このページでは、Spanner のコンピューティング容量と、それを数値化するために使用する 2 つの測定単位(ノードと処理単位)について説明します。
コンピューティング容量
インスタンスを作成するときは、インスタンス構成とインスタンスのコンピューティング容量を選択します。インスタンスのコンピューティング容量には次の特徴があります。
- インスタンス内のデータベースで使用可能なサーバー リソースとストレージ リソースの量(ディスク負荷を含む)を決定します。ディスク負荷は、HDD ストレージに保存されているデータにアクセスするワークロードにのみ適用されます。詳細については、階層型ストレージの概要をご覧ください。
これは、処理ユニット(PU)またはノードで測定されます。1, 000 PU は 1 ノードに相当します。
- ノードまたは 1,000 PU はコンピューティング容量の論理単位であり、単一の物理サーバーを表すものではありません。各ノードのコンピューティング リソースは、複数の基盤となる物理マシン(サーバー)に分散されます。ノードあたりのサーバーの数は、インスタンス構成によって異なります。たとえば、リージョン インスタンスはノードあたり少なくとも 3 台のサーバーを使用しますが、マルチリージョン インスタンスは少なくとも 5 台のサーバーを使用します。詳細については、コンピューティング容量とインスタンス構成をご覧ください。
- インスタンスのコンピューティング容量を定義または変更する場合は、PU を 100 の倍数(100、200、300 など)で指定する必要があります。PU の数が 1,000 に達すると、1,000 PU の倍数(1,000、2,000、3,000 など)またはノード(1、2、3 など)として、より大きな量を指定できます。
Spanner は、データのレプリカをホストする各ゾーンに、指定されたコンピューティング容量を複製して使用可能な状態にします。たとえば、通常は 3 つのゾーンにレプリカがあるリージョン インスタンスに 1,000 個の PU をプロビジョニングすると、3 つのゾーンのそれぞれに、レプリカの処理に使用できる 1,000 個の PU のコンピューティング能力が割り当てられます。Spanner は、PU の合計数をゾーン間で分割または分散しません。コンピューティング容量が 1,000 PU(1 ノード)未満のインスタンスを作成している場合を除き、どちらの測定単位を使用するかは重要ではありません。この場合は、PU を使用してインスタンスのコンピューティング容量を指定する必要があります。
PU が 1,000 未満のインスタンスは、より小さいデータサイズ、クエリ、ワークロード向けに作られています。コンピューティング リソースが制限されているため、一部のワークロードではスケーリングとパフォーマンスの問題が発生する可能性があります。また、これらのインスタンスでは、断続的にレイテンシが増加することもあります。
Spanner の可用性
Spanner は高可用性を実現するように設計されています。各インスタンスのコンピューティング容量は、異なるゾーンの複数のサーバーに分散されるため、Spanner は 1 つのサーバーの障害に対して復元力があります。個々のサーバーの損失は、ノード障害には該当しません。Spanner は、基盤となるリソースを自動的に管理し、インスタンスの継続的な可用性を実現します。
データ ストレージの上限
割り当てと上限で詳しく説明されているように、高可用性とデータベース アクセスのレイテンシ低減のため、Spanner は次のガイドラインを使用して、インスタンスのコンピューティング容量に基づいてストレージの上限を決定します。
- 1 ノード(1,000 PU)未満のインスタンスの場合、Spanner はデータベース内の 100 PU ごとに 1,024.0 GiB のデータを割り当てます。
- 1 ノード以上のインスタンスの場合、Spanner はノードごとに 10 TiB のデータを割り当てます。
たとえば、300 GB のデータベース用のインスタンスを作成する場合、そのコンピューティング容量を 100 PU に設定できます。このコンピューティング容量では、データベースが 1,024.0 GiB を超えるまで、インスタンスは上限未満に保持されます。データベースがこのサイズを超えた場合は、データベースを拡大できるように、さらに 100 PU を追加する必要があります。そうしないと、Spanner がデータベースへの書き込みを拒否する可能性があります。詳細については、データベースのストレージ使用量の推奨事項をご覧ください。
Spanner では、ストレージ割り当ての合計ではなく、インスタンスが実際に使用したストレージに対して課金されます。
パフォーマンス
一定量のコンピューティング容量のピーク読み取り / 書き込みスループット値は、インスタンス構成、スキーマ設計、データセットの特性によって異なります。詳細については、パフォーマンス ダッシュボードの概要をご覧ください。
小規模なデータサイズ、クエリ、ワークロードには、1,000 PU 未満のインスタンスを使用します。大規模なワークロードでは、コンピューティング リソースが制限されるため、スケーリングとパフォーマンスが非線形になり、断続的にレイテンシが増加する可能性があります。
コンピューティング容量とインスタンス構成
リージョン構成、デュアルリージョン構成、マルチリージョン構成で説明されているように、Spanner は 1 つ以上のリージョンのゾーンにインスタンスを分散して、高パフォーマンスと高可用性を実現します。インスタンスのコンピューティング容量で提供されるサーバー リソースも同様に分散されます。
次の図は、このサーバー リソースの分布を示しています。
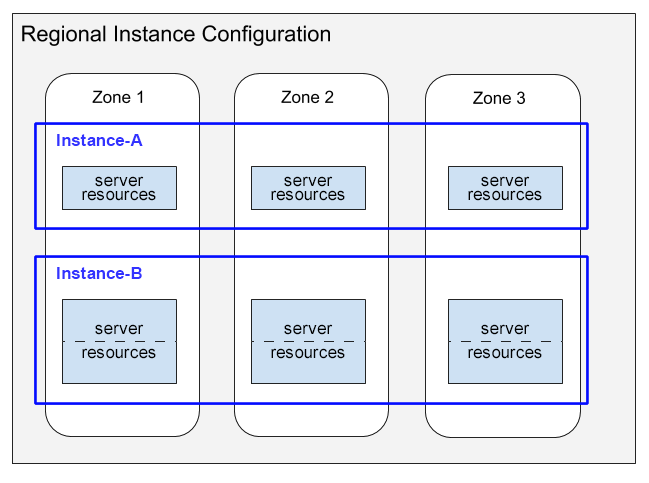
この図は、リージョン構成を備えた 2 つのインスタンスを示しています。
- Instance-A は、1,000 PU(1 ノード)のインスタンスで、3 つのゾーンのそれぞれでサーバー リソースを消費するようにコンピューティング容量が分散されています。
- Instance-B は、2,000 PU(2 ノード)のインスタンスで、3 つのゾーンのそれぞれでサーバー リソースを消費するようにコンピューティング容量が分散されています。
この図で次の点に注意してください。
リージョン構成の各ゾーンで、サーバー リソースがインスタンスごとに割り当てられます。各ゾーンのサーバー リソースは、同じゾーン内のデータレプリカを使用します。インスタンス構成のデータレプリカについては、リージョン、デュアルリージョン、マルチリージョン構成をご覧ください。Spanner でこれらのデータレプリカを同期させる方法については、レプリケーションをご覧ください。
インスタンス A のサーバー リソースは 1 つのボックスで、インスタンス B のリソースは 2 つの部分に分割されたボックスでそれぞれ表されています。この違いは、Spanner がサイズの異なるインスタンスに対して異なるサーバー リソースを割り当てることを意味しています。
- 1,000 PU(1 ノード)以下のインスタンスの場合、Spanner はゾーンごとに 1 つのサーバータスクでサーバー リソースを割り当てます。
- 1,000 PU(1 ノード)を超えるインスタンスの場合、Spanner はゾーンごとに複数のサーバータスクにサーバー リソースを割り当て、1, 000 PU ごとに 1 つのタスクを割り当てます。ゾーンごとに複数のサーバータスクを使用すると、パフォーマンスが向上します。Spanner では、データベース スクリットを作成することで、さらにパフォーマンスを向上させることができます。
コンピューティング容量を変更する
インスタンスを作成した後で、そのコンピューティング容量を増やすことができます。ほとんどの場合、リクエストは数分で完了します。まれに、スケールアップが完了するまでに最大で 1 時間かかることがあります。
次のシナリオを除き、Spanner インスタンスのコンピューティング容量を削減できます。
ノード(1,000 処理ユニット)あたり 10 TiB を超えるデータを保存することはできません。
インスタンスのデータに多数の分割があります。このシナリオでは、コンピューティング容量を削減した後に Spanner がスプリットを管理できない可能性があります。Cloud Spanner でインスタンスのすべてのスプリットを管理するのに必要な最小容量が見つかるまで、コンピューティング容量を徐々に減らすことができます。
Spanner は、使用パターンに合わせて多数のスプリットを作成できます。使用パターンが変化すると、1 ~ 2 週間後に Spanner が一部のスプリットをマージし、インスタンスのコンピューティング容量を削減してみることができます。
コンピューティング容量を削除するときは、Cloud Monitoring で CPU 使用率とリクエスト レイテンシをモニタリングし、CPU 使用率がリージョンのインスタンスで 65% を、マルチリージョンのインスタンスの各リージョンで 45% を下回るようにしてください。コンピューティング容量の削除中に、リクエストのレイテンシが一時的に増加する場合があります。
Spanner に一時停止モードはありません。Spanner のコンピューティング容量は専用のリソースであり、ワークロードが実行されていないときでも、Spanner はデータの最適化と保護のためにバックグランド処理を頻繁に実行しています。
コンピューティング容量を変更するには、Google Cloud コンソール、Google Cloud CLI、または Spanner クライアント ライブラリを使用します。詳細については、コンピューティング容量を変更するをご覧ください。
コンピューティング容量とレプリカ
インスタンス内のサーバー リソースとストレージ リソースをスケールアップする必要がある場合は、インスタンスのコンピューティング容量を増やします。コンピューティング容量を増やしても、レプリカの数は増加しません(レプリカ数は特定のインスタンス構成に対して固定です)が、インスタンス内でレプリカが使用できるリソースは増加傾向にあります。コンピューティング容量を増やすと、各レプリカで使用可能な CPU と RAM が増えるため、レプリカのスループットが向上します(つまり、1 秒あたりの読み取りと書き込み数が増加します)。
次のステップ
- インスタンスの作成方法と管理方法を学習する。