Dataproc-Cluster basieren auf Compute Engine-Instanzen. Maschinentypen definieren die virtualisierten Hardwareressourcen, die für eine Instanz verfügbar sind. Compute Engine bietet sowohl vordefinierte Maschinentypen als auch benutzerdefinierte Maschinentypen. Dataproc-Cluster können sowohl für Master- als auch für Worker-Knoten vordefinierte und benutzerdefinierte Typen verwenden.
Dataproc unterstützt die folgenden vordefinierten Compute Engine-Maschinentypen in Clustern:
- Allgemeine Maschinentypen, einschließlich N1-, N2-, N2D- und E2-Maschinentypen.
Dataproc unterstützt auch benutzerdefinierte Maschinentypen N1, N2, N2D und E2.
Computing-optimierte Maschinentypen, die C2-Maschinentypen umfassen.
Speicheroptimierte Maschinentypen, zu denen auch M1- und M2-Maschinentypen gehören.
Benutzerdefinierte Maschinentypen
Benutzerdefinierte Maschinentypen eignen sich insbesondere für folgende Arbeitslasten:
- Arbeitslasten, die für die vordefinierten Maschinentypen ungeeignet sind.
- Arbeitslasten, die mehr Verarbeitungsleistung oder mehr Speicherplatz erfordern, jedoch nicht alle Upgrades benötigen, die vom nächstgrößeren Maschinentyp bereitgestellt werden.
Wenn Sie beispielsweise eine Arbeitslast haben, die mehr Rechenleistung benötigt, als von einer n1-standard-4-Instanz bereitgestellt wird, aber die nächsthöhere Instanz mit n1-standard-8 zu viel Kapazität bietet. Mit benutzerdefinierten Maschinentypen können Sie Dataproc-Cluster mit Master- und/oder Worker-Knoten im mittleren Bereich mit sechs virtuellen CPUs und 25 GB Arbeitsspeicher erstellen.
Benutzerdefinierten Maschinentyp angeben
Benutzerdefinierte Maschinentypen verwenden eine spezielle machine type-Spezifikation und unterliegen Einschränkungen. Die Spezifikation des benutzerdefinierten Maschinentyps für eine benutzerdefinierte VM mit 6 virtuellen CPUs und 22,5 GB Arbeitsspeicher ist beispielsweise custom-6-23040.
Die Zahlen in der Maschinentypspezifikation entsprechen der Anzahl der virtuellen CPUs (vCPUs) auf der Maschine (6) und der Speichermenge (23040). Die Speichermenge wird berechnet, indem die Speichermenge in Gigabyte mit 1024 multipliziert wird (siehe Arbeitsspeicher in GB oder MB ausdrücken). In diesem Beispiel wird 22, 5 (GB) mit 1.024 multipliziert: 22.5 * 1024 = 23040.
Sie verwenden die obige Syntax, um den benutzerdefinierten Maschinentyp mit Ihren Clustern anzugeben. Beim Erstellen eines Clusters können Sie den Maschinentyp entweder für Master- oder Worker-Knoten oder für beide festlegen. Wenn Sie beide Knoten konfigurieren, kann der Master-Knoten einen benutzerdefinierten Maschinentyp verwenden, der sich vom benutzerdefinierten Maschinentyp des Worker-Knotens unterscheidet. Der Maschinentyp der sekundären Worker verwendet die Einstellungen für primäre Worker und kann nicht separat festgelegt werden (siehe Sekundäre Worker – VMs auf Abruf und nicht auf Abruf verfügbare VMs).
Preise
Die Preise benutzerdefinierter Maschinentypen basieren auf den Ressourcen, die auf einer benutzerdefinierten Maschine verwendet werden. Dataproc-Preise werden den Kosten der Rechenressourcen hinzugerechnet und basieren auf der Gesamtzahl der virtuellen CPUs (vCPUs), die in einem Cluster verwendet werden.
Einen Dataproc-Cluster mit einem angegebenen Maschinentyp erstellen
gcloud-Befehl
Führen Sie den Befehl gcloud Dataproc-Cluster erstellen mit den folgenden Flags aus, um einen Dataproc-Cluster mit Master- und/oder Worker-Maschinentyp zu erstellen:- Mit dem Flag
--master-machine-type machine-typekönnen Sie den vordefinierten oder benutzerdefinierten Maschinentyp festlegen, der von der Master-VM-Instanz in Ihrem Cluster verwendet wird (oder Masterinstanzen, wenn Sie einen Hochverfügbarkeitscluster erstellen). - Mit dem Flag
--worker-machine-type custom-machine-typekönnen Sie den vordefinierten oder benutzerdefinierten Maschinentyp festlegen, der von den Worker-VM-Instanzen in Ihrem Cluster verwendet wird
Beispiel:
gcloud dataproc clusters create test-cluster / --master-machine-type custom-6-23040 / --worker-machine-type custom-6-23040 / other args
... properties: distcp:mapreduce.map.java.opts: -Xmx1638m distcp:mapreduce.map.memory.mb: '2048' distcp:mapreduce.reduce.java.opts: -Xmx4915m distcp:mapreduce.reduce.memory.mb: '6144' mapred:mapreduce.map.cpu.vcores: '1' mapred:mapreduce.map.java.opts: -Xmx1638m ...
REST API
Um einen Cluster mit benutzerdefinierten Maschinentypen zu erstellen, legen SiemachineTypeUri in der masterConfig- und/oder workerConfig- InstanceGroupConfig in der API-Anfrage cluster.create fest.
Beispiel:
POST /v1/projects/my-project-id/regions/is-central1/clusters/
{
"projectId": "my-project-id",
"clusterName": "test-cluster",
"config": {
"configBucket": "",
"gceClusterConfig": {
"subnetworkUri": "default",
"zoneUri": "us-central1-a"
},
"masterConfig": {
"numInstances": 1,
"machineTypeUri": "n1-highmem-4",
"diskConfig": {
"bootDiskSizeGb": 500,
"numLocalSsds": 0
}
},
"workerConfig": {
"numInstances": 2,
"machineTypeUri": "n1-highmem-4",
"diskConfig": {
"bootDiskSizeGb": 500,
"numLocalSsds": 0
}
}
}
}
Console
Wählen Sie in der Google Cloud Console auf der Seite „Knoten konfigurieren“ der Dataproc-Seite Cluster erstellen die Maschinenfamilie, die Serie und den Typ für die Master- und Worker-Knoten des Clusters aus.
Erweiterter CPU-Speicher
Dataproc unterstützt benutzerdefinierte Maschinentypen mit erweitertem Speicher über das Limit von 6,5 GB pro vCPU hinaus (siehe Preise für erweiterten Speicher).
Erweiterten Speicher verwenden
gcloud-Befehl
Wenn Sie einen Cluster aus der gcloud-Befehlszeile mit benutzerdefinierten CPUs mit erweitertem Speicher erstellen möchten, fügen Sie einen -ext-Suffix für ‑‑master-machine-type und/oder ‑‑worker-machine-type-Flags hinzu.
Beispiel
Im folgenden Beispiel für die gcloud-Befehlszeile wird in jedem Knoten ein Dataproc-Cluster mit 1 CPU und 50 GB Arbeitsspeicher (50 * 1024 = 51200) erstellt:
gcloud dataproc clusters create test-cluster / --master-machine-type custom-1-51200-ext / --worker-machine-type custom-1-51200-ext / other args
REST API
Im folgenden Beispiel für ein JSON-Snippet aus einer clusters.create-Anfrage der Dataproc REST API werden 1 CPU und 50 GB Arbeitsspeicher (50 * 1024 = 51200) in jedem Knoten angegeben:
...
"masterConfig": {
"numInstances": 1,
"machineTypeUri": "custom-1-51200-ext",
...
},
"workerConfig": {
"numInstances": 2,
"machineTypeUri": "custom-1-51200-ext",
...
...
Console
Klicken Sie in der Google Cloud Console auf der Dataproc-Seite Cluster erstellen im Abschnitt „Masterknoten“ bzw. „Worker-Knoten“ auf Arbeitsspeicher erweitern.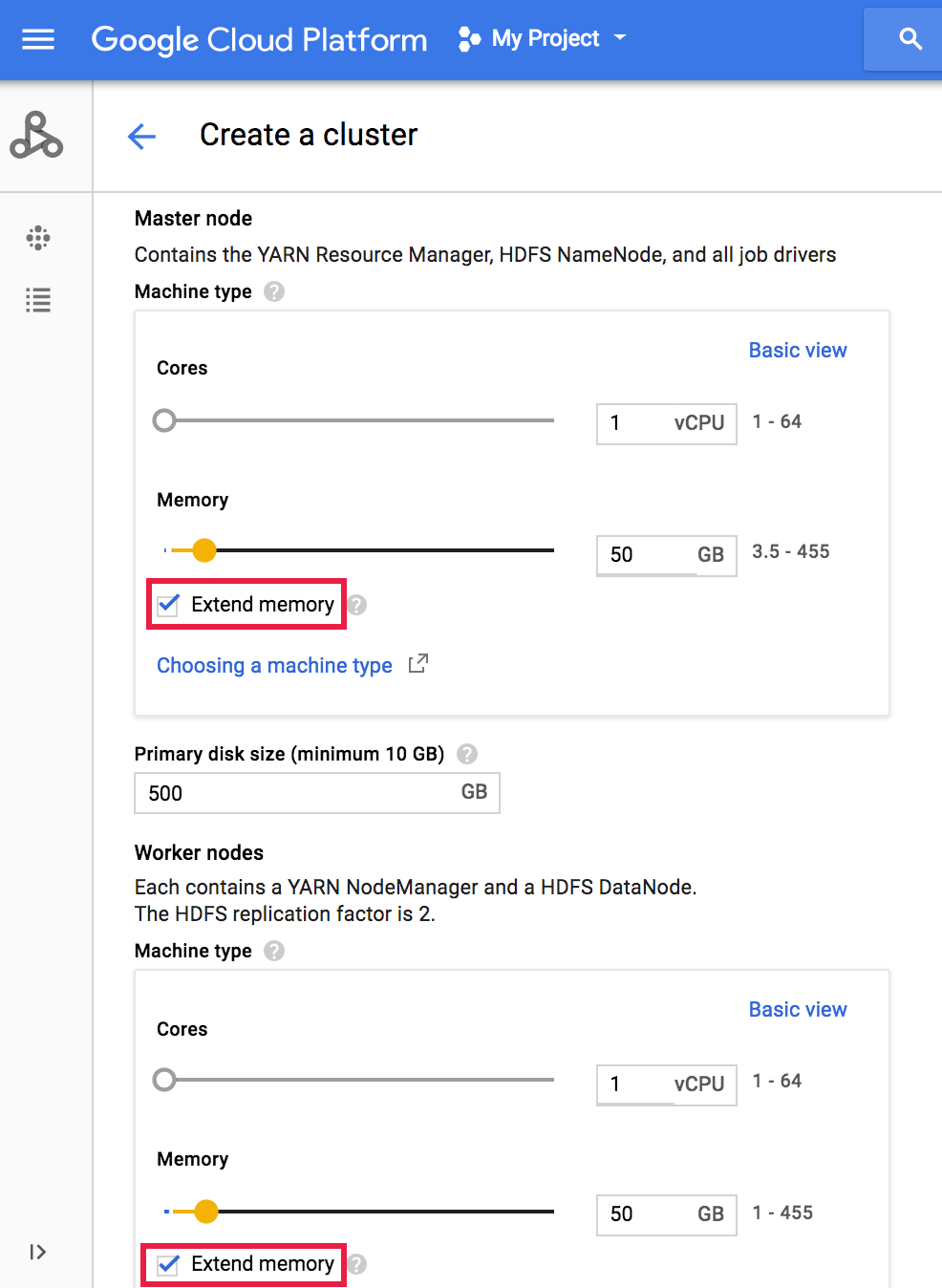
Weitere Informationen
Siehe VM-Instanz mit einem benutzerdefinierten Maschinentyp erstellen