In Looker werden persistente abgeleitete Tabellen (PDTs) in das Scratch-Schema Ihrer Datenbank geschrieben. Looker bleibt bestehen und erstellt einen PDT basierend auf seiner Persistenzstrategie. Wenn die Neuerstellung einer PDT ausgelöst wird, erstellt Looker standardmäßig die ganze Tabelle neu.
Wenn Ihr Dialog inkrementelle PDT unterstützt, können Sie aktuelle Daten an die PDT anhängen, anstatt sie komplett neu zu erstellen:
Wenn Sie zum ersten Mal eine Abfrage mit einer inkrementellen PDT ausführen, erstellt Looker die ganze PDT, um die ersten Daten abzurufen. Bei einer großen Tabelle kann diese erste Erstellung sehr viel Zeit in Anspruch nehmen, wie im Falle jeder großen Tabelle. Nach dem Erstellen der ersten Tabelle sind weitere Erstellungen inkrementell und nehmen weniger Zeit in Anspruch, wenn die inkrementelle PDT strategisch eingestellt wurde.
Achten Sie außerdem darauf, dass die Quelltabelle der inkrementellen PDT für zeitbasierte Abfragen optimiert ist. Insbesondere muss die zeitbasierte Spalte, die für den inkrementellen Schlüssel verwendet wird, eine Optimierungsstrategie wie Partitionierung, Sortierschlüssel, Indexe oder eine andere für Ihren Dialekt unterstützte Optimierungsstrategie haben. Eine Optimierung der Quelltabelle wird stark empfohlen. Mit jeder Aktualisierung der inkrementellen Tabelle fragt Looker die Quelltabelle ab, um die neuesten Werte der zeitbasierten Spalte zu bestimmen, die für den Inkrementschlüssel verwendet wird. Wenn die Quelltabelle nicht für diese Abfragen optimiert ist, kann die Abfrage der aktuellen Werte von Looker langsam und teuer sein.
Wenn Ihr Dialekt inkrementelle PDT unterstützt, können Sie die folgenden PDT-Typen in inkrementelle PDTs umwandeln:
- Aggregierte Tabellen
- LookML-basierte (nativ) PDTs
SQL-basierte PDTs
Bei SQL-basierten PDTs muss die Tabellenabfrage mit dem Parameter
sqldefiniert werden, der als inkrementeller PDT verwendet wird. SQL-basierte PDTs, die mit dem Parametersql_createodercreate_processdefiniert sind, können nicht inkrementell erstellt werden. Wie Sie in Beispiel 1 auf dieser Seite sehen können, verwendet Looker einen INSERT- oder MERGE-Befehl, um die Inkremente für einen inkrementellen PDT zu erstellen. Die abgeleitete Tabelle kann nicht mit benutzerdefinierten DDL-Anweisungen (Data Definition Language) definiert werden, da Looker nicht ermitteln kann, welche DDL-Anweisungen zum Erstellen eines genauen Schritts erforderlich wären.
Inkrementelle PDT definieren
Mit den folgenden Parametern können Sie eine PDT in eine inkrementelle PDT umwandeln:
increment_key(erforderlich, um die PDT zu einer inkrementellen PDT zu machen): Definiert den Zeitraum, für den neue Einträge abgefragt werden sollen.{% incrementcondition %}Liquid Filter (erforderlich, um eine SQL-basierte PDT als inkrementellen PDT zu erstellen; gilt nicht für LookML-basierte PDT): Verbindet den Inkrementschlüssel mit der Datenbankzeitspalte, auf der der Inkrementschlüssel basiert. Weitere Informationen finden Sie auf der Dokumentationsseite zuincrement_key.increment_offset(optional): Eine Ganzzahl, die die Anzahl vorheriger Zeiträume (im Detaillierungsgrad des Schlüssels) definiert, die für jeden inkrementellen Build neu erstellt werden. Der Parameterincrement_offsetist bei verspäteten Daten nützlich, bei denen in früheren Zeiträumen möglicherweise neue Daten enthalten waren, die beim ursprünglichen Erstellen und Anhängen an die PDT nicht berücksichtigt wurden.
Auf der Dokumentationsseite zum Parameter increment_key finden Sie Beispiele, die zeigen, wie Sie aus persistenten nativen abgeleiteten Tabellen, persistenten SQL-basierten abgeleiteten Tabellen und zusammengefassten Tabellen PDTs erstellen.
Hier ist ein einfaches Beispiel einer inkrementellen LookML-basierten PDT:
view: flights_lookml_incremental_pdt {
derived_table: {
indexes: ["id"]
increment_key: "departure_date"
increment_offset: 3
datagroup_trigger: flights_default_datagroup
distribution_style: all
explore_source: flights {
column: id {}
column: carrier {}
column: departure_date {}
}
}
dimension: id {
type: number
}
dimension: carrier {
type: string
}
dimension: departure_date {
type: date
}
}
Diese Tabelle wird vollständig erstellt, wenn zum ersten Mal eine Abfrage darin erfolgt. Danach wird die PDT in Schritten von einem Tag (increment_key: departure_date) neu erstellt und drei Tage zurück (increment_offset: 3).
Der Schlüssel für die Erhöhung basiert auf der Dimension departure_date. Dabei handelt es sich um den date-Zeitraum aus der Dimensionsgruppe departure. Auf der Seite mit der Dokumentation zu dimension_group-Parametern finden Sie eine Übersicht über die Funktionsweise von Dimensionsgruppen. Die Dimensionsgruppe und der Zeitraum sind in der Ansicht flights definiert, der für diesen PDT den Wert explore_source hat. So wird die Dimensionsgruppe departure in der Ansichtsdatei flights definiert:
...
dimension_group: departure {
type: time
timeframes: [
raw,
date,
week,
month,
year
]
sql: ${TABLE}.dep_time ;;
}
...
Interaktion von Inkrementparametern und Persistenzstrategie
Die increment_key- und increment_offset-Einstellungen eines PDT sind unabhängig von der Persistenzstrategie des PDT:
- Die inkrementelle Persistenzstrategie (PDT) bestimmt nur, wenn sich die PDT erhöht. Der PDT-Builder ändert die inkrementelle PDT nicht, es sei denn, die Persistenz der Tabelle wird ausgelöst oder sie wird manuell mit der Option Abgeleitete Tabellen & Ausführen in einem explorativen Analysetool ausgelöst.
- Wenn die PDT erhöht wird, bestimmt der PDT-Builder, wann die neuesten Daten zuvor in die Tabelle aufgenommen wurden. Dies geschieht in Form des aktuellen Zeitintervalls (der Zeitraum, der durch den Parameter
increment_keydefiniert wird). Basierend darauf kürzt der PDT-Generator die Daten zum Beginn des jüngsten Zeitinkrements in der Tabelle und erstellt dann das neueste Inkrement von dort. - Wenn der PDT den Parameter
increment_offsethat, erstellt der PDT-Builder auch die Anzahl der vorherigen Zeiträume, die im Parameterincrement_offsetangegeben sind. Die vorherigen Zeiträume beginnen am Anfang des aktuellsten Zeitintervalls, also dem Zeitraum, der durch den Parameterincrement_keydefiniert wird.
Die folgenden Beispielszenarien zeigen, wie inkrementelle PDTs aktualisiert werden, indem die Interaktion von increment_key, increment_offset und Persistenzstrategie dargestellt wird.
Beispiel 1
Dieses Beispiel verwendet eine PDT mit diesen Eigenschaften:
- Anstiegsschlüssel: Datum
- Versatzunterschied: 3
- Persistenzstrategie: Wird einmal pro Monat am ersten Tag des Monats ausgelöst
So wird diese Tabelle aktualisiert:
- Bei einer monatlichen Persistenzstrategie wird die Tabelle automatisch ein Mal im Monat erstellt. Das bedeutet, dass etwa am 1. Juni die letzte Zeile der Tabelle am 1. Mai hinzugefügt worden ist.
- Da diese Tabelle einen auf dem Datum basierten Inkrementschlüssel verwendet, kürzt der PDT-Generator den 1. Mai zurück zum Beginn des Tages und erstellt die Daten für den 1. Mai neu bis zum aktuellen Tag, dem 1. Juni.
- Außerdem hat dieser PDT einen inkrementellen Offset von
3. Der PDT-Generator erstellt also auch die Daten der vorherigen drei Zeiträume (Tage) vor dem 1. Mai neu. Es werden also Daten neu erstellt für den 28., 29. und 30. Mai und bis zum 1. Juni, dem aktuellen Tag.
Diesen SQL-Befehl führt der PDT-Generator am 1. Juni aus, um die Reihen der vorhandenen PDT zu bestimmen, die neu erstellt werden müssen:
## Example SQL for BigQuery:
SELECT FORMAT_TIMESTAMP('%F %T',TIMESTAMP_ADD(MAX(pdt_name),INTERVAL -3 DAY))
## Example SQL for other dialects:
SELECT CAST(DATE_ADD(MAX(pdt_name),INTERVAL -3 DAY) AS CHAR)
Und diesen SQL-Befehl führt der PDT-Generator am 1. Juni aus, um das neueste Inkrement zu erstellen:
## Example SQL for BigQuery:
MERGE INTO [pdt_name] USING (SELECT [columns]
WHERE created_at >= TIMESTAMP('4/28/21 12:00:00 AM'))
AS tmp_name ON FALSE
WHEN NOT MATCHED BY SOURCE AND created_date >= TIMESTAMP('4/28/21 12:00:00 AM')
THEN DELETE
WHEN NOT MATCHED THEN INSERT [columns]
## Example SQL for other dialects:
START TRANSACTION;
DELETE FROM [pdt_name]
WHERE created_date >= TIMESTAMP('4/28/21 12:00:00 AM');
INSERT INTO [pdt_name]
SELECT [columns]
FROM [source_table]
WHERE created_at >= TIMESTAMP('4/28/21 12:00:00 AM');
COMMIT;
Beispiel 2
Dieses Beispiel verwendet eine PDT mit diesen Eigenschaften:
- Persistenzstrategie: Wird einmal täglich ausgelöst
- Anstiegsschlüssel: Monat
- Offset erhöhen: 0
So wird diese Tabelle am 1. Juni aktualisiert:
- Bei einer täglichen Persistenzstrategie wird die Tabelle automatisch ein Mal im Tag erstellt. Am 1. Juni wird die letzte Zeile der Tabelle am 31. Mai hinzugefügt worden sein.
- Da diese Tabelle einen auf dem Monat basierten Inkrementschlüssel verwendet, kürzt der PDT-Generator den 31. Mai zurück zum Beginn des Monats und erstellt die Daten für den gesamten Mai neu bis zum aktuellen Tag, einschließlich des 1. Junis.
- Da diese PDT keinen inkrementellen Offset hat, werden keine vorherigen Zeiträume neu erstellt.
So wird diese Tabelle am 2. Juni aktualisiert:
- Am 2. Juni wird die letzte Zeile der Tabelle am 1. Juni hinzugefügt worden sein.
- Da der PDT-Generator bis zum Anfang des Monats Juni zurück kürzt und dann die Daten beginnend mit dem 1. Juni bis zum aktuellen Tag neu erstellt, werden nur die Daten für den 1. und 2. Juni neu erstellt.
- Da diese PDT keinen inkrementellen Offset hat, werden keine vorherigen Zeiträume neu erstellt.
Beispiel 3
Dieses Beispiel verwendet eine PDT mit diesen Eigenschaften:
- Anstiegsschlüssel: Monat
- Versatzunterschied: 3
- Persistenzstrategie: Wird einmal täglich ausgelöst
Dieses Szenario veranschaulicht eine schlechte Einrichtung einer inkrementellen PDT, da sie eine tägliche PDT mit einem Versatz von drei Monaten ist. Jeden Tag werden die Daten von mindestens drei Monaten neu erstellt, was eine sehr ineffiziente Nutzung einer inkrementellen PDT darstellt. Die Untersuchung dieses Szenarios ist jedoch interessant, um die Funktionsweise einer inkrementellen PDT zu verstehen.
So wird diese Tabelle am 1. Juni aktualisiert:
- Bei einer täglichen Persistenzstrategie wird die Tabelle automatisch ein Mal im Tag erstellt. Am 1. Juni etwa wird die letzte Zeile der Tabelle am 31. Mai hinzugefügt worden sein.
- Da diese Tabelle einen auf dem Monat basierten Inkrementschlüssel verwendet, kürzt der PDT-Generator den 31. Mai zurück zum Beginn des Monats und erstellt die Daten für den gesamten Mai neu bis zum aktuellen Tag, einschließlich des 1. Junis.
- Außerdem hat dieser PDT einen inkrementellen Offset von
3. Das bedeutet, dass der PDT-Builder auch die Daten der letzten drei Zeiträume (Monate) vor Mai neu erstellt. Das Ergebnis ist, dass die Daten vom Februar, März, April bis zum aktuellen Tag (1. Juni) neu erstellt werden.
So wird diese Tabelle am 2. Juni aktualisiert:
- Am 2. Juni wird die letzte Zeile der Tabelle am 1. Juni hinzugefügt worden sein.
- Der PDT-Generator kürzt den Monat zurück zum 1. Juni und erstellt die Daten für den Monat Juni neu, einschließlich des 2. Junis.
- Durch den inkrementellen Offset werden außerdem die Daten der drei Monate vor Juni neu erstellt. Das Ergebnis ist die Neuerstellung der Daten von März, April, Mai und bis zum aktuellen Tag, dem 2. Juni.
Test einer inkrementellen PDT im Entwicklungsmodus
Bevor Sie eine neue inkrementelle PDT für Ihre Produktionsumgebung entwickeln, können Sie die PDT testen und sicherstellen, dass sie erstellt und inkrementiert. Für den Test einer inkrementellen PDT im Entwicklungsmodus:
- So erkundest du eine PDT:
include: "/views/e_faa_pdt.view"
explore: e_faa_pdt {}
Öffnen Sie die Explore der PDT.
TIPP: Nachdem Sie die Ansicht in Ihre Modelldatei aufgenommen und einen Bericht erstellt haben, können Sie über die Datei oder das Modell in Ihrem LookML-Projekt direkt zum Menü „Erkunden“ gehen. Verwenden Sie dazu das Menü „Dateiaktionen“ oben in der LookML-Datei:
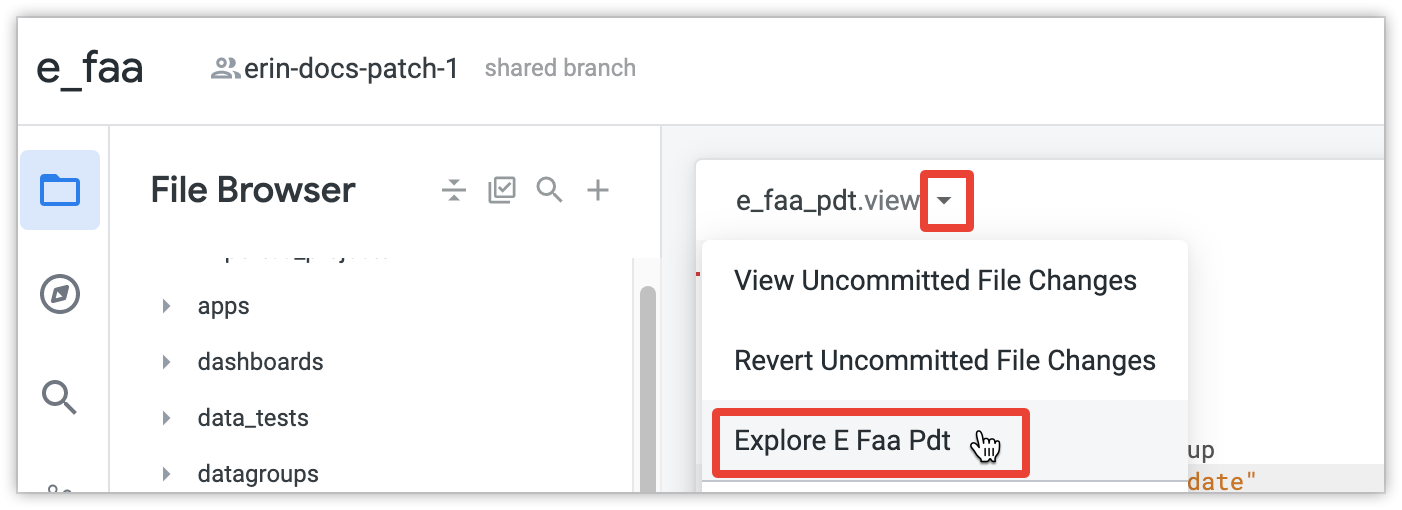
Wählen Sie im Bereich „Erkunden“ einige Dimensionen oder Messwerte aus und klicken Sie auf Ausführen. Looker erstellt dann die gesamte PDT. Ist dies die erste Abfrage mit einer inkrementellen PDT, erstellt der PDT-Generator die gesamte PDT, um die ersten Daten abzurufen. Bei einer großen Tabelle kann diese erste Erstellung sehr viel Zeit in Anspruch nehmen, wie im Falle jeder großen Tabelle.
Mit den folgenden Möglichkeiten können Sie die Erstellung der ersten PDT bestätigen:
- Wenn Sie die Berechtigung
see_logshaben, können Sie anhand des PDT-Ereignisprotokolls prüfen, ob die Tabelle erstellt wurde. Wenn Sie im PDT-Ereignisprotokoll keine PDT-Ereignisse erstellen, sehen Sie sich die Statusinformationen oben im PDT-Ereignisprotokoll an. Wenn dort „Aus dem Cache“ steht, können Sie Cache leeren & Aktualisieren auswählen, um neuere Informationen zu erhalten. - Andernfalls können Sie sich die Kommentare auf dem Tab SQL in der Datenleiste unter „Erkunden“ ansehen. Auf dem Tab SQL sehen Sie die Abfrage und die Aktionen, die ausgeführt werden, wenn Sie die Abfrage im Tab „Erkunden“ ausführen. Wenn in den Kommentaren auf dem Tab SQL beispielsweise
-- generate derived table e_incremental_pdt
- Wenn Sie die Berechtigung
Nachdem Sie den ersten Build der PDT erstellt haben, können Sie mit der Option Abgeleitete Tabellen &Ausführen von „Erkunden“ einen inkrementellen Build der PDT veranlassen.
Sie können mit denselben Methoden wie zuvor die inkrementelle Erstellung der PDT bestätigen:
- Mit der Berechtigung
see_logskannst du im PDT-Ereignisprotokollcreate increment complete-Ereignisse für die inkrementelle PDT ansehen. Wenn Sie dieses Ereignis nicht im PDT-Ereignisprotokoll sehen und der Abfragestatus „Aus dem Cache“ lautet, wählen Sie Cache leeren & Aktualisieren aus, um neuere Informationen zu erhalten. - Sehen Sie sich auf dem Tab SQL der Daten-Leiste des Tabs „Entdecken“ die Kommentare an. In diesem Fall zeigen die Kommentare, dass die PDT inkrementiert wurde. Beispiel:
-- increment persistent derived table e_incremental_pdt to generation 2
- Mit der Berechtigung
Nachdem Sie sich vergewissert haben, dass die PDT erstellt wurde und korrekt inkrementiert wird, können Sie die Parameter
exploreundincludeder PDT aus Ihrer Modelldatei entfernen oder auskommentieren, wenn Sie die entsprechende explorative Datenanalyse für die PDT nicht beibehalten möchten.
Nachdem der PDT im Entwicklungsmodus erstellt wurde, wird dieselbe Tabelle für die Produktion verwendet, sobald Sie Ihre Änderungen bereitstellen, es sei denn, Sie nehmen weitere Änderungen an der Definition der Tabelle vor. Weitere Informationen finden Sie auf der Dokumentationsseite Abgeleitete Tabellen in Looker im Abschnitt Persistierte Tabellen im Entwicklungsmodus.
Unterstützte Datenbankdialekte für inkrementelle PDTs
Damit Looker inkrementelle PDTs in Ihrem Looker-Projekt unterstützt, muss Ihr Datenbankdialekt die Data Definition Language (DDL)-Befehle unterstützen, die das Löschen und Einfügen von Zeilen ermöglichen.
Die folgende Tabelle zeigt, welche Dialekte in der neuesten Version von Looker inkrementelle PDTs unterstützen: