Dieses Dokument ist Teil einer Reihe, die wichtige Informationen und Anleitungen zur Planung und Durchführung von Oracle® 11g/12c-Datenbankmigrationen zu Cloud SQL for PostgreSQL Version 12 enthält. Zusätzlich zum Teil der anfänglichen Einrichtung umfasst die Reihe die folgenden Teile:
- Oracle-Nutzer zu Cloud SQL for PostgreSQL migrieren: Terminologie und Funktionalität
- Oracle-Nutzer zu Cloud SQL for PostgreSQL migrieren: Datentypen, Nutzer und Tabellen
- Oracle-Nutzer zu Cloud SQL for PostgreSQL migrieren: Abfragen, gespeicherte Verfahren, Funktionen und Trigger
- Oracle-Nutzer zu Cloud SQL for PostgreSQL migrieren: Sicherheit, Vorgänge, Monitoring und Logging (dieses Dokument)
- Oracle Database-Nutzer und -Schemas zu Cloud SQL for PostgreSQL migrieren
Sicherheit
Dieser Abschnitt enthält Hinweise zu Verschlüsselung, Auditing und Zugriffskontrolle.
Verschlüsselung
Sowohl Oracle als auch Cloud SQL for PostgreSQL bieten Datenverschlüsselungsmechanismen, um über die grundlegende Nutzerauthentifizierung und die Verwaltung von Nutzerberechtigungen hinaus eine weitere Schutzschicht hinzuzufügen.
Verschlüsselung inaktiver Daten
Daten, die nicht in Netzwerken verschoben (gespeichert) werden, werden als "inaktive Daten" bezeichnet. Oracle bietet den TDE-Mechanismus (transparente Datenverschlüsselung), um eine Verschlüsselungsebene auf Betriebssystemebene hinzuzufügen. In Cloud SQL werden Daten mit dem 256-Bit-Advanced Encryption Standard (AES-256) oder höher verschlüsselt. Diese Datenschlüssel werden mit einem Masterschlüssel verschlüsselt, in einem sicheren Schlüsselspeicher abgelegt und regelmäßig geändert. Weitere Informationen zur Verschlüsselung inaktiver Daten finden Sie unter Verschlüsselung inaktiver Daten in Google Cloud.
Verschlüsselung während der Übertragung
Oracle bietet erweiterte Sicherheit für die Verschlüsselung von Daten über das Netzwerk. Cloud SQL verschlüsselt und authentifiziert alle Daten auf einer oder mehreren Netzwerkebenen, wenn Daten außerhalb der physischen Grenzen übertragen werden, die nicht von Google oder im Auftrag von Google kontrolliert werden. Daten, die innerhalb einer physischen Grenze übertragen werden, die von Google oder im Auftrag von Google kontrolliert wird, werden in der Regel zwar authentifiziert, aber nicht standardmäßig verschlüsselt. Sie können wählen, welche zusätzlichen Sicherheitsmaßnahmen auf der Grundlage Ihres Bedrohungsmodells angewendet werden sollen. Beispielsweise können Sie für Intra-Zonen-Verbindungen zu Cloud SQL SSL konfigurieren. Informationen zur Verschlüsselung bei der Übertragung finden Sie unter Verschlüsselung bei der Übertragung in Google Cloud.
Audit
Oracle bietet verschiedene Auditing-Methoden (z. B. ein standardmäßiges und detailliertes Auditing). Im Gegensatz dazu kann das Auditing in Cloud SQL for PostgreSQL mit folgenden Mitteln durchgeführt werden:
- pgAudit-Erweiterung. Erfassen und verfolgen Sie SQL-Vorgänge, die für eine bestimmte Datenbankinstanz ausgeführt werden.
- Cloud-Audit-Logs. Verwaltungs- und Wartungsvorgänge für eine Cloud SQL for PostgreSQL-Instanz prüfen.
Zugriffssteuerung
Nutzer können eine Verbindung zur Cloud SQL for PostgreSQL-Instanz herstellen, indem sie einen PostgreSQL-Client mit einer autorisierten statischen IP-Adresse oder einen Cloud SQL-Proxy verwenden, wie bei jeder anderen Datenbankverbindung. Für andere Verbindungsquellen wie App Engine oder Compute Engine haben Nutzer mehrere Optionen, z. B. die Verwendung des Cloud SQL-Proxys. Weitere Informationen zu diesen Optionen finden Sie unter Instanzzugriffssteuerung.
Cloud SQL for PostgreSQL ist in Identity and Access Management (IAM) eingebunden. Es bietet vordefinierte Rollen, mit denen Sie den Zugriff auf Ihre Cloud SQL-Ressourcen steuern können. Mit diesen Rollen können IAM-Nutzer verschiedene Verwaltungsvorgänge wie Neustarts von Instanzen, Sicherungen und Failovers einleiten. Weitere Informationen finden Sie unter Projektzugriffssteuerung.
Vorgänge
Dieser Abschnitt enthält eine Anleitung zu Export- und Importvorgängen, Sicherung und Wiederherstellung auf Instanzebene sowie Standby-Instanzen für schreibgeschützte Vorgänge und die Implementierung der Notfallwiederherstellung.
Export und Import
Die Hauptmethode von Oracle für logische Export- und Importvorgänge ist die Verwendung des Dienstprogramms Data Pump unter Verwendung der Befehle EXPDP/IMPDP (eine ältere Version der Export-/Importfunktion von Oracle enthielt die Befehle exp/imp). Die entsprechenden Befehle von Cloud SQL for PostgreSQL sind die pg_dump- und pg_restore-Dienstprogramme, die Dumpdateien generieren und dann auf Datenbank- oder Objektebene importieren (einschließlich des ausschließlichen Exportierens und Importierens von Metadaten).
Es gibt keine direkte Cloud SQL for PostgreSQL-Entsprechung für das Oracle-Dienstprogramm DBMS_DATAPUMP. Die Oracle-Methode zur Anwendung von EXPDP/IMPDP interagiert direkt mit dem Paket DBMS_DATAPUMP. Verwenden Sie zur Konvertierung von Oracle DBMS_DATAPUMP PL/SQL-Code alternativen Code (z. B. Bash und Python), um logische Elemente und die Cloud SQL for PostgreSQL-Programme pg_dump und pg_restore zur Ausführung von Export-/Importvorgängen zu implementieren.
Mit Oracle SQL*Loader können externe Dateien in Datenbanktabellen geladen werden. SQL*Loader kann eine Konfigurationsdatei verwenden, die sogenannte Kontrolldatei. Diese enthält die von SQL*Loader verwendeten Metadaten, um zu bestimmen, wie Daten geparst und in die Oracle-Datenbank geladen werden sollen. SQL*Loader unterstützt sowohl feste als auch variable Quelldateien.
Die Dienstprogramme pg_dump und pg_restore werden auf Clientebene ausgeführt und remote mit der Cloud SQL for PostgreSQL-Instanz verbunden. Dumpdateien werden clientseitig erstellt. Zum Laden externer Dateien in Cloud SQL for PostgreSQL verwenden Sie den Befehl COPY von der psql-Client-Schnittstelle oder Sie verwenden Dataflow oder Dataproc. In diesem Abschnitt liegt der Fokus auf dem Befehl COPY von Cloud SQL for PostgreSQL, der eine direktere Entsprechung zum SQL*Loader-Dienstprogramm von Oracle ist.
Für komplexere Datenladevorgänge in Ihre Cloud SQL for PostgreSQL-Datenbank sollten Sie eventuell Dataflow oder Dataproc verwenden, die einen ETL-Prozess erstellen.
Weitere Informationen zu Dataflow finden Sie in der Dataflow-Dokumentation. Weitere Informationen zu Dataproc finden Sie in der Dataproc-Dokumentation.
pg_dump
Das Clientdienstprogramm pg_dump führt konsistente Sicherungen und Ausgaben im Skript- oder Archivdateiformat durch. Das Skript-Dump ist eine Reihe von SQL-Anweisungen, die ausgeführt werden können, um die ursprünglichen Definitionen der Datenbankobjekte und der Tabellendaten zu reproduzieren. Diese SQL-Anweisungen können für die Wiederherstellung an jeden PostgreSQL-Client gesendet werden. Sicherungen in Archivdateiformaten müssen mit pg_restore während der Wiederherstellung verwendet werden. Mit Sicherungen können jedoch ausgewählte Objekte wiederhergestellt werden und sie sind auf verschiedene Architekturen ausgelegt.
Verwendung:
-- Single database backup & specific tables backup # pg_dump database_name > outputfile.sql # pg_dump -t table_name database_name > outputfile.sql -- Dump all tables in a given schema with a prefix and ignore a given table # pg_dump -t 'schema_name.table_prefixvar>*' -T schema_name.ignore_table database_name > outputfile.sql -- Backup metadata only - Schema only # pg_dump -s database_name > metadata.sql -- Backup in custom-format archive pg_dump -Fc database_name > outputfile.dump
pg_restore
Das Clientprogramm pg_restore stellt eine PostgreSQL-Datenbank aus einem Archiv wieder her, das von pg_dump erstellt wurde. Wenn kein Datenbankname angegeben ist, gibt pg_restore ein Skript aus, in dem die SQL-Befehle enthalten sind, die für die Neuerstellung der Datenbank ähnlich wie bei pg_dump erforderlich sind.
Verwendung:
-- Connect to an existing database and restore the backup archive
pg_restore -d database_name outputfile.dump
-- Create and restore the database from the backup archive
pg_restore -C -d database_name outputfile.dump
psql-COPY-Befehl
psql ist eine Befehlszeilen-Clientschnittstelle zu Cloud SQL for PostgreSQL. Mit dem Befehl COPY liest psql die Datei, die in den Befehlsargumenten angegeben ist, und leitet die Daten zwischen dem Server und dem lokalen Dateisystem weiter.
Verwendung:
-- Connect to an existing database and restore the backup archive psql -p 5432 -U username -h cloud_sql_instance_ip -d database_name -c "\copy emps from '/opt/files/inputfile.csv' WITH csv;" -W
Cloud SQL for PostgreSQL-Export/Import:
Die folgenden Dokumentationslinks zeigen, wie und Google Cloud CLI für die Interaktion mit der Cloud SQL-Instanz und mit Cloud Storage verwendet werden, um Export- und Importvorgänge durchzuführen.
Auf Instanzebene sichern und wiederherstellen
In Cloud SQL werden Sicherungs- und Wiederherstellungsaufgaben über automatische und On-Demand-Datenbanksicherungen durchgeführt.
Sicherungen bieten die Möglichkeit zur Wiederherstellung Ihrer Cloud SQL-Instanz, um verlorene Daten zurückzuholen oder um ein Problem in Ihrer Instanz zu beheben. Es wird empfohlen, automatische Sicherungen für alle Instanzen zu aktivieren, die Daten enthalten, die Sie vor Verlust oder Beschädigung schützen möchten.
Sie können jederzeit eine Sicherung erstellen. Dies ist nützlich, wenn Sie einen riskanten Vorgang in Ihrer Datenbank ausführen oder wenn Sie eine Sicherung benötigen und nicht auf den nächsten Sicherungszeitraum warten möchten. Sie können bedarfsorientierte Sicherungen für jede Instanz erstellen, unabhängig davon, ob automatische Sicherungen für diese Instanz aktiviert sind oder nicht.
On-Demand-Sicherungen werden nicht wie automatische Sicherungen automatisch gelöscht. Sie bleiben erhalten, bis sie oder ihre Instanz gelöscht werden. Da sie nicht automatisch gelöscht werden, können bedarfsorientierte Sicherungen langfristig Auswirkungen auf Ihre Abrechnungsgebühren haben, wenn Sie sie nicht löschen.
Beim Aktivieren einer automatischen Sicherung geben Sie einen vierstündigen Sicherungszeitraum an. Die Sicherung wird in diesem Zeitfenster gestartet. Planen Sie Sicherungen nach Möglichkeit so, dass sie durchgeführt werden, wenn Ihre Instanz die geringste Aktivität aufweist. Wenn Ihre Daten seit der letzten Sicherung nicht geändert wurden, wird keine Sicherung erstellt.
Cloud SQL speichert bis zu 7 automatische Sicherungen pro Instanz. Für den benötigten Speicherplatz für Sicherungen gilt ein vergünstigter Tarif, abhängig von der Region, in der die Sicherungen gespeichert werden. Weitere Informationen zur Preisliste finden Sie unter Preise für Cloud SQL for PostgreSQL.
Mithilfe der Cloud SQL for PostgreSQL-Datenbankinstanzwiederherstellung können Sie zur selben Instanz wiederherstellen, vorhandene Daten überschreiben oder eine andere Instanz wiederherstellen. Mit Cloud SQL for PostgreSQL können Sie eine PostgreSQL-Datenbank auch für einen bestimmten Zeitpunkt mit aktivierter automatischer Sicherung wiederherstellen.
Weitere Informationen zum Erstellen oder Verwalten von On-Demand- und automatischen Sicherungen finden Sie unter On-Demand- und automatische Sicherungen erstellen und verwalten.
In der folgenden Tabelle sind die häufigsten Sicherungs- und Wiederherstellungsvorgänge in Oracle und ihre Entsprechungen in Cloud SQL for PostgreSQL aufgeführt:
| Beschreibung | Oracle (Recovery Manager – RMAN) |
Cloud SQL for PostgreSQL |
|---|---|---|
| Geplante automatische Sicherungen | Erstellen Sie einen DBMS_SCHEDULER-Job, der Ihr RMAN-Skript nach einem festgelegten Zeitplan ausführt. |
gcloud sql instances patch INSTANCE_NAME --backup-start-time HH:MM
|
| Manuelle vollständige Datenbanksicherungen | BACKUP DATABASE PLUS ARCHIVELOG;
|
gcloud sql backups create --async --instance INSTANCE_NAME
|
| Datenbank wiederherstellen | RUN
|
gcloud sql backups list --instance INSTANCE_NAME
|
| Inkrementell und differenziell | BACKUP INCREMENTAL LEVEL 0 DATABASE;
|
Alle Sicherungen werden inkrementell erstellt und es gibt keine Option zur Auswahl eines inkrementellen Typs. |
| Inkrementell und kumulativ | BACKUP INCREMENTAL LEVEL 0 CUMULATIVE DATABASE;
|
Alle Sicherungen werden inkrementell erstellt und es gibt keine Option zur Auswahl eines inkrementellen Typs. |
| Datenbank für einen bestimmten Zeitpunkt wiederherstellen | RUN
|
gcloud sql instances clone SOURCE_INSTANCE_NAME NEW_INSTANCE_NAME \
|
| Datenbank-Archivlogs sichern | BACKUP ARCHIVELOG ALL;
|
Nicht unterstützt. |
Standby-Instanzen für schreibgeschützte Vorgänge und die Implementierung der Notfallwiederherstellung
Mit Oracle Active Data Guard kann eine Standby-Instanz als schreibgeschützter Endpunkt dienen, während neue Daten weiterhin über die Redo- und Archivierungslogs angewendet werden. Sie können auch Oracle GoldenGate verwenden, um eine zusätzliche Instanz mit Lesezugriff zu aktivieren, während Datenänderungen in Echtzeit angewendet werden. Dies dient als CDC-Lösung (Change Data Capture).
Cloud SQL for PostgreSQL verwendet eine Standby-Instanz für Hochverfügbarkeit. Diese Instanz wird über die Replikation auf Laufwerksebene mit der primären Instanz synchronisiert. Im Gegensatz zu Active Data Guard ist es nicht für Lese- oder Schreibvorgänge geöffnet. Wenn die primäre Instanz ausfällt oder ungefähr 60 Sekunden lang nicht reagiert, wird die primäre Instanz automatisch per Failover auf die Standby-Instanz übertragen. Innerhalb weniger Sekunden wechseln die Rollen und die neue primäre Rolle übernimmt.
Cloud SQL for PostgreSQL bietet auch Lesereplikate, mit denen Sie Leseanfragen skalieren können. Sie sind so konzipiert, dass Lesevorgänge von der primären Instanz ausgelagert werden, statt als Standby-Instanz für die Notfallwiederherstellung zu dienen. Im Unterschied zur Standby-Instanz werden Lesereplikate asynchron mit der primären Instanz synchronisiert. Sie können sich in einer anderen Zone als die primäre Instanz und in einer anderen Region befinden. Sie können ein Lesereplikat mit derGoogle Cloud -Console oder der gcloud CLI erstellen. Beachten Sie, dass für einige Vorgänge ein Neustart der Instanz erforderlich ist (z. B. das Hinzufügen von Hochverfügbarkeit zu einer vorhandenen primären Instanz).
Logging und Monitoring
Die Warn-Logdatei von Oracle ist die Hauptquelle für die Identifizierung allgemeiner System- und Fehlerereignisse. Sie ist hilfreich, um den Lebenszyklus von Oracle-Datenbankinstanzen zu verstehen und enthält hauptsächlich Ereignisse fehlgeschlagener Fehlerbehebungen und Fehlerereignisse.
Das Oracle-Benachrichtigungslog enthält Informationen zu Folgendem:
- Fehler und Warnungen von Oracle-Datenbankinstanzen (
ORA-+ Fehlernummer) - Ereignisse beim Starten und Herunterfahren einer Oracle-Datenbankinstanz
- Netzwerk- und Verbindungsprobleme
- Änderungsereignisse in Redo-Logs von Datenbanken
- Oracle-Trace-Dateien können mit einem Link zu weiteren Details zu einem bestimmten Datenbankereignis erwähnt werden.
Oracle bietet dedizierte Logdateien für verschiedene Dienste wie LISTENER, ASM und Enterprise Manager (OEM) an, die keine entsprechenden Komponenten in Cloud SQL for PostgreSQL haben.
Vorgangslogs von Cloud SQL for PostgreSQL ansehen
Cloud Logging ist die Hauptplattform zum Anzeigen aller Logeinträge in postgres.log (Äquivalent von alert.log in Oracle). Sie können nach Logereignisebene filtern, z. B. "Kritisch", "Fehler" oder "Warnung". Außerdem können die Ereignisse nach Zeiträumen und mit freier Texteingabe gefiltert werden.
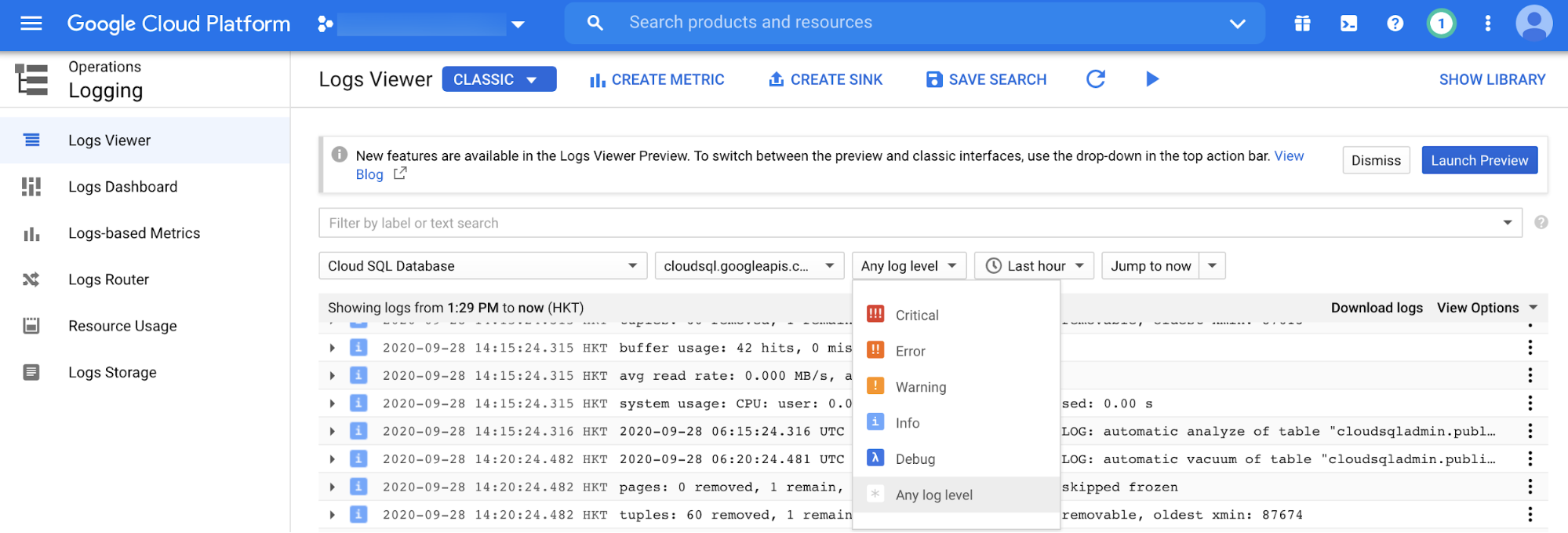
Cloud SQL for PostgreSQL-Datenbankinstanz-Monitoring
Die wichtigsten Monitoring-Dashboards von Oracle sind Bestandteile der OEM- und Grid/Cloud Control-Produkte (z. B. Top Activity Graphs) und nützlich für das Echtzeit-Monitoring von Datenbankinstanzen auf Sitzungs- oder SQL-Anweisungsebene. Cloud SQL for PostgreSQL bietet ähnliche Monitoring-Funktionen über dieGoogle Cloud Console. Sie können sich aggregierte Informationen zu den Cloud SQL for PostgreSQL-Datenbankinstanzen mit mehreren Monitoringmesswerten wie CPU-Auslastung, Speichernutzung, Lese-/Schreibvorgänge, eingehende/ausgehende Byte, aktive Verbindungen und mehr anzeigen lassen.
Cloud Logging unterstützt zusätzliche Monitoringmesswerte für Cloud SQL for PostgreSQL. Der folgende Screenshot zeigt eine Cloud SQL für PostgreSQL-Abfragegrafik für die letzten 12 Stunden.
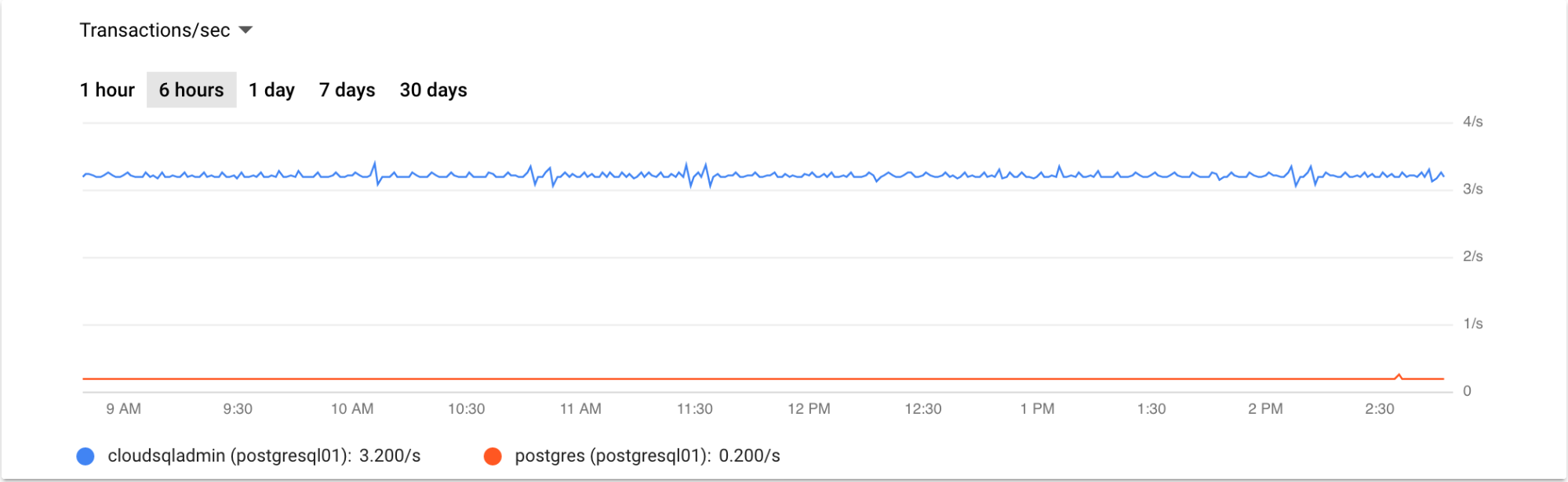
Monitoring von Cloud SQL for PostgreSQL-Lesereplikaten
Sie können Lesereplikate auf dieselbe Weise überwachen, wie Sie die primäre Instanz überwachen. Dazu verwenden Sie die Google Cloud Monitoringmesswerte der Console (wie oben beschrieben). Darüber hinaus gibt es einen dedizierten Monitoring-Messwert zum Überwachen der Replikationsverzögerung. Dieser gibt Auskunft über die Zeitverzögerung zwischen der primären Instanz und der Instanz des Lesereplikats in Byte (kann in der Google Cloud Console im Tab mit der Übersicht zur Lesereplikatinstanz überwacht werden).
Mit der gcloud CLI können Sie den Replikationsstatus abrufen:
gcloud sql instances describe REPLICA_NAME
Sie können das Replikationsmonitoring auch mithilfe von Befehlen eines PostgreSQL-Clients durchführen, der den Status der primären und der Standby-Datenbank angibt.
Mit der folgenden SQL-Anweisung können Sie den Status des Lesereplikats prüfen:
postgres=> select * from pg_stat_replication;
Cloud SQL for PostgreSQL-Monitoring
In diesem Abschnitt werden grundlegende Monitoringmethoden von Cloud SQL for PostgreSQL beschrieben, die als Routineaufgaben gelten, die von einem Datenbankadministrator (DBA) wie Oracle oder Cloud SQL for PostgreSQL ausgeführt werden.
Monitoring einer Sitzung
Die Sitzungsüberwachung in Oracle erfolgt durch Abfrage der dynamischen Leistungsansichten, die als "V$-Ansichten" bezeichnet werden. Die Ansichten V$SESSION und V$PROCESS werden in der Regel verwendet, um mithilfe von SQL-Anweisungen Echtzeitinformationen zur aktuellen Datenbankaktivität abzurufen. Sie können die Sitzungsaktivität durch Abfragen der dynamischen Ansicht pg_stat_activity überwachen:
postgres=> select * from pg_stat_activity;
Monitoring einer langen Transaktion
Sie können lange laufende Abfragen ermitteln, indem Sie in der dynamischen Ansicht pg_stat_activity entsprechende Filter für Spalten wie query_start und state anwenden.
Sperrungsmonitoring
Datenbanksperrungen können Sie mit der dynamischen Ansicht pg_locks überwachen. In dieser Ansicht werden Echtzeitinformationen zu Sperrvorgängen angezeigt, die zu Leistungsproblemen führen können.
Nächste Schritte
- Mehr über Cloud SQL for PostgreSQL-Nutzerkonten erfahren.
- Referenzarchitekturen, Diagramme und Best Practices zu Google Cloud kennenlernen. Weitere Informationen zu Cloud Architecture Center