Nutzung
|
Hierarchie
aggregate_table |
Standardwert
KeineAkzeptiert
Einen Namen für die zusammengefasste Tabelle, den Unterparameter query zum Definieren der Tabelle und den Unterparameter materialization zum Definieren der Persistenzstrategie der Tabelle
Sonderregeln
|
Definition
Mit dem Parameter aggregate_table werden zusammengefasste Tabellen erstellt, mit denen die Anzahl der erforderlichen Abfragen für große Tabellen in Ihrer Datenbank minimiert wird.
Looker ermittelt mithilfe der Logik für aggregierte Bekanntheit die kleinste und effizienteste zusammengefasste Tabelle in Ihrer Datenbank, um eine Abfrage auszuführen und gleichzeitig die Richtigkeit zu gewährleisten. Eine Übersicht und Strategien zum Erstellen aggregierter Tabellen finden Sie auf der Dokumentationsseite Zusammengefasste Daten zur Steigerung der Bekanntheit.
Für sehr große Tabellen in Ihrer Datenbank können Sie kleinere aggregierte Datentabellen erstellen, die nach verschiedenen Attributkombinationen gruppiert sind. Die zusammengefassten Tabellen dienen als Zusammenfassungen oder Zusammenfassungstabellen, die Looker nach Möglichkeit anstelle der ursprünglichen großen Tabelle für Abfragen verwenden kann.
Aggregierte Tabellen müssen in Ihrer Datenbank beibehalten werden, um für die aggregierte Bekanntheit zugänglich zu sein. Die Persistenzstrategie wird im Parameter
materializationder zusammengefassten Tabelle angegeben. Da Aggregattabellen eine Art von persistenter abgeleiteter Tabelle (PDT) sind, haben zusammengefasste Tabellen dieselben Datenbankverbindungs- und Dialektanforderungen wie PDTs. Weitere Informationen finden Sie auf der Dokumentationsseite Abgeleitete Tabellen in Looker.
Nachdem Sie die zusammengefassten Tabellen erstellt haben, können Sie in der Funktion „Erkunden“ Abfragen ausführen, um zu sehen, welche aggregierten Tabellen Looker verwendet. Weitere Informationen finden Sie auf der Dokumentationsseite Zusammengefasste Markenbekanntheit im Abschnitt Bestimmen, welche zusammengefasste Tabelle für eine Abfrage verwendet wird.
Im Abschnitt Fehlerbehebung auf der Dokumentationsseite zu aggregierter Bekanntheit finden Sie häufige Gründe für die Verwendung von zusammengefassten Tabellen.
Aggregierte Tabelle in LookML definieren
Statt LookML von Grund auf neu zu erstellen, können Sie mit der Funktion „Erkunden“ oder einem Dashboard eine zusammengefasste Tabelle für LookML erstellen. Weitere Informationen finden Sie auf dieser Seite in den Abschnitten Aggregierte Tabellen-LookML von einem explorativen Analysetool abrufen und Zusammengefasste Tabelle von LookML aus einem Dashboard abrufen.
Jeder aggregate_table-Parameter muss einen eindeutigen Namen für einen explore-Wert haben.
Der Parameter aggregate_table hat die Unterparameter query und materialization.
query
Der Parameter query definiert die Abfrage für die zusammengefasste Tabelle, einschließlich der zu verwendenden Dimensionen und Messwerte. Der Parameter query enthält die folgenden Unterparameter:
Dieser Abschnitt bezieht sich auf den Parameter
query, der Teil vonaggregate_tableist.
querykann auch als Teil einerexploreverwendet werden, wie auf der Dokumentationsseite zum Parameterquerybeschrieben.
| Parametername | Beschreibung | Beispiel |
|---|---|---|
dimensions |
Eine durch Kommas getrennte Liste der Dimensionen aus dem Tab „Erkunden“, der in die zusammengefasste Tabelle aufgenommen werden soll. Das Feld dimensions hat folgendes Format: dimensions: [dimension1, dimension2, ...]
Jede Dimension in dieser Liste muss als dimension in der Ansichtsdatei für die Funktion „Erkunden“ definiert sein. Wenn Sie ein Feld hinzufügen möchten, das als filter-Feld in der Abfrage „Erkunden“ definiert ist, können Sie es in die Abfrage der zusammengefassten Tabelle in die Liste filters aufnehmen.
|
dimensions: |
measures |
Eine durch Kommas getrennte Liste der Messwerte vom Tab „Erkunden“, die in die zusammengefasste Tabelle aufgenommen werden sollen. Das Feld „measures“ hat folgendes Format: measures: [measure1, measure2, ...]Informationen zu den für die aggregierte Bekanntheit unterstützten Messtypen finden Sie auf der Dokumentationsseite Zusammengefasste Markenbekanntheit im Abschnitt Faktoren für Messwerttypen. |
measures: |
filters |
Optional kann query ein Filter hinzugefügt werden. Filter werden der WHERE-Klausel des SQL-Codes hinzugefügt, mit dem die zusammengefasste Tabelle generiert wird.Im Feld filters wird folgendes Format verwendet: filters: [field1: "value1", field2: "value2", ...]
Informationen dazu, wie Filter die Verwendung Ihrer zusammengefassten Tabelle verhindern können, finden Sie auf der Dokumentationsseite Zusammengefasste Markenbekanntheit im Abschnitt Filterfaktoren. |
filters: [orders.country: "United States", orders.state: "California"]
|
sorts |
Optional: Sortierfelder und Sortierrichtung (aufsteigend oder absteigend) für query. Das Feld sorts hat folgendes Format: sorts: [field1: asc|desc, field2: asc|desc, ...]
|
[orders.country: asc, orders.state: desc] |
timezone |
Legt die Zeitzone für query fest. Wenn keine Zeitzone angegeben ist, führt die zusammengefasste Tabelle keine Zeitzonenkonvertierung durch. Stattdessen wird die Zeitzone der Datenbank verwendet.
Informationen zum Festlegen der Zeitzone, damit Ihre aggregierte Tabelle als Abfragequelle verwendet wird, finden Sie auf der Dokumentationsseite Zusammengefasste Markenbekanntheit im Abschnitt Faktoren für Zeitzonen. Die IDE schlägt den Zeitzonenwert automatisch vor, wenn Sie den Parameter timezone in der IDE eingeben. In der IDE wird auch eine Liste der unterstützten Zeitzonenwerte im Schnellhilfe-Bereich angezeigt. |
timezone: America/Los_Angeles |
materialization
Der Parameter materialization gibt die Persistenzstrategie für Ihre zusammengefasste Tabelle sowie andere Optionen für Verteilung, Partitionierung, Indexe und Clustering an, die von Ihrem SQL-Dialekt unterstützt werden können.
Für die zusammengefasste Wahrnehmung muss die zusammengefasste Tabelle in der Datenbank dauerhaft beibehalten werden. Eine zusammengefasste Tabelle muss eine der folgenden Persistenzstrategien haben:
datagroup_triggersql_trigger_valuepersist_for(nicht empfohlen)
Je nach SQL-Dialekt werden für die zusammengefasste Tabelle möglicherweise weitere materialization-Optionen unterstützt:
Verwenden Sie zum Erstellen einer inkrementellen zusammengefassten Tabelle schließlich die folgenden materialization-Unterparameter:
datagroup_trigger
Verwenden Sie den Parameter datagroup_trigger, um die erneute Generierung der aggregierten Tabelle basierend auf einer vorhandenen Datengruppe auszulösen, die in der Modelldatei definiert ist:
explore: event {
aggregate_table: monthly_orders {
materialization: {
datagroup_trigger: order_datagroup
}
query: {
...
}
}
...
}
sql_trigger_value
Verwenden Sie den Parameter sql_trigger_value, um die Neugenerierung der aggregierten Tabelle anhand einer von Ihnen bereitgestellten SQL-Anweisung auszulösen. Wenn sich das Ergebnis der SQL-Anweisung vom vorherigen Wert unterscheidet, wird die Tabelle neu generiert. Diese sql_trigger_value-Anweisung löst eine Neugenerierung aus, wenn sich das Datum ändert:
explore: event {
aggregate_table: monthly_orders {
materialization: {
sql_trigger_value: SELECT CURDATE() ;;
}
query: {
...
}
}
...
}
persist_for
Der Parameter persist_for wird auch für zusammengefasste Tabellen unterstützt. Die Strategie „persist_for“ bietet jedoch möglicherweise nicht die beste Leistung, um die Bekanntheit zu steigern. Das liegt daran, dass Looker das Alter der Tabelle mit der Einstellung persist_for prüft, wenn ein Nutzer eine Abfrage ausführt, die auf einer persist_for-Tabelle basiert. Wenn die Tabelle älter als die Einstellung persist_for ist, wird die Tabelle vor der Ausführung der Abfrage neu generiert. Wenn das Alter kleiner als persist_for ist, wird die vorhandene Tabelle verwendet. Solange ein Nutzer keine Abfrage innerhalb des Zeitraums persist_for ausführt, muss die zusammengefasste Tabelle neu erstellt werden, bevor sie für die aggregierte Markenbekanntheit verwendet werden kann.
explore: event {
aggregate_table: monthly_orders {
materialization: {
persist_for: "90 minutes"
}
query: {
...
}
}
...
}
Wenn Sie die Einschränkungen nicht kennen und einen bestimmten Anwendungsfall für die persist_for-Implementierung haben, ist es besser, datagroup_trigger oder sql_trigger_value als Persistenzstrategie für zusammengefasste Tabellen zu verwenden.
cluster_keys
Mit dem Parameter cluster_keys können Sie geclusterten Spalten zu partitionierten Tabellen in BigQuery oder Snowflake hinzufügen. Beim Clustering werden die Daten in einer Partition basierend auf den Werten in den geclusterten Spalten sortiert und die geclusterten Spalten werden in Speicherblöcken von optimaler Größe organisiert.
Für BigQuery wird das Clustering für zusammengefasste Tabellen unterstützt, die auch mit dem Parameter
partition_keyspartitioniert sind.
Weitere Informationen finden Sie auf der Dokumentationsseite zum Parameter cluster_keys.
distribution
Mit dem Parameter distribution können Sie die Spalte aus einer aggregierten Tabelle angeben, auf die ein Verteilungsschlüssel angewendet werden soll. distribution funktioniert nur mit Redshift- und Aster-Datenbanken. Verwenden Sie für andere SQL-Dialekte wie MySQL und Postgres stattdessen indexes.
Weitere Informationen finden Sie auf der Dokumentationsseite zum Parameter distribution.
distribution_style
Mit dem Parameter distribution_style können Sie angeben, wie die Abfrage für eine zusammengefasste Tabelle auf die Knoten in einer Redshift-Datenbank verteilt wird:
distribution_style: allgibt an, dass alle Zeilen vollständig in jeden Knoten kopiert werden.- Mit
distribution_style: evenwird eine gleichmäßige Verteilung festgelegt, sodass Zeilen auf unterschiedliche Knoten verteilt werden.
Wenn Sie die Abfrage anhand eindeutiger Werte in einer bestimmten Spalte (Verteilungsschlüssel) verteilen möchten, können Sie den Parameter
distributionverwenden.
Weitere Informationen finden Sie auf der Dokumentationsseite zum Parameter distribution_style.
indexes
Mit dem Parameter indexes können Sie Indexe auf die Spalten einer aggregierten Tabelle anwenden.
Weitere Informationen finden Sie auf der Dokumentationsseite zum Parameter indexes.
partition_keys
Der Parameter partition_keys definiert ein Array von Spalten, nach denen die zusammengefasste Tabelle partitioniert wird. partition_keys unterstützt Datenbankdialekte, die Spalten partitionieren können. Wenn eine Abfrage ausgeführt wird, die nach einer partitionierten Spalte gefiltert wird, scannt die Datenbank nur die Partitionen, die die gefilterten Daten enthalten, und nicht die gesamte Tabelle. partition_keys wird nur mit Presto- und BigQuery-Dialekten unterstützt.
Weitere Informationen finden Sie auf der Dokumentationsseite zum Parameter partition_keys.
sortkeys
Mit dem Parameter sortkeys können Sie eine oder mehrere Spalten einer aggregierten Tabelle angeben, auf die ein regulärer Sortierschlüssel angewendet werden soll.
Weitere Informationen finden Sie auf der Dokumentationsseite zum Parameter sortkeys.
increment_key
Sie können inkrementelle PDTs in Ihrem Projekt erstellen, wenn Ihr Dialekt sie unterstützt. Eine inkrementelle PDT ist eine persistente abgeleitete Tabelle (PDT), die von Looker erstellt wird, indem neue Daten an die Tabelle angehängt werden, anstatt die Tabelle vollständig neu zu erstellen. Weitere Informationen finden Sie auf der Dokumentationsseite Inkrementelle PDTs.
Aggregierte Tabellen sind eine Art von PDT und können inkrementell erstellt werden, indem der Parameter increment_key hinzugefügt wird. Der Parameter increment_key gibt das Zeitintervall an, für das aktuelle Daten abgefragt und an die zusammengefasste Tabelle angefügt werden sollen.
Weitere Informationen finden Sie auf der Dokumentationsseite zum Parameter increment_key.
increment_offset
Der Parameter increment_offset definiert die Anzahl der vorherigen Zeiträume (auf Basis des Detaillierungsgrads des Schlüssels), die beim Anhängen von Daten an die zusammengefasste Tabelle neu erstellt werden. Der Parameter increment_offset ist für inkrementelle PDTs und zusammengefasste Tabellen optional.
Weitere Informationen finden Sie auf der Dokumentationsseite zum Parameter increment_offset.
Zusammengefasste Tabelle „LookML“ aus einer Funktion „Erkunden“ abrufen
Als Verknüpfung können Looker-Entwickler eine Explorative Abfrage erstellen, um eine zusammengefasste Tabelle zu erstellen, und dann LookML in das LookML-Projekt kopieren:
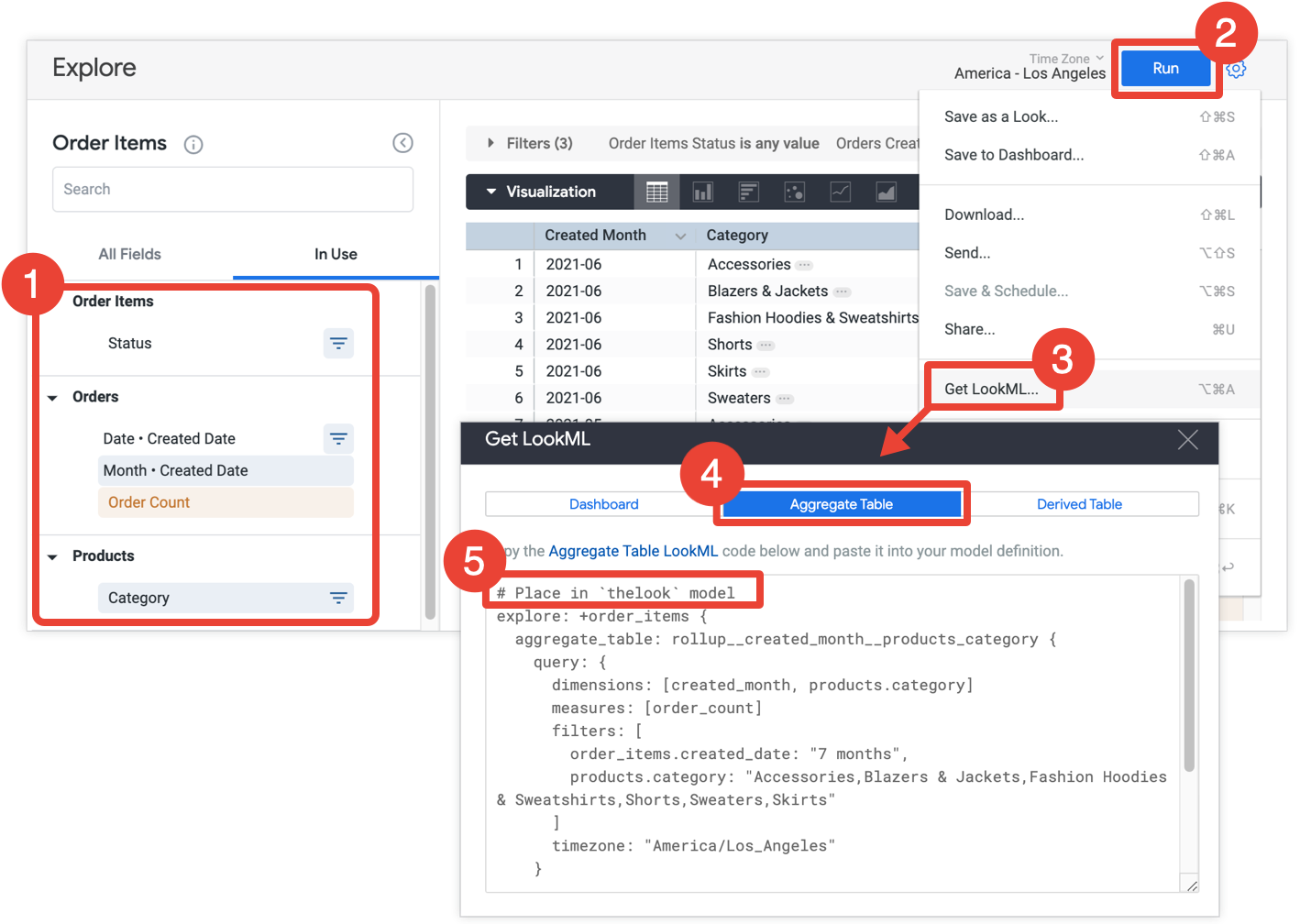
- Wählen Sie unter „Erkunden“ alle Felder und Filter aus, die Sie in die zusammengefasste Tabelle aufnehmen möchten.
- Klicken Sie auf Ausführen, um die Ergebnisse aufzurufen.
- Wählen Sie im Zahnrad-Menü die Option LookML aus. Diese Option ist nur für Looker-Entwickler verfügbar.
- Klicken Sie auf den Tab Aggregierte Tabelle.
- Looker bietet die Such-ML-Optimierung, mit der die zusammengefasste Tabelle der Funktion „Erkunden“ hinzugefügt wird. Kopieren Sie die LookML-Datei und fügen Sie sie in die zugehörige Modelldatei ein, die im Kommentar über dem Suchfilter „Erkunden“ angegeben ist. Wenn der Tab „Entdecken“ in einer separaten Datei mit dem Namen „Entdecken“ und nicht in einer Modelldatei definiert ist, können Sie den Suchfilter anstelle der Modelldatei in die Datei „Erkunden“ einfügen. Beide Standorte funktionieren.
Looker gibt der zusammengefassten Tabelle basierend auf den Dimensionen in „Erkunden“ einen Namen. Looker verwendet für die aggregierte Tabelle jedes Mal denselben Namen, wenn die zusammengefasste Tabelle „LookML“ für „Erkunden“ bereitgestellt wird. Achte auf andere Suchfilter für denselben Erkunden, den du möglicherweise zuvor hinzugefügt hast. Wenn Sie oder ein anderer Entwickler die zusammengefasste Tabelle LookML von einer explorativen Datenanalyse abgerufen haben, gibt Looker denselben Namen für die zusammengefasste Tabelle an. Wenn eine explorative Datenanalyse mehrere Suchfilter mit jeweils zusammengefassten Tabellen mit demselben Namen hat, überschreibt eine Suchfilter die anderen Suchfilter, wie auf der Dokumentationsseite für Such-ML-Suchfilter beschrieben.
Wenn Sie die aggregierte Tabelle in LookML ändern müssen, können Sie dies mithilfe der Parameter tun, die im Abschnitt Aggregierte Tabelle in LookML definieren auf dieser Seite beschrieben werden. Sie können die zusammengefasste Tabelle umbenennen, ohne ihre Anwendbarkeit in die ursprüngliche Abfrageabfrage zu ändern. Alle anderen Änderungen an der zusammengefassten Tabelle können sich jedoch darauf auswirken, ob Looker die zusammengefasste Tabelle für die Abfrage verwenden kann. Tipps zur Optimierung Ihrer zusammengefassten Tabellen, um sicherzustellen, dass sie für die aggregierte Bekanntheit verwendet werden, finden Sie im Abschnitt Zusammengefasste Tabellen entwerfen auf der Dokumentationsseite für die aggregierte Bekanntheit.
LookML-Code einer aggregierten Tabelle aus einem Dashboard abrufen
Eine weitere Möglichkeit für Looker-Entwickler besteht darin, die aggregierte Tabelle LookML für alle Kacheln auf einem Dashboard abzurufen und dann die LookML in das LookML-Projekt zu kopieren.
Das Erstellen von zusammengefassten Tabellen kann die Leistung eines Dashboards erheblich verbessern, insbesondere bei Kacheln, die große Datasets abfragen.
Wenn Sie die Berechtigung develop haben, können Sie LookML verwenden, um zusammengefasste Tabellen für ein Dashboard zu erstellen. Öffnen Sie dazu das Dashboard, wählen Sie im Dreipunkt-Menü des Dashboards GetML aus und klicken Sie dann auf den Tab Aggregate Tables.
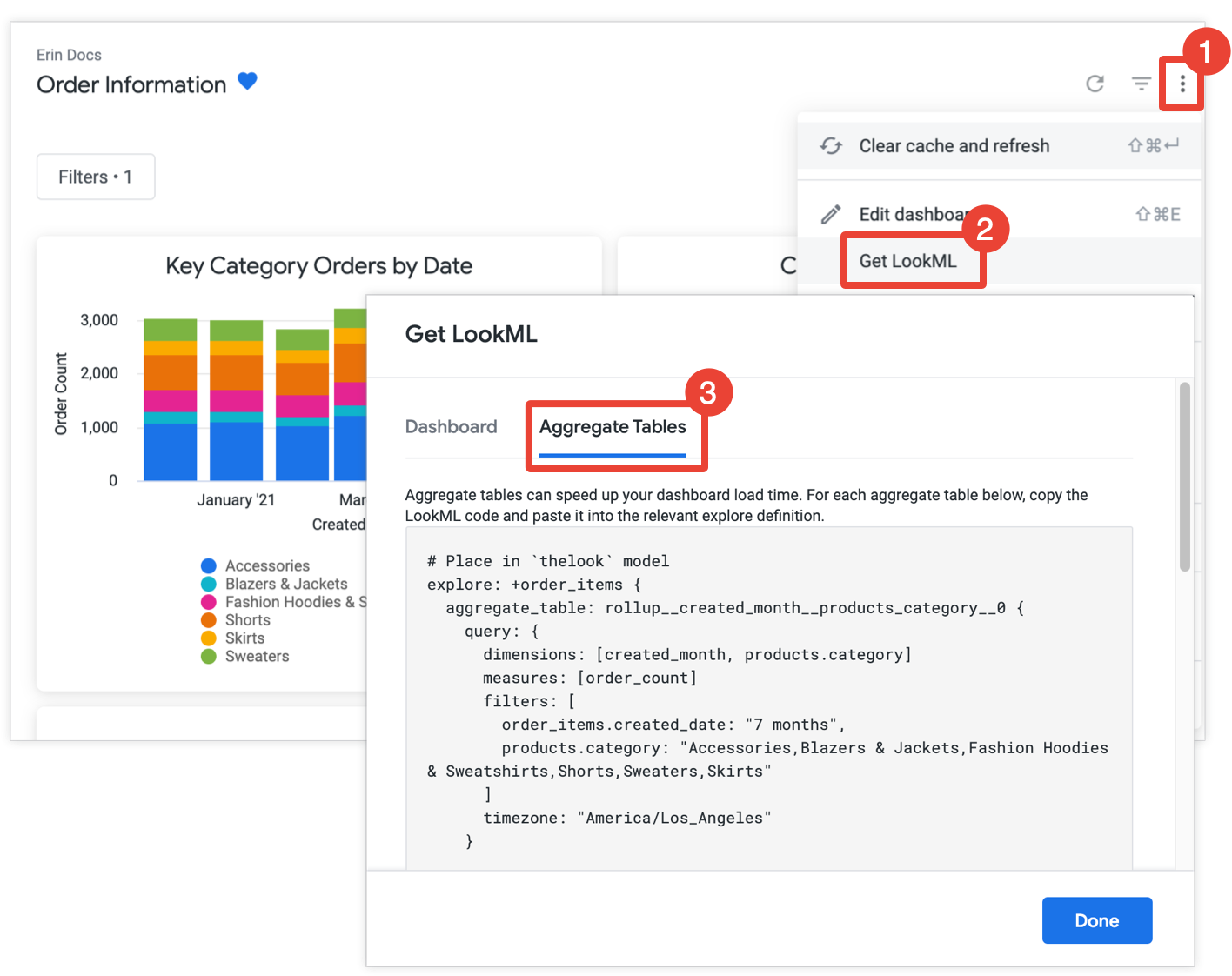
Für jede Kachel, die noch nicht mit aggregierter Bekanntheit optimiert wurde, bietet Looker die LookML für eine Suchfilterung, mit der die zusammengefasste Tabelle der Funktion hinzugefügt wird. Wenn das Dashboard mehrere Kacheln aus derselben Umgebung enthält, fasst Looker alle zusammengefassten Tabellen in eine einzige Suchfilter-Variante zusammen. Um die Anzahl der generierten zusammengefassten Tabellen zu reduzieren, ermittelt Looker, ob eine generierte zusammengefasste Tabelle für mehr als eine Kachel verwendet werden kann. Wenn ja, werden alle redundanten zusammengefassten Tabellen gelöscht, die für weniger Kacheln verwendet werden können.
Kopieren Sie jede Suchfilter-Suchfilter und fügen Sie sie in die zugehörige Modelldatei ein, die im Kommentar über dem Suchfilter angegeben ist. Wenn der Tab „Entdecken“ in einer separaten Datei mit dem Namen „Entdecken“ und nicht in einer Modelldatei definiert ist, können Sie den Suchfilter anstelle der Modelldatei in die Datei „Erkunden“ einfügen. Beide Standorte funktionieren.
Beachten Sie, dass Looker jeder aggregierten Tabelle einen Namen basierend auf den Dimensionen in der Abfrage der Kachel gibt. Looker verwendet für jede zusammengefasste Tabelle denselben Namen, wenn die zusammengefasste Tabelle LookML für eine Kachelabfrage bereitgestellt wird. Daher solltest du auch bei der Entdeckung der Kachel, die möglicherweise bereits hinzugefügt wurde, weitere Optimierungen vornehmen. Wenn Sie oder ein anderer Entwickler die zusammengefasste Tabelle „LookML“ bereits aus der Abfrage der Dashboard-Kachel abgerufen haben, gibt Looker denselben Namen für die aggregierte Tabelle an. Wenn eine explorative Datenanalyse mehrere Suchfilter mit jeweils zusammengefassten Tabellen mit demselben Namen hat, überschreibt eine Suchfilter die anderen Suchfilter, wie auf der Dokumentationsseite für Such-ML-Suchfilter beschrieben.
Wenn auf eine Kachel ein Dashboard-Filter angewendet wird, fügt Looker die Dimension des Filters der zusammengefassten Tabelle der Kachel hinzu, damit die aggregierte Tabelle für die Kachel verwendet werden kann. Das liegt daran, dass zusammengefasste Tabellen nur für eine Abfrage verwendet werden können, wenn die Filter der Abfrage auf Felder verweisen, die in der zusammengefassten Tabelle als Dimensionen verfügbar sind. Weitere Informationen finden Sie auf der Dokumentationsseite Zusammengefasste Markenbekanntheit.
Wenn Sie die aggregierte Tabelle in LookML ändern müssen, können Sie dies mithilfe der Parameter tun, die im Abschnitt Aggregierte Tabelle in LookML definieren auf dieser Seite beschrieben werden. Sie können die zusammengefasste Tabelle umbenennen, ohne ihre Anwendbarkeit auf die ursprüngliche Dashboard-Kachel zu ändern. Andere Änderungen an der aggregierten Tabelle können sich jedoch auf die Fähigkeit von Looker auswirken, die zusammengefasste Tabelle für das Dashboard zu verwenden. Tipps zur Optimierung Ihrer zusammengefassten Tabellen, um sicherzustellen, dass sie für die aggregierte Bekanntheit verwendet werden, finden Sie im Abschnitt Zusammengefasste Tabellen entwerfen auf der Dokumentationsseite für die aggregierte Bekanntheit.
Beispiel
Im folgenden Beispiel wird eine aggregierte monthly_orders-Tabelle für die event-explorative Datenanalyse erstellt. In der zusammengefassten Tabelle wird eine monatliche Anzahl von Bestellungen erstellt. Looker verwendet die zusammengefasste Tabelle für Abfragen zur Bestellanzahl, die den monatlichen Detaillierungsgrad nutzen können, z. B. Abfragen für die jährliche, vierteljährliche und monatliche Anzahl von Bestellungen.
Die zusammengefasste Tabelle wird mit der Datengruppe orders_datagroup dauerhaft eingerichtet.
Die Definition der zusammengefassten Tabelle sieht so aus:
explore: event {
aggregate_table: monthly_orders {
materialization: {
datagroup_trigger: orders_datagroup
}
query: {
dimensions: [orders.created_month]
measures: [orders.count]
filters: [orders.created_date: "1 year", orders.status: "fulfilled"]
timezone: America/Los_Angeles
}
}
}
Wichtige Punkte
Tipps zum strategischen Erstellen von zusammengefassten Tabellen finden Sie auf der Seite Zusammengefasste Tabellen im Abschnitt Aggregierte Tabellen entwerfen:
Dialektunterstützung für aggregierte Bekanntheit
Die Möglichkeit, Aggregate Awareness zu nutzen, hängt von dem Datenbankdialekt ab, den Ihre Looker-Verbindung verwendet. In der neuesten Version von Looker unterstützen die folgenden Dialekte die aggregierte Bekanntheit: