この記事は、Google Cloud で AI Platform(AI Platform)を使用してお客様のライフタイム バリュー(CLV)を予測する方法を説明した 4 つのパートからなるシリーズのパート 4 です。この記事では、AutoML テーブルを使用して予測を行う方法を説明します。
このシリーズの記事は次のとおりです。
- パート 1: はじめに。CLV の概要と、CLV 予測の 2 つのモデリング手法について説明します。
- パート 2: モデルのトレーニング。データを準備し、モデルをトレーニングする方法について説明します。
- パート 3: 本番環境へのデプロイ。パート 2 で説明したモデルを本番環境システムにデプロイする方法について説明します。
- パート 4: AutoML Tables の使用(この記事)。 AutoML Tables を使用してモデルをビルドおよびデプロイする方法を説明します。
この記事で説明するプロセスは、シリーズのパート 2 で説明された BigQuery のデータ処理手順を前提とします。この記事では、その BigQuery データセットを AutoML Tables にアップロードしてモデルを作成する方法について説明します。この記事では、パート 3 で説明した本番環境のシステムに AutoML モデルを統合する方法も紹介します。
このシステムを実装するコードは、元のシリーズと同じ GitHub リポジトリに配置されていす。この記事では、そのリポジトリ内の AutoML Tables のコードの使い方について説明します。
AutoML Tables のメリット
シリーズのこれまでの部分では、TensorFlow に実装された統計モデルと DNN モデルの両方を使用して CLV を予測する方法を確認しました。AutoML Tables には、他の 2 つの方法に比べて次のようなメリットがあります。
- モデルを作成のためのコーディングが不要です。データセットとモデルの作成、トレーニング、管理、デプロイが可能なコンソール UI があります。
- 機能の追加や変更が容易であり、コンソール インターフェースから直接行うことができます。
- ハイパーパラメータの調整などのトレーニング プロセスが自動化されています。
- データセットに最適なアーキテクチャが AutoML Tables によって検索されるため、多数の選択可能なオプションからの選択から解放されます。
- AutoML Tables には、特徴の重要性などのトレーニング済みモデルのパフォーマンスの詳細な分析があります。
このため、AutoML Tables を使用して完全に最適化されたモデルを開発してトレーニングするための時間と費用を削減できます。
AutoML Tables ソリューションの本番環境デプロイでは、モデルの作成とデプロイ、および予測実行に Python クライアント API を使用する必要があります。この記事では、クライアント API を使用して AutoML Tables モデルを作成およびトレーニングする方法について説明します。AutoML Tables のコンソールを使用してこれらの手順を実行する方法については、AutoML Tables のドキュメントをご覧ください。
コードのインストール
元のシリーズのコードがまだインストールされていない場合は、元のシリーズのパート 2 で説明した手順でコードをインストールしてください。GitHub リポジトリの README ファイルには、環境の準備、コードのインストール、およびプロジェクト内での AutoML Tables の設定に必要なすべての手順が記載されています。
すでにコードをインストールしている場合は、追加の手順を実行して、この記事のインストールを完了させます。
- プロジェクトで、AutoML Tables API を有効にします。
- すでにインストールされている Miniconda 環境をアクティブにします。
- AutoML Tables のドキュメントの説明に従って、Python クライアント ライブラリをインストールします。
- API キーファイルを作成してからダウンロードし、後でクライアント ライブラリで使用できるように既知の場所に保存します。
コードの実行
この記事の手順の多くで、Python コマンドを実行します。環境を準備してコードをインストールした後は、次のいずれかの方法でコードを実行できます。
Jupyter のノートブックでコードを実行します。アクティブにした Miniconda 環境のターミナル ウィンドウで、以下のコマンドを実行します。
$ (clv) jupyter notebookこの記事の各手順のコードは、
notebooks/clv_automl.ipynbという名前のコード リポジトリ内のノートブックにあります。Jupyter インターフェース上でこのノートブックを開きます。開くと、チュートリアルに従って各手順を実行できます。Python スクリプトとしてコードを実行します。このチュートリアルのコードステップは、
clv_automl/clv_automl.pyファイルのコード リポジトリにあります。このスクリプトでは、プロジェクト ID、API キーファイルのロケーション、Google Cloud リージョン、BigQuery データセットの名前などの構成可能なパラメータの引数がコマンドラインで指定されます。スクリプトは、アクティブにした Miniconda 環境のターミナル ウィンドウから実行します。その際に、[YOUR_PROJECT]は Google Cloud プロジェクト名に置き換えます。$ (clv) cd clv_automl $ (clv) python clv_automl.py --project_id [YOUR_PROJECT]
パラメータとデフォルト値の全リストについては、スクリプト内の
create_parserメソッドを参照するか、引数を指定せずにスクリプトを実行して使用方法のドキュメントを確認します。README で説明したように、Cloud Composer 環境をインストールした後、DAG を実行するで後述するように DAG を実行してコードを実行します。
データの準備
この記事では、元のシリーズのパート 2 で説明されている BigQuery のデータセットとデータ準備の手順を使用します。その記事の説明に従ってデータの集約が完了したら、AutoML Tables で使用するデータセットを作成する準備が整います。
AutoML Tables データセットの作成
まず、BigQuery で準備したデータを AutoML Tables にアップロードします。
クライアントを初期化するには、キーファイル名をインストール手順でダウンロードしたファイルの名前に設定します。
keyfile_name = "mykey.json" client = automl_v1beta1.AutoMlClient.from_service_account_file(keyfile_name)データセットを作成します。
create_dataset_response = client.create_dataset( location_path, {'display_name': dataset_display_name, 'tables_dataset_metadata': {}}) dataset_name = create_dataset_response.name
BigQuery からのデータのインポート
データセットを作成したら、BigQuery からデータをインポートできます。
BigQuery から AutoML Tables データセットにデータをインポートします。
dataset_bq_input_uri = 'bq://{}.{}.{}'.format(args.project_id, args.bq_dataset, args.bq_table) input_config = { 'bigquery_source': { 'input_uri': dataset_bq_input_uri}} import_data_response = client.import_data(dataset_name, input_config)
モデルのトレーニング
CLV データ用の AutoML データセットを作成したら、AutoML Tables モデルを作成できます。
データセットの列ごとに AutoML Tables 列の仕様を取得します。
list_table_specs_response = client.list_table_specs(dataset_name) table_specs = [s for s in list_table_specs_response] table_spec_name = table_specs[0].name list_column_specs_response = client.list_column_specs(table_spec_name) column_specs = {s.display_name: s for s in list_column_specs_response}この列の仕様は後の手順で使用します。
AutoML Tables モデルのラベルとして列の 1 つを割り当てます。
TARGET_LABEL = 'target_monetary' ... label_column_name = TARGET_LABEL label_column_spec = column_specs[label_column_name] label_column_id = label_column_spec.name.rsplit('/', 1)[-1] update_dataset_dict = { 'name': dataset_name, 'tables_dataset_metadata': { 'target_column_spec_id': label_column_id } } update_dataset_response = client.update_dataset(update_dataset_dict)このコードは、パート 2 の TensorFlow DNN モデルと同じラベル列(
target_monetary)を使用しています。モデルをトレーニングするための特徴を定義します。
feat_list = list(column_specs.keys()) feat_list.remove('target_monetary') feat_list.remove('customer_id') feat_list.remove('monetary_btyd') feat_list.remove('frequency_btyd') feat_list.remove('frequency_btyd_clipped') feat_list.remove('monetary_btyd_clipped') feat_list.remove('target_monetary_clipped')AutoML Tables モデルのトレーニングに使用される特徴は、元のシリーズのパート 2 で TensorFlow DNN モデルの学習に使用されるものと同じです。ただし、AutoML Tables を使用すると、モデルへの特徴の追加や削除がはるかに容易になります。BigQuery で特徴を作成した後は、前述のコード スニペットのように明示的に削除しない限り、その特徴が自動的にモデルに含められます。
モデルを作成するためのオプションを定義します。このデータセットには、パラメータ
MINIMIZE_MAEで表される平均絶対誤差を最小化するという最適化目標をおすすめします。model_display_name = args.automl_model model_training_budget = args.training_budget * 1000 model_dict = { 'display_name': model_display_name, 'dataset_id': dataset_name.rsplit('/', 1)[-1], 'tables_model_metadata': { 'target_column_spec': column_specs['target_monetary'], 'input_feature_column_specs': [ column_specs[x] for x in feat_list], 'train_budget_milli_node_hours': model_training_budget, 'optimization_objective': 'MINIMIZE_MAE' } }詳細については、最適化目標に関する AutoML Tables のドキュメントをご覧ください。
モデルを作成してトレーニングを開始します。
create_model_response = client.create_model(location_path, model_dict) create_model_result = create_model_response.result() model_name = create_model_result.nameクライアント呼び出し(
create_model_response)からの戻り値がすぐに返されます。値create_model_response.result()は、Promise です。トレーニングが完了するまでブロックされます。model_name値は、モデルで動作するクライアント呼び出しに必要なリソースパスです。
モデルの評価
モデルのトレーニングが完了したら、モデル評価の統計情報を取得できます。Google Cloud Console またはクライアント API を使用できます。
コンソールを使用するには、AutoML Tables コンソールで [評価] タブに移動します。
![AutoML Tables コンソールの [評価] タブ](https://cloud.google.com/static/architecture/images/clv-prediction-with-automl-tables-screenshot-eval-tab.png?hl=ja)
このクライアント API を使用するには、モデル評価の統計情報を取得します。
model_evaluations = [e for e in client.list_model_evaluations(model_name)] model_evaluation = model_evaluations[0]次のような出力が表示されます。
name: "projects/595920091534/locations/us-central1/models/TBL3912308662231629824/modelEvaluations/9140437057533851929" create_time { seconds: 1553108019 nanos: 804478000 } evaluated_example_count: 125 regression_evaluation_metrics: { mean_absolute_error: 591.091 root_mean_squared_error: 853.481 mean_absolute_percentage_error: 21.47 r_squared: 0.907 }
二乗平均平方根誤差 853.481 は、元のシリーズで使用されている確率モデルおよび TensorFlow モデルと比較して優れていると言えます。ただし、パート 2 で説明したように、提供されている各手法を自分のデータで試して、どれが最も効果的かを確認することをおすすめします。
AutoML モデルのデプロイ
元のシリーズの Cloud Composer DAG は更新され、トレーニングと予測の両方に AutoML Tables モデルが組み込まれました。Cloud Composer DAG の機能に関する一般的な情報については、元の記事のパート 3 のソリューションの自動化に関するセクションをご覧ください。
README の指示に従って、このソリューション用の Cloud Composer オーケストレーション システムをインストールできます。
更新された DAG は、前に示したクライアント コード呼び出しを複製する clv_automl/clv_automl.py スクリプトのメソッドを呼び出して、モデルを作成し予測を実行します。
トレーニング DAG
トレーニング用に更新された DAG には、AutoML Tables モデルを作成するためのタスクが含まれています。次の図は、トレーニング用の新しい DAG を示しています。

予測 DAG
予測用に更新された DAG には、AutoML Tables モデルを使用してバッチ予測を実行するタスクが含まれています。次の図は、予測用の新しい DAG を示しています。
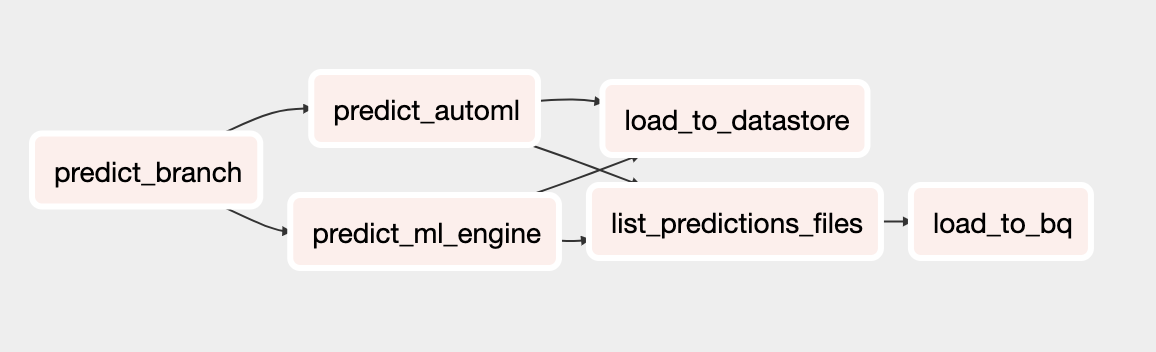
DAG の実行
DAG を手動でトリガーするには、Cloud Shell の README ファイルの DAG の実行のセクションからコマンドを実行するか、または Google Cloud CLI を使用します。
build_train_deployDAG を実行するには:gcloud composer environments run ${COMPOSER_NAME} \ --project ${PROJECT} \ --location ${REGION} \ dags trigger \ -- \ build_train_deploy \ --conf '{"model_type":"automl", "project":"'${PROJECT}'", "dataset":"'${DATASET_NAME}'", "threshold_date":"2011-08-08", "predict_end":"2011-12-12", "model_name":"automl_airflow", "model_version":"v1", "max_monetary":"15000"}'predict_serveDAG を実行するには:gcloud composer environments run ${COMPOSER_NAME} \ --project ${PROJECT} \ --location ${REGION} \ dags trigger \ -- \ predict_serve \ --conf '{"model_name":"automl_airflow", "model_version":"v1", "dataset":"'${DATASET_NAME}'"}'
次のステップ
- 完全な CLV チュートリアル セットを確認する。
- GitHub リポジトリで完全な例を実行する。
- 他の予測ソリューションについて学習する。
- Google Cloud に関するリファレンス アーキテクチャ、図、チュートリアル、ベスト プラクティスを確認する。Cloud Architecture Center を確認します。