このドキュメントは、データスキュー検出を行うために、AI Platform Prediction で機械学習(ML)モデルをモニタリングする方法を説明するシリーズの 4 番目のパートです。このガイドでは、時間の経過によるトレーニング / サービング データ スキューの検知を自動化し、異常が見つかった場合にアラートを生成するためのエンドツーエンドのソリューションを紹介します。このガイドでは、スキューとデータのズレの検知のためのサービングログ分析プロセスの自動化、スケジューリング、運用、スケーリングに重点が置かれています。
このガイドは、時間の経過とともにサービング データがどのように変化するかをモニタリングし、データのスキューと異常を自動的に特定することで、本番環境で ML モデルの予測パフォーマンスを維持したい ML エンジニアを対象としています。
このシリーズは、次のガイドで構成されています。
- AI Platform Prediction を使用したサービング リクエストのロギング
- BigQuery でのログの分析
- TensorFlow Data Validation によるトレーニング / サービング スキューの分析
- トレーニング / サービング スキュー検知の自動化(このドキュメント)
- 特異点検知によるトレーニング / サービング スキューの特定
このシリーズの GitHub リポジトリ
このシリーズに関連する GitHub リポジトリには、このドキュメントで説明するシステムをデプロイし、Log Analyzer のパイプライン実行を送信してスケジュールするためのサンプルコードと手順が含まれています。リポジトリには、Jupyter ノートブックの例も含まれています。これらのノートブックは、統計情報へのアクセスと分析、システムが生成する異常の分析を行う手法を示しています。
アーキテクチャ
次の図は、このドキュメントで説明するシステムのアーキテクチャを示したものです。
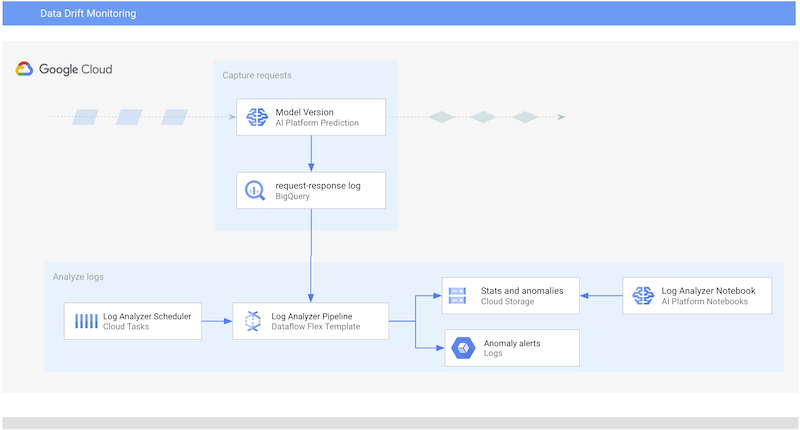
このシステムは次の 2 つのコンポーネントで構成されています。
- Log Analyzer パイプラインシステムの中核は Dataflow Flex テンプレートです。このテンプレートは、AI Platform Prediction のリクエスト / レスポンスログからレコードを抽出して分析する Apache Beam パイプライン(ログ分析パイプライン)をカプセル化します。Dataflow はスケールアップが可能で大量のデータを扱うことができるため、このタスクに適しています。このパイプラインでは、TensorFlow Data Validation(TFDV)を使用して記述統計を計算し、ログから抽出された時系列レコードのデータ異常を検出します。パイプラインによって生成されたアーティファクトは Cloud Storage に push されます。これらを Jupyter ノートブックで分析するには、このシリーズの前のドキュメント、TensorFlow Data Validation によるトレーニング / サービング スキューの分析で説明されている手法を使用します。
- パイプライン スケジューラ。Log Analyzer のパイプラインを将来の特定の時間に実行するようにスケジュールできます。Cloud Tasks を使用して、将来の実行のスケジューリングと実行を管理します。Cloud Tasks は、Google Cloud でコンピューティング タスクをスケジューリングし、ディスパッチするためのスケーラブルなフルマネージド サービスです。また、Dataflow Flex テンプレート ジョブを直接実行することもできます(つまり、すぐに実行できます)。
ログ分析のワークフローについて
Log Analyzer パイプラインは、BigQuery に格納されているサービング リクエスト / レスポンスログで、TFDV を使用してデータスキューと異常を特定する Dataflow パイプラインです。
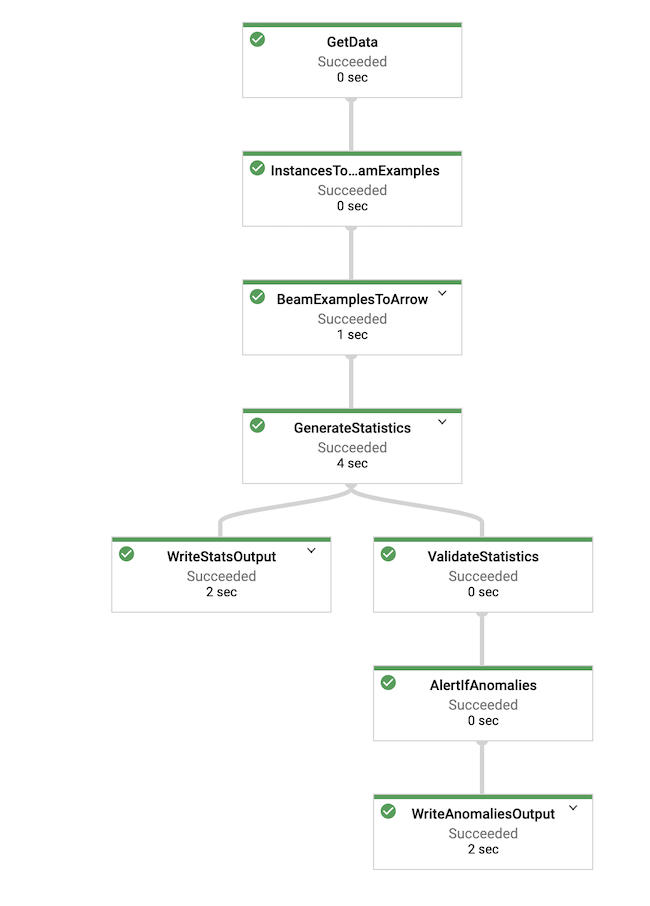
次の図は、Log Analyzer パイプラインで実装されるワークフローを示しています。

この図は、パイプラインが実行するタスクのシーケンスを示しています(パラメータについては、このセクションの後半で説明します)。タスクは次のとおりです。
- BigQuery 内のテーブルから、
request_response_log_tableパラメータで表されるレコードと、model、version、start_time、end_timeのフィルタリング パラメータでフィルタされるレコードの時系列を抽出します。 - レコードを TFDV で必要とされる形式に変換します。
time_windowパラメータで指定された長さを持つスライスでフィルタすることで、時系列の記述統計を計算します。schema_fileパラメータで指定された位置から読み込まれた参照スキーマに対して計算された統計を検証し、時系列のデータ異常を検出します。- 異常が検出された場合はアラートが生成されます。
- 計算済みの統計と異常プロトコル バッファを、
output_locationパラメータで指定された Cloud Storage の場所に保存します。
次の表は、Log Analyzer パイプラインに渡すことができる主要なパラメータを示したものです。
| パラメータ名 | 種類 | 省略可 | 説明 |
|---|---|---|---|
request_response_log_table |
文字列 | × |
BigQuery のリクエスト / レスポンス ログ テーブルのフルネーム。名前は次の形式になります。
|
model |
文字列 | × | AI Platform Prediction モデルの名前。 |
version |
文字列 | × | AI Platform Prediction モデルのバージョン番号。 |
start_time |
文字列 | × | ログ内のレコードの時系列の先頭(ISO の日時形式、YYYY-MM-DDTHH:MM:SS)。 |
end_time |
文字列 | × | ログ内のレコードの時系列の末尾(ISO の日時形式、YYYY-MM-DDTHH:MM:SS)。 |
output_location |
文字列 | × | 出力の統計情報と異常値の Cloud Storage URL |
schema_file |
文字列 | × | モデルの入力インターフェースを記述する、参照スキーマ ファイルの Cloud Storage URL |
baseline_stats_file |
文字列 | ○ | ベースライン統計ファイルの Cloud Storage URL |
time_window |
文字列 | ○ | スライス計算の時間枠。分または時間を指定するには、m または h サフィックスを使用する必要があります。たとえば、60m は 60 分の時間枠を定義します。 |
パイプラインの実装とパイプラインをトリガーする方法については、関連する GitHub リポジトリの README ファイルをご覧ください。
リクエスト / レスポンス ログレコードの抽出とエンコード
AI Platform Prediction のリクエスト / レスポンスログにキャプチャされたサービング リクエストのレコードには、リクエストがキャプチャされた時点を示すタイムスタンプが含まれます。レコードには、JSON 形式のリクエストの本文のコピーも含まれます。
パイプラインの最初のステップでは、2 つの時点の間の時系列レコードを抽出します。開始時間と終了時間は、パイプライン実行のインスタンスのパラメータとして提供されます。リクエスト本文は JSON 形式から TFDV で必要な形式(tensorflow_data_validation.type.BeamExample)に変換され、TFDV 統計情報の生成と異常検出の他のコンポーネントに転送されます。
記述統計の計算
パイプラインは、tensorflow_data_validation.GenerateStatistics PTransform を使用してレコードの時系列の統計を計算します。計算される統計の種類については、TensorFlow データ検証: データの確認と分析をご覧ください。
デフォルトでは、パイプラインは時系列内のすべてのレコードを使用して統計情報を計算します。また、パイプラインは時系列を一連の連続したスライスに分割し、各スライスの追加の統計情報を計算することもできます。実行時に、パイプラインは時系列スライスを使用するかどうかと、スライスの幅に関するパラメータを受け取ります。
データ異常の検知
記述統計を計算したら、次の手順は異常検知です。このパイプラインでは、tensorflow_data_validation.validate_statistics 関数を使用してデータの異常を検知します。関数によって検知された異常の種類の詳細については、TensorFlow データ検証: データの確認と分析をご覧ください。
デフォルトでは、パイプラインは、計算された統計と、サービング リクエストに適合することが想定される参照スキーマを比較して、データの異常を検知します。参照スキーマは、パイプラインの必須のランタイム パラメータです。スキーマを定義する方法については、TensorFlow Data Validation によるトレーニング / サービング スキューの分析をご覧ください。サービング データの統計と参照スキーマを比較して、スキーマ型のスキューを検知できます。たとえば、特徴量に一貫性がない場合、特徴量のタイプに一貫性がない場合、特徴量ドメインに一貫性がない場合などがこれに該当します。
特徴量分布のスキューを検知するには、パイプラインに追加の情報が必要です。パイプラインにベースライン統計を提供できます。ベースライン統計は、サービング リクエストの特徴量の想定される分布をキャプチャするため、TFDV はスキーマの異常の検知に加えて、特徴量分布スキューの異常を検知できます。
次のフロー図は、Log Analyzer の Dataflow パイプラインが正常に実行されていることを示しています。
データ異常のアラート
データの異常が検出された場合は、パイプラインによってアラートを生成できます。パイプラインでは、対応する Dataflow ジョブの実行ログに警告メッセージが記録されます。
パイプラインの Generate
anomaly alerts ステップを変更することで、追加のアラート機能を含めることができます。
ログ分析実行のスケジューリング
アーキテクチャの概要で説明したように、Log Analyzer パイプラインは Dataflow Flex テンプレートにカプセル化されます。パイプラインの実行は、Dataflow Flex テンプレート ジョブを構成して送信することで行われます。
このドキュメントで説明しているシステムでは、Dataflow フレックス テンプレート ジョブをすぐに開始することも、後で開始するようにスケジュールすることもできます。時間表で一連のジョブのスケジュールを設定すると、サービング データを積極的かつ自動的にモニタリングできます。
積極的なモニタリングの場合は、Dataflow Flex テンプレート サービスを呼び出してジョブ リクエストを送信するとすぐにジョブが開始されます。自動モニタリングの場合は、ジョブのスケジュールを設定した後、ジョブ リクエストが Cloud Tasks キューに追加されます。キューに登録されたリクエストには、パイプラインに渡すランタイム パラメータが含まれ、これにはスケジュールされた実行時間が含まれます。
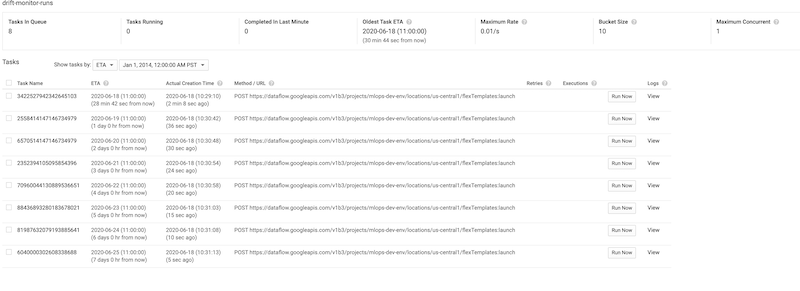
次のスクリーンショットは、Cloud Tasks のキューに登録された Log Analyzer ジョブを示しています。
次のステップ
- TensorFlow Data Validation による AI Platform Prediction のトレーニング / サービング スキューの分析ガイドを読む。
- TensorFlow Data Validation によるサービング データ スキューの分析リファレンス ガイドを読む。
- 特異点検知によるトレーニング サービング スキューの特定ガイドを読む。
- Google Cloud に関するリファレンス アーキテクチャ、図、ベスト プラクティスを確認する。Cloud Architecture Center をご覧ください。