このドキュメントでは Message Passing Interface(MPI)から最適なパフォーマンスを引き出すよう Google Cloud リソースを調整する際のベスト プラクティスについて説明します。密結合なハイ パフォーマンス コンピューティング(HPC)ワークロードでは、プロセスとインスタンス間の通信に MPI がよく使用されます。最適な MPI パフォーマンスを実現するには、基盤となるシステムとネットワーク インフラストラクチャの適切な調整が重要です。Google Cloud で MPI ベースのコードを実行する場合は、これらの方法を使用して最適なパフォーマンスを実現させます。
前提条件と要件
通常、インスタンスの管理には Slurm や HTCondor などのワークロード スケジューラが使用されます。このドキュメントの推奨事項とベスト プラクティスは、すべてのスケジューラとワークフロー マネージャーに適用されます。
さまざまなスケジューラやワークフロー ツールを使用した、これらのベスト プラクティスの実装は、このドキュメントでは取り上げません。その他のドキュメントやチュートリアルでは、実装のためのツールと、それらのツールのガイドラインについて説明しています。
このドキュメントのガイドラインは一般的なもので、すべてのアプリケーションに役立つとは限りません。最も効率的または、費用対効果の高い構成を見つけるには、アプリケーションのベンチマークを行うことをおすすめします。
Bash または Ansible スクリプトを使用して構成を適用する
Google は、Cloud MPI リポジトリから入手できる Bash スクリプトまたは Ansible スクリプトを使用して、この最適化とベスト プラクティスを Compute Engine インスタンスに適用するオプションを提供しています。
事前構成された HPC VM イメージを使用する
このドキュメントに記載されているベスト プラクティスを手動で適用する代わりに、MPI ワークロードと密結合ワークロード用に最適化された HPC 仮想マシン(VM)イメージ(CentOS または Rocky Linux ベース)を使用できます。HPC VM イメージは、これらのベスト プラクティスをパッケージ化しており、Google Cloud Marketplace から追加料金なしで入手できます。詳しくは、HPC 対応 VM インスタンスの作成をご覧ください。
Compute Engine の構成
ベスト プラクティス:
コンパクト プレースメント ポリシーを使用するコンピューティング最適化インスタンスを使用する
同時マルチスレッド処理を無効にする
ユーザー制限を調整する
SSH ホストキーを設定する
このセクションでは、アプリケーションの最適なコンピューティング パフォーマンスを実現するためのベストプラクティスについて説明します。システム内で適切なマシンタイプと設定を使用すると、MPI のパフォーマンスに大きな影響を与える可能性があります。
コンパクト プレースメント ポリシーを使用する
プレースメント ポリシーでは、データセンターでの仮想マシン(VM)の配置を制御できます。コンパクト プレースメント ポリシーでは、単一のアベイラビリティ ゾーンに VM を配置するために、低レイテンシのトポロジが用意されています。最新の API を使用すると、物理的に近接する最大 150 個のコンピューティング最適化(C2、C2D、または H3)VM を作成できます。150 個を超える VM が必要な場合は、VM を複数のプレースメント ポリシーに分割します。ワークロードを処理できる最小数のプレースメント ポリシーの使用をおすすめします。
プレースメント ポリシーを使用するには、まず、特定のリージョンに必要な数の VM を持つコロケーション プレースメント ポリシーを作成します。
gcloud compute resource-policies create group-placement \ PLACEMENT_POLICY_NAME \ --collocation=collocated \ --vm-count=NUMBER_OF_VMs
次に、必要なゾーンでポリシーを使用して VM を作成します。
gcloud compute instances create
INSTANCE1 INSTANCE2 INSTANCEn
--zone=us-central1-a --resource-policies=PLACEMENT_POLICY_NAME
--maintenance-policy=TERMINATE
場合によっては、VM の作成方法を直接制御できない場合があります。たとえば、統合されていないサードパーティ製ツールを使用して VM が作成される場合があります。既存の VM にプレースメント ポリシーを適用するには、次の手順を実行します。
プレースメント ポリシーを適用する VM を停止します。
gcloud compute instances stop \ INSTANCE1 INSTANCE2 INSTANCEn
各 VM の可用性ポリシーを更新して、ホストのメンテナンス中に終了し、障害発生時に自動的に再起動しないように VM を構成します。
gcloud compute instances set-scheduling INSTANCE_NAME \ --maintenance-policy TERMINATE --no-restart-on-failure
プレースメント ポリシーを適用します。
gcloud compute instances add-resource-policies \ INSTANCE1 INSTANCE2 INSTANCEn \ --zone=us-central1-a --resource-policies=PLACEMENT_POLICY_NAME
コンピューティング最適化インスタンスを使用する
HPC アプリケーションの実行には、C2、C2D、または H3 VM を使用することをおすすめします。これらの VM は、仮想コアから物理コアへの固定されたマッピングを持ち、NUMA セル アーキテクチャをゲスト OS に公開します。どちらの機能も、密結合な HPC アプリケーションのパフォーマンスのために重要です。
H3 VM は 2 個の第 4 世代 Intel Xeon Scalable プロセッサ(Sapphire Rapids)、合計 88 コア、最大 352 GB の DDR5 メモリを搭載しており、全コアの周波数は 3.0 GHz です。これらの VM は、Google のカスタム Intel Infrastructure Processing Engine(IPU)を使用して、ネットワーク パフォーマンスを高速化します。H3 VM は、ホストサーバー全体で構成されるワンサイズ(88 個の仮想コアまたは vCPU)で使用でき、最大 200 Gbps のネットワーク スループットをサポートします。最適なパフォーマンスの整合性を確保するために、H3 VM では CPU のオーバーコミットは行われません。
C2 VM には、最大 60 個の vCPU(30 個の物理コア)と 240 GB の RAM があります。最大 3 TiB のローカル SSD ストレージを備え、最大 100 Gbps のネットワーク スループットをサポートできます。また、C2 インスタンスは第 2 世代の Intel Xeon Scalable プロセッサ(Cascade Lake)を活用します。これにより、他のインスタンス タイプと比較して、より広いメモリ帯域幅と高いクロック速度(最大 3.8 GHz)が提供されます。C2 インスタンスでは、通常、N1 インスタンス タイプと比較して、パフォーマンスが最大 40% 改善します。
C2D VM は、第 3 世代の AMD EPYC Milan をベースにしています。C2D VM は C2 VM と比較して、AMD(Milan)のプロセッサ・アーキテクチャの進化、CPU 周波数の向上、より大きな L3 キャッシュ、CCX アーキテクチャ、より高いメモリ帯域幅を活用しています。C2D VM の仕様は次のとおりです。
- 最大 112 個の vCPU(56 コア)
- 最大 448 GB のメモリ
- 最大 3 TiB のローカル SSD ストレージ
- VM ごとの Tier_1 ネットワーキング パフォーマンスにより、最大 100 Gbps のネットワーク スループットをサポート
マシン間の通信オーバーヘッドを削減するには、多数の小規模な C2、C2D、または H3 の VM を起動するのではなく、ワークロードを少数の c2-standard-60、c2d-standard-112、または h3-standard-88 VM(同じ合計コア数)に統合することをおすすめします。
同時マルチスレッディングを無効にする
一部の HPC アプリケーションは、ゲスト オペレーティング システムで同時マルチスレッディング(SMT)を無効にすることで、パフォーマンスが向上します。同時マルチスレッディングは Intel ハイパー スレッディングとも呼ばれ、ノード上の物理コアごとに 2 つの vCPU を割り当てます。多くの一般的なコンピューティング タスクや、大量の I/O を必要とするタスクでは、SMT によってアプリケーションのスループットを大幅に向上させることができます。両方の仮想コアがコンピューティング能力による制約を受ける計算依存型ジョブの場合、SMT はアプリケーションの全体的なパフォーマンスを妨げ、ジョブに予測不能なばらつきが発生する場合があります。SMT をオフにすると、パフォーマンスがより予測可能になり、ジョブの時間を短縮できます。
すべての VM タイプで、VM の作成時に SMT を無効にできます。ただし、次の例外があります。
H3 VM では SMT がデフォルトで無効になっており、有効にすることはできません。
vCPU が 2 個未満のマシンタイプ(例:
n1-standard-1)や、共有コアマシン(例:e2-small)で実行される VM。Tau T2D マシンタイプで実行される VM。
VM の作成時に SMT を無効にするには、1 に設定された --threads-per-core フラグをコマンドに含めます。次に例を示します。
gcloud beta compute instances create VM_NAME
--zone=ZONE
--machine-type=MACHINE_TYPE
--threads-per-core=1
詳しくは、同時マルチスレッディングの構成に関するドキュメントをご覧ください。
ユーザー制限を調整する
Unix システムでは、オープン ファイルや、すべてのユーザーが使用できるプロセスの数などのシステム リソースにデフォルトで制限があります。これらの制限により、1 人のユーザーがシステム リソースを独占して他のユーザーの作業に影響を与えることを防止します。ただし、HPC のコンテキストでは、クラスタ内のコンピューティング ノードはユーザー間で直接共有されないため、通常これらの制限は不要です。
/etc/security/limits.conf ファイルを編集してノードに再度ログインすることで、ユーザー制限を調整できます。自動化の場合、これらの変更を VM イメージにベイクできます。また、Deployment Manager、Terraform、Ansible などのツールを使用して、デプロイ時に制限を調整できます。
ユーザー制限を調整する場合は、次の制限の値を変更します。
nproc- プロセスの最大数memlock- 最大ロックイン メモリ アドレス空間(KB)stack- 最大スタックサイズ(KB)nofile- オープン ファイルの最大数cpu- 最大 CPU 時間(分)rtprio- 非特権プロセスに許容されるリアルタイムの最大優先度(Linux 2.6.12 以降)
これらの制限は、Debian、CentOS、Rocky Linux、Red Hat など、Unix および Linux システムのほとんどで /etc/security/limits.conf システム構成ファイルの中で構成されます。
ユーザー制限を変更するには、テキスト エディタを使用して次の値を変更します。
/etc/security/limits.confで次のように変更します。* - nproc unlimited * - memlock unlimited * - stack unlimited * - nofile 1048576 * - cpu unlimited * - rtprio unlimited/etc/security/limits.d/20-nproc.confで次のように変更します。* - nproc unlimited
ゾーン再利用モードを有効にする
ゾーン再利用モードでは、ゾーンのメモリが不足したときにメモリを回収する積極的なアプローチを設定できます。モードをゼロに設定すると、ゾーン再利用は行われません。その場合は、システム内の他のゾーンまたはノードから割り当てられます。
NUMA ノードのメモリを超えるジョブと NUMA ノード外に拡張されるマルチコア ジョブは、ゾーン再利用モードを有効にすることでメリットが得られます。この値は 1 に設定することをおすすめします。
sudo sysctl vm.zone_reclaim_mode=1
トランスペアレントな巨大ページを有効にする
HPC アプリケーションには、多くの場合、透明でサイズの大きなページの使用が有用です。
トランスペアレントな巨大なページを有効にするには、次のコマンドを使用します。
echo ‘always’ > /sys/kernel/mm/transparent_hugepage/enabled
echo ‘always’ > /sys/kernel/mm/transparent_hugepage/defrag
自動 NUMA 分散を無効にする
オペレーティング システムによる自動 NUMA 分散は、オーバーヘッドが発生する可能性があるため、MPI アプリケーションにはおすすめしません。
自動 NUMA 分散を無効にするには、次のコマンドを使用します。
sudo sysctl kernel.numa_balancing=0
SSH ホストキーを設定する
Intel MPI では、mpirun を実行するノードの ~/.ssh/known_hosts ファイル内にあるすべてのクラスタノードのホストキーが必要です。SSH 認証鍵も authorized_keys に保存する必要があります。
ホストキーを追加するには、次のコマンドを実行します。
ssh-keyscan -H 'cat HOSTFILE' >> ~/.ssh/known_hosts
次のコマンドを実行して、~/.ssh/config ファイルに StrictHostKeyChecking=no を追加する方法もあります。
Host *
StrictHostKeyChecking no
Google Virtual NIC(gVNIC)を使用する
Virtio-net の代わりに Google Virtual NIC(gVNIC)を使用すると、通信パフォーマンスとスループットが向上し、MPI アプリケーションのスケーラビリティを改善できます。また、gVNIC は、VM ごとの Tier_1 ネットワーキング パフォーマンスを使用する VM の前提条件です。新しい VM を作成する場合、第 1 世代または第 2 世代のマシンシリーズ(C2、C2D など)では、Virtio-net がデフォルトの仮想ネットワーク インターフェースとなります。第 3 世代のマシンシリーズ(C3、H3 など)では、gVNIC ネットワーク インターフェースのみが使用されます。第 1 世代と第 2 世代のマシンシリーズで gVNIC を有効にする方法については、Google Virtual NIC の使用をご覧ください。
ジャンボ フレームを使用する
Virtual Private Cloud(VPC)ネットワークのデフォルトの最大伝送単位(MTU)は 1,460 バイトです。VPC ネットワークを構成して MTU を異なる値に設定することができ、最大 8,896 バイト(ジャンボ フレーム)まで設定可能です。ただし、1,600 より大きい MTU は、送信元インターフェースと宛先インターフェースが同じサブネット内にあり、サブネットのプライマリ IPv4 範囲にある内部 IPv4 アドレスを使用して通信している場合にのみ使用できます。
HPC アプリケーションでは、内部通信や並列ファイル システムへのアクセスにジャンボ フレームを使用するのが有用です。ネットワーク パケットの処理オーバーヘッドを最小限に抑えるには、より大きなパケットサイズを使用することをおすすめします。より大きなパケットサイズは、アプリケーションの仕様に応じて検証する必要があります。ジャンボ フレームとパケットサイズの使用方法については、最大伝送単位のガイドをご覧ください。
ストレージ
多くの HPC アプリケーションのパフォーマンスは、基盤となるストレージ システムのパフォーマンスに大きく依存します。これは特に、大量のデータを読み書きするアプリケーションや、多数のファイルやオブジェクトを作成またはアクセスするアプリケーションに当てはまります。また、多くのランクが同時にストレージ システムにアクセスする場合も同様です。
NFS ファイル システムまたは並列ファイル システムを選択する
密結合なアプリケーション向けのプライマリ ストレージの種類を以下に示します。それぞれに独自のコスト、パフォーマンス プロファイル、API、整合性セマンティクスがあります。
- Filestore や NetApp Cloud Volumes などの NFS ベースのソリューションは、共有ストレージ オプションをデプロイするのに最適です。どちらのオプションも Google Cloud でフルマネージドであり、アプリケーションで 1 つのデータセットに対する I/O 要件が厳しくなく、アプリケーションの実行と更新時にコンピューティング ノード間でデータ共有ができない場合に最適です。パフォーマンスの制限については、Filestore と NetApp Cloud Volumes のドキュメントをご覧ください。
- POSIX ベースの並列ファイル システムは、MPI アプリケーションでより一般的に使用されています。POSIX ベースのオプションには、オープンソースの Lustre と、完全にサポートされた Lustre サービスである DDN Storage EXAScaler Cloud があります。コンピューティング ノードは、データを生成して共有する際、並列ファイル システムで提供される優れたパフォーマンスと、POSIX セマンティクスの完全なサポートを利用することがしばしばあります。Lustre などの並列ファイル システムは、大規模なスーパーコンピュータにデータを送信し、何千ものクライアントをサポートできます。また、NetCDF、HDF5、MPI-IO などのデータ ライブラリや I/O ライブラリをサポートしており、幅広いアプリケーション ドメインで並列 I/O を利用できます。
ストレージ インフラストラクチャを選択する
アプリケーションのパフォーマンス要件は、選択したファイル システムのストレージ インフラストラクチャまたはストレージ階層を示す必要があります。たとえば、高い 1 秒あたり I/O オペレーション(IOPS)を必要としないアプリケーション用に SSD をデプロイすると、コストの増加にもかかわらずメリットがあまり得られない可能性があります。
マネージド ストレージ サービスの Filestore と NetApp Cloud Volumes は、容量に基づいてスケーリングする複数のパフォーマンス階層を備えています。
オープンソースの Lustre または DDN Storage EXAScaler Cloud の正しいインフラストラクチャを判断するには、まず、標準永続ディスク、SSD 永続ディスク、またはローカル SSD を使用して必要なパフォーマンスを達成するために必須となる vCPU と容量を把握する必要があります。正しいインフラストラクチャを判断する方法について詳しくは、ブロック ストレージのパフォーマンス情報と、永続ディスクのパフォーマンスの最適化をご覧ください。たとえば Lustre を使用している場合は、メタデータ サーバー(MDS)に SSD 永続ディスク、ストレージ サーバー(OSS)に標準永続ディスクを使用して、低コストで高帯域幅のソリューションをデプロイできます。
ネットワークの設定
多くの HPC アプリケーションでは、MPI ネットワークのパフォーマンスが重要です。この点は特に、異なるノード上の MPI プロセスが頻繁に通信する、またはデータ量の大きい通信を行う密結合なアプリケーションに当てはまります。このセクションでは、MPI パフォーマンスを最適化するためにネットワーク設定を調整する際のベスト プラクティスについて説明します。
tcp_*mem 設定を増やす
C2 VM と C2D VM は、Tier_1 ネットワーキングなしで最大 32 Gbps の帯域幅をサポートできます。H3 VM は、Tier_1 ネットワーキングなしで最大 200 Gbps の帯域幅に達することができます。したがって、3 タイプの VM の帯域幅使用量に対応するには、Linux で有効になっているデフォルトの帯域幅設定よりも多くの TCP メモリが必要になります。
ネットワークのパフォーマンスを高めるには、tcp_mem 値を増やします。
TCP メモリ上限を増やすには、/etc/sysctl.conf で次の値を更新します。
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
/etc/sysctl.conf に新しい値を読み込むには、sysctl -p を実行します。
ネットワーク プロファイルを使用する
一部のアプリケーションでは、アプリケーションに適したネットワーク プロファイルを使用すると、パフォーマンスを改善できます。ネットワーク レイテンシの影響を受けやすい一部のアプリは、ビジー ポーリングを有効にすることで改善される場合があります。ビジー ポーリングは、ソケットレイヤのコードがネットワーク デバイスの受信キューをポーリングできるようにし、ネットワークの割り込みを無効にすることによって、ネットワーク受信パスのレイテンシを短縮します。アプリケーションのレイテンシを評価して、ビジー ポーリングが有効かどうかを確認します。
ネットワーク レイテンシ プロファイルは再起動後も維持されます。システムに tuned-adm がインストールされている場合は、次のコマンドを実行すると、低レイテンシのプロファイルを有効にできます。
tuned-adm profile network-latency
システムに tuned-adm がインストールされていない場合は、/etc/sysctl.conf に次のコマンドを追加することで、ビジー ポーリングを有効にできます。
net.core.busy_poll = 50
net.core.busy_read = 50
/etc/sysctl.conf に新しい値を読み込むには、sysctl -p を実行します。
アプリケーションがサイズの大きいパケットを送信し、帯域幅の影響を受ける場合は、次のコマンドを使用してネットワーク スループット プロファイルを有効にできます。
tuned-adm profile network-throughput
MPI ライブラリとユーザー アプリケーション
ベスト プラクティス:
Intel MPI を使用するmpitune を使用して MPI グループの調整を行う
MPI / OpenMP ハイブリッド モードを使用する
ベクトル命令と Math Kernel Library を使用してアプリケーションをコンパイルする
適切な CPU 番号を使用する
オープン MPI を使用する
MPI ライブラリの設定と HPC アプリケーションの構成は、アプリケーションのパフォーマンスに影響する可能性があります。HPC アプリケーションのパフォーマンスを最大限に引き出すには、それらの設定や構成を詳細に調整することが重要です。このセクションでは、Google Cloud で MPI ライブラリとユーザー アプリケーションを実行するためのベスト プラクティスについて説明します。
Intel MPI を使用する
最適なパフォーマンスを得るには、Intel MPI 2021 を使用することをおすすめします。
Google では、HPC MPI ワークロードのパフォーマンスを向上させ、Google Cloud 環境で簡単に実行できるように、google-hpc-compute ユーティリティを提供しています。google-hpc-compute ユーティリティは、Rhel 7、CentOS 7、Rhel 8、Rocky Linux 8 など、EL7 と EL8 のディストリビューションで使用できます。google_install_impi スクリプトは、IntelMPI 2021 を設定するためのコマンドを提供します。
google-hpc-compute ユーティリティを取得する
google-hpc-compute ユーティリティは、HPC-CentOS-7 イメージと HPC-RL8-VM イメージに付属しています。HPC VM イメージを使用して新しく作成された VM インスタンスには、このユーティリティが付属しています。
既存の VM インスタンスに対するユーティリティを取得するには、次のいずれかの方法を使用します。
HPC-CentOS-7 イメージで作成された既存の VM インスタンス。次のコマンドを実行すると、既存の
google-hpc-computeユーティリティを更新できます。sudo yum update -y google-hpc-compute
EL7/EL8 イメージで作成された既存の VM インスタンス。Google Cloud で HPC MPI ワークロードを実行する場合は、HPC VM イメージを使用することをおすすめしますが、次のコマンドで
google-hpc-compute-el7-x86_64リポジトリを追加すれば、google-hpc-computeユーティリティにアクセスできます。cat > /etc/yum.repos.d/google-hpc-compute.repo << EOF [google-hpc-compute] name=Google HPC Compute baseurl=https://packages.cloud.google.com/yum/repos/google-hpc-compute-el7-x86_64 enabled=1 gpgcheck=1 repo_gpgcheck=0 gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg EOFVM に
google-hpc-compute-el7-x86_64リポジトリが作成されたら、次のコマンドを使用してgoogle-hpc-computeユーティリティをダウンロードできます。sudo yum install -y google-hpc-compute
IntelMPI 2021 サポートのために google-hpc-compute ユーティリティを使用する
google_install_intelmpi ツールによって IntelMPI 2021.8 ライブラリがインストールされます。ライブラリをインストールするときに、次のフラグを設定します。
--install_dir <var>install_path</var>: インストール用のプレフィックス ディレクトリを構成します。デフォルトの場所は/opt/intelです。--impi_2021: Intel MPI 2021.8 をインストールします。これは、Google Cloud で MPI ジョブを実行する場合に推奨されるバージョンです。
IntelMPI ライブラリをインストールするには、このユーティリティに sudo モードが必要です。このコマンドにより、MPI ライブラリが install_dir ディレクトリにインストールされます。
MPI ライブラリの呼び出しには、次のコマンドを使用します。
source install_path/mpi/latest/env/vars.sh
mpitune を使用して MPI グループの調整を行う
MPI 実装には、特に MPI グループ通信パフォーマンスに関連する内部構成パラメータが多数あります。IntelMPI を使用すると、Google Cloud 環境に基づいてアルゴリズムと構成パラメータを指定できます。
IntelMPI 2021 には、Google Cloud 環境向けに一般的に適用できる組み込み調整構成パラメータがあります。デプロイされたクラスタ環境とアプリケーションの特性に基づいて、カスタマイズされた調整構成パラメータを生成できます。Intel の公式ガイドに沿って、mpitune または mpitune_fast ユーティリティを使用して、カスタマイズされた調整プロファイルを生成することをおすすめします。
ベクトル命令と Math Kernel Library を使用してアプリケーションをコンパイルする
C2 VM は、AVX2 と AVX512 のベクトル命令をサポートしています。AVX 命令を使用してコンパイルすることで、多くの HPC アプリケーションのパフォーマンスを向上させることができます。一部のアプリケーションでは、AVX512 の代わりに AVX2 を使用するとパフォーマンスが向上します。ワークロードに対して両方のタイプの AVX 命令の試行をおすすめします。科学計算のパフォーマンスを向上させるには、Intel Math Kernel Library(Intel MKL)の使用もおすすめします。
Intel コンパイラを使用して C2 インスタンス用の MPI バイナリをビルドすることをおすすめします。
AMD 固有の最適化
このセクションでは、AMD ベースのシステムの推奨事項について説明します。
AMD コンパイラ / ツールチェーン
AMD Optimization CPU Compiler(AOCC)は、32 ビット版と 64 ビット版の Linux プラットフォームを対象とする C、C++、Fortran のアプリケーションを構築し最適化する開発者にさまざまなオプションを提供する、高性能で本番環境に対応した品質のコード生成ツールです。C2D で HPC アプリケーションをコンパイルするには、AOCC を使用することをおすすめします。第 3 世代 AMD EPYC シリーズ CPU で実行される命令を生成するには、-march=znver3 フラグを使用します。gcc ツールでコンパイルするときも、同じフラグを使用できます。
ベクター命令と Math Kernel Library
C2D VM はベクトル命令(AVX2)をサポートしています。AVX2 命令を使ってコンパイルすることで、多数の HPC アプリケーションでパフォーマンスが大幅に向上することが確認されています。この手順によって最適化された AMD Math Kernel Library(BLIS)を使用することをおすすめします。
Intel Math Kernel Library にリンクされているアプリケーションでは、AMD EPYC で AVX2 の効果が発揮されない場合があります。
MPI OpenMP ハイブリッド モードを使用する
多くの MPI アプリケーションは、MPI アプリケーションでの OpenMP の有効化に使用できるハイブリッド モードをサポートしています。ハイブリッド モードでは、各 MPI プロセスが固定数のスレッドを使用して特定のループ構造の実行を加速できます。
アプリケーションのパフォーマンスを最適化する場合は、ハイブリッド モード オプションを確認することをおすすめします。ハイブリッド モードを使用すると、各 VM で MPI プロセスを少なくできるため、プロセス間の通信が減少し、全体的な通信時間が短縮されます。
ハイブリッド モードまたは OpenMP を有効にする方法はアプリケーションによって異なります。多くの場合、次の環境変数を設定してハイブリッド モードを有効にできます。
export OMP_NUM_THREADS=NUM_THREADS
このハイブリッド アプローチを使用する場合は、スレッドの合計数が VM の物理コア数を超えないようにすることをおすすめします。c2-standard-60 VM には、15 個のコア、30 個の vCPU を含む NUMA ソケットが 2 つあります。複数の NUMA ノードにまたがる OpenMP スレッドを含む MPI プロセスを使用しないことをおすすめします。
C2D-standard-112 には、各ソケットに 28 個のコアを含むソケットが 2 つ、計 56 個のコアがあります。これらのコアは 7 つの CCX にグループ化され、それぞれに 4 つのコアが含まれています。各 CCX には 32 MB の L3 キャッシュがあります。各コアには、512 KB の L2 キャッシュと、32 KB の L1 命令およびデータ キャッシュがあります。各ソケットには 220 GB の DRAM が接続されています。C2D-standard-112 では、プロセスが 1 つの CCX に収まるように、2 つまたは 4 つの OMP スレッドを使用することをおすすめします。OMP スレッド数を 4 に設定すると、L3 キャッシュごとに 1 つの MPI プロセスが作成されます。
export OMP_NUM_THREADS=4
CPULIST=$(seq -s , 0 4 55)
Open MPI:
mpirun –bind-to one –cpu-list $CPULIST …
Intel MPI:
export I_MPI_PIN_PROCESSOR_LIST=$CPULIST
適切な CPU 番号を使用する
c2-standard-60 には 2 つの NUMA ソケットがあり、NUMA ノードに関して CPU は次のように番号付けされています。
NUMA node0 CPU(s): 0-14,30-44
NUMA node1 CPU(s): 15-29,45-59
次の図は、c2-standard-60 インスタンスの NUMA ノードにおける各 CPU への CPU 番号の割り当てを示しています。ソケット 0 は CPU 0~14、30~44 を持つ NUMA ノード 0 に対応します。ソケット 1 は、CPU 15~29、45~59 を持つ NUMA ノード 1 に対応します。
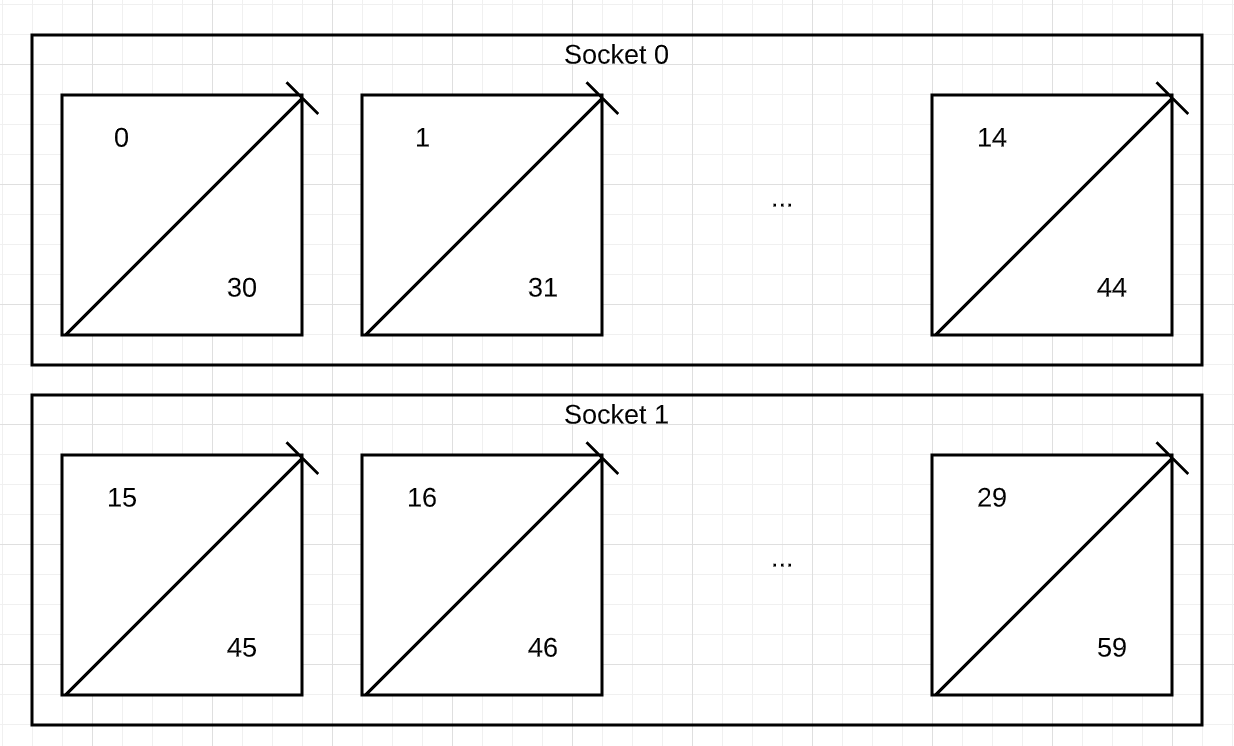
VM の単一コアにマッピングされるハイパー スレッドのシブリングスは (0,30)(1,31)..(29,59) です。
Intel MPI では、MPI ジョブのプロセッサの固定に NUMA CPU 番号が使用されます。実行全体で一貫性のある、すべてのノードでコアごとに 1 つのハイパー スレッドを使用する場合は、CPU 番号 0~29 を使用します。
Open MPI は、Portable Hardware Locality(hwloc)によって報告される論理 CPU 番号を使用します。Open MPI を使用する場合、ハイパー スレッドの兄弟要素は次のように連続で番号付けされます。
ソケット 0: 0(コア 0 HT 0)、1(コア 0 HT 1)、2(コア 1 HT 0)、...、28(コア 14 HT 0)、29(コア 14、HT 1)
ソケット 1: 30(コア 0 HT 0)、31(コア 0 HT 1)、2(コア 1 HT 0)、...、58(コア 14 HT 0)、59(コア 14、HT 1)
出力は次のようになります。
lstopo-no-graphics
Machine (240GB total)
NUMANode L#0 (P#0 120GB) + Package L#0 + L3 L#0 (25MB)
L2 L#0 (1024KB) + L1d L#0 (32KB) + L1i L#0 (32KB) + Core L#0
PU L#0 (P#0)
PU L#1 (P#30)
L2 L#1 (1024KB) + L1d L#1 (32KB) + L1i L#1 (32KB) + Core L#1
PU L#2 (P#1)
PU L#3 (P#31)
Open MPI を使用する場合、CPU 番号 0,2,4,..58 を使用することで、実行全体で一貫性のあるすべてのノード間でコアごとに 1 つのハイパー スレッドを使用できます。MPI でプロセスをコアに固定するには、openMPI の実行時に --bind-to core オプションを使用し、--report-bindings オプションを使用して正しいバインディングを検証します。
Open MPI を使用する
Open MPI を使用しているお客様は、Open MPI の最新の Stable リリースを使用することをおすすめします。
Google Cloud 上で Open MPI のパフォーマンスを向上させるには、オペレーティング システム レベルと Open MPI MCA レベルの両方で次の調整オプションを使用することをおすすめします。
オペレーティング システムの調整に関しては、ビジー ポーリングを無効にすると Open MPI のパフォーマンスが向上することが確認されています。ビジー ポーリングを無効にするには、次のコマンドを使用します。
tuned-adm profile network-throughput
Open MPI のパフォーマンスを、調整によってさらに向上させるには、次の MCA パラメータを使用します。
--mca opal_event_include epoll
ネットワーク イベントのポーリング時に使用されるデフォルトのポーリング方法を、poll から epoll に変更します。この変更により、ビジー ポーリングが有効な場合にはパフォーマンスが向上し、無効な場合も低下はありません。--mca btl_tcp_progress_thread 1
BTL(バイト転送レイヤ)フレームワークの TCP コンポーネントで、progress_threadの値を 0(デフォルト)から 1 に変更します。--mca coll_han_priority 100
COLL(コレクティブ)フレームワークで Hierarchical-Aware Networking(HAN)コンポーネントを有効にします。
提案された MCA パラメータを有効にするには、次のコマンドを使用します。
mpirun -hostfile HOSTFILE -np NUM_PROCESSES -npernode PROCESSES_PER_NODE \
--mca opal_event_include epoll \
--mca btl_tcp_progress_thread 1 \
--mca coll_han_priority 100 APPLICATION
これらのパラメータは、MCA ファイルに追加して有効にすることもできます。詳細については、MCA パラメータの値を設定する方法をご覧ください。
セキュリティ設定
組み込みの Linux セキュリティ機能の一部を無効にすると、MPI のパフォーマンスを向上させることができます。これらの各機能を無効にした場合のパフォーマンス上のメリットは異なります。システムが十分に保護されていると確信できれば、次のセキュリティ機能の無効化を検討できます。
Linux ファイアウォールを無効にする
Google Cloud の CentOS または Rocky Linux のイメージでは、ファイアウォールはデフォルトで有効になっています。ファイアウォールを無効にするには、次のコマンドを実行して、firewalld デーモンを停止して無効にします。
sudo systemctl stop firewalld
sudo systemctl disable firewalld
sudo systemctl mask --now firewalld
SELinux を無効にする
CentOS または Rocky Linux の SELinux は、デフォルトで有効になっています。SELinux を無効にするには、/etc/selinux/config ファイルを編集して、SELINUX=enforcing または SELINUX=permissive の行を SELINUX=disabled に置き換えます。
この変更を有効にするには、再起動する必要があります。
Meltdown と Spectre の緩和策を無効にする
Linux システムでは、次のセキュリティ パッチがデフォルトで有効になっています。
- Variant 1、Spectre: CVE-2017-5753
- Variant 2、Spectre: CVE-2017-5715
- Variant 3、Meltdown: CVE-2017-5754
- Variant 4、Speculative Store Bypass: CVE-2018-3639
これらの CVE に記載されているセキュリティの脆弱性は、Google Cloud にデプロイされたプロセッサを含む、最新のマイクロプロセッサに存在する可能性があります。起動時にカーネル コマンドラインを使用する(再起動しても保持されます)、または実行時に debugfs を使用する(再起動時に保持されません)ことで、これらの複数の緩和策のうち 1 つ以上を無効にできます(関連するセキュリティ リスクを負うことになります)。
上記のセキュリティ対策を完全に無効にするには、次の手順を行います。
ファイル
/etc/default/grubを変更します。sudo sed -i 's/^GRUB_CMDLINE_LINUX=\"\(.*\)\"/GRUB_CMDLINE_LINUX=\"\1 mitigations=off\"/' /etc/default/grubgrubファイルを変更した後、次のコマンドを実行して GRUB システム構成ファイルを更新してから、システムを再起動します。CentOS の場合:
sudo grub2-mkconfig -o /boot/efi/EFI/centos/grub.cfgRocky Linux の場合:
sudo grub2-mkconfig -o /boot/efi/EFI/rocky/grub.cfgシステムに従来の BIOS 起動モードがある場合は、代わりに次のコマンドを実行します。
sudo grub2-mkconfig -o /boot/grub2/grub.cfg再起動します。
システムがすでに実行されている場合、次のコマンドを実行すると、上記のセキュリティ対策を無効にできます。これは再起動後は保持されません。
echo 0 > /sys/kernel/debug/x86/pti_enabled
echo 0 > /sys/kernel/debug/x86/retp_enabled
echo 0 > /sys/kernel/debug/x86/ibrs_enabled
echo 0 > /sys/kernel/debug/x86/ssbd_enabled
さまざまな緩和策がシステムに及ぼす影響の可能性と、その制御方法については、Red Hat のドキュメントである「マイクロコードとセキュリティ パッチのパフォーマンスへの影響の制御」および、「投機的ストアバイパスを使用したカーネル サイドチャネル攻撃」をご覧ください。
CPU の影響を受ける脆弱性を見つけるには、次のコマンドを実行します。
grep . /sys/devices/system/cpu/vulnerabilities/*
有効になっている緩和策を確認するには、次のコマンドを実行します。
grep . /sys/kernel/debug/x86/*_enabled
チェックリストの概要
次の表に、Compute Engine で MPI を使用するためのベスト プラクティスをまとめます。
| 領域 | タスク |
|---|---|
| Compute Engine の構成 | |
| ストレージ | |
| ネットワークの設定 | |
| MPI ライブラリとユーザー アプリケーション | |
| セキュリティ設定 |
次のステップ
- Google コンピューティング最適化 VM の詳細を確認する。
- Google Cloud に Slurm クラスタをデプロイする。
- Google Cloud のハイ パフォーマンス ストレージの詳細を確認する。
- HTCondor について確認する。
- Google Cloud に関するリファレンス アーキテクチャ、図、ベスト プラクティスを確認する。Cloud アーキテクチャ センター をご覧ください。