pipeline auf der Seite Dataflow.
Die Ausführung der Pipeline dauert etwa zehn Minuten.
Rufen Sie nach Abschluss des Jobs die BigQuery-Seite auf.
Fragen Sie Felder aus der verschachtelten Tabelle in BigQuery ab:
SELECT artist_name, artist_gender, artist_area, artist_recordings FROM musicbrainz.recordings_by_artists_dataflow_nested WHERE artist_area IS NOT NULL AND artist_gender IS NOT NULL LIMIT 1000;In der Ausgabe werden die
artist_recordingsals verschachtelte Zeilen angezeigt, die erweitert werden können:Row artist_name artist_gender artist_area artist_recordings 1 mirin Female Japan (5 rows) 3 Gaudiburschen Male Germany (1 row) 4 Sa4 Male Hamburg (10 rows) 6 Dpat Male Houston (9 rows) Die tatsächliche Ausgabe kann abweichen, da die Ergebnisse nicht sortiert sind.
Führen Sie eine Abfrage aus, um Werte aus dem
STRUCTzu extrahieren und zum Filtern der Ergebnisse zu verwenden. Beispiel: Künstler, die Aufnahmen mit dem Wort "Justin" haben:SELECT artist_name, artist_gender, artist_area, ARRAY(SELECT artist_credit_name_name FROM UNNEST(recordings_by_artists_dataflow_nested.artist_recordings)) AS artist_credit_name_name, ARRAY(SELECT recording_name FROM UNNEST(recordings_by_artists_dataflow_nested.artist_recordings)) AS recording_name FROM musicbrainz.recordings_by_artists_dataflow_nested, UNNEST(recordings_by_artists_dataflow_nested.artist_recordings) AS artist_recordings_struct WHERE artist_recordings_struct.recording_name LIKE "%Justin%" LIMIT 1000;In der Ausgabe werden
artist_credit_name_nameundrecording_nameals verschachtelte Zeilen angezeigt, die erweitert werden können. Beispiel:Row artist_name artist_gender artist_area artist_credit_name_name recording_name 1 Damonkenutz null null (1 row) 1 Yellowpants (Justin Martin remix) 3 Fabian Male Germany (10+ rows) 1 Heatwave . 2 Starlight Love . 3 Dreams To Wishes . 4 Last Flight (Justin Faust remix) . ... 4 Digital Punk Boys null null (6 rows) 1 Come True . 2 We Are... (Punkgirlz remix by Justin Famous) . 3 Chaos (short cut) . ... Die tatsächliche Ausgabe kann abweichen, da die Ergebnisse nicht sortiert sind.
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
Projekt löschen
- Wechseln Sie in der Google Cloud Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie dann auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Shut down (Beenden), um das Projekt zu löschen.
Einzelne Ressourcen löschen
Gehen Sie wie unten beschrieben vor, um einzelne Ressourcen statt des ganzen Projekts zu löschen.
Cloud Storage-Bucket löschen
- Wechseln Sie in der Cloud Console zur Seite Cloud Storage-Buckets.
- Klicken Sie auf das Kästchen neben dem Bucket, der gelöscht werden soll.
- Klicken Sie zum Löschen des Buckets auf Löschen und folgen Sie der Anleitung.
BigQuery-Datasets löschen
Öffnen Sie die BigQuery-Web-UI.
Wählen Sie die BigQuery-Datasets aus, die Sie in der Anleitung erstellt haben.
Klicken Sie auf Löschendelete.
Nächste Schritte
- Mehr über das Schreiben von Abfragen für BigQuery erfahren. Im Artikel Interaktive und Batch-Abfragejobs ausführen wird unter anderem erläutert, wie synchrone und asynchrone Abfragen ausgeführt und benutzerdefinierte Funktionen (User Defined Functions, UDFs) erstellt werden.
- BigQuery-Syntax erkunden. BigQuery nutzt eine SQL-ähnliche Syntax, die in der Abfragereferenz (Legacy-SQL) beschrieben wird.
- Referenzarchitekturen, Diagramme und Best Practices zu Google Cloud kennenlernen. Weitere Informationen zu Cloud Architecture Center