以下の手順は、SAP Landscape Transformation(LT)Replication Server と SAP Data Services(DS)を使用して、SAP S/4HANA や SAP Business Suite などの SAP アプリケーションから BigQuery にデータを複製するためのソリューションを設定する方法を示しています。
データ レプリケーションを使用して、SAP データをほぼリアルタイムでバックアップする、SAP システムのデータを BigQuery の他のシステムの消費者データと統合して機械学習から分析情報を導き出すなど、ペタバイト規模のデータ分析を行うことができます。
これらの手順は、SAP Basis、SAP LT Replication Server、SAP DS、 Google Cloudの構成に関する基本的な経験がある SAP システム管理者を対象としています。
アーキテクチャ

SAP LT Replication Server は、SAP NetWeaver Operational Data Provisioning Framework(ODP)のデータ プロバイダとして機能できます。SAP LT Replication Server は、接続された SAP システムからデータを受信し、SAP LT Replication Server システムの Operational Delta Queue(ODQ)の ODP フレームワークに保存します。したがって、SAP LT Replication Server 自体も SAP LT Replication Server 構成のターゲットとして機能します。ODP フレームワークは、ソースシステム テーブルに対応する ODP オブジェクトとしてデータを利用可能にします。
ODP フレームワークは、サブスクライバーと呼ばれるさまざまなターゲット SAP アプリケーションの抽出およびレプリケーション シナリオをサポートします。サブスクライバーは、さらに処理するためにデルタキューからデータを取得します。
サブスクライバーが ODP コンテキストを介してデータソースからデータを要求すると、すぐにデータが複製されます。複数のサブスクライバーが、同じ ODQ をソースとして使用できます。
SAP LT Replication Server は、SAP Data Services 4.2 SP1 以降の changed-data capture(CDC)サポートを活用します。これには、すべてのソーステーブルのリアルタイム データ プロビジョニングおよびデルタ機能が含まれます。
次の図は、システムを介するデータフローについて説明しています。
- SAP アプリケーションは、ソースシステムのデータを更新します。
- SAP LT Replication Server は、データの変更を複製し、Operational Delta Queue にデータを保存します。
- SAP DS は Operational Delta Queue のサブスクライバーであり、データの変更を定期的にキューにポーリングします。
- SAP DS は、デルタキューからデータを取得して BigQuery 形式との互換性を保持するようデータを変換し、BigQuery にデータを移動する読み込みジョブを開始します。
- データは、分析用に BigQuery で使用できます。
このシナリオでは、SAP ソースシステム、SAP LT Replication Server、SAP Data Services は、 Google Cloudの内外で実行できます。SAP の詳細については、Operational Data Provisioning in Real-time with SAP Landscape Transformation Replication Server をご覧ください。

コア ソリューション コンポーネント
SAP Landscape Transformation Replication Server と SAP Data Services を使用して SAP アプリケーションから BigQuery にデータを複製するには、次のコンポーネントが必要です。
| コンポーネント | 必要なバージョン | 注 |
|---|---|---|
| SAP アプリケーション サーバー スタック | R/3 4.6C 以降の ABAP ベースの SAP システム SAP_Basis(最小要件):
|
このガイドでは、アプリケーション サーバーとデータベース サーバーを別々のマシンで実行している場合でも、ソースシステムと総称されます。 適切な権限で RFC ユーザーを定義する 省略可: ロギング テーブル用に個別のテーブル スペースを定義する |
| Database(DB)システム | SAP Product Availability Matrix(PAM)でサポート対象として表示されている DB バージョン。PAM に表示されている SAP NetWeaver スタックの制限が適用されます。service.sap.com/pam をご覧ください。 | |
| オペレーティング システム(OS) | SAP PAM でサポート対象として表示されている OS バージョン。PAM に表示されている SAP NetWeaver スタックの制限が適用されます。service.sap.com/pam をご覧ください。 | |
| SAP Data Migration Server(DMIS) | DMIS:
|
|
| SAP Landscape Transformation Replication Server | SAP LT Replication Server 2.0 以降 | ソースシステムへの RFC 接続が必要です。 SAP LT Replication Server システムのサイズ設定は、ODQ に保存されるデータ量と予定された保持期間に大きく依存します。 |
| SAP Data Services | SAP Data Services 4.2 SP1 以降 | |
| BigQuery | なし |
費用
BigQuery は課金対象の Google Cloud コンポーネントです。
料金計算ツールを使うと、予想使用量に基づいて費用の見積もりを出すことができます。
前提条件
次の手順は、SAP アプリケーション サーバー、データベース サーバー、SAP LT Replication Server、SAP Data Services がインストール済みで、通常の操作が行えるよう構成されていることを前提としています。
BigQuery を使用するには、 Google Cloudプロジェクトが必要です。
Google Cloudで Google Cloud プロジェクトを設定する
BigQuery API を有効にする必要があります。Google Cloud プロジェクトをまだ作成していない場合は、作成してください。
Google Cloud プロジェクトを作成する
Google Cloud コンソールにアクセスして、設定ウィザードの指示に従って登録します。
左上隅にある Google Cloud ロゴの横のプルダウンをクリックして、[プロジェクトを作成] を選択します。
プロジェクトに名前を付けて、[作成] をクリックします。
プロジェクトが作成されたら(右上に通知が表示されます)、ページを更新します。
API の有効化
BigQuery API を有効にします。
Google Cloud API へのプライベート アクセスを有効にする
Google Cloudの外部で実行されている SAP ワークロードの場合は、 Google Cloudへのネットワーク接続を確立した後、 Google Cloud API へのプライベート アクセスを有効にする必要があります。
詳細については、サービスのプライベート Google アクセス オプションをご覧ください。
サービス アカウントを作成する
サービス アカウント(特にそのキーファイル)は、SAP DS を BigQuery に対して認証するために使用されます。キーファイルは、後でターゲット データストアを作成するときに使用します。
Google Cloud コンソールで、[サービス アカウント] ページに移動します。
Google Cloud プロジェクトを選択します。
[サービス アカウントを作成] をクリックします。
サービス アカウント名を入力します。
[作成して続行] をクリックします。
[ロールを選択] リストで、[BigQuery] > [BigQuery データ編集者] の順に選択します。
[別のロールを追加] をクリックします。
[ロールを選択] リストで、[BigQuery] > [BigQuery ジョブユーザー] の順に選択します。
[続行] をクリックします。
必要に応じて、他のユーザーにサービス アカウントへのアクセス権を付与します。
[完了] をクリックします。
Google Cloud コンソールの [サービス アカウント] ページで、作成したサービス アカウントのメールアドレスをクリックします。
サービス アカウント名で [キー] タブをクリックします。
[鍵を追加] プルダウン メニューをクリックして、[新しい鍵を作成] を選択します。
キーのタイプとして [JSON] を指定します。
[作成] をクリックします。
自動的にダウンロードされたキーファイルを安全な場所に保存します。
SAP アプリケーションと BigQuery 間のレプリケーションの構成
このソリューションの構成には、大きく分けて次の手順が含まれます。
- SAP LT Replication Server の構成
- SAP Data Services の構成
- SAP Data Services と BigQuery 間のデータフローの作成
SAP Landscape Transformation Replication Server の構成
次の手順では、SAP LT Replication Server が運用データ プロビジョニング フレームワーク内でプロバイダとして機能し、Operational Delta Queue を作成するように構成します。この構成では、SAP LT Replication Server はトリガーベースのレプリケーションを使用して、データをソース SAP システムからデルタキューのテーブルにコピーします。ODP フレームワークでサブスクライバーとして機能する SAP Data Services は、デルタキューからデータを取得して変換し、BigQuery に読み込ませます。
Operational Delta Queue(ODQ)を構成する
- SAP LT Replication Server で、トランザクション
SM59を使用して、データソースである SAP アプリケーション システムの RFC 宛先を作成します。 - SAP LT Replication Server で、トランザクション
LTRCを使用して構成を作成します。構成で、SAP LT Replication Server のソースとターゲットを定義します。ODP を使用したデータ転送のターゲットは、SAP LT Replication Server 自体になります。- ソースを指定するには、データソースとして使用される SAP アプリケーション システムの RFC 宛先を入力します。
- ターゲットを指定するには:
- RFC 接続として「NONE」と入力します。
- RFC 通信の [ODQ Replication Scenario] を選択します。このシナリオを使用して、運用デルタキューを備えた運用データ プロビジョニング インフラストラクチャを使用して、データが転送されるように指定します。
- キュー エイリアスを割り当てます。
キュー エイリアスは、SAP Data Services でデータソース ODP コンテキスト設定に使用されます。
SAP Data Services の構成
データサービス プロジェクトを作成する
- SAP Data Services Designer アプリケーションを開きます。
- [File] > [New] > [Project] の順に移動します。
- [Project name] フィールドに名前を指定します。
- [Data Services Repository] で、データサービス リポジトリを選択します。
- [Finish] をクリックします。左側の Project Explorer にプロジェクトが表示されます。
SAP Data Services はソースシステムに接続してメタデータを収集します。次に SAP Replication Server エージェントに接続して構成を取得し、データを変更します。
ソース データストアを作成する
次の手順では、SAP LT Replication Server への接続を作成し、Designer オブジェクト ライブラリの該当するデータストア ノードにデータテーブルを追加します。
SAP LT Replication Server と SAP Data Services を使用するには、データストアを ODP インフラストラクチャに接続することにより、SAP DataServices を ODP の適切な Operational Delta Queue に接続する必要があります。
- SAP Data Services Designer アプリケーションを開きます。
- Project Explorer で SAP Data Services のプロジェクト名を右クリックします。
- [New] > [Datastore] を選択します。
- [Datastore Name] に入力します。たとえば、「DS_SLT」と入力します。
- [Datastore type] フィールドで、[SAP Applications] を選択します。
- [Application server name] フィールドに、SAP LT Replication Server のインスタンス名を入力します。
- SAP LT Replication Server アクセス認証情報を指定します。
- [Advanced] タブを開きます。
- [ODP Context] で、SLT~ALIAS を入力します。ここで、ALIAS は Operational Delta Queue(ODQ)の構成で指定したキュー エイリアスです。
- [OK] をクリックします。
新しいデータストアが、Designer のローカル オブジェクト ライブラリの [Datastore] タブに表示されます。
ターゲット データストアを作成する
次の手順により、サービス アカウントの作成セクションで以前に作成したサービス アカウントを使用する BigQuery データストアを作成します。サービス アカウントにより、SAP Data Services は BigQuery に安全にアクセスできるようになります。
詳細については、SAP Data Services ドキュメントの Obtain your Google service account email および Obtain a Google service account private key file をご覧ください。
- SAP Data Services Designer アプリケーションを開きます。
- Project Explorer で SAP Data Services のプロジェクト名を右クリックします。
- [New] > [Datastore] を選択します。
- [Name] フィールドに入力します。たとえば、「BQ_DS」と入力します。
- [Next] をクリックします。
- [Datastore type] フィールドで、[Google BigQuery] を選択します。
- [Web Service URL] オプションが表示されます。ソフトウェアは、デフォルトの BigQuery ウェブサービス URL を使用してオプションを自動的に補完します。
- [Advanced] を選択します。
- SAP Data Services ドキュメントにある BigQuery の Datastore option descriptions に基づいて、詳細オプションを完了します。
- [OK] をクリックします。
新しいデータストアが、Designer のローカル オブジェクト ライブラリの [Datastore] タブに表示されます。
レプリケーションのためにソース ODP オブジェクトをインポートする
次の手順により、初期およびデルタロードのためにソース データストアから ODP オブジェクトをインポートし、SAP Data Services で使用できるようにします。
- SAP Data Services Designer アプリケーションを開きます。
- Project Explorer でレプリケーション ロードのソース データストアを展開します。
- 右パネルの上にある [External Metadata] オプションを選択します。使用可能なテーブルと ODP オブジェクトを含むノードのリストが表示されます。
- ODP オブジェクト ノードをクリックして、使用可能な ODP オブジェクトのリストを取得します。リストの表示には時間がかかる場合があります。
- [Search] ボタンをクリックします。
- ダイアログの [Look in] メニューで [External data] を選択し、[Object type] メニューで [ODP object] を選択します。
- [Search] ダイアログで、検索条件を選択して、ソース ODP オブジェクトのリストをフィルタリングします。
- インポートする ODP オブジェクトをリストから選択します。
- 右クリックして、[Import] オプションを選択します。
- [Name of Consumer] を入力します。
- [Name of project] を入力します。
- Extraction mode で [Changed-data capture (CDC)] オプションを選択します。
- [Import] をクリックします。これにより、ODP オブジェクトの Data Services へのインポートが開始されます。ODP オブジェクトが、DS_SLT ノードのオブジェクト ライブラリで使用できるようになります。
詳細については、SAP Data Services のドキュメントの Importing ODP source metadata をご覧ください。
スキーマ ファイルを作成する
次の手順により、SAP Data Services にデータフローが作成され、ソーステーブルの構造を反映するスキーマ ファイルが生成されます。その後、スキーマ ファイルを使用して BigQuery テーブルを作成します。
このスキーマにより、BigQuery ローダーのデータフローが新しい BigQuery テーブルに入力されます。
データフローを作成する
- SAP Data Services Designer アプリケーションを開きます。
- Project Explorer で SAP Data Services のプロジェクト名を右クリックします。
- [Project] > [New] > [Data flow] を選択します。
- [Name] フィールドに入力します。たとえば、「DF_BQ」と入力します。
- [Finish] をクリックします。
オブジェクト ライブラリを更新する
- Project Explorer で初期ロードするソース データストアを右クリックし、[Refresh Object Library] オプションを選択します。これにより、データフローで使用できるデータソース データベース テーブルのリストが更新されます。
データフローを構築する
- ソーステーブルをデータフロー ワークスペースにドラッグ&ドロップし、プロンプトが表示されたら [Import as Source] を選択して、データフローを構築します。
- オブジェクト ライブラリの [Transforms] タブで、[Platform] ノード i から [XML_Map transform] をデータフローにドラッグし、プロンプトが表示されたら [Batch Load] オプションを選択します。
- ワークスペース内のすべてのソーステーブルを XML Map transform に接続します。
- [XML Map transform] を開き、BigQuery テーブルに含まれているデータに基づいて入力スキーマと出力スキーマのセクションを完成させます。
- [Schema Out] 列の [XML_Map] ノードを右クリックし、プルダウン メニューから [Generate Google BigQuery Schema] を選択します。
- スキーマの名前と場所を入力します。
- [Save] をクリックします。
- Project Explorer でデータフローを右クリックし、[Remove] を選択します。
SAP Data Services は、.json ファイル拡張子を持つスキーマ ファイルを生成します。
BigQuery テーブルを作成する
初期ロードとデルタロードの両方に対して、Google Cloud の BigQuery データセットにテーブルを作成する必要があります。SAP Data Services で作成したスキーマを使用して、テーブルを作成します。
初期ロード用のテーブルは、ソース データセット全体の初期レプリケーションに使用されます。デルタロード用のテーブルは、初期ロード後に発生するソース データセット変更のレプリケーションに使用されます。テーブルは、前の手順で生成したスキーマに基づいています。デルタロードのテーブルには、各デルタロードの時間を識別する追加のタイムスタンプ フィールドが含まれます。
初期ロード用の BigQuery テーブルを作成する
次の手順により、BigQuery データセットに初期ロード用のテーブルが作成されます。
- Google Cloud コンソールで Google Cloud プロジェクトにアクセスします。
- [BigQuery] を選択します。
- 該当するデータセットをクリックします。
- [テーブルを作成] をクリックします。
- テーブルの名前を入力します。たとえば、「BQ_INIT_LOAD」と入力します。
- [スキーマ] で設定を切り替え、[テキストとして編集] モードを有効にします。
- スキーマ ファイルを作成するで作成したスキーマ ファイルの内容をコピーして貼り付けることにより、BigQuery で新しいテーブルのスキーマを設定します。
- [テーブルを作成] をクリックします。
デルタロード用の BigQuery テーブルを作成する
次の手順により、BigQuery データセットのデルタロード用のテーブルが作成されます。
- Google Cloud コンソールで Google Cloud プロジェクトにアクセスします。
- [BigQuery] を選択します。
- 該当するデータセットをクリックします。
- [テーブルを作成] をクリックします。
- テーブルの名前を入力します。たとえば、「BQ_DELTA_LOAD」と入力します。
- [スキーマ] で設定を切り替え、[テキストとして編集] モードを有効にします。
- スキーマ ファイルを作成するで作成したスキーマ ファイルの内容をコピーして貼り付けることにより、BigQuery で新しいテーブルのスキーマを設定します。
スキーマ ファイルの JSON リストで、DI_SEQUENCE_NUMBER フィールドのフィールド定義の直前に、次の DL_TIMESTAMP フィールド定義を追加します。このフィールドには、各デルタロード実行のタイムスタンプが格納されます。
{ "name": "DL_TIMESTAMP", "type": "TIMESTAMP", "mode": "REQUIRED", "description": "Delta load timestamp" },[テーブルを作成] をクリックします。
SAP Data Services と BigQuery 間のデータフローを設定する
データフローを設定するには、BigQuery テーブルを外部メタデータとして SAP Data Services にインポートし、レプリケーション ジョブと BigQuery ローダーのデータフローを作成する必要があります。
BigQuery テーブルをインポートする
次の手順により、前の手順で作成した BigQuery テーブルをインポートし、SAP Data Services で使用できるようにします。
- SAP Data Services Designer オブジェクト ライブラリで、前に作成した BigQuery データストアを開きます。
- 右パネルの上にある、[External Metadata] を選択します。作成した BigQuery テーブルが表示されます。
- 該当する BigQuery のテーブル名を右クリックして、[Import] を選択します。
- 選択したテーブルの SAP Data Services へのインポートが開始されます。これで、テーブルがターゲット データストア ノードのオブジェクト ライブラリで使用できるようになります。
レプリケーション ジョブと BigQuery ローダーのデータフローを作成する
次の手順により、SAP LT Replication Server から BigQuery テーブルへのデータ読み込みに使用される SAP Data Services に、レプリケーション ジョブとデータフローが作成されます。
データフローは 2 つの部分で構成されています。1 つ目はソース ODP オブジェクトから BigQuery テーブルへのデータの初期ロードを実行し、2 つ目は後続のデルタロードを有効にします。
グローバル変数を作成する
レプリケーション ジョブが初期ロードを実行するかデルタロードを実行するかを決定できるように、データフロー ロジックでロードタイプを追跡するグローバル変数を作成する必要があります。
- SAP Data Services Designer アプリケーションのメニューで、[Tools] > [Variables] を選択します。
- [Global Variables] を右クリックして、[Insert] を選択します。
- 変数の [Name] を右クリックし、[Properties] を選択します。
- 変数の [Name] に「$INITLOAD」と入力します。
- [Data Type] で [Int] を選択します。
- [Value] フィールドに「0」を入力します。
- [OK] をクリックします。
レプリケーション ジョブを作成する
- Project Explorer でプロジェクト名を右クリックします。
- [New] > [Batch Job] を選択します
- [Name] フィールドに入力します。たとえば、「JOB_SRS_DS_BQ_REPLICATION」と入力します。
- [Finish] をクリックします。
初期ロードのデータフロー ロジックを作成する
条件付きを作成する
- [Job Name] を右クリックして、[Add New] > [Conditional] オプションを選択します。
- [Conditional] アイコンを右クリックして、[Rename] を選択します。
名前を「InitialOrDelta」に変更します。

[Conditional] アイコンをダブルクリックして、Conditional Editor を開きます。
[If statement] フィールドに、「$INITLOAD = 1」と入力します。これにより、初期ロードを実行する条件が設定されます。
[Then] ペインを右クリックして、[Add New] > [Script] を選択します。
[Script] アイコンを右クリックして、[Rename] を選択します。
名前を変更します。たとえば、これらの手順では「InitialLoadCDCMarker」を使用します。
[Script] アイコンをダブルクリックして、Function editor を開きます。
「
print('Beginning Initial Load');」と入力します。「
begin_initial_load();」と入力します。
アプリケーション ツールバーにある [Back] アイコンをクリックして、Function Editor を終了します。
初期ロード用のデータフローを作成する
- [Then] ペインを右クリックして、[Add New] > [Data Flow] を選択します。
- データフローの名前を変更します。たとえば、「DF_SRS_DS_InitialLoad」にします。
- InitialLoadCDCMarker にある [Connection Output] アイコンをクリックし、DF_SRS_DS_InitialLoad の [Input] アイコンに接続線をドラッグして、InitialLoadCDCMarker を DF_SRS_DS_InitialLoad に接続します。
- [DF_SRS_DS_InitialLoad] データフローをダブルクリックします。
データフローをインポートして、ソース データストア オブジェクトに接続する
- データストアから、ソース ODP オブジェクトをデータフロー ワークスペースにドラッグ&ドロップします。この手順では、データストアの名前は「DS_SLT」です。データストアの名前は異なる場合があります。
- オブジェクト ライブラリの [Transforms] タブの [Platform] ノードから [Query transform] をデータフローにドラッグします。
ODP オブジェクトをダブルクリックし、[Source] タブで [Initial Load] オプションを [Yes] に設定します。
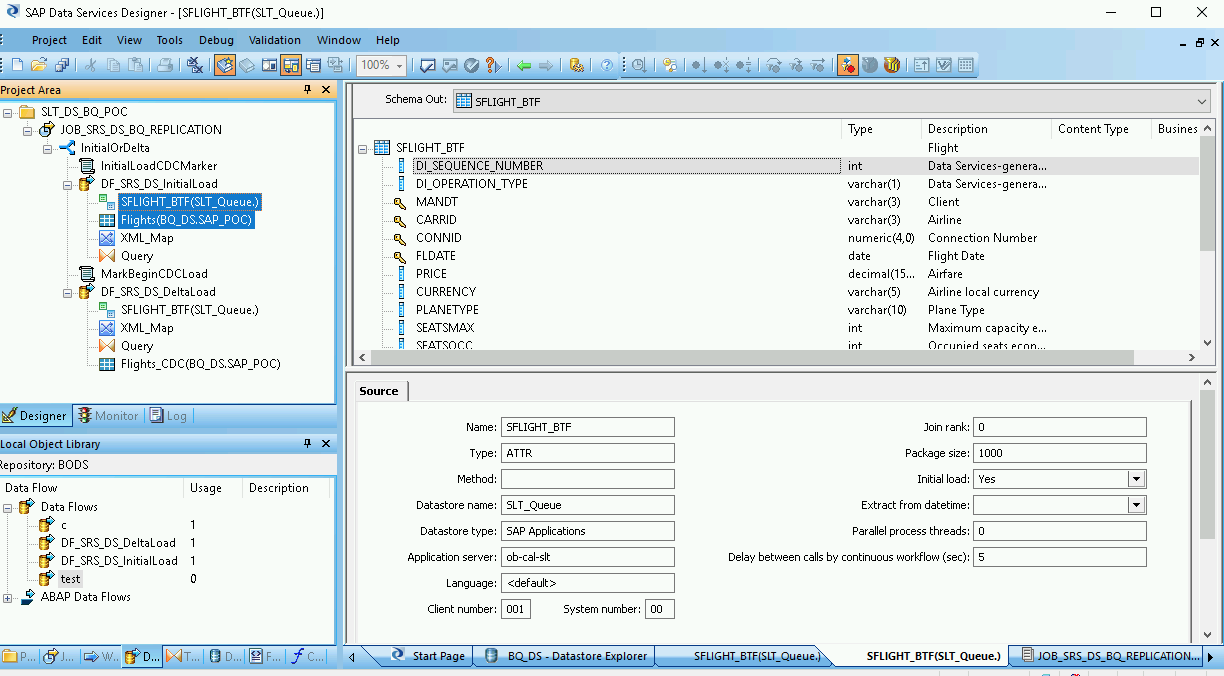
ワークスペース内のすべてのソース ODP オブジェクトを [Query transform] に接続します。
[Query transform] をダブルクリックします。
左側の [Schema In] の下にあるすべてのテーブル フィールドを選択し、右側の [Schema Out] にドラッグします。
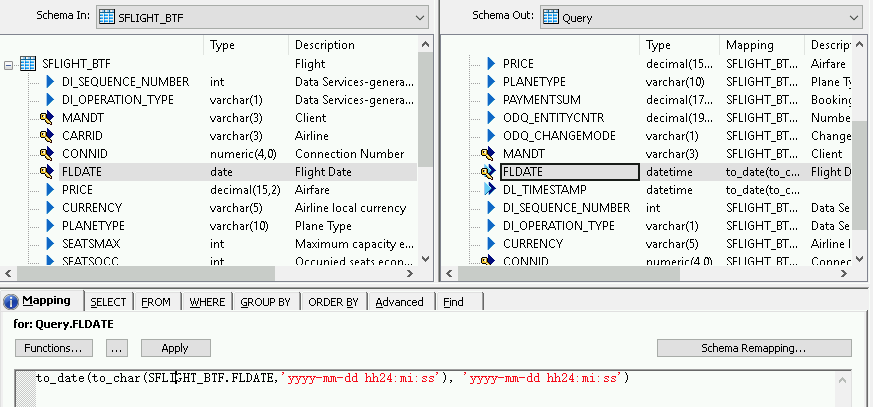
datetime フィールドに変換関数を追加するには:
- 右の [Schema Out] リストで [datetime] フィールドを選択します。
- スキーマリストの下の [Mapping] タブを選択します。
フィールド名を次の関数に置き換えます。
to_date(to_char(FIELDNAME,'yyyy-mm-dd hh24:mi:ss'), 'yyyy-mm-dd hh24:mi:ss')ここで、「FIELDNAME」は、選択したフィールドの名前です。
アプリケーション ツールバーの [Back] アイコンをクリックして、データフローに戻ります。
データフローをインポートして、ターゲット データストア オブジェクトに接続する
- オブジェクト ライブラリのデータストアから、初期ロード用にインポートした BigQuery テーブルをデータフローにドラッグします。この手順では、データストアの名前は「BQ_DS」です。データストアの名前は異なる場合があります。
- オブジェクト ライブラリの [Transforms] タブの [Platform] ノードから [XML_Map transform] をデータフローにドラッグします。
- ダイアログで [Batch mode] を選択します。
- [Query transform] を [XML_Map transform] に接続します。
[XML_Map transform] をインポートされた BigQuery テーブルに接続します。
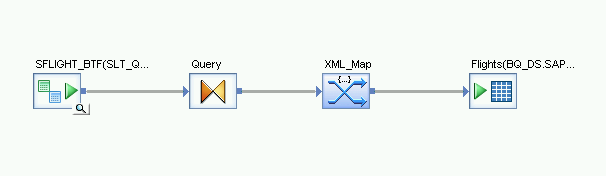
[XML_Map transform] を開き、BigQuery テーブルに含まれているデータに基づいて入力スキーマと出力スキーマのセクションを完成させます。
ワークスペースで BigQuery テーブルをダブルクリックして開き、次の表に示すように [Target] タブのオプションを完了します。
| オプション | 説明 |
|---|---|
| ポートの作成 | [No] を指定します。これはデフォルトです。 [Yes] を指定すると、ソースファイルまたはターゲット ファイルが埋め込みデータフロー ポートになります。 |
| モード | 初期ロードに [Truncate] を指定します。これにより、BigQuery テーブル内の既存のレコードが SAP Data Services によってロードされたデータに置き換えられます。デフォルトは [Truncate] です。 |
| ローダー数 | 正の整数を指定して、処理に使用するローダー(スレッド)の数を設定します。デフォルトは 4 です。
各ローダーは、BigQuery で再開可能な読み込みジョブを 1 つ開始します。任意のローダー数を指定できます。 適切なローダー数を判断するには、以下を含む SAP のドキュメントをご覧ください。 |
| 1 回のローダーで失敗できる記録の最大数 | 0 または正の整数を指定して、BigQuery が記録の読み込みを停止するまでに、1 回の読み込みジョブで失敗できる記録の最大数を設定します。デフォルトはゼロ(0)です。 |
- 上のツールバーにある [Validate] アイコンをクリックします。
- アプリケーション ツールバーにある [Back] アイコンをクリックして、Conditional Editor を終了します。
デルタロードのデータフローを作成する
初期ロード後に蓄積される変更データ キャプチャ レコードを複製するには、データフローを作成する必要があります。
条件付きデルタフローを作成するには:
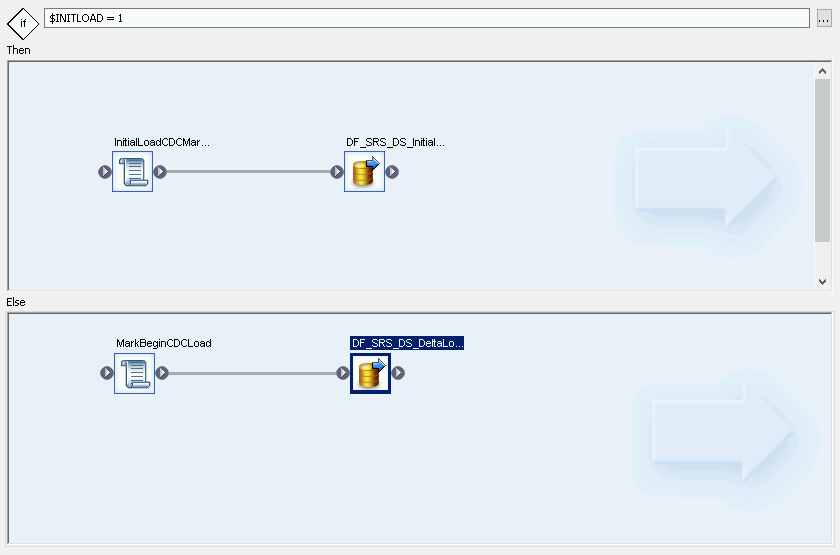
- [InitialOrDelta conditional] をダブルクリックします。
- [Else] セクションを右クリックして、[Add New] > [Script] を選択します。
- スクリプトの名前を変更します。たとえば、「MarkBeginCDCLoad」にします。
- [Script] アイコンをダブルクリックして、Function editor を開きます。
「print('Beginning Delta Load');」と入力します。

アプリケーション ツールバーにある [Back] アイコンをクリックして、Conditional Editor を終了します。
デルタロードのデータフローを作成する
- Conditional Editor で右クリックし、[Add New] > [Data Flow] を選択します。
- データフローの名前を変更します。たとえば、「DF_SRS_DS_DeltaLoad」にします。
- 次の図に示すように、[MarkBeginCDCLoad] を [DF_SRS_DS_DeltaLoad] に接続します。
[DF_SRS_DS_DeltaLoad] データフローをダブルクリックします。
データフローをインポートして、ソース データストア オブジェクトに接続する
- ソース ODP オブジェクトを、データストアからデータフロー ワークスペースにドラッグ&ドロップします。この手順では、データストアの名前は「DS_SLT」です。 データストアの名前は異なる場合があります。
- オブジェクト ライブラリの [Transforms] タブの [Platform] ノードから [Query transform] をデータフローにドラッグします。
- ODP オブジェクトをダブルクリックし、[Source] タブで [Initial Load] オプションを [No] に設定します。
- ワークスペース内のすべてのソース ODP オブジェクトを [Query transform] に接続します。
- [Query transform] をダブルクリックします。
- 左側の [Schema In] リストにあるすべてのテーブル フィールドを選択し、右側の [Schema Out] リストにドラッグします。
デルタロードのタイムスタンプを有効にする
以下の手順により、SAP Data Services は、デルタロード テーブルのフィールドに各デルタロード実行のタイムスタンプを自動的に記録できます。
- 右側の [Schema Out] ペインで [Query] ノードを右クリックします。
- [New Output Column] を選択します。
- [Name] に「DL_TIMESTAMP」と入力します。
- [Data type] で [datetime] を選択します。
- [OK] をクリックします。
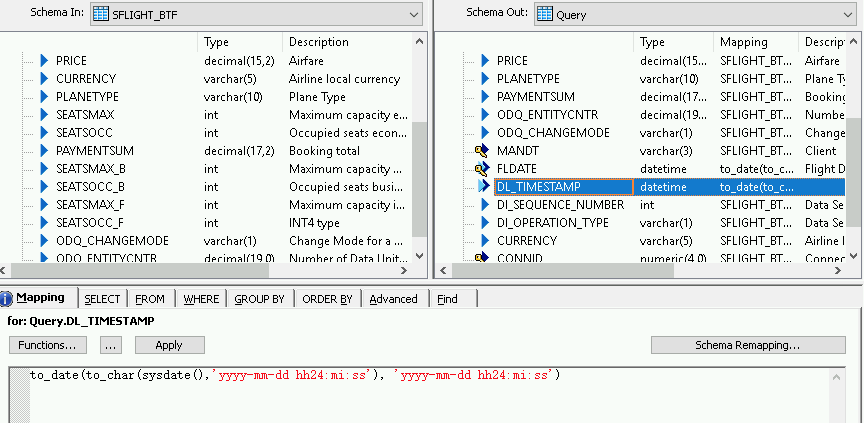
- 新しく作成された [DL_TIMESTAMP] フィールドをクリックします。
- 下にある [Mapping] タブに移動します。
次の関数を入力します。
- to_date(to_char(sysdate(),'yyyy-mm-dd hh24:mi:ss'), 'yyyy-mm-dd hh24:mi:ss')
データフローをインポートして、ターゲット データストア オブジェクトに接続する
- オブジェクト ライブラリのデータストアから、デルタロード用にインポートした BigQuery テーブルを、データフロー ワークスペースの [XML_Map transform] の後ろにドラッグします。この手順では、サンプル データストアの名前は「BQ_DS」です。データストアの名前は異なる場合があります。
- オブジェクト ライブラリの [Transforms] タブの [Platform] ノードから [XML_Map transform] をデータフローにドラッグします。
- [Query transform] を [XML_Map transform] に接続します。
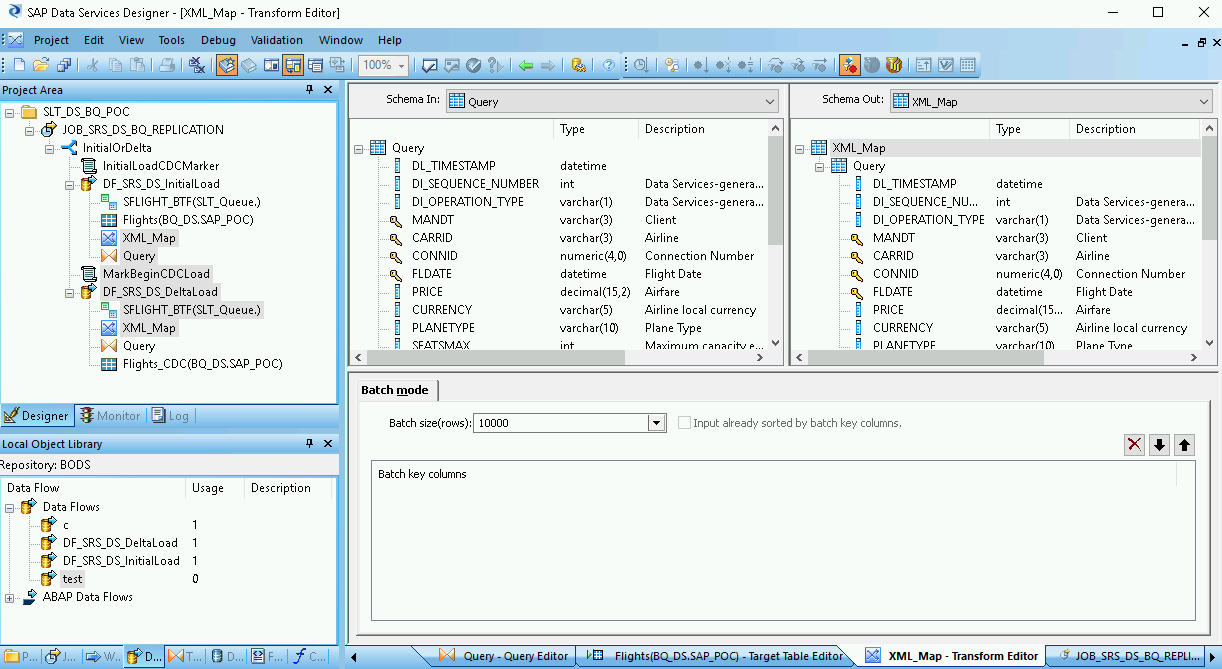
[XML_Map transform] をインポートされた BigQuery テーブルに接続します。
[XML_Map transform] を開き、BigQuery テーブルに含まれているデータに基づいて入力スキーマと出力スキーマのセクションを完成させます。
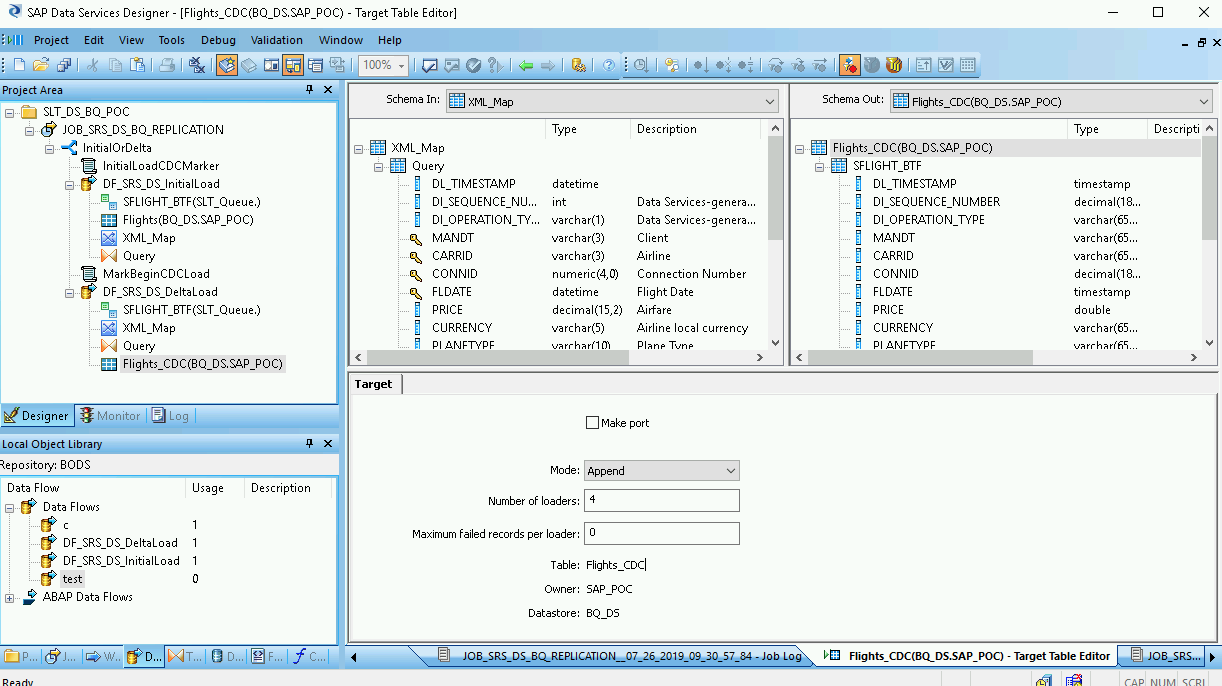
ワークスペースで BigQuery テーブルをダブルクリックして開き、次の説明に基づいて [Target] タブのオプションを完了させます。
| オプション | 説明 |
|---|---|
| ポートの作成 | [No] を指定します。これはデフォルトです。 [Yes] を指定すると、ソースファイルまたはターゲット ファイルが埋め込みデータフロー ポートになります。 |
| モード | デルタロードに [Append] を指定します。これにより、SAP Data Services から新しいレコードがロードされたときに、BigQuery テーブル内の既存のレコードを保持します。 |
| ローダー数 | 正の整数を指定して、処理に使用するローダー(スレッド)の数を設定します。
各ローダーは、BigQuery で再開可能な読み込みジョブを 1 つ開始します。任意のローダー数を指定できます。 一般に、デルタロードでは、初期ロードほどのロード数を必要としません。 適切なローダー数を判断するには、以下を含む SAP のドキュメントをご覧ください。 |
| 1 回のローダーで失敗できる記録の最大数 | 0 または正の整数を指定して、BigQuery が記録の読み込みを停止するまでに、1 回の読み込みジョブで失敗できる記録の最大数を設定します。デフォルトはゼロ(0)です。 |
- 上のツールバーにある [Validate] アイコンをクリックします。
- アプリケーション ツールバーにある [Back] アイコンをクリックして、Conditional editor を終了します。
BigQuery へのデータの読み込み
初期ロードとデルタロードの手順は似ています。各ロードでレプリケーション ジョブを開始し、SAP Data Services でデータフローを実行して SAP LT Replication Server から BigQuery にデータをロードします。2 つのロード手順の大きな違いは、$INITLOAD グローバル変数の値です。初期ロードの場合、$INITLOAD は「1」に設定する必要があります。デルタロードの場合、$INITLOAD は「0」でなければなりません。
初期ロードを実行する
初期ロードを実行すると、ソース データセット内のすべてのデータが、初期ロード データフローに接続されているターゲット BigQuery テーブルに複製されます。ターゲット テーブルのデータはすべて上書きされます。
- SAP Data Services Designer で、Project Explorer を開きます。
- レプリケーション ジョブ名を右クリックして、[Execute] を選択します。ダイアログが表示されます。
- ダイアログで [Global Variable] タブに移動し、初期ロードが最初に実行されるように
$INITLOADの値を 1 に変更します。 - [OK] をクリックします。読み込みプロセスが開始し、SAP Data Services ログにデバッグ メッセージが表示され始めます。データは、初期ロードのために BigQuery で作成したテーブルに読み込まれます。この手順では、初期ロードテーブルの名前は「BQ_INIT_LOAD」です。テーブルの名前は異なる場合があります。
- 読み込みが完了したかどうかを確認するには、 Google Cloud コンソールに移動して、テーブルを含む BigQuery データセットを開きます。データがまだ読み込み中の場合、テーブル名の横に「読み込み中」と表示されます。
読み込み後、データは BigQuery で処理できる状態になります。
この時点で、ソーステーブルのすべての変更が SAP LT Replication Server のデルタキューに記録されます。デルタキューから BigQuery にデータをロードするには、デルタロード ジョブを実行します。
デルタロードを実行する
デルタロードを実行すると、最後のロード以降にソース データセットで発生した変更のみが、デルタロード データフローに接続されているターゲット BigQuery テーブルに複製されます。
- ジョブ名を右クリックして、[Execute] を選択します。
- [OK] をクリックします。読み込みプロセスが開始され、SAP Data Services ログにデバッグ メッセージが表示され始めます。データは、デルタロード用に BigQuery で作成したテーブルにロードされます。この手順では、デルタロード テーブルの名前は「BQ_DELTA_LOAD」です。テーブルの名前は異なる場合があります。
- 読み込みが完了したかどうかを確認するには、 Google Cloud コンソールに移動して、テーブルを含む BigQuery データセットを開きます。データがまだ読み込み中の場合、テーブル名の横に「読み込み中」と表示されます。
- 読み込み後、データは BigQuery で処理できる状態になります。
ソースデータへの変更を追跡するために、SAP LT Replication Server は、変更データ操作の順序を DI_SEQUENCE_NUMBER 列に、変更データ操作の種類を DI_OPERATION_TYPE 列に記録します(D=delete、U=update、I=insert)。SAP LT Replication Server は、デルタキュー テーブルの列にデータを格納し、そこから BigQuery に複製されます。
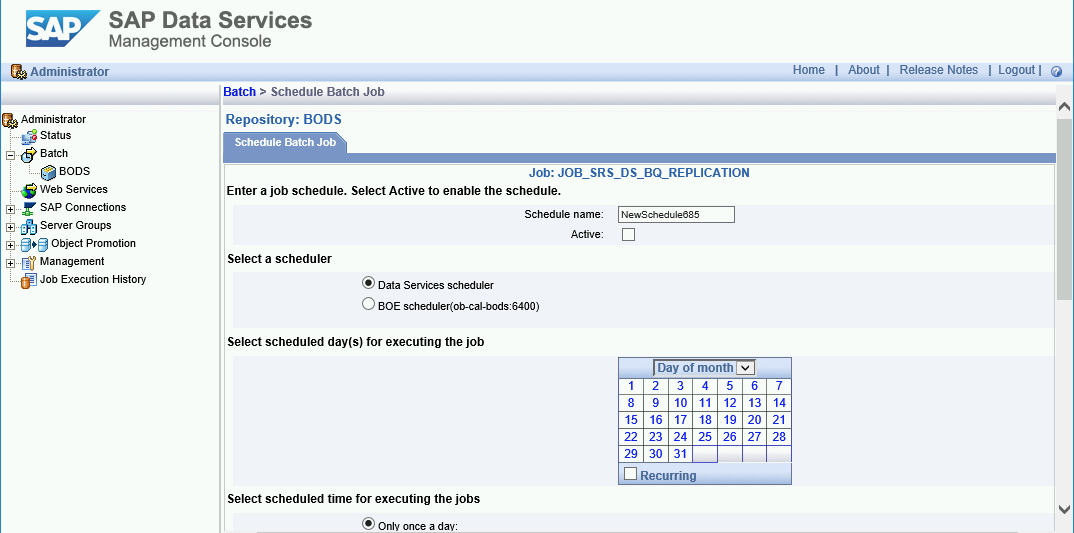
デルタロードのスケジューリング
SAP Data Services Management Console を使用して、デルタロード ジョブを定期的に実行するようにスケジュールできます。
- SAP Data Services Management Console アプリケーションを開きます。
- [Administrator] をクリックします。
- 左側のメニューツリーで [Batch] ノードを展開します。
- SAP Data Services リポジトリの名前をクリックします。
- [Batch Job Configuration] タブをクリックします。
- [Add Schedule] をクリックします。
- [Schedule name] に入力します。
- [Active] にチェックを入れます。
- [Select scheduled time for executing the jobs] セクションで、デルタロードの実行頻度を指定します。
- 重要: Google Cloud では、1 日に実行できる BigQuery 読み込みジョブの数に制限があります。スケジュールが上限を超えないようにしてください。上限を引き上げることはできません。BigQuery の読み込みジョブ制限の詳細については、BigQuery ドキュメントの割り当てと上限をご覧ください。
- [Global Variables] を開き、[$INITLOAD] が「0」に設定されているかを確認します。
- [Apply] をクリックします。
次のステップ
BigQuery で複製されたデータをクエリおよび分析します。
クエリの詳細については、以下をご覧ください。
- BigQuery ドキュメントの BigQuery データのクエリの概要。
大規模な BigQuery で初期ロードデータとデルタロード データを統合する方法の詳細については、以下をご覧ください。
- BigQuery での大規模なミューテーションの実行ソリューションは、 Google Cloud のブログで入手できます。
- BigQuery ドキュメントのデータ操作言語。
Google Cloud に関するリファレンス アーキテクチャ、図、ベスト プラクティスを確認する。Cloud アーキテクチャ センターをご覧ください。