Dieser Artikel ist der zweite Teil einer vierteiligen Reihe, in der erläutert wird, wie Sie in Google Cloud den Customer Lifetime Value (CLV) mithilfe der AI Platform (AI Platform) vorhersagen können.
Die Artikel dieser Reihe umfassen die folgenden Punkte:
- Teil 1: Einführung. Einführung in CLV und zwei Modellierungstechniken zur Vorhersage des CLV.
- Teil 2: Modell trainieren (dieser Artikel): Es wird erläutert, wie die Daten vorbereitet und die Modelle trainiert werden.
- Teil 3: Für die Produktion bereitstellen: Es wird beschrieben, wie die in Teil 2 erläuterten Modelle in einem Produktionssystem bereitgestellt werden.
- Teil 4: AutoML-Tabellen verwenden. Es wird gezeigt, wie Modelle mit AutoML-Tabellen erstellt und bereitgestellt werden.
Der Code zur Implementierung dieses Systems befindet sich in einem GitHub-Repository. In dieser Reihe wird erklärt, wozu der Code dient und wie er verwendet wird.
Einführung
Dieser Artikel folgt auf Teil 1, in dem Sie zwei verschiedene Modelle zur Vorhersage des Customer Lifetime Value (CLV) kennen gelernt haben:
- Probabilistische Modelle
- DNN-Modelle (Deep Neural Network, neuronales Deep-Learning-Netzwerk), eine Art Modell für maschinelles Lernen
Wie in Teil 1 erwähnt, werden in dieser Reihe die Modelle zur Vorhersage von CLV verglichen. In diesem Teil der Reihe wird beschrieben, wie Sie die Daten vorbereiten und beide Modelltypen erstellen und zur Vorhersage von CLV trainieren. Außerdem erhalten Sie einige vergleichende Informationen.
Code installieren
Zur Durchführung des in diesem Artikel erläuterten Vorgangs müssen Sie den Beispielcode von GitHub installieren.
Öffnen Sie, wenn das gcloud CLI installiert ist, auf Ihrem Computer ein Terminalfenster für die Ausführung der Befehle. Wenn Sie das gcloud-CLI nicht installiert haben, öffnen Sie eine Instanz von Cloud Shell.
Klonen Sie das Beispielcode-Repository:
git clone https://github.com/GoogleCloudPlatform/tensorflow-lifetime-value
Folgen Sie der Anleitung im Abschnitt Installieren der README-Datei, um die Umgebung einzurichten.
Datenvorbereitung
In diesem Abschnitt wird beschrieben, wie Sie die Daten abrufen und bereinigen.
Quell-Dataset abrufen und bereinigen
Bevor Sie den CLV berechnen können, müssen die Quelldaten mindestens Folgendes enthalten:
- Eine Kundennummer zur Unterscheidung einzelner Kunden
- Einen Kaufbetrag pro Kunde, der zeigt, wie viel ein Kunde zu einer bestimmten Zeit ausgegeben hat
- Ein Datum für jeden Einkauf
In diesem Artikel wird erläutert, wie Modelle mithilfe historischer Verkaufsdaten aus dem öffentlich verfügbaren Online Retail Data Set im UCI Machine Learning Repository trainiert werden.[1]
Im ersten Schritt wird das Dataset als CSV-Datei in Cloud Storage kopiert.
Anschließend erstellen Sie mit einem der Ladetools für BigQuery eine Tabelle mit dem Namen data_source. Dieser beliebige Name wird vom Code im GitHub-Repository verwendet. Das Dataset ist in einem öffentlichen Bucket verfügbar, der dieser Reihe zugeordnet ist, und wurde bereits in das CSV-Format konvertiert.
- Führen Sie auf Ihrem Computer oder in Cloud Shell die Befehle aus, die im Abschnitt Setup der README-Datei im GitHub-Repository dokumentiert sind.
Das Beispiel-Dataset enthält die Felder, die in der folgenden Tabelle aufgeführt sind. Für den in diesem Artikel beschriebenen Ansatz werden nur die Felder verwendet, in denen die Spalte Verwendet auf Ja festgelegt ist. Einige Felder werden nicht direkt verwendet, helfen jedoch beim Erstellen neuer Felder. So wird beispielsweise mit UnitPrice und Quantity das Feld order_value erstellt.
| Verwendet | Feld | Typ | Beschreibung |
|---|---|---|---|
| Nein | InvoiceNo |
STRING |
Nominal. Eine 6-stellige Ganzzahl, die jeder Transaktion einmalig zugewiesen ist.
Beginnt dieser Code mit dem Buchstaben c, handelt es sich um eine Stornierung. |
| Nein | StockCode |
STRING |
Produktcode (Artikelcode). Nominal. Eine 5-stellige Ganzzahl, die jedem einzelnen Produkt einmalig zugeordnet ist. |
| Nein | Description |
STRING |
Produktname (Artikelname). Nominal. |
| Ja | Quantity |
INTEGER |
Die Mengen jedes Produkts (Artikels) pro Transaktion. Numerisch. |
| Ja | InvoiceDate |
STRING |
Datum und Uhrzeit der Rechnung im Format MM/TT/JJ hh:mm. Datum und Uhrzeit der Generierung der einzelnen Transaktionen. |
| Ja | UnitPrice |
FLOAT |
Preis pro Einheit. Numerisch. Der Produktpreis pro Einheit in Pfund Sterling. |
| Ja | CustomerID |
STRING |
Kundennummer. Nominal. Eine 5-stellige Ganzzahl, die jedem Kunden einmalig zugewiesen ist. |
| Nein | Country |
STRING |
Name des Landes. Nominal. Der Name des Landes, in dem die einzelnen Kunden ihren Wohnsitz haben. |
Daten bereinigen
Unabhängig vom Modell, das Sie verwenden, müssen eine Reihe von Vorbereitungs- und Bereinigungsschritten durchgeführt werden, die für alle Modelle gleich sind. Die folgenden Vorgänge sind erforderlich, um einen Satz funktionsfähiger Felder und Datasets abzurufen:
- Aufträge nach Tag und nicht nach
InvoiceNogruppieren, denn in dieser Lösung ist der Tag die von den probabilistischen Modellen verwendete Mindestzeiteinheit. - Nur die Felder behalten, die für probabilistische Modelle sinnvoll sind.
- Nur Datasets mit positiven Bestellmengen und Geldwerten, z. B. Einkäufe, behalten.
- Nur Datasets mit negativen Bestellmengen, z. B. Retouren, behalten.
- Nur Datasets mit einer Kundennummer behalten.
- Nur Kunden behalten, die in den letzten 90 Tagen etwas gekauft haben.
- Nur Kunden behalten, die in dem für die Erstellung der Merkmale genutzten Zeitraum mindestens zweimal etwas gekauft haben.
Sie können alle diese Vorgänge mit der folgenden BigQuery-Abfrage ausführen. Wie bei den vorherigen Befehlen wird dieser Code dort ausgeführt, wo Sie das GitHub-Repository geklont haben. Da die Daten alt sind, gilt hier der 12. Dezember 2011 als aktuelles Datum.
Diese Abfrage führt zwei Aufgaben aus. Erstens verkleinert sie große Arbeits-Datasets. Das Arbeits-Dataset für diese Lösung ist relativ klein. Die Abfrage kann jedoch ein extrem großes Dataset in wenigen Sekunden um zwei Größenordnungen verkleinern.
Zweitens erstellt die Abfrage ein Basis-Dataset, das so aussieht:
customer_id
|
order_date
|
order_value
|
order_qty_articles
|
|---|---|---|---|
| 16915 | 2011-08-04 | 173,7 | 6 |
| 15349 | 2011-07-04 | 107,7 | 77 |
| 14794 | 2011-03-30 | -33,9 | -2 |
Das bereinigte Dataset enthält auch das Feld order_qty_articles. Dieses Feld ist nur für das neuronale Deep-Learning-Netzwerk (DNN) enthalten, das im nächsten Abschnitt beschrieben wird.
Trainings- und Zielintervalle definieren
Wählen Sie zur Vorbereitung des Trainings der Modelle ein Grenzdatum. Dieses Datum teilt die Aufträge in zwei Partitionen auf:
- Aufträge vor dem Grenzdatum werden zum Trainieren des Modells verwendet.
- Aufträge nach dem Grenzdatum werden zur Berechnung des Zielwerts verwendet.

Die Lifetimes-Bibliothek enthält Methoden zur Vorverarbeitung der Daten. Die für den CLV verwendeten Datasets können jedoch recht groß sein. Damit ist es unpraktisch, die Vorverarbeitung der Daten auf einer einzelnen Maschine auszuführen. Der in diesem Artikel beschriebene Ansatz verwendet direkt in BigQuery ausgeführte Abfragen, um Aufträge in zwei Sätze aufzuteilen. ML- und probabilistische Modelle verwenden die gleichen Abfragen, um sicherzustellen, dass beide Modelle mit den gleichen Daten arbeiten.
Das optimale Grenzdatum bei ML-Modellen und das bei probabilistischen Modellen kann unterschiedlich sein. Sie können diesen Datumswert direkt in der SQL-Anweisung aktualisieren. Stellen Sie sich den optimalen Grenzwert als Hyperparameter vor. Den am besten geeigneten Wert finden Sie, indem Sie die Daten untersuchen und einige Testtrainings machen.
Das Grenzdatum wird in der WHERE-Klausel der SQL-Abfrage verwendet, die, wie im folgenden Beispiel zu sehen, Trainingsdaten aus der gelöschten Datentabelle auswählt.
Daten aggregieren
Nachdem die Daten in Trainings- und Zielintervalle aufgeteilt wurden, werden sie zusammengefasst, um tatsächliche Merkmale und Ziele für jeden Kunden zu erstellen. Bei probabilistischen Modellen ist die Zusammenfassung auf die Felder Recency (Aktualität), Frequency (Häufigkeit) und Monetary (Geldwert) (RFM) beschränkt. DNN-Modelle verwenden auch RFM-Merkmale, können jedoch zusätzliche Merkmale verwenden, um bessere Vorhersagen zu treffen.
Die folgende Abfrage zeigt, wie Merkmale gleichzeitig für DNN- und probabilistische Modelle erstellt werden:
In der folgenden Tabelle sind die Merkmale aufgeführt, die von der Abfrage erstellt werden.
| Featurename | Beschreibung | Probabilistisch | DNN |
|---|---|---|---|
monetary_dnn
|
Summe der Geldwerte aller Bestellungen pro Kunde während des Merkmalzeitraums. | x | |
monetary_btyd
|
Durchschnitt der Geldwerte aller Aufträge für jeden Kunden während des Merkmalzeitraums. Probabilistische Modelle gehen davon aus, dass der Wert der ersten Bestellung 0 ist. Dies wird durch die Abfrage durchgesetzt. | x | |
recency
|
Zeit zwischen der ersten und der letzten Bestellung, die ein Kunde während des Merkmalzeitraums aufgegeben hat. | x | |
frequency_dnn
|
Anzahl der Bestellungen, die ein Kunde während des Merkmalzeitraums aufgegeben hat. | x | |
frequency_btyd
|
Anzahl der Bestellungen, die ein Kunde während des Merkmalzeitraums aufgegeben hat, abzüglich der ersten. | x | |
T
|
Zeit zwischen der ersten Bestellung eines Kunden und dem Ende des Merkmalzeitraums. | x | x |
time_between
|
Durchschnittlicher Zeitraum zwischen den Bestellungen eines Kunden während des Merkmalzeitraums. | x | |
avg_basket_value
|
Durchschnittlicher Geldwert des Warenkorbs des Kunden während des Merkmalzeitraums. | x | |
avg_basket_size
|
Anzahl der Artikel, die sich während des Merkmalzeitraums durchschnittlich im Warenkorb des Kunden befinden. | x | |
cnt_returns
|
Anzahl der Bestellungen, die der Kunde während des Merkmalzeitraums zurückgegeben hat. | x | |
has_returned
|
Gibt an, ob der Kunde während des Merkmalzeitraums mindestens eine Bestellung zurückgesendet hat. | x | |
frequency_btyd_clipped
|
Wie frequency_btyd, aber durch Cap-Ausreißer begrenzt. |
x | |
monetary_btyd_clipped
|
Wie monetary_btyd, aber durch Cap-Ausreißer begrenzt. |
x | |
target_monetary_clipped
|
Wie target_monetary, aber durch Cap-Ausreißer begrenzt. |
x | |
target_monetary
|
Gesamtbetrag, der von einem Kunden ausgegeben wird, einschließlich Trainings- und Zielzeiträume. | x |
Die Auswahl dieser Spalten erfolgt im Code. Bei probabilistischen Modellen erfolgt die Auswahl mit einem Pandas DataFrame:
Bei DNN-Modellen werden TensorFlow-Merkmale in der Datei context.py definiert. Für diese Modelle werden folgende Merkmale ignoriert:
customer_id: Hierbei handelt es sich um einen eindeutigen Wert, der als Merkmal nutzlos ist.target_monetary: Dies ist das Ziel, das vom Modell vorhergesagt werden muss und daher nicht als Eingabe verwendet wird.
Trainings-, Evaluierungs- und Test-Datasets für DNN erstellen
Dieser Abschnitt gilt nur für DNN-Modelle. Für das Training eines ML-Modells sollten Sie drei nicht überlappende Datasets verwenden:
Das Dataset training (70 - 80 %) dient zum Lernen von Gewichtungen, um eine Verlustfunktion zu reduzieren. Das Training wird so lange fortgesetzt, bis die Verlustfunktion nicht mehr abnimmt.
Das Dataset evaluation (10–15 %) wird in der Trainingsphase verwendet, um eine Überanpassung zu verhindern. Eine Überanpassung tritt auf, wenn das Modell mit den Trainingsdaten gute Ergebnisse erzielt, aber nicht gut verallgemeinerbar ist.
Das Dataset test (10 - 15 %) sollte nur einmal verwendet werden, nachdem das Training und die Evaluation abgeschlossen sind, um eine endgültige Messung der Modellleistung durchzuführen. Dieses Dataset hat das Modell während des Trainingsprozesses noch nie gesehen. Es liefert daher ein statistisch gültiges Maß für die Modellgenauigkeit.
Die folgende Abfrage erstellt ein Trainings-Dataset mit etwa 70 % der Daten. Die Abfrage trennt die Daten mit der folgenden Methode:
- Es wird ein Hash der Kundennummer berechnet, der eine Ganzzahl ergibt.
- Es wird eine Modulo-Operation verwendet, um die Hashwerte auszuwählen, die unter einem bestimmten Grenzwert liegen.
Dasselbe Konzept wird für die Evaluations- und Testsets verwendet, bei denen Daten, die über dem Grenzwert liegen, beibehalten werden.
Training
Wie im vorherigen Abschnitt beschrieben, können Sie verschiedene Modelle verwenden, um den CLV vorherzusagen. Mit dem in diesem Artikel verwendeten Code können Sie entscheiden, welches Modell verwendet werden soll. Sie wählen das Modell mithilfe des Parameters model_type aus, den Sie an das folgende Training-Shell-Skript übergeben. Der Code kümmert sich um den Rest.
Das erste Ziel des Trainings besteht darin, dass beide Modelle eine naive Benchmark übertreffen, die wir weiter unten definieren. Wenn beide Modelltypen die Benchmark übertreffen können (und das sollten sie), können Sie vergleichen, wie sich die einzelnen Typen gegenüber dem anderen entwickeln.
Die Modelle mit Benchmarking vergleichen
Für diese Reihe wird eine naive Benchmark mit den folgenden Parametern definiert:
- Durchschnittlicher Warenkorbwert: Dieser Wert wird für alle Bestellungen berechnet, die vor dem Grenzdatum liegen.
- Anzahl der Bestellungen: Dieser Wert wird für das Trainingsintervall aller Bestellungen berechnet, die vor dem Grenzdatum eingegangen sind.
- Multiplikator: Dieser Wert wird auf Grundlage des Verhältnisses zwischen der Anzahl der Tage vor dem Grenzdatum und der Anzahl der Tage zwischen dem Grenzdatum und dem aktuellen Datum berechnet.
Die Benchmark geht naiv davon aus, dass die von einem Kunden während des Trainingsintervalls festgelegte Kaufrate über das Zielintervall konstant bleibt. Wenn ein Kunde also sechsmal in 40 Tagen gekauft hat, wird davon ausgegangen, dass er in 60 Tagen neunmal kaufen würde (60/40 * 6 = 9). Der Multiplikator, die Bestellanzahl und der durchschnittliche Warenkorbwert für jeden Kunden miteinander multipliziert ergeben einen naiven vorhergesagten Zielwert für diesen Kunden.
Der Benchmark-Fehler ist der mittlere quadratische Fehler (Root Mean Squared Error, RMSE): der Durchschnitt der absoluten Differenz zwischen dem vorhergesagten Zielwert und dem tatsächlichen Zielwert aller Kunden. Der RMSE wird anhand der folgenden Abfrage in BigQuery berechnet:
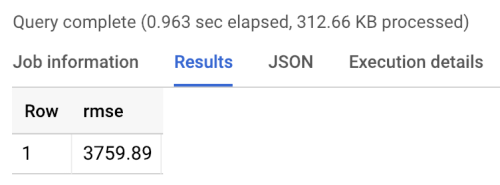
Das Ergebnis des Benchmark-Tests ist ein RMSE von 3760, wie unten gezeigt. Modelle sollten diesen Wert übertreffen.
Probabilistische Modelle
Wie in Teil 1 erwähnt, verwendet diese Reihe eine Python-Bibliothek namens Lifetimes, die verschiedene Modelle unterstützt, unter anderem Pareto/Negativ-Binomialverteilung (NBD) und beta-geometrische BG/NBD-Modelle. Der folgende Beispielcode zeigt, wie die Lifetimes-Bibliothek verwendet wird, um Vorhersagen zum Lifetime Value mit probabilistischen Modellen durchzuführen.
Um CLV-Ergebnisse mithilfe des probabilistischen Modells in Ihrer lokalen Umgebung zu generieren, können Sie das folgende mltrain.sh-Skript ausführen. Sie geben Parameter für das Start- und Enddatum des Trainingsteils und für das Ende des Vorhersagezeitraums an.
./mltrain.sh local data --model_type paretonbd_model --threshold_date [YOUR_THRESHOLD_DATE] --predict_end [YOUR_END_DATE]
DNN-Modelle
Der Beispielcode enthält Implementierungen von DNN in TensorFlow, bei denen die vorgefertigte Estimator-Klasse DNNRegressor verwendet wird, sowie ein benutzerdefiniertes Estimator-Modell. Der DNNRegressor und der benutzerdefinierte Estimator verwenden auf jeder Ebene dieselbe Anzahl von Ebenen und Neuronen. Diese Werte sind Hyperparameter, die angepasst werden müssen. In der folgenden task.py-Datei finden Sie eine Liste einiger Hyperparameter, deren Werte manuell getestet wurden und gute Ergebnisse lieferten.
In AI Platform können Sie die Funktion zur Hyperparameter-Abstimmung verwenden. Sie testet eine Reihe von Parametern, die in einer YAML-Datei definiert werden. Die AI Platform verwendet die Bayes'sche Optimierung, um den Bereich der Hyperparameter zu durchsuchen.
Ergebnisse des Modellvergleichs
Die folgende Tabelle zeigt die RMSE-Werte für jedes Modell, nachdem es anhand des Beispiel-Datasets trainiert wurde. Alle Modelle werden mit RFM-Daten trainiert. Aufgrund der zufälligen Parameterinitialisierung variieren die RMSE-Werte leicht zwischen den Ausführungen. Das DNN-Modell verwendet zusätzliche Merkmale, wie den durchschnittlichen Warenkorbwert und die Anzahl der Retouren.
| Modell | RMSE |
|---|---|
| DNN | 947,9 |
| BG/NBD | 1557 |
| Pareto/NBD | 1558 |
Die Ergebnisse zeigen, dass das DNN-Modell in diesem Dataset bei der Vorhersage des Geldwerts bessere Ergebnisse liefert als die probabilistischen Modelle. Die relativ geringe Größe des UCI-Datasets begrenzt jedoch die statistische Gültigkeit dieser Ergebnisse. Testen Sie, welche der Techniken jeweils die besten Ergebnisse für Ihr Dataset liefern. Alle Modelle wurden anhand derselben Originaldaten (unter anderem Kundennummer, Bestelldatum und Bestellwert) für die aus diesen Daten entnommenen RFM-Werte trainiert. Die DNN-Trainingsdaten enthielten einige zusätzliche Merkmale, wie die durchschnittliche Korbgröße und die Anzahl der Retouren.
Das DNN-Modell gibt nur den gesamten Geldwert des Kunden aus. Wenn Sie Häufigkeit oder Abwanderung vorhersagen möchten, müssen Sie einige zusätzliche Aufgaben ausführen:
- Bereiten Sie die Daten unterschiedlich vor, sodass das Ziel und möglicherweise das Grenzdatum variieren.
- Trainieren Sie ein Regressormodell noch einmal so, dass das gewünschte Ziel vorhergesagt wird.
- Stimmen Sie die Hyperparameter ab.
Ziel war es, einen Vergleich zwischen den zwei Modellarten mit den gleichen Eingabefunktionen durchzuführen. Ein Vorteil bei DNN-Modellen besteht darin, dass Sie bessere Ergebnisse erzielen können, wenn Sie mehr Merkmale hinzufügen als in diesem Beispiel verwendet werden. Mit DNN-Modellen können Sie Daten aus Quellen wie Clickstream-Ereignissen, Benutzerprofilen oder Produktfunktionen nutzen.
Quellen
Dua, D. und Karra Taniskidou, E. (2017). UCI Machine Learning Repository http://archive.ics.uci.edu/ml. Irvine, CA: University of California, School of Information and Computer Science.
Nächste Schritte
- In Teil 3: Für die Produktion bereitstellen dieser Reihe lesen, wie Sie die vorgestellten Modelle bereitstellen.
- Informationen zu anderen vorausschauenden Prognoselösungen
- Referenzarchitekturen, Diagramme, Anleitungen und Best Practices zu Google Cloud kennenlernen. Weitere Informationen zu Cloud Architecture Center