In diesem Dokument wird beschrieben, wie Sie die Leistung des TensorFlow-Systems messen, das Sie unter Skalierbares TensorFlow-Inferenzsystem bereitstellen erstellt haben. Außerdem erfahren Sie, wie Sie die Parameterabstimmung anwenden, um den Systemdurchsatz zu verbessern.
Die Bereitstellung basiert auf der Referenzarchitektur, die unter Skalierbares TensorFlow-Inferenzsystem beschrieben wird.
Diese Reihe richtet sich an Entwickler, die mit Google Kubernetes Engine und ML-Frameworks (ML) vertraut sind, einschließlich TensorFlow und TensorRT.
In diesem Dokument werden nicht die Leistungsdaten eines bestimmten Systems bereitgestellt. Stattdessen erhalten Sie allgemeine Hinweise zum Vorgang der Leistungsmessung. Die angezeigten Leistungsmesswerte, z. B. Anfragen pro Sekunde (RPS) insgesamt und Antwortzeiten (ms), variieren je nach Trainingsmodell, Softwareversion und Hardwarekonfiguration, die Sie verwenden.
Architektur
Eine Architekturübersicht über das TensorFlow-Inferenzsystem finden Sie unter Skalierbares TensorFlow-Inferenzsystem.
Lernziele
- Leistungsziel und die -Messwerte definieren
- Referenzleistung messen
- Grafik optimieren
- FP16-Umwandlung messen
- INT8-Quantisierung messen
- Anzahl der Instanzen anpassen
Kosten
Weitere Informationen zu den Kosten für die Bereitstellung finden Sie unter Kosten.
Nach Abschluss der in diesem Dokument beschriebenen Aufgaben können Sie weitere Kosten vermeiden, indem Sie die erstellten Ressourcen löschen. Weitere Informationen finden Sie unter Bereinigen.
Hinweise
Prüfen Sie, ob Sie die Schritte unter Skalierbares TensorFlow-Inferenzsystem bereitstellen bereits ausgeführt haben.
In diesem Dokument verwenden Sie die folgenden Tools:
- Ein SSH-Terminal der Worker-Instanz, die Sie unter Arbeitsumgebung erstellen vorbereitet haben.
- Das Grafana-Dashboard, das Sie unter Monitoring-Server mit Prometheus und Grafana bereitstellen vorbereitet haben.
- Die Locust-Konsole, die Sie unter Belastungstesttool bereitstellen vorbereitet haben
Verzeichnis festlegen
Gehen Sie in der Google Cloud Console zu Compute Engine > VM-Instanzen.
Sie sehen die Instanz
working-vm, die Sie erstellt haben.Klicken Sie zum Öffnen der Terminalkonsole der Instanz auf SSH.
Legen Sie im SSH-Terminal das aktuelle Verzeichnis auf das Unterverzeichnis
clientfest:cd $HOME/gke-tensorflow-inference-system-tutorial/clientIn diesem Dokument führen Sie alle Befehle von diesem Verzeichnis her aus.
Leistungsziel definieren
Beim Messen der Leistung von Inferenzsystemen müssen Sie das Leistungsziel und entsprechende Leistungsmesswerte gemäß dem Anwendungsfall des Systems definieren. Zu Demonstrationszwecken werden in diesem Dokument die folgenden Leistungsziele verwendet:
- Mindestens 95 % der Anfragen erhalten Antworten innerhalb von 100 ms.
- Der Gesamtdurchsatz, der durch Anfragen pro Sekunde (RPS) dargestellt wird, verbessert sich, ohne das vorherige Ziel zu beeinträchtigen.
In Erwägung dieser Ziele messen und verbessern Sie den Durchsatz der folgenden ResNet-50-Modelle mit verschiedenen Optimierungen. Wenn ein Client Inferenzanfragen sendet, gibt er das Modell anhand des Modellnamens in dieser Tabelle an.
| Modellname | Optimierung |
|---|---|
original |
Ursprüngliches Modell (keine Optimierung mit TF-TRT) |
tftrt_fp32 |
Grafikoptimierung (Batchgröße: 64, Instanzgruppen: 1) |
tftrt_fp16 |
Konvertierung in FP16 zusätzlich zur Grafikoptimierung (Batchgröße: 64, Instanzgruppen: 1) |
tftrt_int8 |
Quantisierung mit INT8 zusätzlich zur Grafikoptimierung (Batchgröße: 64, Instanzgruppen: 1) |
tftrt_int8_bs16_count4 |
Quantisierung mit INT8 zusätzlich zur Grafikoptimierung (Batchgröße: 16, Instanzgruppen: 4) |
Referenzleistung messen
Sie verwenden zuerst TF-TRT als Referenz, um die Leistung des ursprünglichen, nicht optimierten Modells zu messen. Vergleichen Sie die Leistung anderer Modelle mit dem Original, um die Leistungsverbesserung quantitativ zu bewerten. Bei der Bereitstellung von Locust wurde es bereits so konfiguriert, dass Anfragen für das ursprüngliche Modell gesendet werden.
Öffnen Sie die Locust-Konsole, die Sie unter Belastungstest-Tool bereitstellen vorbereitet haben
Bestätigen Sie, dass die Anzahl der Clients (als Slaves bezeichnet) zehn ist.
Wenn die Zahl unter zehn liegt, werden die Clients noch gestartet. Warten Sie in diesem Fall einige Minuten, bis sie zehn wird.
Leistung messen:
- Geben Sie im Feld Anzahl der zu simulierenden Nutzer den Wert
3000ein. - Geben Sie im Feld Hatch rate den Wert
5ein. - Klicken Sie auf Swarm starten, um die Anzahl der simulierten Nutzer um 5 pro Sekunde zu erhöhen, bis sie 3.000 erreicht.
- Geben Sie im Feld Anzahl der zu simulierenden Nutzer den Wert
Klicken Sie auf Diagramme.
Die Grafiken zeigen die Leistungsergebnisse. Beachten Sie, dass der Wert für die Anfragen pro Sekunde insgesamt linear erhöht wird, während der Wert Antwortzeiten (ms) entsprechend ansteigt.
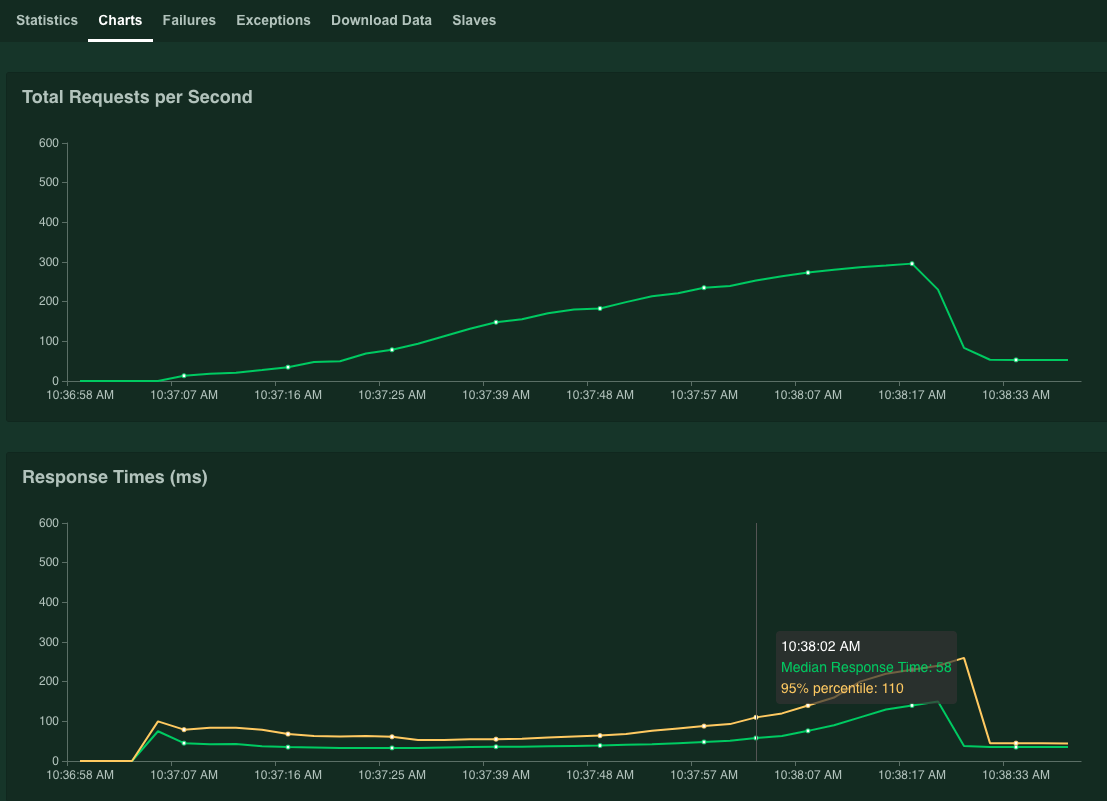
Wenn der Wert 95% Perzentil der Antwortzeiten 100 ms überschreitet, klicken Sie auf Stop, um die Simulation zu beenden.
Wenn Sie den Zeiger auf das Diagramm bewegen, können Sie die Anzahl der Anfragen pro Sekunde prüfen, in Korrespondenz zu der Zeit, als der Wert von 95 % Perzentil der Antwortzeiten 100 ms überschritt.
Im folgenden Screenshot beträgt die Anzahl der Anfragen pro Sekunde beispielsweise 253,1.
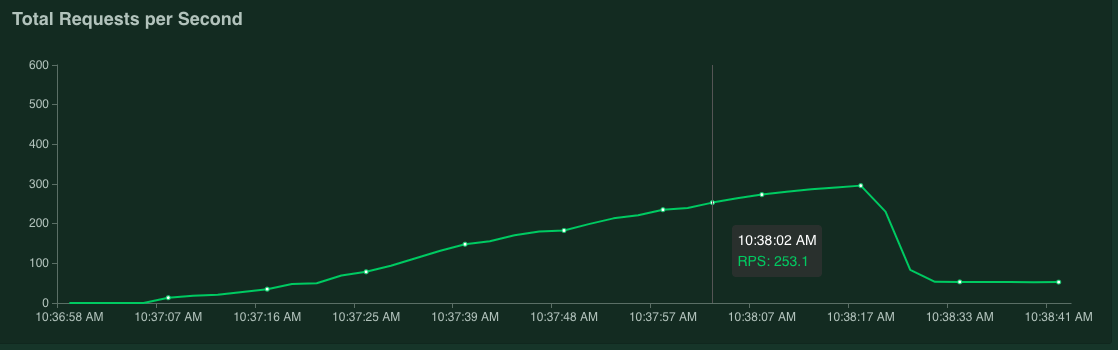
Wir empfehlen, diese Messung mehrmals zu wiederholen und dabei einen Durchschnittswert zu ermitteln, der Schwankungen berücksichtigt.
Starten Sie im SSH-Terminal Locust neu:
kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustWiederholen Sie diesen Vorgang, um die Messung zu wiederholen.
Grafiken optimieren
In diesem Abschnitt messen Sie die Leistung des Modells tftrt_fp32, das mit TF-TRT für die Grafikoptimierung optimiert wird. Dies ist eine gängige Optimierung, die mit den meisten NVIDIA-GPU-Karten kompatibel ist.
Starten Sie im SSH-Terminal das Belastungstest-Tool neu:
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_fp32 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustDie
configmap-Ressource gibt das Modell alstftrt_fp32an.Starten Sie den Triton-Server neu:
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1Warten Sie einige Minuten, bis die Serverprozesse bereit sind.
Prüfen Sie den Serverstatus:
kubectl get podsDie Ausgabe sieht etwa so aus, wobei in der Spalte
READYder Serverstatus angezeigt wird:NAME READY STATUS RESTARTS AGE inference-server-74b85c8c84-r5xhm 1/1 Running 0 46sDer Wert
1/1in der SpalteREADYgibt an, dass der Server bereit ist.Leistung messen:
- Geben Sie im Feld Anzahl der zu simulierenden Nutzer den Wert
3000ein. - Geben Sie im Feld Hatch rate den Wert
5ein. - Klicken Sie auf Swarm starten, um die Anzahl der simulierten Nutzer um 5 pro Sekunde zu erhöhen, bis sie 3.000 erreicht.
Die Grafiken zeigen die Leistungssteigerung der TF-TRT-Grafikoptimierung.
Ihr Diagramm könnte beispielsweise zeigen, dass die Anzahl der Anfragen pro Sekunde jetzt 381 mit einer mittleren Antwortzeit von 59 ms beträgt.
- Geben Sie im Feld Anzahl der zu simulierenden Nutzer den Wert
In FP16 konvertieren
In diesem Abschnitt messen Sie die Leistung des Modells tftrt_fp16, das mit TF-TRT für die Grafikoptimierung und FP16-Konvertierung optimiert ist. Diese Optimierung ist für NVIDIA T4 verfügbar.
Starten Sie im SSH-Terminal das Belastungstest-Tool neu:
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_fp16 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustStarten Sie den Triton-Server neu:
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1Warten Sie einige Minuten, bis die Serverprozesse bereit sind.
Leistung messen:
- Geben Sie im Feld Anzahl der zu simulierenden Nutzer den Wert
3000ein. - Geben Sie im Feld Hatch rate den Wert
5ein. - Klicken Sie auf Swarm starten, um die Anzahl der simulierten Nutzer um 5 pro Sekunde zu erhöhen, bis sie 3.000 erreicht.
Die Diagramme zeigen neben der Leistungsverbesserung der FP16-Konvertierung auch die TF-TRT-Grafikoptimierung.
Ein Diagramm könnte beispielsweise zeigen, dass die Anzahl der Anfragen pro Sekunde 1072,5 beträgt, während die mittlere Antwortzeit 63 ms beträgt.
- Geben Sie im Feld Anzahl der zu simulierenden Nutzer den Wert
Mit INT8 quantisieren
In diesem Abschnitt messen Sie die Leistung des Modells tftrt_int8, das mit TF-TRT für die Diagrammoptimierung und INT8-Quantisierung optimiert ist. Diese Optimierung ist für NVIDIA T4 verfügbar.
Starten Sie im SSH-Terminal das Belastungstest-Tool neu.
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_int8 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustStarten Sie den Triton-Server neu:
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1Warten Sie einige Minuten, bis die Serverprozesse bereit sind.
Leistung messen:
- Geben Sie im Feld Anzahl der zu simulierenden Nutzer den Wert
3000ein. - Geben Sie im Feld Hatch rate den Wert
5ein. - Klicken Sie auf Swarm starten, um die Anzahl der simulierten Nutzer um 5 pro Sekunde zu erhöhen, bis sie 3.000 erreicht.
Die Grafiken zeigen die Leistungsergebnisse.
Ein Diagramm könnte beispielsweise zeigen, dass die Anzahl der Anfragen pro Sekunde 1085,4 beträgt, während die mittlere Antwortzeit 32 ms beträgt.
In diesem Beispiel ist das Ergebnis im Vergleich zur FP16-Conversion keine signifikante Leistungssteigerung. Theoretisch kann die NVIDIA T4-GPU schneller INT8-Quantisierungsmodelle verarbeiten als FP16-Konvertierungsmodelle. In diesem Fall kann es einen anderen Engpass als die GPU-Leistung geben. Sie können dies anhand der GPU-Auslastungsdaten im Grafana-Dashboard prüfen. Wenn die Auslastung beispielsweise unter 40 % liegt, kann das Modell die GPU-Leistung nicht vollständig nutzen.
Wie im nächsten Abschnitt gezeigt, können Sie diesen Engpass möglicherweise beheben, indem Sie die Anzahl der Instanzgruppen erhöhen. Sie können beispielsweise die Anzahl der Instanzgruppen von 1 auf 4 erhöhen und die Batchgröße von 64 auf 16 verringern. Bei diesem Ansatz wird die Gesamtzahl der Anfragen, die auf einer einzelnen GPU verarbeitet werden, bei 64 gehalten.
- Geben Sie im Feld Anzahl der zu simulierenden Nutzer den Wert
Anzahl der Instanzen anpassen
In diesem Abschnitt messen Sie die Leistung des Modells tftrt_int8_bs16_count4. Dieses Modell hat die gleiche Struktur wie tftrt_int8, Sie ändern jedoch die Batchgröße und die Anzahl der Instanzgruppen wie unter Mit INT8 quantisieren beschrieben.
Starten Sie im SSH-Terminal Locust neu:
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_int8_bs16_count4 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locust kubectl scale deployment/locust-slave --replicas=20 -n locustIn diesem Befehl verwenden Sie die Ressource
configmap, um das Modell alstftrt_int8_bs16_count4anzugeben. Sie erhöhen außerdem die Anzahl der Locust-Client-Pods, um genügend Arbeitslasten zu generieren, um die Leistungsbeschränkung des Modells zu messen.Starten Sie den Triton-Server neu:
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1Warten Sie einige Minuten, bis die Serverprozesse bereit sind.
Leistung messen:
- Geben Sie im Feld Anzahl der zu simulierenden Nutzer den Wert
3000ein. - Geben Sie im Feld Hatch rate den Wert
15ein. Bei diesem Modell kann es lange dauern, bis die Leistungsgrenze erreicht ist, wenn die Erzeugungsrate auf5gesetzt ist. - Klicken Sie auf Swarm starten, um die Anzahl der simulierten Nutzer um 5 pro Sekunde zu erhöhen, bis sie 3.000 erreicht.
Die Grafiken zeigen die Leistungsergebnisse.
Ein Diagramm könnte beispielsweise zeigen, dass die Anzahl der Anfragen pro Sekunde 2236,6 beträgt, während die mittlere Antwortzeit 38 ms beträgt.
Wenn Sie die Anzahl der Instanzen anpassen, können Sie die Zahl der Anfragen pro Sekunde fast verdoppeln. Die GPU-Auslastung hat sich im Grafana-Dashboard erhöht (z. B. könnte die Auslastung 75 % erreichen).
- Geben Sie im Feld Anzahl der zu simulierenden Nutzer den Wert
Leistung und mehrere Knoten
Bei der Skalierung mit mehreren Knoten messen Sie die Leistung eines einzelnen Pods. Da die Inferenzprozesse unabhängig voneinander auf verschiedenen Pods nach dem Prinzip shared-nothing ausgeführt werden, können Sie davon ausgehen, dass der Gesamtdurchsatz linear mit der Anzahl der Pods skaliert wird. Diese Annahme gilt, solange keine Engpässe wie die Netzwerkbandbreite zwischen Clients und Inferenzservern vorliegen.
Sie müssen jedoch verstehen, wie Inferenzanfragen auf mehrere Inferenzserver verteilt werden. Triton verwendet das gRPC-Protokoll, um eine TCP-Verbindung zwischen einem Client und einem Server herzustellen. Da Triton die hergestellte Verbindung zum Senden mehrerer Inferenzanfragen wiederverwendet, werden Anfragen von einem einzelnen Client immer an denselben Server gesendet. Sie müssen mehrere Clients verwenden, um Anfragen für mehrere Server zu verteilen.
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Reihe verwendeten Ressourcen nicht in Rechnung gestellt werden, können Sie das Projekt löschen:
Projekt löschen
- Wechseln Sie in der Google Cloud Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie dann auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Shut down (Beenden), um das Projekt zu löschen.
Nächste Schritte
- Informationen zum Konfigurieren von Rechenressourcen für Vorhersagen
- Mehr über Google Kubernetes Engine (GKE) erfahren.
- Mehr über Cloud Load Balancing erfahren.
- Weitere Referenzarchitekturen, Diagramme und Best Practices finden Sie im Cloud-Architekturcenter.