In diesem Dokument wird beschrieben, wie Sie einen Exportmechanismus bereitstellen, um Logs vonGoogle Cloud -Ressourcen zu Splunk zu streamen. Es wird davon ausgegangen, dass Sie die entsprechende Referenzarchitektur für diesen Anwendungsfall bereits gelesen haben.
Diese Anleitung richtet sich an Betriebs- und Sicherheitsadministratoren, die Logs von Google Cloud zu Splunk streamen möchten. Sie müssen mit Splunk und dem HTTP Event Collector (HEC) von Splunk vertraut sein, wenn Sie diese Anweisungen für IT-Vorgänge oder Anwendungsfälle im Bereich Sicherheit verwenden. Für diese Bereitstellung ist es zwar hilfreich, mit Dataflow-Pipelines, Pub/Sub, Cloud Logging, Identity and Access Management und Cloud Storage vertraut zu sein.
Informationen zum Automatisieren der Bereitstellungsschritte in dieser Referenzarchitektur mit Infrastruktur als Code (IaC) finden Sie im GitHub-Repository terraform-splunk-log-export.
Architektur
Das folgende Diagramm zeigt die Referenzarchitektur und zeigt, wie die Logdaten von Google Cloud zu Splunk fließen.

Wie im Diagramm dargestellt, erfasst Cloud Logging die Logs in einer Logsenke auf Organisationsebene und sendet sie an Pub/Sub. Der Pub/Sub-Dienst erstellt ein einzelnes Thema und ein Abo für die Logs und leitet die Logs an die Dataflow-Hauptpipeline weiter. Die Haupt-Dataflow-Pipeline ist eine Pub/Sub to Splunk-Streaming-Pipeline, die Logs aus dem Pub/Sub-Abo abruft und an Splunk übermittelt. Parallel zur primären Dataflow-Pipeline ist die sekundäre Dataflow-Pipeline eine Pub/Sub-zu-Pub/Sub-Streaming-Pipeline, um Nachrichten wiederzugeben, wenn eine Übermittlung fehlschlägt. Am Ende des Vorgangs fungiert Splunk Enterprise oder Splunk Cloud Platform als HEC-Endpunkt und empfängt die Logs zur weiteren Analyse. Weitere Informationen finden Sie im Abschnitt Architektur der Referenzarchitektur.
Zum Bereitstellen dieser Referenzarchitektur führen Sie die folgenden Aufgaben aus:
- Führen Sie Einrichtungsaufgaben aus.
- Eine aggregierte Logsenke in einem zugehörigen Projekt erstellen.
- Erstellen Sie ein Thema für unzustellbare Nachrichten.
- Richten Sie einen Splunk-HEC-Endpunkt ein.
- Konfigurieren Sie die Dataflow-Pipelinekapazität.
- Exportieren Sie Logs nach Splunk.
- Transformieren Sie Logs oder Ereignisse während der Übertragung mit benutzerdefinierten Funktionen (User-Defined Functions, UDF) in der Splunk Dataflow-Pipeline.
- Verarbeiten Sie Übermittlungsfehler, um Datenverluste bei potenziellen Fehlkonfigurationen oder vorübergehenden Netzwerkproblemen zu vermeiden.
Hinweise
Führen Sie die folgenden Schritte aus, um eine Umgebung für die Referenzarchitektur vonGoogle Cloud zu Splunk einzurichten:
- Richten Sie ein Projekt ein, aktivieren Sie die Abrechnung und aktivieren Sie die APIs.
- Weisen Sie IAM-Rollen zu.
- Umgebung einrichten
- Richten Sie ein sicheres Netzwerk ein.
Richten Sie ein Projekt ein, aktivieren Sie die Abrechnung und aktivieren Sie die APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Monitoring API, Secret Manager, Compute Engine, Pub/Sub, and Dataflow APIs.
IAM-Rollen zuweisen
Prüfen Sie in der Google Cloud Console, ob Sie die folgenden IAM-Berechtigungen (Identity and Access Management) für Organisations- und Projektressourcen haben. Weitere Informationen finden Sie unter Zugriff auf Ressourcen erteilen, ändern und entziehen.
| Berechtigungen | Vordefinierte Rollen | Ressource |
|---|---|---|
|
|
Organisation |
|
|
Projekt |
|
|
Projekt |
Wenn die vordefinierten IAM-Rollen nicht genügend Berechtigungen enthalten, um Ihre Aufgaben auszuführen, erstellen Sie eine benutzerdefinierte Rolle. Eine benutzerdefinierte Rolle bietet Ihnen den erforderlichen Zugriff und hilft Ihnen dabei, das Prinzip der geringsten Berechtigung einzuhalten.
Umgebung einrichten
In the Google Cloud console, activate Cloud Shell.
Legen Sie das Projekt für die aktive Cloud Shell-Sitzung fest:
gcloud config set project
PROJECT_ID Ersetzen Sie
PROJECT_IDdurch Ihre Projekt-ID.
Sicheres Netzwerk einrichten
In diesem Schritt richten Sie ein sicheres Netzwerk ein, bevor Sie Logs verarbeiten und in Splunk Enterprise exportieren.
Erstellen Sie ein VPC-Netzwerk und ein Subnetz:
gcloud compute networks create
NETWORK_NAME --subnet-mode=custom gcloud compute networks subnets createSUBNET_NAME \ --network=NETWORK_NAME \ --region=REGION \ --range=192.168.1.0/24Ersetzen Sie Folgendes:
NETWORK_NAME: der Name des NetzwerksSUBNET_NAME: der Name Ihres SubnetzesREGION: die Region, die Sie für dieses Netzwerk verwenden möchten
Erstellen Sie eine Firewallregel für die virtuellen Maschinen (VMs) von Dataflow-Workern, damit sie miteinander kommunizieren können:
gcloud compute firewall-rules create allow-internal-dataflow \ --network=
NETWORK_NAME \ --action=allow \ --direction=ingress \ --target-tags=dataflow \ --source-tags=dataflow \ --priority=0 \ --rules=tcp:12345-12346Diese Regel lässt internen Traffic zwischen Dataflow-VMs zu, die die TCP-Ports 12345–12346 verwenden. Außerdem legt der Dataflow-Dienst das Tag
dataflowfest.Erstellen Sie ein Cloud-NAT-Gateway:
gcloud compute routers create nat-router \ --network=
NETWORK_NAME \ --region=REGION gcloud compute routers nats create nat-config \ --router=nat-router \ --nat-custom-subnet-ip-ranges=SUBNET_NAME \ --auto-allocate-nat-external-ips \ --region=REGION Aktivieren Sie den privaten Google-Zugriff für das Subnetz:
gcloud compute networks subnets update
SUBNET_NAME \ --enable-private-ip-google-access \ --region=REGION
Logsenke erstellen
In diesem Abschnitt erstellen Sie die organisationsweite Logsenke und das zugehörige Pub/Sub-Ziel sowie die erforderlichen Berechtigungen.
Erstellen Sie in Cloud Shell ein Pub/Sub-Thema und das zugehörige Abo als neues Ziel für die Logsenke:
gcloud pubsub topics create
INPUT_TOPIC_NAME gcloud pubsub subscriptions create \ --topicINPUT_TOPIC_NAME INPUT_SUBSCRIPTION_NAME Ersetzen Sie Folgendes:
INPUT_TOPIC_NAME: der Name des Pub/Sub-Themas, das als Ziel der Logsenke verwendet werden sollINPUT_SUBSCRIPTION_NAME: der Name des Pub/Sub-Abos für das Logsenkenziel
Erstellen Sie die Logsenke der Organisation:
gcloud logging sinks create
ORGANIZATION_SINK_NAME \ pubsub.googleapis.com/projects/PROJECT_ID /topics/INPUT_TOPIC_NAME \ --organization=ORGANIZATION_ID \ --include-children \ --log-filter='NOT logName:projects/PROJECT_ID /logs/dataflow.googleapis.com'Ersetzen Sie Folgendes:
ORGANIZATION_SINK_NAME: der Name Ihrer Senke in der OrganisationORGANIZATION_ID: Ihre Organisations-ID.
Der Befehl besteht aus folgenden Flags:
- Das
--organizationFlag gibt an, dass es sich um eine Logsenke auf Organisationsebene handelt. - Das Flag
--include-childrenist erforderlich und sorgt dafür, dass die Logsenke auf Organisationsebene alle Logs in allen Unterordnern und Projekten enthält. - Das
--log-filterFlag gibt die Logs an, die weitergeleitet werden sollen. In diesem Beispiel schließen Sie Dataflow-Vorgangslogs speziell für das ProjektPROJECT_IDaus, da die Dataflow-Pipeline für den Logexport selbst mehr Logs generiert, während sie Logs verarbeitet. Der Filter verhindert, dass die Pipeline ihre eigenen Logs exportiert, wodurch ein potenziell exponentieller Zyklus vermieden wird. Die Ausgabe enthält ein Dienstkonto im Formato#####-####@gcp-sa-logging.iam.gserviceaccount.com.
Weisen Sie dem Dienstkonto der Logsenke im Pub/Sub-Thema
INPUT_TOPIC_NAMEdie IAM-Rolle „Pub/Sub-Publisher“ zu. Mit dieser Rolle kann das Dienstkonto der Logsenke Nachrichten zum Thema veröffentlichen.gcloud pubsub topics add-iam-policy-binding
INPUT_TOPIC_NAME \ --member=serviceAccount:LOG_SINK_SERVICE_ACCOUNT @PROJECT_ID .iam.gserviceaccount.com \ --role=roles/pubsub.publisherErsetzen Sie
LOG_SINK_SERVICE_ACCOUNTdurch den Namen des Dienstkontos für Ihre Logsenke.
Thema für unzustellbare Nachrichten erstellen
Erstellen Sie ein Pub/Sub-Thema für nicht übermittelbare Nachrichten und ein entsprechendes Abo, um potenzielle Datenverluste zu vermeiden, die auftreten, wenn eine Nachricht nicht übermittelt werden kann. Die fehlgeschlagene Nachricht wird im Thema für unzustellbare Nachrichten gespeichert, bis ein Operator oder ein Site Reliability Engineer den Fehler untersuchen und beheben kann. Weitere Informationen finden Sie im Abschnitt Fehlgeschlagene Nachrichten wiedergeben der Referenzarchitektur.
Erstellen Sie in Cloud Shell ein Pub/Sub-Thema für unzustellbare Nachrichten und ein Abo, um Datenverlust zu vermeiden, indem Sie nicht zustellbare Nachrichten speichern:
gcloud pubsub topics create
DEAD_LETTER_TOPIC_NAME gcloud pubsub subscriptions create --topicDEAD_LETTER_TOPIC_NAME DEAD_LETTER_SUBSCRIPTION_NAME Ersetzen Sie Folgendes:
DEAD_LETTER_TOPIC_NAME: der Name des Pub/Sub-Themas, das das Thema für nicht übermittelbare Nachrichten istDEAD_LETTER_SUBSCRIPTION_NAME: der Name des Pub/Sub-Abos für das Thema für nicht übermittelbare Nachrichten
Splunk-HEC-Endpunkt einrichten
In den folgenden Verfahren richten Sie einen Splunk-HEC-Endpunkt ein und speichern das neu erstellte HEC-Token als Secret in Secret Manager. Wenn Sie die Splunk-Dataflow-Pipeline bereitstellen, müssen Sie sowohl die Endpunkt-URL als auch das Token angeben.
Splunk-HEC konfigurieren
- Wenn Sie noch keinen Splunk HEC-Endpunkt haben, finden Sie in der Splunk-Dokumentation Informationen zur Konfiguration von Splunk HEC. Splunk HEC wird auf dem Splunk Cloud Platform-Dienst oder auf Ihrer eigenen Splunk Enterprise-Instanz ausgeführt. Lassen Sie die Option „Splunk HEC Indexer Acknowledgement“ deaktiviert, da sie von Splunk Dataflow nicht unterstützt wird.
- Kopieren Sie in Splunk nach dem Erstellen eines Splunk HEC-Tokens den Tokenwert.
- Speichern Sie in Cloud Shell den Splunk HEC-Tokenwert in einer temporären Datei namens
splunk-hec-token-plaintext.txt.
Splunk-HEC-Token in Secret Manager speichern
In diesem Schritt erstellen Sie ein Secret und eine einzelne zugrunde liegende Secret-Version, in der der Splunk-HEC-Tokenwert gespeichert wird.
Erstellen Sie in Cloud Shell ein Secret zum Speichern Ihres Splunk-HEC-Tokens:
gcloud secrets create hec-token \ --replication-policy="automatic"
Weitere Informationen zu den Replikationsrichtlinien für Secrets finden Sie unter Replikationsrichtlinie auswählen.
Fügen Sie das Token als Secret-Version hinzu. Verwenden Sie dazu den Inhalt der Datei
splunk-hec-token-plaintext.txt:gcloud secrets versions add hec-token \ --data-file="./splunk-hec-token-plaintext.txt"
Löschen Sie die Datei
splunk-hec-token-plaintext.txt, da sie nicht mehr benötigt wird.
Dataflow-Pipelinekapazität konfigurieren
In der folgenden Tabelle sind die empfohlenen allgemeinen Best Practices für die Konfiguration der Dataflow-Pipeline-Kapazitätseinstellungen zusammengefasst:
| Einstellung | Allgemeine Best Practice |
|---|---|
|
Auf Basis der Maschinengröße |
|
Auf die maximale Anzahl von Workern festgelegt, die Sie benötigen, um die erwarteten Spitzen-EPS gemäß Ihren Berechnungen zu verarbeiten |
|
Für 2 x vCPUs/Worker x die maximale Anzahl von Workern festlegen, um die Anzahl der parallelen Splunk HEC-Verbindungen zu maximieren |
|
Für Logs 10 bis 50 Ereignisse/Anfrage einstellen, sofern die maximale Pufferverzögerung von zwei Sekunden akzeptabel ist |
Denken Sie daran, Ihre eigenen eindeutigen Werte und Berechnungen zu verwenden, wenn Sie diese Referenzarchitektur in Ihrer Umgebung bereitstellen.
Legen Sie Werte für Maschinentyp und Anzahl der Maschinen fest. Informationen zum Berechnen der Werte, die für Ihre Cloud-Umgebung geeignet sind, finden Sie in den Abschnitten Maschinentyp und Maschinenanzahl der Referenzarchitektur.
DATAFLOW_MACHINE_TYPE DATAFLOW_MACHINE_COUNT Legen Sie die Werte für die Parallelität und Batch-Anzahl von Dataflow fest. Informationen zum Berechnen der für Ihre Cloud-Umgebung geeigneten Werte finden Sie in den Abschnitten Parallelität und Batchanzahl der Referenzarchitektur.
JOB_PARALLELISM JOB_BATCH_COUNT
Weitere Informationen zur Berechnung der Kapazitätsparameter von Dataflow-Pipelines finden Sie im Abschnitt Überlegungen zur Leistungs- und Kostenoptimierung der Referenzarchitektur.
Logs mit der Dataflow-Pipeline exportieren
In diesem Abschnitt stellen Sie die Dataflow-Pipeline mit den folgenden Schritten bereit:
- Erstellen Sie einen Cloud Storage-Bucket und ein Dataflow-Worker-Dienstkonto.
- Weisen Sie dem Dataflow-Worker-Dienstkonto Rollen und Zugriff zu.
- Stellen Sie die Dataflow-Pipeline bereit.
- Sehen Sie sich die Logs in Splunk an.
Die Pipeline sendet Google Cloud Lognachrichten an den Splunk HEC.
Cloud Storage-Bucket und Dataflow-Worker-Dienstkonto erstellen
Erstellen Sie in Cloud Shell einen neuen Cloud Storage-Bucket mit einer einheitlichen Zugriffseinstellung auf Bucket-Ebene:
gcloud storage buckets create gs://
PROJECT_ID -dataflow/ --uniform-bucket-level-accessIm Cloud Storage-Bucket, den Sie gerade erstellt haben, werden die temporären Dateien vom Dataflow-Job bereitgestellt.
Erstellen Sie in Cloud Shell ein Dienstkonto für Ihre Dataflow-Worker:
gcloud iam service-accounts create
WORKER_SERVICE_ACCOUNT \ --description="Worker service account to run Splunk Dataflow jobs" \ --display-name="Splunk Dataflow Worker SA"Ersetzen Sie
WORKER_SERVICE_ACCOUNTdurch den Namen, den Sie für das Dataflow-Worker-Dienstkonto verwenden möchten.
Rollen und Zugriff auf das Dataflow-Worker-Dienstkonto gewähren
Weisen Sie in diesem Abschnitt dem Dataflow-Worker-Dienstkonto die erforderlichen Rollen zu, wie in der folgenden Tabelle dargestellt.
| Rolle | Pfad | Purpose |
|---|---|---|
| Dataflow-Administrator |
|
Aktivieren Sie das Dienstkonto, das als Dataflow-Administrator fungiert. |
| Dataflow-Worker |
|
Aktivieren Sie das Dienstkonto, das als Dataflow-Worker fungieren soll. |
| Storage-Objekt-Administrator |
|
Aktivieren Sie das Dienstkonto, um auf den Cloud Storage-Bucket zuzugreifen, der von Dataflow für Staging-Dateien verwendet wird. |
| Pub/Sub-Publisher |
|
Aktivieren Sie das Dienstkonto, um fehlgeschlagene Nachrichten im Pub/Sub-Thema für unzustellbare Nachrichten zu veröffentlichen. |
| Pub/Sub-Abonnent |
|
Aktivieren Sie das Dienstkonto für den Zugriff auf das Eingabeabo. |
| Pub/Sub-Betrachter |
|
Aktivieren Sie das Dienstkonto, um das Abo aufzurufen. |
| Zugriffsperson für Secret Manager-Secret |
|
Aktivieren Sie das Dienstkonto, um auf das Secret zuzugreifen, das das Splunk HEC-Token enthält. |
Weisen Sie in Cloud Shell dem Konto des Dataflow-Workers die Rollen „Dataflow-Administrator“ und „Dataflow-Worker“ zu, die dieses Konto zur Ausführung von Dataflow-Jobvorgängen und Verwaltungsaufgaben benötigt:
gcloud projects add-iam-policy-binding
PROJECT_ID \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT @PROJECT_ID .iam.gserviceaccount.com" \ --role="roles/dataflow.admin"gcloud projects add-iam-policy-binding
PROJECT_ID \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT @PROJECT_ID .iam.gserviceaccount.com" \ --role="roles/dataflow.worker"Gewähren Sie dem Dataflow-Worker-Dienstkonto Zugriff zum Aufrufen und Verarbeiten von Nachrichten aus dem Pub/Sub-Eingabeabo:
gcloud pubsub subscriptions add-iam-policy-binding
INPUT_SUBSCRIPTION_NAME \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT @PROJECT_ID .iam.gserviceaccount.com" \ --role="roles/pubsub.subscriber"gcloud pubsub subscriptions add-iam-policy-binding
INPUT_SUBSCRIPTION_NAME \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT @PROJECT_ID .iam.gserviceaccount.com" \ --role="roles/pubsub.viewer"Gewähren Sie dem Dataflow-Worker-Dienstkonto Zugriff auf die Veröffentlichung fehlgeschlagener Nachrichten im Pub/Sub-Thema für nicht verarbeitete Datensätze:
gcloud pubsub topics add-iam-policy-binding
DEAD_LETTER_TOPIC_NAME \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT @PROJECT_ID .iam.gserviceaccount.com" \ --role="roles/pubsub.publisher"Gewähren Sie dem Dataflow-Worker-Dienstkonto Zugriff auf das Splunk HEC-Token-Secret in Secret Manager:
gcloud secrets add-iam-policy-binding hec-token \ --member="serviceAccount:
WORKER_SERVICE_ACCOUNT @PROJECT_ID .iam.gserviceaccount.com" \ --role="roles/secretmanager.secretAccessor"Gewähren Sie dem Dataflow-Worker-Dienstkonto Lese- und Schreibzugriff auf den Cloud Storage-Bucket, der vom Dataflow-Job für das Staging von Dateien verwendet werden soll:
gcloud storage buckets add-iam-policy-binding gs://
PROJECT_ID -dataflow/ \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT @PROJECT_ID .iam.gserviceaccount.com" --role=”roles/storage.objectAdmin”
Dataflow-Pipeline bereitstellen
Legen Sie in Cloud Shell die folgende Umgebungsvariable für die Splunk HEC-URL fest:
export SPLUNK_HEC_URL=
SPLUNK_HEC_URL Ersetzen Sie die Variable
SPLUNK_HEC_URLim Formatprotocol://host[:port]. Dabei gilt:protocolist entwederhttpoderhttps.hostist der voll qualifizierte Domainname (FQDN) oder die IP-Adresse Ihrer Splunk HEC-Instanz oder, wenn Sie mehrere HEC-Instanzen haben, der zugehörige HTTP(S)- (oder DNS-basierte) Load-Balancer.portist die HEC-Portnummer. Er ist optional und hängt von der Splunk HEC-Endpunktkonfiguration ab.
Ein Beispiel für eine gültige Splunk HEC-URL-Eingabe ist
https://splunk-hec.example.com:8088. Wenn Sie Daten an HEC in der Splunk Cloud Platform senden, finden Sie unter Daten an HEC in Splunk Cloud senden Informationen zum Ermitteln der oben genannten TeilehostundportIhrer spezifischen Splunk HEC-URL.Die Splunk-HEC-URL darf den HEC-Endpunktpfad nicht enthalten, z. B.
/services/collector. Die Dataflow-Vorlage "Pub/Sub to Splunk" unterstützt derzeit nur den Endpunkt/services/collectorfür JSON-formatierte Ereignisse und hängt diesen Pfad automatisch an die Splunk HEC-URL-Eingabe an. Weitere Informationen zu diesem HEC-Endpunkt finden Sie in der Splunk-Dokumentation für den services/collector-Endpunkt.Stellen Sie die Dataflow-Pipeline mit der Dataflow-Vorlage „Pub/Sub to Splunk“ bereit:
gcloud beta dataflow jobs run
JOB_NAME \ --gcs-location=gs://dataflow-templates/latest/Cloud_PubSub_to_Splunk \ --staging-location=gs://PROJECT_ID -dataflow/temp/ \ --worker-machine-type=DATAFLOW_MACHINE_TYPE \ --max-workers=DATAFLOW_MACHINE_COUNT \ --region=REGION \ --network=NETWORK_NAME \ --subnetwork=regions/REGION /subnetworks/SUBNET_NAME \ --disable-public-ips \ --parameters \ inputSubscription=projects/PROJECT_ID /subscriptions/INPUT_SUBSCRIPTION_NAME ,\ outputDeadletterTopic=projects/PROJECT_ID /topics/DEAD_LETTER_TOPIC_NAME ,\ url=SPLUNK_HEC_URL ,\ tokenSource=SECRET_MANAGER, \ tokenSecretId=projects/PROJECT_ID /secrets/hec-token/versions/1, \ batchCount=JOB_BATCH_COUNT ,\ parallelism=JOB_PARALLELISM ,\ javascriptTextTransformGcsPath=gs://splk-public/js/dataflow_udf_messages_replay.js,\ javascriptTextTransformFunctionName=processJOB_NAMEdurch das Namensformatpubsub-to-splunk-date+"%Y%m%d-%H%M%S"ersetzenDie optionalen Parameter
javascriptTextTransformGcsPathundjavascriptTextTransformFunctionNamegeben eine öffentlich verfügbare Beispiel-UDF an:gs://splk-public/js/dataflow_udf_messages_replay.js. Die Beispiel-UDF enthält Codebeispiele für die Ereignistransformations- und Decodierungslogik, mit der Sie fehlgeschlagene Zustellungen wiederholen. Weitere Informationen zu UDF finden Sie unter Ereignisse während der Laufzeit mit UDF transformieren.Wenn der Pipelinejob abgeschlossen ist, suchen Sie die neue Job-ID in der Ausgabe, kopieren Sie die Job-ID und speichern sie. Sie geben diese Job-ID in einem späteren Schritt ein.
Logs in Splunk ansehen
Es dauert einige Minuten, bis die Dataflow-Pipeline-Worker bereitgestellt und bereit sind, Logs an Splunk HEC zu senden. Sie können in der Splunk Enterprise- oder Splunk Cloud Platform-Suchoberfläche prüfen, ob die Logs ordnungsgemäß empfangen und indexiert werden. So zeigen Sie die Anzahl der Logs pro Typ der überwachten Ressource an:
Öffnen Sie in Splunk Splunk Search & Reporting.
Führen Sie den Suchbefehl
index=[MY_INDEX] | stats count by resource.typeaus, um den IndexMY_INDEXfür Ihr Splunk HEC-Token zu konfigurieren: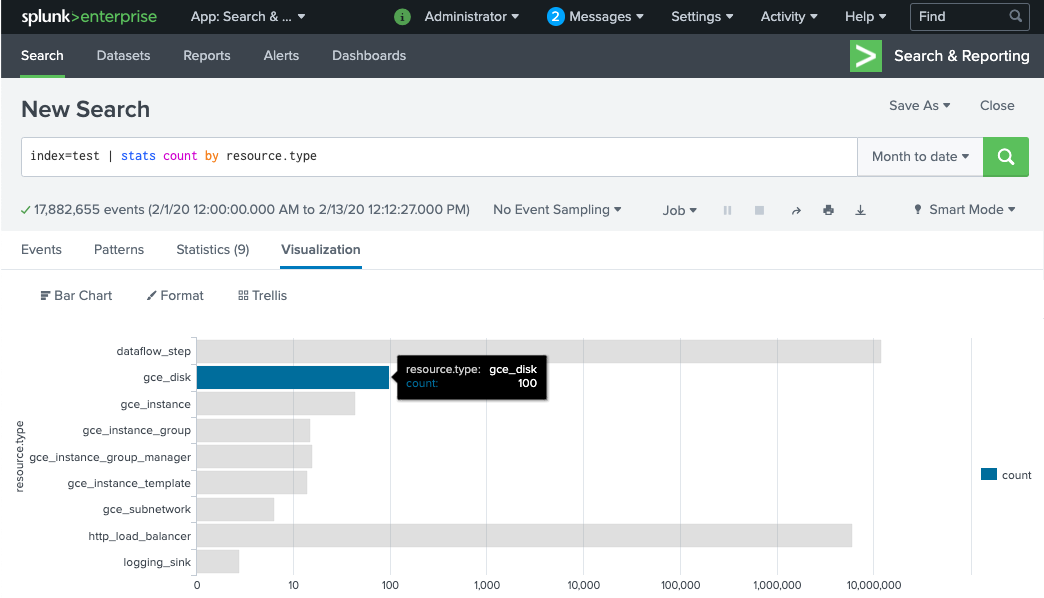
Wenn Sie keine Ereignisse sehen, lesen Sie den Abschnitt Übermittlungsfehler verarbeiten.
Ereignisse während der Laufzeit mit UDF umwandeln
Die Dataflow-Vorlage Pub/Sub zu Splunk unterstützt eine JavaScript-UDF für benutzerdefinierte Ereignistransformationen, z. B. das Hinzufügen neuer Felder oder das Festlegen von Splunk HEC-Metadaten auf Ereignisbasis. Die von Ihnen bereitgestellte Pipeline verwendet diese Beispiel-UDF.
In diesem Abschnitt bearbeiten Sie zuerst die Beispiel-UDF-Funktion, um ein neues Ereignisfeld hinzuzufügen. In diesem neuen Feld wird der Wert des ursprünglichen Pub/Sub-Abos als zusätzliche Kontextinformationen angegeben. Anschließend aktualisieren Sie die Dataflow-Pipeline mit der geänderten UDF.
Beispiel-UDF ändern
Laden Sie in Cloud Shell die JavaScript-Datei herunter, die die Beispiel-UDF-Funktion enthält:
wget https://storage.googleapis.com/splk-public/js/dataflow_udf_messages_replay.js
Öffnen Sie in einem Texteditor Ihrer Wahl die JavaScript-Datei, suchen Sie das Feld
event.inputSubscription, entfernen Sie das Kommentarzeichen in dieser Zeile und ersetzen Siesplunk-dataflow-pipelinedurchINPUT_SUBSCRIPTION_NAME:event.inputSubscription = "
INPUT_SUBSCRIPTION_NAME ";Speichern Sie die Datei.
Laden Sie die Datei in den Cloud Storage-Bucket hoch.
gcloud storage cp ./dataflow_udf_messages_replay.js gs://
PROJECT_ID -dataflow/js/
Dataflow-Pipeline mit der neuen UDF aktualisieren
Beenden Sie die Pipeline in Cloud Shell mit der Drain-Option, damit die Logs, die bereits aus Pub/Sub abgerufen wurden, nicht verloren gehen:
gcloud dataflow jobs drain
JOB_ID --region=REGION Führen Sie den Dataflow-Pipelinejob mit der aktualisierten UDF aus.
gcloud beta dataflow jobs run
JOB_NAME \ --gcs-location=gs://dataflow-templates/latest/Cloud_PubSub_to_Splunk \ --worker-machine-type=DATAFLOW_MACHINE_TYPE \ --max-workers=DATAFLOW_MACHINE_COUNT \ --region=REGION \ --network=NETWORK_NAME \ --subnetwork=regions/REGION /subnetworks/SUBNET_NAME \ --disable-public-ips \ --parameters \ inputSubscription=projects/PROJECT_ID /subscriptions/INPUT_SUBSCRIPTION_NAME ,\ outputDeadletterTopic=projects/PROJECT_ID /topics/DEAD_LETTER_TOPIC_NAME ,\ url=SPLUNK_HEC_URL ,\ tokenSource=SECRET_MANAGER, \ tokenSecretId=projects/PROJECT_ID /secrets/hec-token/versions/1, \ batchCount=JOB_BATCH_COUNT ,\ parallelism=JOB_PARALLELISM ,\ javascriptTextTransformGcsPath=gs://PROJECT_ID -dataflow/js/dataflow_udf_messages_replay.js,\ javascriptTextTransformFunctionName=processJOB_NAMEdurch das Namensformatpubsub-to-splunk-date+"%Y%m%d-%H%M%S"ersetzen
Übermittlungsfehler verarbeiten
Fehler bei der Zustellung können aufgrund von Fehlern bei der Verarbeitung der Ereignisse oder der Verbindung mit Splunk HEC auftreten. In diesem Abschnitt führen Sie einen Übermittlungsfehler durch, um den Workflow zur Fehlerbehandlung zu demonstrieren. Sie erfahren auch, wie Sie die erneute Übermittlung der fehlgeschlagenen Nachrichten an Splunk anzeigen und auslösen.
Zustellungsfehler auslösen
Führen Sie einen der folgenden Schritte aus, um einen Übermittlungsfehler in Splunk manuell einzuführen:
- Wenn Sie eine einzelne Instanz ausführen, beenden Sie den Splunk-Server, um Verbindungsfehler zu verursachen.
- Deaktivieren Sie das relevante HEC-Token aus der Splunk-Eingabekonfiguration.
Fehlerbehebung bei fehlgeschlagenen Nachrichten
Um eine fehlgeschlagene Nachricht zu untersuchen, können Sie die Google Cloud Console verwenden:
Rufen Sie in der Google Cloud Console die Seite Pub/Sub-Abos auf.
Klicken Sie auf das unverarbeitete Abo, das Sie erstellt haben. Wenn Sie das vorherige Beispiel verwendet haben, lautet der Abo-Name
projects/PROJECT_ID/subscriptions/DEAD_LETTER_SUBSCRIPTION_NAME.Klicken Sie zum öffnen der Nachrichtenanzeige auf Nachrichten anzeigen.
Klicken Sie zum Abrufen von Nachrichten auf Pull. Außerdem muss die Option Bestätigungsnachrichten aktivieren deaktiviert sein.
Prüfen Sie die fehlgeschlagenen Nachrichten. Achten Sie auf Folgendes:
- Die Splunk-Ereignisnutzlast in der Spalte
Message body. - Die Fehlermeldung in der Spalte
attribute.errorMessage. - Der Fehlerzeitstempel in der Spalte
attribute.timestamp.
- Die Splunk-Ereignisnutzlast in der Spalte
Der folgende Screenshot zeigt ein Beispiel für eine Fehlermeldung, die Sie erhalten, wenn der Splunk HEC-Endpunkt vorübergehend nicht verfügbar oder nicht erreichbar ist. Der Text des Attributs errorMessage lautet The target server failed to respond.
Die Nachricht enthält auch den Zeitstempel, der mit jedem Fehler verknüpft ist. Sie können diesen Zeitstempel verwenden, um die Ursache des Fehlers zu beheben.

Fehlgeschlagene Nachrichten wiedergeben
In diesem Abschnitt müssen Sie den Splunk-Server neu starten oder den Splunk HEC-Endpunkt aktivieren, um den Bereitstellungsfehler zu beheben. Sie können dann die nicht verarbeiteten Nachrichten wiedergeben.
Verwenden Sie in Splunk eine der folgenden Methoden, um die Verbindung zuGoogle Cloudwiederherzustellen:
- Wenn Sie den Splunk-Server gestoppt haben, starten Sie den Server neu.
- Wenn Sie den Splunk HEC-Endpunkt im Abschnitt Trigger für fehlgeschlagene Übermittlung deaktiviert haben, prüfen Sie, ob der Splunk HEC-Endpunkt jetzt funktioniert.
Erstellen Sie in Cloud Shell einen Snapshot des nicht verarbeiteten Abos, bevor Sie die Nachrichten in diesem Abo noch einmal verarbeiten. Der Snapshot verhindert den Verlust von Nachrichten, wenn ein unerwarteter Konfigurationsfehler auftritt.
gcloud pubsub snapshots create
SNAPSHOT_NAME \ --subscription=DEAD_LETTER_SUBSCRIPTION_NAME Ersetzen Sie
SNAPSHOT_NAMEdurch einen Namen, mit dem Sie den Snapshot identifizieren können, z. B.dead-letter-snapshot-date+"%Y%m%d-%H%M%S.Verwenden Sie die Dataflow-Vorlage „Pub/Sub to Splunk“ zum Erstellen einer Pub/Sub-zu-Pub/Sub-Pipeline. Die Pipeline verwendet einen anderen Dataflow-Job, um die Nachrichten aus dem nicht verarbeiteten Abo wieder an das Eingabethema zu übertragen.
DATAFLOW_INPUT_TOPIC="
INPUT_TOPIC_NAME " DATAFLOW_DEADLETTER_SUB="DEAD_LETTER_SUBSCRIPTION_NAME " JOB_NAME=splunk-dataflow-replay-date +"%Y%m%d-%H%M%S" gcloud dataflow jobs runJOB_NAME \ --gcs-location= gs://dataflow-templates/latest/Cloud_PubSub_to_Cloud_PubSub \ --worker-machine-type=n2-standard-2 \ --max-workers=1 \ --region=REGION \ --parameters \ inputSubscription=projects/PROJECT_ID /subscriptions/DEAD_LETTER_SUBSCRIPTION_NAME ,\ outputTopic=projects/PROJECT_ID /topics/INPUT_TOPIC_NAME Kopieren Sie die Dataflow-Job-ID aus der Befehlsausgabe und speichern Sie sie für später. Sie geben diese Job-ID als
REPLAY_JOB_IDein, wenn Sie den Dataflow-Job per Drain beenden.Rufen Sie in der Google Cloud Console die Seite Pub/Sub-Abos auf.
Wählen Sie das nicht verarbeitete Abo aus. Prüfen Sie, ob die Grafik Unbestätigte Nachrichtenanzahl auf 0 reduziert ist, wie im folgenden Screenshot dargestellt.

Entfernen Sie in Cloud Shell den von Ihnen erstellten Dataflow-Job:
gcloud dataflow jobs drain
REPLAY_JOB_ID --region=REGION Ersetzen Sie
REPLAY_JOB_IDdurch die zuvor gespeicherte Dataflow-Job-ID.
Wenn Nachrichten wieder in das ursprüngliche Eingabethema übertragen werden, übernimmt die Dataflow-Hauptpipeline die fehlgeschlagenen Nachrichten automatisch und übermittelt sie an Splunk.
Nachrichten in Splunk bestätigen
Öffnen Sie in Splunk Splunk Search & Reporting, um zu bestätigen, dass die Nachrichten noch einmal übermittelt wurden.
Führen Sie eine Suche nach
delivery_attempts > 1durch. Dies ist ein spezielles Feld, das die Beispiel-UDF jedem Ereignis hinzufügt, um die Anzahl der Übermittlungsversuche zu verfolgen. Erweitern Sie den Suchzeitbereich um Ereignisse, die möglicherweise in der Vergangenheit aufgetreten sind, da der Ereigniszeitstempel der ursprüngliche Zeitpunkt der Erstellung und nicht der Zeitpunkt der Indizierung ist.
Im folgenden Screenshot werden die beiden ursprünglich fehlgeschlagenen Nachrichten jetzt erfolgreich zugestellt und in Splunk mit dem richtigen Zeitstempel indexiert.
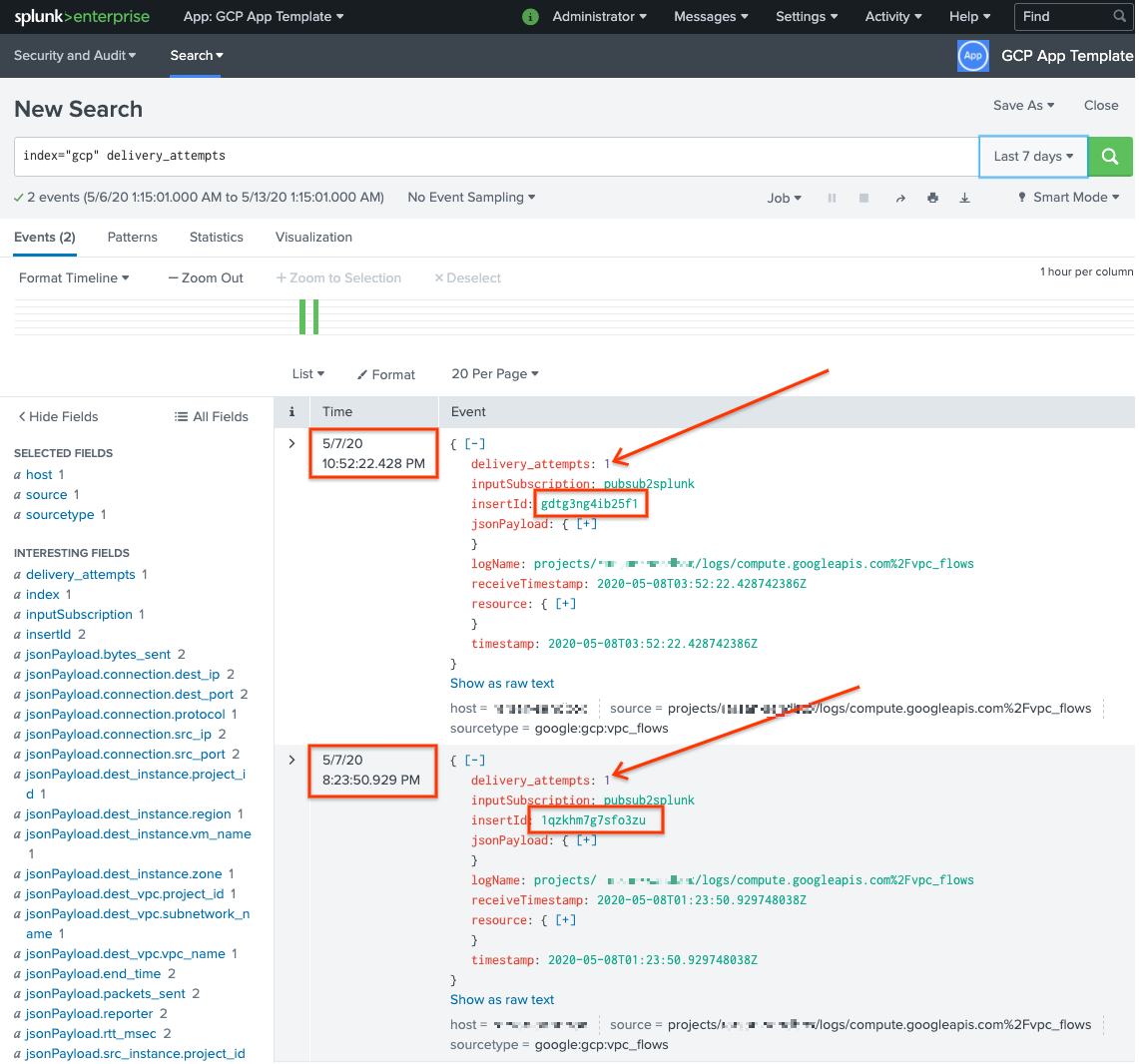
Beachten Sie, dass der Feldwert insertId mit dem Wert übereinstimmt, der in den fehlgeschlagenen Nachrichten angezeigt wird, wenn Sie das nicht verarbeitete Abo aufrufen.
Das Feld insertId ist eine eindeutige Kennung, die Cloud Logging dem ursprünglichen Logeintrag zuweist. insertId wird auch im Pub/Sub-Nachrichtentext angezeigt.
Bereinigen
Damit Ihrem Google Cloud -Konto die in dieser Referenzarchitektur verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
Senke auf Organisationsebene löschen
- Verwenden Sie den folgenden Befehl, um die Logsenke auf Organisationsebene zu löschen:
gcloud logging sinks delete
ORGANIZATION_SINK_NAME --organization=ORGANIZATION_ID
Projekt löschen
Nachdem die Logsenke gelöscht wurde, können Sie mit dem Löschen von Ressourcen fortfahren, die zum Empfangen und Exportieren von Logs erstellt wurden. Am einfachsten ist es, das für die Referenzarchitektur erstellte Projekt zu löschen.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Nächste Schritte
- Eine vollständige Liste der Parameter der Dataflow-Vorlage "Pub/Sub to Splunk" finden Sie in der Dokumentation „Pub/Sub to Splunk Dataflow“.
- Die entsprechenden Terraform-Vorlagen zur Bereitstellung dieser Referenzarchitektur finden Sie im GitHub-Repository
terraform-splunk-log-export. Es enthält ein vordefiniertes Cloud Monitoring-Dashboard für das Monitoring Ihrer Splunk Dataflow-Pipeline. - Weitere Informationen zu benutzerdefinierten Messwerten und Logging von Splunk Dataflow finden Sie in diesem Blog: Neue Beobachtbarkeitsfeatures für Ihre Splunk Dataflow-Streamingpipelines.
- Weitere Referenzarchitekturen, Diagramme und Best Practices finden Sie im Cloud-Architekturcenter.