この記事では、データベースを Oracle® オンライン トランザクション処理(OLTP)システムから Spanner に移行する方法について説明します。
Spanner では、特定のコンセプトの扱いが他のエンタープライズ データベース管理ツールとは異なるため、その機能を最大限に活用するにはアプリケーションを調整する必要がある場合があります。ニーズを満たすために、Spanner を Google Cloud の他のサービスで補完する必要がある場合もあります。
移行の制約
アプリケーションを Spanner に移行する際には、利用可能なさまざまな機能を考慮する必要があります。アプリケーションを Spanner の機能セットに合わせたり、 Google Cloud の他のサービスと統合したりする場合は、アーキテクチャを設計し直す必要が生じるでしょう。
ストアド プロシージャとトリガー
Spanner はデータベース レベルでのユーザーコードの実行をサポートしていないため、移行の一環として、データベースのストアド プロシージャとトリガーによって実装されたビジネス ロジックをアプリケーションに移す必要があります。
シーケンス
主キー値を生成するデフォルトの方法として UUID バージョン 4 を使用することをおすすめします。GENERATE_UUID() 関数(GoogleSQL、PostgreSQL)は、UUID バージョン 4 の値を STRING 型として返します。
64 ビットの整数値を生成する必要がある場合は、Spanner でビット反転した正のシーケンス(GoogleSQL、PostgreSQL)を使用します。これにより 64 ビットの正の数空間に均等に分散する値が生成されます。ホットスポットの問題を回避するため、これらの数値を使用できます。
詳細については、主キーのデフォルト値の戦略をご覧ください。
アクセス制御
Identity and Access Management(IAM)を使用すると、プロジェクト レベル、Spanner インスタンス レベル、Spanner データベース レベルで、Spanner リソースに対するユーザーとグループのアクセスを制御できます。詳しくは IAM の概要をご覧ください。
データベースにアクセスするすべてのユーザーとサービス アカウントに対して、最小権限の原則に従って IAM ポリシーを実装します。アプリケーションで特定のテーブル、列、ビュー、変更ストリームへのアクセスを制限する必要がある場合は、きめ細かいアクセス制御(FGAC)を実装します。詳細については、きめ細かいアクセス制御の概要をご覧ください。
データ検証制約
Spanner は、データベース レイヤで一部のデータ検証制約をサポートしています。
より複雑なデータ制約が必要な場合は、それらをアプリケーション レイヤに実装します。
次の表に、Oracle® データベースで一般的に見られる制約の種類、およびそれらを Spanner で実装する方法を示します。
| 制約 | Spanner での実装 |
|---|---|
| null 以外 | NOT NULL 列の制約 |
| 一意 | UNIQUE 制約付きのセカンダリ インデックス |
| 外部キー(通常のテーブル用) | 外部キー関係の作成と管理をご覧ください。 |
外部キーの ON DELETE/ON UPDATE アクション |
インターリーブされたテーブルでのみ使用可能で、それ以外の場合はアプリケーション レイヤに実装 |
CHECK 制約またはトリガーによる値の確認と検証
|
アプリケーション レイヤに実装 |
サポートされているデータ型
Oracle® データベースと Spanner ではそれぞれ異なるデータ型がサポートされます。次の表に、Oracle のデータ型とそれに対応する Spanner のデータ型を示します。Spanner の各データ型の定義の詳細については、データ型をご覧ください。
備考列で説明されているように、Oracle のデータを Spanner データベースに適合させるために追加のデータ変換が必要になる場合もあります。
たとえば、大きな BLOB をデータベースではなく Cloud Storage バケットにオブジェクトとして保存してから、Cloud Storage オブジェクトへの URI 参照を STRING としてデータベースに保存できます。
| Oracle のデータ型 | Spanner の対応するデータ型 | 注 |
|---|---|---|
文字型(CHAR、VARCHAR、NCHAR、NVARCHAR)
|
STRING
|
注: Spanner では全体的に Unicode 文字列が使用されます。 Oracle は最大 32,000 バイトまたは文字(型によって異なる)をサポートしているのに対し、Spanner は最大 2,621,440 文字をサポートしています。 |
BLOB、LONG RAW、BFILE
|
オブジェクトへの URI を含む BYTES または STRING
|
小さなオブジェクト(10 MiB 未満)は BYTES として保存できます。より大きなオブジェクトを保存する際には、Cloud Storage などの代替 Google Cloud サービスの使用を検討してください。 |
CLOB、NCLOB、LONG |
STRING(データまたは外部オブジェクトへの URI を含む)
|
小さなオブジェクト(2,621,440 文字未満)は STRING として保存できます。より大きなオブジェクトを保存する際には、Cloud Storage などの代替 Google Cloud サービスの使用を検討してください。 |
NUMBER、NUMERIC、DECIMAL |
STRING、FLOAT64、INT64 |
Oracle の NUMBER データ型は、GoogleSQL の NUMERIC データ型と同等です。それぞれ 38 桁の精度と 9 桁のスケールをサポートします((P,S) = (38,9))。PostgreSQL の NUMERIC データ型は、任意精度の数値データを格納します。GoogleSQL の FLOAT64 データ型は、最大 16 桁の精度をサポートします。 |
INT、INTEGER、SMALLINT |
INT64
|
|
BINARY_FLOAT、BINARY_DOUBLE
|
FLOAT64
|
|
DATE
|
DATE
|
Spanner の DATE 型のデフォルトの STRING 表現は yyyy-mm-dd です。これは Oracle のものとは異なるため、日付の STRING 表現との間で自動変換を行う場合は注意が必要です。日付を書式設定済み文字列に変換するための SQL 関数が提供されています。 |
DATETIME
|
TIMESTAMP
|
Spanner では時間はタイムゾーンから切り離して保存されます。タイムゾーンを保存する必要がある場合は、個別の STRING 列を使用する必要があります。タイムスタンプをタイムゾーン付きの書式設定済み文字列に変換するための SQL 関数が提供されています。 |
XML
|
STRING(データまたは外部オブジェクトへの URI を含む) |
小さな XML オブジェクト(2,621,440 文字未満)は STRING として保存できます。より大きなオブジェクトを保存する際には、Cloud Storage などの代替 Google Cloud サービスの使用を検討してください。 |
URI、DBURI、XDBURI、HTTPURI |
STRING
|
|
ROWID
|
PRIMARY KEY
|
Spanner ではテーブルの主キーを使用して内部的に行の並べ替えや参照を行っているため、Spanner では実質的に主キーが ROWID データ型と同じ働きをします。 |
SDO_GEOMETRY、SDO_TOPO_GEOMETRY_SDO_GEORASTER
|
Spanner は地理空間データ型をサポートしていません。標準のデータ型を使用してこのデータを保存し、検索およびフィルタリング ロジックはアプリケーション レイヤに実装する必要があります。 | |
ORDAudio、ORDDicom、ORDDoc、ORDImage、ORDVideo、ORDImageSignature
|
Spanner はメディアデータ型をサポートしていません。メディアデータを保存する際には、Cloud Storage の使用を検討してください。 |
移行プロセス
移行プロセスの全体的なタイムラインは次のようになります。
- スキーマとデータモデルを変換します。
- SQL クエリを変換します。
- Oracle に加えて Spanner を使用するようにアプリケーションを移行します。
- Oracle からデータを一括エクスポートし、Dataflow を使用して、そのデータを Spanner にインポートします。
- 移行時には、両方のデータベース間で整合性を維持します。
- アプリケーションを Oracle から移行します。
ステップ 1: データベースとスキーマを変換する
既存のスキーマを Spanner のスキーマに変換してデータを保存します。アプリケーションの変更を簡単にするために、既存の Oracle スキーマとできるだけ一致させる必要があります。ただし、機能の違いにより、いくつかの変更が必要になります。
スキーマ設計のベスト プラクティスに従うと、Spanner データベースのスループットを向上させ、ホットスポットを減らすことができます。
主キー
Spanner では、いずれのテーブルでも、複数の行を保存する必要がある場合は、そのテーブルの 1 つ以上の列からなる主キーが必要になります。テーブルの主キーはテーブル内の各行を一意に識別します。テーブルの行は主キーで並べ替えられます。Spanner は高度に分散されているため、データの増加に合わせて適切にスケーリングできる主キー生成手法を選択することが重要です。詳細については、推奨される主キーの移行の戦略をご覧ください。
主キーを指定した後は、後でテーブルを削除して再作成しない限り、主キー列の追加や削除はできません。また、主キーの値を変更することもできません。主キーの指定方法の詳細については、スキーマとデータモデルの主キーをご覧ください。
テーブルをインターリーブする
Spanner には、1 対多の親子関係を持つ 2 つのテーブルを定義するための機能があります。この機能を使用すると、データ行の親子がストレージ内でインターリーブされるため、テーブルを事前結合するのと同じ効果があります。こうすることで、親と子を対象としたクエリにおいて、より効率的なデータ取得が可能になります。
子テーブルの主キーは、親テーブルの主キー列で始まる必要があります。子行の観点からは、親行の主キーは外部キーとなります。最大 6 レベルの親子関係を定義できます。
子テーブルに対して削除時アクションを定義して、親行の削除が実行されたときの動作を指定できます。つまり、子行がすべて削除されるようにするか、子行が存在する間は親行の削除がブロックされるようにすることができます。
次に、Albums テーブルを作成して、前に定義した親の Singers テーブルにインターリーブする例を示します。
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
) PRIMARY KEY (SingerId, AlbumId)
INTERLEAVE IN PARENT (Singers)
ON DELETE CASCADE;
セカンダリ インデックスを作成する
セカンダリ インデックスを作成して、テーブル内のデータを主キー以外でインデックス登録することもできます。
Spanner ではテーブルと同じ方法でセカンダリ インデックスが実装されるため、インデックス キーとして使用される列値にはテーブルの主キーと同じ制約が適用されます。したがって、Spanner のテーブルと同様にインデックスの整合性も保証されます。
セカンダリ インデックスを使用した値検索は、テーブル結合を使用したクエリと実質的に同じです。STORING 句を使用して元のテーブルの列値のコピーをセカンダリ インデックスに保存して Covering index とすることで、インデックスを使用したクエリのパフォーマンスが向上します。
Spanner のクエリ オプティマイザーでは、クエリの対象となるすべての列がセカンダリ インデックス自体に保存されている場合(カバードクエリ)に限り、セカンダリ インデックスが自動的に使用されます。元のテーブルの列をクエリするときにインデックスを強制的に使用するには、次の例に示すように、SQL ステートメントで FORCE INDEX ディレクティブを使う必要があります。
SELECT *
FROM MyTable@{FORCE_INDEX=MyTableIndex}
WHERE IndexedColumn=@value
インデックスを使用してテーブルの列内の値を一意にするには、その列に UNIQUE インデックスを定義します。重複する値の追加はインデックスによって防止されます。
次に、Albums テーブルにセカンダリ インデックスを作成する DDL ステートメントの例を示します。
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
データの読み込み後に追加のインデックスを作成すると、インデックスへのデータの入力に時間がかかることがあります。インデックスを追加する頻度は 1 日に平均 3 回までにしてください。セカンダリ インデックスの作成方法の詳細については、セカンダリ インデックスをご覧ください。インデックス作成の制限事項の詳細については、スキーマの更新をご覧ください。
ステップ 2: SQL クエリを変換する
Spanner は、拡張機能を含む ANSI 2011 SQL に対応し、データの変換や集計に役立つ多数の関数と演算子を備えています。Oracle 固有の構文、関数、型を使用する SQL クエリについては、Spanner との互換性を保つために変換する必要があります。
Spanner では構造化データを列定義として使用することはできませんが、ARRAY 型と STRUCT 型を使用すれば、SQL クエリで構造化データを扱うことができます。
たとえば、1 つのクエリで STRUCTs の ARRAY を使用して(事前結合されたデータを利用して)、アーティストのすべてのアルバムを返せます。詳細については、ドキュメントのサブクエリに関する注意セクションをご覧ください。
SQL クエリを実行する際には、 Google Cloud コンソールの [Spanner Studio] ページを使用してクエリのプロファイリングを行うことができます。一般に、大きなテーブルを対象としてテーブル全体のスキャンを実行するクエリには非常にコストがかかるため、使用は控えめにする必要があります。
SQL クエリの最適化の詳細については、SQL のベスト プラクティス ドキュメントをご覧ください。
ステップ 3: Spanner を使用するようにアプリケーションを移行する
Spanner は、さまざまな言語用のクライアント ライブラリを備えています。また、データの読み取りや書き込みには、Spanner 固有の API 呼び出しを使用することも、SQL クエリやデータ変更言語(DML)ステートメントを使用することもできます。キーによって行を直接読み取る場合など一部のクエリでは、API 呼び出しを使用したほうが、処理が速くなることがあります(SQL ステートメントの変換が不要であるため)。
Java Database Connectivity(JDBC)ドライバを使用して Spanner に接続し、ネイティブに統合されていない既存のツールやインフラストラクチャを利用することもできます。
移行プロセスの一環として、Spanner で利用できない機能をアプリケーションに実装する必要があります。たとえば、データ値を検証して関連テーブルを更新するトリガーは、既存の行の読み取り、制約の検証、更新された行の両方のテーブルへの書き込みという一連の処理を実行する読み取り / 書き込みトランザクションを使用して、アプリケーションに実装する必要があります。
Spanner に備えられた読み取り / 書き込みトランザクションと読み取り専用トランザクションによってデータの外部整合性が保証されます。さらに、読み取りトランザクションには、次の方法で指定した整合性のあるデータ バージョンを読み取るようにタイムスタンプ バウンドを適用できます。
- 過去の正確な時刻(最大 1 時間前まで)。
- 将来の時刻(その時間になるまで読み取りがブロックされる)。
- 許容範囲内のバウンド ステイルネス。最新のデータが別のレプリカで利用可能かどうかをチェックすることなく、過去の特定の時点までの整合性のあるビューが返されます。この方法を使用すると、パフォーマンス上の利点が得られる代わりに、データが古くなる可能性があります。
ステップ 4: Oracle から Spanner にデータを転送する
Oracle から Spanner にデータを転送するには、Oracle データベースをポータブル ファイル形式(CSV など)にエクスポートしてから、Dataflow を使用してそのデータを Spanner にインポートする必要があります。
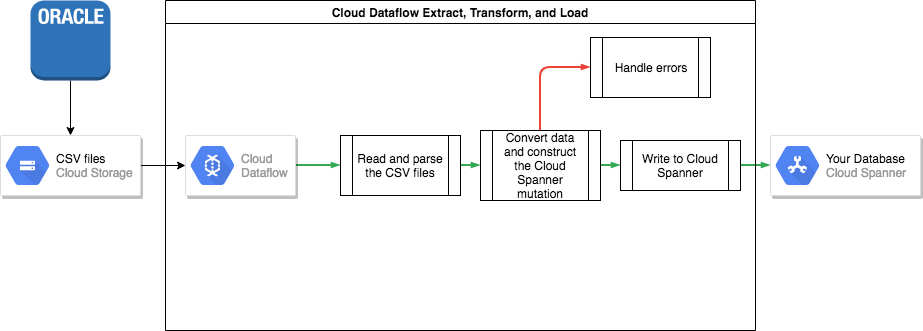
Oracle からの一括エクスポート
Oracle には、データベース全体をポータブル ファイル形式にエクスポートまたはアンロードするための組み込みユーティリティは用意されていません。
Oracle FAQ に、エクスポートを実行する際に使用できるいくつかのオプションが記載されています。
一部を次に示します。
- SQL*plus または SQLcl を使用して、クエリをテキスト ファイルにスプールします。
- テーブルをテキスト ファイルに並列にアンロードするために、UTL_FILE を使用した PL/SQL 関数を記述します。
- Oracle APEX または Oracle SQL Developer 内の機能を使用して、テーブルを CSV または XML ファイルにアンロードします。
これらのいずれについても、一度に 1 つのテーブルしかエクスポートできないという欠点があります。つまり、エクスポートする際には、データベースの整合性を維持するために、アプリケーションを一時停止するか、データベースを静止する必要があります。
Oracle FAQ ページに記載されているサードパーティ ツールを使用するという選択肢もあります。これらのツールの中には、データベース全体の整合性のあるビューをアンロードできるものもあります。
アンロードが終了したら、データファイルを Cloud Storage バケットにアップロードして、インポートできるようにする必要があります。
Spanner への一括インポート
Oracle と Spanner ではデータベース スキーマが異なる可能性があるため、インポート プロセスでデータ変換が必要になる場合があります。
このようなデータ変換処理と Spanner へのデータのインポートは、Dataflow を使用すると最も簡単に実行できます。
Dataflow は、 Google Cloud 分散抽出、変換、読み込み(ETL)サービスです。このサービスは、Apache Beam SDK で記述されたデータ パイプラインを実行するプラットフォームです。これにより、複数のマシン上の大量のデータを並列に読み取って処理できます。
Apache Beam SDK では、簡単な Java プログラムを記述するだけで、データの読み取り、変換、書き込みを実装できます。Cloud Storage と Spanner 用のビームコネクタが標準装備されているため、実際にコーディングが必要なのはデータ変換部分だけです。
この記事に付属のサンプルコード リポジトリで、CSV ファイルから読み取って Spanner に書き込む単純なパイプラインの例をご覧ください。
親子でインターリーブされたテーブルを Spanner で使用する場合は、インポート プロセスで親行が子行より先に作成されるように注意する必要があります。したがって、Spanner のインポート パイプライン コードでは、最初にルートレベルのテーブルのすべてのデータをインポートしてから、レベル 1 のすべての子テーブル、レベル 2 のすべての子テーブル(これ以降も同様)という順序でインポートする必要があります。
Spanner のインポート パイプラインを直接使用してデータを一括でインポートすることもできますが、この場合、適切なスキーマ設計を持つ Avro ファイルにデータが格納されている必要があります。
ステップ 5: 両方のデータベース間で整合性を維持する
多くのアプリケーションには可用性要件が定められており、データのエクスポートとインポートに必要な時間だけアプリケーションをオフラインにすることは困難です。つまり、データを Spanner に転送している間は、引き続き既存のデータベースに変更が反映されることになります。そのため、アプリケーション実行中は、Spanner データベースへの更新内容を複製する必要があります。
変更データ キャプチャ、アプリケーションでの同時更新の実装など、さまざまな方法で 2 つのデータベースを同期できます。
変更データ キャプチャ
Oracle GoldenGate は、Oracle データベースのログから変更データ キャプチャ(CDC)ストリームを生成します。Oracle GoldenGate を使わずに Oracle データベースが CDC ストリームを取得するには、Oracle LogMiner または Oracle XStream Out が代替インターフェースになります。
これらのストリームの 1 つをサブスクライブし、データの変換後に Spanner データベースに同じ変更を適用するアプリケーションを作成できます。このようなストリーム処理アプリケーションでは、次のような機能を実装する必要があります。
- Oracle データベース(移行元データベース)に接続する。
- Spanner(移行先データベース)に接続する。
- 次の処理を繰り返し実行する。
- Oracle データベースの CDC ストリームによって生成されたデータを受信する。
- CDC ストリームによって生成されたデータを解釈する。
- データを Spanner
INSERTステートメントに変換する。 - Spanner
INSERTステートメントを実行する。
データベース移行テクノロジーは、必要な機能が組み込まれたミドルウェア テクノロジーです。データベース移行プラットフォームは、お客様の要件に応じて移行元または移行先に個別のコンポーネントとしてインストールされます。移行元データベースから移行先データベースへの継続的なデータ転送を設定して開始するため、データベース移行プラットフォームには関連するデータベースの接続構成のみが必要になります。
Striim は、Google Cloudで利用可能なデータベース移行テクノロジーのプラットフォームです。Oracle GoldenGate、Oracle LogMiner、Oracle XStream Out からの CDC ストリームに接続できます。Striim のグラフィック ツールを使用して、Oracle から Spanner へのデータ転送に必要なデータベース接続と変換ルールを構成できます。
ストリーム処理アプリケーションを自分で構築しなくても、Google Cloud Marketplace から Striim をインストールして移行元データベースと移行先データベースに接続し、変換ルールを実装してデータを移行できます。
アプリケーションから両方のデータベースを同時に更新する
別の方法は、両方のデータベースへの書き込みを実行するようにアプリケーションを変更することです。一方のデータベース(最初は Oracle)が信頼できる情報源と見なされ、データベースへの書き込みが発生するたびに、行全体が読み取られ、変換されてから Spanner データベースに書き込まれます。
このようにして、アプリケーションによって常に Spanner の行が最新のデータで上書きされます。
すべてのデータが正しく転送されたことを確認したら、信頼できる情報源を Spanner データベースに切り替えることができます。
このメカニズムによって、Spanner に切り替えるときに問題が見つかった場合のロールバック パスが確保されます。
データの整合性を確認する
データが Spanner データベースにストリーミングされるときに、Spanner データと Oracle データを定期的に比較して、データの整合性を検証できます。
整合性を検証する際には、両方のデータソースに対してクエリを実行し、その結果を比較します。
Dataflow では、Join 変換を使用して大規模なデータセットに対して詳細な比較を行うことができます。この変換に 2 つのキー付きデータセットを渡すと、対応する値がキー別に照合されます。その後、対応する値を比較して、等しいかどうかを確認できます。
整合性のレベルがビジネス要件を満たすまで、この検証を定期的に実行できます。
ステップ 6: アプリケーションの信頼できる情報源を Spanner に切り替える
データ移行が確実に終了したら、Spanner を信頼できる情報源として使用するようにアプリケーションを切り替えることができます。以降は、変更を Oracle データベース側にも継続的に反映することで Oracle データベースを最新の状態に保ち、問題が発生した場合のロールバック パスを確保してください。
最終的には、Oracle データベースの更新コードを無効にして削除し、Oracle データベースをシャットダウンできます。
Spanner データベースをエクスポートしてインポートする
必要に応じて、Dataflow テンプレートを使用して、Spanner から Cloud Storage バケットにテーブルをエクスポートできます。その結果、フォルダには、エクスポートされたテーブルを含む一連の Avro ファイルと JSON マニフェスト ファイルが保存されます。これらのファイルは、次のようなさまざまな目的に役立ちます。
- データ保持ポリシーの遵守または障害復旧のためにデータベースをバックアップできます。
- Avro ファイルを BigQuery などの他の Google Cloud サービスにインポートできます。
エクスポートおよびインポート プロセスの詳細については、データベースのエクスポートとデータベースのインポートをご覧ください。
次のステップ
- Spanner スキーマを最適化する方法について読む。
- Dataflow をより複雑な状況で使用する方法を確認する。