In dieser Anleitung erhalten Sie einen Einstieg in das Thema „Data Science bei umfangreichen Projekten mit R in Google Cloud“. Diese Anleitung richtet sich an Personen, die bereits mit R und Jupyter-Notebooks sowie mit SQL vertraut sind.
Der Schwerpunkt dieser Anleitung liegt auf der Durchführung einer explorativen Datenanalyse mit nutzerverwalteten Vertex AI Workbench-Notebooks und BigQuery. Den Code für diese Anleitung finden Sie in einem Jupyter Notebook auf GitHub.
Übersicht
R ist eine der am häufigsten verwendeten Programmiersprachen für die statistische Modellierung. Sie hat eine große und aktive Community von Data Scientists und ML-Experten. Mit über 15.000 Paketen im Open-Source-Repository des Comprehensive R Archive Network (CRAN) verfügt R über Tools für alle statistischen Datenanalyseanwendungen, ML und Visualisierung. R ist in den letzten zwei Jahrzehnten wegen der Ausdruckskraft seiner Syntax und aufgrund seiner umfassenden Daten- und ML-Bibliotheken stetig gewachsen.
Als Data Scientist möchten Sie möglicherweise wissen, wie Sie Ihr Know-how mit R nutzen können und wie Sie von den Vorteilen der skalierbaren, vollständig verwalteten Cloud-Dienste für ML profitieren können.
Architektur
In dieser Anleitung verwenden Sie nutzerverwaltete Notebooks als Data-Science-Umgebung zur Durchführung einer explorativen Datenanalyse. Sie verwenden R mit Daten, die Sie im Rahmen dieser Anleitung aus BigQuery, dem serverlosen, hoch skalierbaren und kostengünstigen Cloud Data Warehouse von Google extrahieren. Nachdem Sie die Daten analysiert und verarbeitet haben, werden die transformierten Daten in Cloud Storage für weitere ML-Aufgaben gespeichert. Dieser Ablauf wird im folgenden Diagramm dargestellt:
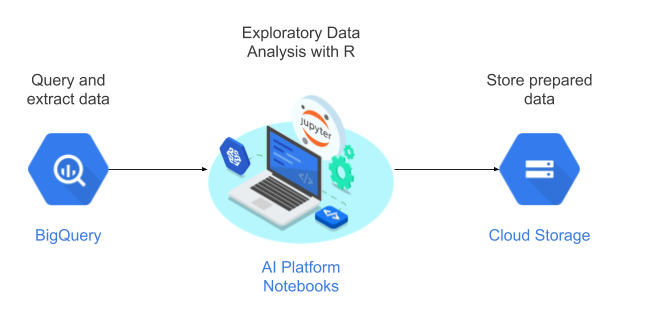
Daten für die Anleitung
Das in dieser Anleitung verwendete Dataset ist das BigQuery-Dataset „natality“. Dieses öffentliche Dataset enthält Informationen zu über 137 Millionen Geburten, die von 1969 bis 2008 in den USA registriert wurden.
Der Schwerpunkt dieser Anleitung liegt auf EDA und Visualisierungen mit R und BigQuery. In dieser Anleitung wird das Ziel des maschinellen Lernens festgelegt, das Gewicht eines Babys anhand verschiedener Faktoren zur Schwangerschaft und der Mutter des Kindes vorhergesagt werden kann. Diese Aufgabe wird in dieser Anleitung jedoch nicht behandelt.
Nutzerverwaltete Notebooks
Nutzerverwaltete Vertex AI Workbench-Notebooks sind ein Dienst, der eine integrierte JupyterLab-Umgebung mit den folgenden Features bietet:
- Bereitstellung mit nur einem Klick. Mit einem einzigen Klick können Sie eine JupyterLab-Instanz starten, die mit den neuesten Frameworks für maschinelles Lernen und Data-Science vorkonfiguriert ist.
- Nach Bedarf skalierbar. Sie können mit einer kleinen Maschinenkonfiguration beginnen, z. B. 4 vCPUs und 15 GB RAM, wie in dieser Anleitung. Wenn Ihre Daten für eine Maschine zu groß werden, können Sie sie mit CPUs, RAM und GPUs hochskalieren.
- Google Cloud-Integration. Nutzerverwaltete Vertex AI Workbench-Notebook-Instanzen sind in Google Cloud-Dienste wie BigQuery eingebunden. Diese Integration vereinfacht den Weg von der Datenaufnahme zur Vorverarbeitung und Exploration.
- Nutzungsbasierter Tarif. Es gibt keine Mindestgebühren oder Vorabverpflichtungen. Weitere Informationen finden Sie unter Preise für nutzerverwaltete Vertex AI Workbench-Notebooks. Außerdem zahlen Sie für die Google Cloud-Ressourcen, die Sie mit der nutzerverwalteten Notebook-Instanz verwenden.
Nutzerverwaltete Notebooks werden auf Deep Learning VM Images ausgeführt. Diese Images sind für die Unterstützung von ML-Frameworks wie PyTorch und TensorFlow optimiert. In dieser Anleitung wird das Erstellen einer nutzerverwalteten Notebook-Instanz mit R 3.6 unterstützt.
Mit R in BigQuery arbeiten
BigQuery erfordert keine Infrastrukturverwaltung, sodass Sie sich darauf konzentrieren können, aussagekräftige Erkenntnisse zu gewinnen. Dank BigQuery können Sie mit Ihren Daten vertrautes SQL verwenden, sodass Sie keinen Datenbankadministrator benötigen. Sie können BigQuery verwenden, um große Datenmengen in umfangreichen Projekten zu analysieren und Datasets mithilfe der umfassenden SQL-Analysefunktionen von BigQuery auf ML vorzubereiten.
Sie können bigrquery, eine Open-Source-R-Bibliothek, verwenden, um BigQuery-Daten mit R abzufragen. Das bigrquery-Paket bietet die folgenden Abstraktionsebenen zusätzlich zu BigQuery:
Die Low-Level-API bietet Thin Wrapper über die zugrunde liegende BigQuery REST-API.
Die DBI-Schnittstelle umschließt die Low-Level-API und führt dazu, dass die Arbeit mit BigQuery ähnlich verläuft wie mit jedem anderen Datenbanksystem. Diese Ebene eignet sich insbesondere dann, wenn Sie SQL-Abfragen in BigQuery ausführen oder weniger als 100 MB hochladen möchten.
Mit der Schnittstelle dbplyr können Sie BigQuery-Tabellen wie speicherinterne Datenframes verarbeiten. Dies ist die praktischste Ebene, wenn Sie keine SQL-Abfrage schreiben möchten, aber dbplyr sie für Sie schreiben soll.
In dieser Anleitung wird die Low-Level-API aus "bigrquery" verwendet, ohne dass DBI oder dbplyr benötigt wird.
Ziele
- Eine nutzerverwaltete Notebook-Instanz mit R-Unterstützung erstellen.
- Daten aus BigQuery mit der R-Bibliothek "bigrquery" abfragen und analysieren.
- Daten für ML in Cloud Storage vorbereiten und speichern.
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
- BigQuery
- Nutzerverwaltete Vertex AI Workbench-Notebook-Instanz. Außerdem werden Ihnen Ressourcen berechnet, die in Notebooks verwendet werden, darunter Rechenressourcen, BigQuery und API-Anfragen.
- Cloud Storage
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Hinweis
- Melden Sie sich bei Ihrem Google Cloud-Konto an. Wenn Sie mit Google Cloud noch nicht vertraut sind, erstellen Sie ein Konto, um die Leistungsfähigkeit unserer Produkte in der Praxis sehen und bewerten zu können. Neukunden erhalten außerdem ein Guthaben von 300 $, um Arbeitslasten auszuführen, zu testen und bereitzustellen.
-
Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
-
Compute Engine API aktivieren.
-
Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
-
Compute Engine API aktivieren.
Nutzerverwaltete Notebook-Instanz mit R erstellen
Im ersten Schritt erstellen Sie eine nutzerverwaltete Notebook-Instanz, die Sie für diese Anleitung verwenden können.
Rufen Sie in der Google Cloud Console die Seite Notebooks auf.
Klicken Sie auf dem Tab Nutzerverwaltete Notebooks auf Neues Notebook.
Wählen Sie R 3.6 aus.
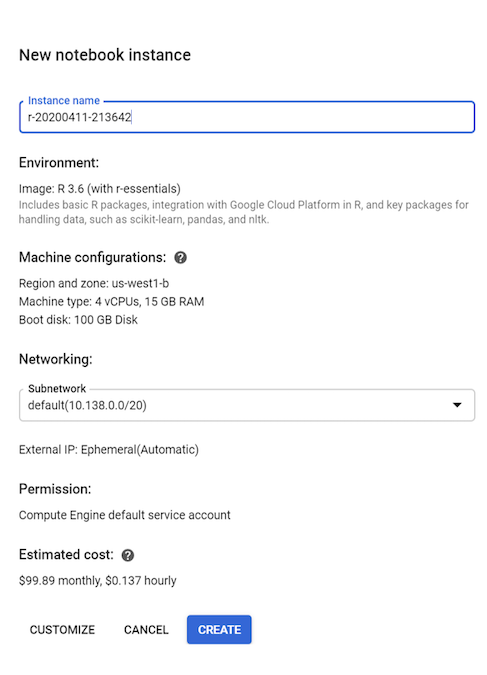
Lassen Sie in dieser Anleitung alle Standardwerte unverändert und klicken Sie auf Erstellen:
Es kann bis zu 90 Sekunden dauern, bis die nutzerverwaltete Notebook-Instanz gestartet wurde. Wenn sie fertig ist, wird sie im Bereich Notebookinstanzen mit dem Link JupyterLab öffnen neben dem Instanznamen angezeigt:
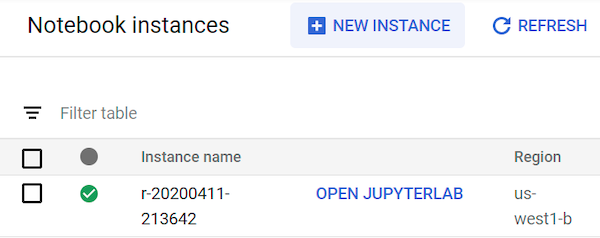
JupyterLab öffnen
Um die Anleitung im Notebook durchzugehen, müssen Sie die JupyterLab-Umgebung öffnen, das ml-on-gcp-GitHub-Repository klonen und dann das Notebook öffnen.
Klicken Sie in der Instanzliste auf Jupyterlab öffnen. Dadurch wird die JupyterLab-Umgebung im Browser geöffnet.
Klicken Sie zum Starten eines Terminal-Tabs im Launcher auf Terminal.
Klonen Sie im Terminal das GitHub-Repository
ml-on-gcp:git clone https://github.com/GoogleCloudPlatform/ml-on-gcp.gitWenn der Befehl ausgeführt ist, wird der Ordner
ml-on-gcpim Dateibrowser angezeigt.Öffnen Sie im Dateibrowser
ml-on-gcp, danntutorialsund dannR..Das Ergebnis des Klonens sieht so aus:
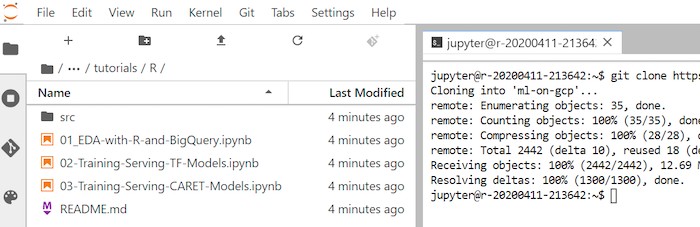
Notebook öffnen und R einrichten
Die R-Bibliotheken, die Sie für diese Anleitung benötigen, einschließlich Big Query, sind standardmäßig in R-Notebooks installiert. Im Rahmen dieses Verfahrens importieren Sie sie, um sie für das Notebook verfügbar zu machen.
Öffnen Sie im Dateibrowser das Notebook
01-EDA-with-R-and-BigQuery.ipynb.Dieses Notebook behandelt die Anleitung zur explorativen Datenanalyse mit R und BigQuery. An diesem Punkt der Anleitung arbeiten Sie im Notebook und führen den Code aus dem Jupyter-Notebook selbst aus.
Importieren Sie die R-Bibliotheken, die Sie für diese Anleitung benötigen:
library(bigrquery) # used for querying BigQuery library(ggplot2) # used for visualization library(dplyr) # used for data wranglingAuthentifizieren Sie
bigrquerymit Out-of-Band-Authentifizierung:bq_auth(use_oob = True)Legen Sie für eine Variable den Namen des Projekts fest, das Sie für diese Anleitung verwenden:
# Set the project ID PROJECT_ID <- "gcp-data-science-demo"Legen Sie eine Variable für den Namen des Cloud Storage-Buckets fest:
BUCKET_NAME <- "bucket-name"
Ersetzen Sie bucket-name durch einen global eindeutigen Namen.
Sie verwenden den Bucket später, um die Ausgabedaten zu speichern.
Daten aus BigQuery abfragen
In diesem Abschnitt der Anleitung werden die Ergebnisse der Ausführung einer BigQuery-SQL-Anweisung in R beschrieben und die Daten vorab geprüft.
Erstellen Sie eine BigQuery-SQL-Anweisung, die einige mögliche Vorhersagen und die Zielvorhersagevariable für eine Stichprobe von Geburten seit 2000 extrahiert:
sql_query <- " SELECT ROUND(weight_pounds, 2) AS weight_pounds, is_male, mother_age, plurality, gestation_weeks, cigarette_use, alcohol_use, CAST(ABS(FARM_FINGERPRINT(CONCAT( CAST(YEAR AS STRING), CAST(month AS STRING), CAST(weight_pounds AS STRING))) ) AS STRING) AS key FROM publicdata.samples.natality WHERE year > 2000 AND weight_pounds > 0 AND mother_age > 0 AND plurality > 0 AND gestation_weeks > 0 AND month > 0 LIMIT %s "Die Spalte
keyist eine generierte Zeilenkennzeichnung, die auf den verketteten Werten der Spaltenyear,monthundweight_poundsbasiert.Führen Sie die Abfrage aus und rufen Sie die Daten als speicherinternes
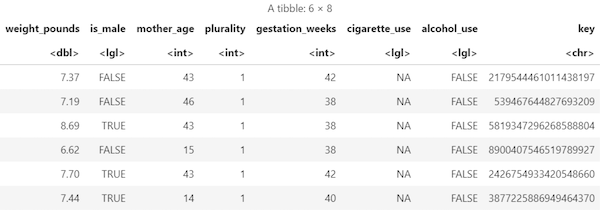
data frame-Objekt ab:sample_size <- 10000 sql_query <- sprintf(sql_query, sample_size) natality_data <- bq_table_download( bq_project_query( PROJECT_ID, query=sql_query ) )Die abgerufenen Ergebnisse anzeigen:
head(natality_data)Die Ausgabe sieht etwa so aus:
Anzahl der Zeilen und Datentypen jeder Spalte anzeigen:
str(natality_data)Die Ausgabe sieht etwa so aus:
Classes ‘tbl_df’, ‘tbl’ and 'data.frame': 10000 obs. of 8 variables: $ weight_pounds : num 7.75 7.4 6.88 9.38 6.98 7.87 6.69 8.05 5.69 9.22 ... $ is_male : logi FALSE TRUE TRUE TRUE FALSE TRUE ... $ mother_age : int 47 44 42 43 42 43 42 43 45 44 ... $ plurality : int 1 1 1 1 1 1 1 1 1 1 ... $ gestation_weeks: int 41 39 38 39 38 40 35 40 38 39 ... $ cigarette_use : logi NA NA NA NA NA NA ... $ alcohol_use : logi FALSE FALSE FALSE FALSE FALSE FALSE ... $ key : chr "3579741977144949713" "8004866792019451772" "7407363968024554640" "3354974946785669169" ...
Zusammenfassung der abgerufenen Daten anzeigen:
summary(natality_data)Die Ausgabe sieht etwa so aus:
weight_pounds is_male mother_age plurality Min. : 0.620 Mode :logical Min. :13.0 Min. :1.000 1st Qu.: 6.620 FALSE:4825 1st Qu.:22.0 1st Qu.:1.000 Median : 7.370 TRUE :5175 Median :27.0 Median :1.000 Mean : 7.274 Mean :27.3 Mean :1.038 3rd Qu.: 8.110 3rd Qu.:32.0 3rd Qu.:1.000 Max. :11.440 Max. :51.0 Max. :4.000 gestation_weeks cigarette_use alcohol_use key Min. :18.00 Mode :logical Mode :logical Length:10000 1st Qu.:38.00 FALSE:580 FALSE:8284 Class :character Median :39.00 TRUE :83 TRUE :144 Mode :character Mean :38.68 NA's :9337 NA's :1572 3rd Qu.:40.00 Max. :47.00
Daten mit ggplot2 visualisieren
In diesem Abschnitt verwenden Sie die Bibliothek ggplot2 in R, um einige Variablen aus dem Natality-Dataset zu untersuchen.
Stellen Sie die Verteilung der
weight_pounds-Werte in einem Histogramm dar:ggplot( data = natality_data, aes(x = weight_pounds) ) + geom_histogram(bins = 200)Die resultierende Darstellung sieht in etwa so aus:
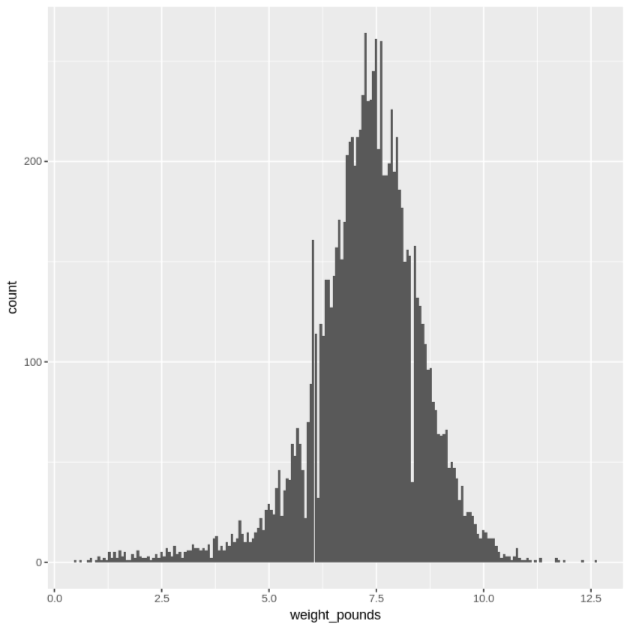
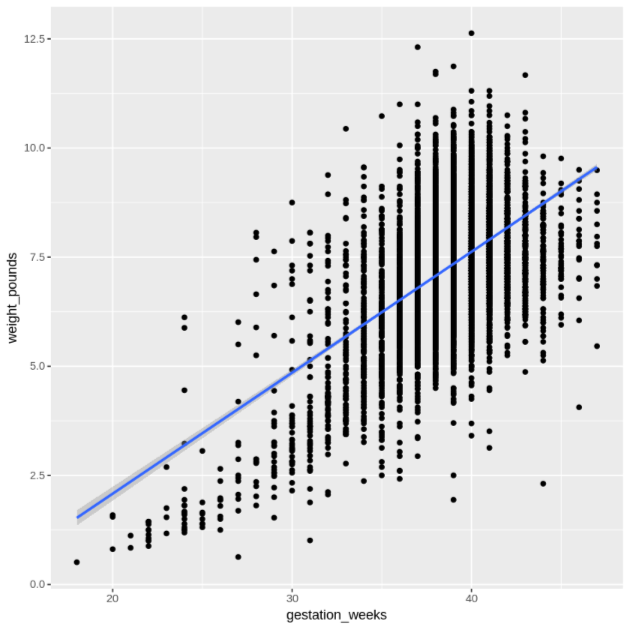
Stellen Sie die Beziehung zwischen
gestation_weeksundweight_poundsin einem Streudiagramm dar:ggplot( data = natality_data, aes(x = gestation_weeks, y = weight_pounds) ) + geom_point() + geom_smooth(method = "lm")Die resultierende Darstellung sieht in etwa so aus:
Daten in BigQuery aus R verarbeiten
Wenn Sie mit großen Datasets arbeiten, empfehlen wir, dass Sie in BigQuery so viele Analysen wie möglich ausführen (Zusammenfassung, Filterung, Join-Verknüpfungen, Computing-Spalten usw.) und dann die Ergebnisse abrufen. Das Ausführen dieser Aufgaben in R ist weniger effizient. Bei der Verwendung von BigQuery für Analysen wird die Skalierbarkeit und Leistung von BigQuery genutzt und es wird sichergestellt, dass die zurückgegebenen Ergebnisse in den Arbeitsspeicher von R passen.
Erstellen Sie eine Funktion, die die Anzahl der Datensätze und das Durchschnittsgewicht für jeden Wert der gewählten Spalte ermittelt:
get_distinct_values <- function(column_name) { query <- paste0( 'SELECT ', column_name, ', COUNT(1) AS num_babies, AVG(weight_pounds) AS avg_wt FROM publicdata.samples.natality WHERE year > 2000 GROUP BY ', column_name) bq_table_download( bq_project_query( PROJECT_ID, query = query ) ) }Rufen Sie diese Funktion mit der Spalte
mother_ageauf und sehen Sie dann die Anzahl der Babys und das durchschnittliche Gewicht nach Alter der Mutter an:df <- get_distinct_values('mother_age') ggplot(data = df, aes(x = mother_age, y = num_babies)) + geom_line() ggplot(data = df, aes(x = mother_age, y = avg_wt)) + geom_line()Die Ausgabe des ersten
ggplot-Befehls ist so und zeigt die Anzahl der geborenen Babys nach dem Alter der Mutter.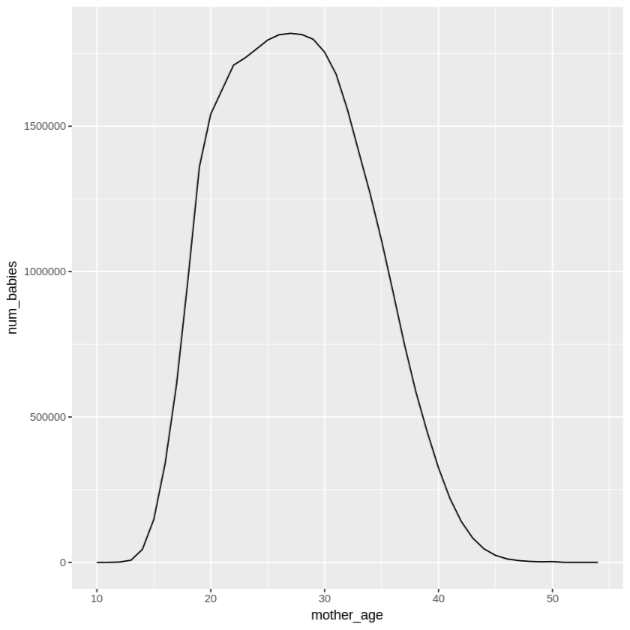
Die Ausgabe des zweiten
ggplot-Befehls sieht so aus: Sie zeigt das durchschnittliche Gewicht von Babys nach dem Alter der Mutter.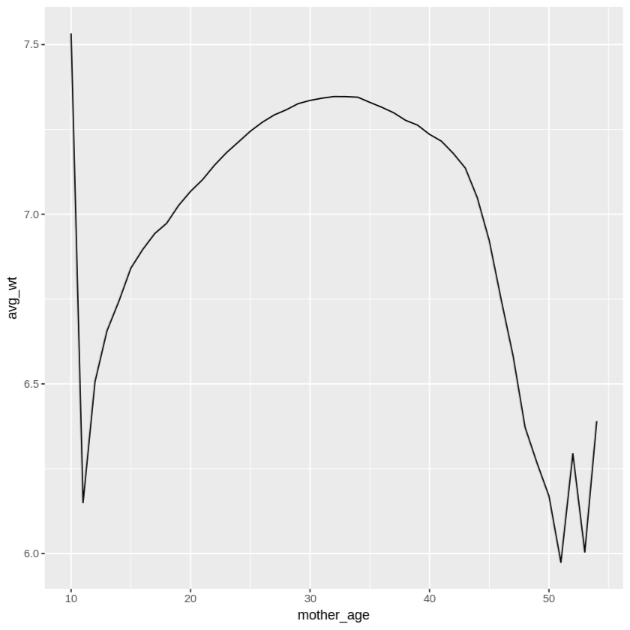
Weitere Beispiele zur Visualisierung finden Sie im Notebook.
Daten als CSV-Dateien speichern
Als Nächstes müssen Sie extrahierte Daten aus BigQuery als CSV-Dateien in Cloud Storage speichern, um sie für weitere ML-Aufgaben zu verwenden.
Laden Sie Trainings- und Evaluationsdaten aus BigQuery nach R:
# Prepare training and evaluation data from BigQuery sample_size <- 10000 sql_query <- sprintf(sql_query, sample_size) train_query <- paste('SELECT * FROM (', sql_query, ') WHERE MOD(CAST(key AS INT64), 100) <= 75') eval_query <- paste('SELECT * FROM (', sql_query, ') WHERE MOD(CAST(key AS INT64), 100) > 75') # Load training data to data frame train_data <- bq_table_download( bq_project_query( PROJECT_ID, query = train_query ) ) # Load evaluation data to data frame eval_data <- bq_table_download( bq_project_query( PROJECT_ID, query = eval_query ) )Schreiben Sie die Daten in eine lokale CSV-Datei:
# Write data frames to local CSV files, without headers or row names dir.create(file.path('data'), showWarnings = FALSE) write.table(train_data, "data/train_data.csv", row.names = FALSE, col.names = FALSE, sep = ",") write.table(eval_data, "data/eval_data.csv", row.names = FALSE, col.names = FALSE, sep = ",")Laden Sie die CSV-Dateien in den Cloud Storage hoch, indem Sie an das System übergebene
gsutil-Befehle umhüllen:# Upload CSV data to Cloud Storage by passing gsutil commands to system gcs_url <- paste0("gs://", BUCKET_NAME, "/") command <- paste("gsutil mb", gcs_url) system(command) gcs_data_dir <- paste0("gs://", BUCKET_NAME, "/data") command <- paste("gsutil cp data/*_data.csv", gcs_data_dir) system(command) command <- paste("gsutil ls -l", gcs_data_dir) system(command, intern = TRUE)Eine weitere Option für diesen Schritt ist die Verwendung der googleCloudStorageR-Bibliothek mithilfe der Cloud Storage JSON API.
Bereinigen
Entfernen Sie die in dieser Anleitung verwendeten Ressourcen, um zu vermeiden, dass Ihrem Google Cloud-Konto dafür Gebühren berechnet werden.
Projekt löschen
Am einfachsten vermeiden Sie weitere Kosten, indem Sie das für die Anleitung erstellte Projekt löschen.
- Wechseln Sie in der Google Cloud Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie dann auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Shut down (Beenden), um das Projekt zu löschen.
Nächste Schritte
- In der Dokumentation zu bigrquery erfahren, wie Sie BigQuery-Daten in Ihren R-Notebooks verwenden können
- Maschinelles Lernen: Best Practices für ML-Entwicklung
- Referenzarchitekturen, Diagramme und Best Practices zu Google Cloud kennenlernen. Weitere Informationen zu Cloud Architecture Center