Dieser Leitfaden enthält Anleitungen zum Betrieb von SAP HANA-Systemen, die auf Google Cloud gemäß der Anleitung unter Terraform: Bereitstellungsleitfaden für SAP HANA zur vertikalen Skalierung bereitgestellt werden. Beachten Sie, dass diese Anleitung keine Standard-SAP-Dokumentation ersetzen soll.
SAP HANA-Systeme auf Google Cloudverwalten
In diesem Abschnitt wird gezeigt, wie Sie administrative Aufgaben ausführen, die für den typischen Betrieb eines SAP HANA-Systems erforderlich sind, wie etwa das Starten, Anhalten und Klonen von Systemen.
Instanzen starten und anhalten
Sie können jederzeit einen oder mehrere SAP HANA-Hosts anhalten. Durch das Anhalten einer Instanz wird die Instanz heruntergefahren. Wenn das Herunterfahren nicht innerhalb des Herunterfahrzeitraums abgeschlossen ist, wird das Anhalten der Instanz erzwungen. Um Datenverluste oder beschädigte Dateisysteme zu vermeiden, empfehlen wir Folgendes:
Halten Sie SAP HANA an, bevor Sie die Instanz anhalten.
Wenn Sie die Zeitspanne für das Herunterfahren einer Instanz verlängern möchten, aktivieren Sie in der Instanz die Option Graceful Shutdown (sanftes Herunterfahren).
Informationen zum Beenden oder Neustarten einer Instanz finden Sie unter Compute Engine-Instanz beenden oder neu starten.
VM ändern
Sie können verschiedene Attribute einer VM ändern, einschließlich des VM-Typs, nachdem die VM bereitgestellt wurde. Bei einigen Änderungen müssen Sie möglicherweise Ihr SAP-System aus Sicherungen wiederherstellen. Bei anderen wiederum reicht es aus, lediglich die VM neu zu starten.
Weitere Informationen finden Sie unter VM-Konfigurationen für SAP-Systeme ändern.
Snapshots von SAP HANA erstellen
Damit Sie eine Sicherung Ihres nichtflüchtigen Speichers zu einem bestimmten Zeitpunkt erhalten, können Sie einen Snapshot erstellen. Compute Engine speichert redundant mehrere Kopien jedes Snapshots verteilt über mehrere Speicherorte mit automatischen Prüfsummen, um die Integrität der Daten zu gewährleisten.
Befolgen Sie zum Erstellen eines Snapshots die Anweisungen zu Compute Engine unter Snapshots erstellen. Achten Sie besonders auf die vorbereitenden Schritte, bevor Sie einen konsistenten Snapshot erstellen z. B. das Leeren der Laufwerkzwischenspeicher, damit dafür gesorgt wird, dass der Snapshot konsistent ist.
Snapshots eignen sich für folgende Anwendungsfälle:
| Anwendungsfall | Details |
|---|---|
| Eine einfache, softwareunabhängige und kostengünstige Datensicherungslösung bereitstellen | Sie sichern Ihre Daten, Logs, Sicherungen und freigegebenen Laufwerke mit Snapshots. Sie planen eine tägliche Sicherung dieser Laufwerke, damit das gesamte Dataset zu einem bestimmten Zeitpunkt gesichert wird. Nach dem ersten Snapshot werden lediglich die inkrementellen Blockänderungen in folgenden Snapshots gespeichert. Dies hilft, Kosten zu sparen. |
| Zu einem anderen Speichertyp migrieren | Compute Engine bietet verschiedene Arten von nichtflüchtigem Speicher, darunter Standardspeicher (magnetisch) und SSD-basierte Speicher (Solid-State Drive). Jede Art hat unterschiedliche Kosten- und Leistungsmerkmale. Verwenden Sie beispielsweise einen Standardtyp für Ihr Sicherungs-Volume und einen SSD-basierten Typ für die Volumes /hana/log und /hana/data, da sie eine höhere Leistung erfordern. Verwenden Sie zum Migrieren zwischen Speichertypen den Volume-Snapshot, erstellen Sie dann mit dem Snapshot ein neues Volume und wählen Sie einen anderen Speichertyp aus. |
| SAP HANA in eine andere Region oder Zone migrieren | Verwenden Sie Snapshots, um Ihr SAP HANA-System von einer Zone in eine andere Zone in derselben Region oder sogar in eine andere Region zu verschieben. Snapshots können global innerhalb vonGoogle Cloud verwendet werden, um Laufwerke in einer anderen Zone oder Region zu erstellen. Um in eine andere Region oder Zone zu wechseln, erstellen Sie einen Snapshot Ihrer Laufwerke, einschließlich des Root-Laufwerks. Dann erstellen Sie die virtuellen Maschinen in Ihrer gewünschten Zone oder Region mit Laufwerken, die aus diesen Snapshots erstellt wurden. |
Laufwerkseinstellungen ändern
Sie können die bereitgestellten IOPS oder den bereitgestellten Durchsatz ändern oder die Größe der Hyperdisk-Volumes einmal alle vier Stunden erhöhen.
Wenn Sie versuchen, das Laufwerk noch einmal zu ändern, bevor die vier Stunden abgelaufen sind, erhalten Sie die Meldung Ratenbegrenzung wie Cannot update provisioned throughput due to being rate limited.
Um diese Fehler zu beheben, warten Sie nach der letzten Änderung vier Stunden, bevor Sie versuchen, das Laufwerk noch einmal zu ändern.
Verwenden Sie dieses Verfahren nur in Notfällen, wenn Sie nicht vier Stunden warten können, um die Laufwerkgröße, die bereitgestellten IOPS oder den Durchsatz der Hyperdisk-Volumes anzupassen.
Führen Sie die folgenden Schritte aus, um die Laufwerkseinstellungen zu ändern:
Stoppen Sie Ihre SAP HANA-Instanz mit einem der folgenden Befehle:
HDB stopsapcontrol -nr INSTANCE_NUMBER -function StopSystem HDB
Ersetzen Sie
INSTANCE_NUMBERdurch die Instanznummer für Ihr SAP HANA-System.Weitere Informationen finden Sie unter SAP HANA-Systeme starten und beenden.
Erstellen Sie einen Snapshot oder ein Image Ihres vorhandenen Laufwerks:
Snapshot-basierte Sicherung
gcloud compute snapshots create SNAPSHOT_NAME \ --project=PROJECT_NAME \ --source-disk=SOURCE_DISK_NAME \ --source-disk-zone=ZONE \ --storage-location=LOCATIONErsetzen Sie Folgendes:
SNAPSHOT_NAME: Name des Snapshots, den Sie erstellen möchten.PROJECT_NAME: der Name Ihres Google Cloud Projekts.SOURCE_DISK_NAME: das Quelllaufwerk, das zum Erstellen des Snapshots verwendet wurde.ZONE: Zone des Quelllaufwerks, mit dem der Vorgang ausgeführt werden soll.LOCATION: Cloud Storage-Speicherort, entweder regional oder multiregional, an dem der Snapshot-Inhalt gespeichert werden soll.Weitere Informationen finden Sie unter Laufwerk-Snapshots erstellen und verwalten.
Image-basierte Sicherung
gcloud compute images create IMAGE_NAME \ --project=PROJECT_NAME \ --source-disk=SOURCE_DISK_NAME \ --source-disk-zone=ZONE \ --storage-location=LOCATIONErsetzen Sie Folgendes:
IMAGE_NAMEist der Name des Laufwerks-Images, das Sie erstellen möchten.PROJECT_NAME: der Name Ihres Google Cloud Projekts.SOURCE_DISK_NAMEist das Quelllaufwerk, das zum Erstellen des Images verwendet wurde.ZONE: Zone des Quelllaufwerks, mit dem der Vorgang ausgeführt werden soll.LOCATION: Cloud Storage-Speicherort, entweder regional oder multiregional, an dem Bildinhalte gespeichert werden sollen.Weitere Informationen finden Sie unter Benutzerdefinierte Images erstellen.
Erstellen Sie ein neues Laufwerk anhand dieses Snapshots oder Images.
Achten Sie bei Hyperdisk-Volumes darauf, dass Sie die Laufwerksgröße, den IOPS-Wert und den Durchsatz angeben, um Ihre Arbeitslastanforderungen zu erfüllen. Weitere Informationen zur Bereitstellung von IOPS und Durchsatz für Hyperdisk finden Sie unter Informationen zur bereitgestellten Leistung für Hyperdisk.
Aus einem Snapshot
gcloud compute disks create NEW_DISK_NAME \ --project=PROJECT_NAME \ --type=DISK_TYPE \ --size=DISK_SIZE \ --zone=ZONE \ --source-snapshot=SOURCE_SNAPSHOT_NAME \ --provisioned-iops=IOPS \ --provisioned-throughput=THROUGHPUTErsetzen Sie Folgendes:
NEW_DISK_NAME: Name des Laufwerks, das Sie erstellen möchten.PROJECT_NAME: der Name Ihres Google Cloud Projekts.DISK_TYPE: der zu erstellende LaufwerkstypDISK_SIZE: Größe des Laufwerks.ZONE: Zone der zu erstellenden Laufwerke.SOURCE_SNAPSHOTist der Quell-Snapshot, der zum Erstellen der Laufwerke verwendet wird.IOPS: Bereitgestellte IOPS des Laufwerks, das erstellt werden soll.THROUGHPUT: bereitgestellter Durchsatz des zu erstellenden Laufwerks.
Über ein Bild
gcloud compute disks create NEW_DISK_NAME \ --project=PROJECT_NAME \ --type=DISK_TYPE \ --size=DISK_SIZE \ --zone=ZONE \ --image=SOURCE_IMAGE_NAME \ --image-project=IMAGE_PROJECT_NAME \ --provisioned-iops=IOPS \ --provisioned-throughput=THROUGHPUTErsetzen Sie Folgendes:
NEW_DISK_NAME: Name des Laufwerks, das Sie erstellen möchten.PROJECT_NAME: der Name Ihres Google Cloud Projekts.DISK_TYPE: der zu erstellende LaufwerkstypDISK_SIZE: Größe des Laufwerks.ZONE: Zone der zu erstellenden Laufwerke.SOURE_IMAGE_NAME: das Quell-Image, das auf die zu erstellenden Laufwerke angewendet werden soll.IMAGE_PROJECT_NAME: das Google Cloud Projekt, auf das sich alle Verweise auf Images und Image-Familien beziehen.IOPS: Bereitgestellte IOPS des Laufwerks, das erstellt werden soll.THROUGHPUT: bereitgestellter Durchsatz des zu erstellenden Laufwerks.
Weitere Informationen zu
gcloud compute disks create.Trennen Sie das vorhandene Laufwerk von Ihrem SAP HANA-System:
gcloud compute instances detach-disk INSTANCE_NAME \ --disk OLD_DISK_NAME \ --zone ZONE \ --project PROJECT_NAMEErsetzen Sie Folgendes:
INSTANCE_NAME: Name der Instanz, die verwendet werden soll.OLD_DISK_NAME: Das Laufwerk, das anhand seines Ressourcennamens getrennt werden soll.ZONE: Zone der Instanz, die verwendet werden soll.PROJECT_NAME: der Name Ihres Google Cloud Projekts.
Weitere Informationen finden Sie unter
gcloud compute instances detach-disk.Hängen Sie das neue Laufwerk an Ihr SAP HANA-System an:
gcloud compute instances attach-disk INSTANCE_NAME \ --disk NEW_DISK_NAME \ --zone ZONE \ --project PROJECT_NAMEErsetzen Sie Folgendes:
INSTANCE_NAME: Name der Instanz, die verwendet werden soll.NEW_DISK_NAME: durch den Namen des Laufwerks, das an die Instanz angehängt werden soll.ZONE: Zone der Instanz, die verwendet werden soll.PROJECT_NAME: der Name Ihres Google Cloud Projekts.
Weitere Informationen finden Sie unter
gcloud compute instances attach-disk.Prüfen Sie, ob die Bereitstellungspunkte korrekt angehängt sind:
lsblkDie Ausgabe sollte in etwa so aussehen:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT ... sdd 8:48 0 1T 0 disk └─vg_hana_shared-shared 254:0 0 1024G 0 lvm /hana/shared sde 8:64 0 32G 0 disk └─vg_hana_usrsap-usrsap 254:3 0 32G 0 lvm /usr/sap sdf 8:80 0 13.8T 0 disk └─vg_hana_data-data 254:1 0 13.8T 0 lvm /hana/data sdg 8:96 0 512G 0 disk └─vg_hana_log-log 254:2 0 512G 0 lvm /hana/logStarten Sie Ihre SAP HANA-Instanz mit einem der folgenden Befehle:
HDB startsapcontrol -nr INSTANCE_NUMBER -function StartSystem HDB
Ersetzen Sie
INSTANCE_NUMBERdurch die Instanznummer für Ihr SAP HANA-System.Weitere Informationen finden Sie unter SAP HANA-Systeme starten und beenden.
Prüfen Sie die Laufwerkgröße, die IOPS und den Durchsatz Ihres neuen Hyperdisk-Volumes:
gcloud compute disks describe DISK_NAME \ --zone ZONE \ --project PROJECT_NAMEErsetzen Sie Folgendes:
DISK_NAME: Name des zu beschreibenden Laufwerks.ZONE: Zone des zu beschreibenden Laufwerks.PROJECT_NAME: der Name Ihres Google Cloud Projekts.
Weitere Informationen finden Sie unter
gcloud compute disks describe.
SAP HANA-System klonen
Sie können Snapshots eines vorhandenen SAP HANA-Systems in Google Cloud erstellen, um einen genauen Klon des Systems zu erstellen.
So klonen Sie ein SAP HANA-System mit einzelnem Host:
Erstellen Sie einen Snapshot Ihrer Daten und Sicherungslaufwerke.
Erstellen Sie mithilfe der Snapshots neue Laufwerke.
Rufen Sie in der Google Cloud Console die Seite VM-Instanzen auf.
Klicken Sie auf die zu klonende Instanz, um die Detailseite der Instanz zu öffnen, und klicken Sie anschließend auf Klonen.
Fügen Sie die Laufwerke hinzu, die aus den Snapshots erstellt wurden.
So klonen Sie ein SAP HANA-System mit mehreren Hosts:
Stellen Sie ein neues SAP HANA-System mit derselben Konfiguration wie das SAP HANA-System bereit, das Sie klonen möchten.
Führen Sie eine Datensicherung des ursprünglichen Systems durch.
Stellen Sie die Sicherung des ursprünglichen Systems auf dem neuen System wieder her.
gcloud CLI installieren und aktualisieren
Nach der Bereitstellung einer VM für SAP HANA und der Installation des Betriebssystems ist eine aktuelle Google Cloud CLI für verschiedene Zwecke erforderlich, z. B. zum Übertragen von Dateien zu und von Cloud Storage, zur Interaktion mit Netzwerkdiensten usw.
Wenn Sie den Anleitungen im Bereitstellungsleitfaden für SAP HANA folgen, wird die gcloud CLI automatisch installiert.
Wenn Sie jedoch Ihr eigenes Betriebssystem als benutzerdefiniertes Image in Google Cloud übertragen oder ein älteres öffentliches Image verwenden, das vonGoogle Cloudbereitgestellt wird, müssen Sie möglicherweise die gcloud CLI selbst installieren oder aktualisieren.
Wenn Sie prüfen möchten, ob die gcloud CLI installiert ist und ob Updates verfügbar sind, öffnen Sie ein Terminal oder eine Eingabeaufforderung und geben Sie Folgendes ein:
gcloud version
Wenn der Befehl nicht erkannt wird, ist die gcloud CLI nicht installiert.
Folgen Sie der Anleitung in gcloud CLI installieren, um die gcloud CLI zu installieren.
So ersetzen Sie Version 140 oder eine frühere Version der SLES-integrierten gcloud CLI:
Melden Sie sich mit
sshbei der VM an.Wechseln Sie zum Superuser:
sudo suGeben Sie die folgenden Befehle ein:
bash <(curl -s https://dl.google.com/dl/cloudsdk/channels/rapid/install_google_cloud_sdk.bash) --disable-prompts --install-dir=/usr/local update-alternatives --install /usr/bin/gsutil gsutil /usr/local/google-cloud-sdk/bin/gsutil 1 --force update-alternatives --install /usr/bin/gcloud gcloud /usr/local/google-cloud-sdk/bin/gcloud 1 --force gcloud --quiet compute instances list
SAP HANA Fast Restart aktivieren
Google Cloud Wir empfehlen dringend, SAP HANA Fast Restart für jede Instanz von SAP HANA zu aktivieren, insbesondere bei größeren Instanzen. SAP HANA Fast Restart verkürzt die Neustartzeit, wenn SAP HANA beendet wird, das Betriebssystem jedoch weiter ausgeführt wird.
In der Konfiguration der von Google Cloud bereitgestellten Automatisierungsscripts unterstützen die Betriebssystem- und Kerneleinstellungen bereits SAP HANA Fast Restart.
Sie müssen das tmpfs-Dateisystem definieren und SAP HANA konfigurieren.
Zum Definieren des Dateisystems tmpfs und zum Konfigurieren von SAP HANA können Sie den manuellen Schritten folgen oder das vonGoogle Cloud bereitgestellte Automatisierungsskript verwenden, um SAP HANA Fast Restart zu aktivieren. Weitere Informationen finden Sie hier:
- Manuelle Schritte: SAP HANA Fast Restart aktivieren
- Automatisierte Schritte: SAP HANA Fast Restart aktivieren
Die Anleitungen für SAP HANA Fast Restart finden Sie in der Dokumentation zu SAP HANA Fast Restart.
Manuelle Schritte
tmpfs-Dateisystem konfigurieren
Nachdem die Host-VMs und die SAP HANA-Basissysteme erfolgreich bereitgestellt wurden, müssen Sie Verzeichnisse für die NUMA-Knoten im tmpfs-Dateisystem erstellen und bereitstellen.
NUMA-Topologie Ihrer VM anzeigen lassen
Bevor Sie das erforderliche tmpfs-Dateisystem zuordnen können, müssen Sie wissen, wie viele NUMA-Knoten Ihre VM hat. Geben Sie den folgenden Befehl ein, um die verfügbaren NUMA-Knoten auf einer Compute Engine-VM anzeigen zu lassen:
lscpu | grep NUMA
Der VM-Typ m2-ultramem-208 hat beispielsweise vier NUMA-Knoten mit der Nummerierung 0–3, wie im folgenden Beispiel gezeigt:
NUMA node(s): 4 NUMA node0 CPU(s): 0-25,104-129 NUMA node1 CPU(s): 26-51,130-155 NUMA node2 CPU(s): 52-77,156-181 NUMA node3 CPU(s): 78-103,182-207
NUMA-Knotenverzeichnisse erstellen
Erstellen Sie ein Verzeichnis für jeden NUMA-Knoten in Ihrer VM und legen Sie die Berechtigungen fest.
Beispiel für vier NUMA-Knoten mit der Nummerierung 0–3:
mkdir -pv /hana/tmpfs{0..3}/SID
chown -R SID_LCadm:sapsys /hana/tmpfs*/SID
chmod 777 -R /hana/tmpfs*/SIDNUMA-Knotenverzeichnisse unter tmpfs bereitstellen
Stellen Sie die Verzeichnisse des tmpfs-Dateisystems bereit und geben Sie für mpol=prefer jeweils eine NUMA-Knoteneinstellung an:
SID: Geben Sie die SID in Großbuchstaben an.
mount tmpfsSID0 -t tmpfs -o mpol=prefer:0 /hana/tmpfs0/SID mount tmpfsSID1 -t tmpfs -o mpol=prefer:1 /hana/tmpfs1/SID mount tmpfsSID2 -t tmpfs -o mpol=prefer:2 /hana/tmpfs2/SID mount tmpfsSID3 -t tmpfs -o mpol=prefer:3 /hana/tmpfs3/SID
/etc/fstab aktualisieren
Fügen Sie der Dateisystemtabelle /etc/fstab Einträge hinzu, damit die Bereitstellungspunkte nach dem Neustart eines Betriebssystems verfügbar sind:
tmpfsSID0 /hana/tmpfs0/SID tmpfs rw,nofail,relatime,mpol=prefer:0 tmpfsSID1 /hana/tmpfs1/SID tmpfs rw,nofail,relatime,mpol=prefer:1 tmpfsSID1 /hana/tmpfs2/SID tmpfs rw,nofail,relatime,mpol=prefer:2 tmpfsSID1 /hana/tmpfs3/SID tmpfs rw,nofail,relatime,mpol=prefer:3
Optional: Limits für die Speichernutzung festlegen
Das tmpfs-Dateisystem kann dynamisch wachsen und schrumpfen.
Wenn Sie den vom tmpfs-Dateisystem verwendeten Speicher begrenzen möchten, können Sie mit der Option size eine Größenbeschränkung für ein NUMA-Knoten-Volume festlegen.
Beispiel:
mount tmpfsSID0 -t tmpfs -o mpol=prefer:0,size=250G /hana/tmpfs0/SID
Sie können auch die tmpfs-Speichernutzung für alle NUMA-Knoten für eine bestimmte SAP-HANA-Instanz und einen bestimmten Serverknoten begrenzen, indem Sie den Parameter persistent_memory_global_allocation_limit im Abschnitt [memorymanager] der Datei global.ini festlegen.
SAP HANA-Konfiguration für Fast Restart
Um SAP HANA für Fast Restart zu konfigurieren, aktualisieren Sie die Datei global.ini und geben Sie die Tabellen an, die im nichtflüchtigen Speicher gespeichert werden sollen.
Aktualisieren Sie den Abschnitt [persistence] in der Datei global.ini.
Konfigurieren Sie den Abschnitt [persistence] in der SAP HANA-Datei global.ini, um auf die tmpfs-Standorte zu verweisen. Trennen Sie die einzelnen tmpfs-Standorte durch ein Semikolon:
[persistence] basepath_datavolumes = /hana/data basepath_logvolumes = /hana/log basepath_persistent_memory_volumes = /hana/tmpfs0/SID;/hana/tmpfs1/SID;/hana/tmpfs2/SID;/hana/tmpfs3/SID
Im vorherigen Beispiel werden vier Arbeitsspeicher-Volumes für vier NUMA-Knoten angegeben, die m2-ultramem-208 entspricht. Bei der Ausführung auf m2-ultramem-416 müssten Sie acht Arbeitsspeicher-Volumes (0..7) konfigurieren.
Starten Sie SAP HANA neu, nachdem Sie die Datei global.ini geändert haben.
SAP HANA kann jetzt den Standort tmpfs als nichtflüchtigen Speicherbereich verwenden.
Tabellen angeben, die im nichtflüchtigen Speicher gespeichert werden sollen
Geben Sie bestimmte Spaltentabellen oder Partitionen an, die im nichtflüchtigen Speicher gespeichert werden sollen.
Wenn Sie beispielsweise nichtflüchtigen Speicher für eine vorhandene Tabelle aktivieren möchten, führen Sie diese SQL-Abfrage aus:
ALTER TABLE exampletable persistent memory ON immediate CASCADE
Um den Standardwert für neue Tabellen zu ändern, fügen Sie den Parameter table_default zur Datei indexserver.ini hinzu. Beispiel:
[persistent_memory] table_default = ON
Weitere Informationen zur Steuerung von Spalten, Tabellen und dazu, welche Monitoringansichten detaillierte Informationen enthalten, finden Sie unter Nichtflüchtiger SAP HANA-Speicher.
Automatisierte Schritte
Das von Google Cloud bereitgestellte Automatisierungsskript zum Aktivieren von SAP HANA Fast Restart nimmt Änderungen an den Verzeichnissen /hana/tmpfs*, der Datei /etc/fstab und der SAP HANA-Konfiguration vor. Wenn Sie das Script ausführen, müssen Sie möglicherweise zusätzliche Schritte ausführen, je nachdem, ob es sich um die anfängliche Bereitstellung Ihres SAP HANA-Systems handelt oder Sie die Größe Ihrer Maschine in eine andere NUMA-Größe ändern.
Achten Sie bei der ersten Bereitstellung Ihres SAP HANA-Systems oder bei der Größenanpassung der Maschine zur Erhöhung der Anzahl der NUMA-Knoten darauf, dass SAP HANA während der Ausführung des Automatisierungsskripts ausgeführt wird, das Google Cloudzur Aktivierung von SAP HANA Fast Restart bereitstellt.
Wenn Sie die Größe der Maschine ändern, um die Anzahl der NUMA-Knoten zu verringern, müssen Sie darauf achten, dass SAP HANA während der Ausführung des Automatisierungsskripts gestoppt wird, das Google Cloud zur Aktivierung von SAP HANA Fast Restart bereitstellt. Nachdem das Script ausgeführt wurde, müssen Sie die SAP HANA-Konfiguration manuell aktualisieren, um die Einrichtung von SAP HANA Fast Restart abzuschließen. Weitere Informationen finden Sie unter SAP HANA-Konfiguration für Fast Restart.
So aktivieren Sie SAP HANA Fast Restart:
Stellen Sie eine SSH-Verbindung zu Ihrer Host-VM her.
Wechseln Sie zum Root:
sudo su -
Laden Sie das
sap_lib_hdbfr.sh-Skript herunter:wget https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/lib/sap_lib_hdbfr.sh
Machen Sie die Datei ausführbar:
chmod +x sap_lib_hdbfr.sh
Prüfen Sie, ob das Script Fehler enthält:
vi sap_lib_hdbfr.sh ./sap_lib_hdbfr.sh -help
Wenn der Befehl einen Fehler zurückgibt, wenden Sie sich an Cloud Customer Care. Weitere Informationen zur Kontaktaufnahme mit Customer Care finden Sie unter Support für SAP in Google Cloud.
Führen Sie das Script aus, nachdem Sie die SAP HANA-System-ID (SID) und das Passwort für den SYSTEM-Nutzer der SAP HANA-Datenbank ersetzt haben. Damit Sie das Passwort sicher bereitstellen können, empfehlen wir die Verwendung eines Secrets in Secret Manager.
Führen Sie das Script mit dem Namen eines Secrets in Secret Manager aus. Dieses Secret muss in dem Google Cloud Projekt vorhanden sein, das Ihre Host-VM-Instanz enthält.
sudo ./sap_lib_hdbfr.sh -h 'SID' -s SECRET_NAME
Ersetzen Sie Folgendes:
SID: Geben Sie die SID in Großbuchstaben an. Beispiel:AHA.SECRET_NAME: Geben Sie den Namen des Secrets an, das dem Passwort für den SYSTEM-Nutzer der SAP HANA-Datenbank entspricht. Dieses Secret muss in dem Google Cloud Projekt vorhanden sein, das Ihre Host-VM-Instanz enthält.
Alternativ können Sie das Script mit einem Nur-Text-Passwort ausführen. Nachdem SAP HANA Fast Restart aktiviert wurde, müssen Sie Ihr Passwort ändern. Die Verwendung eines Nur-Text-Passworts wird nicht empfohlen, da Ihr Passwort im Befehlszeilenverlauf Ihrer VM aufgezeichnet werden würde.
sudo ./sap_lib_hdbfr.sh -h 'SID' -p 'PASSWORD'
Ersetzen Sie Folgendes:
SID: Geben Sie die SID in Großbuchstaben an. Beispiel:AHA.PASSWORD: Geben Sie das Passwort für den SYSTEM-Nutzer der SAP HANA-Datenbank an.
Bei einer erfolgreichen ersten Ausführung sollte die Ausgabe in etwa so aussehen:
INFO - Script is running in standalone mode
ls: cannot access '/hana/tmpfs*': No such file or directory
INFO - Setting up HANA Fast Restart for system 'TST/00'.
INFO - Number of NUMA nodes is 2
INFO - Number of directories /hana/tmpfs* is 0
INFO - HANA version 2.57
INFO - No directories /hana/tmpfs* exist. Assuming initial setup.
INFO - Creating 2 directories /hana/tmpfs* and mounting them
INFO - Adding /hana/tmpfs* entries to /etc/fstab. Copy is in /etc/fstab.20220625_030839
INFO - Updating the HANA configuration.
INFO - Running command: select * from dummy
DUMMY
"X"
1 row selected (overall time 4124 usec; server time 130 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('persistence', 'basepath_persistent_memory_volumes') = '/hana/tmpfs0/TST;/hana/tmpfs1/TST;'
0 rows affected (overall time 3570 usec; server time 2239 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('persistent_memory', 'table_unload_action') = 'retain';
0 rows affected (overall time 4308 usec; server time 2441 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('indexserver.ini', 'SYSTEM') SET ('persistent_memory', 'table_default') = 'ON';
0 rows affected (overall time 3422 usec; server time 2152 usec)
SAP-Supportkanal mit SAProuter einrichten
Wenn Sie einem SAP-Supportmitarbeiter Zugriff auf Ihre SAP HANA-Systeme inGoogle Cloudgewähren müssen, können Sie dies mit SAProuter tun. Gehen Sie so vor:
Starten Sie die Compute Engine VM-Instanz, auf der die SAProuter-Software installiert werden soll, und weisen Sie eine externe IP-Adresse zu, damit die Instanz über Internetzugang verfügt.
Erstellen Sie eine neue statische externe IP-Adresse und weisen Sie diese IP-Adresse der Instanz zu.
Erstellen und konfigurieren Sie eine bestimmte SAProuter-Firewallregel in Ihrem Netzwerk. Lassen Sie in dieser Regel nur den erforderlichen eingehenden und ausgehenden Zugriff auf das SAP-Support-Netzwerk für die SAProuter-Instanz zu.
Begrenzen Sie den eingehenden und ausgehenden Zugriff auf eine bestimmte IP-Adresse, die SAP Ihnen für die Verbindung zur Verfügung stellt, zusammen mit dem TCP-Port
3299. Fügen Sie Ihrer Firewallregel ein Ziel-Tag hinzu und geben Sie Ihren Instanznamen ein. Damit sorgen Sie dafür, dass die Firewallregel nur für die neue Instanz gilt. Weitere Informationen zum Erstellen und Konfigurieren von Firewallregeln finden Sie in der Dokumentation zu Firewallregeln.Installieren Sie die SAProuter-Software gemäß SAP-Hinweis 1628296 und erstellen Sie eine
saprouttab-Datei, die den Zugriff von SAP auf Ihre SAP HANA-Systeme auf Google Cloudermöglicht.Richten Sie die Verbindung mit SAP ein. Verwenden Sie für Ihre Internetverbindung die sichere Netzwerkkommunikation. Weitere Informationen finden Sie unter SAP Fernwartung – Hilfe.
Netzwerk konfigurieren
Sie stellen Ihr SAP HANA-System mithilfe von VMs mit dem virtuellenGoogle Cloud -Netzwerk bereit. Google Cloud nutzt ein hochentwickeltes softwarebasiertes Netzwerk und die Technologien verteilter Systeme zum weltweiten Hosten und Bereitstellen Ihrer Dienste.
Für SAP HANA erstellen Sie ein nicht standardmäßiges Subnetz mit nicht überlappenden CIDR-IP-Adressbereichen für jedes Subnetz im Netzwerk. Beachten Sie, dass jedes Subnetzwerk und seine internen IP-Adressbereiche einer einzelnen Region zugeordnet sind.
Ein Subnetzwerk erstreckt sich über alle Zonen in der Region, in der es erstellt wird.
Wenn Sie jedoch eine VM-Instanz erstellen, geben Sie eine Zone und ein Subnetzwerk für die VM an. Beispielsweise können Sie eine Instanzgruppe in subnetwork1 und zone1 von region1 und eine weitere Instanzgruppe in subnetwork2 und zone2 von region1 erstellen, je nach Ihren Anforderungen.
Ein neues Netzwerk hat keine Firewallregeln und somit keinen Netzwerkzugriff. Firewallregeln, die den Zugriff auf Ihre SAP HANA-Instanzen ermöglichen, sollten auf der Grundlage des Modells der geringsten Berechtigung erstellt werden. Die Firewallregeln gelten für das gesamte Netzwerk und können mithilfe des Tagging-Mechanismus auch gezielt für bestimmte Zielinstanzen konfiguriert werden.
Routen sind globale und keine regionalen Ressourcen, die mit einem einzelnen Netzwerk verbunden sind. Von Nutzern erstellte Routen gelten für alle Instanzen in einem Netzwerk. Das bedeutet, dass Sie eine Datenverbindung hinzufügen können, die den Traffic innerhalb eines Netzwerks von einer Instanz zur anderen und sogar subnetzwerkübergreifend weiterleitet, ohne externe IP-Adressen zu benötigen.
Starten Sie für Ihre SAP HANA-Instanz die Instanz ohne externe IP-Adresse und konfigurieren Sie eine weitere VM als NAT-Gateway für den externen Zugriff. Für diese Konfiguration müssen Sie das NAT-Gateway als Route für die SAP HANA-Instanz hinzufügen. Dieses Verfahren wird in der Bereitstellungsanleitung beschrieben.
Sicherheit
In den folgenden Abschnitten werden Sicherheitsvorgänge erläutert.
Modell der geringsten Berechtigung
Ihre erste Verteidigungslinie besteht darin, den Zugang auf die Instanz mithilfe von Firewalls zu beschränken. Mithilfe von Firewallregeln können Sie den gesamten Traffic zu einem Netzwerk oder zu Zielgeräten mit einem bestimmten Satz von Ports auf bestimmte Quell-IP-Adressen beschränken. Folgen Sie dem Modell der geringsten Berechtigung, um den Zugriff auf die jeweiligen IP-Adressen, Protokolle und Ports zu beschränken, die zugänglich sein müssen. So sollten Sie immer einen Bastion Host einrichten und SSH-Verbindungen in das SAP HANA-System nur von diesem Host aus zulassen.
Konfigurationsänderungen
Sie sollten Ihr SAP HANA-System und das Betriebssystem mit den empfohlenen Sicherheitseinstellungen konfigurieren. Achten Sie beispielsweise darauf, dass nur relevante Netzwerkports für den Zugriff aufgelistet werden, verstärken Sie außerdem die Sicherheit des Betriebssystems, auf dem SAP HANA ausgeführt wird, usw.
Weitere Informationen finden Sie in den folgenden SAP-Hinweisen (SAP-Nutzerkonto erforderlich):
- 1944799: Richtlinien für die Installation von SLES SAP HANA
- 1730999: Empfohlene Konfigurationsänderungen
- 1731000: Nicht empfohlene Konfigurationsänderungen
Nicht benötigte SAP HANA-Dienste deaktivieren
Wenn Sie die SAP HANA Extended Application Services (SAP HANA XS) nicht benötigen, deaktivieren Sie den Dienst. Weitere Informationen finden Sie im SAP-Hinweis 1697613: SAP HANA XS Classic Engine-Dienst aus der Topologie entfernen.
Nach dem Deaktivieren des Dienstes entfernen Sie alle TCP-Ports, die für den Dienst geöffnet wurden. In Google Cloudbedeutet dies, dass Sie die Firewallregeln für Ihr Netzwerk bearbeiten, um diese Ports von der Zugriffsliste zu entfernen.
Audit-Logging
Cloud-Audit-Logs bestehen aus zwei Logstreams: einem zu Administratoraktivitäten und einem zum Datenzugriff. Beide werden automatisch von Google Cloudgeneriert. Damit können Sie die Fragen „Wer hat was, wo und wann getan?“ in IhremGoogle Cloud -Projekt beantworten.
Logs der Administratoraktivität enthalten Logeinträge für API-Aufrufe oder Verwaltungsmaßnahmen, die die Konfiguration oder die Metadaten eines Dienstes oder Projekts ändern. Diese Logs sind immer aktiviert und für alle Projektmitglieder sichtbar.
Datenzugriffs-Logs enthalten Logeinträge für API-Aufrufe, die vom Nutzer bereitgestellte Daten, die von einem Dienst verwaltet werden, erstellen, ändern oder lesen, zum Beispiel in einem Datenbankdienst gespeicherte Daten. Diese Art von Logging ist in Ihrem Projekt standardmäßig aktiviert und steht Ihnen über Cloud Logging oder über Ihren Aktivitätsfeed zur Verfügung.
Cloud Storage-Bucket sichern
Wenn Sie Ihre Daten- und Logsicherungen auf Cloud Storage hosten, sollten Sie für die Datenübertragung von Ihren Instanzen zu Cloud Storage unbedingt TLS (HTTPS) verwenden. Damit sind die Daten während der Übertragung geschützt. Cloud Storage verschlüsselt inaktive Daten automatisch. Sie können Ihre eigenen Verschlüsselungsschlüssel angeben, wenn Sie mit einem eigenen Schlüsselverwaltungssystem arbeiten.
Zugehörige Dokumente zum Thema Sicherheit
Zum Thema Sicherheit für Ihre SAP HANA-Umgebung auf Google Cloudstehen Ihnen folgende zusätzliche Ressourcen zur Verfügung:
- Sicherheitscenter
- Compliance in Google Cloud
- Whitepaper zur Sicherheit in Google Cloud
- Sicherheitsdesign der Google-Infrastruktur
Hochverfügbarkeit für SAP HANA auf Google Cloud
Google Cloud bietet eine Vielzahl von Optionen, um eine hohe Verfügbarkeit für Ihr SAP HANA-System zu gewährleisten, einschließlich der Compute Engine-Features für Live-Migration und automatischen Neustart. Diese Features sowie der hohe Prozentsatz der monatlichen Betriebszeit von Compute Engine-VMs machen möglicherweise das Bezahlen und Unterhalten von Standby-Systemen überflüssig.
Bei Bedarf können Sie aber ein horizontal skalierbares System mit mehreren Hosts bereitstellen, das Standby-Hosts für das automatische Failover des SAP HANA-Hosts enthält, oder Sie können ein vertikal skalierbares System mit einer Standby-SAP-HANA-Instanz in einem Linux-Cluster mit Hochverfügbarkeit bereitstellen.
Weitere Informationen zu den Hochverfügbarkeitsoptionen für SAP HANA aufGoogle Cloudfinden Sie im Leitfaden zur Planung der Hochverfügbarkeit für SAP HANA.
Provider-Hook SAP HANA-HA/DR aktivieren
SUSE empfiehlt, die Provider-Hooks für SAP HANA-HA/DR zu aktivieren. Dadurch kann SAP HANA Benachrichtigungen für bestimmte Ereignisse senden und die Fehlererkennung verbessern.
Die Provider-Hooks für SAP HANA HA/DR erfordern SAP HANA 2.0 SPS 03 oder höher für den SAPHanaSR-Hook und SAP HANA 2.0 SPS 05 oder höher für den SAPHanaSR-angi-Hook.
Führen Sie sowohl auf der primären als auch auf der sekundären Website die folgenden Schritte aus:
Öffnen Sie als Root oder
SID_LCadmdie Dateiglobal.inizur Bearbeitung:>vi /hana/shared/SID/global/hdb/custom/config/global.iniFügen Sie der Datei
global.inidie folgenden Definitionen hinzu:vertikal skalieren
Für SLES for SAP 15 SP5 oder niedriger:
[ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /usr/share/SAPHanaSR/ execution_order = 1 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR/ execution_order = 3 action_on_lost = stop [trace] ha_dr_saphanasr = info
Für SLES for SAP 15 SP6 oder höher:
[ha_dr_provider_susHanaSR] provider = susHanaSR path = /usr/share/SAPHanaSR-angi execution_order = 1 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR-angi execution_order = 3 action_on_lost = stop [ha_dr_provider_susTkOver] provider = susTkOver path = /usr/share/SAPHanaSR-angi execution_order = 1 sustkover_timeout = 30 [trace] ha_dr_sushanasr = info ha_dr_suschksrv = info ha_dr_sustkover = info
Hochskalieren
Für SLES for SAP 15 SP5 oder niedriger:
[ha_dr_provider_saphanasrmultitarget] provider = SAPHanaSrMultiTarget path = /usr/share/SAPHanaSR-ScaleOut/ execution_order = 1 [ha_dr_provider_sustkover] provider = susTkOver path = /usr/share/SAPHanaSR-ScaleOut/ execution_order = 2 sustkover_timeout = 30 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR-ScaleOut/ execution_order = 3 action_on_lost = stop [trace] ha_dr_saphanasrmultitarget = info ha_dr_sustkover = info
Für SLES for SAP 15 SP6 oder höher:
[ha_dr_provider_susHanaSR] provider = susHanaSR path = /usr/share/SAPHanaSR-angi execution_order = 1 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR-angi execution_order = 3 action_on_lost = stop [ha_dr_provider_susTkOver] provider = susTkOver path = /usr/share/SAPHanaSR-angi execution_order = 1 sustkover_timeout = 30 [trace] ha_dr_sushanasr = info ha_dr_suschksrv = info ha_dr_sustkover = info
Erstellen Sie als Root eine benutzerdefinierte Konfigurationsdatei im Verzeichnis
/etc/sudoers.d. Führen Sie dazu den folgenden Befehl aus. Mit dieser neuen Konfigurationsdatei kann der NutzerSID_LCadmbeim Aufrufen der Hook-MethodesrConnectionChanged()auf die Clusterknotenattribute zugreifen.>visudo -f /etc/sudoers.d/SAPHanaSRFügen Sie in der Datei
/etc/sudoers.d/SAPHanaSRden folgenden Text hinzu:vertikal skalieren
Für SLES for SAP 15 SP5 oder niedriger:
Ersetzen Sie Folgendes:
SITE_A: Standortname des primären SAP HANA-Servers.SITE_B: Standortname des sekundären SAP HANA-Servers.SID_LC: die SID, die in Kleinbuchstaben angegeben wird
crm_mon -A1 | grep siteals Root-Nutzer entweder auf dem primären SAP HANA-Server oder auf dem sekundären Server ausführen.Cmnd_Alias SOK_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SOK_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SFAIL -t crm_config -s SAPHanaSR SID_LCadm ALL=(ALL) NOPASSWD: SOK_SITEA, SFAIL_SITEA, SOK_SITEB, SFAIL_SITEB
Für SLES for SAP 15 SP6 oder höher:
Ersetzen Sie Folgendes:
SITE_A: Standortname des primären SAP HANA-Servers.SITE_B: Standortname des sekundären SAP HANA-Servers.SID_LC: die SID, die in Kleinbuchstaben angegeben wird
crm_mon -A1 | grep siteals Root-Nutzer entweder auf dem primären SAP HANA-Server oder auf dem sekundären Server ausführen.Cmnd_Alias SOK_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SOK_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias HOOK_HELPER = /usr/bin/SAPHanaSR-hookHelper --sid=SID --case=* SID_LCadm ALL=(ALL) NOPASSWD: SOK_SITEA, SFAIL_SITEA, SOK_SITEB, SFAIL_SITEB
Hochskalieren
Für SLES for SAP 15 SP5 oder niedriger:
Ersetzen Sie
SID_LCdurch die SID in Kleinbuchstaben.SID_LCadm ALL=(ALL) NOPASSWD: /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_* SID_LCadm ALL=(ALL) NOPASSWD: /usr/sbin/crm_attribute -n hana_SID_LC_gsh * SID_LCadm ALL=(ALL) NOPASSWD: /usr/sbin/SAPHanaSR-hookHelper --sid=SID_LC *
Für SLES for SAP 15 SP6 oder höher:
Ersetzen Sie Folgendes:
SITE_A: Standortname des primären SAP HANA-Servers.SITE_B: Standortname des sekundären SAP HANA-Servers.SID_LC: die SID, die in Kleinbuchstaben angegeben wird
crm_mon -A1 | grep siteals Root-Nutzer entweder auf dem primären SAP HANA-Server oder auf dem sekundären Server ausführen.Cmnd_Alias SOK_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SOK_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SFAIL -t crm_config -s SAPHanaSR SID_LCadm ALL=(ALL) NOPASSWD: /usr/bin/SAPHanaSR-hookHelper --sid=SID --case=* SID_LCadm ALL=(ALL) NOPASSWD: SOK_SITEA, SFAIL_SITEA, SOK_SITEB, SFAIL_SITEB
Achten Sie darauf, dass in der Datei
/etc/sudoersder folgende Text enthalten ist:Für SLES for SAP 15 SP3 oder höher:
@includedir /etc/sudoers.d
Für Versionen bis SLES for SAP 15 SP2:
#includedir /etc/sudoers.d
Beachten Sie, dass die Datei
#in diesem Text Teil der Syntax ist und nicht bedeutet, dass die Zeile ein Kommentar ist.
Versetzen Sie Pacemaker in den Wartungsmodus:
>crm configure property maintenance-mode=trueÄnderungen anwenden:
HANA SPS4 und höher
Als SID_LCadm lädt die Änderung sowohl auf den primären als auch auf den sekundären Master-SAP HANA-Knoten.
>hdbnsutil -reloadHADRProvidersMit einer der folgenden Optionen können Sie die Ausfallzeit Ihrer Hauptwebsite vermeiden oder minimieren:
Option 1
Als SID_LCadm startet die sekundäre Website neu.
>HDB restartOption 2
Kontrolliertes Failover von der primären auf die sekundäre ausführen
HANA SPS3
Als SID_LCadm starten sowohl primäre als auch sekundäre SAP HANA-Systeme neu:
>HDB restartDeaktivieren Sie Pacemaker aus dem Wartungsmodus:
>crm configure property maintenance-mode=falseNachdem Sie die Clusterkonfiguration für SAP HANA abgeschlossen haben, können Sie prüfen, ob der Hook während eines Failover-Tests ordnungsgemäß funktioniert, wie unter Fehlerbehebung für den SAPHanaSR-Python-Hook und HA-Cluster-Übernahme dauert zu lange bei einem HANA-Indexserverfehler beschrieben.
Notfallwiederherstellung
Das SAP HANA-System bietet mehrere Hochverfügbarkeitsfeatures, um zu gewährleisten, dass Ihre SAP HANA-Datenbank Fehlern auf Software- oder Infrastrukturebene standhält. Zu diesen Features gehören die SAP HANA-Systemreplikation und SAP HANA-Sicherungen, die beide von Google Cloud unterstützt werden.
Weitere Informationen zu SAP HANA-Sicherungen finden Sie unter Sicherung und Wiederherstellung.
Weitere Informationen zur Systemreplikation finden Sie im Leitfaden zur Notfallwiederherstellung für SAP HANA.
Sicherung und Wiederherstellung
Sicherungen sind für den Schutz Ihres Erfassungssystems (Ihrer Datenbank) von entscheidender Bedeutung. Da es sich bei SAP HANA um eine In-Memory-Datenbank handelt, können Sie durch regelmäßiges Erstellen von Sicherungen und Implementieren einer geeigneten Sicherungsstrategie die SAP HANA-Datenbank in Situationen wie Datenbeschädigung oder -verlust aufgrund eines ungeplanten Ausfalls oder Fehlers in der Infrastruktur wiederherstellen. Das SAP HANA-System bietet integrierte Sicherungs- und Wiederherstellungsfeatures, um Ihnen dabei zu helfen. Sie können Google Cloud-Dienste wie Cloud Storage als Sicherungsziel für die SAP HANA-Sicherung verwenden.
Sie können auch das Backint-Feature des Google Cloud-Agents für SAP aktivieren, damit Sie Cloud Storage direkt für Sicherungen und Wiederherstellungen verwenden können.
Informationen zu Sicherungs- und Wiederherstellungsempfehlungen für SAP HANA-Systeme, die auf Compute Engine-Bare-Metal-Instanzen wie X4 ausgeführt werden, finden Sie unter Sicherung und Wiederherstellung für SAP HANA auf Bare-Metal-Instanzen.
In diesem Dokument wird davon ausgegangen, dass Sie mit der Sicherung und Wiederherstellung von SAP HANA sowie den folgenden SAP-Service-Hinweisen vertraut sind:
- 1642148: FAQ: SAP HANA-Datenbanksicherung und -wiederherstellung
- 1821207: Erforderliche Wiederherstellungsdateien ermitteln
- 1869119: Sicherungen mit
hdbbackupcheckprüfen - 1873247: Wiederherstellbarkeit mit
hdbbackupdiag --checkprüfen - 1651055: SAP HANA-Datenbanksicherungen unter Linux planen
Persistent Disk-Volumes von Compute Engine und Cloud Storage für Sicherungen verwenden
Wenn Sie die Terraform-basierte Bereitstellungsanleitung von Google Cloud zum Bereitstellen Ihres SAP HANA-Systems befolgt haben, haben Sie eine SAP HANA-Installation mit einem gehosteten /hanabackup-Verzeichnis auf einem abgestimmten Persistent Disk-Volume.
Zum Erstellen Ihrer Online-Datenbanksicherungen im Verzeichnis /hanabackup verwenden Sie die SAP-Standardtools wie SAP HANA Studio, SAP HANA Cockpit, SAP ABAP-Transaktion DB13 oder SAP HANA-SQL-Anweisungen. Zum Schluss speichern Sie die fertige Sicherung. Dazu laden Sie sie in einen Cloud Storage-Bucket hoch, von dem Sie die Sicherung herunterladen können, wenn Sie Ihr SAP HANA-System wiederherstellen müssen.
Compute Engine zum Erstellen von Sicherungen und Laufwerk-Snapshots verwenden
Sie können Compute Engine für SAP HANA-Sicherungen verwenden und haben außerdem die Option, das gesamte Laufwerk, das Ihre SAP HANA-Daten- und -Log-Volumes hostet, mithilfe von Standard-Laufwerk-Snapshots zu sichern.
Wenn Sie dem Bereitstellungsleitfaden gefolgt sind, haben Sie eine SAP HANA-Installation mit einem Verzeichnis /hanabackup für Ihre Online-Datenbanksicherungen. Sie können dasselbe Verzeichnis verwenden, um Snapshots des Volumes /hanabackup zu speichern und eine Sicherung Ihrer SAP HANA-Daten- und -Log-Volumes zu einem bestimmten Zeitpunkt zu verwalten.
Ein Vorteil von Standard-Laufwerk-Snapshots besteht darin, dass sie inkrementell sind und bei jeder folgenden Sicherung nur inkrementelle Blockänderungen gespeichert werden, anstatt eine völlig neue Sicherung zu erstellen. Compute Engine speichert redundant mehrere Kopien jedes Snapshots verteilt über mehrere Speicherorte mit automatischen Prüfsummen, um die Integrität der Daten zu gewährleisten.
Hier sehen Sie eine Illustration der inkrementellen Sicherungen:
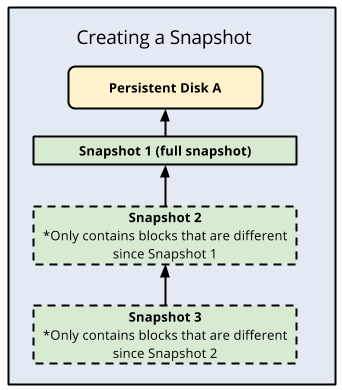
Cloud Storage als Sicherungsziel
Cloud Storage ist eine gute Wahl als Sicherungsziel für SAP HANA, da eine hohe Lebensdauer und Verfügbarkeit der Daten gewährleistet wird.
Cloud Storage ist ein Objektspeicher für Dateien beliebigen Typs oder Formats. Der Speicher ist praktisch unbegrenzt und Sie müssen sich keine Gedanken über die Bereitstellung oder das Hinzufügen weiterer Kapazitäten machen. Ein Objekt in Cloud Storage besteht aus Dateidaten sowie den zugehörigen Metadaten und kann bis zu 5 TB groß sein. In einem Cloud Storage-Bucket können beliebig viele Objekte gespeichert werden.
Mit Cloud Storage werden Ihre Daten an mehreren Standorten gespeichert, wodurch Langlebigkeit und hohe Verfügbarkeit gewährleistet werden. Wenn Sie Ihre Daten in Cloud Storage hochladen oder innerhalb von Cloud Storage kopieren, werden diese Vorgänge von Cloud Storage nur dann als erfolgreich verzeichnet, wenn Objektredundanz erzielt wurde.
Die folgende Tabelle zeigt die von Cloud Storage angebotenen Speicheroptionen:
| Häufigkeit der Lese-/Schreibvorgänge der Daten | Die empfohlene Cloud Storage-Option |
|---|---|
| Häufige Lese- oder Schreibvorgänge | Wählen Sie die Standardspeicherklasse für Datenbanken, die in Verwendung sind, da sie häufig auf Cloud Storage zugreifen, um Sicherungsdateien zu schreiben und zu lesen. |
| Seltene Lese- oder Schreibvorgänge | Wählen Sie Nearline- oder Coldline-Speicher für Daten, auf die nur selten zugegriffen wird, z. B. archivierte Sicherungen, die gemäß der Aufbewahrungsrichtlinie Ihrer Organisation gewartet werden müssen. Nearline ist eine gute Wahl für gesicherte Daten, auf die Sie höchstens einmal im Monat zugreifen möchten, während Coldline für Daten besser geeignet ist, bei denen die Wahrscheinlichkeit eines Zugriffs sehr gering ist, z. B. höchstens einmal pro Jahr. |
| Archivdaten | Wählen Sie Archive Storage für Ihre langfristigen Archivdaten. Archive ist eine gute Wahl für Daten, für die Sie eine Kopie über einen längeren Zeitraum aufbewahren müssen, auf die Sie jedoch nur einmal pro Jahr zugreifen möchten. Verwenden Sie beispielsweise Archive Storage für Sicherungen, die Sie langfristig aufbewahren müssen, um regulatorische Anforderungen zu erfüllen. Denken Sie darüber nach, Ihre auf Band speichernde Sicherungslösung durch Archive zu ersetzen. |
Wenn Sie die Verwendung dieser Speicheroptionen planen, beginnen Sie mit der Ebene, auf die häufig zugegriffen wird, und weisen die älteren Sicherungsdaten den seltenen Zugriffsebenen zu. Sicherungen werden im Allgemeinen umso seltener verwendet, je älter sie werden. Die Wahrscheinlichkeit, dass eine drei Jahre alte Sicherung benötigt wird, ist äußerst gering. Sie können diese Sicherung zur Reduzierung der Kosten in die Archive-Ebene einstufen. Informationen zu Cloud Storage-Kosten finden Sie unter Cloud Storage – Preise.
Cloud Storage im Vergleich zur Bandsicherung
Das herkömmliche lokale Sicherungsziel ist das Band. Cloud Storage bietet gegenüber Band viele Vorteile, einschließlich der Fähigkeit, Sicherungen automatisch "extern" vom Quellsystem zu speichern, da Daten in Cloud Storage über mehrere Einrichtungen hinweg repliziert werden. Dies bedeutet auch, dass die in Cloud Storage gespeicherten Sicherungen hochverfügbar sind.
Ein weiterer wichtiger Unterschied ist die Geschwindigkeit, mit der Sie Sicherungen wiederherstellen können, wenn Sie sie benötigen. Wenn Sie ein neues SAP HANA-System aus einer Sicherung erstellen oder ein vorhandenes System aus einer Sicherung wiederherstellen müssen, bietet Cloud Storage einen schnelleren Zugriff auf Ihre Daten, sodass Sie das System schneller aufbauen können.
Backint-Feature des Google Cloud-Agents für SAP
Sie können Cloud Storage direkt für Sicherungen und Wiederherstellungen sowohl für lokale als auch für Cloud-Installationen verwenden. Dazu verwenden Sie das von SAP zertifizierte Backint-Feature des Google Cloud-Agents für SAP.
Weitere Informationen zu diesem Feature finden Sie unter Backint-basierte Sicherung und Wiederherstellung für SAP HANA.
SAP HANA mit Backint sichern und wiederherstellen
In den folgenden Abschnitten erfahren Sie, wie Sie SAP HANA mit der Funktion Backint des Agents für SAP von Google Cloudsichern und wiederherstellen.
- Daten- und Deltasicherungen auslösen
- Logsicherungen auslösen
- Sicherungskatalog abfragen
- Datenbank wiederherstellen
Daten- und Deltasicherungen auslösen
Wenn Sie eine Sicherung für das SAP HANA-Datenvolume auslösen und mit dem Backint-Feature des Google Cloud-Agents für SAP an Cloud Storage senden möchten, können Sie SAP HANA Studio, SAP HANA Cockpit, SAP HANA SQL oder das DBA Cockpit verwenden.
Im Folgenden finden Sie SAP HANA-SQL-Anweisungen zum Auslösen von Datensicherungen:
So erstellen Sie eine vollständige Sicherung für die Systemdatenbank:
BACKUP DATA USING BACKINT ('BACKUP_NAME');Ersetzen Sie
BACKUP_NAMEdurch den Namen, den Sie für die Sicherung festlegen möchten.So erstellen Sie eine vollständige Sicherung für eine Mandantendatenbank:
BACKUP DATA FOR TENANT_SID USING BACKINT ('BACKUP_NAME');Ersetzen Sie
TENANT_SIDdurch die SID der Mandantendatenbank.So erstellen Sie differenzielle und inkrementelle Sicherungen:
BACKUP DATA BACKUP_TYPE USING BACKINT ('BACKUP_NAME'); BACKUP DATA BACKUP_TYPE FOR TENANT_SID USING BACKINT ('BACKUP_NAME');Ersetzen Sie
BACKUP_TYPEdurchDIFFERENTIALoderINCREMENTAL, je nach Art der Sicherung, die Sie erstellen möchten.
Es gibt mehrere Optionen, die Sie beim Auslösen von Datensicherungen verwenden können. Informationen zu diesen Optionen finden Sie im SAP HANA-SQL-Referenzhandbuch unter Anweisung BACKUP DATA (Sicherung und Wiederherstellung).
Weitere Informationen zu Daten- und Deltasicherungen finden Sie in den SAP-Dokumenten Datensicherungen und Deltasicherungen.
Logsicherungen auslösen
Führen Sie die folgenden Schritte aus, um eine Sicherung für das SAP HANA-Logvolume auszulösen und mit dem Backint-Feature des Agents von Google Cloudfür SAP an Cloud Storage zu senden:
- Eine vollständige Datenbanksicherung erstellen Eine Anleitung finden Sie in der SAP-Dokumentation für Ihre SAP HANA-Version.
- Legen Sie in der SAP HANA-Datei
global.iniden Parametercatalog_backup_using_backintaufyesfest.
Achten Sie darauf, dass der Logmodus für Ihr SAP HANA-System normal ist. Dies ist der Standardwert. Wenn der Logmodus auf overwrite gesetzt ist, deaktiviert die SAP HANA-Datenbank das Erstellen von Logsicherungen.
Weitere Informationen zu Logsicherungen finden Sie im SAP-Dokument Logsicherungen.
Sicherungskatalog abfragen
Der SAP HANA-Sicherungskatalog ist ein wichtiger Bestandteil der Sicherungs- und Wiederherstellungsvorgänge. Er enthält Informationen zu den Sicherungen, die für die SAP HANA-Datenbank erstellt wurden.
Führen Sie die folgenden Schritte aus, um den Sicherungskatalog nach Informationen zu Sicherungen einer Mandantendatenbank abzufragen:
- Schalten Sie die Mandantendatenbank offline.
Führen Sie in der Systemdatenbank die folgende SQL-Anweisung aus:
BACKUP COMPLETE LIST DATA FOR TENANT_SID;
Alternativ können Sie die folgende SQL-Anweisung ausführen, um einen bestimmten Zeitpunkt abzufragen:
BACKUP LIST DATA FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD';
Mit der Anweisung wird die Datei
strategyOutput.xmlim folgenden Verzeichnis erstellt:/usr/sap/SID/HDBINSTANCE_NUMBER/HOST_NAME/trace/DB_TENANT_SID.
Informationen zur BACKUP LIST DATA-Anweisung finden Sie im SAP HANA-SQL-Referenzhandbuch Anweisung BACKUP DATA (Sicherung und Wiederherstellung).
Informationen zum Sicherungskatalog finden Sie im SAP-Dokument Backup Catalog.
Datenbank wiederherstellen
Wenn Sie eine Wiederherstellung mit einer Mehrstream-Datensicherung durchführen, verwendet SAP HANA die gleiche Anzahl von Kanälen, die bei der Erstellung der Sicherung verwendet wurden. Weitere Informationen finden Sie im SAP-Dokument Voraussetzungen: Wiederherstellung mit mehrstream-basierten Sicherungen.
Zum Wiederherstellen einer SAP HANA-Datenbanksicherung, die Sie mit dem Backint-Feature des Agents für SAP von Google Clouderstellt haben, bietet SAP HANA die SQL-Anweisungen RECOVER DATA und RECOVER DATABASE.
Mit beiden SQL-Anweisungen werden Sicherungen aus dem Cloud Storage-Bucket wiederhergestellt, den Sie in der Datei PARAMETERS.json für den Parameter bucket angegeben haben, sofern Sie keinen Bucket für den Parameter recover_bucket angegeben haben.
Im Folgenden finden Sie Beispiel-SQL-Anweisungen zum Wiederherstellen einer SAP HANA-Datenbank mithilfe einer Sicherung, die Sie mit dem Backint-Feature desGoogle Cloud-Agents für SAP erstellt haben:
So stellen Sie eine Mandantendatenbank wieder her, indem Sie den Namen der Sicherungsdatei angeben:
RECOVER DATA FOR TENANT_SID USING BACKINT('BACKUP_NAME') CLEAR LOG;So stellen Sie eine Mandantendatenbank wieder her, indem Sie die Sicherungs-ID angeben:
RECOVER DATA FOR TENANT_SID USING BACKUP_ID BACKUP_ID CLEAR LOG;
Ersetzen Sie
BACKUP_IDdurch die ID der erforderlichen Sicherung.Zum Wiederherstellen einer Mandantendatenbank geben Sie die Sicherungs-ID an, wenn Sie die Sicherung des SAP HANA-Sicherungskatalogs verwenden müssen, der in Ihrem Cloud Storage-Bucket gespeichert ist:
RECOVER DATA FOR TENANT_SID USING BACKUP_ID BACKUP_ID USING CATALOG BACKINT CLEAR LOG;
So stellen Sie eine Mandantendatenbank zu einem bestimmten Zeitpunkt oder an einer bestimmten Logposition wieder her:
RECOVER DATABASE FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD HH:MM:SS' CHECK ACCESS USING BACKINT;
So stellen Sie eine Mandantendatenbank mithilfe einer Sicherung aus einer externen Datenbank wieder her:
RECOVER DATABASE FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD HH:MM:SS' CLEAR LOG USING SOURCE 'SOURCE_TENANT_SID@SOURCE_SID' USING CATALOG BACKINT CHECK ACCESS USING BACKINT
Ersetzen Sie Folgendes:
SOURCE_TENANT_SID: die SID der Quell-MandantendatenbankSOURCE_SID: die SID des SAP-Systems, in dem sich die Quell-Mandantendatenbank befindet
Wenn Sie eine SAP HANA-Datenbank wiederherstellen müssen, wenn der SAP HANA-Sicherungskatalog in der in Ihrem Cloud Storage-Bucket gespeicherten Sicherung nicht verfügbar ist, folgen Sie der Anleitung im SAP-Hinweis 3227931 – HANA-DB aus Backint ohne HANA-Sicherungskatalog wiederherstellen.
Identitäts- und Zugriffsverwaltung für Sicherungen
Wenn Sie Cloud Storage oder Compute Engine zum Sichern Ihrer SAP HANA-Daten verwenden, wird der Zugriff auf diese Sicherungen durch Identitäts- und Zugriffsverwaltung (IAM) gesteuert. Dieses Feature gibt Administratoren die Möglichkeit, Nutzer dazu zu autorisieren, Aktionen für bestimmte Ressourcen auszuführen. IAM bietet zentralisierte Kontrolle und Übersicht für die Verwaltung aller IhrerGoogle Cloud -Ressourcen, einschließlich Ihrer Sicherungen.
Darüber hinaus bietet IAM einen vollständigen Audit-Trail-Verlauf, in dem Ihren Administratoren die Erteilung, Entfernung und Delegation von Berechtigungen automatisch angezeigt wird. Dies ermöglicht es Ihnen, Richtlinien zu konfigurieren, die den Zugriff auf Ihre Daten in den Sicherungen überwachen. So können Sie den vollständigen Zyklus der Zugriffskontrolle mit Ihren Daten komplettieren. IAM bietet eine einheitliche Darstellung der Sicherheitsrichtlinien in Ihrem gesamten Unternehmen und ein integriertes Auditing, um Compliance-Prozesse zu vereinfachen.
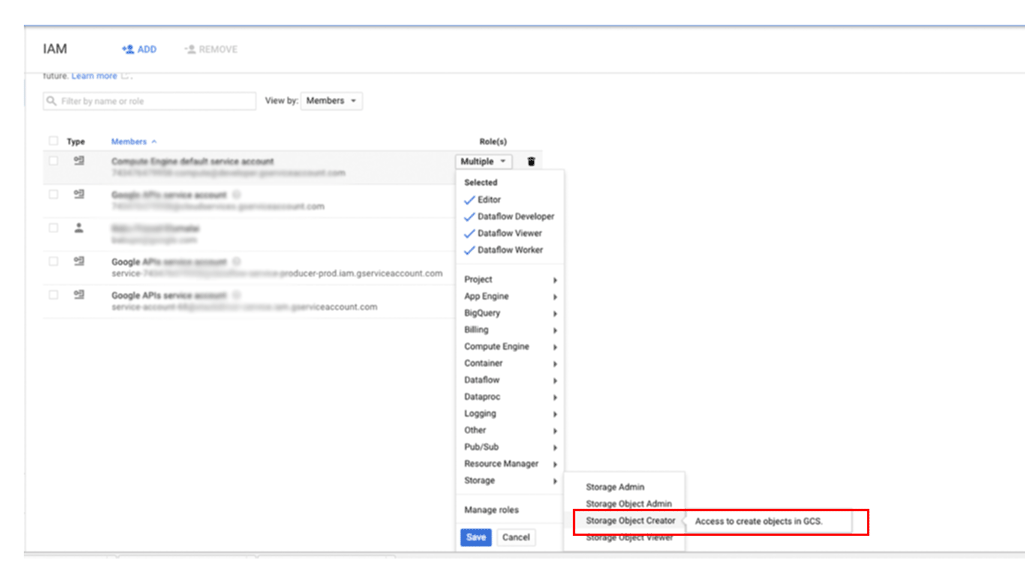
So gewähren Sie einem Hauptkonto Zugriff auf Ihre Sicherungen in Cloud Storage:
Google Cloud Rufen Sie in der Console die Seite IAM und Verwaltung auf:
Geben Sie den Nutzer an, dem Sie Zugriff gewähren möchten, und weisen Sie dann die Rolle Storage > Storage-Objekt-Ersteller zu:
Dateisystembasierte Sicherungen für SAP HANA erstellen
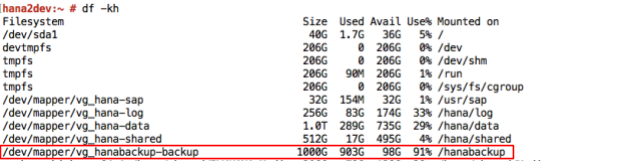
SAP HANA-Systeme, die gemäß der Bereitstellungsanleitung in Google Cloud bereitgestellt werden, sind mit einer Reihe von Persistent Disk- oder Hyperdisk-Volumes konfiguriert, die als NFS-Sicherungsziel verwendet werden. SAP HANA-Sicherungen werden zuerst auf diesen lokalen Laufwerken gespeichert und müssen dann zur langfristigen Speicherung in Cloud Storage kopiert werden. Sie können die Sicherungen entweder manuell in Cloud Storage kopieren oder crontab verwenden, um die Kopie in Cloud Storage zu planen.
Wenn Sie das Backint-Feature des Google Cloud-Agents für SAP verwenden, erfolgen Sicherung und Wiederherstellung direkt in einem Cloud Storage-Bucket. Dadurch ist kein nichtflüchtiger Speicher für Sicherungen erforderlich.
Zum Starten oder Planen der SAP HANA-Datensicherungen können Sie SAP HANA Studio, SQL-Befehle oder das DBA-Cockpit verwenden. Logsicherungen werden automatisch geschrieben, sofern sie nicht deaktiviert sind. Der folgende Screenshot zeigt ein Beispiel:
SAP HANA-global.ini konfigurieren
Wenn Sie den Angaben in der Bereitstellungsanleitung gefolgt sind, wird die SAP HANA-Konfigurationsdatei global.ini mit Datenbanksicherungen angepasst, die in /hanabackup/data/ und automatischen Logarchivierungsdateien in /hanabackup/log/ gespeichert sind. Das folgende Beispiel zeigt, wie global.ini aussieht:
[persistence]
basepath_datavolumes = /hana/data
basepath_logvolumes = /hana/log
basepath_databackup = /hanabackup/data
basepath_logbackup = /hanabackup/log
[system_information]
usage = production
Informationen zum Anpassen der Konfigurationsdatei global.ini für das Backint-Feature desGoogle Cloud-Agents für SAP finden Sie unter SAP HANA für das Backint-Feature konfigurieren.
Hinweise für Bereitstellungen mit horizontaler Skalierung
In einer Implementierung mit horizontaler Skalierung funktioniert eine Hochverfügbarkeitslösung, die von Live-Migration und automatischem Neustart Gebrauch macht, auf dieselbe Weise wie bei einer Konfiguration mit einem einzelnen Host. Der Hauptunterschied besteht darin, dass das Volume /hana/shared für alle Worker-Hosts NFS-bereitgestellt ist und im HANA-Master gesteuert wird. Bei einer Live-Migration oder einem automatischen Neustart eines Master-Hosts besteht auf dem NFS-Volume ein kurzer Zeitraum der Unzugänglichkeit. Wenn der Master-Host neu gestartet wird, funktioniert das NFS-Volume bald wieder auf allen Hosts und der normale Betrieb wird automatisch fortgesetzt.
Das SAP HANA-Sicherungsvolume /hanabackup muss während Sicherungs- und Wiederherstellungsvorgängen auf allen Hosts verfügbar sein. Im Falle eines Fehlers müssen Sie prüfen, ob /hanabackup auf allen Hosts bereitgestellt ist, und es dort noch einmal bereitstellen, wo dies nicht der Fall ist. Wenn Sie den Sicherungssatz auf ein anderes Volume oder in Cloud Storage kopieren möchten, führen Sie die Kopie auf dem Master-Host aus, um eine bessere E/A-Leistung zu erzielen und die Netzwerknutzung zu verringern. Zur Vereinfachung des Sicherungs- und Wiederherstellungsprozesses können Sie Cloud Storage FUSE verwenden, um den Cloud Storage-Bucket auf jedem Host bereitzustellen.
Die Leistung der horizontalen Skalierung ist nur so gut wie Ihre Datenverteilung. Je besser die Daten verteilt sind, desto besser ist die Abfrageleistung. Dies setzt voraus, dass Sie Ihre Daten gut kennen, wissen, wie die Daten verwendet werden, und die Verteilung und Partitionierung der Tabellen entsprechend gestalten. Weitere Informationen finden Sie im SAP-Hinweis 2081591 – FAQ: SAP HANA-Tabellenverteilung.
Gcloud Python
Gcloud Python ist ein idiomatischer Python-Client, mit dem Sie aufGoogle Cloud -Dienste zugreifen können. In dieser Anleitung wird Gcloud Python verwendet, um Sicherungs- und Wiederherstellungsvorgänge in und aus Cloud Storage für Ihre SAP HANA-Datenbanksicherungen durchzuführen.
Wenn Sie die Anleitungen im Bereitstellungsleitfaden befolgt haben, dann sind Gcloud Python-Bibliotheken bereits in den Compute Engine-Instanzen verfügbar.
Die Bibliotheken sind Open Source und ermöglichen es Ihnen, in Ihrem Cloud Storage-Bucket Sicherungsdaten zu speichern und abzurufen.
Mit dem folgenden Befehl können Sie Objekte in Ihrem Cloud Storage-Bucket auflisten. Sie können damit die verfügbaren Sicherungen auflisten:
python 2>/dev/null - <<EOF
from google.cloud import storage
storage_client = storage.Client()
bucket = storage_client.get_bucket("<bucket_name>")
blobs = bucket.list_blobs()
for fileblob in blobs:
print(fileblob.name)
EOF
Alle Details zu Gcloud Python finden Sie in der Referenzdokumentation zur Storage-Clientbibliothek.
Beispiel für Sicherung und Wiederherstellung
In folgenden Abschnitten wird die Vorgehensweise beschrieben, die Sie für typische Sicherungs- und Wiederherstellungsaufgaben mit SAP HANA Studio befolgen können.
Beispiel für die Erstellung einer Sicherung
Wählen Sie im SAP HANA Backup Editor Open Backup Wizard (Sicherungsassistenten öffnen).
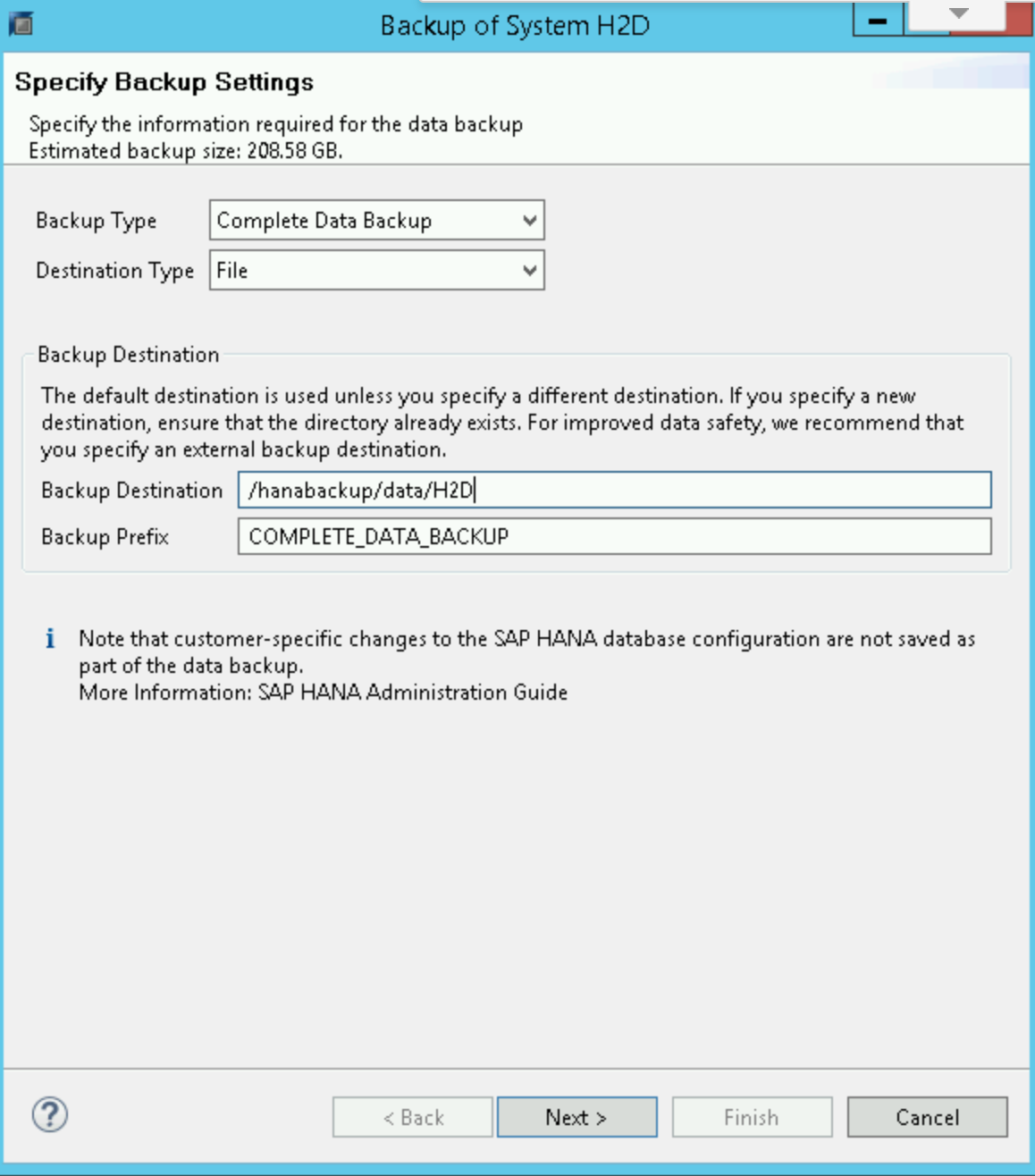
- Wählen Sie File (Datei) als Zieltyp. Dadurch wird die Datenbank in Dateien im angegebenen Dateisystem gesichert.
- Geben Sie das Sicherungsziel
/hanabackup/data/SIDund das Sicherungspräfix an. Ersetzen SieSIDdurch die System-ID Ihres SAP-Systems. - Klicken Sie auf Weiter.
Klicken Sie im Bestätigungsformular auf Finish (Fertig stellen), um die Sicherung zu starten.
Wenn die Sicherung startet, zeigt ein Statusfenster den Fortschritt Ihrer Sicherung an. Warten Sie, bis die Sicherung abgeschlossen ist.
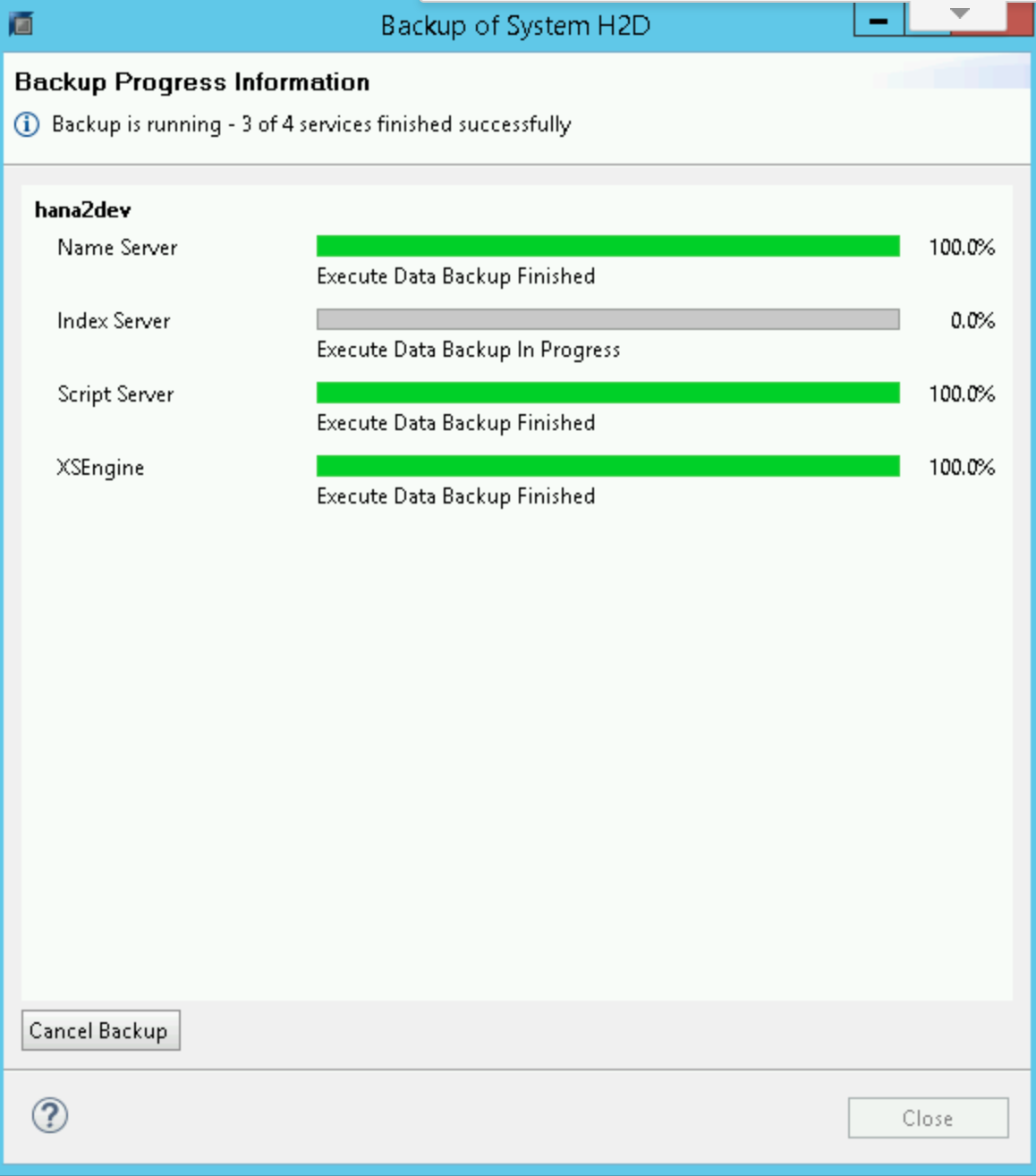
Nach Abschluss der Sicherung wird in der Zusammenfassung der Sicherung die Meldung
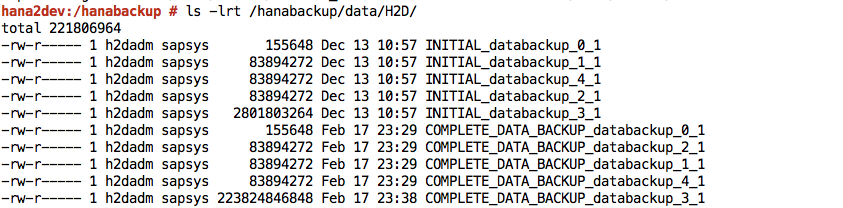
Finishedangezeigt.Melden Sie sich bei Ihrem SAP HANA-System an und prüfen Sie, ob die Sicherungen an den erwarteten Speicherorten im Dateisystem verfügbar sind. Beispiel:

Übertragen oder synchronisieren Sie die Sicherungsdateien aus dem Dateisystem
/hanabackupnach Cloud Storage. Das folgende Beispiel-Python-Script überträgt die Daten aus/hanabackup/dataund/hanabackup/login den für Sicherungen verwendeten Bucket, in der FormNODE_NAME/DATAoderLOG/YYYY/MM/DD/HH/BACKUP_FILE_NAME. Damit können Sie Sicherungsdateien anhand des Zeitpunkts identifizieren, zu dem die Sicherung kopiert wurde. Diesesgcloud Python-Script führen Sie über die Bash-Eingabeaufforderung Ihres Betriebssystems aus:python 2>/dev/null - <<EOF import os import socket from datetime import datetime from google.cloud import storage storage_client = storage.Client() today = datetime.today() current_hour = today.strftime('%Y/%m/%d/%H') hostname = socket.gethostname() bucket = storage_client.get_bucket("hanabackup") for subdir, dirs, files in os.walk('/hanabackup/data/H2D/'): for file in files: backupfilename = os.path.join(subdir, file) if 'COMPLETE_DATA_BACKUP' in backupfilename: only_filename = backupfilename.split('/')[-1] backup_file = hostname + '/data/' + current_hour + '/' + only_filename blob = bucket.blob(backup_file) blob.upload_from_filename(filename=backupfilename) for subdir, dirs, files in os.walk('/hanabackup/log/H2D/'): for file in files: backupfilename = os.path.join(subdir, file) if 'COMPLETE_DATA_BACKUP' in backupfilename: only_filename = backupfilename.split('/')[-1] backup_file = hostname + '/log/' + current_hour + '/' + only_filename blob = bucket.blob(backup_file) blob.upload_from_filename(filename=backupfilename) EOFVerwenden Sie entweder die Gcloud Python-Bibliotheken oder die Google Cloud Console, um die Sicherungsdaten aufzulisten.
Beispiel für die Wiederherstellung einer Sicherung
Wenn die Sicherungsdateien nicht im Verzeichnis
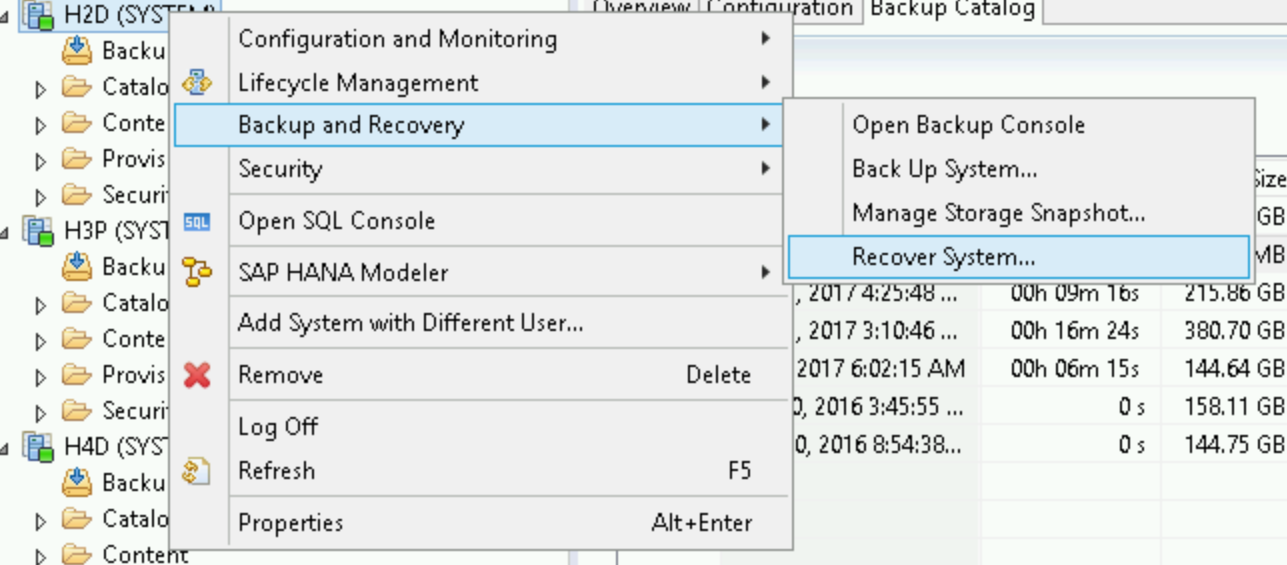
/hanabackup, aber in Cloud Storage verfügbar sind, laden Sie die Dateien aus Cloud Storage herunter. Dafür führen Sie das folgende Skript über die Bash-Eingabeaufforderung Ihres Betriebssystems aus:python - <<EOF from google.cloud import storage storage_client = storage.Client() bucket = storage_client.get_bucket("hanabackup") blobs = bucket.list_blobs() for fileblob in blobs: blob = bucket.blob(fileblob.name) fname = str(fileblob.name).split('/')[-1] blob.chunk_size=1<<30 if 'log' in fname: blob.download_to_filename('/hanabackup/log/H2D/' + fname) else: blob.download_to_filename('/hanabackup/data/H2D/' + fname) EOFKlicken Sie zum Wiederherstellen der SAP HANA-Datenbank auf Backup and Recovery > Recover System (Sicherung und Wiederherstellung > System wiederherstellen):
Klicken Sie auf Weiter.
Geben Sie den Speicherort Ihrer Sicherungen in Ihrem lokalen Dateisystem an und klicken Sie auf Add (Hinzufügen).
Klicken Sie auf Weiter.
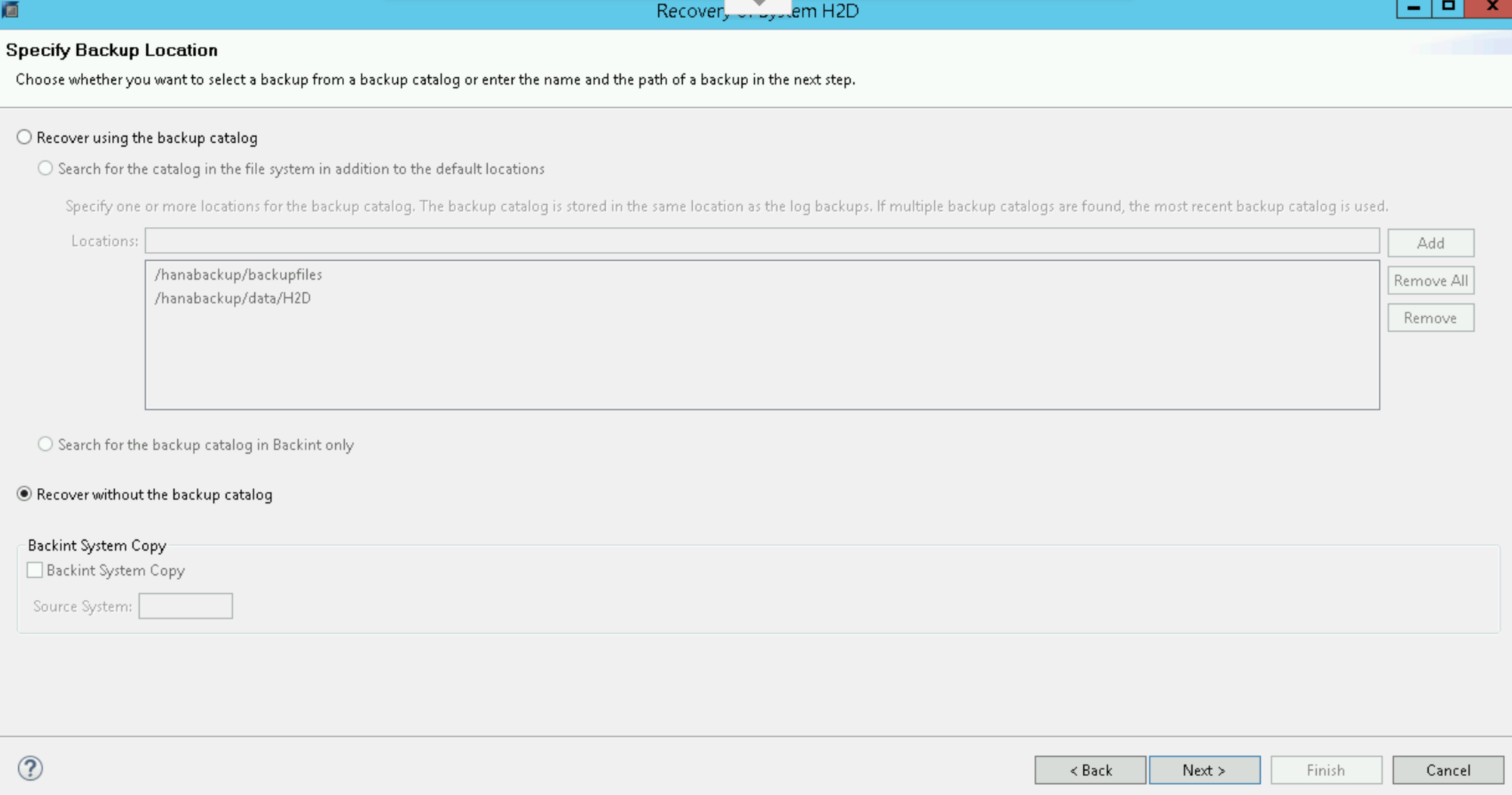
Wählen Sie Recover without the backup catalog (Ohne Sicherungskatalog wiederherstellen) aus:
Klicken Sie auf Weiter.
Wählen Sie File (Datei) als Zieltyp aus und geben Sie dann den Speicherort der Sicherungsdateien und das richtige Präfix für die Sicherung an. Wenn Sie das Beispiel für die Erstellung einer Sicherung befolgt haben, wurde
COMPLETE_DATA_BACKUPals Präfix festgelegt.Klicken Sie zweimal auf Next (Weiter).
Klicken Sie auf Finish (Fertig stellen), um die Wiederherstellung zu starten.
Wenn die Wiederherstellung abgeschlossen ist, nehmen Sie den normalen Betrieb wieder auf und entfernen die Sicherungsdateien aus den
/hanabackup/data/SID/*-Verzeichnissen.
Weitere Informationen
Die folgenden SAP-Standarddokumente könnten hilfreich für Sie sein:
Möglicherweise finden Sie auch die folgenden Google Cloud Dokumente nützlich: