このチュートリアルでは、Cloud Functions を使用して、Cloud Storage バケットから BigQuery に新しいオブジェクトをストリーミングする方法について説明します。Cloud Functions は、Google Cloud イベント ドリブンのサーバーレス コンピューティング プラットフォームで、サーバーをプロビジョニング、管理、更新、パッチすることなく、自動スケーリング、高可用性、フォールト トレランスを提供します。Cloud Functions 経由でデータをストリーミングすれば、他の Google Cloud サービスに接続して拡張できますが、課金されるのはアプリの実行中のみで済みます。
この記事は、Cloud Storage に追加されたファイルをほぼリアルタイムで分析する必要があるデータ アナリスト、デベロッパー、オペレーターを対象とします。また、読者が Linux、Cloud Storage、BigQuery に精通していることを前提とします。
アーキテクチャ
次のアーキテクチャ図は、このチュートリアルのストリーミング パイプラインのすべてのコンポーネントとフロー全体を示しています。このパイプラインでは JSON ファイルが Cloud Storage にアップロードされることが想定されていますが、他のファイル形式をサポートするには、多少のコード変更が必要になります。この記事では、他のファイル形式の取り込みについては説明しません。

上の図では、パイプラインが以下のステップで構成されています。
- JSON ファイルが
FILES_SOURCECloud Storage バケットにアップロードされます。 - このイベントが Cloud Functions の関数
streamingをトリガーします。 - データが解析され、BigQuery に挿入されます。
- 取り込みステータスが Firestore と Cloud Logging に記録されます。
- 次の Pub/Sub トピックのいずれかでメッセージが発行されます。
streaming_success_topicstreaming_error_topic
- 結果に応じて、Cloud Functions が JSON ファイルを
FILES_SOURCEバケットから次のバケットのいずれかに移動します。FILES_ERRORFILES_SUCCESS
目標
- JSON ファイルを保存するための Cloud Storage バケットを作成します。
- データのストリーミング先となる BigQuery データセットとテーブルを作成します。
- ファイルがバケットに追加されるたびにトリガーされるように Cloud Functions の関数を構成します。
- Pub/Sub トピックを設定します。
- 関数の出力を処理するように追加の関数を構成します。
- ストリーミング パイプラインをテストします。
- 予期せぬ動作を警告するように Cloud Monitoring を構成します。
費用
このドキュメントでは、Google Cloud の次の課金対象のコンポーネントを使用します。
- Cloud Storage
- Cloud Functions
- Firestore
- BigQuery
- Logging
- Monitoring
- Container Registry
- Cloud Build
料金計算ツールを使うと、予想使用量に基づいて費用の見積もりを生成できます。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Functions and Cloud Build APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Functions and Cloud Build APIs.
- Google Cloud Console で [Monitoring] に移動します。
このドキュメントに記載されているタスクの完了後、作成したリソースを削除すると、それ以上の請求は発生しません。詳細については、クリーンアップをご覧ください。
環境設定
このチュートリアルでは、Cloud Shell を使用してコマンドを入力します。Cloud Shell では Google Cloud コンソールのコマンドラインにアクセスできます。また、Google Cloud で開発を行うために必要な Google Cloud CLI やその他のツールも含まれています。Cloud Shell は、Google Cloud コンソールの下部にウィンドウとして表示されます。初期化が完了するまでに数分かかることもありますが、ウィンドウはすぐに表示されます。
Cloud Shell を使用して環境をセットアップし、このチュートリアルで使用する git リポジトリのクローンを作成するには、以下の手順を実行します。
Google Cloud コンソールで Cloud Shell を開きます。
作成したばかりのプロジェクトで作業していることを確認してください。
[YOUR_PROJECT_ID]を新しく作成した Google Cloud プロジェクトに置き換えます。gcloud config set project [YOUR_PROJECT_ID]デフォルトのコンピューティング ゾーンを設定します。このチュートリアルでは、
us-east1に設定します。本番環境にデプロイする場合は、選択したリージョンにデプロイします。REGION=us-east1このチュートリアルで使用される関数を含むリポジトリのクローンを作成します。
git clone https://github.com/GoogleCloudPlatform/solutions-gcs-bq-streaming-functions-python cd solutions-gcs-bq-streaming-functions-python
ストリーミング ソースシンクとストリーミング宛先シンクの作成
コンテンツを BigQuery にストリーミングするには、BigQuery に FILES_SOURCE Cloud Storage バケットと宛先テーブルが必要です。
Cloud Storage バケットを作成する
このチュートリアルのストリーミング パイプラインのソースになる Cloud Storage バケットを作成します。このバケットの主な目的は、BigQuery にストリーミングされる JSON ファイルを一時的に保存することです。
FILES_SOURCECloud Storage バケットを作成します。ここで、FILES_SOURCEは一意の名前を持つ環境変数としてセットアップされます。FILES_SOURCE=${DEVSHELL_PROJECT_ID}-files-source-$(date +%s) gsutil mb -c regional -l ${REGION} gs://${FILES_SOURCE}
BigQuery テーブルを作成する
このセクションでは、ファイルのコンテンツ宛先として使用される BigQuery テーブルを作成します。BigQuery では、テーブルにデータを読み込むときや新しいテーブルを作成するときにテーブルのスキーマを指定できます。このセクションでは、テーブルを作成すると同時にそのスキーマを指定します。
BigQuery データセットとテーブルを作成します。
schema.jsonファイルで定義されたスキーマは、FILES_SOURCEバケットから取得されるファイルのスキーマと一致する必要があります。bq mk mydataset bq mk mydataset.mytable schema.jsonテーブルが作成されたことを確認します。
bq ls --format=pretty mydataset次のように出力されます。
+---------+-------+--------+-------------------+ | tableId | Type | Labels | Time Partitioning | +---------+-------+--------+-------------------+ | mytable | TABLE | | | +---------+-------+--------+-------------------+
BigQuery へのデータのストリーミング
ソースシンクと宛先シンクを作成したので、次は Cloud Storage から BigQuery にデータをストリーミングするための Cloud Function を作成します。
Cloud Functions の関数 streaming を設定する
streaming 関数は、FILES_SOURCE バケットに追加された新しいファイルをリッスンしてから、次の処理を行うプロセスをトリガーします。
- ファイルを解析して検証します。
- 重複をチェックします。
- ファイルのコンテンツを BigQuery に挿入します。
- Firestore と Logging に取り込みステータスをログに記録します。
- Pub/Sub のエラートピックまたは成功トピックにメッセージをパブリッシュします。
関数をデプロイするには:
関数をデプロイする際にステージングするための Cloud Storage バケットを作成します。
FUNCTIONS_BUCKETは一意の名前を持つ環境変数として設定されます。FUNCTIONS_BUCKET=${DEVSHELL_PROJECT_ID}-functions-$(date +%s) gsutil mb -c regional -l ${REGION} gs://${FUNCTIONS_BUCKET}streaming関数をデプロイします。実装コードは./functions/streamingフォルダ内にあります。完了するまで数分かかる場合があります。gcloud functions deploy streaming --region=${REGION} \ --source=./functions/streaming --runtime=python37 \ --stage-bucket=${FUNCTIONS_BUCKET} \ --trigger-bucket=${FILES_SOURCE}このコードは
streamingという名前の Python で書かれた Cloud Functions の関数をデプロイします。この関数は、FILES_SOURCEバケットにファイルが追加されるたびにトリガーされます。関数がデプロイされたことを確認します。
gcloud functions describe streaming --region=${REGION} \ --format="table[box](entryPoint, status, eventTrigger.eventType)"次のように出力されます。
┌────────────────┬────────┬────────────────────────────────┐ │ ENTRY_POINT │ STATUS │ EVENT_TYPE │ ├────────────────┼────────┼────────────────────────────────┤ │ streaming │ ACTIVE │ google.storage.object.finalize │ └────────────────┴────────┴────────────────────────────────┘
エラーパスを処理する
streaming_error_topicという名前の Pub/Sub トピックをプロビジョニングします。STREAMING_ERROR_TOPIC=streaming_error_topic gcloud pubsub topics create ${STREAMING_ERROR_TOPIC}成功パスを処理する
streaming_success_topicという名前の Pub/Sub トピックをプロビジョニングします。STREAMING_SUCCESS_TOPIC=streaming_success_topic gcloud pubsub topics create ${STREAMING_SUCCESS_TOPIC}
Firestore データベースを設定する
データが BigQuery にストリーミングされる間に各ファイルの取り込みで何が起きているのかを理解することが重要です。たとえば、適切にインポートされなかったファイルがあるとします。このケースでは、問題の根本原因を把握し、それを修正して、パイプラインの最後で破損したデータや不正確なレポートが生成されるのを防ぐ必要があります。前のセクションでデプロイされた streaming 関数は Firestore ドキュメントにファイル取り込みステータスを保存するため、最近のエラーをクエリして問題のトラブルシューティングを行うことができます。
Firestore インスタンスを作成するには、次の手順を行います。
Google Cloud Console で [Firestore] に移動します。
[Cloud Firestore モードの選択] ウィンドウで、[ネイティブ モードを選択] をクリックします。
[ロケーションを選択] リストで、[nam5(United States)] を選択してから、[データベースを作成] をクリックします。Firestore の初期化が完了するまで待機します。通常は数分かかります。
ストリーミング エラーを処理する
エラーファイルを処理するためのパスをプロビジョニングするには、streaming_error_topic に発行されたメッセージをリッスンする別の Cloud Functions の関数をデプロイします。本番環境でこのようなエラーをどのように処理するかは、ビジネスニーズによって異なります。このチュートリアルでは、トラブルシューティングを容易にするために、問題のあるファイルを別の Cloud Storage バケットに移動します。
問題のあるファイルを保存するための Cloud Storage バケットを作成します。
FILES_ERRORは、エラーファイルを格納するバケットの一意の名前を持つ環境変数としてセットアップします。FILES_ERROR=${DEVSHELL_PROJECT_ID}-files-error-$(date +%s) gsutil mb -c regional -l ${REGION} gs://${FILES_ERROR}エラーを処理する
streaming_error関数をデプロイします。これには数分かかる場合があります。gcloud functions deploy streaming_error --region=${REGION} \ --source=./functions/move_file \ --entry-point=move_file --runtime=python37 \ --stage-bucket=${FUNCTIONS_BUCKET} \ --trigger-topic=${STREAMING_ERROR_TOPIC} \ --set-env-vars SOURCE_BUCKET=${FILES_SOURCE},DESTINATION_BUCKET=${FILES_ERROR}このコマンドは、
streaming関数をデプロイするコマンドに似ています。主な違いは、このコマンドでは、関数がトピックに発行されたメッセージによってトリガーされ、ファイルのコピー元のSOURCE_BUCKET変数とファイルのコピー先のDESTINATION_BUCKET変数の 2 つの環境変数を受け取る点です。streaming_error関数が作成されたことを確認します。gcloud functions describe streaming_error --region=${REGION} \ --format="table[box](entryPoint, status, eventTrigger.eventType)"次のように出力されます。
┌─────────────┬────────┬─────────────────────────────┐ │ ENTRY_POINT │ STATUS │ EVENT_TYPE │ ├─────────────┼────────┼─────────────────────────────┤ │ move_file │ ACTIVE │ google.pubsub.topic.publish │ └─────────────┴────────┴─────────────────────────────┘
成功したストリーミングを処理する
成功ファイルを処理するためのパスをプロビジョニングするには、3 つ目の Cloud Functions の関数をデプロイします。この関数は、streaming_success_topic に発行されるメッセージをリッスンします。このチュートリアルでは、正常に取り込まれたファイルが Coldline Cloud Storage バケットにアーカイブされます。
Coldline Cloud Storage バケットを作成します。
FILES_SUCCESSは、成功ファイルを格納するバケットの一意の名前を持つ環境変数としてセットアップします。FILES_SUCCESS=${DEVSHELL_PROJECT_ID}-files-success-$(date +%s) gsutil mb -c coldline -l ${REGION} gs://${FILES_SUCCESS}成功を処理する
streaming_success関数をデプロイします。これには数分かかる場合があります。gcloud functions deploy streaming_success --region=${REGION} \ --source=./functions/move_file \ --entry-point=move_file --runtime=python37 \ --stage-bucket=${FUNCTIONS_BUCKET} \ --trigger-topic=${STREAMING_SUCCESS_TOPIC} \ --set-env-vars SOURCE_BUCKET=${FILES_SOURCE},DESTINATION_BUCKET=${FILES_SUCCESS}関数が作成されたことを確認します。
gcloud functions describe streaming_success --region=${REGION} \ --format="table[box](entryPoint, status, eventTrigger.eventType)"次のように出力されます。
┌─────────────┬────────┬─────────────────────────────┐ │ ENTRY_POINT │ STATUS │ EVENT_TYPE │ ├─────────────┼────────┼─────────────────────────────┤ │ move_file │ ACTIVE │ google.pubsub.topic.publish │ └─────────────┴────────┴─────────────────────────────┘
ストリーミング パイプラインのテスト
これで、ストリーミング パイプラインの作成が完了しました。今度は、さまざまなパスをテストします。まず、新しいファイルの取り込みをテストしてから、重複ファイルの取り込みをテストし、最後に問題のあるファイルの取り込みをテストします。
新しいファイルを取り込む
新しいファイルの取り込みをテストするには、パイプライン全体を正常に通過する必要があるファイルをアップロードします。すべてが正しく動作していることを確認するには、すべてのストレージ部分(BigQuery、Firestore、Cloud Storage バケット)を確認する必要があります。
data.jsonファイルをFILES_SOURCEバケットにアップロードします。gsutil cp test_files/data.json gs://${FILES_SOURCE}出力:
Operation completed over 1 objects/312.0 B.
BigQuery でデータをクエリします。
bq query 'select first_name, last_name, dob from mydataset.mytable'このコマンドは
data.jsonファイルのコンテンツを出力します。+------------+-----------+------------+ | first_name | last_name | dob | +------------+-----------+------------+ | John | Doe | 1968-01-22 | +------------+-----------+------------+
Google Cloud Console で、[Firestore] ページに移動します。
/ > streaming_files > data.json ドキュメントに移動して、success: true フィールドが存在することを確認します。
streaming関数は、ファイルのステータスを streaming_files という名前のコレクションに格納し、ファイル名をドキュメント ID として使用します。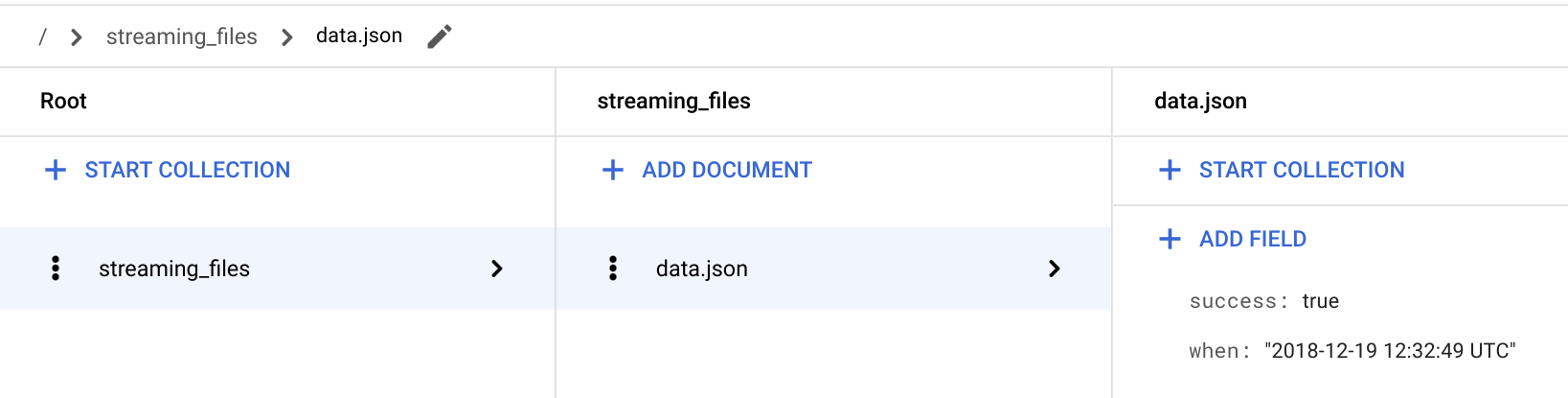
Cloud Shell に戻ります。
streaming_success関数を使用して、取り込まれたファイルがFILES_SOURCEバケットから削除されたことを確認します。gsutil ls -l gs://${FILES_SOURCE}/data.jsonファイルが
FILES_SOURCEバケットに存在しなくなったため、出力はCommandExceptionになります。取り込まれたファイルが
FILES_SUCCESSバケット内に存在することを確認します。gsutil ls -l gs://${FILES_SUCCESS}/data.json次のように出力されます。
TOTAL: 1 objects, 312 bytes.
すでに処理されたファイルを取り込む
ファイル名は Firestore 内のドキュメント ID として使用されます。これにより、streaming 関数は、特定のファイルが処理されたかどうかを簡単にクエリできます。ファイルがすでに正常に取り込まれている場合は、そのファイルを新たに追加しようとしても、BigQuery で情報が重複して不正確なレポートが生成されることになるため、その操作は無視されます。
このセクションでは、重複したファイルが FILES_SOURCE バケットにアップロードされたときに、パイプラインが想定どおりに機能することを確認します。
同じ
data.jsonファイルを再度FILES_SOURCEバケットにアップロードします。gsutil cp test_files/data.json gs://${FILES_SOURCE}次のように出力されます。
Operation completed over 1 objects/312.0 B.
BigQuery をクエリすると、以前と同じ結果が返されます。これは、パイプラインがファイルを処理したものの、以前取り込まれているため、そのコンテンツが BigQuery に挿入されなかったことを意味します。
bq query 'select first_name, last_name, dob from mydataset.mytable'次のように出力されます。
+------------+-----------+------------+ | first_name | last_name | dob | +------------+-----------+------------+ | John | Doe | 1968-01-22 | +------------+-----------+------------+
Google Cloud コンソールで [Firestore] ページに移動します。
/ > streaming_files > data.json ドキュメントに移動して、新しい
**duplication_attempts**フィールドが追加されていることを確認します。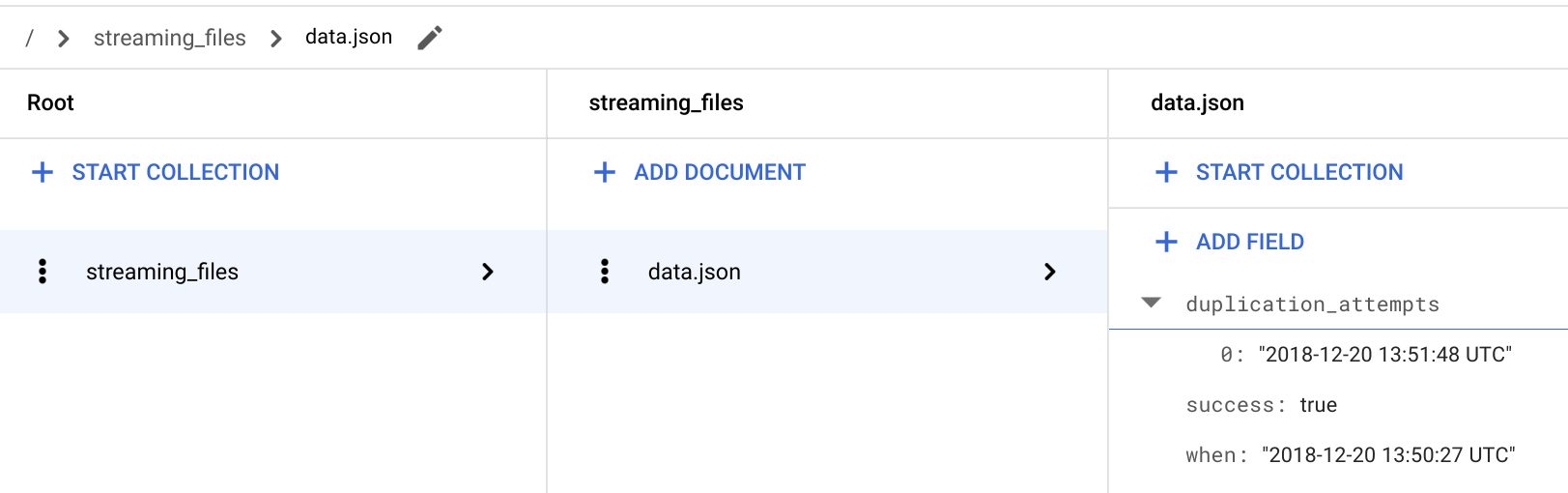
以前に正常に処理されたファイルと同じ名前のファイルが
FILES_SOURCEバケットに追加されるたびに、ファイルのコンテンツは無視され、新しい重複の試行が Firestore の**duplication_attempts**フィールドに追加されます。Cloud Shell に戻ります。
重複したファイルがまだ
FILES_SOURCEバケット内に存在することを確認します。gsutil ls -l gs://${FILES_SOURCE}/data.json次のように出力されます。
TOTAL: 1 objects, 312 bytes.
重複シナリオでは、
streaming関数が、予期せぬ動作を Logging に記録して、取り込みを無視し、後で分析するためにFILES_SOURCEバケットにファイルを残したままにします。
エラーのあるファイルを取り込む
ストリーミング パイプラインが機能しており、重複が BigQuery に取り込まれていないことを確認したので、今度はエラーパスをチェックします。
data_error.jsonをFILES_SOURCEバケットにアップロードします。gsutil cp test_files/data_error.json gs://${FILES_SOURCE}次のように出力されます。
Operation completed over 1 objects/311.0 B.
BigQuery をクエリすると、以前と同じ結果が返されます。これは、パイプラインがファイルを処理したものの、想定されたスキーマに準拠していないため、コンテンツを BigQuery に挿入しなかったことを意味します。
bq query 'select first_name, last_name, dob from mydataset.mytable'次のように出力されます。
+------------+-----------+------------+ | first_name | last_name | dob | +------------+-----------+------------+ | John | Doe | 1968-01-22 | +------------+-----------+------------+
Google Cloud Console で、[Firestore] ページに移動します。
/ > streaming_files > data_error.json ドキュメントに移動して、success: false フィールドが追加されていることを確認します。
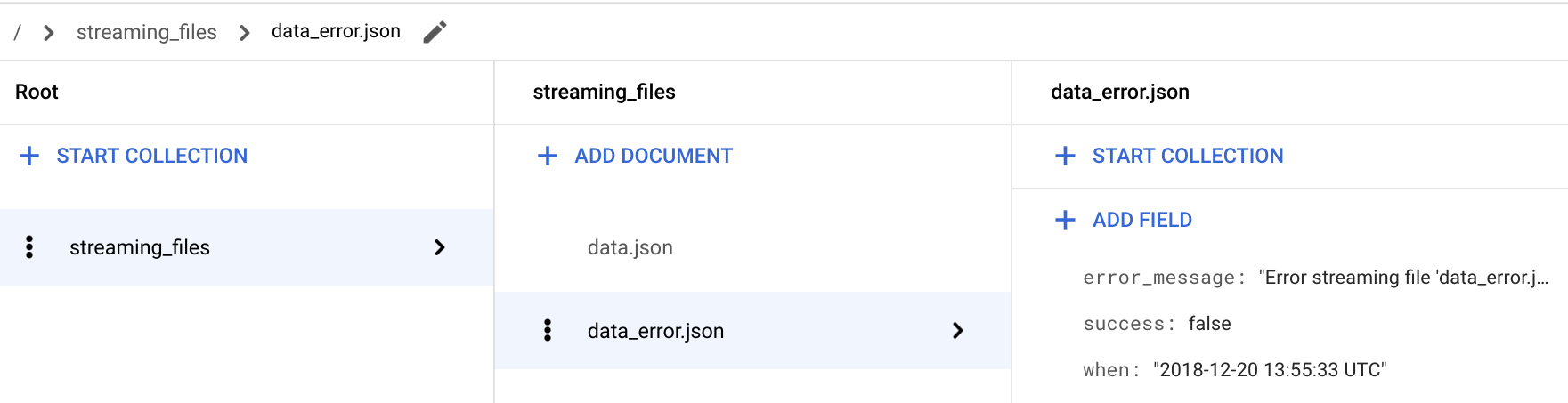
エラーのあるファイルの場合は、
streaming関数がerror_messageフィールドも格納します。このフィールドは、ファイルが取り込まれなかった理由に関する詳細情報を提供します。Cloud Shell に戻ります。
streaming_error関数によってファイルがFILES_SOURCEバケットから削除されたことを確認します。gsutil ls -l gs://${FILES_SOURCE}/data_error.jsonファイルが
FILES_SOURCEバケットに存在しなくなったため、出力はCommandExceptionになります。ファイルが想定どおり
FILES_ERRORバケット内に存在することを確認します。gsutil ls -l gs://${FILES_ERROR}/data_error.json次のように出力されます。
TOTAL: 1 objects, 311 bytes.
データの取り込み問題を見つけて修正する
Firestore の streaming_files コレクションに対してクエリを実行すると、問題をすばやく診断して修正できます。このセクションでは、Firestore 用の標準 Python API を使用して、すべてのエラーファイルをフィルタ処理します。
ご使用の環境でクエリの結果を確認するには、次の手順を実施します。
firestoreフォルダで仮想環境を作成します。pip install virtualenv virtualenv firestore source firestore/bin/activate仮想環境に Cloud Firestore モジュールをインストールします。
pip install google-cloud-firestore既存のパイプライン問題を可視化します。
python firestore/show_streaming_errors.pyshow_streaming_errors.pyファイルには、Firestore クエリと、結果をループして出力を書式設定するためのその他のひな形が含まれています。上記のコマンドを実行すると、出力は次のようになります。+-----------------+-------------------------+----------------------------------------------------------------------------------+ | File Name | When | Error Message | +-----------------+-------------------------+----------------------------------------------------------------------------------+ | data_error.json | 2019-01-22 11:31:58 UTC | Error streaming file 'data_error.json'. Cause: Traceback (most recent call las.. | +-----------------+-------------------------+----------------------------------------------------------------------------------+
分析が完了したら、仮想環境を無効にします。
deactivate問題のあるファイルを見つけて修正したら、それらを同じファイル名で再度
FILES_SOURCEバケットにアップロードします。このプロセスにより、修正されたファイルがストリーミング パイプライン全体を通過し、そのコンテンツが BigQuery に挿入されます。
予期せぬ動作を警告する
本番環境では、予期せぬ動作の発生をモニタリングして警告することが重要です。数ある Logging 機能の 1 つがカスタム指標です。カスタム指標を使用すると、指標が指定された基準を満たしたときに自分自身や所属するチームに通知するアラート ポリシーを作成できます。
このセクションでは、ファイルの取り込みに失敗したときにメール通知アラートを送信するように Monitoring を構成します。失敗した取り込みを識別するために、次の構成でデフォルトの Python logging.error(..) メッセージを使用します。
Google Cloud コンソールで、[ログベースの指標] ページに移動します。
[指標を作成] をクリックします。
[フィルタ] リストで、[高度なフィルタに変換] を選択します。
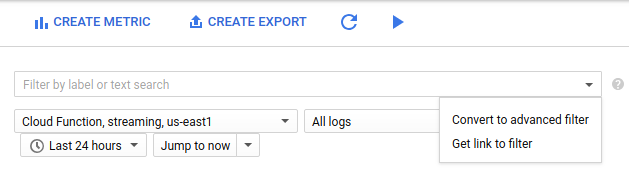
高度なフィルタで、次の構成を貼り付けます。
resource.type="cloud_function" resource.labels.function_name="streaming" resource.labels.region="us-east1" "Error streaming file "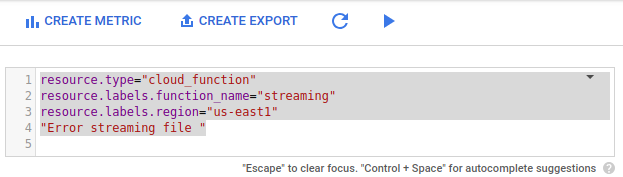
[指標エディタ] で、次のフィールドに値を入力して、[指標を作成] をクリックします。
- [名前] フィールドに「
streaming-error」と入力します。 - [ラベル] セクションで、[名前] フィールドに「
payload_error」と入力します。 - [ラベルのデータ型] リストで、[文字列] を選択します。
- [フィールド名] リストで、[textPayload] を選択します。
- [抽出の正規表現] フィールドに「
(Error streaming file '.*'.)」と入力します。 [タイプ] リストで、[カウンタ] を選択します。
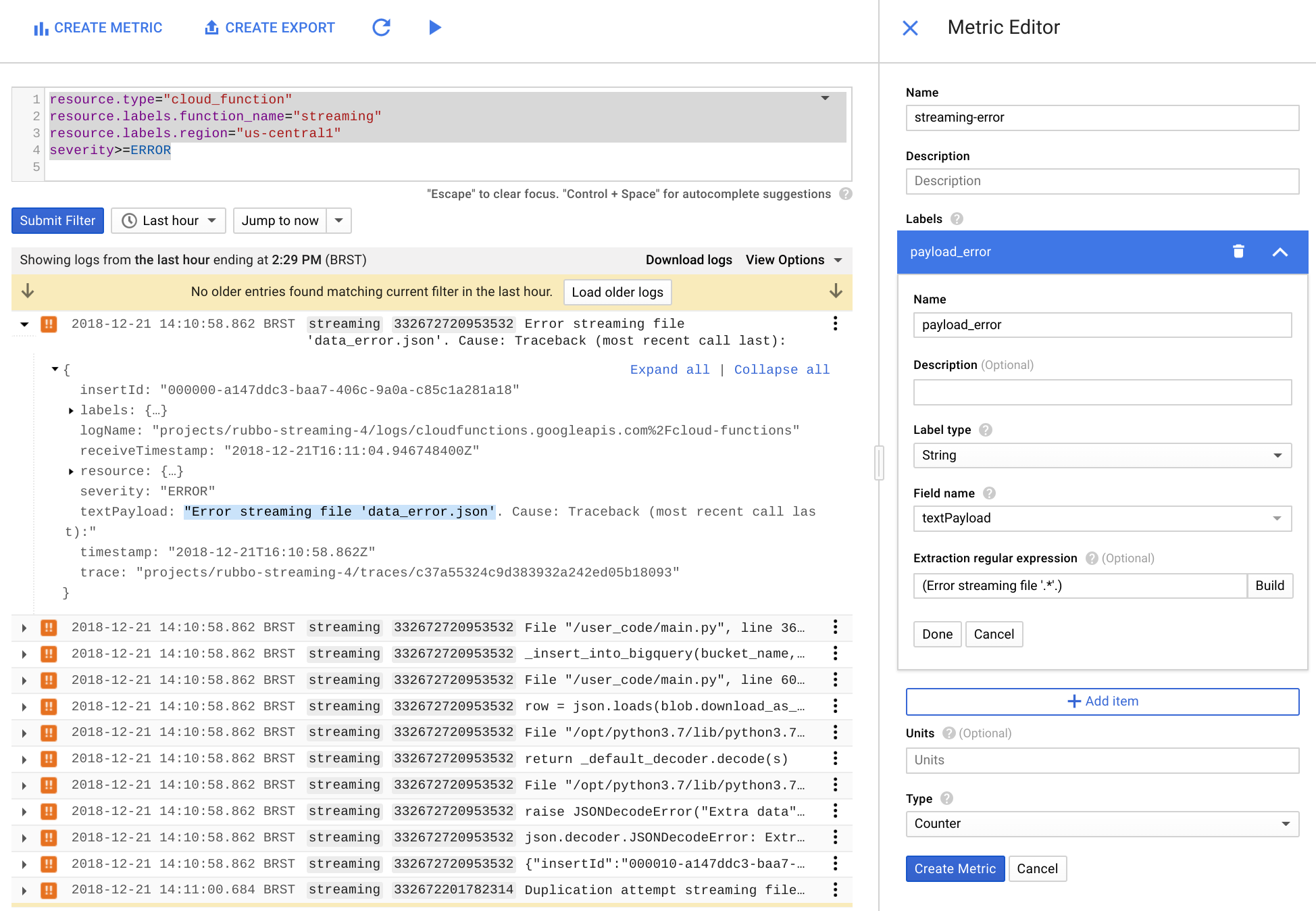
- [名前] フィールドに「
Cloud Console で、[Monitoring] に移動するか、次のボタンを使用します。
Monitoring のナビゲーション パネルで、notifications(アラート)を選択し、[Create Policy] を選択します。
[Name this policy] フィールドに「
streaming-error-alert」と入力します。[Add Condition] をクリックします。
- [Title] フィールドに「
streaming-error-condition」と入力します。 - [Metric] フィールドに「
logging/user/streaming-error」と入力します。 - [Condition trigger If] リストで、[Any time series violates] を選択します。
- [Condition] リストで、[is above] を選択します。
- [Threshold] フィールドに「
0」と入力します。 - [For] リストで、[1 minute] を選択します。
- [Title] フィールドに「
[Notification Channel Type] リストで、[Email] を選択して、メールアドレスを入力してから、[Add Notification Channel] をクリックします。
(省略可)[Documentation] をクリックして、通知メッセージに追加する情報を入力します。
[Save] をクリックします。
アラート ポリシーを保存すると、Monitoring が streaming 関数のエラーログを 1 分間隔で監視して、ストリーミング エラーが発生するたびにメール通知アラートを送信します。
クリーンアップ
このチュートリアルで使用したリソースについて、Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
プロジェクトの削除
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
次のステップ
- Google Cloud でサーバーレス ファンクションをトリガーするその他の方法を確認する。イベントとトリガーをご覧ください。
- このチュートリアルで定義されるアラート ポリシーを改良する方法を学習する。アラートページをご覧ください。
- グローバル スケールの NoSQL データベースの詳細について学習する。Firestore のドキュメントをご覧ください。
- BigQuery の割り当てと上限ページで、このソリューションを本番環境に実装する場合のストリーミング挿入制限について理解する。
- デプロイされた関数で処理できる最大サイズを確認する。Cloud Functions の割り当てと上限ページをご覧ください。
- Google Cloud に関するリファレンス アーキテクチャ、図、チュートリアル、ベスト プラクティスについて確認する。Cloud Architecture Center を確認します。