このドキュメントでは、オンプレミスまたは他のクラウド環境から Google Cloud にデータベースを移行するクラウド アーキテクト向けに、ダウンタイムがほぼゼロのデータベース移行のコンセプト、原則、用語、アーキテクチャについて説明します。 Google Cloud
このドキュメントは 2 部構成の前半です。後半では、障害シナリオを含め、移行プロセスの設定と実行について説明します。
データベース移行は、データベース移行サービスを使用して 1 つ以上のソース データベースから 1 つ以上のターゲット データベースにデータを移行するプロセスです。移行の完了後、(再構築される場合があるものの)ソース データベースのデータセットは完全にターゲット データベースに移動されます。ソース データベースにアクセスしたクライアントはターゲット データベースにリダイレクトされ、ソース データベースは停止されます。
次の図は、このデータベース移行プロセスを示しています。
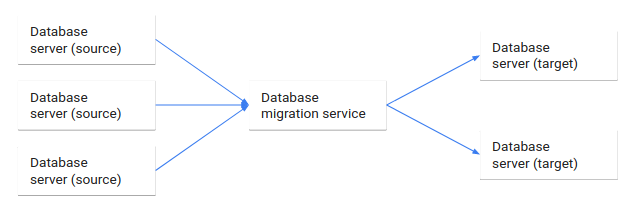
このドキュメントでは、アーキテクチャの観点からのデータベースの移行について説明します。
- データベース移行に関連するサービスとテクノロジー。
- 同機種のデータベース移行と異機種のデータベース移行の違い。
- 移行のダウンタイム許容範囲のトレードオフと選択。
- 移行中に予期しないエラーが発生した場合のフォールバックをサポートする設定アーキテクチャ。
このドキュメントでは、具体的なデータベース移行テクノロジーの設定方法については説明しません。代わりに、基本的、概念的、原則的な用語を使用してデータベース移行について説明します。
アーキテクチャ
次の図は、一般的なデータベース移行アーキテクチャを示しています。
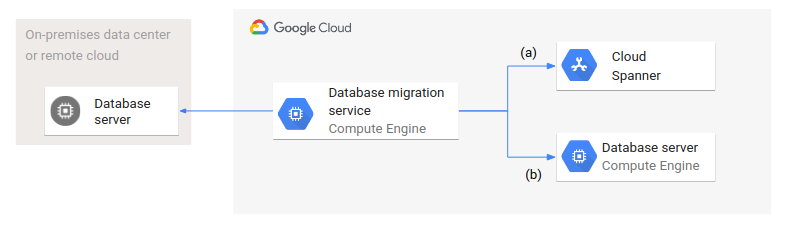
データベース移行サービスは Google Cloud 内で実行され、ソース データベースとターゲット データベースの両方にアクセスします。ここでは、2 つのバリアントがあります。(a) は、オンプレミス データセンターやリモート クラウドのソース データベースから Spanner などのマネージド データベースへの移行を、(b) は、Compute Engine 上のデータベースへの移行を示しています。
ターゲット データベースのタイプ(マネージドと非マネージド)や設定は異なりますが、データベース移行のアーキテクチャと構成はどちらの場合も同じです。
用語
このドキュメントで最も重要なデータ移行に関する用語は、次のように定義されています。
ソース データベース: 1 つ以上のターゲット データベースに移行するデータを含むデータベース。
ターゲット データベース: 1 つ以上のソース データベースから移行されたデータを受け取るデータベース。
データベースの移行: 移行完了後にソース データベース システムを停止することを目的とした、ソース データベースからターゲット データベースへのデータの移行。データセット全体またはサブセットが移行されます。
同機種の移行: ソース データベースとターゲット データベースでデータベース管理システムとそのプロバイダが同じ場合の、ソース データベースからターゲット データベースへのデータの移行。
異機種の移行: ソース データベースとターゲット データベースでデータベース管理システムとそのプロバイダが異なる場合の、ソース データベースからターゲット データベースへのデータの移行。
データベース移行システム: ソース データベースとターゲット データベースに接続し、ソースからターゲットにデータを移行するソフトウェア システムまたはサービス。
データ移行プロセス: ソース データベースからターゲット データベースにデータを転送し場合に応じて転送中にデータを変換する、構成または実装されたプロセス。データ移行システムによって実行される。
データベース レプリケーション: ソース データベースを停止することを目的としない、ソース データベースからターゲット データベースへのデータの連続的な転送。データベース レプリケーション(データベース ストリーミングとも呼ばれます)は、連続的なプロセスです。
データベース移行の分類
データベース移行はいくつかの種類に分類されます。このセクションでは、これらの分類を定義する基準について説明します。
レプリケーションと移行
データベースの移行では、ソース データベースからターゲット データベースにデータを移動します。データの移行が完了したら、ソース データベースを削除し、クライアント アクセスをターゲット データベースにリダイレクトします。ターゲット データベースで予期しない問題が発生した場合に、代替データベースとしてソース データベースを保持する場合もあります。ただし、ターゲット データベースが正常に動作する場合は、最終的にソース データベースを削除します。
対してデータベース レプリケーションでは、ソース データベースを削除せずに、ソース データベースからターゲット データベースにデータを連続的に転送します。データベース レプリケーションは、データベース ストリーミングと呼ばれることもあります。データベース レプリケーションの開始時間は定義されますが、完了時間は通常定義されません。レプリケーションが停止することや、レプリケーションが移行になることもあります。
このドキュメントでは、データベースの移行についてのみ説明します。
部分移行と完全移行
データベースの移行は、データの完全で一貫した転送であるとみなされます。転送する最初のデータセットは、完全なデータベース、あるいは部分的なデータベース(データベース内のデータのサブセット)のいずれかに、その後にソース データベース システムで commit されたすべての変更を加えたものとして定義されます。
異機種および同機種の移行
同機種のデータベース移行とは、同じデータベース テクノロジーを使用するソース データベースとターゲット データベースの間のデータの移行です。たとえば、MySQL データベースから MySQL データベース、Oracle® データベースから Oracle データベースなどです。同機種の移行には、PostgreSQL などのセルフホストのデータベース システムと Cloud SQL for PostgreSQL や AlloyDB for PostgreSQL などのマネージド バージョンとの移行も含まれます。
同機種のデータベースの移行では、ソース データベースとターゲット データベースのスキーマは同じであることが多いです。スキーマが異なる場合は、移行中にソース データベースのデータを変換する必要があります。
異機種のデータベース移行とは、異なるデータベース テクノロジーを使用するソース データベースとターゲット データベースの間のデータの移行です。たとえば、Oracle データベースから Spanner への移行などです。異機種のデータベース移行は、同じデータモデル間(たとえば、リレーショナルからリレーショナル)、および異なるデータモデル間(たとえば、リレーショナルから Key-Value)で行うことができます。
異なるデータベース テクノロジー間での移行は、必ずしも異なるデータモデルを伴うわけではありません。たとえば、Oracle、MySQL、PostgreSQL、Spanner はすべてリレーショナル データモデルをサポートしています。ただし、Oracle、MySQL、PostgreSQL などのマルチモデル データベースは、さまざまなデータモデルをサポートしています。マルチモデル データベースに JSON ドキュメントとして保存されたデータは、ソース データベースとターゲット データベースでデータモデルが同じであるため、変換をほとんど、またはまったく必要とせずに MongoDB に移行できます。
同機種の移行と異機種の移行の分類の基準はデータベース テクノロジーですが、データベース モデルを基準として分類する場合もあります。たとえば、Oracle データベースから Spanner への移行は、両方がリレーショナル データモデルを使用する場合は同機種の移行になります。JSON オブジェクトとして Oracle に保存されているデータが Spanner のリレーショナル モデルに移行される場合、異機種の移行になります。
データモデルで移行を分類する場合、関与するデータベース システムに基づいて分類する場合よりも、データの移行に必要な複雑さと労力がより正確に表現されます。ただし、業界で一般的に使用されている分類方法は、関与するデータベース システムに基づいたものであるため、残りのセクションではその分類方法に基づいています。
移行のダウンタイム: ゼロ、ほぼゼロ、大幅の違い
データセットをソース データベースからターゲット データベースに正常に移行したら、クライアント アクセスをターゲット データベースに切り替えて、ソース データベースを削除します。
クライアントをソース データベースからターゲット データベースに切り替えるには、いくつかの手順を踏む必要があります。
- 処理を続行する場合、クライアントはソース データベースへの既存の接続を閉じ、ターゲット データベースへの新しい接続を作成する必要があります。理想的には、接続を閉じることが適切です。すなわち、進行中のトランザクションを不必要にロールバックしないようにします。
- ソース データベースの接続を閉じた後、残りの変更をソース データベースからターゲット データベースに移行(ドレインと呼ばれます)して、すべての変更が確実にキャプチャされるようにする必要があります。
- ターゲット データベースをテストして、これらのデータベースが機能していること、クライアントが機能していて、定義されたサービスレベル目標(SLO)内で動作していることを確認する必要がある場合があります。
移行において、クライアントでダウンタイムが発生しないようにすることはできません。クライアントがリクエストを処理できない時間が必ず発生するためです。ただし、複数の方法で、クライアントがリクエストを処理できない期間を最小化(ダウンタイムがほぼゼロ)することはできます。
- クライアントを切り替えるよりもさらに前に、ターゲット データベースに対して読み取り専用モードでアクセスをテストできます。このアプローチでは、テストは移行と同時に行われます。
- 切り替え期間が近づいたときに移行されるデータ(ソース データベースとターゲット データベース間で送信されるデータ)の量をできるだけ少なくするように構成できます。この手順によって、ソース データベースとターゲット データベースの差が小さくなるため、ドレインの時間を短縮できます。
- 新しいクライアントのターゲット データベースへの接続を、既存のクライアントのソース データベースへの接続と同時に開始できる場合、切り替えの時間を短縮できます。これは、新しいクライアントが、データがすべてドレインされた後にすぐにターゲット データベースを利用できるようになるためです。
切り替え時のダウンタイムをゼロにすることは非現実的です。ただし可能な場合は、データ移行の実行と同時にアクティビティを開始することで、ダウンタイムを最小化できます。
一部のデータベース移行シナリオでは、大幅なダウンタイムが許容されます。通常、この許容範囲はビジネス要件に依存します。このように、大幅なダウンタイムが許容される場合はアプローチを簡素化できます。たとえば、同機種のデータベース移行では、データの変更が不要な場合があります。「エクスポートとインポート」や「バックアップと復元」が最適なアプローチです。異機種の移行においては、移行中にデータベース移行システムでソース データベース システムの更新を処理する必要がなくなります。
ただし、データベースの移行とフォローアップ テストを行うのに十分な、許容範囲内のダウンタイムを確保する必要があります。このダウンタイムを明確に確立できない場合や、許容できないほど長い場合は、最小限のダウンタイムを伴う移行を計画する必要があります。
データベース移行のカーディナリティ
多くの場合、データベースの移行は単一のソース データベースと単一のターゲット データベースの間で行われます。その場合、カーディナリティは 1:1(直接マッピング)です。つまり、ソース データベースが変更なしでターゲット データベースに移行されます。
ただし、直接マッピング以外のものもあります。その他のカーディナリティには次のものがあります。
- 統合(n:1)。統合では、複数のソース データベースからより少数のターゲット データベース(または 1 つのターゲット)にデータを移行します。このアプローチは、データベース管理を簡素化したり、拡張可能なターゲット データベースを導入したりする場合などに使用できます。
- 分散(1:n)。分散では、1 つのソース データベースから複数のターゲット データベースにデータを移行します。たとえば、地域データを含む大規模な集中型データベースを、複数の地域別のターゲット データベースに移行する必要がある場合に、このアプローチを使用できます。
- 再分散(n:m)再分散では、複数のソース データベースから複数のターゲット データベースにデータを移行します。このアプローチは、ソース データベースが異なるサイズのシャードにシャーディングされている場合に使用できます。再分散では、シャーディングされたデータが、シャードに対応する複数のターゲット データベースに均等に分散されます。
データベース移行では、データの移行だけでなく、データベース アーキテクチャの再設計と実装が可能になります。
移行における整合性
データベース移行において、整合性があることが求められます。移行における整合性とは、次のことを意味します。
- 完全性。移行対象として指定されるすべてのデータは実際に移行されます。指定されるデータは、ソース データベース内のすべてのデータか、データのサブセットです。
- 重複がない。各データは 1 回だけ移行されます。ターゲット データベースに重複するデータが導入されることはありません。
- 正しい順序。ソース データベースのデータ変更は、ソース データベースで行われた変更と同じ順序でターゲット データベースに適用されます。この点は、データの整合性を確保するために不可欠です。
移行の完了後、ソース データベースとターゲット データベースのデータ状態が同等であるかどうかが、移行の整合性を表す別の方法です。たとえば、リレーショナル データベースの直接マッピングが行われる同機種の移行では、ソース データベースとターゲット データベースに同じテーブルと行が存在する必要があります。
すべてのデータ移行が、ソース データベースのトランザクションをターゲット データベースに順次適用することに基づいているわけではないため、移行の整合性を表すためのこの方法は重要になります。たとえば、大幅なダウンタイムが許容できる場合に、ソース データベースをバックアップし、そのバックアップを使用してソース データベースのコンテンツをターゲット データベースに復元する場合があります。
アクティブ - パッシブ移行とアクティブ - アクティブ移行
主な分類基準は、ソース データベースとターゲット データベースの両方がクエリ処理の変更に対してオープンであるかどうかです。アクティブ - パッシブ データベース移行では、移行中にソース データベースを変更できますが、ターゲット データベースは読み取りのみ許可されます。
アクティブ - アクティブ移行では、移行中のソース データベースとターゲット データベースの両方への書き込みが許可されます。このタイプの移行では、競合が発生する可能性があります。たとえば、ソース データベースとターゲット データベースの同じデータ項目が意味的に競合するように変更された場合に、競合解決ルールを実行して競合を解決する必要がある場合があります。
アクティブ - アクティブ移行では、競合解決ルールを使用してすべてのデータ競合を解決できるようにする必要があります。それができない場合、データに不整合が生じる可能性があります。
データベース移行アーキテクチャ
データベース移行アーキテクチャは、データベース移行を行うために必要なさまざまなコンポーネントを記述します。このセクションでは、一般的なデプロイ アーキテクチャを紹介し、データベース移行システムを個別のコンポーネントとして扱います。また、データ移行をサポートするデータベース管理システムの機能や、多くのユースケースで重要となる、機能以外に関するプロパティについても説明します。
デプロイ アーキテクチャ
オンプレミスや別のクラウドなど、あらゆる環境にあるソース データベースとターゲット データベースの間でのデータベースの移行が考えられます。各ソース データベースとターゲット データベースは、異なる環境にあってもかまいません。すべてを同じ環境に配置する必要はありません。
次の図は、複数の環境が関与するデプロイ アーキテクチャの例を示しています。
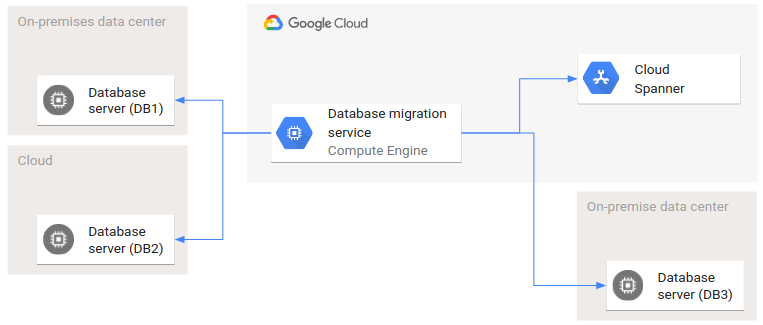
DB1 と DB2 の 2 つはソース データベースで、DB3 と Spanner はターゲット データベースです。このデータベース移行では、2 つのクラウドと 2 つのオンプレミス データセンターが関与します。矢印は呼び出し関係を表します。データベース移行サービスは、すべてのソース データベースとターゲット データベースのインターフェースを呼び出します。
ここで説明されていない特殊なケースとして、あるデータベースからそれと同じデータベースへのデータの移行があります。この特殊なケースでは、データベース移行システムをデータ変換の目的でのみ使用します。異なる環境の異なるシステム間でデータを移行するためには使用されません。
基本的に、データベースの移行には 3 つの方法があります。これらの方法について、このセクションで説明します。
- データベース移行システムを使用する
- データベース管理システムのレプリケーション機能を使用する
- カスタム データベース移行機能を使用する
データベース移行システム
データベース移行システムは、データベースの移行における中核です。データベース移行システムは、ソース データベースから実際のデータ抽出を実行し、そのデータをターゲット データベースに転送し、場合に応じて転送中にデータを変更します。このセクションでは、基本的なデータベース移行システムの機能全般について説明します。データベース移行システムの例として、Database Migration Service、Striim、Debezium、tcVision、Cloud Data Fusion などがあります。
データ移行プロセス
データ移行プロセスは、データベース移行システムの中核となる技術的構成要素です。データ移行プロセスはデベロッパーにより指定されるもので、データの抽出元となるソース データベース、データの移行先となるターゲット データベース、移行中にデータに適用されるデータ変更ロジックを定義します。
1 つ以上のデータ移行プロセスを指定し、移行のニーズに応じて順次的に実行することも、同時に実行することもできます。たとえば、独立したデータベースを移行する場合に、対応する複数のデータ移行プロセスを同時に実行できます。
データの抽出と挿入
データベース システムでの変更(挿入、更新、削除)は、トランザクション ログに基づいた、データベースでサポートされる変更データ キャプチャ(CDC)と、データベース管理システムのクエリ インターフェースを使用したデータ自体の差分クエリの 2 つの方法で検出できます。
トランザクション ログに基づいた CDC
データベースでサポートされる CDC は、クエリ インターフェースとは異なるデータベース管理機能に基づいています。このアプローチのうちの 1 つは、MySQL のバイナリログなど、トランザクション ログに基づいています。トランザクション ログには、データに加えられた変更が正しい順序で含められます。トランザクション ログは継続的に読み取られるため、すべての変更をモニタリングできます。データベース移行において、このロギングが非常に役立ちます。CDC で各変更を表示し、正しい順序でデータの損失を発生させることなくターゲット データベースにデータを移行できます。
CDC は、データベース管理システムの変更の取得で推奨されるアプローチです。CDC はデータベース自体に組み込まれており、システムへの負荷の影響が最も少ないアプローチです。
差分クエリ
すべての変更を正しい順序でモニタリングできるデータベース管理システム機能が存在しない場合は、代替手段として差分クエリを使用できます。このアプローチでは、データベース内の各データ項目に、タイムスタンプまたはシーケンス番号を含む追加の属性を付与します。データ項目が変更されるたびに、変更タイムスタンプが追加されるか、シーケンス番号が増分されます。ポーリング アルゴリズムが、最後にタイムスタンプが追加されたとき以降の、あるいは最後に使用されたシーケンス番号以降のすべてのデータ項目を読み取ります。ポーリング アルゴリズムにより変更が検出されると、現在の時刻またはシーケンス番号が内部状態に記録され、変更がターゲット データベースに渡されます。
このアプローチは挿入と更新で問題なく機能しますが、削除の場合はデータ項目がデータベースから削除されるため、削除に関しては慎重に設計する必要があります。データが削除された後、ポーラーは削除が発生したことを検出できません。削除は、データが削除されたことを示す追加のステータス フィールド(論理削除フラグ)を使用して実装できます。また、削除されたデータ項目を 1 つ以上のテーブルに収集し、ポーラーでそれらのテーブルにアクセスすることで、削除が発生したかどうかを判定することもできます。
差分クエリのバリアントについては、変更データ キャプチャをご覧ください。
差分クエリは、スキーマと機能の変更を伴うため、最も推奨されないアプローチです。データベースにクエリを実行すると、クライアント ロジックの実行に関係のないクエリ負荷も追加されます。
アダプタとエージェント
データベース移行システムは、ソースとデータベース システムにアクセスする必要があります。アダプタは、アクセス機能をカプセル化した抽象化機能です。最も単純な形式では、JDBC をサポートするターゲット データベースにデータを挿入する JDBC ドライバをアダプタとして使用できます。より複雑なケースでは、アダプタはターゲット(エージェントとも呼ばれます)の環境で実行され、ログファイルなどの組み込みのデータベース インターフェースにアクセスします。さらに複雑なケースでは、アダプタやエージェントがさらに別のソフトウェア システムと接続され、そこからデータベースにアクセスします。たとえば、エージェントが Oracle GoldenGate にアクセスし、そこから Oracle データベースにアクセスする場合などです。
ソース データベースにアクセスするアダプタまたはエージェントは、データベース システムの設計に応じて、CDC インターフェースまたは差分クエリ インターフェースを実装します。どちらのケースでも、アダプタやエージェントによりデータベース移行システムに変更内容が提供されます。データベース移行システムは、変更が CDC と差分クエリのどちらによってキャプチャされたかを認識しません。
データの変更
一部のユースケースでは、データは変更されずにソース データベースからターゲット データベースに移行されます。これらのストレートスルーな移行は通常、同機種の移行になります。
しかし多くのユースケースでは、移行プロセス中にデータを変更する必要があります。通常、スキーマやデータ値に違いがある場合や、移行中にデータをクリーンアップする機会がある場合には、変更が必要です。
次のセクションでは、データ移行で必要となる可能性があるいくつかのタイプの変更(データの変換、データ拡充または相関、データの削減またはフィルタリング)について説明します。
データの変換
データの変換は、ソース データベースの一部またはすべてのデータ値を変換します。以下はその一例です。
- データ型の変換。ソース データベースとターゲット データベース間で、データ型が同等ではない場合があります。このような場合、データ型変換が型変換ルールに基づいてソース値をターゲット値にキャストします。たとえば、ソースのタイムスタンプ型がターゲットで文字列型に変換されることがあります。
- データ構造の変換。データ構造の変換は、同じデータベース モデル内、または異なるデータベース モデル間の構造を変更します。たとえば、リレーショナル システムで、1 つのソーステーブルが 2 つのターゲット テーブルに分割されたり、複数のソーステーブルが結合を使用して 1 つのターゲット テーブルに非正規化されたりすることがあります。ソース データベースの 1:n 関係が、Spanner では親子関係に変換される場合があります。ソース ドキュメント データベース システムのドキュメントが、ターゲット システムでは一連のリレーショナル行に分解される場合があります。
- データ値の変換。データ値の変換は、データ型の変換とは異なります。データ値の変換は、データ型を変更せずに値を変更します。たとえば、ローカル タイムゾーンが協定世界時(UTC)に変換される場合などがあります。また、文字列で表される短い郵便番号(5 桁)が、長い郵便番号(5 桁の後にダッシュと 4 桁が続く。ZIP+4 とも呼ばれる)に変換される場合もあります。
データの拡充と相関
データ変換は、追加の関連する参照データを参照せずに既存のデータに適用されます。データの拡充では、追加のデータがクエリされ、ソースデータがターゲット データベースに格納される前に拡充されます。
- データ相関。ソースデータは関連付けることができます。たとえば、2 つのソース データベースの 2 つのテーブルのデータを組み合わせることができます。たとえば、顧客データと注文データを 2 つの異なるデータベースから取得し、顧客データをオープン、完了、キャンセル済みの 3 つの注文すべてに関連付け、単一のターゲット データベースに格納できます。
- データ拡充。データ拡充は参照データを追加します。たとえば、郵便番号のみを含むレコードに郵便番号と対応する市区町村名を追加することで、レコードを拡充できます。郵便番号と対応する市区町村名を含む参照テーブルは、このユースケースでアクセスされる静的データセットです。また、参照データは動的にすることもできます。たとえば、すべての既知の顧客のリストを参照データとして使用できます。
データの削減とフィルタリング
ターゲット データベースに移行する前にソースデータを削減またはフィルタリングするデータ変換もあります。
- データの削減。データの削減は、データ項目から属性を削除します。たとえば、データ項目に郵便番号が含まれていて、再計算できる、必要がなくなったなどの理由で対応する市区町村名が不要になった場合に、市区町村名を削除できます。またこの情報が、(年月を経て市区町村名が変わる場合でも)ユーザーが入力した市区町村名を記録するための履歴として保持されることもあります。
- データのフィルタリング。データのフィルタリングは、データ項目を完全に削除します。たとえば、キャンセルされたすべての注文データを削除して、ターゲット データベースに移行しないようにすることができます。
データの結合と再結合
データが異なるソース データベースから異なるターゲット データベースに移行される場合に、ソース データベースとターゲット データベースの間でデータを異なる方法で結合する必要性が生じることがあります。
たとえば、顧客データと注文データが 2 つの異なるソース データベースに格納されているとします。片方のソース データベースにはすべての注文データが含まれ、もう片方のソース データベースにはすべての顧客データが含まれます。移行後、顧客データとその注文データは 1 つのターゲット データベース スキーマ内で 1:n の関係で格納されます。ただし、1 つのターゲット データベースではなく、それぞれにデータのパーティションが含まれる複数のターゲット データベースに格納されます。各ターゲット データベースはリージョンを表し、そのリージョン内のすべての顧客データとその注文データが含まれます。
ターゲット データベースのアドレス指定
ターゲット データベースが 1 つだけの場合を除き、移行する各データ項目は適切なターゲット データベースに送信する必要があります。ターゲット データベースのアドレス指定の方法には、次の 2 つがあります。
- スキーマベースのアドレス指定。スキーマベースのアドレス指定は、スキーマに基づいてターゲット データベースを決定します。たとえば、一連の顧客情報にあるすべてのデータ項目や顧客テーブルのすべての行は、複数のソース データベースに分散されていたとしても、顧客情報を格納する同じターゲット データベースに移行されます。
- コンテンツ ベースのルーティング。コンテンツ ベースのルーターなどを使用して行うコンテンツ ベースのルーティングは、データ値に基づいてターゲット データベースを決定します。たとえば、ラテンアメリカ リージョンの顧客データのすべてを、そのリージョンを表す特定のターゲット データベースに移行できます。
データベースの移行では、両方のアドレス指定方法を同時に使用できます。使用されるアドレス指定方法に関係なくデータ項目が格納されるように、ターゲット データベースには正しいスキーマが必要です。
転送中データの永続性
データベース移行システム、あるいはそれらが実行される環境で移行中に障害が発生し、転送中のデータが失われる場合があります。障害が発生した場合は、データベース移行システムを再起動し、ソース データベースに保存されているデータがターゲット データベースに整合性のある形で完全に移行されているかを確認する必要があります。
復元の一環として、データベース移行システムで最後に正常に移行されたデータ項目を特定して、ソース データベースからの抽出を開始する場所を決定する必要があります。障害が発生した時点から再開するには、システムで移行の進行状況に関する内部状態を保持する必要があります。
状態を保持する方法は複数あります。
- データベースを変更する前に、抽出したすべてのデータ項目をデータベース移行システムに保存し、変更後のバージョンが正常にターゲット データベースに保存された後にデータ項目を削除します。このアプローチにより、データベース移行システムは、どの項目が抽出され保存されているかを正確に特定できるようになります。
- 転送中のデータ項目への参照リストは保持できます。各データ項目の主キーなど、一意の識別子をステータス属性とともに保持することが 1 つの方法です。障害の発生後は、この状態がシステムを整合性のある形で復元するための基盤になります。
- 障害発生後にソース データベースとターゲット データベースにクエリを実行して、ソース データベース システムとターゲット データベース システムの違いを判断できます。次に抽出されるデータ項目を、この差に基づいて決定できます。
状態を保持する他の方法は、ソース データベースによって異なります。たとえば、データベース移行システムでは、ソース データベースから取得されるトランザクション ログエントリや、ターゲット データベースに挿入されるトランザクション ログエントリをトラックできます。障害が発生した場合、最後に正常に挿入されたエントリから移行を再開できます。
転送中データの永続性は、エラーや障害以外の理由でも重要となります。たとえば、ソース データベースのデータをクエリしてその状態を判断できない場合があります。たとえば、ソース データベースにキューが含まれていた場合、そのキュー内のメッセージがいずれかの時点で削除された可能性があります。
転送中データの永続性のもう 1 つのユースケースは、データの大規模なウィンドウ処理です。データの変更中、データ項目を互いに独立して変換できます。ただし、データの変更が複数のデータ項目に依存している場合があります(たとえば、毎日 0 から開始され処理されるデータ項目の番号付け)。
転送中データの永続性の最後のユースケースは、データベース システムがソース データベースに再度アクセスできない場合のデータ変更中に、データの再現性を提供することです。たとえば、異なる変更ルールを使用してデータ変更を再実行し、その結果を検証して、初期のデータ変更と比較する必要がある場合があります。不適切なデータ変更のために生じたターゲット データベースの不整合をトラックする必要がある場合、このアプローチが必要になることがあります。
完全性と整合性の検証
データベースの移行が完全で、整合性があることを確認する必要があります。このチェックにより、各データ項目が一度だけ移行され、ソース データベースとターゲット データベースのデータセットが同一であり、移行が完了していることを確認できます。
データ変更ルールによっては、データ項目が抽出されたとしてもターゲット データベースに挿入されない場合があります。そのため、ソース データベースとターゲット データベースを直接比較することは、完全性と整合性を検証するための確実なアプローチにはなりません。ただし、データベース移行システムによりフィルタで除外された項目がトラックされている場合は、除外された項目を加味することでソース データベースとターゲット データベースを比較できます。
データベース管理システムのレプリケーション機能
同機種の移行における特殊なユースケースとして、ターゲット データベースがソース データベースのコピーである場合があります。具体的には、ソース データベースとターゲット データベースのスキーマが同じで、データ値が同じで、各ソース データベースがターゲット データベースに直接マッピング(1:1)される場合です。
この場合、ほとんどのデータベース管理システムに組み込まれているレプリケーション機能を使用して、データベースを別のデータベースに複製できます。
データ レプリケーションには、論理と物理の 2 種類があります。
論理レプリケーション: 論理レプリケーションの場合、データベース オブジェクトの変更はレプリケーション識別子(通常は主キー)に基づいて転送されます。論理レプリケーションのメリットは、柔軟性が高く、きめ細かいこと、またカスタマイズできることです。場合によっては、論理レプリケーションを使用して、異なるデータベース エンジン バージョン間で変更を複製できます。多くのデータベース エンジンは論理レプリケーション フィルタをサポートしています。このフィルタでは、複製するデータセットを定義できます。主なデメリットは、論理レプリケーションではパフォーマンスのオーバーヘッドが生じる可能性があることです。また、このレプリケーション方法のレイテンシは通常、物理レプリケーションのレイテンシよりも高くなります。
物理レプリケーション: 一方、物理レプリケーションはディスク ブロックレベルで動作し、レプリケーション レイテンシが低いため、パフォーマンスが向上します。大規模なデータセットの場合、特に非リレーショナル データ構造の場合、物理レプリケーションはより簡単で効率的です。ただし、カスタマイズはできず、データベース エンジンのバージョンに大きく依存します。
レプリケーション機能には、MySQL レプリケーション、PostgreSQL レプリケーション(pglogical もご覧ください)、Microsoft SQL Server レプリケーションなどがあります。
ただし、データの変更が必要な場合や、直接マッピング以外のカーディナリティがある場合は、このようなユースケースに対処するためにデータベース移行システムの機能が必要です。
カスタム データベース移行機能
データベース移行システムやデータベース管理システムを使用する代わりに、データベース移行機能を構築する理由には以下のようなものがあります。
- あらゆる箇所を完全に制御する必要がある場合。
- データベース移行機能を再利用したい場合。
- コストの削減や、技術的なフットプリントの簡素化を行いたい場合。
移行機能を構築するための構成要素には、以下のものがあります。
- エクスポートとインポート: 同機種のデータベースの移行でダウンタイムが問題にならない場合は、データベースのエクスポートとインポートを使用して、データを移行できます。ただし、エクスポートとインポートでは、データをエクスポートする前にソース データベースを停止して更新を止める必要があります。そうしないと、変更がエクスポートでキャプチャされず、ターゲット データベースがソース データベースの正確なコピーにならない場合があります。
- バックアップと復元: エクスポートとインポートの場合と同様に、バックアップと復元ではダウンタイムが発生します。バックアップにすべてのデータと最新の変更を含めるためにソース データベースを停止する必要があるからです。このダウンタイムは、ターゲット データベースで復元が正常に完了するまで続きます。
- 差分クエリ: データベース スキーマを変更できる場合に、スキーマを拡張して、クエリ インターフェースでデータベースの変更を照会できるようにします。この場合、最後の変更時刻を示す追加のタイムスタンプ属性が付与されます。追加の削除フラグを加えて、データ項目が削除されたかどうか(論理削除)を表すこともできます。これら 2 つの変更を加えることで、一定間隔で実行されるポーラーで、最後にポーラーが実行された時点以降のすべての変更をクエリできます。これらの変更はすべてターゲット データベースに適用されます。その他のアプローチについては、変更データ キャプチャをご覧ください。
これらは、カスタム データベース移行を構築するために利用できるオプションのごく一部です。カスタム ソリューションは実装を最も柔軟に制御できますが、バグやスケーラビリティの制限など、データベースの移行中に発生する可能性がある問題に対処するための、定期的なメンテナンスが必要となります。
データベース移行に関するその他の考慮事項
以下のセクションでは、データベースの移行において重要な機能以外の点について簡単に説明します。これらの点として、エラー処理、スケーラビリティ、高可用性、障害復旧などがあります。
エラー処理
データベースの移行中に障害が発生しても、データが失われたり、データベースの変更処理の順序が変わったりすることはあってはなりません。データの整合性は、障害の原因(システムのバグ、ネットワークの中断、VM のクラッシュ、ゾーンの障害など)に関係なく保持されなければなりません。
データ損失は、移行システムがソース データベースからデータを取得し、なんらかのエラーのためにターゲット データベースに保存しない場合に発生します。データが失われた場合、ターゲット データベースはソース データベースと一致しないため、整合性がなく不完全になります。完全性と整合性の検証機能では、この状態にフラグが立てられます(完全性と整合性の検証)。
スケーラビリティ
データベースの移行において、移行時間は重要な指標です。ゼロ ダウンタイム(正確には最小のダウンタイム)の移行では、ソース データベースが変更されている間にデータの移行が行われます。(特にソース データベース システムが大規模な場合に)適切な時間枠で移行するには、データ転送速度がソース データベース システムの更新速度よりも大幅に高速でなければなりません。転送速度が高いほど、データベースの移行を迅速に完了できます。
ソース データベース システムが停止していて変更されていない場合は、組み込む変更がないため、移行が速くなる可能性があります。同機種のデータベースでは、「バックアップと復元」機能や「エクスポートとインポート」機能を使用でき、またファイル転送がスケーリングされるため、移行時間を大幅に短縮できる場合があります。
高可用性と障害復旧
一般に、ソース データベースとターゲット データベースは高可用性向けに構成されています。プライマリ データベースには、障害発生時にプライマリ データベースとして昇格される、対応するリードレプリカがあります。
ゾーンに障害が発生した場合、ソース データベースまたはターゲット データベースは別のゾーンにフェイルオーバーするため、継続的に使用できます。データベースの移行中にゾーン障害が発生すると、ソース データベースまたはターゲット データベースの一部にアクセスできなくなるため、移行システムそのものが影響を受けます。移行システムは、障害発生後に実行される、新たに昇格したプライマリ データベースに再接続する必要があります。データベース移行システムが再接続されたら、移行そのものを復元して、ターゲット データベース内のデータの完全性と整合性を確保する必要があります。移行システムは、再開する場所を確立するために、最後に行われた整合性のある転送を特定する必要があります。
実行されているゾーンにアクセスできなくなった場合など、データベース移行システム自体に障害が発生した場合、システムを復旧する必要があります。復旧アプローチの 1 つに、コールド リスタートがあります。このアプローチでは、データベース移行システムが運用ゾーンにインストールされ、再起動されます。移行システムで、障害発生前の最後の整合性のあるデータ転送を特定し、その時点から再開して、ターゲット データベースのデータの完全性と整合性を確保できるようにすることが最も重要です。
データベース移行システムで高可用性が有効になっている場合は、フェイルオーバーを行い処理を続行できます。データベース移行システムのダウンタイムを短縮することが重要となる場合は、データベースを選択して高可用性を実装する必要があります。
データベース移行の復元という点において、障害復旧は高可用性と非常に似ています。別のゾーンで新しく昇格したプライマリ データベースに再接続する代わりに、データベース移行システムは別のリージョン(フェイルオーバー リージョン)のデータベースに再接続する必要があります。同じことがデータベース移行システムそのものにも当てはまります。データベース移行システムが実行されているリージョンにアクセスできなくなった場合、データベース移行システムは別のリージョンにフェイルオーバーし、最後に整合性のあるデータ転送が行われた時点から続行する必要があります。
注意点
ターゲット データベースでデータの不整合を引き起こす可能性がある注意点がいくつかあります。よくある問題は次のとおりです。
- 順序の違反。スケールアウトによって移行システムのスケーラビリティが実現されている場合、複数のデータ転送プロセスが同時に(並行で)実行されます。ソース データベース システムの変更は、commint されたトランザクションに応じて順序付けられます。トランザクション ログから変更が取得される場合は、移行全体を通じてその順序が保持される必要があります。並列データ転送では、基盤のプロセス間で速度が異なるため、順序が変わる可能性があります。データがソース データベースから受信される順序と同じ順序でターゲット データベースに挿入されるようにする必要があります。
- 整合性の違反。差分クエリの場合、ソース データベースには commit タイムスタンプなどを含む追加のデータ属性が付与されています。commit タイムスタンプは、ソース データベースでチェンジ マネジメントを行うためにのみ使用されるため、ターゲット データベースには commit タイムスタンプがありません。ターゲット データベースに挿入されるデータが、タイムスタンプの点で整合性のある状態にすることが重要です。つまり、同じタイムスタンプを持つすべての変更が、同じ insert、update、upsert トランザクション内にある必要があります。そのようにしない場合、一部の変更が挿入され、同じタイムスタンプを持つ他の変更が挿入されない状況が発生し、ターゲット データベースの状態が一時的に不整合な状態になる可能性があります。この一時的な不整合状態は、ターゲット データベースが処理のためにアクセスされない場合は問題になりません。ただし、ターゲット データベースがテストで使用される場合は、整合性が最も重要になります。別の側面は、ソースデータベースでのタイムスタンプ値の作成と、それらが設定されているトランザクションの commit 時間との関係です。トランザクションの commit の依存関係のため、タイムスタンプが早いトランザクションは、タイムスタンプが遅いトランザクションの後に表示される可能性があります。2 つのトランザクション間で差分クエリが実行された場合、タイムスタンプが古いトランザクションは確認されないため、ターゲット データベースで不整合が発生します。
- データの欠落や重複。フェイルオーバーの発生時、プライマリとフェイルオーバー レプリカの間で一部のデータが複製されない場合、慎重に復元する必要があります。たとえば、ソース データベースがフェイルオーバーしていて、すべてのデータがフェイルオーバー レプリカに複製されていないとします。また、データは障害が発生する前にターゲット データベースにすでに移行されているとします。フェイルオーバー後に新たに昇格したプライマリ データベースは、ターゲット データベースに加えられたデータ変更の点で遅れています(フラッシュバックと呼ばれます)。移行システムでこの状況を認識し、ターゲット データベースとソース データベースで整合性のとれた状態に戻るように復元する必要があります。
- ローカル トランザクション。ソース データベースとターゲット データベースに同じ変更を適用する場合、データ移行システムを使用せずに、ソース データベースとターゲット データベースの両方に書き込む方法が一般的です。このアプローチにはいくつかの注意点があります。1 つ目の注意点は、2 つのデータベース書き込みが 2 つの別々のトランザクションであるということです。1 つ目の書き込みが終了してから 2 つ目が終了するまでに障害が発生する可能性があります。このシナリオではデータの整合性が失われるため、そこから復元する必要があります。また、たいていの場合クライアントは複数存在しており、クライアント同士に連係はありません。クライアントはソース データベース トランザクションの commit 順序を把握できないため、そのトランザクション順序を反映しているターゲット データベースに書き込むことはできません。クライアントにより順序が変更される可能性があり、これによりデータの不整合が発生する可能性があります。すべてのアクセスが連係のあるクライアントを経由していて、すべてのクライアントがターゲット トランザクションの順序を把握できる場合を除き、このアプローチではターゲット データベースとの不整合が発生する可能性があります。
他にも、一般的な注意点があります。データの不整合につながる可能性のある問題を見つける最適な方法は、考えられるすべての障害シナリオを繰り返す完全な障害分析を行うことです。データベース移行システムで同時実行が実装されている場合、考えられるすべてのデータ移行プロセスの実行順序を調べて、データの整合性が維持されるようにする必要があります。高可用性や障害復旧(あるいはその両方)が実装されている場合は、考えられるすべての障害の組み合わせを調べる必要があります。
次のステップ
- データベースの移行: コンセプトと原則(パート 2)を読む。
- データベースの移行については、次のドキュメントをご覧ください。
- データベースの移行で、その他のデータベースへの移行方法を確認する。
- Google Cloud に関するリファレンス アーキテクチャ、図、ベスト プラクティスを確認する。Cloud アーキテクチャ センターをご覧ください。