In dieser Anleitung erfahren Sie, wie Sie mit SAP Data Services (DS) Daten aus einer SAP-Anwendung oder der zugrunde liegenden Datenbank nach BigQuery exportieren.
Die Datenbank kann SAP HANA oder eine andere von SAP unterstützte Datenbank sein.
Im vorliegenden Beispiel werden SQL Anywhere-Datenbanktabellen exportiert. Sie können diese jedoch verwenden, um den Export anderer Objekttypen aus SAP-Anwendungen und der Datenbankschicht in BigQuery einzurichten.
Sie können den Datenexport verwenden, um Ihre SAP-Daten zu sichern oder die Daten aus Ihren SAP-Systemen mit Nutzerdaten aus anderen Systemen in BigQuery zu konsolidieren. Dort können Sie Erkenntnisse aus maschinellem Lernen und Datenanalysen im Petabytebereich gewinnen.
Die Anleitung richtet sich an SAP-Systemadministratoren mit Grundkenntnissen in der Konfiguration von SAP Basis, SAP DS und Google Cloud.
Architektur

SAP Data Services ruft die Daten aus der SAP-Anwendung oder der zugrunde liegenden Datenbank ab, transformiert die Daten so, dass sie mit dem BigQuery-Format kompatibel sind, und initiiert den Ladejob, der die Daten nach BigQuery verschiebt. Nach Abschluss des Ladejobs stehen die Daten in BigQuery zur Analyse zur Verfügung.
Der Export ist ein Snapshot der Daten im Quellsystem zum Zeitpunkt des Exports. Sie legen fest, wann SAP Data Services einen Export initiiert. Alle vorhandenen Daten in der BigQuery-Zieltabelle werden von den exportierten Daten überschrieben. Nach Abschluss des Exports werden die Daten in BigQuery nicht mehr mit den Daten im Quellsystem synchronisiert.
In diesem Szenario können das SAP-Quellsystem und SAP Data Services entweder in oder außerhalb von Google Cloudausgeführt werden.
Kernkomponenten der Lösung
Die folgenden Komponenten sind erforderlich, um mit SAP Data Services Daten aus einer SAP-Anwendung oder einer Datenbank nach BigQuery zu exportieren:
| Komponente | Erforderliche Versionen | Hinweise |
|---|---|---|
| SAP-Anwendungsserver-Stack | Jedes ABAP-basierte SAP-System ab R/3 4.6C | In dieser Anleitung werden der Anwendungsserver und der Datenbankserver zusammen als Quellsystem bezeichnet, auch wenn sie auf unterschiedlichen Computern ausgeführt werden. Definieren Sie den RFC-Nutzer mit entsprechender Berechtigung. Optional: Definieren Sie einen separaten Tablespace für Logging-Tabellen. |
| Datenbanksystem | Jede Datenbankversion, die in der SAP Product Availability Matrix (PAM) als unterstützt aufgeführt wird, vorbehaltlich etwaiger Einschränkungen des SAP NetWeaver-Stacks, die in der PAM aufgeführt sind. | |
| SAP Data Services | SAP Data Services 4.2 SP1 oder höher | |
| BigQuery | – |
Kosten
BigQuery ist eine abrechenbare Google Cloud Komponente.
Mit dem Preisrechner können Sie eine Kostenschätzung für die voraussichtliche Nutzung erstellen.
Vorbereitung
In dieser Anleitung wird davon ausgegangen, dass das SAP-Anwendungssystem, der Datenbankserver und SAP Data Services bereits installiert und für den normalen Betrieb konfiguriert sind.
Klären Sie in direktem Kontakt mit SAP, ob Ihre geplante Konfiguration den SAP-Lizenzanforderungen entspricht. Die Anforderungen können unterschiedlich sein, je nachdem, ob Sie Daten aus einem SAP-Anwendungssystem oder aus einer zugrunde liegenden Datenbank exportieren.
Google Cloud -Projekt in Google Cloudeinrichten
Sie benötigen ein Google Cloud -Projekt, um BigQuery verwenden zu können.
Google Cloud -Projekt erstellen
Öffnen Sie die Google Cloud und registrieren Sie sich anhand der Schritte im Einrichtungsassistenten.
Klicken Sie links oben neben dem Google Cloud -Logo auf das Drop-down-Menü und wählen Sie NEUES PROJEKT aus.
Geben Sie Ihrem Projekt einen Namen und klicken Sie auf Erstellen.
Aktualisieren Sie die Seite, nachdem das Projekt erstellt wurde (am Hinweis oben rechts zu erkennen).
APIs aktivieren
Aktivieren Sie die BigQuery API:
Dienstkonto erstellen
Mit dem Dienstkonto (insbesondere seiner Schlüsseldatei) wird SAP DS bei BigQuery authentifiziert. Sie benötigen die Schlüsseldatei später, wenn Sie den Zieldatenspeicher erstellen.
Rufen Sie in der Google Cloud Console die Seite Dienstkonten auf.
Wählen Sie Ihr Google Cloud Projekt aus.
Klicken Sie auf Dienstkonto erstellen.
Geben Sie im Feld Name des Dienstkontos einen Namen ein.
Klicken Sie auf Erstellen und fortfahren.
Wählen Sie in der Liste Rolle auswählen die Option BigQuery > BigQuery-Datenbearbeiter aus.
Klicken Sie auf Weitere Rolle hinzufügen.
Wählen Sie in der Liste Rolle auswählen die Option BigQuery > BigQuery-Jobnutzer aus.
Klicken Sie auf Weiter.
Gewähren Sie Nutzern gegebenenfalls Zugriff auf das Dienstkonto.
Klicken Sie auf Fertig.
Klicken Sie in der Google Cloud Console auf der Seite Dienstkonten auf die E-Mail-Adresse des erstellten Dienstkontos.
Klicken Sie unter dem Namen des Dienstkontos auf den Tab Schlüssel.
Klicken Sie auf das Drop-down-Menü Schlüssel hinzufügen und wählen Sie Neuen Schlüssel erstellen aus.
Achten Sie darauf, dass der Schlüsseltyp JSON angegeben ist.
Klicken Sie auf Erstellen.
Speichern Sie die automatisch heruntergeladene Schlüsseldatei an einem sicheren Ort.
Export aus SAP-Systemen in BigQuery konfigurieren
Das Konfigurieren dieser Lösung umfasst im Allgemeinen folgende Schritte:
- SAP Data Services konfigurieren
- Datenfluss zwischen SAP Data Services und BigQuery erstellen
SAP Data Services konfigurieren
Data Services-Projekt erstellen
- Öffnen Sie die Anwendung SAP Data Services Designer.
- Wählen Sie File > New > Project aus.
- Geben Sie im Feld Project name einen Namen an.
- Klicken Sie auf Erstellen. Ihr Projekt wird links im "Project Explorer" angezeigt.
Quelldatenspeicher erstellen
Sie können entweder ein SAP-Anwendungssystem oder die zugrunde liegende Datenbank als Quelldatenspeicher für SAP Data Services verwenden. Welche Datenobjekte exportiert werden können, hängt davon ab, ob Sie ein SAP-Anwendungssystem oder eine Datenbank als Datenspeicher verwenden.
Wenn Sie ein SAP-Anwendungssystem als Datenspeicher verwenden, können Sie die folgenden Objekte exportieren:
- Tabellen
- Aufrufe
- Hierarchien
- ODP
- BAPI (Funktionen)
- IDocs

Wenn Sie eine zugrunde liegende Datenbank als Datenspeicherverbindung verwenden, können Sie folgende Objekte exportieren:
- Tabellen
- Aufrufe
- Gespeicherte Prozeduren
- Andere Datenobjekte

Die Datenspeicherkonfigurationen für SAP-Anwendungssysteme und -Datenbanken werden in den folgenden Abschnitten beschrieben. Unabhängig vom Typ der Datenspeicherverbindung oder des Datenobjekts ist das Verfahren zum Importieren und Verwenden der Objekte in einem SAP Data Services-Datenfluss nahezu identisch.
Konfiguration für SAP-Verbindung auf Anwendungsebene
Mit diesen Schritten wird eine Verbindung zu einer SAP-Anwendung hergestellt und die Datenobjekte werden dem jeweiligen Datenspeicherknoten in der Designer-Objektbibliothek hinzugefügt.
- Öffnen Sie die Anwendung SAP Data Services Designer.
- Öffnen Sie Ihr SAP Data Services-Projekt im Project Explorer.
- Wählen Sie Project > New > Datastore aus.
- Füllen Sie Datastore Name aus. z. B. ECC_DS.
- Wählen Sie im Feld Datastore type die Option SAP Applicationsaus.
- Geben Sie im Feld Application server name den Instanznamen des SAP-Anwendungsservers an.
- Geben Sie die Zugriffsanmeldedaten für den SAP-Anwendungsserver an.
- Klicken Sie auf OK.
Konfiguration für SAP-Verbindung auf Datenbankebene
SAP HANA
Mit diesen Schritten wird eine Verbindung zur SAP HANA-Datenbank hergestellt und die Datentabellen werden dem jeweiligen Datenspeicherknoten in der Designer-Objektbibliothek hinzugefügt.
- Öffnen Sie die Anwendung SAP Data Services Designer.
- Öffnen Sie Ihr SAP Data Services-Projekt im Project Explorer.
- Wählen Sie Project > New > Datastore aus.
- Füllen Sie das Feld Datastore Name aus, z. B. HANA_DS.
- Wählen Sie im Feld Datastore type die Option Database aus.
- Wählen Sie im Feld Database type die Option SAP HANA aus.
- Wählen Sie im Feld Database version Ihre Datenbankversion aus.
- Geben Sie den Namen für den Datenbankserver, die Portnummer und die Anmeldedaten ein.
- Klicken Sie auf OK.
Andere unterstützte Datenbanken
Mit diesen Schritten wird eine Verbindung zu SQL Anywhere erstellt und die Datentabellen werden dem jeweiligen Datenspeicherknoten in der Designer-Objektbibliothek hinzugefügt.
Die Schritte zum Herstellen einer Verbindung zu anderen unterstützten Datenbanken sind nahezu identisch.
- Öffnen Sie die Anwendung SAP Data Services Designer.
- Öffnen Sie Ihr SAP Data Services-Projekt im Project Explorer.
- Wählen Sie Project > New > Datastore aus.
- Füllen Sie das Feld Name aus, z. B. SQL_ANYWHERE_DS.
- Wählen Sie im Feld Datastore type die Option Database aus.
- Wählen Sie im Feld Database typedie Option SQL Anywhere aus.
- Wählen Sie im Feld Database version Ihre Datenbankversion aus.
- Geben Sie Database server name, Database name und die Anmeldedaten ein.
- Klicken Sie auf OK.
Der neue Datenspeicher wird auf dem Tab Datastore in der lokalen Objektbibliothek von Designer angezeigt.
Zieldatenspeicher erstellen
Mit diesen Schritten wird ein BigQuery-Datenspeicher erstellt, der das Dienstkonto verwendet, das Sie zuvor im Bereich Dienstkonto erstellen angelegt haben. Das Dienstkonto ermöglicht SAP Data Services sicheren Zugriff auf BigQuery.
Weitere Informationen finden Sie in den Abschnitten zum Abrufen der E-Mail-Adresse Ihres Google-Dienstkontos und zum Abrufen einer Datei mit dem privaten Schlüssel des Google-Dienstkontos in der Dokumentation zu SAP Data Services.
- Öffnen Sie die Anwendung SAP Data Services Designer.
- Öffnen Sie Ihr SAP Data Services-Projekt im Project Explorer.
- Wählen Sie Project > New > Datastore aus.
- Geben Sie im Feld Name einen Namen ein, beispielsweise BQ_DS.
- Wählen Sie im Feld Datastore type die Option Google BigQuery aus.
- Die Option Web Service URL (Webdienst-URL) wird angezeigt. Die Software trägt für die Option automatisch die standardmäßige BigQuery-Webdienst-URL ein.
- Wählen Sie Erweitert aus.
- Legen Sie die Optionen unter "Advanced" (Erweitert) anhand der Beschreibungen der Datenspeicheroptionen für BigQuery in der SAP Data Services-Dokumentation fest.
- Klicken Sie auf OK.
Der neue Datenspeicher wird auf dem Tab Datastore in der lokalen Objektbibliothek von Designer angezeigt.
Datenfluss zwischen SAP Data Services und BigQuery einrichten
Zum Einrichten des Datenflusses müssen Sie den Batchjob und den BigQuery-Loader-Datenfluss erstellen und die Quell- und BigQuery-Tabellen als externe Metadaten in SAP Data Services importieren.
Batchjob erstellen
- Öffnen Sie die Anwendung SAP Data Services Designer.
- Öffnen Sie Ihr SAP Data Services-Projekt im Project Explorer.
- Wählen Sie Project > New > Batch Job aus.
- Füllen Sie das Feld Name aus, z. B. JOB_SQL_ANYWHERE_BQ.
- Klicken Sie auf OK.
Datenflusslogik erstellen
Quelltabelle importieren
Mit diesen Schritten werden Datenbanktabellen aus dem Quelldatenspeicher importiert und in SAP Data Services zur Verfügung gestellt.
- Öffnen Sie die Anwendung SAP Data Services Designer.
- Erweitern Sie den Quelldatenspeicher im Project Explorer.
- Wählen Sie im oberen Teil des rechten Steuerfeldes die Option External Metadata aus. Die Liste der Knoten mit verfügbaren Tabellen und/oder anderen Objekten wird angezeigt.
- Wählen Sie die zu importierende Tabelle aus der Liste aus.
- Klicken Sie mit der rechten Maustaste und wählen Sie die Option Import aus.
- Die importierte Tabelle ist jetzt in der Objektbibliothek unter dem Quelldatenspeicherknoten verfügbar.
Datenfluss erstellen
- Wählen Sie den Batchjob im Project Explorer aus.
- Klicken Sie mit der rechten Maustaste auf den leeren Arbeitsbereich im rechten Bereich und wählen Sie die Option Add New > Dataflow aus.
- Klicken Sie mit der rechten Maustaste auf das Datenflusssymbol und wählen Sie Rename aus.
- Ändern Sie den Namen in DF_SQL_ANYWHERE_BQ.
Öffnen Sie den Datenflussarbeitsbereich mit einem Doppelklick auf das Datenflusssymbol.
Datenfluss importieren und mit den Quellobjekten des Datenspeichers verbinden
- Erweitern Sie den Quelldatenspeicher im Project Explorer.
- Ziehen Sie die Quelltabelle per Drag-and-Drop aus dem Datenspeicher zum Arbeitsbereich des Datenflusses. Wählen Sie die Option Make Source aus, wenn Sie die Tabelle in den Arbeitsbereich ziehen. In dieser Anleitung heißt der Datenspeicher SQL_ANYWHERE_DS. Der Name Ihres Datenspeichers kann abweichen.
- Ziehen Sie die Transformation Query aus dem Knoten Platform auf dem Tab Transforms der Objektbibliothek zum Datenfluss.
- Verbinden Sie die Quelltabelle im Arbeitsbereich mit der Transformation Query.
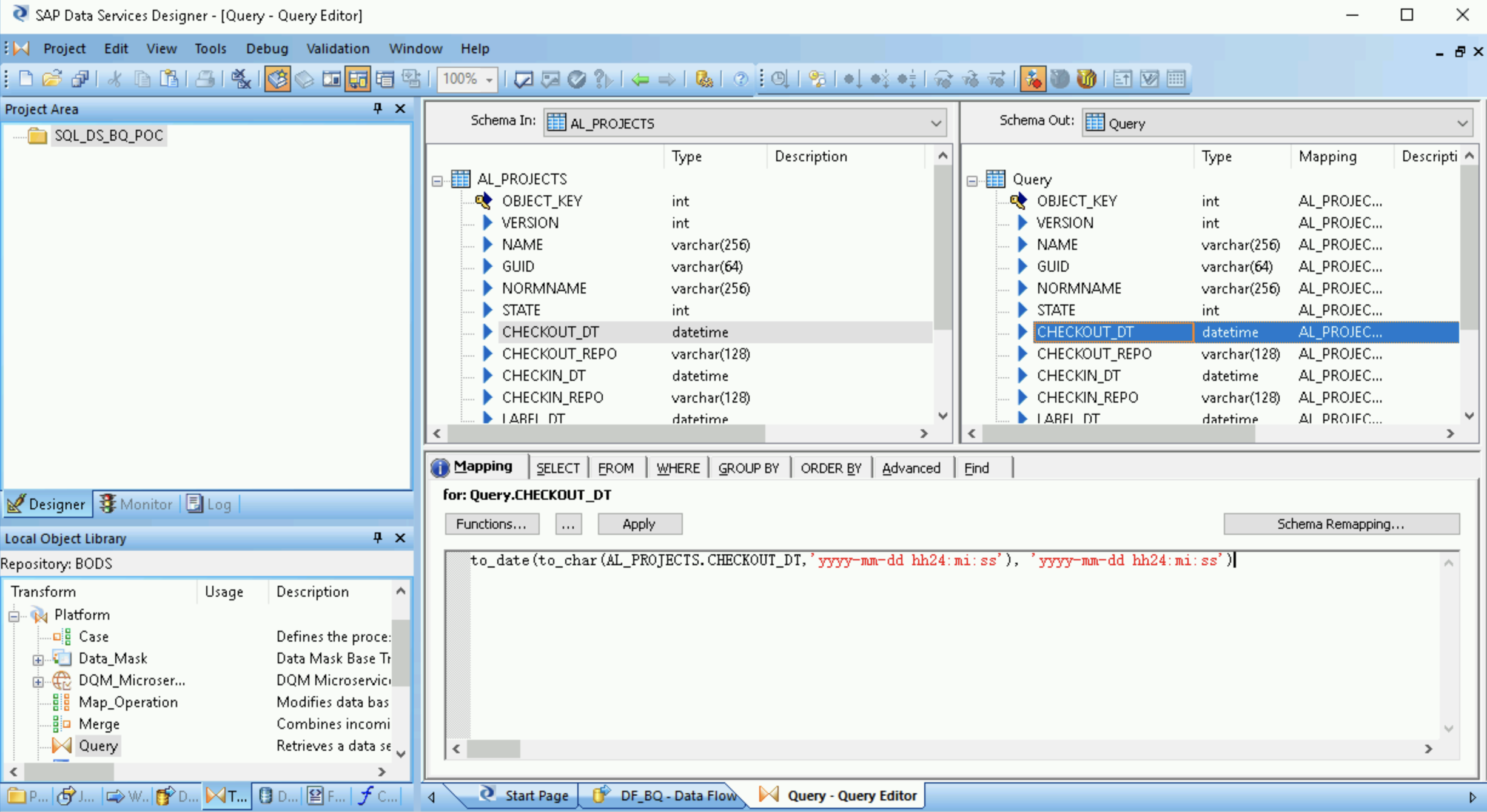
- Klicken Sie doppelt auf die Transformation Query.
Wählen Sie alle Tabellenfelder unter Schema In auf der linken Seite aus und ziehen Sie sie zu Schema Out auf der rechten Seite.
- Wählen Sie rechts in der Liste Schema Out das Datetime-Feld aus.
- Wählen Sie unter den Schemalisten den Tab Mapping (Zuordnung) aus.
Ersetzen Sie den Feldnamen durch die folgende Funktion:
to_date(to_char(FIELDNAME,'yyyy-mm-dd hh24:mi:ss'), 'yyyy-mm-dd hh24:mi:ss')
Dabei ist FIELDNAME der Name des Feldes, das Sie ausgewählt haben.
Klicken Sie in der Symbolleiste der Anwendung auf das Zurück-Symbol, um zum Dataflow Editor zurückzukehren.
Ziehen Sie eine Transformation vom Typ XML_Map aus dem Knoten Platform auf dem Tab Transforms der Objektbibliothek zum Datenfluss.
Wählen Sie im Dialogfeld den Modus Batch aus.
Verbinden Sie die Transformation Query mit der Transformation XML_Map.
Schemadatei erstellen
Mit diesen Schritten wird eine Schemadatei erstellt, die die Struktur der Quelltabellen widerspiegelt. Die Schemadatei wird später benötigt, um eine BigQuery-Tabelle zu erstellen.
Das Schema sorgt dafür, dass der BigQuery-Loader-Datenfluss die neue BigQuery-Tabelle erfolgreich füllt.
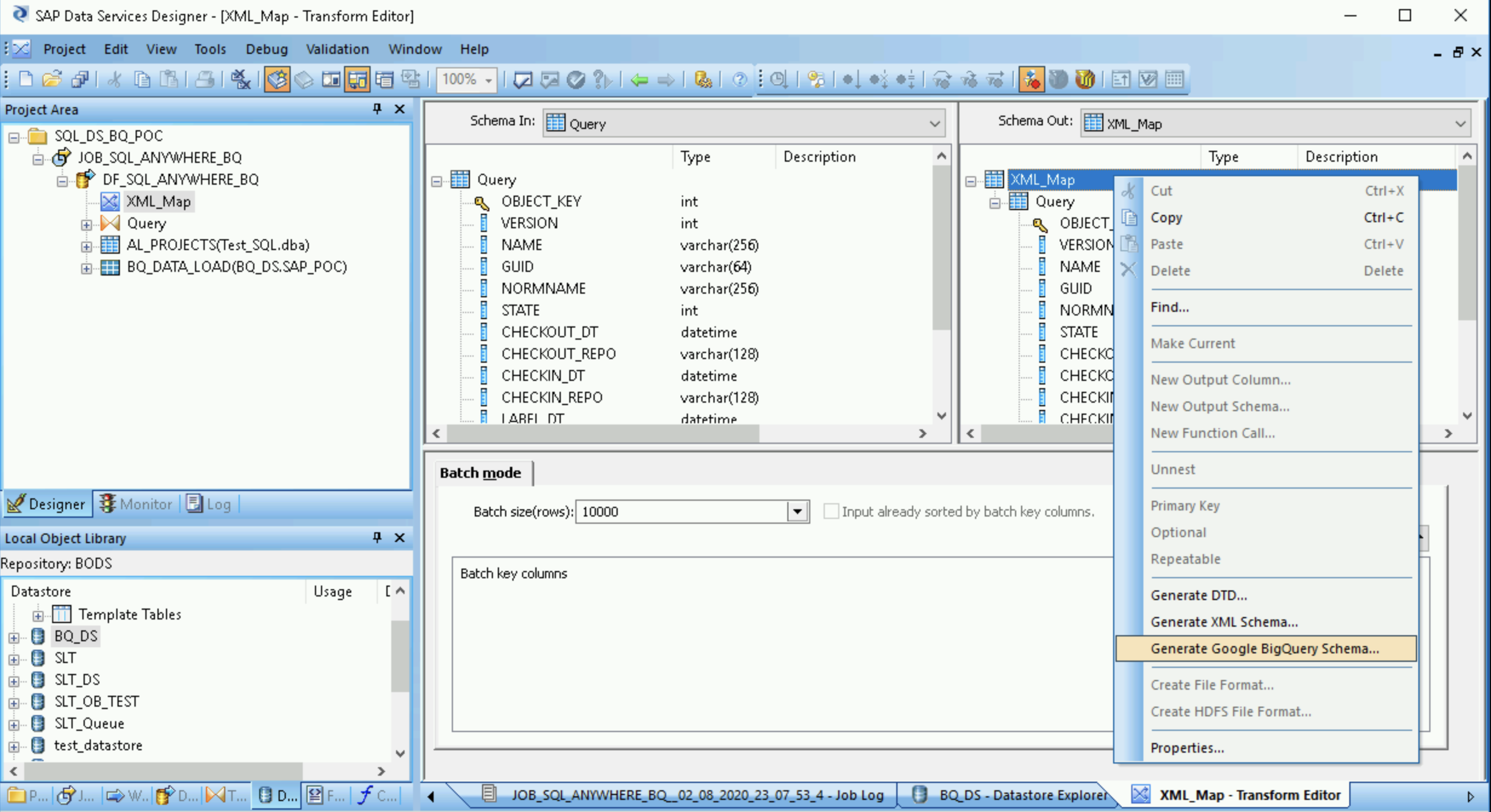
- Öffnen Sie die Transformation XML_Map und legen Sie die Abschnitte für das Eingabe- und Ausgabeschema anhand der Daten fest, die Sie in die BigQuery-Tabelle aufnehmen.
- Klicken Sie mit der rechten Maustaste auf den Knoten XML_Map (XML-Zuordnung) in der Spalte Schema Out (Ausgabeschema) und wählen Sie Generate Google BigQuery Schema (Google BigQuery-Schema generieren) aus dem Drop-down-Menü aus.
- Geben Sie einen Namen und einen Speicherort für das Schema ein.
- Klicken Sie auf Speichern.
SAP Data Services generiert eine Schemadatei mit der .json-Dateierweiterung.
BigQuery-Tabelle erstellen
Sie müssen eine Tabelle in Ihrem BigQuery-Dataset inGoogle Cloud für das Laden der Daten erstellen. Sie verwenden das in SAP Data Services erstellte Schema, um die Tabelle zu erstellen.
Die Tabelle beruht auf dem Schema, das Sie im vorherigen Schritt generiert haben.
- Greifen Sie in der Google Cloud Console auf Ihr Google Cloud Projekt zu.
- Wählen Sie BigQuery aus.
- Klicken Sie auf das jeweilige Dataset.
- Klicken Sie auf Tabelle erstellen.
- Geben Sie einen Tabellennamen ein, z. B.
BQ_DATA_LOAD - Schalten Sie unter Schema die Einstellung um, sodass der Modus Als Text bearbeiten aktiviert wird.
- Legen Sie das Schema der neuen Tabelle in BigQuery fest. Kopieren Sie hierzu den Inhalt der Schemadatei, die Sie unter Schemadatei erstellen angelegt haben, und fügen Sie ihn ein.
- Klicken Sie auf Tabelle erstellen.
BigQuery-Tabelle importieren
Mit diesen Schritten wird die BigQuery-Tabelle, die Sie im vorherigen Schritt erstellt haben, importiert und in SAP Data Services zur Verfügung gestellt.
- Klicken Sie in der SAP Data Services Designer-Objektbibliothek mit der rechten Maustaste auf den BigQuery-Datenspeicher und wählen Sie die Option Refresh Object Library aus. Dadurch wird die Liste der Datenquellentabellen aktualisiert, die Sie in Ihrem Datafluss verwenden können.
- Öffnen Sie den BigQuery-Datenspeicher.
- Klicken Sie im oberen Bereich des rechten Steuerfeldes auf External Metadata. Die von Ihnen erstellte BigQuery-Tabelle wird angezeigt.
- Klicken Sie mit der rechten Maustaste auf den jeweiligen BigQuery-Tabellennamen und wählen Sie Import aus.
- Der Import der ausgewählten Tabelle in SAP Data Services wird gestartet. Die Tabelle ist jetzt in der Objektbibliothek unter dem Knoten des Zieldatenspeichers verfügbar.
Datenfluss importieren und mit den Zielobjekten des Datenspeichers verbinden
- Ziehen Sie die importierte BigQuery-Tabelle aus dem Datenspeicher in der Objektbibliothek zum Datenfluss. Der Name des Datenspeichers in dieser Anleitung ist
BQ_DS. Der Name Ihres Datenspeichers kann abweichen. Verbinden Sie die Transformation XML_Map mit der importierten BigQuery-Tabelle.
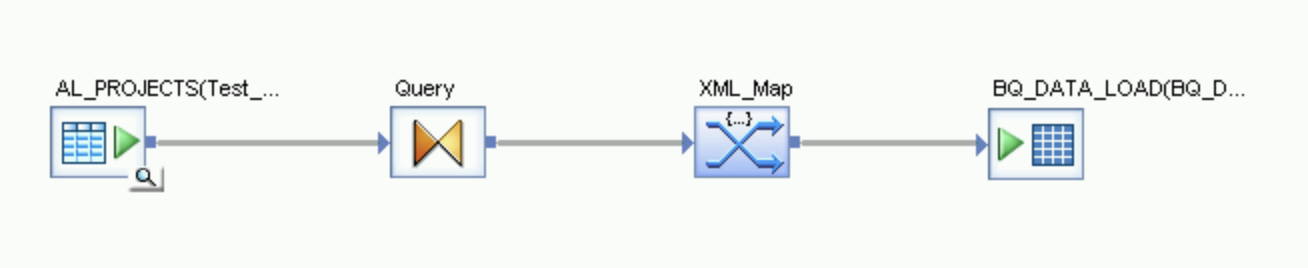
Öffnen Sie die Transformation XML_Map und legen Sie die Abschnitte für die Ein- und Ausgabeschemas anhand der Daten fest, die Sie in die BigQuery-Tabelle aufnehmen.
Klicken Sie im Arbeitsbereich doppelt auf die BigQuery-Tabelle, um sie zu öffnen und die Optionen auf dem Tab Target (Ziel) wie in der folgenden Tabelle angegeben festzulegen:
Option Beschreibung Make Port (Als Port verwenden) Geben Sie No an. Dies ist die Standardeinstellung.
Wenn Sie Yes angeben, wird eine Quell- oder Zieldatei als eingebetteter Datenflussport verwendet.Mode Geben Sie für den anfänglichen Ladevorgang Truncate an, um eventuell vorhandene Datensätze in der BigQuery-Tabelle durch die von SAP Data Services geladenen Daten zu ersetzen. Truncate ist die Standardeinstellung. Number of loaders Geben Sie eine positive Ganzzahl ein, um die Anzahl der Loader (Threads) festzulegen, die für die Verarbeitung verwendet werden soll. Der Standardwert ist 4.
Jeder Loader startet einen fortsetzbaren Ladejob in BigQuery. Sie können eine beliebige Anzahl von Loadern angeben.
Hilfe beim Bestimmen einer angemessenen Anzahl von Loadern erhalten Sie unter anderem in folgenden SAP-Dokumentationen:
Maximum failed records per loader Geben Sie 0 oder eine positive Ganzzahl an, um die maximale Anzahl von Datensätzen festzulegen, die pro Ladejob fehlschlagen kann, bevor BigQuery das Laden der Datensätze beendet. Die Standardeinstellung ist null (0). Klicken Sie in der oberen Symbolleiste auf das Symbol "Validate".
Klicken Sie in der Anwendungssymbolleiste auf das Symbol "Back", um zum Dataflow Editor zurückzukehren.
Daten in BigQuery laden
Mit diesen Schritten wird der Replikationsjob gestartet und der Datenfluss in SAP Data Services ausgeführt, um die Daten aus dem Quellsystem in BigQuery zu laden.
Wenn Sie den Ladevorgang ausführen, werden alle Daten im Quell-Dataset in die BigQuery-Zieltabelle repliziert, die mit dem Ladedatenfluss verbunden ist. Alle Daten in der Zieltabelle werden überschrieben.
- Öffnen Sie in SAP Data Services Designer den "Project Explorer" (Projektexplorer).
- Klicken Sie mit der rechten Maustaste auf den Namen des Replikationsjobs und wählen Sie Execute aus.
- Klicken Sie auf OK.
- Der Ladevorgang wird gestartet und im SAP Data Services-Log werden jetzt Debug-Meldungen angezeigt. Die Daten werden in die Tabelle geladen, die Sie in BigQuery für anfängliche Ladevorgänge erstellt haben. Der Name der Ladetabelle in dieser Anleitung lautet
BQ_DATA_LOAD. Der Name Ihrer Tabelle kann abweichen. - Wenn Sie wissen möchten, ob der Ladevorgang abgeschlossen ist, rufen Sie die Google Cloud Console auf und öffnen das BigQuery-Dataset, das die Tabelle enthält. Wenn die Daten noch geladen werden, sehen Sie Wird geladen neben dem Tabellennamen.
Nachdem die Daten geladen wurden, können sie in BigQuery verarbeitet werden.
Ladevorgänge planen
Mit der SAP Data Services Management Console können Sie die Ausführung eines Ladejobs in regelmäßigen Abständen planen.
- Öffnen Sie die Anwendung SAP Data Services Management Console.
- Klicken Sie auf Administrator.
- Maximieren Sie in der Menüstruktur auf der linken Seite den Knoten Batch.
- Klicken Sie auf den Namen Ihres SAP Data Services-Repositorys.
- Klicken Sie auf den Tab Batch Job Configuration (Batchjobkonfiguration).
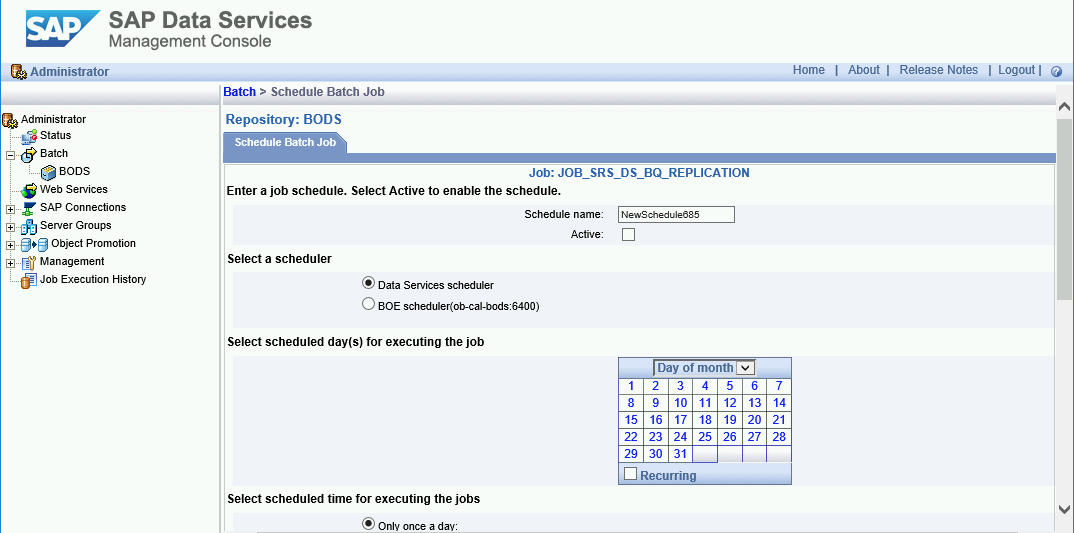
- Klicken Sie auf Add Schedule (Zeitplan hinzufügen).
- Geben Sie im Feld Schedule name einen Namen ein.
- Aktivieren Sie Active (Aktiv).
- Geben Sie im Abschnitt Select scheduled time for executing the jobs die Häufigkeit für die Ausführung Ihrer Deltaladevorgänge an.
- Wichtig: Google Cloud begrenzt die Anzahl der BigQuery-Ladejobs, die Sie pro Tag ausführen können. Achten Sie darauf, dass Ihr Zeitplan dieses Limit nicht überschreitet, da es nicht erhöht werden kann. Weitere Informationen zum Limit für BigQuery-Ladejobs finden Sie unter Kontingente und Limits in der BigQuery-Dokumentation.
Klicken Sie auf Apply (Übernehmen).
Weitere Informationen
Replizierte Daten in BigQuery abfragen und analysieren Mehr zu Abfragen finden Sie unter:
- BigQuery-Daten abfragen – Übersicht in der BigQuery-Dokumentation.
Einige Ideen zum Einrichten einer Lösung, um Daten mit SAP Landscape Transformation Replication Server und SAP Data Services aus SAP-Anwendungen nahezu in Echtzeit in BigQuery zu replizieren, finden Sie hier:
Weitere Referenzarchitekturen, Diagramme und Best Practices finden Sie im Cloud-Architekturcenter.