このガイドでは、高可用性(HA)SAP HANA システムを Google Cloudにデプロイする前に知っておく必要があるオプション、推奨事項、一般的なコンセプトについて説明します。
このガイドは、SAP HANA の高可用性システムの実装に必要な一般的なコンセプトと手順について理解していることを前提としています。このガイドでは主に、このようなシステムを Google Cloudに実装するために必要な知識について説明します。
SAP HANA HA システムの実装に必要な一般的なコンセプトと手順の詳細については、以下のドキュメントをご覧ください。
- SAP のベスト プラクティス ドキュメント: Building High Availability for SAP NetWeaver and SAP HANA on Linux
- SAP HANA のドキュメント
このプランニング ガイドでは、専ら SAP HANA の高可用性に焦点を当てて説明します。アプリケーション システムの高可用性については説明しません。SAP NetWeaver の高可用性については、 Google Cloud の SAP NetWeaver 向け高可用性のプランニング ガイドをご覧ください。
このガイドは、SAP が提供するドキュメントに代わるものではありません。
Google Cloud上の SAP HANA の高可用性オプション
インフラストラクチャ レベルとソフトウェア レベルの両方で障害に対応できるようにするために、SAP HANA の高可用性構成において、 Google Cloud と SAP の機能を組み合わせて使用できます。次のテーブルに、高可用性を実現するために使用される SAP の機能と Google Cloud 機能を示します。
| 機能 | 説明 |
|---|---|
| Compute Engine ライブ マイグレーション |
Compute Engine は、基盤となるインフラストラクチャの状態をモニタリングし、インスタンスをインフラストラクチャ メンテナンス イベントから自動的に移行します。ユーザーの介入は必要ありません。 Compute Engine は、可能であれば移行中もインスタンスの実行を続行します。大規模な障害の場合、インスタンスが停止してから使用可能になるまでに少し時間がかかることがあります。 マルチホスト システムでは、デプロイ ガイドで使用される `/hana/shared` ボリュームなどの共有ボリュームは、マスターホストをホストする VM に接続された永続ディスクであり、ワーカーホストに NFS マウントされます。マスターホストのライブ マイグレーションが発生すると、NFS ボリュームは最大で数秒間アクセスできなくなります。マスターホストが再起動すると、NFS ボリュームはすべてのホストで再び機能し、通常の動作が自動的に再開されます。 復旧インスタンスは、インスタンス ID、プライベート IP アドレス、インスタンスのすべてのメタデータとストレージを含めて、元のインスタンスと同じになります。デフォルトでは、標準インスタンスがライブ マイグレーションに設定されています。この設定は変更しないことをおすすめします。 詳細は、ライブ マイグレーションをご覧ください。 |
| Compute Engine の自動再起動 |
メンテナンス イベントの発生時にインスタンスが終了するように設定されている場合、または基盤となるハードウェアの問題でインスタンスがクラッシュした場合は、インスタンスを自動的に再起動するように Compute Engine を設定できます。 インスタンスは、デフォルトで自動的に再起動するように設定されています。この設定は変更しないことをおすすめします。 |
| SAP HANA サービスの自動再起動 |
SAP HANA Service Auto-Restart は、SAP が提供する障害復旧ソリューションです。 SAP HANA には、さまざまなアクティビティのために常時実行される多くの構成済みサービスがあります。ソフトウェアの障害や人為的エラーのためにこれらのサービスのいずれかが無効になった場合、SAP HANA サービスの自動再起動ウォッチドッグ機能によって自動的に再起動します。サービスが再起動されると、必要なすべてのデータがメモリに戻り、処理が再開されます。 |
| SAP HANA バックアップ |
SAP HANA バックアップは、データベースから特定の時点へのデータベースの再構築に使用できるデータのコピーを作成します。 Google Cloudでの SAP HANA バックアップの使用の詳細については、SAP HANA 運用ガイドをご覧ください。 |
| SAP HANA ストレージ レプリケーション |
SAP HANA ストレージ レプリケーションは、特定のハードウェア パートナーを通じてストレージ レベルの障害復旧サポートを提供します。SAP HANA ストレージ レプリケーションは Google Cloudではサポートされていません。その代わりに、Compute Engine の永続ディスク スナップショットの使用をご検討ください。 永続ディスク スナップショットを使用して SAP HANA システムを Google Cloudでバックアップする方法の詳細については、SAP HANA 運用ガイドをご覧ください。 |
| SAP HANA ホスト自動フェイルオーバー |
SAP HANA ホスト自動フェイルオーバーは、ローカルの障害復旧ソリューションであり、スケールアウト システムで 1 つ以上のスタンバイ SAP HANA ホストを必要とします。メインホストの 1 つに障害が発生すると、ホストの自動フェイルオーバーによりスタンバイ ホストが自動的にオンラインになり、障害が発生したホストがスタンバイ ホストとして再起動されます。 詳しくは以下をご覧ください。 |
| SAP HANA システム レプリケーション |
SAP HANA システム レプリケーションを使用すると、高可用シナリオまたは障害復旧シナリオでプライマリ システムを引き継ぐように、1 つ以上のシステムを構成できます。レプリケーションは、パフォーマンスとフェイルオーバー時間の面のニーズに応じて調整できます。 |
| SAP HANA 高速再起動オプション(推奨) |
SAP HANA 高速再起動により、SAP HANA の終了後もオペレーティング システムが稼働し続けている場合の再起動時間が短縮されます。SAP HANA では、SAP HANA の永続メモリ機能を利用して、 SAP HANA 高速再起動オプションの使用方法については、次の高可用性デプロイガイドをご覧ください。 |
| SAP HANA HA/DR プロバイダ フック(推奨) |
SAP HANA HA/DR プロバイダ フックを使用すると、SAP HANA は特定のイベントに関する通知を Pacemaker クラスタに送信します。これにより、障害検出が改善されます。SAP HANA HA/DR プロバイダ フックには、 SAP HANA HA/DR プロバイダ フックの使用方法については、次の高可用性デプロイガイドをご覧ください。 |
Google Cloudでの SAP HANA 用の OS ネイティブ HA クラスタ
Linux オペレーティング システムのクラスタリングは、アプリケーションとゲストがアプリケーションの状態を認識できるようにし、障害発生時の復旧処理を自動化します。
一般的には、クラウド以外の環境で通用する高可用クラスタの原則は Google Cloudにも当てはまりますが、フェンシングや仮想 IP など、実装方法が異なるものもあります。
Google Cloud上の SAP HANA の HA クラスタには、Red Hat または SUSE の高可用性 Linux ディストリビューションを使用できます。
Google Cloud で SAP HANA に HA クラスタをデプロイして手動で構成する手順については、以下をご覧ください。
- RHEL での HA スケールアップ クラスタの手動構成
- SLES での HA クラスタ手動構成:
Google Cloudが提供する自動デプロイ オプションについては、SAP HANA 高可用性構成の自動デプロイ オプションをご覧ください。
クラスタ リソース エージェント
Red Hat と SUSE はどちらも、Pacemaker クラスタ ソフトウェアの高可用性実装を備えた Google Cloud 用のリソース エージェントを提供しています。 Google Cloud のリソース エージェントは、フェンシング、ルートまたはエイリアス IP で実装された VIP、ストレージ アクションを管理します。
ベース OS のリソース エージェントにまだ含まれていない更新を配信するために、Google Cloud では SAP の HA クラスタ用のコンパニオン リソース エージェントを定期的に提供しています。これらのコンパニオン リソース エージェントが必要な場合は、Google Cloud デプロイ手順にそれらをダウンロードするためのステップが記載されています。
フェンシング エージェント
フェンシングは、 Google Cloud Compute Engine OS クラスタリングのコンテキストでは STONITH の形式をとり、2 ノードクラスタ内の各メンバーに他方のノードを再起動する機能を提供します。
Google Cloud では、Linux オペレーティング システム上の SAP で使用できるフェンシング エージェントが 2 つあります。一つは、認定済みの Red Hat / SUSE Linux ディストリビューションに含まれている fence_gce エージェントであり、もう一つは fence_gce エージェントが含まれていない Linux ディストリビューションでダウンロードして使用することもできる以前の gcpstonith エージェントです。使用可能な場合は、fence_gce エージェントを使用することをおすすめします。
フェンシング エージェントに必要な IAM 権限
フェンシング エージェントは、Compute Engine API にリセット呼び出しを行って VM を再起動します。フェンシング エージェントは、API へのアクセスの認証と認可に VM のサービス アカウントを使用します。フェンシング エージェントが使用するサービス アカウントには、次の権限を含むロールを付与する必要があります。
- compute.instances.get
- compute.instances.list
- compute.instances.reset
- compute.instances.start
- compute.instances.stop
- compute.zoneOperations.get
- logging.logEntries.create
- compute.zoneOperations.list
事前定義の Compute インスタンス管理者ロールには、必要な権限がすべて含まれています。
エージェントの再起動権限のスコープをターゲット ノードに制限するには、リソースベースのアクセスを構成します。詳細については、リソースベースのアクセスの構成をご覧ください。
仮想 IP アドレス
Google Cloud 上の SAP の高可用性クラスタは、フェイルオーバーが発生すると、仮想 IP アドレス(VIP)(フローティング IP アドレスとも呼ばれる)を使用してネットワーク トラフィックを別のホストにリダイレクトします。
クラウド以外のデプロイでは通常、Gratuitous Address Resolution Protocol(ARP)リクエストを使用して、VIP が新しい MAC アドレスに移動して再割り振りされたことを通知します。
Google Cloudでは、Gratuitous ARP リクエストを使用する代わりに、いくつかある方法のいずれかを使用して HA クラスタ内で VIP を移動して再割り振ります。内部 TCP / UDP ロードバランサを使用する方法をおすすめしますが、必要に応じて、ルートベースの VIP 実装、またはエイリアス IP ベースの VIP 実装も使用できます。
Google Cloudでの VIP の実装の詳細については、 Google Cloudでの仮想 IP の実装をご覧ください。
ストレージとレプリケーション
SAP HANA の HA クラスタ構成では、同期 SAP HANA システム レプリケーションを使用して、プライマリとセカンダリの SAP HANA データベースの同期を維持します。標準の OS が提供する SAP HANA 用のリソース エージェントは、フェイルオーバー時のシステム レプリケーションを管理します。レプリケーションの開始と停止を行ったり、レプリケーション プロセスにおいてアクティブおよびスタンバイとして機能するインスタンスの切り替えを行ったりします。
共有ファイル ストレージが必要な場合は、必要な機能を NFS ベースまたは SMB ベースのファイラーが提供します。
高可用性の共有ストレージ ソリューションでは、Filestore、Google Cloud NetApp Volumes のプレミアムまたはエクストリーム サービスレベル、またはサードパーティのファイル共有ソリューションを使用できます。Filestore の Regional サービスティア(旧称 Enterprise)はマルチゾーン デプロイに使用でき、Filestore の Basic ティアはシングルゾーン デプロイに使用できます。
Compute Engine のリージョン永続ディスクを使用すると、ゾーン間で同期的にブロック ストレージを複製できます。リージョン永続ディスクは、SAP HA システムのデータベース ストレージとしてはサポートされていませんが、NFS ファイル サーバーで使用できます。
Google Cloudのストレージ オプションの詳細については、以下をご覧ください。
Google Cloudでの HA クラスタの構成設定
Google Cloud は、特定のクラスタ構成パラメータのデフォルト値を、 Google Cloud 環境の SAP システムに適した値に変更することをおすすめしています。 Google Cloudが提供する自動化スクリプトを使用する場合は、推奨値が自動的に設定されます。
HA クラスタの Corosync 設定を調整する際は、最初に推奨値を検討してください。障害検出とフェイルオーバー トリガーの感度が、 Google Cloud 環境内のシステムとワークロードに適しているかどうかを確認する必要があります。
Corosync 構成パラメータ値
SAP HANA の HA クラスタ構成ガイドで、 Google Cloudでは corosync.conf 構成ファイルの totem セクションでいくつかのパラメータの値を推奨しています。これらの値は、Corosync または Linux ディストリビューターによって設定されたデフォルト値とは異なります。
totem パラメータと、値の変更による影響を示します。パラメータのデフォルト値は Linux ディストリビューションごとに異なります。詳細は、Linux ディストリビューションのドキュメントをご覧ください。| パラメータ | 推奨値 | 値の変更による影響 |
|---|---|---|
secauth |
off |
すべての totem メッセージの認証と暗号化を無効にします。 |
join |
60(ミリ秒) | メンバーシップ プロトコルの join メッセージに対するノードの待機時間を増やします。 |
max_messages |
20 | トークンの受信後にノードから送信される可能性があるメッセージの最大数を増やします。 |
token |
20000(ミリ秒) |
ノードがトークンの損失を宣言してノード障害を想定したアクションを開始する前に、
また、 |
consensus |
なし | 新しいメンバーシップ構成を開始する前に合意を得るまでの待機時間をミリ秒単位で指定します。
このパラメータは省略することをおすすめします。 consensus の値を明示的に指定する場合は、値が 24000 または 1.2*token のいずれか大きい方を指定してください。
|
token_retransmits_before_loss_const |
10 | 受信ノードが失敗したと判断してアクションを実行する前に、ノードが再試行するトークンの再送回数を増やします。 |
transport |
|
corosync で使用されるトランスポート メカニズムを指定します。 |
corosync.conf ファイルの構成の詳細については、Linux ディストリビューションの構成ガイドをご覧ください。
- RHEL: corosync.conf のデフォルト設定を編集する
- SLES: Corosync 構成ファイルを作成する
クラスタ リソースのタイムアウトと間隔の設定
クラスタ リソースを定義するときは、さまざまなリソース オペレーション(op)に対して、interval と timeout の値を秒単位で設定します。次に例を示します。
primitive rsc_SAPHanaTopology_HA1_HDB00 ocf:suse:SAPHanaTopology \ operations \$id="rsc_sap2_HA1_HDB00-operations" \ op monitor interval="10" timeout="600" \ op start interval="0" timeout="600" \ op stop interval="0" timeout="300" \ params SID="HA1" InstanceNumber="00" clone cln_SAPHanaTopology_HA1_HDB00 rsc_SAPHanaTopology_HA1_HDB00 \ meta is-managed="true" clone-node-max="1" target-role="Started" interleave="true"
次の表に示すように、timeout の値は各リソース オペレーションに異なる影響を与えます。
| リソース オペレーション | タイムアウト処理 |
|---|---|
monitor |
タイムアウトを超えると、モニタリング ステータスは通常「失敗」と表示され、関連リソースは「失敗状態」とみなされます。クラスタは復旧オプションを試します(フェイルオーバーが含まれる場合もあります)。クラスタは失敗したモニタリング オペレーションを再試行しません。 |
start |
タイムアウトに到達する前にリソースの起動に失敗した場合、クラスタはリソースの再起動を試みます。この動作は、リソースに関連付けられた on-fail アクションによって決まります。 |
stop |
タイムアウトに到達する前にリソースが停止オペレーションに応答しない場合、フェンシング イベントをトリガーします。 |
他のクラスタ構成設定とともに、クラスタ リソースの interval と timeout の設定は、クラスタ ソフトウェアが障害を検出し、フェイルオーバーをトリガーする速さに影響を与えます。
SAP HANA のクラスタ構成ガイドで Google Cloud が推奨する timeout と interval の値は、Compute Engine ライブ マイグレーション メンテナンス イベントを構成します。
使用する timeout と interval の値に関係なく、クラスタのテスト時には値を評価する必要があります。ライブ マイグレーションのテストでは、使用しているマシンタイプやシステム使用率などの要素によってライブ マイグレーション イベントの長さが若干異なる可能性があるため、特に必要です。
フェンシング リソースの設定
SAP HANA の HA クラスタ構成ガイドで、 Google Cloudでは HA クラスタのフェンシング リソースを構成する際にいくつかのパラメータを推奨しています。推奨される値は、Corosync または Linux ディストリビューターが設定するデフォルト値とは異なります。
次のテーブルに、 Google Cloudが推奨するフェンシング パラメータ、推奨値、パラメータの詳細を示します。パラメータのデフォルト値は Linux ディストリビューションごとに異なります。詳細は、Linux ディストリビューションのドキュメントをご覧ください。
| パラメータ | 推奨値 | 詳細 |
|---|---|---|
pcmk_reboot_timeout |
300(秒) | 再起動アクションのタイムアウト値を指定します。
|
pcmk_monitor_retries |
4 | タイムアウト期間内に monitor コマンドを再試行する最大回数を指定します。 |
pcmk_delay_max |
30(秒) | クラスタノードでのフェンシングの競合を防ぐため、フェンシング アクションの遅延を指定します。ランダムな遅延を 1 つのインスタンスのみに割り当ててフェンシングの競合を回避する場合は、2 ノード HANA HA クラスタ(スケールアップ)のいずれかのフェンシング リソースでのみ、このパラメータを有効にする必要があります。 スケールアウト HANA HA クラスタの場合は、サイトに含まれるすべてのノード(プライマリまたはセカンダリ)でこのパラメータを有効にする必要があります。 |
Google Cloudでの HA クラスタのテスト
クラスタを構成して、クラスタと SAP HANA システムをテスト環境にデプロイしたら、クラスタをテストして、HA システムが正しく構成され、想定どおりに機能することを確認する必要があります。
フェイルオーバーが期待どおりに機能していることを確認するため、さまざまな障害シナリオで次の操作をシミュレートします。
- VM をシャットダウンする
- カーネル パニックを発生させる
- アプリケーションをシャットダウンする
- インスタンス間のネットワークを中断する
また、プライマリ ホストで Compute Engine のライブ マイグレーション イベントをシミュレートし、フェイルオーバーがトリガーされないことを確認します。メンテナンス イベントをシミュレートするには、Google Cloud CLI コマンド gcloud compute instances
simulate-maintenance-event を使用します。
ロギングとモニタリング
リソース エージェントには、分析のためにログを Google Cloud Observability に伝播するロギング機能を含めることができます。各リソース エージェントには、ロギング オプションを識別する構成情報が含まれます。bash 実装の場合、ロギング オプションは gcloud logging です。
Cloud Logging エージェントをインストールして、オペレーティング システムのプロセスからログ出力を取得し、リソースの使用状況とシステム イベントを関連付けることもできます。Logging エージェントは、デフォルトのシステムログを取得します。これには Pacemaker やクラスタリング サービスからのログデータも含まれます。詳細については、Logging エージェントについてをご覧ください。
Cloud Monitoring を使用してサービス エンドポイントの可用性をモニタリングするサービス チェックを構成する方法については、稼働時間チェックの管理をご覧ください。
サービス アカウントと HA クラスタ
クラスタ ソフトウェアが Google Cloud環境で実行できるアクションは、各ホスト VM のサービス アカウントに付与された権限によって保護されます。セキュリティの高い環境では、最小権限の原則に従って、ホスト VM のサービス アカウントの権限を制限します。
サービス アカウントの権限を制限する際には、システムが Cloud Storage などの Google Cloud サービスとやり取りする可能性があるため、ホスト VM のサービス アカウントにそれらのサービスとやり取りするための権限を含める必要があるので注意してください。
最も制限の厳しい権限を実現するには、最小限必要な権限のみを付与したカスタムロールを作成します。カスタムロールについては、カスタムロールの作成と管理をご覧ください。権限をさらに制限するには、HA クラスタ内の VM インスタンスなど、リソースの特定のインスタンスのみに権限を制限します。これを行うには、リソースの IAM ポリシーのロール バインディングで条件を追加します。
システムに必要な最小権限は、システムがアクセスするGoogle Cloud リソースとシステムが実行するアクションによって異なります。したがって、HA クラスタ内のホスト VM にとって必要な最小権限を決定するには、ホスト VM 上のシステムがアクセスするリソースと、システムがそれらのリソースに対して実行するアクションを正確に調べる必要があります。
出発点として、次のリストに HA クラスタ リソースと、それらに必要な権限を示します。
- フェンシング
- compute.instances.list
- compute.instances.get
- compute.instances.reset
- compute.instances.stop
- compute.instances.start
- logging.logEntries.create
- compute.zones.list
- エイリアス IP を使用して実装される VIP
- compute.instances.list
- compute.instances.get
- compute.zones.list
- logging.logEntries.create
- compute.instances.updateNetworkInterface
- compute.zoneOperations.get
- logging.logEntries.create
- 静的ルートを使用して実装される VIP
- compute.instances.list
- compute.instances.get
- compute.zones.list
- logging.logEntries.create
- compute.routes.get
- compute.routes.create
- compute.routes.delete
- compute.routes.update
- compute.routes.list
- compute.networks.updatePolicy
- compute.networks.get
- compute.globalOperations.get
- logging.logEntries.create
- 内部ロードバランサを使用して実装される VIP
- 特定の権限は不要 - ロードバランサはヘルスチェック ステータスに対して動作するため、クラスタで Google Cloudのリソースを操作または変更する必要はありません。
Google Cloudでの仮想 IP の実装
高可用性クラスタは、フローティング IP アドレスまたは仮想 IP アドレス(VIP)を使用して、予期しない障害が発生した場合や定期メンテナンスが行われる場合に、クラスタノード間でワークロードを移動します。VIP の IP アドレスは変更されないため、作業が別のノードで行われることをクライアント アプリケーションが認識することはありません。
VIP はフローティング IP アドレスとも呼ばれます。
Google Cloudの場合、VIP の実装がオンプレミス環境と若干異なります。フェイルオーバーが発生したときに、Gratuitous ARP リクエストで変更を通知できません。代わりに、次のいずれかの方法を使用して SAP HA クラスタの VIP アドレスを実装できます。
- 内部パススルー ネットワーク ロードバランサのフェイルオーバーのサポート(推奨)。
- Google Cloud 静的 ルート
- Google Cloud エイリアス IP アドレス
内部パススルー ネットワーク ロードバランサの VIP の実装
通常、ロードバランサはユーザーのトラフィックをアプリケーションの複数のインスタンスに分散します。複数のアクティブなシステム間でワークロードを分散し、処理速度の低下や特定のインスタンスの障害から保護します。
また、内部パススルー ネットワーク ロードバランサはフェイルオーバー サポートも提供しています。これと Compute Engine のヘルスチェックを組み合わせて使用することによって、障害の検出、フェイルオーバーのトリガー、OS ネイティブの HA クラスタ内の新しいプライマリ SAP システムへのトラフィックのルート変更を行うことができます。
フェイルオーバー サポートは、次のようなさまざまな理由から VIP の実装方法として推奨されます。
- Compute Engine でのロード バランシングは 99.99% の可用性の SLA を提供します。
- ロード バランシングはマルチゾーンの高可用性クラスタをサポートしており、予測可能なクロスゾーン フェイルオーバー時間でゾーン障害から保護します。
- ロード バランシングを使用すると、フェイルオーバーの検出とトリガーに必要な時間が短縮され、通常は障害発生から数秒以内に完了します。全体的なフェイルオーバー時間は、HA システム内の各コンポーネントのフェイルオーバー時間(ホスト、データベース システム、アプリケーション システムなど)によって左右されます。
- ロード バランシングを使用すると、クラスタ構成が簡素化され、依存関係が削減されます。
- ルートを使用する VIP の実装とは異なり、ロード バランシングでは独自の VPC ネットワークの IP 範囲を使用でき、それらの IP 範囲は必要に応じて予約や構成を行うことができます。
- ロード バランシングを使用すると、計画されたメンテナンスで停止する場合に、トラフィックのルートをセカンダリ システムに簡単に変更できます。
ロードバランサによる VIP の実装でヘルスチェックを作成する場合は、ホストの状態を判断するためにヘルスチェックでプローブするホストポートを指定します。SAP HA クラスタの場合は、他のサービスと競合しないように、プライベート範囲 49152~65535 のターゲット ホストポートを指定してください。ホスト VM では、socat ユーティリティや HAProxy などのセカンダリ ヘルパー サービスを使用してターゲット ポートを構成します。
データベース クラスタでセカンダリのスタンバイ システムをオンライン状態のままにしている場合、ヘルスチェックとヘルパー サービスによってロード バランシングを有効にし、クラスタ内で現在プライマリ システムとして機能しているオンライン システムにトラフィックを転送できます。
ヘルパー サービスとポート リダイレクトを使用して、SAP システムの計画されたソフトウェア メンテナンスの際にフェイルオーバーをトリガーできます。
フェイルオーバーのサポートの詳細については、内部パススルー ネットワーク ロードバランサのフェイルオーバーを構成するをご覧ください。
ロードバランサによる VIP の実装を使用して HA クラスタをデプロイするには、以下をご覧ください。
静的ルートの VIP の実装
静的ルートの実装ではゾーン障害に対する保護も提供されますが、VM が存在する既存の VPC サブネットの IP 範囲外の VIP を使用する必要があります。そのため、VIP が拡張ネットワーク内の外部 IP アドレスと競合しないか確認する必要もあります。
静的ルートの実装を共有 VPC 構成とともに使用する場合は、複雑さが高まることがあります。この構成は、ネットワーク構成を分離してホスト プロジェクトに含めることを意図するものです。
VIP に静的ルートの実装を使用する場合は、ネットワーク管理者に相談して、静的ルートの実装に適した IP アドレスを決定してください。
エイリアス IP の VIP の実装
エイリアス IP の VIP の実装は、マルチゾーンの HA のデプロイにはおすすめしません。一つのゾーンに障害が発生した場合に、エイリアス IP を別のゾーンのノードに再割り振りするには時間がかかる可能性があるためです。代わりに、フェイルオーバーをサポートする内部パススルー ネットワーク ロードバランサを使用して VIP を実装してください。
SAP HA クラスタのすべてのノードを同じゾーンにデプロイしている場合は、エイリアス IP を使用して HA クラスタの VIP を実装できます。
VIP にエイリアス IP の実装を使用するマルチゾーン SAP HA クラスタがすでに存在する場合は、VIP アドレスを変更せずに内部パススルー ネットワーク ロードバランサの実装に移行できます。エイリアス IP アドレスと内部パススルー ネットワーク ロードバランサの両方で、VPC ネットワークの IP 範囲が使用されます。
エイリアス IP アドレスはマルチゾーン HA クラスタでの VIP の実装には推奨されませんが、SAP のデプロイでは他の用途があります。たとえば、SAP Landscape Management で管理されるようなフレキシブルな SAP デプロイの場合に、エイリアス IP アドレスを使用して論理ホスト名と IP 割り当てを提供できます。
Google Cloudの VIP に関する一般的なベスト プラクティス
Google Cloudの VIP の詳細については、フローティング IP アドレスのベスト プラクティスをご覧ください。
Google Cloudでの SAP HANA ホストの自動フェイルオーバー
Google Cloud は、SAP HANA が提供するローカル障害復旧ソリューションである SAP HANA ホスト自動フェイルオーバーをサポートしています。ホスト自動フェイルオーバー ソリューションでは、ホスト障害が発生した場合に、マスターホストまたはワーカーホストから処理を引き継ぐように予約されている 1 つ以上のスタンバイ ホストを使用します。スタンバイ ホストにはデータが含まれず、作業も処理されません。
フェイルオーバーが完了すると、障害が発生したホストはスタンバイ ホストとして再起動されます。
SAP では、 Google Cloud上のスケールアウト システムで最大 3 つのスタンバイ ホストがサポートされます。スタンバイ ホストは、Google Cloudのスケールアウト システムで SAP がサポートする最大 16 個のアクティブ ホストにはカウントされません。
ホスト自動フェイルオーバー ソリューションに関する SAP からの情報については、Host Auto-Failover をご覧ください。
Google Cloudで SAP HANA ホスト自動フェイルオーバーを使用する場合
SAP HANA ホスト自動フェイルオーバーは、SAP HANA スケールアウト システムの単一ノードを次のコンポーネントの障害から保護します。
- SAP HANA インスタンス
- ホスト オペレーティング システム
- ホスト VM
ホスト VM の障害の点では、 Google Cloudは自動再起動とライブ マイグレーションにより、予期しない VM の停止や定期検査による停止からシステムを保護しています。通常、SAP HANA ホスト VM の場合、ホスト自動フェイルオーバーよりも自動再起動のほうが復旧が早くなります。そのため、VM の保護に SAP HANA ホスト自動フェイルオーバー ソリューションは必要ありません。
SAP HANA ホスト自動フェイルオーバーでは、SAP HANA スケールアウト システムのすべてのノードが 1 つのゾーンにデプロイされるため、ゾーン障害からは保護されません。
SAP HANA ホスト自動フェイルオーバーは SAP HANA データをスタンバイ ノードのメモリにプリロードしません。このため、スタンバイ ノードに引き継がれるときのノード全体の復旧時間は、スタンバイ ノードのメモリへのデータの読み込みにかかる時間に左右されます。
次のシナリオでは、SAP HANA ホスト自動フェイルオーバーの使用を検討してください。
- Google Cloudで検出されない可能性がある SAP HANA ノードのソフトウェアまたはホスト オペレーティング システムの障害。
- リフト&シフトでの移行。この移行では、SAP HANA がGoogle Cloud用に最適化されるまで、オンプレミスに SAP HANA 構成を複製しておく必要があります。
- 完全に複製されたクロスゾーンの高可用性構成を維持することがコスト的に厳しく、次のことを許容できる場合:
- スタンバイ ノードのメモリに SAP HANA データを読み込む必要があるため、ノードの復旧時間が長くなること。
- ゾーン障害のリスク。
SAP HANA 用ストレージ マネージャー
/hana/data ボリュームと /hana/log ボリュームは、マスターホストとワーカーホストにのみマウントされます。引き継ぎが発生すると、ホスト自動フェイルオーバー ソリューションが SAP HANA Storage Connector API と SAP HANA スタンバイ ノード用のGoogle Cloud ストレージ マネージャーを使用して、障害が発生したホストからスタンバイ ホストにボリューム マウントを移行します。
Google Cloudでは、SAP HANA ホスト自動フェイルオーバーを使用する SAP HANA システムに SAP HANA 用ストレージ マネージャーが必要になります。
SAP HANA 用ストレージ マネージャーのサポート対象バージョン
SAP HANA 用ストレージ マネージャーのバージョン 2.0 以降がサポートされています。2.0 より前のバージョンはすべて非推奨であり、サポートされていません。以前のバージョンを使用している場合は、SAP HANA システムを更新して SAP HANA 用ストレージ マネージャーの最新バージョンを使用します。SAP HANA 用ストレージ マネージャーの更新をご覧ください。
サポートが終了しているかどうか確認するには、gceStorageClient.py ファイルを開きます。デフォルトのインストール ディレクトリは /hana/shared/gceStorageClient です。
バージョン 2.0 以降では、次の例のように gceStorageClient.py ファイルの先頭のコメント部分にバージョン番号があります。バージョン番号がない場合は、SAP HANA 用ストレージ マネージャーの非推奨バージョンを使用しています。
"""Google Cloud Storage Manager for SAP HANA Standby Nodes. The Storage Manager for SAP HANA implements the API from the SAP provided StorageConnectorClient to allow attaching and detaching of disks when running in Compute Engine. Build Date: Wed Jan 27 06:39:49 PST 2021 Version: 2.0.20210127.00-00 """
SAP HANA 用ストレージ マネージャーのインストール
SAP HANA 用ストレージ マネージャーをインストールする場合は、SAP HANA スケールアウト システムをデプロイする自動デプロイの使用をおすすめします。この方法では、SAP HANA 用の最新のストレージ マネージャーが使用されます。
Google Cloudの既存の SAP HANA スケールアウト システムに SAP HANA ホストの自動フェイルオーバーを追加する必要がある場合は、 Google Cloud で提供されている Terraform 構成ファイルを使用して、新しいスケールアウト SAP HANA システムをデプロイし、既存のシステムから新しいシステムにデータを読み込むアプローチをおすすめします。データを読み込むには、標準の SAP HANA バックアップと復元手順、または SAP HANA システム レプリケーションを使用します。これにより、ダウンタイムを制限できます。システム レプリケーションの詳細については、SAP Note 2473002 - Using HANA system replication to migrate scale out system をご覧ください。
自動デプロイを使用できない場合は、Google Cloud Consulting サービスなどで SAP ソリューション コンサルタントを探し、SAP HANA 用ストレージ マネージャーの手動インストールのサポートを依頼することを検討してください。
既存のスケールアウトまたはスケールアウトした新しい SAP HANA システムに SAP HANA 用ストレージ マネージャーを手動でインストールする方法については、現在文書化されていません。
SAP HANA ホスト自動フェイルオーバー用の自動デプロイ オプションの詳細については、SAP HANA ホスト自動フェイルオーバーを備えた SAP HANA スケールアウト システムの自動デプロイをご覧ください。
SAP HANA 用ストレージ マネージャーの更新
SAP HANA 用ストレージ マネージャーを更新するには、まず、インストール パッケージをダウンロードしてインストール スクリプトを実行します。これにより、SAP HANA /shared ドライブにある SAP HANA 実行可能ファイルのストレージ マネージャーが更新されます。
次の手順は、SAP HANA 用ストレージ マネージャーのバージョン 2 のみを対象としています。2021 年 2 月 1 日より前にダウンロードされた SAP HANA のストレージ マネージャーのバージョンを使用している場合は、SAP HANA のストレージ マネージャーを更新する前にバージョン 2 をインストールしてください。
SAP HANA 用ストレージ マネージャーを更新するには:
SAP HANA 用ストレージ マネージャーの現在のバージョンを確認します。
RHEL
sudo yum check-update google-sapgcestorageclient
SLES
sudo zypper list-updates -r google-sapgcestorageclient
アップデートが存在する場合は、アップデートをインストールします。
RHEL
sudo yum update google-sapgcestorageclient
SLES
sudo zypper update
更新された SAP HANA 用ストレージ マネージャーが
/usr/sap/google-sapgcestorageclient/gceStorageClient.pyにインストールされます。既存の
gceStorageClient.pyを更新後のgceStorageClient.pyファイルに置き換えます。gceStorageClient.pyファイルが/hana/shared/gceStorageClient(デフォルトのインストール場所)に存在する場合は、インストール スクリプトを使用してファイルを更新します。sudo /usr/sap/google-sapgcestorageclient/install.sh
既存の
gceStorageClient.pyファイルが/hana/shared/gceStorageClientにない場合は、更新後のファイルを既存のファイルと同じ場所にコピーし、既存のファイルと置き換えます。
global.ini ファイルの構成パラメータ
フェンシングが有効かどうかなど、SAP HANA 用ストレージ マネージャーの特定の構成パラメータは、SAP HANA の global.ini ファイルのストレージ セクションに保存されます。 Google Cloud 提供の Terraform 構成ファイルを使用して、ホストの自動フェイルオーバー機能を備えた SAP HANA システムをデプロイすると、デプロイ プロセスで構成パラメータが global.ini ファイルに追加されます。
次の例は、SAP HANA 用ストレージ マネージャーに作成された global.ini の内容を示しています。
[persistence] basepath_datavolumes = %BASEPATH_DATAVOLUMES% basepath_logvolumes = %BASEPATH_LOGVOLUMES% use_mountpoints = %USE_MOUNTPOINTS% basepath_shared = %BASEPATH_SHARED% [storage] ha_provider = gceStorageClient ha_provider_path = %STORAGE_CONNECTOR_PATH% # # Example configuration for 2+1 setup # # partition_1_*__pd = node-mnt00001 # partition_2_*__pd = node-mnt00002 # partition_3_*__pd = node-mnt00003 # partition_*_data__dev = /dev/hana/data # partition_*_log__dev = /dev/hana/log # partition_*_*__gcloudAccount = svc-acct-name@project-id. # partition_*_data__mountOptions = -t xfs -o logbsize=256k # partition_*_log__mountOptions = -t xfs -o logbsize=256k # partition_*_*__fencing = disabled [trace] ha_gcestorageclient = info
SAP HANA 用ストレージ マネージャーへの Sudo アクセス権
SAP HANA のサービスとストレージを管理するために、SAP HANA 用ストレージ マネージャーは SID_LCadm ユーザー アカウントを使用し、特定のシステム バイナリへの sudo アクセス権を必要とします。
Google Cloud が提供する自動化スクリプトを使って、ホスト自動フェイルオーバーを使用した SAP HANA をデプロイする場合、必要な sudo アクセス権が構成されます。
SAP HANA 用ストレージ マネージャーを手動でインストールする場合は、visudo コマンドを使用して /etc/sudoers ファイルを編集し、以下の必要なバイナリに対する sudo アクセス権を SID_LCadm ユーザー アカウントに付与します。
ご使用のオペレーティング システムのタブをクリックしてください。
RHEL
/bin/kill /bin/mount /bin/umount /sbin/dmsetup /sbin/lvdisplay /sbin/lvscan /sbin/pvscan /sbin/vgchange /sbin/vgscan /usr/bin/gcloud /usr/bin/lsof /usr/bin/mkdir /usr/bin/sg_persist /usr/bin/systemctl /usr/sbin/lsof /usr/sbin/xfs_repair
SLES
/bin/kill /bin/mount /bin/umount /sbin/dmsetup /sbin/lvdisplay /sbin/lvscan /sbin/pvscan /sbin/vgchange /sbin/vgscan /sbin/xfs_repair /usr/bin/gcloud /usr/bin/lsof /usr/bin/mkdir /usr/bin/sg_persist /usr/bin/systemctl /usr/sbin/lsof
次の例は、/etc/sudoers ファイルのエントリを示しています。この例では、関連付けられている SAP HANA システムのシステム ID が SID_LC に置き換えられています。サンプル エントリは、ホストの自動フェイルオーバーを使用する SAP HANA スケールアウト用に Google Cloud から提供されている Terraform 構成によって作成されました。Terraform 構成によって作成されたエントリには、不要になったものの、下位互換性のために保持されているバイナリが含まれています。このようなバイナリを削除し、前述のリストに含まれているバイナリのみを含めてください。
SID_LCadm ALL=NOPASSWD: /sbin/multipath,/sbin/multipathd,/etc/init.d/multipathd,/usr/bin/sg_persist,/bin/mount,/bin/umount,/bin/kill,/usr/bin/lsof,/usr/bin/systemctl,/usr/sbin/lsof,/usr/sbin/xfs_repair,/sbin/xfs_repair,/usr/bin/mkdir,/sbin/vgscan,/sbin/pvscan,/sbin/lvscan,/sbin/vgchange,/sbin/lvdisplay,/usr/bin/gcloud,/sbin/dmsetup
SAP HANA 用ストレージ マネージャーのサービス アカウントの構成
Google Cloudで SAP HANA スケールアウト システムのホスト自動フェイルオーバーを有効にするには、SAP HANA 用ストレージ マネージャーにサービス アカウントが必要です。専用のサービス アカウントを作成すると、フェイルオーバー中のディスクの取り外しや取り付けなど、SAP HANA VM でアクションを実行するために必要な権限を付与できます。サービス アカウントの作成方法については、サービス アカウントを作成するをご覧ください。
必要な IAM 権限
SAP HANA 用ストレージ マネージャーで使用されるサービス アカウントには、次の IAM 権限を含むロールを付与する必要があります。
gcloud compute instances resetコマンドを使用して VM インスタンスをリセットするには、compute.instances.reset権限を付与します。gcloud compute disks describeコマンドを使用して Persistent Disk ボリュームまたは Hyperdisk ボリュームに関する情報を取得するには、compute.disks.get権限を付与します。gcloud compute instances attach-diskコマンドを使用してディスクを VM インスタンスにアタッチするには、compute.instances.attachDisk権限を付与します。gcloud compute instances detach-diskコマンドを使用して VM インスタンスからディスクを取り外すには、compute.instances.detachDisk権限を付与します。gcloud compute instances listコマンドを使用して VM インスタンスを一覧表示するには、compute.instances.list権限を付与します。gcloud compute disks listコマンドを使用して Persistent Disk ボリュームまたは Hyperdisk ボリュームを一覧表示するには、compute.disks.list権限を付与します。
必要な権限は、カスタムロールや他の事前定義ロールから付与できます。
また、VM のアクセス スコープを cloud-platform に設定して、サービス アカウントに付与する IAM ロールによって VM の IAM 権限が完全に決定されるようにします。
デフォルトでは、SAP HANA 用ストレージ マネージャーは、スケールアウト SAP HANA システムのホストで gcloud CLI が使用することを許可されているアクティブなサービス アカウントまたはユーザー アカウントを使用します。
SAP HANA 用ストレージ マネージャーで使用されているアクティブ アカウントを確認するには、次のコマンドを使用します。
gcloud auth list
このコマンドの詳細については、gcloud auth list をご覧ください。
SAP HANA 用ストレージ マネージャーで使用されるアカウントを変更する手順は次のとおりです。
スケールアウト SAP HANA システムの各ホストでサービス アカウントを使用できることを確認します。
gcloud auth listglobal.iniファイルで、[storage]セクションをサービス アカウントで更新します。[storage] ha_provider = gceStorageClient ... partition_*_*__gcloudAccount = SERVICE_ACCOUNTSERVICE_ACCOUNTは、SAP HANA のストレージ マネージャーで使用されるサービス アカウントの名前(メールアドレス形式)に置き換えます。このサービス アカウントは、SAP HANA 用ストレージ マネージャーからgcloudコマンドを実行するときに使用されます。
SAP HANA ホスト自動フェイルオーバー用の NFS ストレージ
ホスト自動フェイルオーバーを使用する SAP HANA スケールアウト システムでは、すべてのホスト間で /hana/shared ボリュームと /hanabackup ボリュームを共有するため、Filestore などの NFS ソリューションが必要になります。NFS ソリューションの設定は自分で行う必要があります。
自動デプロイを使用する場合、NFS サーバーに関する情報をデプロイ ファイル内に指定して、デプロイ中に NFS ディレクトリをマウントします。
使用する NFS ボリュームは空にしておく必要があります。特にファイルまたはフォルダが SAP システム ID(SID)を参照している場合、既存のファイルとデプロイ プロセスが競合する可能性があります。デプロイ プロセスでは、ファイルが上書き可能かどうかわかりません。
デプロイメント プロセスは、NFS サーバーに /hana/shared ボリュームと /hanabackup ボリュームを保存し、スタンバイ ホストを含むすべてのホストに NFS サーバーをマウントします。その後は、マスターホストが NFS サーバーを管理します。
Cloud Storage Backint agent for SAP HANA などのバックアップ ソリューションを実装する場合は、デプロイの完了後に NFS サーバーから /hanabackup ボリュームを削除できます。
Google Cloudで利用可能な共有ファイル ソリューションの詳細については、 Google Cloud上の SAP のファイル共有ソリューションをご覧ください。
オペレーティング システムのサポート
Google Cloud は、次のオペレーティング システムでのみ SAP HANA ホスト自動フェイルオーバーをサポートしています。
- RHEL for SAP 7.7 以降
- RHEL for SAP 8.1 以降
- RHEL for SAP 9.0 以降
-
RHEL for SAP 9.x に SAP ソフトウェアをインストールする前に、ホストマシン、特に
chkconfigとcompat-openssl11に追加パッケージをインストールする必要があります。Compute Engine が提供するイメージを使用する場合、これらのパッケージは自動的にインストールされます。SAP の詳細については、SAP Note 3108316 - Red Hat Enterprise Linux 9.x: Installation and Configuration をご覧ください。
-
RHEL for SAP 9.x に SAP ソフトウェアをインストールする前に、ホストマシン、特に
- SLES for SAP 12 SP5
- SLES for SAP 15 SP1 以降
Compute Engine から利用できる公開イメージを確認するには、イメージをご覧ください。
ホスト自動フェイルオーバーを使用する SAP HANA システムのアーキテクチャ
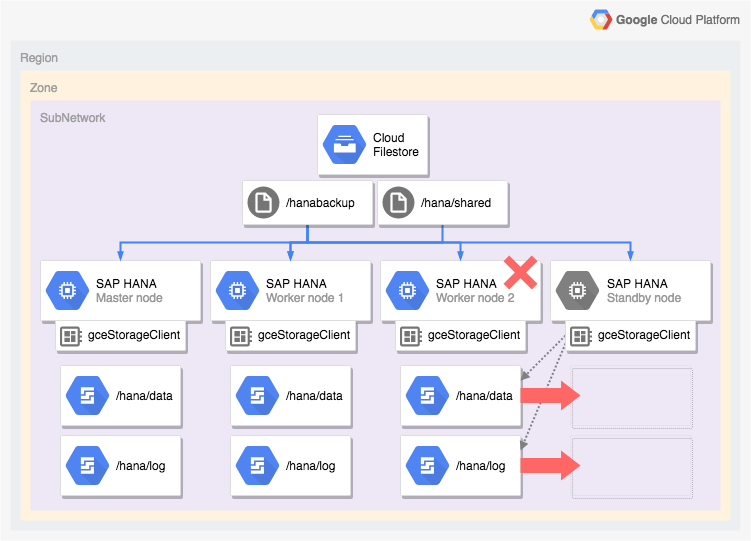
次の図は、SAP HANA ホスト自動フェイルオーバー機能を含む Google Cloud でのスケールアウト アーキテクチャを示しています。この図では、SAP HANA 用ストレージ マネージャーが実行可能ファイルの名前 gceStorageClient で表されています。
この図は、ワーカーノード 2 に障害が発生したことと、スタンバイ ノードが引き継ぐ様子を示しています。SAP HANA 用ストレージ マネージャーは、SAP Storage Connector API(図にはありません)と連携して、失敗したワーカーノードから /hana/data ボリュームと /hana/logs ボリュームを含むディスクを切断し、これらのボリュームをスタンバイ ノードに再マウントします。スタンバイ ノードがワーカーノード 2 になり、障害が発生したノードはスタンバイ ノードになります。
SAP HANA 高可用性構成の自動デプロイ オプション
Google Cloud 提供の Terraform 構成を使用すると、SAP HANA HA システムのデプロイを自動化できます。また、SAP HANA HA システムを手動でデプロイして構成することもできます。
Google Cloud には、デプロイ固有の Terraform 構成ファイルが用意されています。このファイルを編集して完成させます。標準の Terraform コマンドを使用して現在の作業ディレクトリを初期化し、 Google Cloud用の Terraform プロバイダ プラグインとモジュール ファイルをダウンロードして構成を適用します。これにより、SAP HANA システムがデプロイされます。
この自動デプロイでは SAP HANA システムをデプロイします。このシステムは、SAP によって完全にサポートされ、SAP とGoogle Cloudの両方のベスト プラクティスに従っています。
SAP HANA 用の Linux 高可用性クラスタの自動デプロイ
SAP HANA の自動デプロイでは、パフォーマンスが最適化された高可用性 Linux クラスタがデプロイされます。これには以下の内容が含まれます。
- 自動フェイルオーバー。
- 自動再起動。
- 指定した仮想 IP アドレス(VIP)の予約。
- 仮想 IP アドレス(VIP)から HA クラスタのノードへのルーティングを管理する内部 TCP / UDP ロード バランシングによるフェイルオーバー サポート。
- Compute Engine ヘルスチェックにクラスタ内の VM インスタンスのモニタリングを許可するファイアウォール ルール。
- Pacemaker 高可用性クラスタ リソース マネージャー。
- Google Cloud フェンシング メカニズム。
- 各 SAP HANA インスタンスに必要な永続ディスクを備えた VM
- 必要に応じて、単一テナントノード。
- 同期レプリケーションとメモリ プリロードが構成された SAP HANA インスタンス。
Terraform を使用して SAP HANA 用高可用性クラスタのデプロイを自動化するには、以下をご覧ください。
SAP HANA ホスト自動フェイルオーバーを備えた SAP HANA スケールアウト システムの自動デプロイ
Terraform を使用して、スタンバイ ホストを備えたスケールアウト システムのデプロイを自動化できます。詳細については、Terraform: ホストの自動フェイルオーバーを備えた SAP HANA スケールアウト システムのデプロイガイドをご覧ください。
SAP HANA ホスト自動フェイルオーバー機能を含む SAP HANA スケールアウト システムの場合、 Google Cloud 提供の Terraform 構成により、次のものがデプロイされます。
- 1 つのマスター SAP HANA インスタンス
- 1~15 のワーカーホスト
- 1~3 のスタンバイ ホスト
- 各 SAP HANA ホストの VM
- マスターホストとワーカーホストの SSD ベースの Persistent Disk または Hyperdisk ボリューム
- SAP HANA スタンバイ ノード用の Google Cloud ストレージ マネージャー
ホスト自動フェイルオーバーを使用する SAP HANA スケールアウト システムでは、すべてのホスト間で /hana/shared ボリュームと /hanabackup ボリュームを共有するため、Filestore などの NFS ソリューションが必要になります。デプロイ時に Terraform が NFS ディレクトリをマウントできるようにするため、SAP HANA システムのデプロイ前に NFS ソリューションを各自で設定する必要があります。
Filestore NFS サーバー インスタンスは、インスタンスの作成の手順に沿って、すばやく簡単に設定できます。
SAP HANA のアクティブ / アクティブ(読み取り可能)オプション
SAP HANA 2.0 SPS1 以降、SAP では SAP HANA システム レプリケーションにアクティブ / アクティブ(読み取り可能)設定を提供しています。アクティブ / アクティブ(読み取り可能)に構成されているレプリケーション システムでは、セカンダリ システムの SQL ポートが読み取りアクセスとして開いています。これにより、負荷の高いタスクにセカンダリ システムを使用し、コンピューティング リソース間のワークロードのバランスを取ることで、SAP HANA データベースの全体的なパフォーマンスを向上できます。アクティブ / アクティブ(読み取り可能)機能の詳細については、ご使用の SAP HANA バージョンの SAP HANA Administration Guide と SAP Note 1999880 をご覧ください。
セカンダリ システムで読み取りアクセスを可能にするシステム レプリケーションを構成するには、オペレーション モードを logreplay_readaccess にする必要があります。ただし、このオペレーション モードを使用するには、プライマリ システムとセカンダリ システムが同じ SAP HANA バージョンを実行している必要があります。したがって、ローリング アップグレード中は、両方のシステムが同じ SAP HANA バージョンを実行するまで、セカンダリ システムに対する読み取り専用アクセスはできません。
SAP では、アクティブ / アクティブ(読み取り可能)のセカンダリ システムに接続するために、次のオプションをサポートしています。
- セカンダリ システムに対して明示的な接続を開いて、直接接続する。
- プライマリ システムでヒント付きの SQL ステートメントを実行して間接的に接続する。評価時にクエリのルートがセカンダリ システムに変更されます。
次の図は、最初のオプションを使用して、アプリケーションが Google Cloud にデプロイされた Pacemaker クラスタ内のセカンダリ システムに直接アクセスしています。追加のフローティングまたは仮想 IP アドレス(VIP)を使用して、SAP HANA Pacemaker クラスタの一部としてセカンダリ システムの機能を担う VM インスタンスをターゲットにします。VIP はセカンダリ システムに従います。予期しない障害が発生した場合や定期メンテナンス時に、クラスタノード間で読み取りワークロードを移動できます。利用可能な VIP の実装方法については、 Google Cloudでの仮想 IP の実装をご覧ください。

Pacemaker クラスタでアクティブ / アクティブ(読み取り可能)の SAP HANA システム レプリケーションを構成する手順は次のとおりです。
- SUSE Pacemaker クラスタで HANA アクティブ / アクティブ(読み取り可能)を構成する
- Red Hat Pacemaker クラスタで HANA アクティブ / アクティブ(読み取り可能)を構成する
次のステップ
Google Cloud と SAP はどちらも高可用性に関する詳細情報を提供しています。
Google Cloud の高可用性に関する詳細情報
Google Cloudでの SAP HANA の高可用性について詳しくは、SAP HANA 運用ガイドをご覧ください。
さまざまな障害シナリオから Google Cloudでシステムを保護するための一般的な情報については、堅牢なシステムの設計をご覧ください。
SAP が提供する SAP HANA 高可用性機能の詳細情報
SAP HANA 高可用機能に関する SAP の詳細については、次のドキュメントをご覧ください。
- High Availability for SAP HANA
- SAP Note 2057595 - FAQ: SAP HANA High Availability
- How To Perform System Replication for SAP HANA 2.0
- Network Recommendations for SAP HANA System Replication