このドキュメントは、データスキュー検知のために、AI Platform Prediction にデプロイされている機械学習(ML)モデルをモニタリングする方法を説明するシリーズの 2 番目のパートです。このガイドでは、AI Platform Prediction のリクエスト / レスポンスログ内の未加工データを解析し、分析データモデルに変換する方法を説明します。次に、Looker Studio を使用して、データスキューとデータ ドリフトの検知のために、ログに記録されたリクエストを分析する方法を説明します。
このシリーズは、サービング データが時間の経過とともにどのように変化するかをモニタリングすることにより、本番環境で ML モデルのパフォーマンスを維持したいデータ サイエンティストと MLOps エンジニアを対象としています。このドキュメントは、Google Cloud、BigQuery、Jupyter ノートブックの使用経験があることを前提としています。
このシリーズは、次のガイドで構成されています。
- AI Platform Prediction を使用したサービング リクエストのロギング
- BigQuery でのログの分析(このドキュメント)
- TensorFlow Data Validation によるトレーニング / サーバー スキューの分析
- トレーニング / サーバー スキュー検知の自動化
- 特異点検知によるトレーニング / サーバー スキューの特定
このドキュメントで説明するタスクは、Jupyter ノートブックに組み込まれています。ノートブックは GitHub リポジトリにあります。
概要
このシリーズのパート 1 で説明したように、Jupyter ノートブックのこのコードは、地図に関する変数から森林被覆の種類を予測するため、Covertype データセットの Keras 分類モデルをトレーニングします。エクスポートされた SavedModel は、オンライン サービス用に、AI Platform Prediction にデプロイされます。ノートブックはまた、リクエスト / レスポンス ロギングで、オンライン予測リクエスト(インスタンス)とレスポンス(予測ラベル確率)のサンプルのログを BigQuery テーブルに記録できるようにします。
次の図はアーキテクチャ全体を示したものです。

このアーキテクチャでは、AI Platform Prediction のリクエスト / レスポンス ロギングにより、オンライン リクエストのサンプルのログが BigQuery テーブルに記録されます。未加工のインスタンスと予測データが BigQuery に保存されると、このデータを解析して、記述統計を計算し、データスキューとデータドリフトを可視化できます。
次の表は BigQuery テーブルのスキーマをまとめたものです。
| フィールド名 | 型 | モード | 説明 |
|---|---|---|---|
model |
STRING |
REQUIRED |
モデルの名前 |
model_version |
STRING |
REQUIRED |
モデル バージョンの名前 |
time |
TIMESTAMP |
REQUIRED |
リクエストが取り込まれた日時 |
raw_data |
STRING |
REQUIRED |
AI Platform Prediction の JSON 表現のリクエストの本文 |
raw_prediction |
STRING |
NULLABLE |
AI Platform Prediction の JSON 表現のレスポンスの本文(予測) |
groundtruth |
STRING |
NULLABLE |
グラウンド トゥルース(利用可能な場合) |
次の表は、BigQuery テーブルの raw_data 列と raw_prediction 列に保存されているデータのサンプルを示したものです。
| 列 | サンプルデータ |
|---|---|
raw_data |
{
"signature_name":"serving_default",
"instances":[
{
"Elevation":[3158],
"Aspect":[78],
"Slope":[25],
"Horizontal_Distance_To_Hydrology":[150],
"Vertical_Distance_To_Hydrology":[53],
"Horizontal_Distance_To_Roadways":[1080],
"Hillshade_9am":[243],
"Hillshade_Noon":[185],
"Hillshade_3pm":[57],
"Horizontal_Distance_To_Fire_Points":[2234],
"Wilderness_Area":["Rawah"],
"Soil_Type":["7745"],
}
]
}
|
raw_prediction |
{
"predictions": [
{
"probabilities": [
0.03593460097908974,
0.9640452861785889,
1.2815438710234162e-9,
1.5712469103590365e-9,
0.000018715836631599814,
4.030006106603423e-9,
0.0000013792159734293818
],
"confidence": 0.9640452861785889,
"predicted_label": "1"
}
]
} |
このドキュメントでは、各特徴量のコンテンツを個別に分析して、データスキューを特定するため、raw_data フィールドを解析して分析モデルに変換します。
目標
- データセットのメタデータを作成する。
- データセットに固有の SQL
CREATE VIEWステートメントを生成する。 - ビューを使用して、BigQuery のログデータをクエリする。
- ログデータの可視化する。
費用
このドキュメントでは、Google Cloud の次の課金対象のコンポーネントを使用します。
料金計算ツールを使うと、予想使用量に基づいて費用の見積もりを生成できます。
始める前に
始める前に、このシリーズのパート 1 を完了している必要があります。
パート 1 を完了すると、以下が使用できるようになります。
- TensorFlow 2.3 を使用する Vertex AI Workbench ユーザー管理ノートブック インスタンス。
- このガイドで必要な Jupyter ノートブックを含む GitHub リポジトリのクローン。
このシナリオの Jupyter ノートブック
データを解析および分析するタスクは、GitHub リポジトリの Jupyter ノートブックに組み込まれています。タスクを実施するには、ノートブックを入手し、ノートブック内のコードセルを順番に実行します。
このドキュメントでは、Jupyter ノートブックを使用して次のタスクを行います。
- 未加工のリクエスト / レスポンス データポイントを解析する BigQuery SQL ビューを作成します。指定したデータセットと名前のメタデータなどの情報を集めるコードを実行して、ビューを作成します。
- 人工的なスキューを使用して、数日間にわたるサービング データの変化をシミュレートします。
- Looker Studio を使用して、BigQuery に記録されるように解析されたサービング データを可視化します。
ノートブック設定の構成
ノートブックのこのセクションでは、このシナリオのコードを実行する Python 環境を準備します。ノートブックのコードは、データセットの特徴仕様に基づいてビューを作成します。CREATE OR REPLACE VIEW SQL スクリプトを生成するには、いくつかの変数を設定する必要があります。
パート 1 の Vertex AI Workbench のユーザー管理のノートブック インスタンスをまだ開いていない場合は、次の操作を行います。
Google Cloud コンソールで [Notebooks] ページに移動します。
[ユーザー管理のノートブック] タブでノートブックを選択し、[JupyterLab を開く] をクリックします。ブラウザで JupyterLab 環境が開きます。
ファイル ブラウザで
mlops-on-gcpを開き、次にskew-detection1ディレクトリに移動します。
02-covertype-logs-parsing-analysis.ipynbノートブックを開きます。ノートブックの [Setup] で、[Install packages and dependencies] セルを実行して、必要な Python パッケージをインストールし、環境変数を構成します。
[Configure Google Cloud environment settings] で、次の変数を設定します。
PROJECT_ID: リクエスト / レスポンス データの BigQuery データセットがロギングされる Google Cloud プロジェクトの ID。BQ_DATASET_NAME: リクエスト / レスポンス ログを格納する BigQuery データセットの名前。BQ_TABLE_NAME: リクエスト / レスポンスログを保存する BigQuery テーブルの名前。MODEL_NAME: AI Platform Prediction にデプロイされたモデルの名前。VERSION_NAME: AI Platform Prediction にデプロイされたモデルのバージョン名。バージョンは vN という形式です(例:v1)。
[Setup] の残りのセルを実行して、環境の構成を完了します。
- GCP アカウントを認証する
- ライブラリをインポートする
データセットのメタデータの定義
ノートブックのセクション 1 のDefine dataset metadataを実行して、後で SQL スクリプトを生成するコードで使われる変数を設定します。たとえば、このセクションのコードは、コードの次のスニペットに示すように、NUMERIC_FEATURE_NAMES と CATEGORICAL_FEATURES_WITH_VOCABULARY という名前の 2 つの変数を作成します。
NUMERIC_FEATURE_NAMES = ['Aspect', 'Elevation', 'Hillshade_3pm',
'Hillshade_9am', 'Hillshade_Noon',
'Horizontal_Distance_To_Fire_Points',
'Horizontal_Distance_To_Hydrology',
'Horizontal_Distance_To_Roadways','Slope',
'Vertical_Distance_To_Hydrology']
CATEGORICAL_FEATURES_WITH_VOCABULARY = {
'Soil_Type': ['2702', '2703', '2704', '2705', '2706', '2717', '3501', '3502',
'4201', '4703', '4704', '4744', '4758', '5101', '6101', '6102',
'6731', '7101', '7102', '7103', '7201', '7202', '7700', '7701',
'7702', '7709', '7710', '7745', '7746', '7755', '7756', '7757',
'7790', '8703', '8707', '8708', '8771', '8772', '8776'],
'Wilderness_Area': ['Cache', 'Commanche', 'Neota', 'Rawah']
}
次に、このコードにより、次のラインのように、これらの値を結合する FEATURE_NAMES という名前の変数が作成されます。
FEATURE_NAMES = list(CATEGORICAL_FEATURES_WITH_VOCABULARY.keys()) + NUMERIC_FEATURE_NAMES
CREATE VIEW SQL スクリプトの生成
ノートブックのセクション 2 のタスクを実行すると、ログを解析するために後で実行する CREATE VIEW ステートメントが生成されます。
最初のタスクでは、json_features_extraction 変数と json_prediction_extraction 変数のデータ メタデータから外れた値を作成するコードを実行します。これらの変数には、SQL ステートメントに挿入可能な形式の特徴量と予測値が含まれます。
このコードは、ノートブック設定の構成時、およびデータセットのメタデータの定義時よりも先に設定した変数に依存します。次のスニペットは、このコードを示したものです。
LABEL_KEY = 'predicted_label'
SCORE_KEY = 'confidence'
SIGNATURE_NAME = 'serving_default'
def _extract_json(column, feature_name):
return "JSON_EXTRACT({}, '$.{}')".format(column, feature_name)
def _replace_brackets(field):
return "REPLACE(REPLACE({}, ']', ''), '[','')".format(field)
def _replace_quotes(field):
return 'REPLACE({}, "\\"","")'.format(field)
def _cast_to_numeric(field):
return "CAST({} AS NUMERIC)".format(field)
def _add_alias(field, feature_name):
return "{} AS {}".format(field, feature_name)
view_name = "vw_"+BQ_TABLE_NAME+"_"+VERSION_NAME
column_names = FEATURE_NAMES
input_features = ', \r\n '.join(column_names)
json_features_extraction = []
for feature_name in column_names:
field = _extract_json('instance', feature_name)
field = _replace_brackets(field)
if feature_name in NUMERIC_FEATURE_NAMES:
field = _cast_to_numeric(field)
else:
field = _replace_quotes(field)
field = _add_alias(field, feature_name)
json_features_extraction.append(field)
json_features_extraction = ', \r\n '.join(json_features_extraction)
json_prediction_extraction = []
for feature_name in [LABEL_KEY, SCORE_KEY]:
field = _extract_json('prediction', feature_name)
field = _replace_brackets(field)
if feature_name == SCORE_KEY:
field = _cast_to_numeric(field)
else:
field = _replace_quotes(field)
field = _add_alias(field, feature_name)
json_prediction_extraction.append(field)
json_prediction_extraction = ', \r\n '.join(json_prediction_extraction)
2 番目のタスクでは、sql_script という変数を、CREATE OR REPLACE VIEW ステートメントを含む長い文字列に設定します。このステートメントには複数のプレースホルダが含まれており、文字列内で @ を接頭辞として使用してマークされます。たとえば、データセットとビューの名前のプレースホルダがあります。
CREATE OR REPLACE VIEW @dataset_name.@view_name
また、次のように、プロジェクト、テーブル、モデル、バージョンの名前のプレースホルダもあります。
FROM
`@project.@dataset_name.@table_name`
WHERE
model = '@model_name' AND
model_version = '@version'
)
ステートメントの最後には、前のタスクでコードを実行して作成した json_features_extraction 変数と json_prediction_extraction 変数を使用するプレースホルダが含まれます。
step3 AS
(SELECT
model,
model_version,
time,
@json_features_extraction,
@json_prediction_extraction
FROM step2
)
最後に、次のセルを実行して、以下のスニペットに示すように、SQL ステートメント内のプレースホルダを先ほど設定した値に置き換えます。
sql_script = sql_script.replace("@project", PROJECT_ID)
sql_script = sql_script.replace("@dataset_name", BQ_DATASET_NAME)
sql_script = sql_script.replace("@table_name", BQ_TABLE_NAME)
sql_script = sql_script.replace("@view_name", view_name)
sql_script = sql_script.replace("@model_name", MODEL_NAME)
sql_script = sql_script.replace("@version", VERSION_NAME)
sql_script = sql_script.replace("@input_features", input_features)
sql_script = sql_script.replace("@json_features_extraction", json_features_extraction)
sql_script = sql_script.replace("@json_prediction_extraction", json_prediction_extraction)
この手順でビューを作成する SQL ステートメントの生成を完了し、未加工のリクエストとレスポンスのデータポイントを解析します。
生成したスクリプトを表示する場合は、ビューを出力するセルを実行します。セルには次のコードが含まれています。
print(sql_script)
CREATE VIEW SQL スクリプトの実行
CREATE VIEW ステートメントを実行するには、ノートブックのセクション 3 にあるコードを実行します。完了すると、コードにより「View created or
replaced」というメッセージが表示されます。このメッセージが表示されると、データを解析するビューが使用可能になります。
次のスニペットは、結果のステートメントを示したものです。
CREATE OR REPLACE VIEW prediction_logs.vw_covertype_classifier_logs_v1
AS
WITH step1 AS
(
SELECT
model,
model_version,
time,
SPLIT(JSON_EXTRACT(raw_data, '$.instances'), '}],[{') instance_list,
SPLIT(JSON_EXTRACT(raw_prediction, '$.predictions'), '}],[{') as prediction_list
FROM
`sa-data-validation.prediction_logs.covertype_classifier_logs`
WHERE
model = 'covertype_classifier' AND
model_version = 'v1'
),
step2 AS
(
SELECT
model,
model_version,
time,
REPLACE(REPLACE(instance, '[{', '{'),'}]', '}') AS instance,
REPLACE(REPLACE(prediction, '[{', '{'),'}]', '}') AS prediction,
FROM step1
JOIN UNNEST(step1.instance_list) AS instance
WITH OFFSET AS f1
JOIN UNNEST(step1.prediction_list) AS prediction
WITH OFFSET AS f2
ON f1=f2
),
step3 AS
(
SELECT
model,
model_version,
time,
REPLACE(REPLACE(REPLACE(JSON_EXTRACT(instance, '$.Soil_Type'), ']', ''), '[',''), "\"","") AS Soil_Type,
REPLACE(REPLACE(REPLACE(JSON_EXTRACT(instance, '$.Wilderness_Area'), ']', ''), '[',''), "\"","") AS Wilderness_Area,
CAST(REPLACE(REPLACE(JSON_EXTRACT(instance, '$.Aspect'), ']', ''), '[','') AS NUMERIC) AS Aspect,
CAST(REPLACE(REPLACE(JSON_EXTRACT(instance, '$.Elevation'), ']', ''), '[','') AS NUMERIC) AS Elevation,
CAST(REPLACE(REPLACE(JSON_EXTRACT(instance, '$.Hillshade_3pm'), ']', ''), '[','') AS NUMERIC) AS Hillshade_3pm,
CAST(REPLACE(REPLACE(JSON_EXTRACT(instance, '$.Hillshade_9am'), ']', ''), '[','') AS NUMERIC) AS Hillshade_9am,
CAST(REPLACE(REPLACE(JSON_EXTRACT(instance, '$.Hillshade_Noon'), ']', ''), '[','') AS NUMERIC) AS Hillshade_Noon,
CAST(REPLACE(REPLACE(JSON_EXTRACT(instance, '$.Horizontal_Distance_To_Fire_Points'), ']', ''), '[','') AS NUMERIC) AS Horizontal_Distance_To_Fire_Points,
CAST(REPLACE(REPLACE(JSON_EXTRACT(instance, '$.Horizontal_Distance_To_Hydrology'), ']', ''), '[','') AS NUMERIC) AS Horizontal_Distance_To_Hydrology,
CAST(REPLACE(REPLACE(JSON_EXTRACT(instance, '$.Horizontal_Distance_To_Roadways'), ']', ''), '[','') AS NUMERIC) AS Horizontal_Distance_To_Roadways,
CAST(REPLACE(REPLACE(JSON_EXTRACT(instance, '$.Slope'), ']', ''), '[','') AS NUMERIC) AS Slope,
CAST(REPLACE(REPLACE(JSON_EXTRACT(instance, '$.Vertical_Distance_To_Hydrology'), ']', ''), '[','') AS NUMERIC) AS Vertical_Distance_To_Hydrology,
REPLACE(REPLACE(REPLACE(JSON_EXTRACT(prediction, '$.predicted_label'), ']', ''), '[',''), "\"","") AS predicted_label,
CAST(REPLACE(REPLACE(JSON_EXTRACT(prediction, '$.confidence'), ']', ''), '[','') AS NUMERIC) AS confidence
FROM step2
)
SELECT*
FROM step3
ビューのクエリ
ビューを作成したら、ビューにクエリを実施できます。ビューにクエリを実施するには、セクション 4 のビューをクエリするでコードを実行します。このコードは、ノートブックの pandas.io.gbq.read_gbq メソッドを使用しています。次のコード スニペットをご覧ください。
query = '''
SELECT * FROM
`{}.{}`
LIMIT {}
'''.format(BQ_DATASET_NAME, view_name, 3)
pd.io.gbq.read_gbq(
query, project_id=PROJECT_ID).T
このコードにより、次のような出力が生成されます。
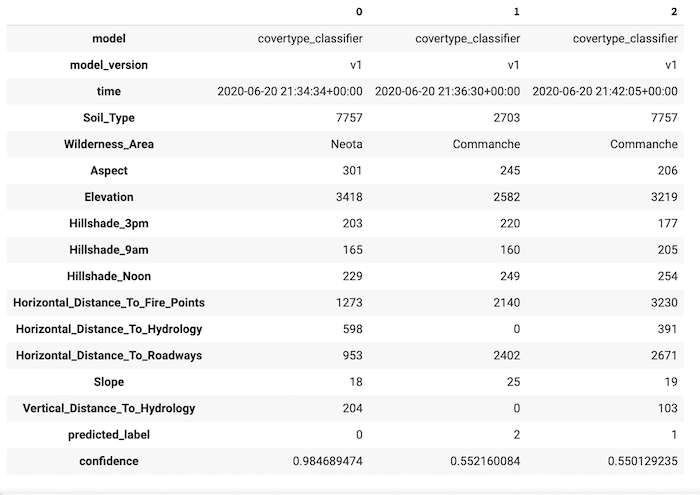
ビューのクエリの結果は、次の内容を示しています。
- 各特徴量には独自のエントリがある。
- 引用符はカテゴリ特徴量から除去される。
- 予測されたクラスラベルは
predicted_labelエントリに表示される。 - 予測されたクラスラベルの確率は、
confidenceエントリに表示される。
BigQuery コンソールの使用
pandas API を使用してビューにクエリを実施する代わりに、BigQuery コンソールでビューにクエリを実施できます。
BigQuery コンソールを開きます。
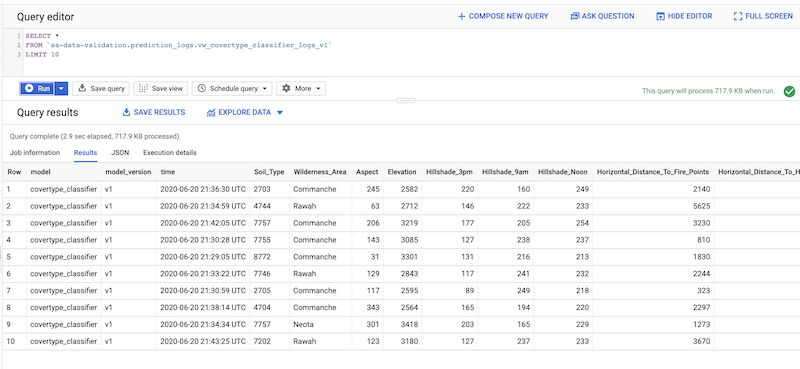
[Query Editor] ペインで、次のようなクエリを入力します。
Select* FROM PROJECT_ID.prediction_logs.vw_covertype_classifier_logs_v1 Limit 10
PROJECT_ID は、前に設定した Google Cloud プロジェクトの ID に置き換えます。
出力は次のようになります。
(省略可)サービング データのシミュレーション
独自のモデルやデータで作業している場合は、このセクションをスキップして次のセクションに進んでください。次のセクションでは、リクエスト / レスポンス ログテーブルにサンプルデータを入力する方法について説明します。
サンプルデータを使用して、偏りのあるデータポイントを生成し、AI Platform Prediction にデプロイされたモデル バージョンに対する予測リクエストをシミュレートできます。このモデルは、リクエスト インスタンスに対して予測を生成します。インスタンスと予測の両方が BigQuery に保存されます。
予測リクエストのサンプル(通常および偏った)データポイントを生成してから、生成されたデータポイントを使用して AI Platform Prediction にデプロイされた covertype 分類モデルを呼び出すことができます。クローンを作成したリポジトリには、このタスクのコードを含むノートブックが含まれています。または、スキューがあるログデータを含む CSV ファイルを読み込むことができます。
ノートブックからサンプルデータを生成する手順は次のとおりです。
- ノートブックでファイル ブラウザに移動し、
mlops-on-gcpを開いてskew-detection/workload_simulatorディレクトリに移動します。 covertype-data-generation.ipynbノートブックを開きます。- [設定] で、プロジェクト ID、バケット名、リージョンの値を設定します。
- ノートブックのすべてのセルを順番に実行します。
生成するデータのサイズのほかに、データを偏らせる方法も変更できます。データで導入されるデフォルトのスキューは、次のとおりです。
- 数値特徴量のスキュー。
Elevation特徴量の場合、コードにより 10% のデータの測定単位が m から km に変換されます。 - 数値特徴量分布のスキュー。
Aspect特徴量の場合、コードにより値が 25% 減少します。 - カテゴリ特徴量のスキュー。
Wilderness_Area特徴量の場合、コードにより 1% のデータの値がランダムにOthersという新しいカテゴリ名に変換されます。 - カテゴリ特徴量分布のスキュー。
Wilderness_Area特徴量の場合、コードによりNeotaとCacheの値の頻度が増加します。この操作は、コードによりランダムに選択された 25% のデータポイントで、元の値からNeotaとCacheの値に変換されることで行われます。
あるいは、workload_simulator/bq_prediction_logs.csv データファイルを BigQuery のリクエスト / レスポンス ログテーブルに読み込むこともできます。この CSV ファイルには、2,000 個の通常のデータポイントと 1,000 個の偏ったデータポイントを含む、リクエスト / レスポンスログのサンプルが含まれています。詳しくは、ローカルデータからの BigQuery へのデータの読み込みをご覧ください。
ログに記録されたサービング データの可視化
可視化ツールを使用して、BigQuery ビューに接続し、ログに記録されたサービング データを可視化できます。以下に示す可視化の例は、Looker Studio を使用して作成されました。
次のスクリーンショットは、このガイドの予測リクエスト / レスポンスのログを可視化するために作成されたサンプル ダッシュボードを示しています。
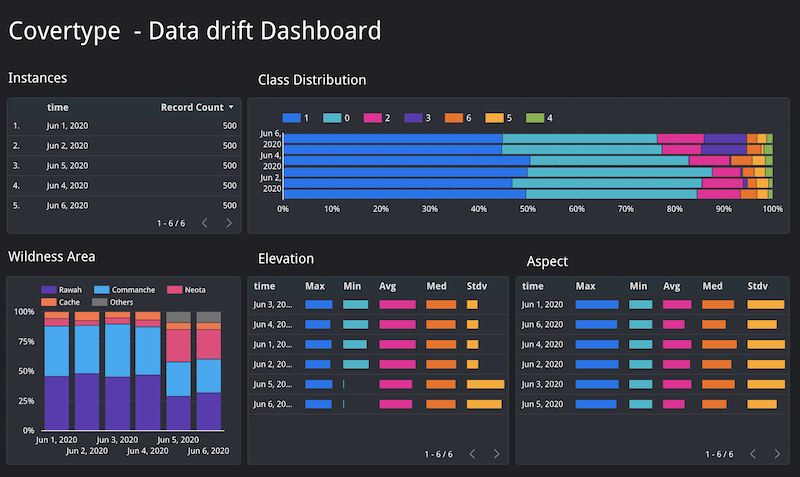
ダッシュボードには、次の情報が表示されます。
- 予測サービスによって受信されたインスタンス数は、6 月 1 日から 6 月 6 日まで毎日同じ(500)です。
- クラス分布では、予測されたクラスラベル
3の頻度が最後の 2 日間(6 月 5 日と 6 月 6 日)で増加しました。 Wilderness Area値の分布では、NeotaとCacheの値が最後の 2 日間で増加しました。Elevation特徴量の記述統計では、最後の 2 日間の最小値は、その前の 4 日間よりも大幅に低い値になっています。標準偏差値は、その前の 4 日間よりも大幅に高い値になっています。
さらに、次のスクリーンショットに示すように、最後の 2 日間の Aspect 特徴量の値の分布は、300~350 の間の値の頻度が大幅に低下しています。
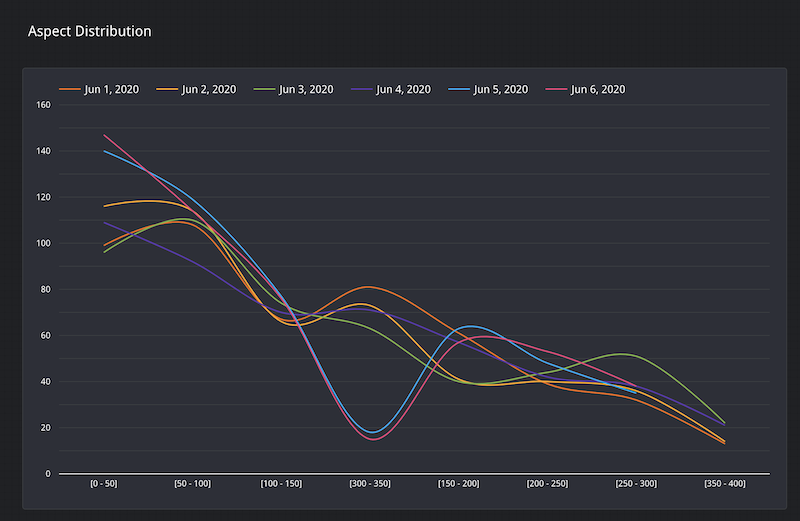
クリーンアップ
このシリーズの残りの部分も継続される予定の場合は、作成済みのリソースを保持してください。継続する予定がない場合は、リソースを含むプロジェクトを削除するか、プロジェクトは保持しつつ個別のリソースを削除します。
プロジェクトを削除する
- Google Cloud コンソールで、[リソースの管理] ページに移動します。
- プロジェクト リストで、削除するプロジェクトを選択し、[削除] をクリックします。
- ダイアログでプロジェクト ID を入力し、[シャットダウン] をクリックしてプロジェクトを削除します。
次のステップ
- TensorFlow Data Validation による AI Platform Prediction のトレーニング / サービング スキューの分析ガイドを読む。
- AI Platform Prediction のトレーニング / サービング スキュー検知の自動化ガイドを読む。
- 特異点検知によるトレーニング サーバー スキューの特定ガイドを読む。
- MLOps: 機械学習における継続的デリバリーと自動化のパイプラインについて学習する。
- TFX、Kubeflow Pipelines、Cloud Build を使用した MLOps のアーキテクチャについて学習する。
- Google Cloud に関するリファレンス アーキテクチャ、図、ベスト プラクティスを確認する。Cloud Architecture Center をご覧ください。