Spanner is a strongly-consistent, distributed, scalable database built by Google engineers to support some of Google's most critical applications. It takes core ideas from the database and distributed systems communities and expands on them in new ways. Spanner exposes this internal Spanner service as a publicly available service on Google Cloud Platform.
Because Spanner must handle the demanding uptime and scale requirements imposed by Google's critical business applications, we built Spanner from the ground-up to be a widely-distributed database - the service can span multiple machines and multiple datacenters and regions. We leverage this distribution to handle huge datasets and huge workloads, while still maintaining very high availability. We also aimed for Spanner to provide the same strict consistency guarantees provided by other enterprise-grade databases, because we wanted to create a great experience for developers. It is much easier to reason about and write software for a database that supports strong consistency than for a database that only supports row-level consistency, entity-level consistency, or has no consistency guarantees at all.
In this document, we describe in detail how writes and reads work in Spanner and how Spanner ensures strong consistency.
Starting points
There are some datasets that are too large to fit on a single machine. There are also scenarios where the dataset is small, but the workload is too heavy for one machine to handle. This means that we need to find a way of splitting our data into separate pieces that can be stored on multiple machines. Our approach is to partition database tables into contiguous key ranges called splits. A single machine can serve multiple splits, and there is a fast lookup service for determining the machine(s) that serve a given key range. The details of how data is split and what machine(s) it resides on are transparent to Spanner users. The result is a system that can provide low latencies for both reads and writes, even under heavy workloads, at very large scale.
We also want to make sure that data is accessible despite failures. To ensure this, we replicate each split to multiple machines in distinct failure domains. Consistent replication to the different copies of the split is managed by the Paxos algorithm. In Paxos, as long as a majority of the voting replicas for the split are up, one of those replicas can be elected leader to process writes and allow other replicas to serve reads.
Spanner provides both read-only transactions and read-write
transactions. The former are the preferred transaction-type for operations
(including SQL SELECT statements) that do not mutate your data. Read-only
transactions still provide strong consistency and operate, by-default, on the
latest copy of your data. But they are able to run without the need for any form
of locking internally, which makes them faster and more scalable. Read-write
transactions are used for transactions that insert, update, or delete data; this
includes transactions that perform reads followed by a write. They are still
highly scalable, but read-write transactions introduce locking and must be
orchestrated by Paxos leaders. Note that locking is transparent to Spanner
clients.
Many previous distributed database systems have elected not to provide strong
consistency guarantees because of the costly cross-machine communication that is
usually required. Spanner is able to provide strongly consistent snapshots
across the entire database using a Google-developed technology
called TrueTime. Like the Flux Capacitor in a circa-1985 time
machine, TrueTime is what makes Spanner possible. It is an API that allows
any machine in Google datacenters to know the exact global time with a high
degree of accuracy (that is, within a few milliseconds). This allows different
Spanner machines to reason about the ordering of transactional operations (and
have that ordering match what the client has observed) often without any
communication at all. Google had to outfit its datacenters with special hardware
(atomic clocks!) in order to make TrueTime work. The resulting time precision
and accuracy is much higher than can be achieved by other protocols (such as
NTP). In particular, Spanner assigns a timestamp to all reads and writes. A
transaction at timestamp T1 is guaranteed to reflect the results of all writes
that happened before T1. If a machine wants to satisfy a read at T2, it must
ensure that its view of the data is up-to-date through at least T2. Because
of TrueTime, this determination is usually very cheap. The protocols for
ensuring consistency of the data are complicated, but they are discussed more in
the original Spanner paper and in
this paper about Spanner and consistency.
Practical example
Let's work through a few practical examples to see how it all works:
CREATE TABLE ExampleTable (
Id INT64 NOT NULL,
Value STRING(MAX),
) PRIMARY KEY(Id);
In this example, we have a table with a simple integer primary key.
| Split | KeyRange |
|---|---|
| 0 | [-∞,3) |
| 1 | [3,224) |
| 2 | [224,712) |
| 3 | [712,717) |
| 4 | [717,1265) |
| 5 | [1265,1724) |
| 6 | [1724,1997) |
| 7 | [1997,2456) |
| 8 | [2456,∞) |
Given the schema for ExampleTable above, the primary key space is partitioned
into splits. For example: If there is a row in ExampleTable with an Id of
3700, it will live in Split 8. As detailed above, Split 8 itself is replicated
across multiple machines.
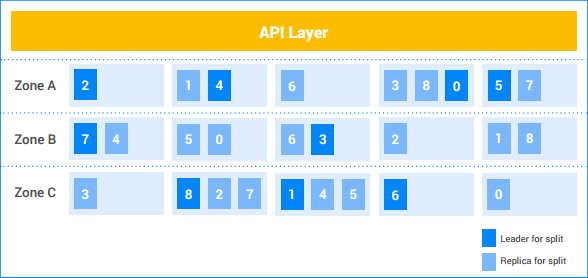
In this example Spanner instance, the customer has five nodes, and the instance is replicated across three zones. The nine splits are numbered 0-8, with Paxos leaders for each split being darkly shaded. The splits also have replicas in each zone (lightly shaded). The distribution of splits among the nodes may be different in each zone, and the Paxos leaders do not all reside in the same zone. This flexibility helps Spanner to be more robust to certain kinds of load profiles and failure modes.
Single-split write
Let's say the client wants to insert a new row (7, "Seven") into
ExampleTable.
- API Layer looks up the split that owns the key range containing
7. It lives in Split 1. - API Layer sends the write request to the Leader of Split 1.
- Leader begins a transaction.
- Leader attempts to get a write lock on the row
Id=7. This is a local operation. If another concurrent read-write transaction is currently reading this row, then the other transaction has a read lock and the current transaction blocks until it can acquire the write lock.- It is possible that transaction A is waiting for a lock held by transaction B, and transaction B is waiting for a lock held by transaction A. Since neither transaction releases any lock until it acquires all locks, this can lead to deadlock. Spanner uses a standard "wound-wait" deadlock prevention algorithm to ensure that transactions make progress. In particular, a "younger" transaction will wait for a lock held by an "older" transaction, but an "older" transaction will "wound" (abort) a younger transaction holding a lock requested by the older transaction. Therefore we never have deadlock cycles of lock waiters.
- Once the lock is acquired, Leader assigns a timestamp to the transaction
based on TrueTime.
- This timestamp is guaranteed to be greater than that of any previously committed transaction which touched the data. This is what ensures that the order of transactions (as perceived by the client) matches the order of changes to the data.
- Leader tells the Split 1 replicas about the transaction and its timestamp. Once a majority of those replicas have stored the transaction mutation in stable storage (in the distributed filesystem), the transaction commits. This ensures that the transaction is recoverable, even if there is a failure in a minority of machines. (The replicas don't yet apply the mutations to their copy of the data.)
The Leader waits until it can be sure that the transaction's timestamp has passed in real time; this typically requires a few milliseconds so that we can wait out any uncertainty in the TrueTime timestamp. This is what ensures strong consistency—once a client has learned the outcome of a transaction, it is guaranteed that all other readers will see the transaction's effects. This "commit wait" typically overlaps with the replica communication in the step above, so its actual latency cost is minimal. More details are discussed in this paper.
The Leader replies to the client to say that the transaction has been committed, optionally reporting the commit timestamp of the transaction.
In parallel to replying to the client, the transaction mutations are applied to the data.
- The leader applies the mutations to its copy of the data and then releases its transaction locks.
- The leader also informs the other Split 1 replicas to apply the mutation to their copies of the data.
- Any read-write or read-only transaction that should see the effects of the mutations waits until the mutations are applied before attempting to read the data. For read-write transactions, this is enforced because the transaction must take a read lock. For read-only transactions, this is enforced by comparing the read's timestamp with that of the latest applied data.
All of this happens in typically a handful of milliseconds. This write is the cheapest kind of write done by Spanner, since a single split is involved.
Multi-split write
If multiple splits are involved, an extra layer of coordination (using the standard two-phase commit algorithm) is necessary.
Let's say the table contains four thousand rows:
| 1 | "one" |
| 2 | "two" |
| ... | ... |
| 4000 | "four thousand" |
And let's say the client wants to read the value for row 1000 and write a
value to rows 2000, 3000, and 4000 within a transaction. This will be
executed within a read-write transaction as follows:
- Client begins a read-write transaction, t.
- Client issues a read request for row 1000 to the API Layer and tags it as part of t.
- API Layer looks up the split that owns the key
1000. It lives in Split 4. API Layer sends a read request to the Leader of Split 4 and tags it as part of t.
Leader of Split 4 attempts to get a read lock on the row
Id=1000. This is a local operation. If another concurrent transaction has a write lock on this row, then the current transaction blocks until it can acquire the lock. However, this read lock does not prevent other transactions from getting read locks.- As in the single split case, deadlock is prevented via "wound-wait".
Leader looks up the value for
Id1000("One Thousand") and returns the read result to the client.
Later...Client issues a Commit request for transaction t. This commit request contains 3 mutations: (
[2000, "Dos Mil"],[3000, "Tres Mil"], and[4000, "Quatro Mil"]).- All of the splits involved in a transaction become participants in
the transaction. In this case, Split 4 (which served the read for key
1000), Split 7 (which will handle the mutation for key2000) and Split 8 (which will handle the mutations for key3000and key4000) are participants.
- All of the splits involved in a transaction become participants in
the transaction. In this case, Split 4 (which served the read for key
One participant becomes the coordinator. In this case perhaps the leader for Split 7 becomes the coordinator. The job of the coordinator is to make sure the transaction either commits or aborts atomically across all participants. That is, it will not commit at one participant and abort at another.
- The work done by participants and coordinators is actually done by the leader machines of those splits.
Participants acquire locks. (This is the first phase of two-phase commit.)
- Split 7 acquires a write lock on key
2000. - Split 8 acquires a write lock on key
3000and key4000. - Split 4 verifies that it still holds a read lock on key
1000(in other words, that the lock was not lost due to a machine crash or the wound-wait algorithm.) - Each participant split records its set of locks by replicating them to (at least) a majority of split replicas. This ensures the locks can remain held even across server failures.
- If all the participants successfully notify the coordinator that their locks are held, then the overall transaction can commit. This ensures there is a point in time in which all the locks needed by the transaction are held, and this point in time becomes the commit point of the transaction, ensuring that we can properly order the effects of this transaction against other transactions that came before or after.
- It is possible that locks cannot be acquired (for example, if we learn there might be a deadlock via the wound-wait algorithm). If any participant says it cannot commit the transaction, the whole transaction aborts.
- Split 7 acquires a write lock on key
If all participants, and the coordinator, successfully acquire locks, Coordinator (Split 7) decides to commit the transaction. It assigns a timestamp to the transaction based on TrueTime.
- This commit decision, as well as the mutations for key
2000, are replicated to the members of Split 7. Once a majority of the Split 7 replicas record the commit decision to stable storage, the transaction is committed.
- This commit decision, as well as the mutations for key
The Coordinator communicates the transaction outcome to all of the Participants. (This is the second phase of two-phase commit.)
- Each participant leader replicates the commit decision to the replicas of the participant split.
If the transaction is committed, the Coordinator and all of the Participants apply the mutations to the data.
- As in the single split case, subsequent readers of data at the Coordinator or Participants must wait until data is applied.
Coordinator leader replies to the client to say that the transaction has been committed, optionally returning the commit timestamp of the transaction
- As in the single split case, the outcome is communicated to the client after a commit wait, to ensure strong consistency.
All of this happens in typically a handful of milliseconds, though typically a few more than in the single split case because of the extra cross-split coordination.
Strong read (multi-split)
Let's say the client wants to read all rows where Id >= 0 and Id < 700 as
part of a read-only transaction.
- API Layer looks up the splits that own any keys in the range
[0, 700). These rows are owned by Split 0, Split 1, and Split 2. - Since this is a strong read across multiple machines, API Layer picks the
read timestamp by using the current TrueTime. This ensures that both reads
return data from the same snapshot of the database.
- Other types of reads, such as stale reads, also pick a timestamp to read at (but the timestamp may be in the past).
- API Layer sends the read request to some replica of Split 0, some replica of Split 1, and some replica of Split 2. It also includes the read-timestamp it has selected in the step above.
For strong reads, the serving replica typically makes an RPC to the leader to ask for the timestamp of the last transaction that it needs to apply and the read can proceed once that transaction is applied. If the replica is the leader or it determines that it's caught up enough to serve the request from its internal state and TrueTime, then it directly serves the read.
The results from the replicas are combined and returned to the client (through the API layer).
Note that reads do not acquire any locks in read-only transactions. And because reads can potentially be served by any up-to-date replica of a given split, the read throughput of the system is potentially very high. If the client is able to tolerate reads that are at least ten seconds stale, read throughput can be even higher. Because the leader typically updates the replicas with the latest safe timestamp every ten seconds, reads at a stale timestamp may avoid an extra RPC to the leader.
Conclusion
Traditionally, designers of distributed database systems have found that strong transactional guarantees are expensive, because of all the cross-machine communication that is required. With Spanner, we have focused on reducing the cost of transactions in order to make them feasible at scale and despite distribution. A key reason this works is TrueTime, which reduces cross-machine communication for many types of coordination. Beyond that, careful engineering and performance tuning has resulted in a system that is highly performant even while providing strong guarantees. Within Google, we have found this has made it significantly easier to develop applications on Spanner compared to other database systems with weaker guarantees. When application developers don't have to worry about race conditions or inconsistencies in their data, they can focus on what they really care about—building and shipping a great application.