Google のストレージ テクノロジーは、世界最大級のアプリケーションでも利用されています。しかし、こうしたシステムを使えば常に自動的にスケールできるというわけではありません。設計者は、データをモデル化する方法を慎重に検討して、アプリケーションがさまざまな次元で成長したときに確実にスケールおよび実行できるようにする必要があります。
Spanner は分散データベースであり、効率よく使用するには、従来のデータベースとは異なる方法でスキーマ設計とアクセス パターンを考える必要があります。分散システムの性質上、設計者はデータと処理の局所性について考える必要があります。
Spanner では、水平方向へのスケールアウト機能によって、SQL クエリとトランザクションがサポートされています。多くの場合、Spanner の利点をフルに活用するには慎重な設計が必要になります。このページでは、アプリケーションを任意のレベルにスケールしてパフォーマンスを最大限に引き出すことができるようにするための重要なアイデアについて説明します。特に、キー定義とインターリーブの 2 つのツールはスケーラビリティに大きな影響を与えます。
テーブルのレイアウト
Spanner のテーブルの行は、PRIMARY
KEY によって辞書順に並べ替えられます。概念的には、キーは PRIMARY KEY 句での宣言順序で列を連結することによって順序付けられます。これにより、局所性に関するすべての標準的な特性が示されます。
- 辞書順にテーブルをスキャンするのが効率的です。
- 十分に近い行は、同じディスク ブロックに格納され、一緒に読み込まれてキャッシュに保存されます。
Spanner は、可用性とスケーラビリティのためにデータを複数のゾーンに複製します。各ゾーンはデータの完全なレプリカを保持します。Spanner インスタンスのノードをプロビジョニングする際に、ノードのコンピューティング容量を指定します。コンピューティング容量とは、これらの各ゾーンのインスタンスに割り振られるコンピューティング リソースの量です。各レプリカはデータの完全なセットですが、レプリカ内のデータはそのゾーン内のコンピューティング リソース間に分割されます。
Spanner の各レプリカ内のデータは、データベース スプリットとブロックという 2 つの物理階層レベルで編成されます。スプリットとは、連続した行の範囲を保持し、Spanner がデータベースをコンピューティング リソースに分散させるときの単位です。時間が経つと、スプリットは小さな部分に分割されたり、マージされたり、インスタンス内の他のノードに移動されたりして並列性が高まり、アプリケーションのスケールが可能になります。スプリットをまたぐオペレーションは、通信が増加するため、スプリットをまたがない同等のオペレーションより高コストになります。これは、スプリットが偶然同じノードによって提供される場合でも当てはまります。
Spanner には、ルートテーブル(最上位テーブルとも呼ばれます)とインターリーブされたテーブルの 2 種類のテーブルがあります。インターリーブされたテーブルは、その親として別のテーブルを指定することによって定義され、インターリーブされたテーブルの行は親の行とともにクラスタ化されます。ルートテーブルに親はなく、ルートテーブルの各行は新しい最上位の行またはルート行を定義します。ルート行とインターリーブされた行は子の行と呼ばれ、ルート行とそのすべての子孫のコレクションは行ツリーと呼ばれます。子の行を挿入するには、親の行が必要です。親の行は、データベースにすでに存在する場合と、同じトランザクションで子の行を挿入する前に挿入される場合があります。
サイズや負荷のために必要と判断された場合、Spanner はスプリットを自動的に分割します。データの局所性を維持するため、Spanner はスプリット境界をルートテーブルにできるだけ近づけて追加し、特定の行ツリーを 1 つのスプリットに保持できるようにします。つまり、行ツリー内のオペレーションは、他のスプリットとの通信を必要としない可能性が高いため、より効率的になる傾向があります。
ただし、子の行にホットスポットがある場合、そのホットスポットの行とその下の子の行すべてを分離するために、Spanner はインターリーブされたテーブルにスプリットの境界を追加しようとします。
ルートにするテーブルの選択は、スケーラブルなアプリケーションを設計するうえで重要な決定です。通常、ルートはユーザー、アカウント、プロジェクトなどであり、子テーブルは当該エンティティに関する他のほとんどのデータを保持します。
推奨事項:
- 局所性を高めるため、同じテーブル内の関連する行には共通のキー接頭部を使用します。
- 意味があるときは常に、関連するデータを別のテーブルにインターリーブします。
局所性のトレードオフ
データがまとめて書き込まれたり読み取られたりすることが多い場合は、主キーを慎重に選択してインターリーブを使用することでデータをクラスタ化すると、レイテンシとスループットの両方の点でメリットがあります。これは、サーバーまたはディスク ブロックとの通信には常に固定コストがかかるためであり、できる限り有効に利用する必要があります。さらに、通信するサーバーが多いほど、一時的にビジー状態のサーバーに遭遇する可能性が高くなり、テイル レイテンシの増加につながります。最後に、複数のスプリットにまたがるトランザクションは、Spanner では自動的かつ透過的に行われますが、2 フェーズ commit の分散特性のため CPU コストとレイテンシがわずかに大きくなります。
反対に、データに関連性があっても、まとめてアクセスされることがあまりない場合は、データを分離する方法を検討してください。これは、頻繁にアクセスされるデータが大きい場合に最も効果的です。たとえば、多くのデータベースでは、大きいバイナリデータはプライマリ行データのバンド外に格納され、その大きいデータへの参照のみがインターリーブされます。
あるレベルの 2 フェーズ commit オペレーションと非ローカルデータ オペレーションは、分散データベースでは避けられないことに注意してください。すべてのオペレーションの局所性を完璧にすることにこだわりすぎないようにしてください。最も重要なルート エンティティと最も一般的なアクセス パターンについて必要な局所性を実現することに焦点を当て、頻度の低い分散オペレーションまたはパフォーマンスの影響を受けにくい分散オペレーションは必要に応じて実行されるようにします。2 フェーズ commit と分散読み取りは、スキーマを簡素化し、プログラマーの労力を軽減するのに役立ちます。最もパフォーマンス重視のユースケースを除き、そのままにすることをおすすめします。
推奨事項:
- 一緒に読み書きされるデータが近くになるように、データを階層構造に整理します。
- あまり頻繁にアクセスされない場合、大きい列はインターリーブされていないテーブルに格納することを検討してください。
インデックスのオプション
セカンダリ インデックスを使用すると、主キー以外の値で行をすばやく見つけることができます。Spanner は、インターリーブされていないインデックスとインターリーブされたインデックスの両方をサポートします。インターリーブされていないインデックスがデフォルトであり、従来の RDBMS でサポートされているものと最も類似しています。インデックス付け対象の列に対する制限はなく、強力ですが、必ずしも最良の選択であるとは限りません。親テーブルと接頭部を共有する列にはインターリーブされたインデックスを定義して、局所性を細かく制御できるようにする必要があります。
Spanner は、テーブルと同じ方法でインデックス データを格納し、インデックス エントリごとに 1 行を使用します。テーブルの設計上の考慮事項の多くは、インデックスにも適用されます。インターリーブされていないインデックスでは、データがルートテーブルに格納されます。ルートテーブルは任意のルート行の間で分割できるため、インターリーブされていないインデックスは、ほとんどどのようなワークロードでも、ホットスポットを無視して、任意のサイズに拡大できます。残念ながらこれは、通常はインデックス エントリがプライマリ データと同じスプリットに含まれないことも意味します。これにより、書き込みプロセスでは余分な作業とレイテンシが発生し、読み取り時には参照するスプリットが増えます。
一方、インターリーブされたインデックスでは、データはインターリーブされたテーブルに格納されます。これらは、単一エンティティのドメイン内を検索する場合に適しています。インターリーブされたインデックスでは、データとインデックスのエントリは強制的に同じ行ツリーに格納され、それらの間の結合がはるかに効率的になります。インターリーブされたインデックスの使用例として、次のようなものがあります。
- 撮影日、最終更新日、タイトル、アルバムなど、さまざまな並べ替え順序で写真にアクセスする場合。
- 特定のタグセットを持つすべての投稿を検索する場合。
- 特定の商品を含む以前の購入注文を検索する場合。
推奨事項:
- データベース内のどこからでも行を検索する必要がある場合は、インターリーブされていないインデックスを使用します。
- 検索範囲が単一のエンティティのときは常に、インターリーブされたインデックスを使用することをおすすめします。
STORING インデックス句
セカンダリ インデックスを使用すると、主キー以外の属性で行を検索できます。要求されたすべてのデータがインデックス自体に含まれる場合、プライマリ レコードを読み取ることなく、それだけで照会できます。これにより、結合が不要なため、重要なリソースを節約できます。
残念ながら、インデックス キーは数が 16 個、合計サイズが 8 KiB に制限されており、格納できるものには限りがあります。これらの制限を補うため、Spanner には STORING 句を使用して任意のインデックスに余分なデータを格納する機能があります。インデックス内の列に対して STORING を使用すると、値が複製されて、インデックスにはコピーが格納されます。STORING を使用したインデックスは、単純な単一テーブルのマテリアライズド ビューと考えることができます(現在、Spanner ではビューはネイティブにサポートされていません)。
STORING のもう一つの便利な応用方法として、NULL_FILTERED インデックスの一部としての使用があります。これにより、テーブルのスパースなサブセットに対して、効率的なスキャンが可能な実質的なマテリアライズド ビューを定義できます。たとえば、メールボックスの is_unread 列にこのようなインデックスを作成すると、すべてのメールボックスの完全にコピーすることなく、1 回のテーブル スキャンで未読メッセージのビューを提供できます。
推奨事項:
STORINGを慎重に使用して、読み取り時間のパフォーマンスと、ストレージ サイズおよび書き込み時間のパフォーマンスをトレードオフします。- 疎なインデックスのストレージ コストを制御するには、
NULL_FILTEREDを使用します。
アンチパターン
アンチパターン: タイムスタンプの順序指定
多くのスキーマ設計者は、ルートテーブルをタイムスタンプの順序に、すべての書き込みで更新されるように定義する傾向があります。残念ながら、これは考えられる最もスケーラビリティの低いものの一つです。このような設計では、容易に緩和することができない巨大なホットスポットがテーブルの最後に作成されるためです。書き込みレートが高くなると、単一スプリットへの RPC が増え、ロックの競合イベントやその他の問題も増加します。多くの場合、この種の問題は小規模な負荷テストでは発生せず、アプリケーションがしばらく運用された後に発生します。それでは遅すぎます。
アプリケーションにタイムスタンプ順のログが絶対に含まれる必要がある場合は、他のルートテーブルの 1 つにインターリーブすることによってログをローカルにできるかどうかを検討します。これには、多くのルートにホットスポットを分散できる利点があります。ただし、個別のルートの書き込みレートが十分低くなるように注意する必要があります。
グローバルな(クロスルートの)タイムスタンプ順テーブルが必要であり、単一ノードで可能なものより高い書き込みレートをそのテーブルでサポートする必要がある場合は、アプリケーション レベルのシャーディングを使用します。テーブルのシャーディングとは、シャードと呼ばれるほぼ等しい N 個の区分にテーブルをパーティショニングすることを指します。これは通常、元の主キーに [0, N) の間の整数値を持つ新しい ShardId 列で接頭辞を追加することによって行います。通常、特定の書き込みに対する ShardId は、ランダムに選択されるか、または基本キーの一部をハッシュすることによって選択されます。ハッシュ化は、特定の型のすべてのレコードが同じシャードに含まれるようにして検索のパフォーマンスを向上させることができるため、しばしば好まれます。いずれにしても、時間の経過とともに書き込みがすべてのシャードに均等に分散されるようにすることが目標です。このアプローチは、読み取りのときにすべてのシャードをスキャンして、書き込みの本来の全体順序を再構築する必要があることを意味する場合があります。
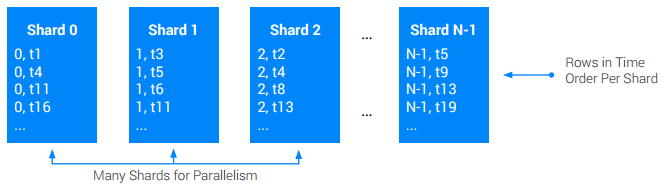
推奨事項:
- 書き込みレートが高いタイムスタンプ順テーブルおよびインデックスを作成することは、絶対に避けてください。
- なんらかの方法で、ホットスポットを分散させたり、別のテーブルにインターリーブしたり、シャーディングしたりします。
アンチパターン: シーケンス
アプリケーション デベロッパーは、データベース シーケンス(または自動インクリメント)を使用して主キーを生成することを好みます。残念なことに、RDBMS 時代からのこの習慣は(サロゲートキーと呼ばれます)、前述のタイムスタンプ順アンチパターンとほとんど同じくらい有害です。なぜなら、データベース シーケンスは、準単調な方法で値を生成し、時間の経過とともに、相互に近いクラスタ化された値を生成する傾向があるからです。通常これは、主キーとして使用されると(特にルート行の場合)、ホットスポットが生成されます。
RDBMS の従来の知恵とは対照的に、できる限り、主キーには現実の属性を使用することをおすすめします。これは特に属性が変更されない場合に当てはまります。
一意の数値の主キーを生成したい場合は、後続の数値の上位ビットを数値空間全体にほぼ均等に分散させることを目指します。1 つの方法は、従来の手段で連続番号を生成し、次にビットを反転して最終値を得ることです。UUID ジェネレータを調べることもできますが、すべての UUID 関数が同じように作成されているわけではなく、一部の関数はタイムスタンプを上位ビットに格納するため、メリットが実質的に失われます。UUID ジェネレータが上位ビットを擬似ランダムに選択することを確認してください。
推奨事項:
- 増分するシーケンス値を主キーとして使用しないでください。代わりに、シーケンス値をビット順逆転するか、慎重に選択した UUID を使用します。
- サロゲートキーではなく実際の値を主キーに使用します。