This page introduces the Autoscaler tool for Spanner (Autoscaler), an open source tool that you can use as a companion tool to Spanner. This tool lets you automatically increase or reduce the compute capacity in one or more Spanner instances based on how much capacity is in use.
For more information about scaling in Spanner, see Autoscaling Spanner. For information about deploying the Autoscaler tool, see the following:
- Deploy the Autoscaler tool for Spanner to Cloud Run functions.
- Deploy the Autoscaler tool for Spanner to Google Kubernetes Engine (GKE).
This page presents the features, architecture, and high-level configuration of the Autoscaler. These topics guide you through the deployment of the Autoscaler to one of the supported runtimes in each of the different topologies.
Autoscaler
The Autoscaler tool is useful for managing the utilization and performance of your Spanner deployments. To help you to balance cost control with performance needs, the Autoscaler tool monitors your instances and automatically adds or removes nodes or processing units to help ensure that they stay within the following parameters:
Plus or minus a configurable margin.
Autoscaling Spanner deployments enables your infrastructure to automatically adapt and scale to meet load requirements with little to no intervention. Autoscaling also right-sizes the provisioned infrastructure, which can help you to minimize incurred charges.
Architecture
The Autoscaler has two main components, the Poller and the Scaler. Although you can deploy the Autoscaler with varying configurations to multiple runtimes in multiple topologies with varying configurations, the functionality of these core components is the same.
This section describes these two components and their purposes in more detail.
Poller
The Poller collects and processes the time-series metrics for one or more Spanner instances. The Poller preprocesses the metrics data for each Spanner instance so that only the most relevant data points are evaluated and sent to the Scaler. The preprocessing done by the Poller also simplifies the process of evaluating thresholds for regional, dual-region, and multi-regional Spanner instances.
Scaler
The Scaler evaluates the data points received from the Poller component, and determines whether you need to adjust the number of nodes or processing units and, if so, by how much. The compares the metric values to the threshold, plus or minus an allowed margin, and adjusts the number of nodes or processing units based on the configured scaling method. For more details, see Scaling methods.
Throughout the flow, the Autoscaler tool writes a summary of its recommendations and actions to Cloud Logging for tracking and auditing.
Autoscaler features
This section describes the main features of the Autoscaler tool.
Manage multiple instances
The Autoscaler tool is able to manage multiple Spanner instances across multiple projects. Multi-regional, dual-region, and regional instances all have different utilization thresholds that are used when scaling. For example, multi-regional and dual-region deployments are scaled at 45% high-priority CPU utilization, whereas regional deployments are scaled at 65% high-priority CPU utilization, both plus or minus an allowed margin. For more information on the different thresholds for scaling, see Alerts for high CPU utilization.
Independent configuration parameters
Each autoscaled Spanner instance can have one or more polling schedules. Each polling schedule has its own set of configuration parameters.
These parameters determine the following factors:
- The minimum and maximum number of nodes or processing units that control how small or large your instance can be, helping you to control incurred charges.
- The scaling method used to adjust your Spanner instance specific to your workload.
- The cooldown periods to let Spanner manage data splits.
Scaling methods
The Autoscaler tool provides three different scaling methods for up and down scaling your Spanner instances: stepwise, linear, and direct. Each method is designed to support different types of workloads. You can apply one or more methods to each Spanner instance being autoscaled when you create independent polling schedules.
The following sections contain further information on these scaling methods.
Stepwise
Stepwise scaling is useful for workloads that have small or multiple peaks. It provisions capacity to smooth them all out with a single autoscaling event.
The following chart shows a load pattern with multiple load plateaus or steps, where each step has multiple small peaks. This pattern is well suited for the stepwise method.

When the load threshold is crossed, this method provisions and removes nodes or processing units using a fixed but configurable number. For example, three nodes are added or removed for each scaling action. By changing the configuration, you can allow for larger increments of capacity to be added or removed at any time.
Linear
Linear scaling is best used with load patterns that change more gradually or have a few large peaks. The method calculates the minimum number of nodes or processing units required to keep utilization below the scaling threshold. The number of nodes or processing units added or removed in each scaling event is not limited to a fixed step amount.
The sample load pattern in the following chart shows large, sudden increases and decreases in load. These fluctuations are not grouped in discernible steps as they are in the previous chart. This pattern might be better handled using linear scaling.

The Autoscaler tool uses the ratio of the observed utilization over the utilization threshold to calculate whether to add or subtract nodes or processing units from the current total number.
The formula to calculate the new number of nodes or processing units is as follows:
newSize = currentSize * currentUtilization / utilizationThreshold
Direct
Direct scaling provides an immediate increase in capacity. This method is intended to support batch workloads where a predetermined higher node count is periodically required on a schedule with a known start time. This method scales the instance up to the maximum number of nodes or processing units specified in the schedule, and is intended to be used in addition to a linear or stepwise method.
The following chart depicts the large planned increase in load, which Autoscaler pre-provisioned capacity for using the direct method.
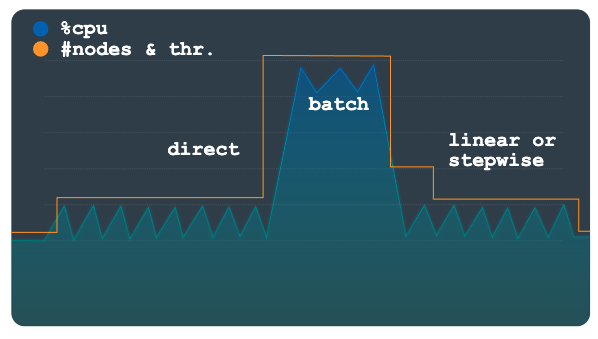
Once the batch workload has completed and utilization returns to normal levels, depending on your configuration, either linear or stepwise scaling is applied to scale the instance down automatically.
Configuration
The Autoscaler tool has different configuration options that you can use to manage the scaling of your Spanner deployments. Though the Cloud Run functions and GKE parameters are similar, they are supplied differently. For more information on configuring the Autoscaler tool, see Configuring a Cloud Run functions deployment and Configuring a GKE deployment.
Advanced configuration
The Autoscaler tool has advanced configuration options that let you more finely control when and how your Spanner instances are managed. The following sections introduce a selection of these controls.
Custom thresholds
The Autoscaler tool determines the number of nodes or processing units to be added or subtracted to an instance using the recommended Spanner thresholds for the following load metrics:
- High priority CPU
- 24-hour rolling average CPU
- Storage utilization
We recommend that you use the default thresholds as described in Creating alerts for Spanner metrics. However, in some cases you might want to modify the thresholds used by the Autoscaler tool. For example, you could use lower thresholds to make the Autoscaler tool react more quickly than for higher thresholds. This modification helps to prevent alerts being triggered at higher thresholds.
Custom metrics
While the default metrics in the Autoscaler tool address most performance and
scaling scenarios, there are some instances when you might need to specify your
own metrics used for determining when to scale in and out. For these scenarios,
you define custom metrics in the configuration using the
metrics
property.
Margins
A margin defines an upper and a lower limit around the threshold. The Autoscaler tool only triggers an autoscaling event if the value of the metric is more than the upper limit or less than the lower limit.
The objective of this parameter is to avoid autoscaling events being triggered for small workload fluctuations around the threshold, reducing the amount of fluctuation in Autoscaler actions. The threshold and margin together define the following range, according to what you want the metric value to be:
[threshold - margin, threshold + margin]
The smaller the margin, the narrower the range, resulting in a higher probability that an autoscaling event is triggered.
Specifying a margin parameter for a metric is optional, and it defaults to five percentage points both preceding and below the parameter.
Data splits
Spanner assigns ranges of data called splits to nodes or subdivisions of a node called processing units. The node or processing units independently manage and serve the data in the apportioned splits. Data splits are created based on several factors, including data volume and access patterns. For more details, see Spanner - schema and data model.
Data is organized into splits and Spanner automatically manages the splits. So, when the Autoscaler tool adds or removes nodes or processing units, it needs to allow the Spanner backend sufficient time to reassign and reorganize the splits as new capacity is added or removed from instances.
The Autoscaler tool uses cooldown periods on both scale-up and scale-down events to control how quickly it can add or remove nodes or processing units from an instance. This method allows the instance the necessary time to reorganize the relationships between compute notes or processing units and data splits. By default, the scale-up and scale-down cooldown periods are set to the following minimum values:
- Scale-up value: 5 minutes
- Scale-down value: 30 minutes
For more information about scaling recommendations and cooldown periods, see Scaling Spanner Instances.
Pricing
The Autoscaler tool resource consumption is minor in terms of compute, memory, and storage. Depending on your configuration of the Autoscaler, when deployed to Cloud Run functions the Autoscaler's resource utilization is usually in the Free Tier of its dependent services (Cloud Run functions, Cloud Scheduler, Pub/Sub, and Firestore).
Use the Pricing Calculator to generate a cost estimate of your environments, based on your projected usage.
What's next
- Learn how to deploy the Autoscaler tool to Cloud Run functions.
- Learn how to deploy the Autoscaler tool to GKE.
- Read more about Spanner recommended thresholds.
- Read more about Spanner CPU utilization metrics and latency metrics.
- Learn about best practices for Spanner schema design to avoid hotspots and for loading data into Spanner.
- Explore reference architectures, diagrams, and best practices about Google Cloud. Take a look at our Cloud Architecture Center.