In diesem Dokument wird erläutert, wie Sie Cloud SQL for PostgreSQL für die Produktion einrichten. Cloud SQL for PostgreSQL ist ein vollständig verwalteter RDBMS-Dienst, der in das Google Cloud-System integriert ist. Cloud SQL for PostgreSQL bietet einige wichtige Features und Funktionen:
- Bereitstellung mehrerer Anwendungen und Nutzer weltweit durch die Verwendung der verwalteten Sicherheitsfunktionen vonGoogle Cloud, einschließlich VPC und automatischer Datenverschlüsselung inaktiver Daten und während der Übertragung.
- Unterstützt Hochverfügbarkeitsarchitektur mit primären und Standby-Instanzen sowie einem automatischen Failover zwischen ihnen.
- Unterstützt verteilte Datenbankarbeitslasten aufgrund der Möglichkeit einer Lese-/Schreibtrennung zwischen dem primären Knoten und Lesereplikaten innerhalb desselben Datenbankclusters.
- Unterstützt automatische in Google Cloud Storage eingebundene Sicherungen und die automatische Datenbankwartung.
- Unterstützt eine Vielzahl von OLTP-Arbeitslasten (Online Transaction Processing).
Stellen Sie eine Cloud SQL for PostgreSQL-Instanz bereit.
Sie können eine Cloud SQL for PostgreSQL-Instanz in wenigen Schritten mithilfe der Google Cloud -Console oder der Google Cloud CLI einrichten. Beide Methoden werden hier beschrieben.
Console
Rufen Sie in der Google Cloud Console die Seite SQL>Instanzen auf.
Klicken Sie auf Instanz erstellen und dann auf PostgreSQL auswählen.
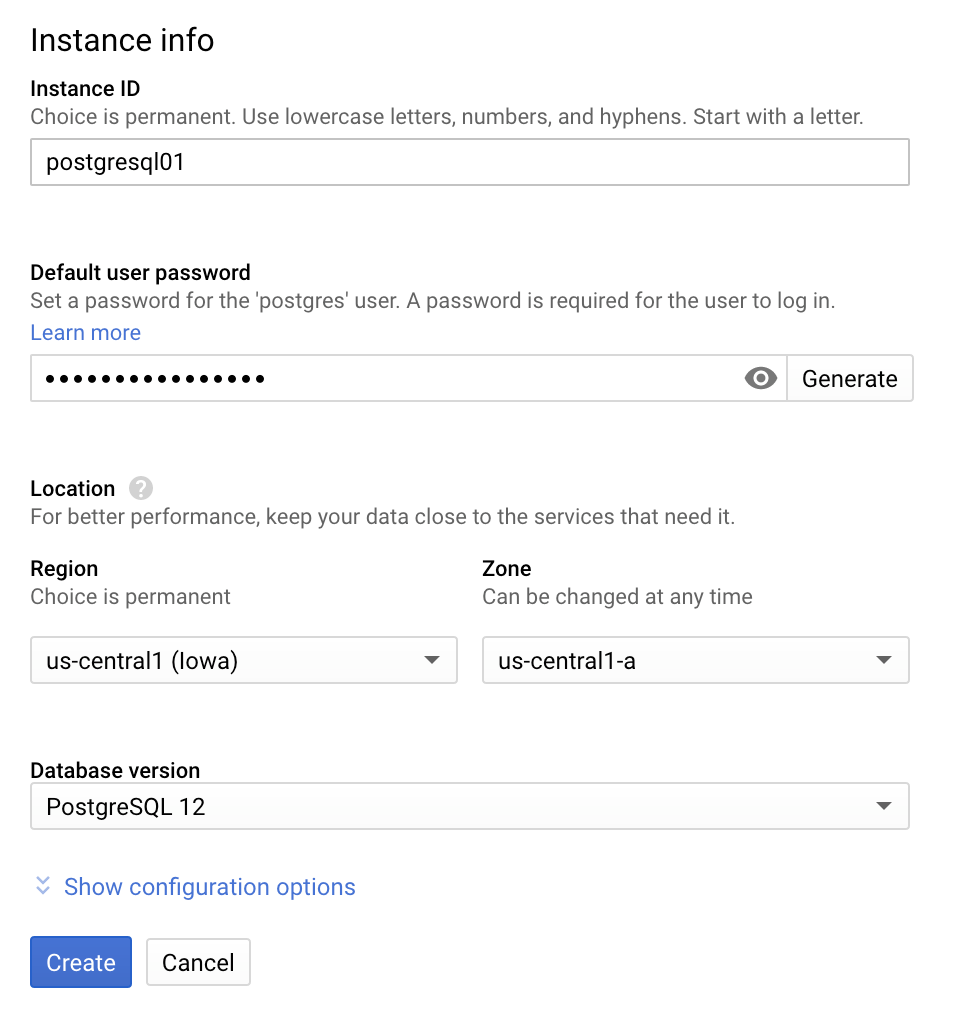
Geben Sie auf der Seite PostgreSQL-Instanz erstellen die folgenden Details an:
- Instanz-ID: Geben Sie einen Namen für die Instanz ein. Der Instanzname kann später nicht mehr geändert werden.
- Standardnutzerpasswort: Wählen Sie das postgres-Nutzerpasswort als Standardadministratorkonto aus. Sie können nach der Bereitstellung der PostgreSQL-Instanz zusätzliche Nutzer erstellen.
- Region und Zone: Wählen Sie eine Region und Zone aus. Die PostgreSQL-Instanz sollte in derselben Region wie die zugehörigen Google Cloud Dienste (z. B. Anwendungen) oder in der geographischen Nähe der Nutzer bereitgestellt werden, um die Latenz für die Datenverarbeitung zu reduzieren. Nachdem Sie eine Region ausgewählt haben, können Sie sie nicht mehr ändern.
- Datenbankversion: Wählen Sie die neueste Version oder bei Bedarf die neueste verfügbare Version aus.
Klicken Sie auf Erstellen, um die PostgreSQL-Instanz bereitzustellen. Sie können auch auf Konfigurationsoptionen einblenden klicken, um zusätzliche Konfigurationen festzulegen.
Zusätzliche Konfigurationsoptionen:
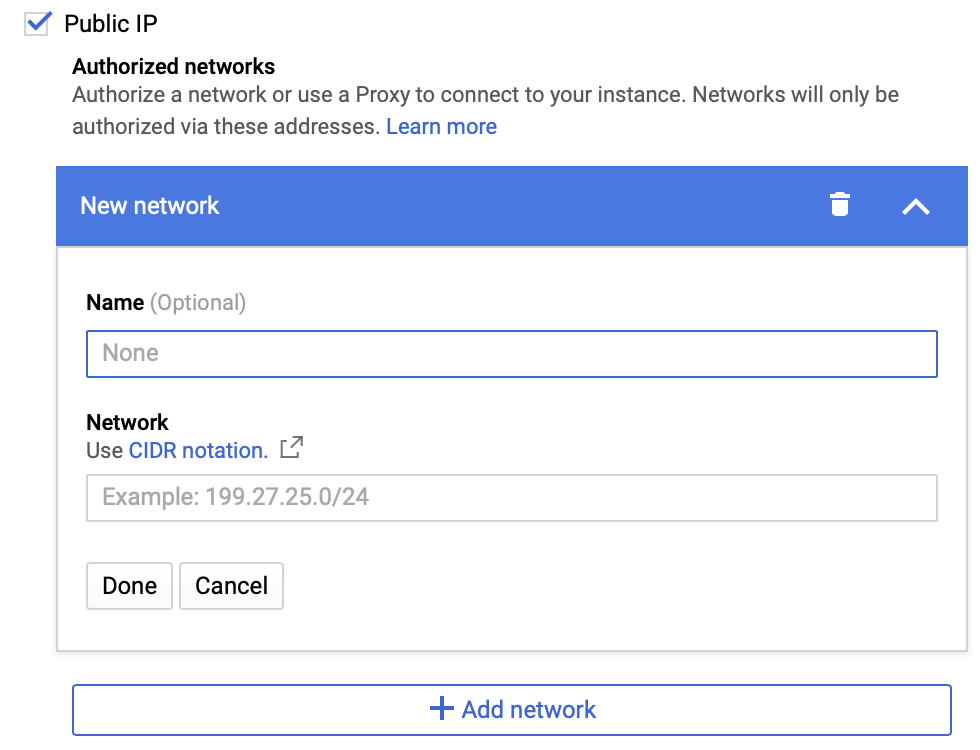
Konnektivität: In der Regel verbinden Sie die PostgreSQL-Instanz über eine öffentliche IP-Adresse, eine private IP-Adresse und autorisierte Netzwerke mit dem Netzwerk. Autorisierte Netzwerke sind zugelassene Verbindungen, die Sie festlegen können, um eine Remote-Verbindung herzustellen, z. B. um eine Verbindung von einer bestimmten IP-Adresse eines Clients zu genehmigen.
Maschinentyp und Speicher: Wählen Sie den Maschinentyp nach zugewiesenen Ressourcen (vCPUs, RAM), den Speichertyp (SSD oder HDD) und die Speicherkapazität aus. Durch Erhöhen der Speicherkapazität erhöhen sich auch der unterstützte Laufwerkdurchsatz (MB/s) sowie die Lese- und Schreib-IOPS für Ihre Datenbank. Passen Sie die Speicherkapazität entsprechend dem erwarteten Laufwerkdurchsatz und den IOPS-Anforderungen an.


Automatische Sicherungen und Hochverfügbarkeit: Mit der automatischen Sicherung, die standardmäßig aktiviert ist, können Sie den Zeitraum festlegen, in dem automatische Sicherungen ausgeführt werden sollen. Außerdem ist die Wiederherstellung zu einem bestimmten Zeitpunkt erforderlich, die Write-Ahead-Logs verwendet. Sie ist außerdem erforderlich, um ein Lesereplikat zu erstellen. Diese Logs werden regelmäßig aktualisiert und sie belegen Speicherplatz. Damit unerwartete Speicherprobleme vermieden werden, empfehlen wir die Aktivierung automatischer Speichererweiterungen bei der Verwendung der Wiederherstellung zu einem bestimmten Zeitpunkt. Die Hochverfügbarkeit ist standardmäßig deaktiviert (Mehrzonen). Wählen Sie zum Aktivieren des automatischen Failovers die Option Hochverfügbarkeit (regional) aus.
Flags: Diese Einstellung gibt die Cloud SQL-Methode zum Steuern von Einstellungen und Parametern für Ihre Instanz an. Sie entspricht der Datei
postgresql.confeiner nicht verwalteten PostgreSQL-Instanz. Eine vollständige Auflistung finden Sie in der Produktdokumentation. Wenn Sie den Wert eines Flags ändern oder ein neues Flag festlegen, muss die Instanz möglicherweise neu gestartet werden.Wartung: In diesem Abschnitt wird das bevorzugte Zeitfenster für Wartungsaufgaben angegeben, darunter Fehlerbehebungen und Upgrades von Nebenversionen. Beachten Sie, dass Wartungsvorgänge im Allgemeinen einen Neustart der Instanz erfordern und zu einer kurzen Dienstunterbrechung führen. Wenn Sie sich hier registrieren, werden Sie per E-Mail über anstehende Wartungsereignisse informiert.
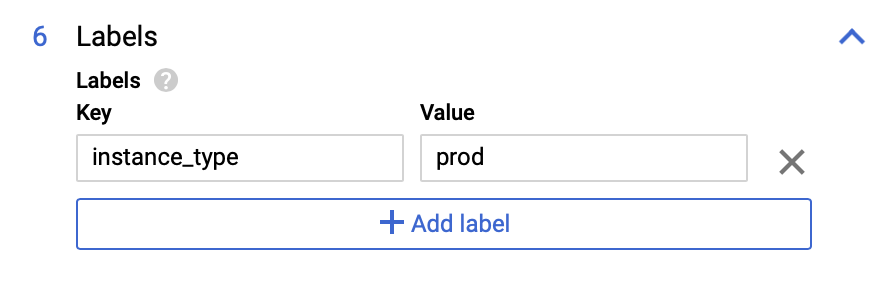
Labels: In diesem Abschnitt definieren Sie Schlüssel/Wert-Paare, um Ihre PostgreSQL-Instanz zu kategorisieren. Beispiel:
gcloud
Erstellen Sie die PostgreSQL-Instanz:
gcloud sql instances create postgresql01 \ --cpu=2 \ --memory=7680MB \ --region=us-central1 --zone=us-central1-aWeisen Sie dem PostgreSQL-Standardnutzer ein Passwort zu (Syntaxbeispiel):
gcloud sql users set-password postgres \ --instance INSTANCE_NAME \ --password PASSWORDSie können auch die folgenden zusätzlichen Optionen festlegen:
- Datenbankversion: Eine der unterstützten PostgreSQL-Versionen.
- Speichertyp: Entweder SSD oder HDD als Speichertyp.
- Speicherkapazität: Die anfänglichen Speichereinstellungen für die Instanz.
- Automatische Speichererweiterung: Cloud SQL-Automatisierung zum Hinzufügen von zusätzlichem Speicher, wenn wenig freier Speicherplatz verfügbar ist.
- Hochverfügbarkeit: Cloud SQL-Hochverfügbarkeit.
- Automatische Sicherungen: Das Startfenster für Sicherungen.
- Wiederherstellung zu einem bestimmten Zeitpunkt: Wiederherstellung zu einem bestimmten Zeitpunkt und Write-Ahead-Logging
- Wartungsfenster: Ein einstündiges Zeitfenster, in dem Cloud SQL tief greifende Wartungsaufgaben durchführen kann.
- Wartungszeitpunkt: Die bevorzugte Zeit für die Aktualisierung der PostgreSQL-Instanz. Sie können für frühere Aktualisierungen preview oder für spätere Aktualisierungen production angeben.
- Datenbank-Flags: Die PostgreSQL-Datenbank-Flags zum Steuern von Einstellungen und Parametern.
Mit dem folgenden
gcloud-Befehl wird eine Cloud SQL for PostgreSQL-Instanz mit einigen zusätzlichen Optionen erstellt:gcloud sql instances create postgresql01 \ --cpu=2 \ --memory=7680MB \ --region=us-central1 \ --zone=us-central1-a \ --database-version=POSTGRES_12 \ --storage-type=SSD \ --storage-size=100 \ --storage-auto-increase \ --availability-type=regional \ --backup-start-time=23:30 \ --enable-point-in-time-recovery \ --maintenance-window-day=sun \ --maintenance-window-hour=11 \ --maintenance-release-channel=production \ --database-flags max_connections=100Weitere Informationen finden Sie unter Instanzen erstellen.
Instanzauswahl
Bei der Instanzauswahl oder -größe muss ein Maschinentyp ausgewählt werden, der Ihre Oracle®-Arbeitslast in Cloud SQL for PostgreSQL unterstützt. Die Instanztypen sind in zwei Hauptgruppen unterteilt:
- Maschinen mit gemeinsam genutztem Kern: kostengünstig.
- Instanzen mit dediziertem Kern: Unterstützung von mehreren vCPUs und Speicherverhältnissen.
Weitere Informationen zu Instanztypen finden Sie unter Cloud SQL-Preise.
Wenn Sie die Größe Ihrer Instanz bestimmen möchten, analysieren Sie zuerst die Ressourcen, die Ihrer Quelldatenbank zugewiesen sind und von dieser genutzt werden. Sie finden die Einstellungen für die Oracle-Datenbankressource in der Systemansicht V$OSSTAT oder in einem Oracle-AWR-Bericht (siehe folgende Beispiele):
Physischer Speicher (Anzahl der Byte des physischen Speichers auf dem Datenbankserver):
SQL> SELECT ROUND(MAX(VALUE)/1024/1024/1024) AS MEM_SIZE_GB
FROM V$OSSTAT
WHERE STAT_NAME = 'PHYSICAL_MEMORY_BYTES';
Zugewiesener Speicher:
SQL> SELECT NAME, VALUE, DISPLAY_VALUE FROM V$PARAMETER
WHERE NAME LIKE '%sga%' OR NAME LIKE '%memory%';
CPU-Kerne (Anzahl der verfügbaren CPU-Kerne):
SQL> SELECT VALUE FROM V$OSSTAT
WHERE STAT_NAME = 'NUM_CPU_CORES';
CPU-Kerne (durch eine Oracle-Instanz mit der Ansicht V$LICENSE identifiziert):
SQL> SELECT CPU_CORE_COUNT_CURRENT FROM V$LICENSE;
Beispiel für Oracle-AWR-Berichtsressourcen (Der Oracle-AWR-Bericht kann zusätzliche Informationen über bestimmte Eigenschaften der Oracle-Instanzarbeitslast liefern):

Wenn Ihnen die Ressourceninformationen Ihrer Quelldatenbank vorliegen, empfehlen wir, den am besten passenden Cloud SQL-Instanztyp auszuwählen und einige Benchmarks auszuführen. Mit den Ergebnissen Ihrer Benchmarks können Sie Ihre Instanzauswahl vervollständigen.
Konfiguration für hohe Verfügbarkeit
Zum Implementieren einer Notfallwiederherstellungslösung, ähnlich wie Oracle Data Guard, bietet Cloud SQL for PostgreSQL Hochverfügbarkeitsfunktionen. So wird ein automatisches Failover von der primären Instanz des Clusters zur Standby-Instanz ermöglicht. Die Standby-Instanz befindet sich in einer anderen Zone, die sich in derselben Region wie die primäre Instanz befindet. Die Standby-Instanz wird durch synchrone Replikation zwischen den nichtflüchtigen Speichern der primären Instanz und der Standby-Instanz synchronisiert. Durch diese Methode werden alle Datenänderungen an der primären Datenbank auch auf die Standby-Instanz angewendet.
Bei einem primären Ausfall, etwa einer nicht reagierenden Instanz oder eines Ausfalls auf Zonenebene, führt Cloud SQL einen automatischen Failover durch. Die primäre Instanz wird durch Heartbeats überwacht, die in Intervallen von einer Sekunde durchgeführt werden, wobei ein Failover aktiviert wird, sobald die primäre Instanz rund 60 Sekunden keine Heartbeats mehr sendet. An diesem Punkt wechselt die primäre Instanz in den Standby-Modus. Dabei wird transparenter Datenzugriff für Anwendungen und Clients bereitgestellt, während die vorhandenen Lesereplikate funktionsfähig bleiben. Im Gegensatz zu Oracle Active Data Guard wird die Standby-Instanz nicht für Lesevorgänge geöffnet, während sie im Standby-Modus ist. Bei Cloud SQL können nur die Lesereplikate verwendet werden, um Lesevorgänge von der primären Instanz auszulagern.
Sie können die Hochverfügbarkeitsfunktion von Cloud SQL for PostgreSQL beim Erstellen einer Instanz oder für eine vorhandenen PostgreSQL-Instanz aktivieren. Gehen Sie wie folgt vor:
Console
- Klicken Sie auf der Seite zur Instanzerstellung auf Konfigurationsoptionen anzeigen> Automatische Sicherungen und Hochverfügbarkeit > Verfügbarkeit und wählen Sie dann die Option Hochverfügbarkeit (regional) aus.
- Bearbeiten Sie bei einer vorhandenen PostgreSQL-Instanz die PostgreSQL-Instanz. Folgen Sie dazu dem vorherigen Schritt. Dafür ist ein Neustart der Datenbank erforderlich.
Wenn Sie einen Failover zu Testzwecken initiieren möchten, rufen Sie die Seite Cloud SQL auf und klicken Sie auf Failover.

Failback kann auf die gleiche Weise aktiviert werden.
gcloud
Aktivieren Sie HA, indem Sie den Parameter
availability-typeaufregionalsetzen:gcloud sql instances create postgresql01 \ --cpu=2 \ --memory=7680MB \ --region=us-central1 \ --zone=us-central1-a \ --availability-type=regionalPrüfen Sie, ob für eine vorhandene PostgreSQL-Instanz HA konfiguriert wurde:
gcloud sql instances describe INSTANCE_NAME
Wenn die Ausgabe dieses Befehls
availabilityType: REGIONALenthält, ist HA bereits aktiviert. Wenn die AusgabeavailabilityType: ZONALenthält, ist HA nicht konfiguriert und kann mit dempatch-Befehl aktiviert werden:gcloud sql instances patch INSTANCE_NAME --availability-type REGIONAL
Starten Sie einen Failover-Test vom primären zum Standby-Cluster:
gcloud sql instances failover PRIMARY_INSTANCE_NAME
Führen Sie denselben Failover-Befehl auf dem neuen Primären aus, um ein Failback auszuführen.
Administratornutzer und -konten
Zwei standardmäßige PostgreSQL-Nutzerkonten werden mit einer Cloud SQL for PostgreSQL-Installation bereitgestellt. Diese Konten sind postgres und cloudsqlimportexport.
Postgres-Konto
Das Konto postgres ist das Administratorkonto und entspricht den Oracle-SYS- oder -SYSTEM-Nutzern unter Cloud PaaS. Da Cloud SQL for PostgreSQL ein verwalteter Dienst ist, wird der postgres-Nutzer im Gegensatz zu Oracle SYS- oder SYSTEM-Nutzern nicht auf bestimmte Systemprozeduren und -tabellen zugreifen können, die erweiterten Berechtigungen erfordern.
Der postgres-Nutzer gehört zur cloudsqlsuperuser-Rolle und hat die folgenden Attribute (Berechtigungen): CREATEROLE, CREATEDB und LOGIN. Er hat nicht die Attribute SUPERUSER oder REPLICATION.
cloudsqlimportexport-Konto
Das Konto cloudsqlimportexport wird mit den minimalen Berechtigungen erstellt, die für CSV-Importe- und -Exporte erforderlich sind. Sie können Ihre eigenen Nutzer erstellen, um diese Vorgänge auszuführen. Wenn Sie das nicht tun, wird der cloudsqlimportexport-Standardnutzer verwendet. Der cloudsqlimportexport-Nutzer ist ein Systemnutzer, der von Kunden nicht direkt verwendet werden kann.
Kontoverwaltung (Passwort hinzufügen, löschen oder ändern)
Die Kontoverwaltung erfordert das Erstellen neuer Nutzerkonten, das Ändern des Passworts eines vorhandenen Kontos und das Löschen eines Kontos, das nicht mehr benötigt wird. Sie können diese Kontovorgänge über die Google Cloud Console, das gcloud-Tool oder den PostgreSQL-Client ausführen.
Console
Listen Sie die vorhandenen Konten in der Google Cloud Console auf: Rufen Sie Cloud SQL Console> PostgreSQL-Instanz auswählen > Nutzer auf.
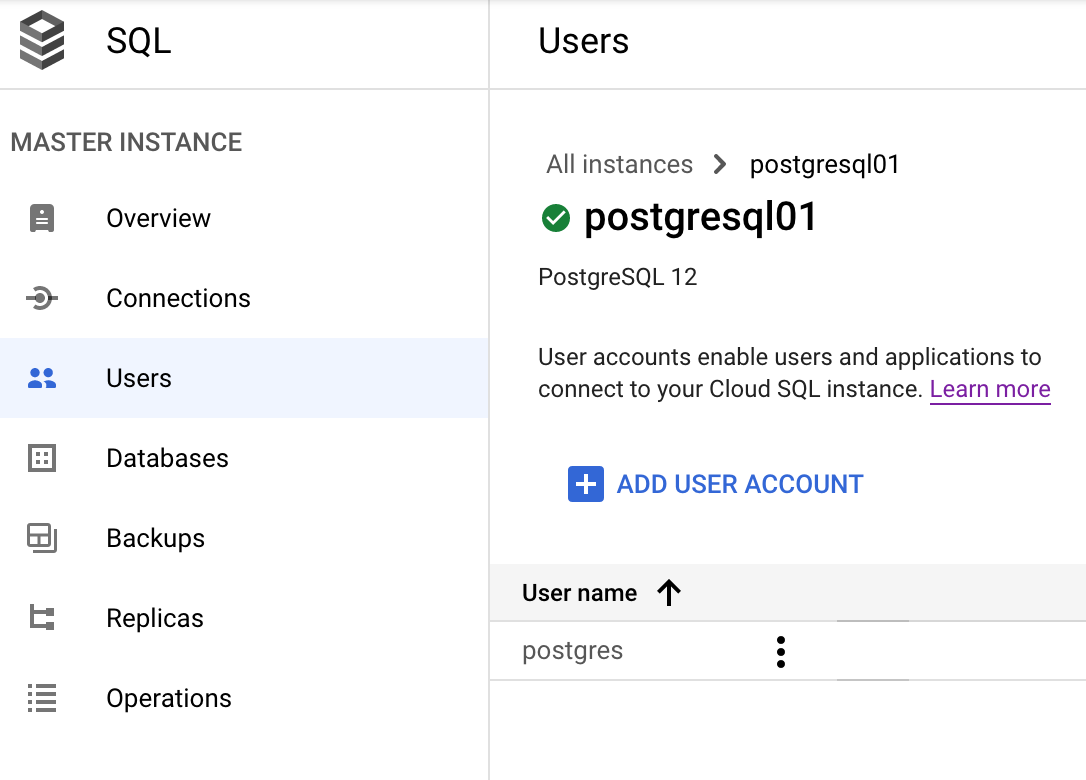
Ändern Sie das Passwort des Kontos oder löschen Sie das Konto. Klicken Sie dazu auf das Dreipunkt-Menü neben dem Konto.
Klicken Sie in diesem Bildschirm auf Nutzerkonto erstellen, um einen neuen PostgreSQL-Nutzer zu erstellen.
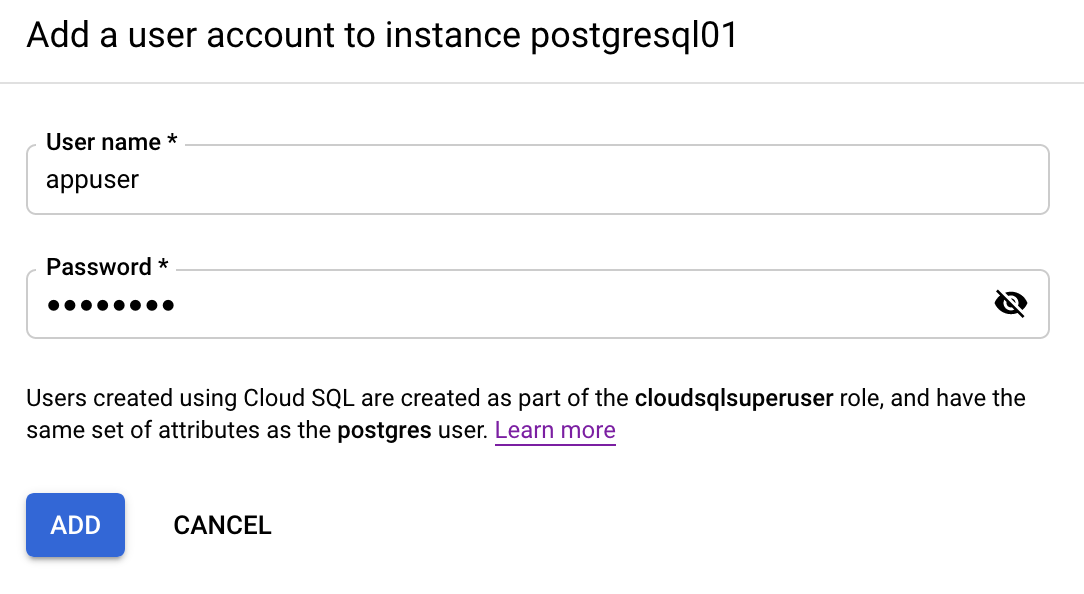
gcloud
Listen Sie die vorhandenen Nutzerkonten auf:
gcloud sql users list --instance=postgresql01Die Ausgabe sieht etwa so aus:
NAME HOST PostgresErstellen Sie das Nutzerkonto
appuser, legen Sie das Passwort fest und löschen Sieappuser:gcloud sql users create appuser \ --instance=postgresql01 --password=PASSWORD gcloud sql users set-password appuser \ --host=% --instance=postgresql01 --prompt-for-password gcloud sql users delete appuser --instance=postgresql01
PostgreSQL
Führen Sie die gleichen Aktionen direkt über einen PostgreSQL-Standardclient aus. Beispiel:
postgres=> create user appuser with login password 'my_password'; postgres=> alter user appuser password 'my_password'; postgres=> drop user appuser;Sie können Berechtigungen auf PostgreSQL-Datenbankebene (z. B. Lesen aus einer bestimmten Tabelle oder Ansicht) mithilfe der
GRANT/REVOKE-Befehle über den PostgreSQL-Client konfigurieren.
Monitoring und Benachrichtigungen
Cloud Logging ist das Haupt-Logging-Tool in Google Cloud. Es wird zum Erfassen und Aufrufen verschiedener Monitoring-Logs für Ressourcen wie Cloud SQL for PostgreSQL verwendet.
Mit Cloud Logging können Sie Logs für Cloud SQL for PostgreSQL ansehen, die nach Ereignisebene gefiltert sind (z. B. kritisch, Fehler oder Warnung), nach Ereigniszeitraum und Freitextsuche filtern, wie im folgenden Screenshot dargestellt.
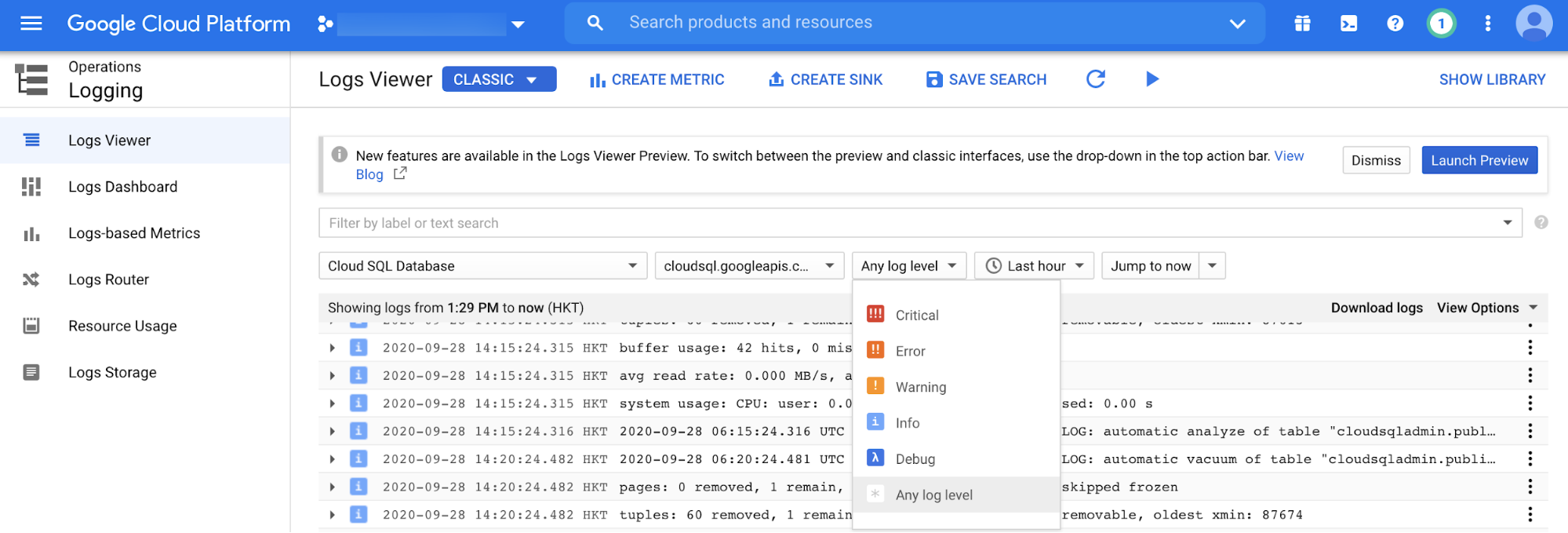
PostgreSQL-Datenbankinstanz-Monitoring
Die wichtigsten Überwachungstools von Oracle sind Enterprise Manager und Grid/Cloud Control. Mit diesen Tools können Sie Datenbankinstanzen in Echtzeit auf Datenbank- und SQL-Anweisungsebene überwachen.
Cloud SQL for PostgreSQL bietet ähnliche Monitoring-Funktionen über die Google Cloud Console. Von dort erhalten Sie eine zusammenfassende Ansicht Ihrer Datenbankinstanzen, einschließlich CPU-Auslastung, Speichernutzung, Arbeitsspeichernutzung, Lese-/Schreibvorgängen, aktiven Verbindungen, Transaktionen pro Sekunde und eingehenden/ausgehenden Byte auf Ihrem Mobilgerät. Beachten Sie, dass Google Cloud Observability zusätzliche Monitoring-Messwerte für Cloud SQL for PostgreSQL bietet, z. B. automatische Failover-Anfragen und Replikationsverzögerung zwischen dem primären und Lesereplikat.
Das folgende Beispiel zeigt eine Grafik mit Transaktionen pro Sekunde für die letzten sechs Stunden:
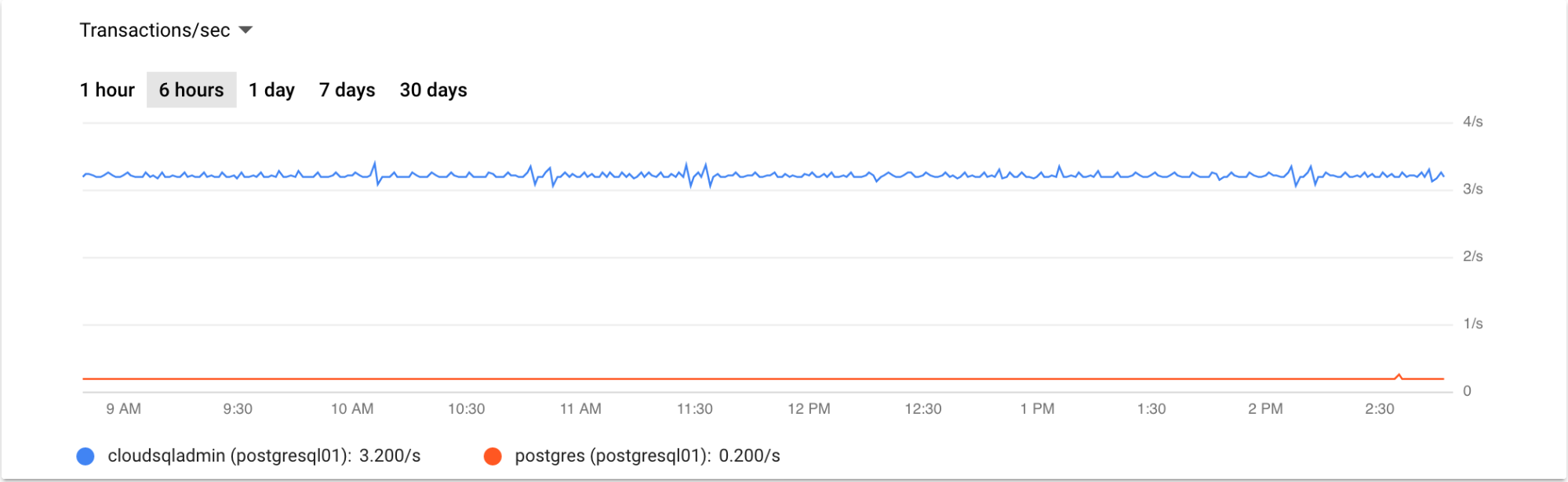
Monitoring von Lesereplikaten
Sie können Lesereplikate über die Google Cloud Console genauso überwachen wie die primäre Instanz. Es gibt bestimmte Messwerte, die den Replikationsstatus zwischen der primären Instanz und den Lesereplikatinstanzen prüfen. Diese Messwerte werden verwendet, um die Übersichtsseite der Lesereplikat-Instanzen in derGoogle Cloud Console zu füllen.
Alternativ können Sie den Replikationsstatus über die Befehlszeile prüfen:
gcloud sql instances describe REPLICA_NAME
Eine dritte Option besteht darin, den Replikationsstatus über einen PostgreSQL-Client zu prüfen. Mit dem folgenden PostgreSQL-Befehl wird der Status des Lesereplikats geprüft:
postgres=> \x on Expanded display is on. postgres=> select * from pg_stat_replication; -[ RECORD 1 ]----+------------------------------------------- pid | 74733 usesysid | 16388 usename | cloudsqlreplica application_name | PROJECT_ID:REPLICA_NAME client_addr | REPLICA_IP client_hostname | client_port | 41660 backend_start | 2020-09-28 06:59:38.783981+00 backend_xmin | state | streaming sent_lsn | 0/2939FFA8 write_lsn | 0/2939FFA8 flush_lsn | 0/2939FFA8 replay_lsn | 0/2939FFA8 write_lag | flush_lag | replay_lag | sync_priority | 0 sync_state | async reply_time | 2020-09-28 07:17:52.714969+00 postgres=>
PostgreSQL-Datenbankmonitoring
In diesem Abschnitt werden einige zusätzliche Monitoringaufgaben beschrieben, die als Routine für eine PostgreSQL-DBA gelten.
Monitoring einer Sitzung
Ein Monitoring von Oracle-Sitzungen erfolgt durch das Abfragen der dynamischen Leistungsansichten, die als „V$-Ansichten“ bezeichnet werden. Die Ansichten V$SESSION und V$PROCESS werden in der Regel verwendet, um mithilfe von SQL-Anweisungen Echtzeitinformationen zur aktuellen Datenbankaktivität abzurufen. Sie können die Sitzungsaktivität in PostgreSQL auf ähnliche Weise überwachen, sowohl über PostgreSQL-Befehle als auch über SQL-Anweisungen.
Die dynamische Ansicht pg_stat_activity von PostgreSQL bietet detaillierte Informationen zur aktuellen Datenbanksitzungsaktivität.
postgres=> \x on postgres=> select * from pg_stat_activity where backend_type = 'client backend' and usename != 'cloudsqladmin'; -[ RECORD 1 ]----+----------------------------------------------------------------------------------------------------- datid | 14052 datname | postgres pid | 74750 usesysid | 16389 usename | postgres application_name | psql client_addr | CLIENT_IP client_hostname | client_port | 51904 backend_start | 2020-09-28 07:01:30.214099+00 xact_start | 2020-09-28 07:28:48.982115+00 query_start | 2020-09-28 07:28:48.982115+00 state_change | 2020-09-28 07:28:48.982117+00 wait_event_type | wait_event | state | active backend_xid | backend_xmin | 88513 query | select * from pg_stat_activity where backend_type = 'client backend' and usename != 'cloudsqladmin'; backend_type | client backend postgres=>
Monitoring einer langen Transaktion
Fragen Sie die dynamische Ansicht pg_stat_activity ab, um langfristige Transaktionen zu finden, die zu Leistungsproblemen führen können. Sie können lang andauernde Abfragen ermitteln, indem Sie entsprechende Filter auf Spalten wie query_start und state anwenden.
Monitoring von Sperren
Sie können Datenbanksperren in der dynamischen Ansicht pg_locks überwachen. In dieser Ansicht werden Echtzeitinformationen zu Sperrenkonflikte angezeigt, die zu Leistungsproblemen führen können.
Benachrichtigungen
Sie können Benachrichtigungen zusätzlich zu Monitoring und Logging verwenden. Sie können auch Benachrichtigungen für Bedingungen erstellen.
Skalieren
Cloud SQL for PostgreSQL unterstützt sowohl vertikale als auch horizontale Skalierungsoptionen.
Sie können vertikal skalieren, indem Sie der Cloud SQL-Instanz weitere Ressourcen hinzufügen und beispielsweise die von der Instanz zugewiesene Anzahl von CPUs und Arbeitsspeicher erhöhen. Der Netzwerkdurchsatz Ihrer Instanz hängt von den Werten ab, die Sie für CPU und Arbeitsspeicher auswählen.
Cloud SQL unterstützt bis zu 30 TB Speicherplatz. Durch das Hinzufügen der Speicherkapazität erhöht sich der Durchsatz und die Laufwerk-IOPS einer Instanz in der Regel. Der Netzwerkdurchsatz einer Cloud SQL-Instanz umfasst Lese-/Schreibvorgänge Ihrer Daten (Laufwerkdurchsatz) sowie den Inhalt von Abfragen, Berechnungen und anderen Daten, die nicht in Ihrer Datenbank gespeichert sind. Es ist wichtig, diese Faktoren bei der vertikalen Skalierung Ihrer Cloud SQL-Instanz zu berücksichtigen.
Sie skalieren horizontal, indem Sie Lesereplikate erstellen. Mit Lesereplikaten können Sie Ihre Lesearbeitslasten auf separate Cloud SQL-Instanzen skalieren, ohne die Leistung und Verfügbarkeit der primären Instanz zu beeinträchtigen.
Sicherung und Wiederherstellung
Es gibt zwei Datenbanksicherungsmethoden für Cloud SQL for PostgreSQL: on demand und automatisch. Sie können jederzeit On-Demand-Sicherungen ausführen, die so lange beibehalten werden, bis Sie sie löschen. Automatische Sicherungen haben ein Sicherungszeitfenster von vier Stunden und werden sieben Tage lang aufbewahrt.
Sie können Cloud SQL for PostgreSQL-Datenbanksicherungen in derselben Instanz wiederherstellen und die vorhandenen Daten überschreiben oder in einer neuen Instanz wiederherstellen. Darüber hinaus können Sie in Cloud SQL for PostgreSQL eine PostgreSQL-Datenbank zu einem bestimmten Zeitpunkt wiederherstellen, solange die Wiederherstellung zu einem bestimmten Zeitpunkt aktiviert ist und die automatische Sicherungsoption aktiviert ist.
Cloud SQL for PostgreSQL bietet Funktionen zum Klonen von Datenbanken. Der Klon muss aus der primären Instanz erstellt werden, d. h., er kann nicht aus einem Replikat erstellt werden. Datenbanksicherungen, Wiederherstellungen und Klonen sind mit derGoogle Cloud -Console oder der gcloud CLI möglich.
Automatisierung
Mit der Cloud SQL Admin API können Sie eine Cloud SQL for PostgreSQL-Instanz vollständig automatisieren. Die Cloud SQL Admin API ist eine REST API zum Steuern verschiedener Arten von Ressourcen, wie z. B. Instanzen, Datenbanken, Nutzer, Flags, Vorgänge, SslCerts, Tiers und BackupRuns. Weitere Informationen finden Sie in der API-Dokumentation.
Nächste Schritte
- Mehr über Cloud SQL for PostgreSQL-Nutzerkonten erfahren.
- Weitere Informationen zu Cloud SQL for PostgreSQL für Oracle-Nutzer:
- Oracle-Nutzer zu Cloud SQL for PostgreSQL migrieren: Terminologie und Funktionalität
- Oracle-Nutzer zu Cloud SQL for PostgreSQL migrieren: Datentypen, Nutzer und Tabellen
- Oracle-Nutzer zu Cloud SQL for PostgreSQL migrieren: Abfragen, gespeicherte Verfahren, Funktionen und Trigger
- Oracle-Nutzer zu Cloud SQL for PostgreSQL migrieren: Sicherheit, Vorgänge, Monitoring und Logging
- Referenzarchitekturen, Diagramme und Best Practices zu Google Cloud kennenlernen. Weitere Informationen zu Cloud Architecture Center