Dieser Artikel ist der vierte Teil einer vierteiligen Reihe, in der erläutert wird, wie Sie den Customer Lifetime Value (CLV) mithilfe von AI Platform in Google Cloudvorhersagen können. In diesem Artikel erfahren Sie, wie Sie die Vorhersagen mit AutoML Tables durchführen können.
Die Artikel dieser Reihe umfassen die folgenden Punkte:
- Teil 1: Einführung. Einführung in CLV und zwei Modellierungstechniken zur Vorhersage des CLV.
- Teil 2: Modell trainieren: Es wird erläutert, wie die Daten vorbereitet und die Modelle trainiert werden.
- Teil 3: Für die Produktion bereitstellen: Es wird beschrieben, wie die in Teil 2 erläuterten Modelle in einem Produktionssystem bereitgestellt werden.
- Teil 4: AutoML Tables verwenden (dieser Artikel). Erläutert, wie Modelle mit AutoML-Tabellen erstellt und bereitgestellt werden.
Der in diesem Artikel beschriebene Prozess beruht auf denselben Datenverarbeitungsschritten in BigQuery, die in Teil 2 der Reihe beschrieben wurden. In diesem Artikel erfahren Sie, wie Sie BigQuery-Datasets in AutoML Tables hochladen und ein Modell erstellen. Außerdem geht es darum, wie Sie das AutoML-Modell in das Produktionssystem einbinden, das in Teil 3 beschrieben wird.
Der Code zur Implementierung dieses Systems befindet sich im selben GitHub-Repository wie der der ursprünglichen Reihe. In diesem Artikel wird beschrieben, wie dieser Code für AutoML Tables verwendet wird.
Vorteile von AutoML Tables
In den vorherigen Teilen der Reihe wurde erklärt, wie Sie CLV mithilfe eines statistischen Modells und eines in TensorFlow implementierten DNN-Modells vorhersagen können. AutoML Tables bietet mehrere Vorteile gegenüber den beiden anderen Methoden:
- Zur Erstellung des Modells ist kein Coding erforderlich. Es gibt eine Konsolen-UI, über die Sie Datasets und Modelle erstellen, trainieren, verwalten und bereitstellen können.
- Das Hinzufügen oder Ändern von Features ist einfach und kann direkt über die Benutzeroberfläche der Konsole erfolgen.
- Der Trainingsprozess ist automatisiert, einschließlich der Abstimmung der Hyperparameter.
- AutoML Tables sucht nach der besten Architektur für Ihr Dataset, damit Sie sich nicht mehr zwischen den vielen verfügbaren Optionen entscheiden müssen.
- AutoML Tables bietet eine detaillierte Analyse der Leistung eines trainierten Modells, einschließlich der Wichtigkeit von Features.
Infolgedessen kann das Entwickeln und Trainieren eines vollständig optimierten Modells mit AutoML Tables weniger Zeit und Kosten in Anspruch nehmen.
Für die Produktionsbereitstellung einer AutoML Tables-Lösung müssen Sie die Python Client API verwenden, um Modelle zu erstellen und bereitzustellen sowie Vorhersagen auszuführen. In diesem Artikel erfahren Sie, wie Sie mithilfe dieser API AutoML Tables-Modelle erstellen und trainieren. Eine Anleitung zur Durchführung dieser Schritte mithilfe der AutoML Tables-Konsole finden Sie in der AutoML Tables-Dokumentation.
Code installieren
Wenn Sie den Code für die ursprüngliche Reihe nicht installiert haben, befolgen Sie die in Teil 2 der ursprünglichen Reihe beschriebenen Schritte, um den Code zu installieren. In der README-Datei im GitHub-Repository werden alle Schritte beschrieben, die zum Vorbereiten der Umgebung, Installieren des Codes und Einrichten von AutoML Tables in Ihrem Projekt erforderlich sind.
Wenn Sie den Code bereits installiert haben, müssen Sie diese zusätzlichen Schritte ausführen, um die Installation für diesen Artikel abzuschließen:
- Aktivieren Sie die AutoML Tables API in Ihrem Projekt.
- Aktivieren Sie die zuvor installierte Miniconda-Umgebung.
- Installieren Sie die Python-Clientbibliothek, wie in der AutoML Tables-Dokumentation beschrieben.
- Erstellen Sie eine API-Schlüsseldatei und laden Sie sie herunter. Speichern Sie die Datei anschließend unter einem bekannten Speicherort, um sie später mit der Clientbibliothek zu verwenden.
Code ausführen
In vielen der Schritte in diesem Artikel werden Python-Befehle ausgeführt. Nachdem Sie Ihre Umgebung vorbereitet und den Code installiert haben, stehen Ihnen folgende Optionen zum Ausführen des Codes zur Verfügung:
Führen Sie den Code in einem Jupyter-Notebook aus. Führen Sie im Terminalfenster in Ihrer aktivierten Miniconda-Umgebung den folgenden Befehl aus:
$ (clv) jupyter notebook
Der Code für jeden der Schritte in diesem Artikel befindet sich im Code-Repository
notebooks/clv_automl.ipynbin einem Notebook. Öffnen Sie dieses Notebook auf der Jupyter-Oberfläche. Anschließend können Sie die in dieser Anleitung beschriebenen Schritte ausführen.Führen Sie den Code als Python-Skript aus. Die Codeschritte für diese Anleitung befinden sich im Code-Repository in der Datei
clv_automl/clv_automl.py. Das Skript übernimmt in der Befehlszeile Argumente für konfigurierbare Parameter wie die Projekt-ID, den Speicherort der API-Schlüsseldatei, die Google Cloud -Region und den Namen des BigQuery-Datasets. Führen Sie das Skript im Terminalfenster in der aktivierten Miniconda-Umgebung aus und ersetzen Sie dabei[YOUR_PROJECT]durch den Namen Ihres Projekts: Google Cloud$ (clv) cd clv_automl $ (clv) python clv_automl.py --project_id [YOUR_PROJECT]
Eine vollständige Liste der Parameter und Standardwerte finden Sie im Skript in der Methode
create_parser. Sie können das Skript auch ohne Argumente ausführen, um die Dokumentation zur Verwendung aufzurufen.Nachdem Sie die Cloud Composer-Umgebung gemäß der Beschreibung in der README-Datei installiert haben, führen Sie den Code aus. Zu diesem Zweck führen Sie die DAGs aus, wie weiter unten in DAGs ausführen beschrieben.
Daten vorbereiten
In diesem Artikel werden dieselben Schritte zur Dataset- und Datenvorbereitung in BigQuery wie in Teil 2 der ursprünglichen Reihe verwendet. Aggregieren Sie die Daten gemäß der Beschreibung im genannten Artikel. Dann sind Sie bereit, ein Dataset zur Verwendung mit AutoML Tables zu erstellen.
AutoML Tables-Dataset erstellen
Laden Sie zuerst die in BigQuery vorbereiteten Daten in AutoML Tables hoch.
Zum Initialisieren des Clients legen Sie den Namen der Schlüsseldatei auf den Namen der Datei fest, die Sie im Installationsschritt heruntergeladen haben:
keyfile_name = "mykey.json" client = automl_v1beta1.AutoMlClient.from_service_account_file(keyfile_name)Erstellen Sie das Dataset:
create_dataset_response = client.create_dataset( location_path, {'display_name': dataset_display_name, 'tables_dataset_metadata': {}}) dataset_name = create_dataset_response.name
Daten aus BigQuery importieren
Nachdem Sie das Dataset erstellt haben, können Sie die Daten aus BigQuery importieren.
Importieren Sie die Daten aus BigQuery in das AutoML Tables-Dataset:
dataset_bq_input_uri = 'bq://{}.{}.{}'.format(args.project_id, args.bq_dataset, args.bq_table) input_config = { 'bigquery_source': { 'input_uri': dataset_bq_input_uri}} import_data_response = client.import_data(dataset_name, input_config)
Modell trainieren
Nachdem Sie das AutoML-Dataset für die CLV-Daten erstellt haben, können Sie das AutoML Tables-Modell erstellen.
Rufen Sie die AutoML Tables-Spaltenspezifikationen für jede Spalte im Dataset ab:
list_table_specs_response = client.list_table_specs(dataset_name) table_specs = [s for s in list_table_specs_response] table_spec_name = table_specs[0].name list_column_specs_response = client.list_column_specs(table_spec_name) column_specs = {s.display_name: s for s in list_column_specs_response}Die Spaltenspezifikationen werden in späteren Schritten benötigt.
Weisen Sie eine der Spalten als Label für das AutoML Tables-Modell zu:
TARGET_LABEL = 'target_monetary' ... label_column_name = TARGET_LABEL label_column_spec = column_specs[label_column_name] label_column_id = label_column_spec.name.rsplit('/', 1)[-1] update_dataset_dict = { 'name': dataset_name, 'tables_dataset_metadata': { 'target_column_spec_id': label_column_id } } update_dataset_response = client.update_dataset(update_dataset_dict)Dieser Code verwendet dieselbe Labelspalte (
target_monetary) wie das TensorFlow-DNN-Modell in Teil 2.Definieren Sie die Features zum Trainieren des Modells:
feat_list = list(column_specs.keys()) feat_list.remove('target_monetary') feat_list.remove('customer_id') feat_list.remove('monetary_btyd') feat_list.remove('frequency_btyd') feat_list.remove('frequency_btyd_clipped') feat_list.remove('monetary_btyd_clipped') feat_list.remove('target_monetary_clipped')Zum Trainieren des AutoML Tables-Modells werden die gleichen Features verwendet, die auch zum Trainieren des TensorFlow-DNN-Modells in Teil 2 der ursprünglichen Reihe verwendet werden. Das Hinzufügen oder Entfernen von Features aus dem Modell ist mit AutoML Tables jedoch viel einfacher. Ein in BigQuery erstelltes Feature wird automatisch in das Modell aufgenommen, sofern es nicht ausdrücklich entfernt wurde, wie im vorherigen Code-Snippet gezeigt.
Definieren Sie die Optionen für die Modellerstellung. Für dieses Dataset wird als Optimierungsziel die Minimierung des mittleren absoluten Fehlers (Mean Absolute Error, MAE) empfohlen, dargestellt durch den Parameter
MINIMIZE_MAE.model_display_name = args.automl_model model_training_budget = args.training_budget * 1000 model_dict = { 'display_name': model_display_name, 'dataset_id': dataset_name.rsplit('/', 1)[-1], 'tables_model_metadata': { 'target_column_spec': column_specs['target_monetary'], 'input_feature_column_specs': [ column_specs[x] for x in feat_list], 'train_budget_milli_node_hours': model_training_budget, 'optimization_objective': 'MINIMIZE_MAE' } }Weitere Informationen finden Sie in der AutoML Tables-Dokumentation unter Ziele der Modelloptimierung.
Erstellen Sie das Modell und beginnen Sie mit dem Training:
create_model_response = client.create_model(location_path, model_dict) create_model_result = create_model_response.result() model_name = create_model_result.nameDer Rückgabewert des Clientaufrufs (
create_model_response) wird sofort zurückgegeben. Der Wertcreate_model_response.result()ist eine Zusage, die bis zum Abschluss des Trainings blockiert wird. Der Wertmodel_nameist ein Ressourcenpfad, der für weitere Clientaufrufe des Modells erforderlich ist.
Modell bewerten
Nach Abschluss des Modelltrainings können Sie die Modellbewertungsstatistik abrufen. Sie können dazu die Google Cloud Console oder die Client API verwenden.
Zur Verwendung der Console wechseln Sie in der AutoML Tables-Konsole zum Tab Bewerten:

Bei Verwendung der Client API rufen Sie die Modellbewertungsstatistiken ab:
model_evaluations = [e for e in client.list_model_evaluations(model_name)] model_evaluation = model_evaluations[0]Die Ausgabe sollte in etwa so aussehen:
name: "projects/595920091534/locations/us-central1/models/TBL3912308662231629824/modelEvaluations/9140437057533851929" create_time { seconds: 1553108019 nanos: 804478000 } evaluated_example_count: 125 regression_evaluation_metrics: { mean_absolute_error: 591.091 root_mean_squared_error: 853.481 mean_absolute_percentage_error: 21.47 r_squared: 0.907 }
Die Wurzel des mittleren quadratischen Fehlers (853,481) fällt im Vergleich zu den in der ursprünglichen Reihe verwendeten probabilistischen Modellen und TensorFlow-Modellen günstig aus. Wie in Teil 2 beschrieben, ist es jedoch ratsam, jede der bereitgestellten Techniken mit Ihren Daten zu testen, um zu ermitteln, welche die beste Leistung erzielt.
AutoML-Modell bereitstellen
Die Cloud Composer-DAGs aus der ursprünglichen Reihe wurden aktualisiert und enthalten das AutoML Tables-Modell für Training und Vorhersage. Allgemeine Informationen zur Funktionsweise der Cloud Composer-DAGs finden Sie im Abschnitt zur Automatisierung der Lösung in Teil 3 der ursprünglichen Artikel.
Folgen Sie der Anleitung in der README-Datei, um das Cloud Composer-Orchestrierungssystem für diese Lösung zu installieren.
Die aktualisierten DAGs rufen Methoden im Skript clv_automl/clv_automl.py auf, die die zuvor gezeigten Client-Codeaufrufe replizieren, um das Modell zu erstellen und Vorhersagen auszuführen.
Trainings-DAG
Der aktualisierte DAG für Trainings enthält Aufgaben zum Erstellen eines AutoML Tables-Modells. Das folgende Diagramm zeigt den neuen Trainings-DAG.

Vorhersage-DAG
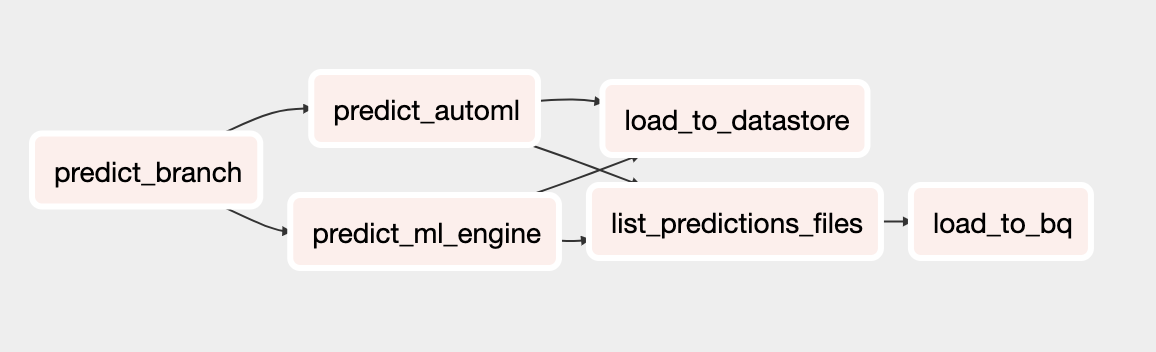
Der aktualisierte DAG für Vorhersagen umfasst Aufgaben zum Ausführen von Batchvorhersagen mit dem AutoML Tables-Modell. Das folgende Diagramm zeigt den neuen DAG für Vorhersagen.
DAGs ausführen
Sie können die DAGs auf zwei Arten ausführen: entweder in Cloud Shell über die Befehle im Abschnitt Run DAGs der README-Datei oder über die Google Cloud CLI.
So führen Sie den DAG
build_train_deployaus:gcloud composer environments run ${COMPOSER_NAME} \ --project ${PROJECT} \ --location ${REGION} \ dags trigger \ -- \ build_train_deploy \ --conf '{"model_type":"automl", "project":"'${PROJECT}'", "dataset":"'${DATASET_NAME}'", "threshold_date":"2011-08-08", "predict_end":"2011-12-12", "model_name":"automl_airflow", "model_version":"v1", "max_monetary":"15000"}'So führen Sie den DAG
predict_serveaus:gcloud composer environments run ${COMPOSER_NAME} \ --project ${PROJECT} \ --location ${REGION} \ dags trigger \ -- \ predict_serve \ --conf '{"model_name":"automl_airflow", "model_version":"v1", "dataset":"'${DATASET_NAME}'"}'
Nächste Schritte
- Alle CLV-Anleitungen lesen
- Komplettes Beispiel im GitHub-Repository ausführen
- Informationen zu anderen vorausschauenden Prognoselösungen
- Referenzarchitekturen, Diagramme und Best Practices zu Google Cloud kennenlernen. Weitere Informationen zu Cloud Architecture Center