このページでは、オープンソース PostgreSQL データベースを Spanner に移行する方法について説明します。
この移行では次のタスクを行います。
- PostgreSQL スキーマを Spanner スキーマにマッピングする。
- Spanner のインスタンス、データベース、スキーマを作成する。
- アプリケーションをリファクタリングして Spanner データベースと連携できるようにする。
- データを移行する。
- 新しいシステムを検証して本番環境ステータスに移行する。
また、このページでは MusicBrainz PostgreSQL データベースのテーブルを使用したスキーマの例をいくつか紹介します。
PostgreSQL スキーマを Spanner にマッピングする
データベースを PostgreSQL から Spanner に移行するための最初のステップは、スキーマをどのように変更する必要があるのかを判断することです。pg_dump を使用して、PostgreSQL データベース内のオブジェクトを定義するデータ定義言語(DDL)ステートメントを作成し、次のセクションの説明に従ってステートメントを変更します。DDL ステートメントを更新したら、それを使用して Spanner インスタンスにデータベースを作成します。
データ型
次の表に、PostgreSQL のデータ型と Cloud Spanner のデータ型の対応を示します。DDL ステートメントのデータ型を PostgreSQL のデータ型から Spanner のデータ型に変更してください。
| PostgreSQL | Spanner |
|---|---|
Bigint
|
INT64 |
Bigserial
|
INT64 |
bit [ (n) ] |
ARRAY<BOOL> |
bit varying [ (n) ]
|
ARRAY<BOOL> |
Boolean
|
BOOL |
box |
ARRAY<FLOAT64> |
bytea |
BYTES |
character [ (n) ]
|
STRING |
character varying [ (n) ]
|
STRING |
cidr |
STRING(標準の CIDR 表記を使用) |
circle |
ARRAY<FLOAT64> |
date |
DATE |
double precision
|
FLOAT64 |
inet |
STRING |
Integer
|
INT64 |
interval[ fields ] [ (p) ] |
ミリ秒単位で値を格納する場合は INT64、アプリケーションで定義した時間間隔形式で値を格納する場合は STRING。 |
json |
STRING |
jsonb |
JSON |
line |
ARRAY<FLOAT64> |
lseg |
ARRAY<FLOAT64> |
macaddr |
STRING(標準の MAC アドレス表記を使用) |
money |
INT64 または STRING(任意精度の数値の場合) |
numeric [ (p, s) ]
|
PostgreSQL では、カラムの宣言で定義されているように、NUMERIC データ型と DECIMAL データ型は最大 217 桁の精度と、214-1 桁のスケールをサポートします。Spanner NUMERIC のデータ型は、最大 38 桁の精度と 10 進 9 桁のスケールをサポートします。精度の向上が必要な場合は、代替メカニズムについて任意の精度の数値データの保存をご覧ください。 |
path |
ARRAY<FLOAT64> |
pg_lsn |
このデータ型は PostgreSQL 固有であるため、Spanner には対応するデータ型がありません。 |
point |
ARRAY<FLOAT64> |
polygon |
ARRAY<FLOAT64> |
Real
|
FLOAT64 |
Smallint
|
INT64 |
Smallserial
|
INT64 |
Serial
|
INT64 |
text |
STRING |
time [ (p) ] [ without time zone ] |
STRING(HH:MM:SS.sss 表記を使用) |
time [ (p) ] with time zone
|
STRING(HH:MM:SS.sss+ZZZZ 表記を使用)また、TIMESTAMP 型の列と、タイムゾーンを保持する列の 2 つの列に分けることもできます。 |
timestamp [ (p) ] [ without time zone ] |
対応するデータ型はありません。自らの判断で STRING または TIMESTAMP として保存できます。 |
timestamp [ (p) ] with time zone
|
TIMESTAMP |
tsquery |
対応するデータ型はありません。代わりにアプリケーションでストレージ メカニズムを定義してください。 |
tsvector |
対応するデータ型はありません。代わりにアプリケーションでストレージ メカニズムを定義してください。 |
txid_snapshot |
対応するデータ型はありません。代わりにアプリケーションでストレージ メカニズムを定義してください。 |
uuid |
STRING または BYTES |
xml |
STRING |
主キー
Spanner データベースにテーブルを頻繁に追加する場合、そうしたテーブルには単調に増減する主キーを使用しないでください。この方法では、書き込み中にホットスポットが発生するからです。代わりに、DDL の CREATE TABLE ステートメントを変更して、サポートされている主キー戦略を使用します。UUID データ型や関数、SERIAL データ型、IDENTITY 列、シーケンスなどの PostgreSQL 機能を使用している場合は、Google が推奨する自動生成されたキーの移行戦略を利用できます。
主キーを指定した後は、後でテーブルを削除して再作成しない限り、主キー列の追加や削除はできません。また、主キーの値を変更することもできません。主キーの指定方法の詳細については、スキーマとデータモデルの主キーをご覧ください。
移行中に、単調増加する既存の整数キーの一部を保持する必要があるかもしれません。この種のキーが頻繁に操作される、更新頻度の高いテーブルでそれらのキーを保持する必要がある場合は、既存のキーに疑似乱数の接頭辞を付けることで、ホットスポットが作成されるのを防ぐことができます。この手法を使用すると、Spanner は行を再分配します。この手法の詳細については、DBA が Spanner について知っておくべきこと、パート 1: キーとインデックスをご覧ください。
外部キーと参照整合性
詳細については、Spanner での外部キーのサポートをご覧ください。
インデックス
PostgreSQL の B-tree インデックスは、Spanner のセカンダリ インデックスと似ています。Spanner データベースでは、パフォーマンスを向上させる目的でよく検索される列にインデックスを付けたり、テーブルで指定された UNIQUE 制約を代用するためにセカンダリ インデックスを使用します。たとえば、PostgreSQL DDL に次のステートメントがあるとします。
CREATE TABLE customer (
id CHAR (5) PRIMARY KEY,
first_name VARCHAR (50),
last_name VARCHAR (50),
email VARCHAR (50) UNIQUE
);
この場合、Spanner DDL では次のようなステートメントを使用します。
CREATE TABLE customer (
id STRING(5),
first_name STRING(50),
last_name STRING(50),
email STRING(50)
) PRIMARY KEY (id);
CREATE UNIQUE INDEX customer_emails ON customer(email);
任意の PostgreSQL テーブルのインデックスを見つけるには、psql で \di メタコマンドを実行します。
必要なインデックスが判明したら、CREATE INDEX ステートメントを追加してそれらを作成します。インデックスの作成のガイダンスに従ってください。
Spanner はインデックスをテーブルとして実装するので、単調増加する列(TIMESTAMP データを含む列など)にインデックスを付けると、ホットスポットが発生することがあります。ホットスポットを回避する方法の詳細については、DBA が Spanner について知っておくべきこと、パート 1: キーとインデックスをご覧ください。
チェック制約
詳細については、Spanner における CHECK 制約のサポートをご覧ください。
その他のデータベース オブジェクト
アプリケーション ロジックで次のオブジェクトの機能を作成する必要があります。
- ビュー
- トリガー
- ストアド プロシージャ
- ユーザー定義関数(UDF)
- シーケンス ジェネレータとして
serialデータ型を使用する列
これらの機能をアプリケーション ロジックに移行するときは、次のヒントを参考にしてください。
- 使用する SQL ステートメントはすべて、PostgreSQL の SQL 言語から GoogleSQL 言語に移行する必要があります。
- カーソルを使用する場合は、オフセットと制限を使用するようにクエリを作り直すことができます。
Spanner インスタンスを作成する
Spanner のスキーマ要件を満たすように DDL ステートメントを更新したら、それを使用して Spanner でデータベースを作成します。
Spanner インスタンスを作成します。パフォーマンス目標を達成できるように適切なリージョン構成とコンピューティング容量を決定するには、インスタンスのガイダンスに従ってください。
Google Cloud コンソールまたは
gcloudコマンドライン ツールを使用して、データベースを作成します。
コンソール
- インスタンス ページに移動
- サンプル データベースを作成するインスタンスの名前をクリックして、[インスタンスの詳細] ページを開きます。
- [データベースを作成] をクリックします。
- データベースの名前を入力して [続行] をクリックします。
- [データベース スキーマの定義] セクションで、[テキストとして編集] コントロールを切り替えます。
- DDL ステートメントをコピーして [DDL ステートメント] フィールドに貼り付けます。
- [作成] をクリックします。
gcloud
- gcloud CLI をインストールします。
gcloud spanner databases createコマンドを使用して、データベースを作成します。gcloud spanner databases create DATABASE_NAME --instance=INSTANCE_NAME --ddl='DDL1' --ddl='DDL2'
- DATABASE_NAME はデータベースの名前です。
- INSTANCE_NAME は、作成した Spanner インスタンスです。
- DDLn は、変更された DDL ステートメントです。
データベースを作成したら、IAM ロールを適用するの手順でユーザー アカウントを作成し、Cloud Spanner インスタンスとデータベースへの権限を付与します。
アプリケーションとデータアクセス層をリファクタリングする
前述のデータベース オブジェクトを代用するために必要なコードに加えて、次の機能を処理するアプリケーション ロジックを追加する必要があります。
- シーケンシャル キーへの書き込み率が高いテーブルで書き込みに使用する主キーのハッシュ処理。
CHECK制約の範囲に入っていないデータの検証。- 外部キー、テーブルのインターリーブ、またはアプリケーション ロジックでカバーされていない参照整合性チェック(PostgreSQL スキーマのトリガーによって処理される機能を含む)。
リファクタリングは、次の手順で行うことをおすすめします。
- データベースにアクセスするアプリケーション コードをすべて見つけ、それらを単一のモジュールまたはライブラリにリファクタリングします。この方法では、データベースにアクセスするコードが正確にわかるので、変更が必要なコードを正確に把握できます。
- Spanner インスタンスで読み取りと書き込みを行うコードを作成し、PostgreSQL への読み取りと書き込みを行う元のコードに相当する機能を実現します。書き込みの際は、変更された列だけでなく行全体を更新し、Spanner のデータが PostgreSQL のデータと同じになるようにします。
- Spanner では使用できないデータベース オブジェクトと関数の機能を代用するコードを作成します。
データを移行する
Spanner データベースを作成してアプリケーション コードをリファクタリングしたら、データを Spanner に移行できます。
- PostgreSQL の
COPYコマンドを使用して、データを .csv ファイルにダンプします。 .csv ファイルを Cloud Storage にアップロードします。
- Cloud Storage バケットを作成します。
- Cloud Storage コンソールで、バケット名をクリックしてバケット ブラウザを開きます。
- [ファイルをアップロード] をクリックします。
- .csv ファイルがあるディレクトリに移動してそれらを選択します。
- [開く] をクリックします。
Spanner にデータをインポートするアプリケーションを作成します。このアプリケーションでは、Dataflow を使用することも、クライアント ライブラリを直接使用することもできます。最適なパフォーマンスを実現するには、データの一括読み込みのベスト プラクティスのガイダンスに従ってください。
テスト
Spanner インスタンスに対するすべてのアプリケーションの機能をテストして、期待どおりに動作するかどうかを検証します。本番環境レベルのワークロードを実行して、パフォーマンスがニーズを満たすことを確認します。パフォーマンス目標を達成するため、必要に応じてコンピューティング容量を更新します。
新しいシステムに移行する
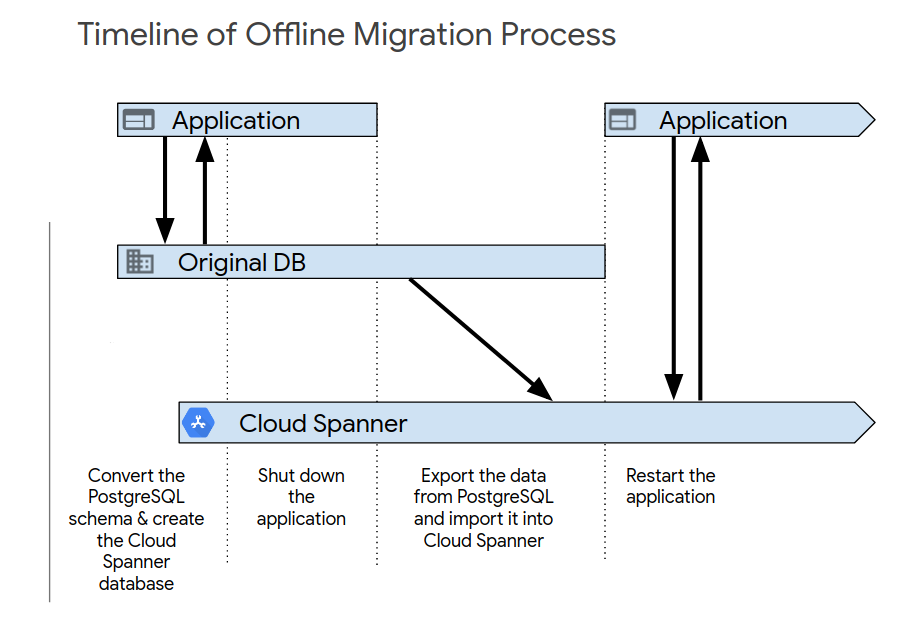
アプリケーションの初期テストが完了したら、次のいずれかの方法で新しいシステムを起動します。最も簡単なのはオフライン移行です。ただし、この方法では一定期間アプリケーションを使用できなくなり、後でデータに関する問題が見つかってもロールバックする手段がありません。オフライン移行を実行するには:
- Spanner データベース内のすべてのデータを削除します。
- PostgreSQL データベースをターゲットとするアプリケーションをシャットダウンします。
- 移行の概要の説明に従って、PostgreSQL データベースからすべてのデータをエクスポートし、Spanner データベースにインポートします。
Spanner データベースをターゲットとするアプリケーションを起動します。
ライブ マイグレーションは可能ですが、マイグレーションを行うにはアプリケーションの大幅な変更が必要です。
スキーマ移行の例
次の例は、MusicBrainz PostgreSQL データベース スキーマのいくつかのテーブル用の CREATE TABLE ステートメントを示しています。それぞれの例には、PostgreSQL スキーマと Spanner スキーマの両方が含まれています。
artist_credit テーブル
GoogleSQL
CREATE TABLE artist_credit (
hashed_id STRING(4),
id INT64,
name STRING(MAX) NOT NULL,
artist_count INT64 NOT NULL,
ref_count INT64,
created TIMESTAMP OPTIONS (
allow_commit_timestamp = true
),
) PRIMARY KEY(hashed_id, id);
PostgreSQL
CREATE TABLE artist_credit (
id SERIAL,
name VARCHAR NOT NULL,
artist_count SMALLINT NOT NULL,
ref_count INTEGER DEFAULT 0,
created TIMESTAMP WITH TIME ZONE DEFAULT NOW()
);
recording テーブル
GoogleSQL
CREATE TABLE recording (
hashed_id STRING(36),
id INT64,
gid STRING(36) NOT NULL,
name STRING(MAX) NOT NULL,
artist_credit_hid STRING(36) NOT NULL,
artist_credit_id INT64 NOT NULL,
length INT64,
comment STRING(255) NOT NULL,
edits_pending INT64 NOT NULL,
last_updated TIMESTAMP OPTIONS (
allow_commit_timestamp = true
),
video BOOL NOT NULL,
) PRIMARY KEY(hashed_id, id);
PostgreSQL
CREATE TABLE recording (
id SERIAL,
gid UUID NOT NULL,
name VARCHAR NOT NULL,
artist_credit INTEGER NOT NULL, -- references artist_credit.id
length INTEGER CHECK (length IS NULL OR length > 0),
comment VARCHAR(255) NOT NULL DEFAULT '',
edits_pending INTEGER NOT NULL DEFAULT 0 CHECK (edits_pending >= 0),
last_updated TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
video BOOLEAN NOT NULL DEFAULT FALSE
);
recording-alias テーブル
GoogleSQL
CREATE TABLE recording_alias (
hashed_id STRING(36) NOT NULL,
id INT64 NOT NULL,
alias_id INT64,
name STRING(MAX) NOT NULL,
locale STRING(MAX),
edits_pending INT64 NOT NULL,
last_updated TIMESTAMP NOT NULL OPTIONS (
allow_commit_timestamp = true
),
type INT64,
sort_name STRING(MAX) NOT NULL,
begin_date_year INT64,
begin_date_month INT64,
begin_date_day INT64,
end_date_year INT64,
end_date_month INT64,
end_date_day INT64,
primary_for_locale BOOL NOT NULL,
ended BOOL NOT NULL,
) PRIMARY KEY(hashed_id, id, alias_id),
INTERLEAVE IN PARENT recording ON DELETE NO ACTION;
PostgreSQL
CREATE TABLE recording_alias (
id SERIAL, --PK
recording INTEGER NOT NULL, -- references recording.id
name VARCHAR NOT NULL,
locale TEXT,
edits_pending INTEGER NOT NULL DEFAULT 0 CHECK (edits_pending >=0),
last_updated TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
type INTEGER, -- references recording_alias_type.id
sort_name VARCHAR NOT NULL,
begin_date_year SMALLINT,
begin_date_month SMALLINT,
begin_date_day SMALLINT,
end_date_year SMALLINT,
end_date_month SMALLINT,
end_date_day SMALLINT,
primary_for_locale BOOLEAN NOT NULL DEFAULT false,
ended BOOLEAN NOT NULL DEFAULT FALSE
-- CHECK constraint skipped for brevity
);