Dieser Leitfaden bietet einen Überblick über die Optionen, Empfehlungen und allgemeinen Konzepte, die Sie kennen sollten, bevor Sie ein SAP HANA-System mit Hochverfügbarkeit (High Availability, HA) in Google Cloudbereitstellen.
In diesem Leitfaden wird davon ausgegangen, dass Sie bereits mit den Konzepten und Vorgehensweisen vertraut sind, die im Allgemeinen für die Implementierung eines SAP HANA-Hochverfügbarkeitssystems erforderlich sind. Daher konzentriert sich der Leitfaden hauptsächlich auf das, was Sie wissen müssen, um ein solches System in Google Cloudzu implementieren.
Weitere Informationen zu den allgemeinen Konzepten und Vorgehensweisen, die für die Implementierung eines SAP HANA-HA-Systems erforderlich sind, finden Sie unter:
- Best-Practices-Dokument von SAP zur Schaffung von Hochverfügbarkeit für SAP NetWeaver und SAP HANA unter Linux
- SAP HANA-Dokumentation
Dieser Planungsleitfaden konzentriert sich ausschließlich auf HA für SAP HANA und behandelt keine HA für Anwendungssysteme. Informationen zu HA für SAP NetWeaver finden Sie im Leitfaden zur Planung von Hochverfügbarkeit für SAP NetWeaver in Google Cloud.
Dieser Leitfaden ersetzt keine von SAP bereitgestellte Dokumentation.
Hochverfügbarkeitsoptionen für SAP HANA in Google Cloud
Sie können eine Kombination aus Google Cloud - und SAP-Features verwenden, um eine Hochverfügbarkeitskonfiguration für SAP HANA zu erstellen, die Ausfälle auf Infrastruktur- oder Softwareebene bewältigen kann. In der folgenden Tabelle werden SAP- und Google Cloud -Features beschrieben, mit denen Hochverfügbarkeit erzielt werden kann.
| Funktion | Beschreibung |
|---|---|
| Compute Engine-Live-Migration |
Compute Engine überwacht den Status der zugrunde liegenden Infrastruktur und migriert Ihre Instanz automatisch von einem Wartungsereignis der Infrastruktur fort. Dabei ist kein Nutzereingriff erforderlich. Compute Engine führt Ihre Instanz während der Migration wenn möglich weiter aus. Bei größeren Ausfällen kann es zu einer leichten Verzögerung zwischen dem Ausfall und der Verfügbarkeit der Instanz kommen. In Systemen mit mehreren Hosts sind freigegebene Volumes, wie das in der Bereitstellungsanleitung verwendete Volume "/hana/shared", nichtflüchtige Speicher, die an die virtuelle Maschine (VM) angehängt sind, die den Master-Host hostet. Sie werden auf den Worker-Hosts per NFS bereitgestellt. Das NFS-Volume ist im Fall einer Live-Migration des Master-Hosts bis zu einige Sekunden lang nicht erreichbar. Nachdem der Master-Host neu gestartet wurde, funktioniert das NFS-Volume auf allen Hosts wieder und es wird automatisch mit dem normalen Betrieb fortgefahren. Eine wiederhergestellte Instanz ist mit der ursprünglichen Instanz identisch, einschließlich der Instanz-ID, der privaten IP-Adresse, aller Instanzmetadaten und des gesamten Instanzspeichers. Für Standardinstanzen ist standardmäßig Live-Migration festgelegt. Wir empfehlen, diese Einstellung nicht zu ändern. Weitere Informationen finden Sie unter Live-Migration. |
| Automatischer Neustart bei Compute Engine |
Wenn Ihre Instanz so eingestellt ist, dass sie bei einem Wartungsereignis beendet wird, oder wenn Ihre Instanz aufgrund eines zugrunde liegenden Hardwareproblems abstürzt, können Sie Compute Engine so einrichten, dass die Instanz automatisch neu gestartet wird. Instanzen sind standardmäßig so eingestellt, dass sie automatisch neu gestartet werden. Wir empfehlen, diese Einstellung nicht zu ändern. |
| Automatischer SAP HANA-Dienstneustart |
Automatischer SAP HANA-Dienstneustart ist eine von SAP bereitgestellte Lösung zur Wiederherstellung im Fall eines Fehlers. In SAP HANA werden jederzeit viele konfigurierte Dienste für verschiedene Aktivitäten ausgeführt. Wenn einer dieser Dienste wegen eines Softwarefehlers oder menschlichen Versagens deaktiviert wird, startet die Watchdog-Funktion des automatischen SAP HANA-Dienstneustarts ihn automatisch neu. Nachdem der Dienst neu gestartet wurde, lädt er alle erforderlichen Daten wieder in den Arbeitsspeicher und setzt seine Arbeit fort. |
| SAP HANA-Sicherungen |
Im Rahmen von SAP HANA-Sicherungen werden Kopien der Daten in Ihrer Datenbank erstellt, mit denen ein Zustand wiederhergestellt werden kann, den die Datenbank zu einer bestimmten Zeit hatte. Weitere Informationen zum Verwenden von SAP HANA-Sicherungen in Google Cloudfinden Sie im Leitfaden für den SAP HANA-Betrieb. |
| SAP HANA-Speicherreplikation |
Die SAP HANA-Speicherreplikation bietet Unterstützung der Notfallwiederherstellung auf Speicherebene durch bestimmte Hardwarepartner. In Google Cloudwird die SAP HANA-Speicherreplikation nicht unterstützt. Sie können stattdessen Compute Engine-Snapshots nichtflüchtiger Speicher verwenden. Weitere Informationen dazu, wie Sie Snapshots nichtflüchtiger Speicher nutzen, um SAP HANA-Systeme auf Google Cloudzu sichern, finden Sie in der Betriebsanleitung für SAP HANA. |
| Automatischer SAP HANA-Host-Failover |
Der automatische SAP HANA-Host-Failover ist eine lokale Lösung zur Wiederherstellung im Fall eines Fehlers, für die ein oder mehrere SAP HANA-Standby-Hosts in einem System mit horizontaler Skalierung erforderlich sind. Wenn einer der Haupthosts ausfällt, aktiviert der automatische Host-Failover automatisch den Standby-Host und startet den ausgefallenen Host als Standby-Host neu. Weitere Informationen finden Sie unter: |
| SAP HANA-Systemreplikation |
Die SAP HANA-Systemreplikation ermöglicht es Ihnen, ein oder mehrere Systeme zu konfigurieren, die in Hochverfügbarkeitsszenarien oder im Fall einer Notfallwiederherstellung die Aufgaben des primären Systems übernehmen. Sie können die Replikation an die Anforderungen in Bezug auf Leistung und Failover-Zeit anpassen. |
| Option: Schneller SAP HANA-Neustart (empfohlen) |
Der schnelle SAP HANA-Neustart verkürzt die Neustartzeit, wenn SAP HANA beendet wird, das Betriebssystem jedoch weiter ausgeführt wird. SAP HANA reduziert die Neustartzeit, da die SAP HANA-Funktionen für nichtflüchtigen Speicher verwendet werden, um Hauptdatenfragmente von Spaltenspeichertabellen in DRAM beizubehalten, die dem Weitere Informationen zur Verwendung der schnellen SAP HANA-Neustart-Option finden Sie in den Bereitstellungsanleitungen für Hochverfügbarkeit: |
| SAP HANA-HA/DR-Anbieter-Hooks (empfohlen) |
Mit SAP HANA HA/DR-Provider-Hooks kann SAP HANA Benachrichtigungen für bestimmte Ereignisse an den Pacemaker-Cluster senden und so die Fehlererkennung verbessern. Die Provider-Hooks für SAP HANA HA/DR erfordern Weitere Informationen zur Verwendung der SAP HANA-HA/DR-Anbieter-Hooks finden Sie in den Bereitstellungsanleitungen für Hochverfügbarkeit: |
Betriebssystemspezifische HA-Cluster für SAP HANA auf Google Cloud
Das Linux-Betriebssystem-Clustering bietet Anwendungs- und Gast-Awareness für Ihren Anwendungsstatus und automatisiert Wiederherstellungsaktionen im Falle eines Ausfalls.
Obwohl die Grundsätze von Hochverfügbarkeitsclustern, die in Nicht-Cloud-Umgebungen angewendet werden, allgemein für Google Cloudgelten, gibt es einige Unterschiede bei der Implementierung, z. B. von Fencing und virtuellen IP-Adressen.
Sie können entweder Red Hat- oder SUSE-Hochverfügbarkeits-Distributionen von Linux für Ihren HA-Cluster für SAP HANA in Google Cloudverwenden.
Eine Anleitung zum Bereitstellen und manuellen Konfigurieren eines HA-Clusters inGoogle Cloud für SAP HANA finden Sie unter:
- Manuelle Konfiguration eines vertikal skalierbaren HA-Clusters in RHEL
- Manuelle HA-Clusterkonfiguration in SLES:
Informationen zu den Optionen für die automatisierte Bereitstellung, die von Google Cloudbereitgestellt werden, finden Sie unter Optionen für die automatische Bereitstellung für SAP HANA-Hochverfügbarkeitskonfigurationen.
Agents für Clusterressourcen
Sowohl Red Hat als auch SUSE stellen Ressourcen-Agents für Google Cloud mit ihren Hochverfügbarkeitskonfigurationen der Pacemaker-Clustersoftware bereit. Die Ressourcen-Agents für Google Cloud verwalten Fencing, VIPs, die entweder mit Routen oder Alias-IP-Adressen implementiert werden, und Speicheraktionen.
Zur Bereitstellung von Aktualisierungen, die noch nicht in den Ressourcen-Agents des Basisbetriebssystems enthalten sind, stelltGoogle Cloud regelmäßig Companion-Ressourcen-Agents für Hochverfügbarkeitscluster für SAP zur Verfügung. Wenn diese Companion-Ressourcen-Agents erforderlich sind, enthalten dieGoogle Cloud Bereitstellungsverfahren einen Schritt zum Herunterladen.
Fencing-Agents
Das Fencing im Sinne des Betriebssystemclusterings der Google Cloud Compute Engine erfolgt in Form von STONITH, wodurch jedes Mitglied in einem Cluster mit zwei Knoten den anderen Knoten neu starten kann.
Google Cloud stellt zwei Fencing-Agents für die Verwendung mit SAP auf Linux-Betriebssystemen zur Verfügung: den Agent fence_gce, der in zertifizierten Red Hat- und SUSE-Linux-Distributionen enthalten ist, und den Legacy-Agent gcpstonith, den Sie auch für die Verwendung mit Linux-Distributionen herunterladen können, die den Agent fence_gce nicht enthalten. Wir empfehlen, den fence_gce-Agenten zu verwenden, sofern verfügbar.
Erforderliche IAM-Berechtigungen für Fencing-Agents
Die Fencing-Agents starten VMs neu. Dazu richten sie einen Aufruf zum Zurücksetzen an die Compute Engine-API. Zur Authentifizierung und Autorisierung für den Zugriff auf die API verwenden die Fence-Agents das Dienstkonto der VM. Das Dienstkonto, das ein Fence-Agent verwendet, muss mit einer Rolle ausgestattet sein, die die folgenden Berechtigungen enthält:
- compute.instances.get
- compute.instances.list
- compute.instances.reset
- compute.instances.start
- compute.instances.stop
- compute.zoneOperations.get
- logging.logEntries.create
- compute.zoneOperations.list
Die vordefinierte Rolle "Compute-Instanzadministrator" enthält alle erforderlichen Berechtigungen.
Um den Umfang der Neustartberechtigung des Agents auf den Zielknoten zu beschränken, können Sie den ressourcenbasierten Zugriff konfigurieren. Weitere Informationen finden Sie unter Ressourcenbasierten Zugriff konfigurieren.
Virtuelle IP-Adresse
Hochverfügbarkeitscluster für SAP in Google Cloud verwenden eine virtuelle oder Floating-IP-Adresse (VIP), damit der Netzwerktraffic bei einem Failover von einem Host zu einem anderen weitergeleitet wird. Google Cloud
Typische cloudunabhängige Bereitstellungen kündigen die Verschiebung und Neuzuweisung einer VIP zu einer neuen MAC-Adresse mit einem Gratuitous Address Resolution Protocol (ARP) an.
In Google Cloudnutzen Sie anstelle von Gratuitous-ARP-Anfragen eine der verschiedenen Methoden, um eine VIP in einem HA-Cluster zu verschieben und neu zuzuweisen. Empfohlen wird die Verwendung eines internen TCP/UDP-Load-Balancers. Je nach Ihren Anforderungen können Sie jedoch auch eine routenbasierte VIP-Implementierung oder eine Alias-IP-basierte VIP-Implementierung verwenden.
Weitere Informationen zur VIP-Implementierung in Google Cloudfinden Sie unter Implementierung virtueller IP-Adressen in Google Cloud.
Speichern und Replizieren
Eine SAP HANA-HA-Clusterkonfiguration verwendet die synchrone SAP HANA-Systemreplikation, um die primäre und sekundäre SAP HANA-Datenbank zu synchronisieren. Die standardmäßigen, vom Betriebssystem bereitgestellten Ressourcen-Agents für SAP HANA verwalten die Systemreplikation während eines Failovers. Sie starten und beenden die Replikation und entscheiden, welche Instanzen im Replikationsprozess als aktive und als Standby-Instanzen ausgeführt werden.
Wenn Sie gemeinsam genutzten Dateispeicher benötigen, können NFS- oder SMB-basierte Filer die erforderlichen Funktionen bieten.
Für eine Hochverfügbarkeitslösung mit freigegebenem Speicher können Sie Filestore, das Premium- oder Extreme-Servicelevel von Google Cloud NetApp Volumes oder eine Dateifreigabelösung eines Drittanbieters verwenden. Die regionale Dienstebene (früher Enterprise) von Filestore kann für Bereitstellungen in mehreren Zonen und die Basisstufe von Filestore kann für Bereitstellungen in einzelnen Zonen verwendet werden.
Regionale nichtflüchtige Compute Engine-Speicher bieten synchron replizierten Blockspeicher über mehrere Zonen hinweg. Regionale nichtflüchtige Speicher werden für den Datenbankspeicher in SAP-HA-Systemen zwar nicht unterstützt, Sie können sie aber mit NFS-Dateiservern verwenden.
Weitere Informationen zu Speicheroptionen auf Google Cloudfinden Sie unter:
Konfigurationseinstellungen für HA-Cluster in Google Cloud
Google Cloud empfiehlt, die Standardwerte bestimmter Clusterkonfigurationsparameter in Werte zu ändern, die für SAP-Systeme in der Google Cloud -Umgebung besser geeignet sind. Wenn Sie die von Google Cloudbereitgestellten Automatisierungsscripts verwenden, werden die empfohlenen Werte für Sie festgelegt.
Betrachten Sie die empfohlenen Werte als Ausgangspunkt für die Feinabstimmung der Corosync-Einstellungen in Ihrem HA-Cluster. Sie müssen bestätigen, dass die Fehlererkennung und die Auslösung des Failovers für Ihre Systeme und Arbeitslasten in der Google Cloud -Umgebung geeignet sind.
Corosync-Konfigurationsparameterwerte
In den Leitfäden zur HA-Clusterkonfiguration für SAP HANA werden Werte für mehrere Parameter im Abschnitt totem der Konfigurationsdatei corosync.conf empfohlen, die sich von den Standardwerten unterscheiden, die von Corosync oder Ihrem Linux-Händler festgelegt werden. Google Cloud
totem-Parameter, für die Google Cloudempfohlene Werte angegeben sind, sowie die Auswirkungen der Änderung der Werte aufgeführt. Die Standardwerte für die Parameter, die bei Linux-Distributionen abweichen können, finden Sie in der Dokumentation zu Ihrer Linux-Distribution.
| Parameter | Empfohlener Wert | Auswirkungen der Wertänderung |
|---|---|---|
secauth |
off |
Deaktiviert die Authentifizierung und Verschlüsselung aller totem-Nachrichten. |
join |
60 (ms) | Erhöht, wie lange der Knoten im Mitgliedsprotokoll auf join-Nachrichten wartet. |
max_messages |
20 | Erhöht die maximale Anzahl von Nachrichten, die vom Knoten nach Erhalt des Tokens gesendet werden können. |
token |
20000 (ms) |
Erhöht, wie lange der Knoten auf ein
Wenn Sie den Wert des Parameters Der Wert des Parameters |
consensus |
– | Gibt in Millisekunden an, wie lange auf die Erzielung von Einigkeit gewartet werden soll, bevor eine neue Runde der Mitgliedschaftskonfiguration gestartet wird.
Wir empfehlen, diesen Parameter wegzulassen. Wenn der Parameter consensus angeben, muss dieser Wert 24000 oder 1.2*token sein, je nachdem, welcher Wert höher ist.
|
token_retransmits_before_loss_const |
10 | Erhöht die Anzahl der Token-Übertragungsversuche, die der Knoten unternimmt, bis er davon ausgeht, dass der Empfängerknoten fehlgeschlagen ist, und Maßnahmen ergreift. |
transport |
|
Gibt den von Corosync verwendeten Transportmechanismus an. |
Weitere Informationen zum Konfigurieren der Datei corosync.conf finden Sie im Konfigurationsleitfaden für Ihre Linux-Distribution:
- RHEL: Standardeinstellungen für „corosync.conf“ bearbeiten
- SLES: Corsync-Konfigurationsdateien erstellen
Zeitüberschreitung und Intervalleinstellungen für Clusterressourcen
Wenn Sie eine Clusterressource definieren, legen Sie die Werte für interval und timeout für verschiedene Ressourcenvorgänge in Sekunden fest (op). Beispiel:
primitive rsc_SAPHanaTopology_HA1_HDB00 ocf:suse:SAPHanaTopology \ operations \$id="rsc_sap2_HA1_HDB00-operations" \ op monitor interval="10" timeout="600" \ op start interval="0" timeout="600" \ op stop interval="0" timeout="300" \ params SID="HA1" InstanceNumber="00" clone cln_SAPHanaTopology_HA1_HDB00 rsc_SAPHanaTopology_HA1_HDB00 \ meta is-managed="true" clone-node-max="1" target-role="Started" interleave="true"
Die timeout-Werte wirken sich auf jeden der Ressourcenvorgänge unterschiedlich aus, wie in der folgenden Tabelle dargestellt.
| Ressourcenvorgang | Aktion bei Zeitüberschreitung |
|---|---|
monitor |
Wird das Zeitlimit überschritten, meldet der Monitoring-Status normalerweise als fehlgeschlagen und die zugehörige Ressource wird als fehlgeschlagen angesehen. Der Cluster versucht, Wiederherstellungsoptionen zu nutzen, die ein Failover beinhalten können. Der Cluster wiederholt einen fehlgeschlagenen Monitoringvorgang nicht. |
start |
Wenn eine Ressource nicht vor Beginn der Zeitüberschreitung gestartet werden kann, versucht der Cluster, die Ressource neu zu starten. Dieses Verhalten wird durch die On-Failure-Aktion vorgegeben, die mit einer Ressource verknüpft ist. |
stop |
Wenn eine Ressource nicht auf einen Stoppvorgang reagiert, bevor das Zeitlimit erreicht ist, wird dadurch ein Fencing-Ereignis ausgelöst. |
Neben anderen Einstellungen für die Clusterkonfiguration steuern die Einstellungen interval und timeout der Clusterressourcen, wie schnell die Clustersoftware einen Fehler erkennt und ein Failover auslöst.
Die timeout- und interval-Werte, die von Google Cloud in den Cluster-Konfigurationsanleitungen für das SAP HANA-Konto zur Wartung der Live-Migration von Compute Engine vorgeschlagen werden. Google Cloud
Unabhängig davon, welche timeout- und interval-Werte Sie verwenden, müssen Sie die Werte beim Testen des Clusters auswerten, insbesondere bei Live-Migrationstests, da die Länge von Live-Migrationsereignissen geringfügig variieren kann – abhängig vom verwendeten Maschinentyp und anderen Faktoren wie der Systemauslastung.
Einstellungen für Fencing-Ressourcen
In den Konfigurationsleitfäden für HA-Cluster für SAP HANA Google Cloudwerden mehrere Parameter empfohlen,die beim Konfigurieren der Ressourcen für das Fencing des HA-Clusters verwendet werden. Die empfohlenen Werte unterscheiden sich von den Standardwerten, die von Corosync oder Ihrem Linux-Betriebssystem-Verteiler festgelegt werden.
In der folgenden Tabelle sind die von Google Cloudempfohlenen Begrenzungsparameter sowie die empfohlenen Werte und Details zu den Parametern aufgeführt. Die Standardwerte für die Parameter, die bei Linux-Distributionen abweichen können, finden Sie in der Dokumentation zu Ihrer Linux-Distribution.
| Parameter | Empfohlener Wert | Details |
|---|---|---|
pcmk_reboot_timeout |
300 Sekunden | Gibt den Wert des Zeitlimits an, das für Neustartaktionen verwendet werden soll.
Der
|
pcmk_monitor_retries |
4 | Gibt die maximale Anzahl der Wiederholungen des monitor-Befehls innerhalb des Zeitlimits an. |
pcmk_delay_max |
30 Sekunden | Gibt eine zufällige Verzögerung bei Fencing-Aktionen an, um zu verhindern, dass die Clusterknoten einander gleichzeitig Fencen. Um ein Fencing-Race zu vermeiden, darf nur einer Instanz eine zufällige Verzögerung zugeordnet sein. Dieser Parameter sollte nur auf einer der Fencing-Ressourcen in einem HANA-Cluster mit zwei Knoten (Hochskalierung) aktiviert werden. In einem HANA HA-Cluster mit horizontaler Skalierung sollte dieser Parameter auf allen Knoten aktiviert werden, die Teil eines Standorts sind (primär oder sekundär). |
HA-Cluster in Google Cloudtesten
Nachdem der Cluster konfiguriert wurde und zusammen mit den SAP HANA-Systemen in Ihrer Testumgebung bereitgestellt wurde, müssen Sie den Cluster testen, um zu prüfen, ob das HA-System richtig konfiguriert ist und wie erwartet funktioniert.
Simulieren Sie verschiedene Fehlerszenarien mit den folgenden Aktionen, um zu prüfen, ob das Failover erwartungsgemäß funktioniert:
- VM herunterfahren
- Kernel Panic erstellen
- Anwendung herunterfahren
- Netzwerk zwischen Instanzen trennen
Simulieren Sie außerdem ein Compute Engine-Live-Migrationsereignis auf dem primären Host, um zu bestätigen, dass kein Failover ausgelöst wird. Sie können ein Wartungsereignis mit dem Google Cloud CLI-Befehl gcloud compute instances
simulate-maintenance-event simulieren.
Logging und Monitoring
Ressourcen-Agents können Logging-Funktionen enthalten, die Logs zur Analyse an Google Cloud Observability weiterleiten. Jeder Ressourcen-Agent enthält Konfigurationsinformationen, mit denen Logging-Optionen identifiziert werden. Bei Bash-Implementierungen ist die Logging-Option gcloud logging.
Sie können auch den Cloud Logging-Agent installieren, um die Logausgabe von Betriebssystemprozessen zu erfassen und die Ressourcenauslastung mit Systemereignissen zu verknüpfen. Der Logging-Agent erfasst Standardsystemlogs, die Logdaten von Pacemaker und den Clustering-Diensten enthalten. Weitere Informationen finden Sie unter Informationen zum Logging-Agent.
Informationen zur Verwendung von Cloud Monitoring zum Konfigurieren von Dienstprüfungen, die die Verfügbarkeit von Dienstendpunkten überwachen, finden Sie unter Verfügbarkeitsdiagnosen verwalten.
Dienstkonten und Hochverfügbarkeitscluster
Die Aktionen, die die Clustersoftware in der Google Cloud-Umgebung ausführen kann, werden durch die Berechtigungen geschützt, die dem Dienstkonto jeder Host-VM zugewiesen werden. In Hochsicherheitsumgebungen können Sie die Berechtigungen für die Dienstkonten Ihrer Host-VMs so einschränken, dass sie dem Prinzip der geringsten Berechtigung entsprechen.
Wenn Sie die Dienstkontoberechtigungen einschränken, beachten Sie, dass Ihr System möglicherweise mit Google Cloud Diensten wie Cloud Storage interagieren kann. Daher müssen Sie möglicherweise Berechtigungen für diese Dienstinteraktionen im Dienstkonto der Host-VM einschließen.
Wenn Sie die restriktivsten Berechtigungen erteilen möchten, erstellen Sie eine benutzerdefinierte Rolle mit den erforderlichen Mindestberechtigungen. Informationen zu benutzerdefinierten Rollen finden Sie unter Benutzerdefinierte Rollen erstellen und verwalten. Sie können Berechtigungen weiter einschränken, indem Sie sie auf bestimmte Instanzen einer Ressource beschränken, z. B. auf die VM-Instanzen Ihres Hochverfügbarkeitsclusters. Fügen Sie dazu Bedingungen in den Rollenbindungen der IAM-Richtlinie einer Ressource hinzu.
Die Mindestberechtigungen, die Ihre Systeme benötigen, hängen von denGoogle Cloud Ressourcen ab, auf die Ihre Systeme zugreifen, und von den Aktionen, die sie ausführen. Daher müssen Sie bei der Ermittlung der erforderlichen Mindestberechtigungen für die Host-VMs in Ihrem Hochverfügbarkeitscluster möglicherweise genau untersuchen, auf welche Ressourcen die Systeme auf der Host-VM zugreifen und welche Aktionen sie bei diesen Ressourcen ausführen.
In der folgenden Liste werden einige HA-Clusterressourcen und die damit verbundenen Berechtigungen aufgeführt:
- Fencing
- compute.instances.list
- compute.instances.get
- compute.instances.reset
- compute.instances.stop
- compute.instances.start
- logging.logEntries.create
- compute.zones.list
- VIP, die mithilfe einer Alias-IP implementiert wurde
- compute.instances.list
- compute.instances.get
- compute.zones.list
- logging.logEntries.create
- compute.instances.updateNetworkInterface
- compute.zoneOperations.get
- logging.logEntries.create
- VIP, die mit statischen Routen implementiert wurde
- compute.instances.list
- compute.instances.get
- compute.zones.list
- logging.logEntries.create
- compute.routes.get
- compute.routes.create
- compute.routes.delete
- compute.routes.update
- compute.routes.list
- compute.networks.updatePolicy
- compute.networks.get
- compute.globalOperations.get
- logging.logEntries.create
- VIP, die mithilfe eines internen Load-Balancers implementiert wurde
- Es sind keine speziellen Berechtigungen erforderlich: Der Load Balancer verarbeitet Systemdiagnosestatus, bei denen der Cluster nicht mit Ressourcen in Google Cloudinteragieren oder diese ändern muss
Virtuelle IP-Implementierung in Google Cloud
Ein Hochverfügbarkeitscluster verwendet eine Floating- oder virtuelle IP-Adresse (VIP), um die Arbeitslast bei einem unerwarteten Ausfall oder einer geplanten Wartung von einem Clusterknoten zu einem anderen zu verschieben. Die IP-Adresse der VIP ändert sich nicht, sodass Clientanwendungen nicht wissen, dass die Arbeit von einem anderen Knoten bereitgestellt wird.
Eine VIP wird auch als Floating-IP-Adresse bezeichnet.
In Google Cloudwerden VIPs etwas anders implementiert als bei lokalen Installationen, da bei einem Failover keine Gratuitous-ARP-Anfragen verwendet werden können, um die Änderung anzukündigen. Stattdessen können Sie eine VIP-Adresse für einen SAP-HA-Cluster mit einer der folgenden Methoden implementieren:
- Failover-Unterstützung für internen Passthrough-Netzwerk-Load-Balancer (empfohlen)
- Google Cloud statische Routen.
- Google Cloud Alias-IP-Adressen
VIP-Implementierungen mit internem Passthrough-Network-Load-Balancer
Ein Load-Balancer verteilt den Nutzertraffic normalerweise auf mehrere Instanzen Ihrer Anwendungen, um die Arbeitslast auf mehrere aktive Systeme zu verteilen und vor einer Verlangsamung oder einem Ausfall auf einer einzelnen Instanz zu schützen.
Der interne Passthrough-Network-Load-Balancer bietet auch Failover-Unterstützung, die Sie zusammen mit Compute Engine-Systemdiagnosen verwenden können, um Fehler zu erkennen, Failover auszulösen und Traffic an ein neues primäres SAP-System in einem standardmäßigen HA-Cluster des Betriebssystems weiterzuleiten.
Die Failover-Unterstützung ist aus verschiedenen Gründen die empfohlene VIP-Implementierung. Dafür gibt es verschiedene Gründe:
- Load-Balancing in Compute Engine bietet eine per SLA zugesagte Verfügbarkeit von 99,99 %.
- Load-Balancing unterstützt Mehrzonencluster mit hoher Verfügbarkeit, die vor Zonenausfällen durch vorhersehbare zonenübergreifende Failover-Zeiten geschützt sind.
- Die Verwendung des Load-Balancings reduziert die Zeit, die zum Erkennen und Auslösen eines Failovers erforderlich ist, normalerweise innerhalb von Sekunden nach dem Ausfall. Die gesamten Failover-Zeiten hängen von den Failover-Zeiten der einzelnen Komponenten im Hochverfügbarkeitssystem ab. Dazu können u. a. die Hosts, Datenbanksysteme und Anwendungssysteme gehören.
- Load-Balancing vereinfacht die Clusterkonfiguration und reduziert Abhängigkeiten.
- Im Gegensatz zu einer VIP-Implementierung, die Routen mit Load-Balancing verwendet, können Sie IP-Bereiche aus Ihrem eigenen VPC-Netzwerk verwenden, um sie nach Bedarf zu reservieren und zu konfigurieren.
- Mit dem Load-Balancing lässt sich der Traffic bei geplanten Wartungsausfällen ganz einfach an ein sekundäres System weiterleiten.
Wenn Sie eine Systemdiagnose für eine Load-Balancer-Implementierung einer VIP erstellen, geben Sie den Hostport an, den die Systemdiagnose prüft, um die Integrität des Hosts zu ermitteln. Geben Sie für einen SAP HA-Cluster einen Zielhostport im privaten Bereich (49152–65535) an, damit keine Probleme mit anderen Diensten auftreten. Konfigurieren Sie auf der Host-VM den Zielport mit einem sekundären Hilfsdienst wie dem Socat-Dienstprogramm oder HAProxy.
Bei Datenbankclustern, in denen das sekundäre Standby-System online bleibt, aktivieren die Systemdiagnose und der Hilfsdienst das Load-Balancing, um Traffic an das Onlinesystem weiterzuleiten, das derzeit als primäres System im Cluster dient.
Mit dem Hilfsdienst und der Portweiterleitung können Sie einen Failover für geplante Softwarewartungen auf Ihren SAP-Systemen auslösen.
Weitere Informationen zur Unterstützung von Failover finden Sie unter Failover für internen Passthrough-Network-Load-Balancer konfigurieren.
Informationen zum Bereitstellen eines Clusters für Hochverfügbarkeit mit einer VIP-Implementierung des Load-Balancers finden Sie unter:
- Terraform: Konfigurationsleitfaden für SAP HANA-Hochverfügbarkeitscluster
- Konfigurationsleitfaden: Hochverfügbarkeitscluster für SAP HANA unter RHEL
- Konfigurationsanleitung für Hochverfügbarkeitscluster für SAP HANA unter SLES
Statische Routen-VIPs implementieren
Die Implementierung einer statischen Route bietet auch Schutz vor Zonenausfällen, erfordert jedoch die Verwendung einer VIP außerhalb der IP-Bereiche Ihrer vorhandenen VPC-Subnetze, in denen sich die VMs befinden. Daher darf die VIP nicht mit externen IP-Adressen in Ihrem erweiterten Netzwerk in Konflikt stehen.
Statische Routenimplementierungen können außerdem komplex sein, wenn sie mit freigegebenen VPC-Konfigurationen verwendet werden, mit denen die Netzwerkkonfiguration in ein Hostprojekt unterteilt werden soll.
Wenn Sie eine statische Routenimplementierung für Ihre VIP verwenden, wenden Sie sich an Ihren Netzwerkadministrator, um eine geeignete IP-Adresse für die Implementierung einer statischen Route zu finden.
Alias-IP-VIP implementieren
Die Implementierung von Alias-IP-VIP wird für Mehrzonen-HA-Bereitstellungen nicht empfohlen, da bei einem Ausfall einer Zone die Neuzuweisung der Alias-IP zu einem Knoten in einer anderen Zone verzögert werden kann. Implementieren Sie Ihre VIP stattdessen mit einem internen Passthrough-Netzwerk-Load-Balancer mit Failover-Unterstützung.
Wenn Sie alle Knoten Ihres SAP-HA-Clusters in derselben Zone bereitstellen, können Sie eine Alias-IP verwenden, um eine VIP für den HA-Cluster zu implementieren.
Wenn Sie bestehende SAP-HA-Cluster mit mehreren Zonen haben, die eine Alias-IP-Implementierung für die VIP verwenden, können Sie zu einer Implementierung eines internen Passthrough-Network-Load-Balancers migrieren, ohne Ihre VIP-Adresse zu ändern. Sowohl Alias-IP-Adressen als auch interne Passthrough-Netzwerk-Load-Balancer verwenden IP-Bereiche aus Ihrem VPC-Netzwerk.
Alias-IP-Adressen werden für VIP-Implementierungen in Mehrzonen-HA-Clustern zwar nicht empfohlen, werden jedoch anderweitig für SAP-Bereitstellungen genutzt. Sie können beispielsweise verwendet werden, um einen logischen Hostnamen und IP-Zuweisungen für flexible SAP-Bereitstellungen zur Verfügung zu stellen, z. B. diejenigen, die von SAP Landscape Management verwaltet werden.
Allgemeine Best Practices für VIPs in Google Cloud
Weitere Informationen zu VIPs in Google Cloudfinden Sie unter Best Practices für Floating-IP-Adressen.
Automatischer SAP HANA-Host-Failover auf Google Cloud
Google Cloud unterstützt den automatischen SAP HANA-Host-Failover, die von SAP HANA bereitgestellte lokale Lösung zur Wiederherstellung im Fall eines Fehlers. Die Lösung für automatischen Host-Failover verwendet einen oder mehrere Standby-Hosts, die in Reserve gehalten werden, um im Fall eines Hostfehlers die Aufgaben des Master-Hosts bzw. eines Worker-Hosts zu übernehmen. Die Standby-Hosts enthalten keine Daten und erledigen keine Arbeit.
Nach dem Abschluss eines Failovers wird der ausgefallene Host als Standby-Host neu gestartet.
SAP unterstützt in Systemen mit horizontaler Skalierung auf Google Cloudbis zu drei Standby-Hosts. Diese werden nicht auf das Maximum von 16 aktiven Hosts angerechnet, die SAP in Systemen mit horizontaler Skalierung aufGoogle Cloudunterstützt.
Weitere Informationen von SAP über die automatische Host-Failover-Lösung finden Sie unter Automatisches Host-Failover.
Wann wird der automatische SAP HANA-Host-Failover in Google Cloud
Das automatische Failover des SAP HANA-Hosts schützt vor Fehlern, die einen einzelnen Knoten in einem SAP HANA-System mit horizontaler Skalierung beeinträchtigen, einschließlich folgender Fehler:
- SAP HANA-Instanz
- Das Hostbetriebssystem
- Host-VM
In Bezug auf Ausfälle der Host-VM wird in Google Cloudder automatische Neustart (einschließlich der automatischen Host-Failover) in der Regel schneller wiederhergestellt. Durch die Live-Migration können Sie sowohl geplante als auch ungeplante VM-Ausfälle gemeinsam schützen. Für den VM-Schutz ist eine automatische SAP HANA-Host-Failover-Lösung nicht erforderlich.
Der automatische SAP HANA-Host-Failover schützt Sie nicht vor zonalen Fehlern, da alle Knoten eines SAP HANA-Systems mit horizontaler Skalierung in einer einzigen Zone bereitgestellt werden.
SAP HANA Host-Auto-Failover lädt keine SAP HANA-Daten in den Speicher von Standby-Knoten vor. Wenn also ein Standby-Knoten übernimmt, wird die Gesamtwiederherstellungszeit des Knotens hauptsächlich dadurch bestimmt, wie lange es dauert, die Daten in den Speicher des Standby-Knotens zu laden.
Erwägen Sie die Verwendung des automatischen Failovers des SAP HANA-Hosts in den folgenden Szenarien:
- Ausfälle der Software oder des Betriebssystems eines SAP HANA-Knotens, die von Google Cloudmöglicherweise nicht erkannt werden.
- Lift-and-Shift-Migrationen, bei denen Sie Ihre lokale SAP HANA-Konfiguration reproduzieren müssen, bis Sie SAP HANA fürGoogle Cloudoptimieren können.
- Wenn eine vollständig replizierte, zonenübergreifende Hochverfügbarkeitskonfiguration äußerst kostengünstig und Ihr Unternehmen tolerant ist:
- Eine längere Wiederherstellung von Knoten aufgrund der Notwendigkeit, SAP HANA-Daten in den Arbeitsspeicher eines Standby-Knotens zu laden.
- Das Risiko eines zonalen Ausfalls.
Speichermanager für SAP HANA
Die Volumes /hana/data und /hana/log werden nur auf dem Master-Host und den Worker-Hosts bereitgestellt. Bei einem Takeover verwendet die Lösung für automatischen Host-Failover die SAP HANA Storage Connector API und denGoogle Cloud Storage Manager für SAP HANA-Standby-Knoten, um die Volume-Bereitstellungen vom ausgefallenen Host in den Host-Standby zu verschieben.
In Google Cloudist der Speichermanager für SAP HANA-Systeme erforderlich, wenn SAP HANA-Systeme mit automatischem SAP HANA-Host-Failover betrieben werden.
Unterstützte Versionen des Storage-Managers für SAP HANA
Versionen 2.0 und höher des Storage-Managers für SAP HANA werden unterstützt. Alle Versionen vor 2.0 wurden verworfen und werden nicht unterstützt. Aktualisieren Sie Ihr SAP HANA-System so, dass die neueste Version des Speichermanagers für SAP HANA verwendet wird, wenn Sie eine ältere Version verwenden. Siehe Storage Manager für SAP HANA aktualisieren.
Öffnen Sie die Datei gceStorageClient.py, um festzustellen, ob Ihre Version veraltet ist.
Das Standardinstallationsverzeichnis ist /hana/shared/gceStorageClient:
Ab Version 2.0 ist die Versionsnummer in den Kommentaren in der Datei gceStorageClient.py aufgeführt, wie im folgenden Beispiel gezeigt. Sehen Sie sich eine verworfene Version des Storage-Managers für SAP HANA an, wenn die Versionsnummer fehlt.
"""Google Cloud Storage Manager for SAP HANA Standby Nodes. The Storage Manager for SAP HANA implements the API from the SAP provided StorageConnectorClient to allow attaching and detaching of disks when running in Compute Engine. Build Date: Wed Jan 27 06:39:49 PST 2021 Version: 2.0.20210127.00-00 """
Storage Manager für SAP HANA installieren
Die empfohlene Methode für die Installation des Speichermanagers für SAP HANA ist die Verwendung einer automatisierten Bereitstellungsmethode, um ein SAP HANA-System mit horizontaler Skalierung bereitzustellen, das den neuesten Speichermanager für SAP HANA enthält.
Wenn Sie einem vorhandenen SAP HANA-System mit horizontaler Skalierung auf Google Cloudein automatisches SAP HANA-Host-Failover hinzufügen möchten, ist der empfohlene Ansatz ähnlich: Verwenden Sie die von Google Cloud bereitgestellte Terraform-Konfigurationsdatei, um ein neues SAP HANA-System mit horizontaler Skalierung bereitzustellen, und laden Sie dann die Daten aus dem vorhandenen System in das neue System. Zum Laden der Daten können Sie entweder die SAP HANA-Sicherungs- und Wiederherstellungsverfahren oder die SAP HANA-Systemreplikation verwenden, die die Ausfallzeiten begrenzen können. Weitere Informationen zur Systemreplikation finden Sie im SAP-Hinweis 2473002 – HANA-Systemreplikation zur Migration von horizontaler Skalierung verwenden.
Wenn Sie keine automatisierte Bereitstellungsmethode verwenden können, sollten Sie sich an einen SAP-Lösungsberater wenden, der Ihnen bei der manuellen Installation des Storage Managers für SAP HANA hilft, z. B. über die Google Cloud Consulting-Dienste.
Die manuelle Installation von Speichermanager für SAP HANA in einem vorhandenen oder neuen SAP HANA-System mit horizontaler Skalierung ist derzeit nicht dokumentiert.
Weitere Informationen zu den automatisierten Bereitstellungsoptionen für das automatische Failover des SAP HANA-Hosts finden Sie unter Automatisierte Bereitstellung von SAP HANA-Systemen mit horizontaler Skalierung und automatischem SAP HANA-Host-Failover.
Storage Manager für SAP HANA aktualisieren
Zum Aktualisieren des Speichermanagers für SAP HANA müssen Sie zuerst das Installationspaket herunterladen und anschließend ein Installationsskript ausführen. Dadurch wird der Storage Manager für die SAP HANA-Ausführung im SAP HANA-Laufwerk /shared aktualisiert.
Das folgende Verfahren gilt nur für Version 2 des Speichermanagers für SAP HANA. Wenn Sie eine Version des Speichermanagers für SAP HANA verwenden, die vor dem 1. Februar 2021 heruntergeladen wurde, installieren Sie Version 2, bevor Sie den Speichermanager für SAP HANA aktualisieren.
So aktualisieren Sie den Speichermanager für SAP HANA:
Überprüfen Sie die Version Ihres aktuellen Speichermanagers für SAP HANA:
RHEL
sudo yum check-update google-sapgcestorageclient
SLES
sudo zypper list-updates -r google-sapgcestorageclient
Wenn ein Update vorhanden ist, installieren Sie dieses:
RHEL
sudo yum update google-sapgcestorageclient
SLES
sudo zypper update
Der aktualisierte Speichermanager für SAP HANA ist in
/usr/sap/google-sapgcestorageclient/gceStorageClient.pyinstalliert.Ersetzen Sie die vorhandene
gceStorageClient.pydurch die aktualisierte DateigceStorageClient.py:Wenn sich Ihre vorhandene
gceStorageClient.py-Datei in/hana/shared/gceStorageClientbefindet, dem Standardinstallationsverzeichnis, aktualisieren Sie die Datei mit dem Installationsskript:sudo /usr/sap/google-sapgcestorageclient/install.sh
Wenn sich Ihre vorhandene
gceStorageClient.py-Datei nicht in/hana/shared/gceStorageClientbefindet, kopieren Sie die aktualisierte Datei in den selben Speicherort wie Ihre vorhandene Datei und ersetzen Sie die vorhandene Datei.
Konfigurationsparameter in der Datei global.ini
Bestimmte Konfigurationsparameter für den Speichermanager von SAP HANA, einschließlich der Aktivierung oder Deaktivierung von Fechten, werden im Abschnitt "Speicher" der SAP HANA-Datei global.ini gespeichert. Wenn Sie die von Google Cloud bereitgestellte Terraform-Konfigurationsdatei verwenden, um ein SAP HANA-System mit der automatischen Failover-Funktion des Hosts bereitzustellen, fügt der Bereitstellungsprozess die Konfigurationsparameter für Sie zur Datei global.ini hinzu.
Das folgende Beispiel zeigt den Inhalt einer global.ini, die für den Storage Manager für SAP HANA erstellt wurde:
[persistence] basepath_datavolumes = %BASEPATH_DATAVOLUMES% basepath_logvolumes = %BASEPATH_LOGVOLUMES% use_mountpoints = %USE_MOUNTPOINTS% basepath_shared = %BASEPATH_SHARED% [storage] ha_provider = gceStorageClient ha_provider_path = %STORAGE_CONNECTOR_PATH% # # Example configuration for 2+1 setup # # partition_1_*__pd = node-mnt00001 # partition_2_*__pd = node-mnt00002 # partition_3_*__pd = node-mnt00003 # partition_*_data__dev = /dev/hana/data # partition_*_log__dev = /dev/hana/log # partition_*_*__gcloudAccount = svc-acct-name@project-id. # partition_*_data__mountOptions = -t xfs -o logbsize=256k # partition_*_log__mountOptions = -t xfs -o logbsize=256k # partition_*_*__fencing = disabled [trace] ha_gcestorageclient = info
Sudo-Zugriff für den Speichermanager für SAP HANA
Zur Verwaltung von SAP HANA-Diensten und -Speicher verwendet der Speichermanager für SAP HANA das Nutzerkonto SID_LCadm und benötigt Sudo-Zugriff auf bestimmte Systembinärdateien.
Wenn Sie die von Google Cloud bereitgestellten Automatisierungsskripts zum Bereitstellen von SAP HANA mit automatischem Host-Failover verwenden, wird der erforderliche Sudo-Zugriff für Sie konfiguriert.
Wenn Sie den Speichermanager für SAP HANA manuell installieren, verwenden Sie den Befehl visudo, um die Datei /etc/sudoers zu bearbeiten und dem Nutzerkonto SID_LCadm Sudo-Zugriff auf die folgenden erforderlichen Binärdateien zu gewähren.
Klicken Sie auf den Tab für Ihr Betriebssystem:
RHEL
/bin/kill /bin/mount /bin/umount /sbin/dmsetup /sbin/lvdisplay /sbin/lvscan /sbin/pvscan /sbin/vgchange /sbin/vgscan /usr/bin/gcloud /usr/bin/lsof /usr/bin/mkdir /usr/bin/sg_persist /usr/bin/systemctl /usr/sbin/lsof /usr/sbin/xfs_repair
SLES
/bin/kill /bin/mount /bin/umount /sbin/dmsetup /sbin/lvdisplay /sbin/lvscan /sbin/pvscan /sbin/vgchange /sbin/vgscan /sbin/xfs_repair /usr/bin/gcloud /usr/bin/lsof /usr/bin/mkdir /usr/bin/sg_persist /usr/bin/systemctl /usr/sbin/lsof
Das folgende Beispiel zeigt einen Eintrag in der Datei /etc/sudoers. Im Beispiel wird die System-ID des zugehörigen SAP HANA-Systems durch SID_LC ersetzt. Der Beispieleintrag wurde von der Terraform-Konfiguration erstellt, die von Google Cloud für die horizontale Skalierung von SAP HANA mit automatischem Host-Failover bereitgestellt wird. Google Cloud
Der von der Terraform-Konfiguration erstellte Eintrag enthält Binärdateien, die nicht mehr benötigt, aber für die Abwärtskompatibilität beibehalten werden. Sie müssen nur die Binärdateien aufnehmen, die in der vorherigen Liste aufgeführt sind.
SID_LCadm ALL=NOPASSWD: /sbin/multipath,/sbin/multipathd,/etc/init.d/multipathd,/usr/bin/sg_persist,/bin/mount,/bin/umount,/bin/kill,/usr/bin/lsof,/usr/bin/systemctl,/usr/sbin/lsof,/usr/sbin/xfs_repair,/sbin/xfs_repair,/usr/bin/mkdir,/sbin/vgscan,/sbin/pvscan,/sbin/lvscan,/sbin/vgchange,/sbin/lvdisplay,/usr/bin/gcloud,/sbin/dmsetup
Dienstkonto für den Speichermanager für SAP HANA konfigurieren
Wenn Sie das automatische Host-Failover für Ihr SAP HANA-System mit horizontaler Skalierung auf Google Cloudaktivieren möchten, benötigt der Speichermanager für SAP HANA ein Dienstkonto. Sie können ein spezielles Dienstkonto erstellen und ihm die erforderlichen Berechtigungen zum Ausführen von Aktionen auf Ihren SAP HANA-VMs erteilen, z. B. zum Trennen und Anschließen von Laufwerken während eines Failovers. Informationen zum Erstellen eines Dienstkontos finden Sie unter Dienstkonto erstellen.
Erforderliche IAM-Berechtigungen
Für das Dienstkonto, das vom Speichermanager für SAP HANA verwendet wird, müssen Sie eine Rolle mit den folgenden IAM-Berechtigungen gewähren:
Wenn Sie eine VM-Instanz mit dem Befehl
gcloud compute instances resetzurücksetzen möchten, gewähren Sie die Berechtigungcompute.instances.reset.Wenn Sie mit dem Befehl
gcloud compute disks describeInformationen zu einem Persistent Disk- oder Hyperdisk-Volume abrufen möchten, gewähren Sie die Berechtigungcompute.disks.get.Wenn Sie ein Laufwerk mit dem Befehl
gcloud compute instances attach-diskan eine VM-Instanz anhängen möchten, gewähren Sie die Berechtigungcompute.instances.attachDisk.Wenn Sie ein Laufwerk mit dem Befehl
gcloud compute instances detach-diskvon einer VM-Instanz trennen möchten, gewähren Sie die Berechtigungcompute.instances.detachDisk.Wenn Sie VM-Instanzen mit dem Befehl
gcloud compute instances listauflisten möchten, gewähren Sie die Berechtigungcompute.instances.list.Wenn Sie die Persistent Disk- oder Hyperdisk-Volumes mit dem Befehl
gcloud compute disks listauflisten möchten, gewähren Sie die Berechtigungcompute.disks.list.
Sie können die erforderlichen Berechtigungen über benutzerdefinierte Rollen oder andere vordefinierte Rollen gewähren.
Legen Sie außerdem den Zugriffsbereich der VM auf cloud-platform fest, damit die IAM-Berechtigungen der VM vollständig durch die IAM-Rollen bestimmt werden, die Sie dem Dienstkonto zuweisen.
Standardmäßig verwendet der Speichermanager für SAP HANA das aktive Dienstkonto oder Nutzerkonto, das die gcloud CLI auf den Hosts im skalierbaren SAP HANA-System verwenden darf.
Mit dem folgenden Befehl können Sie das aktive Konto prüfen, das vom Speichermanager für SAP HANA verwendet wird:
gcloud auth list
Weitere Informationen zu diesem Befehl finden Sie unter gcloud auth list.
So ändern Sie das Konto, das vom Speichermanager für SAP HANA verwendet wird:
Achten Sie darauf, dass das Dienstkonto auf jedem der Hosts im SAP HANA-System mit horizontaler Skalierung verfügbar ist:
gcloud auth listAktualisieren Sie in der Datei
global.iniden Abschnitt[storage]mit dem Dienstkonto:[storage] ha_provider = gceStorageClient ... partition_*_*__gcloudAccount = SERVICE_ACCOUNTErsetzen Sie
SERVICE_ACCOUNTdurch den Namen des Dienstkontos im E-Mail-Adressformat, das vom Speichermanager für SAP HANA verwendet wird. Dieses Dienstkonto wird verwendet, wenngcloud-Befehle vom Speichermanager für SAP HANA ausgeführt werden.
NFS-Speicher für den automatischen SAP HANA-Host-Failover
Ein SAP HANA-System mit horizontaler Skalierung und automatischem Host-Failover erfordert eine NFS-Lösung wie Filestore, um die Volumes /hana/shared und /hanabackup für alle Hosts freizugeben. Sie müssen die NFS-Lösung selbst einrichten.
Wenn Sie eine automatisierte Bereitstellungsmethode verwenden, geben Sie in der Bereitstellungsdatei Informationen zum NFS-Server an, um während der Bereitstellung die NFS-Verzeichnisse bereitzustellen.
Das von Ihnen verwendete NFS-Volume muss leer sein. Vorhandene Dateien können einen Konflikt mit dem Bereitstellungsprozess verursachen, insbesondere wenn die Dateien oder Ordner auf die SAP-System-ID (SID) verweisen. Der Bereitstellungsprozess kann nicht feststellen, ob die Dateien überschrieben werden können.
Der Bereitstellungsprozess speichert die Volumes /hana/shared und /hanabackup auf dem NFS-Server und stellt den NFS-Server auf allen Hosts bereit, einschließlich der Standby-Hosts. Der Master-Host verwaltet dann den NFS-Server.
Wenn Sie eine Sicherungslösung implementieren, z. B. den Cloud Storage Backint-Agent für SAP HANA, können Sie das Volume /hanabackup nach Abschluss der Bereitstellung vom NFS-Server entfernen.
Weitere Informationen zu den Lösungen für freigegebene Dateien, die in Google Cloudverfügbar sind, finden Sie unter Dateifreigabelösungen für SAP in Google Cloud.
Betriebssystemunterstützung
Google Cloud unterstützt den automatischen SAP HANA-Host-Failover nur auf den folgenden Betriebssystemen:
- RHEL für SAP 7.7 oder höher
- RHEL für SAP 8.1 oder höher
- RHEL für SAP 9.0 oder höher
-
Bevor Sie SAP-Software unter RHEL für SAP 9.x installieren, müssen Sie zusätzliche Pakete auf Ihren Hostcomputern installieren, insbesondere
chkconfigundcompat-openssl11. Wenn Sie ein von Compute Engine bereitgestelltes Image verwenden, werden diese Pakete automatisch für Sie installiert. Weitere Informationen von SAP finden Sie im SAP-Hinweis 3108316 – Red Hat Enterprise Linux 9.x: Installation und Konfiguration.
-
Bevor Sie SAP-Software unter RHEL für SAP 9.x installieren, müssen Sie zusätzliche Pakete auf Ihren Hostcomputern installieren, insbesondere
- SLES für SAP 12 SP5
- SLES für SAP 15 SP1 oder höher
Welche öffentlichen Images über Compute Engine zur Verfügung stehen, erfahren Sie unter Images.
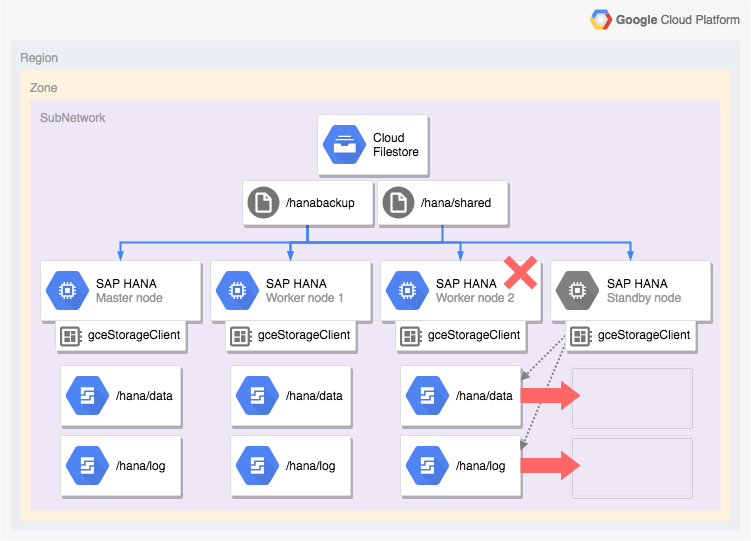
Architektur eines SAP HANA-Systems mit automatischem Host-Failover
Das folgende Diagramm zeigt eine horizontal skalierte Architektur in Google Cloud , die das SAP HANA-Host-Failover-Feature enthält. Im Diagramm wird der Speichermanager für SAP HANA durch den Namen der ausführbaren Datei gceStorageClient dargestellt.
Das Diagramm zeigt, dass Worker-Knoten 2 fehlschlägt und der Standby-Knoten übernimmt.
Der Speichermanager für SAP HANA arbeitet mit der SAP Storage Connector API (nicht gezeigt), um die Laufwerke zu trennen, die die Volumes /hana/data und /hana/logs vom ausgefallenen Worker-Knoten enthalten. Stellen Sie sie auf dem Standby-Knoten noch einmal bereit, der dann zu Worker-Knoten 2 wird, während der ausgefallene Knoten zum Standby-Knoten wird.
Bereitstellungsoptionen für SAP HANA-Hochverfügbarkeitskonfigurationen
Google Cloud bietet Terraform-Konfigurationen, mit denen Sie die Bereitstellung von SAP HANA-HA-Systemen automatisieren oder Ihre SAP HANA-HA-Systeme manuell bereitstellen und konfigurieren können.
Google Cloud bietet bereitgestellte Terraform-Konfigurationsdateien. Sie initialisieren mit Ihrem Terraform-Standardbefehl Ihr aktuelles Arbeitsverzeichnis, laden das Terraform-Plug-in und die Moduldateien für Google Cloudherunter und wenden die Konfiguration zum Bereitstellen eines SAP HANA-Systems an.
Mit dieser automatisierten Bereitstellungsmethode wird ein SAP HANA-System bereitgestellt, das von SAP vollständig unterstützt wird und die Best Practices von SAP sowie vonGoogle Cloudberücksichtigt.
Automatisierte Bereitstellung von Linux-Hochverfügbarkeitsclustern für SAP HANA
Für SAP HANA stellt die automatisierte Bereitstellungsmethode einen leistungsoptimierten Linux-Hochverfügbarkeitscluster bereit, der Folgendes beinhaltet:
- Automatisches Failover.
- Automatischer Neustart.
- Eine Reservierung der von Ihnen angegebenen virtuellen IP-Adresse (VIP).
- Failover-Unterstützung durch internes TCP/UDP-Load-Balancing, das das Routing von der virtuellen IP-Adresse (VIP) zu den Knoten des HA-Clusters verwaltet
- Eine Firewallregel, mit der Compute Engine-Systemdiagnosen die VM-Instanzen im Cluster überwachen können.
- Hochverfügbarkeitsclusterressourcen-Manager von Pacemaker
- Ein Google Cloud Fencing-Mechanismus.
- VM mit den erforderlichen nichtflüchtigen Speichern für jede SAP HANA-Instanz.
- Optional: Knoten für einzelne Mandanten
- SAP HANA-Instanzen, die für die synchrone Replikation und Vorabladung von Arbeitsspeicher konfiguriert wurden.
Informationen zum Automatisieren der Bereitstellung eines Hochverfügbarkeitsclusters für SAP HANA mit Terraform finden Sie hier:
- Terraform: Konfigurationsleitfaden für SAP HANA-Hochverfügbarkeitscluster mit vertikaler Skalierung
- Terraform: Konfigurationsanleitung für SAP HANA-Hochverfügbarkeitscluster mit horizontaler Skalierung
Automatisierte Bereitstellung von SAP HANA-Systemen mit horizontaler Skalierung und automatischem SAP HANA-Host-Failover
Sie können Terraform verwenden, um die Bereitstellung eines Systems mit horizontaler Skalierung und Standby-Hosts zu automatisieren. Weitere Informationen finden Sie unter Terraform: Bereitstellungsanleitung für SAP HANA-Systeme mit horizontaler Skalierung und automatischem Host-Failover.
Bei einem SAP HANA-System mit horizontaler Skalierung, das das Feature für automatischen Failover des SAP HANA-Hosts enthält, wird mit der von Google Cloud bereitgestellten Terraform-Konfiguration Folgendes bereitgestellt:
- Eine SAP HANA-Master-Instanz
- 1 bis 15 Worker-Hosts
- 1 bis 3 Standby-Hosts
- Eine VM für jeden SAP HANA-Host
- SSD-basierte Persistent Disk- oder Hyperdisk-Volumes für den Master- und die Worker-Hosts
- Der Google Cloud Speichermanager für SAP HANA-Standby-Knoten
Ein SAP HANA-System mit horizontaler Skalierung und automatischem Host-Failover erfordert eine NFS-Lösung wie Filestore, um die Volumes /hana/shared und /hanabackup für alle Hosts freizugeben. Damit Terraform während der Bereitstellung auch die NFS-Verzeichnisse bereitstellen kann, müssen Sie selbst die NFS-Lösung einrichten, bevor Sie das SAP HANA-System bereitstellen.
Sie können Filestore-NFS-Serverinstanzen schnell anhand der Anleitung unter Instanzen erstellen einrichten.
Option „Aktiv/Aktiv (Lesezugriff aktiviert)“ für SAP HANA
Ab SAP HANA 2.0 SPS1 bietet SAP die Konfiguration Aktiv/Aktiv (Lesezugriff aktiviert) für SAP HANA-Systemreplikationsszenarien an. In einem Replikationssystem, das für Aktiv/Aktiv (Lesezugriff aktiviert) konfiguriert ist, sind die SQL-Ports auf dem sekundären System für den Lesezugriff geöffnet. So können Sie das sekundäre System für Lese-intensiveaufgaben verwenden und die Arbeitslasten über die Rechenressourcen hinweg besser ausbalancieren, sodass die Gesamtleistung Ihrer SAP HANA-Datenbank verbessert wird. Weitere Informationen zur Funktion „Aktiv/Aktiv (Lesen aktiviert)“ finden Sie im Administratorhandbuch für SAP HANA, das für Ihre SAP HANA-Version spezifisch ist, und in SAP-Hinweis 1999880.
Wenn Sie eine Systemreplikation konfigurieren möchten, die den Lesezugriff auf das sekundäre System ermöglicht, müssen Sie den Betriebsmodus logreplay_readaccess verwenden. Um diesen Vorgangsmodus verwenden zu können, müssen Ihre primären und sekundären Systeme dieselbe SAP HANA-Version ausführen. Daher ist der schreibgeschützte Zugriff auf das sekundäre System während eines Rolling Upgrade erst möglich, wenn beide Systeme dieselbe SAP HANA-Version ausführen.
Zum Herstellen einer Verbindung zu einem sekundären Aktiv/Aktiv-System mit Lesezugriff unterstützt SAP folgende Optionen:
- Um eine direkte Verbindung herzustellen öffnen Sie eine explizite Verbindung zum sekundären System.
- Um eine indirekte Verbindung herzustellen führen Sie eine SQL-Anweisung auf dem primären System mit einem Hinweis aus, der die Anfrage nach der Auswertung zum sekundäre System umleitet.
Das folgende Diagramm zeigt die erste Option, bei der Anwendungen direkt in einem in Google Cloud bereitgestellten Pacemaker-Cluster auf das sekundäre System zugreifen. Eine zusätzliche Floating- oder virtuelle IP-Adresse (VIP) wird für die VM-Instanz verwendet, die als Teil des SAP HANA Pacemaker-Clusters als sekundäres System bereitgestellt wird. Die VIP folgt dem sekundären System und kann die Leselast bei einem unerwarteten Ausfall oder einer geplanten Wartung von einem Clusterknoten zu einem anderen verschieben. Informationen zu den verfügbaren Methoden zur Implementierung virtueller IP-Adressen finden Sie unter Implementierung virtueller IP-Adressen in Google Cloud.

Eine Anleitung zum Konfigurieren der SAP HANA-Systemreplikation mit Aktiv/Aktiv- (Lesezugriff aktiviert) in einem Pacemaker-Cluster:
- HANA Aktiv/Aktiv (Lesezugriff aktiviert) in einem SUSE Pacemaker-Cluster konfigurieren
- HANA Aktiv/Aktiv (Lesezugriff aktiviert) in einem Red Hat Pacemaker-Cluster konfigurieren
Nächste Schritte
Sowohl Google Cloud als auch SAP bieten weitere Informationen zur Hochverfügbarkeit.
Google Cloud Weitere Informationen zur Hochverfügbarkeit
Weitere Informationen zur Hochverfügbarkeit für SAP HANA in Google Cloudfinden Sie im Betriebsleitfaden für SAP HANA.
Allgemeine Informationen zum Schutz von Systemen in Google Cloudvor verschiedenen Ausfallszenarien finden Sie unter Robuste Systeme konzipieren.
Weitere Informationen von SAP zu SAP HANA-Hochverfügbarkeitsfeatures
Weitere Informationen von SAP zu SAP HANA-Hochverfügbarkeitsfeatures finden Sie in den folgenden Dokumenten:
- Hochverfügbarkeit für SAP HANA
- SAP-Hinweis 2057595 – FAQ: Hochverfügbarkeit für SAP HANA
- Systemreplikation für SAP HANA 2.0 durchführen
- Netzwerkempfehlungen für SAP HANA Systemreplikation